24 Regression Discontinuity
-
A regression discontinuity occurs when there is a discrete change (jump) in treatment likelihood in the distribution of a continuous (or roughly continuous) variable (i.e., running/forcing/assignment variable).
- Running variable can also be time, but the argument for time to be continuous is hard to argue because usually we do not see increment of time (e.g., quarterly or annual data). Unless we have minute or hour data, then we might be able to argue for it.
Review paper (G. Imbens and Lemieux 2008; Lee and Lemieux 2010)
-
Other readings:
(Thistlethwaite and Campbell 1960): first paper to use RD in the context of merit awards on future academic outcomes.
-
RD is a localized experiment at the cutoff point
- Hence, we always have to qualify (perfunctory) our statement in research articles that “our research might not generalize to beyond the bandwidth.”
In reality, RD and experimental (from random assignment) estimates are very similar ((Chaplin et al. 2018); Mathematica). But still, it’s hard to prove empirically for every context (there might be future study that finds a huge difference between local estimate - causal - and overall estimate - random assignment.
Threats: only valid near threshold: inference at threshold is valid on average. Interestingly, random experiment showed the validity already.
Tradeoff between efficiency and bias
Regression discontinuity is under the framework of Instrumental Variable (structural IV) argued by (J. D. Angrist and Lavy 1999) and a special case of the Matching Methods (matching at one point) argued by (James J. Heckman, LaLonde, and Smith 1999).
The hard part is to find a setting that can apply, but once you find one, it’s easy to apply
We can also have multiple cutoff lines. However, for each cutoff line, there can only be one breakup point
RD can have multiple coinciding effects (i.e., joint distribution or bundled treatment), then RD effect in this case would be the joint effect.
As the running variable becomes more discrete your framework should be Interrupted Time Series, but for more granular levels you can use RD. When you have infinite data (or substantially large) the two frameworks are identical. RD is always better than Interrupted Time Series
-
Multiple alternative model specifications that produce consistent results are more reliable (parametric - linear regression with polynomials terms, and non-parametric - local linear regression). This is according to (Lee and Lemieux 2010), one straightforward method to ease the linearity assumption is by incorporating polynomial functions of the forcing variable. The choice of polynomial terms can be determined based on the data.
- . According to (Gelman and Imbens 2019), accounting for global high-order polynomials presents three issues: (1) imprecise estimates due to noise, (2) sensitivity to the polynomial’s degree, and (3) inadequate coverage of confidence intervals. To address this, researchers should instead employ estimators that rely on local linear or quadratic polynomials or other smooth functions.
RD should be viewed more as a description of a data generating process, rather than a method or approach (similar to a randomized experiment)
-
RD is close to
other quasi-experimental methods in the sense that it’s based on the discontinuity at a threshold
randomized experiments in the sense that it’s local randomization.
There are several types of Regression Discontinuity:
-
Sharp RD: Change in treatment probability at the cutoff point is 1
- Kink design: Instead of a discontinuity in the level of running variable, we have a discontinuity in the slope of the function (while the function/level can remain continuous) (Nielsen, Sørensen, and Taber 2010). See (Böckerman, Kanninen, and Suoniemi 2018) for application, and (Card et al. 2015) for theory.
Kink RD
Fuzzy RD: Change in treatment probability less than 1
Fuzzy Kink RD
RDiT: running variable is time.
Others:
Multiple cutoff
Multiple Scores
Geographic RD
Dynamic Treatments
Continuous Treatments
Consider
\[ D_i = 1_{X_i > c} \]
\[ D_i = \begin{cases} D_i = 1 \text{ if } X_i > C \\ D_i = 0 \text{ if } X_i < C \end{cases} \]
where
\(D_i\) = treatment effect
\(X_i\) = score variable (continuous)
\(c\) = cutoff point
Identification (Identifying assumptions) of RD:
Average Treatment Effect at the cutoff (Continuity-based)
\[ \begin{aligned} \alpha_{SRDD} &= E[Y_{1i} - Y_{0i} | X_i = c] \\ &= E[Y_{1i}|X_i = c] - E[Y_{0i}|X_i = c]\\ &= \lim_{x \to c^+} E[Y_{1i}|X_i = c] - \lim_{x \to c^=} E[Y_{0i}|X_i = c] \end{aligned} \]
Average Treatment Effect in a neighborhood (Local Randomization-based):
\[ \begin{aligned} \alpha_{LR} &= E[Y_{1i} - Y_{0i}|X_i \in W] \\ &= \frac{1}{N_1} \sum_{X_i \in W, T_i = 1}Y_i - \frac{1}{N_0}\sum_{X_i \in W, T_i =0} Y_i \end{aligned} \]
RDD estimates the local average treatment effect (LATE), at the cutoff point which is not at the individual or population levels.
