Chapter 34 Interrupted Time Series
Regression Discontinuity in Time
Control for
Seasonable trends
Concurrent events
Pros (Penfold and Zhang 2013)
- control for long-term trends
Cons
Min of 8 data points before and 8 after an intervention
Multiple events hard to distinguish
Notes:
- For subgroup analysis (heterogeneity in effect size), see (Harper and Bruckner 2017)
- To interpret with control variables, see (Bottomley, Scott, and Isham 2019)
Interrupted time series should be used when
- longitudinal data (outcome over time - observations before and after the intervention)
- full population was affected at one specific point in time (or can be stacked based on intervention)
In each ITS framework, there can be 4 possible scenarios of outcome after an intervention
No effects
Immediate effect
Sustained (long-term) effect (smooth)
Both immediate and sustained effect
\[ Y = \beta_0 + \beta_1 T + \beta_2 D + \beta_3 P + \epsilon \]
where
\(Y\) is the outcome variable
- \(\beta_0\) is the baseline level of the outcome
\(T\) is the time variable (e.g., days, weeks, etc.) passed from the start of the observation period
- \(\beta_1\) is the slope of the line before the intervention
\(D\) is the treatment variable where \(1\) is after the intervention and \(0\) is before the intervention.
- \(\beta_2\) is the immediate effect after the intervention
\(P\) is the time variable indicating time passed since the intervention (before the intervention, the value is set to 0) (to examine the sustained effect).
- \(\beta_3\) is the sustained effect = difference between the slope of the line prior to the intervention and the slope of the line subsequent to the intervention
Example
Create a fictitious dataset where we know the true data generating process
\[ Outcome = 10 \times time + 20 \times treatment + 25 \times timesincetreatment + noise \]
# number of days
n = 365
# intervention at day
interven = 200
# time index from 1 to 365
time = c(1:n)
# treatment variable: before internvation = day 1 to 200,
# after intervention = day 201 to 365
treatment = c(rep(0, interven), rep(1, n - interven))
# time since treatment
timesincetreat = c(rep(0, interven), c(1:(n - interven)))
# outcome
outcome = 10 + 15 * time + 20 * treatment +
25 * timesincetreat + rnorm(n, mean = 0, sd = 1)
df = data.frame(outcome, time, treatment, timesincetreat)
head(df, 10)
#> outcome time treatment timesincetreat
#> 1 24.21687 1 0 0
#> 2 39.32492 2 0 0
#> 3 54.64543 3 0 0
#> 4 68.85913 4 0 0
#> 5 84.75341 5 0 0
#> 6 101.29995 6 0 0
#> 7 113.72475 7 0 0
#> 8 130.61608 8 0 0
#> 9 143.40385 9 0 0
#> 10 159.76479 10 0 0Visualize
plot(df$time, df$outcome)
# intervention date
abline(v = interven, col = "blue")
# regression line
ts <- lm(outcome ~ time + treatment + timesincetreat, data = df)
lines(df$time, ts$fitted.values, col = "red")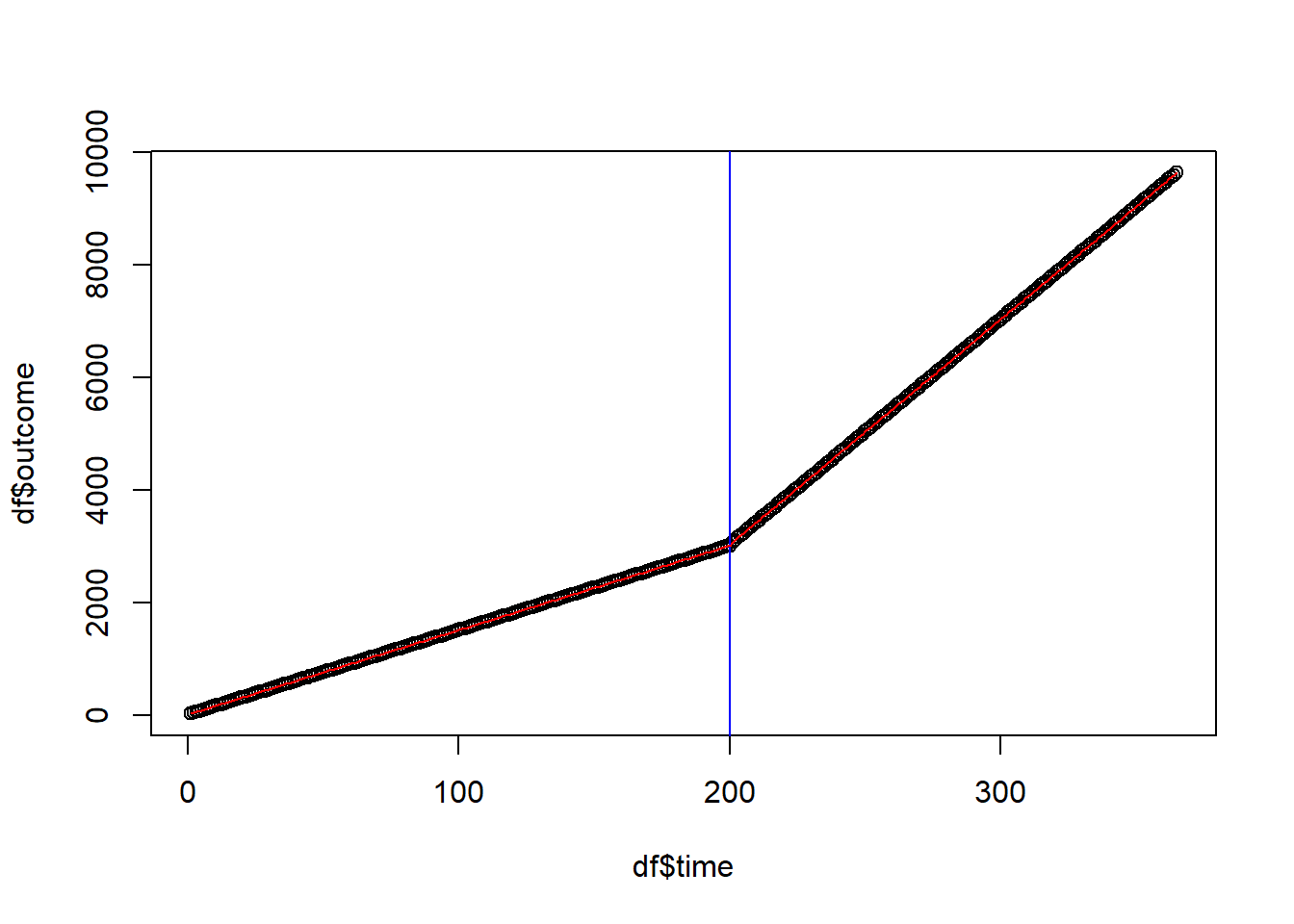
summary(ts)
#>
#> Call:
#> lm(formula = outcome ~ time + treatment + timesincetreat, data = df)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -2.43488 -0.80653 -0.09411 0.76392 3.04793
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 9.904231 0.152106 65.11 <2e-16 ***
#> time 15.000437 0.001312 11430.16 <2e-16 ***
#> treatment 20.068054 0.225567 88.97 <2e-16 ***
#> timesincetreat 25.000138 0.002188 11423.44 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 1.072 on 361 degrees of freedom
#> Multiple R-squared: 1, Adjusted R-squared: 1
#> F-statistic: 8.305e+08 on 3 and 361 DF, p-value: < 2.2e-16Interpretation
Time coefficient shows before-intervention outcome trend. Positive and significant, indicating a rising trend. Every day adds 15 points.
The treatment coefficient shows the immediate increase in outcome. Immediate effect is positive and significant, increasing outcome by 20 points.
The time since treatment coefficient reflects a change in trend subsequent to the intervention. The sustained effect is positive and statistically significant, showing that the outcome increases by 25 points per day after the intervention.
See Lee Rodgers, Beasley, and Schuelke (2014) for suggestions
Plot of counterfactual
# treatment prediction
pred <- predict(ts, df)
# counterfactual dataset
new_df <-
as.data.frame(cbind(
time = time,
# treatment = 0 means counterfactual
treatment = rep(0, n),
# time since treatment = 0 means counterfactual
timesincetreat = rep(0)
))
# counterfactual predictions
pred_cf <- predict(ts, new_df)
# plot
plot(
outcome,
col = gray(0.2, 0.2),
pch = 19,
xlim = c(1,365),
ylim = c(0, 10000),
xlab = "xlab",
ylab = "ylab"
)
# regression line before treatment
lines(rep(1:interven), pred[1:interven], col = "blue", lwd = 3)
# regression line after treatment
lines(rep((interven + 1):n), pred[(interven + 1):n],
col = "blue", lwd = 3)
# regression line after treatment (counterfactual)
lines(
rep(interven:n),
pred_cf[(interven):n],
col = "yellow",
lwd = 3,
lty = 5
)
abline(v = interven, col = "red", lty = 2)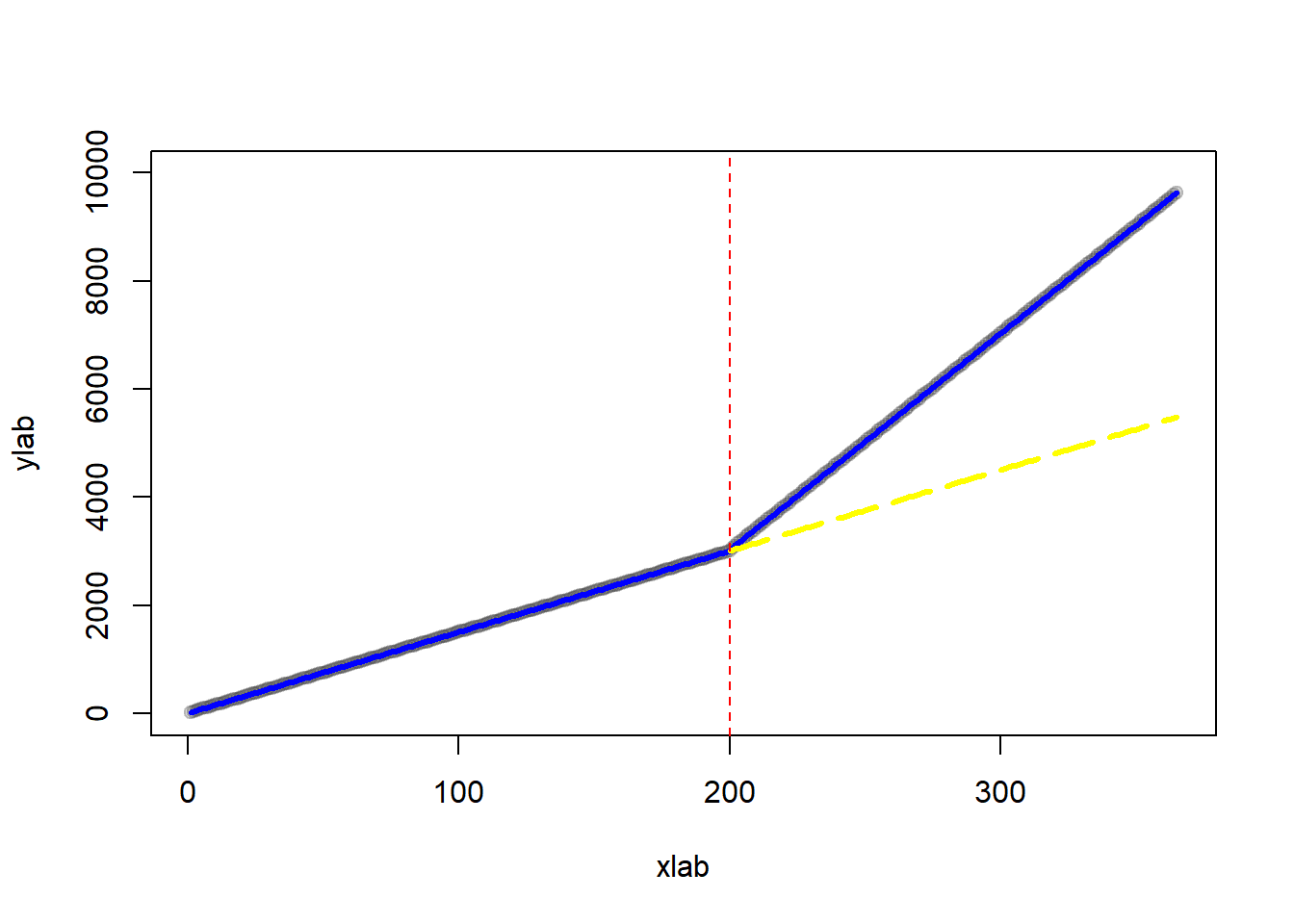
Possible threats to the validity of interrupted time series analysis (Baicker and Svoronos 2019)
Delayed effects (Rodgers, John, and Coleman 2005) (may have to make assess some time after the intervention - do not assess the immediate dates).
Other confounding events Linden (2017)
Intervention is introduced but later withdrawn (Linden 2015)
Autocorrelation (for every time series data): might cause underestimation in the standard errors (i.e., overestimating the statistical significance of the treatment effect)
Regression to the mean: after a the short-term shock to the outcome, individuals can revert back to their initial states.
Selection bias: only certain individuals are affected by the treatment (could use a Multiple Groups).