Since researchers typically care more about the internal validity, than external validity, localness affects only external validity.
Assumptions:
Independent assignment
-
Continuity of conditional regression functions
- \(E[Y(0)|X=x]\) and \(E[Y(1)|X=x]\) are continuous in x.
RD is valid if cutpoint is exogenous (i.e., no endogenous selection) and running variable is not manipulable
Only treatment(s) (e.g., could be joint distribution of multiple treatments) cause discontinuity or jump in the outcome variable
All other factors are smooth through the cutoff (i.e., threshold) value. (we can also test this assumption by seeing no discontinuity in other factors). If they “jump”, they will bias your causal estimate
Threats to RD
-
Variables (other than treatment) change discontinuously at the cutoff
- We can test for jumps in these variables (including pre-treatment outcome)
Multiple discontinuities for the assignment variable
-
Manipulation of the assignment variable
- At the cutoff point, check for continuity in the density of the assignment variable.
24.1 Estimation and Inference
24.1.1 Local Randomization-based
Additional Assumption: Local Randomization approach assumes that inside the chosen window \(W = [c-w, c+w]\) are assigned to treatment as good as random:
- Joint probability distribution of scores for units inside the chosen window \(W\) is known
- Potential outcomes are not affected by value of the score
This approach is stronger than the Continuity-based because we assume the regressions are continuously at \(c\) and unaffected by the running variable within window \(W\)
Because we can choose the window \(W\) (within which random assignment is plausible), the sample size can typically be small.
To choose the window \(W\), we can base on either
- where the pre-treatment covariate-balance is observed
- independent tests between outcome and score
- domain knowledge
To make inference, we can either use
(Fisher) randomization inference
(Neyman) design-based
24.1.2 Continuity-based
-
also known as the local polynomial method
- as the name suggests, global polynomial regression is not recommended (because of lack of robustness, and over-fitting and Runge’s phenomenon)
Step to estimate local polynomial regression
- Choose polynomial order and weighting scheme
- Choose bandwidth that has optimal MSE or coverage error
- Estimate the parameter of interest
- Examine robust bias-correct inference
24.2 Specification Checks
24.2.1 Balance Checks
Also known as checking for Discontinuities in Average Covariates
Null Hypothesis: The average effect of covariates on pseudo outcomes (i.e., those qualitatively cannot be affected by the treatment) is 0.
If this hypothesis is rejected, you better have a good reason to why because it can cast serious doubt on your RD design.
24.2.2 Sorting/Bunching/Manipulation
Also known as checking for A Discontinuity in the Distribution of the Forcing Variable
Also known as clustering or density test
Formal test is McCrary sorting test (McCrary 2008) or (Cattaneo, Idrobo, and Titiunik 2019)
-
Since human subjects can manipulate the running variable to be just above or below the cutoff (assuming that the running variable is manipulable), especially when the cutoff point is known in advance for all subjects, this can result in a discontinuity in the distribution of the running variable at the cutoff (i.e., we will see “bunching” behavior right before or after the cutoff)>
People would like to sort into treatment if it’s desirable. The density of the running variable would be 0 just below the threshold
People would like to be out of treatment if it’s undesirable
-
(McCrary 2008) proposes a density test (i.e., a formal test for manipulation of the assignment variable).
\(H_0\): The continuity of the density of the running variable (i.e., the covariate that underlies the assignment at the discontinuity point)
\(H_a\): A jump in the density function at that point
Even though it’s not a requirement that the density of the running must be continuous at the cutoff, but a discontinuity can suggest manipulations.
(J. L. Zhang and Rubin 2003; Lee 2009; Aronow, Baron, and Pinson 2019) offers a guide to know when you should warrant the manipulation
-
Usually it’s better to know your research design inside out so that you can suspect any manipulation attempts.
- We would suspect the direction of the manipulation. And typically, it’s one-way manipulation. In cases where we might have both ways, theoretically they would cancel each other out.
We could also observe partial manipulation in reality (e.g., when subjects can only imperfectly manipulate). But typically, as we treat it like fuzzy RD, we would not have identification problems. But complete manipulation would lead to serious identification issues.
Remember: even in cases where we fail to reject the null hypothesis for the density test, we could not rule out completely that identification problem exists (just like any other hypotheses)
Bunching happens when people self-select to a specific value in the range of a variable (e.g., key policy thresholds).
Review paper (Kleven 2016)
This test can only detect manipulation that changes the distribution of the running variable. If you can choose the cutoff point or you have 2-sided manipulation, this test will fail to detect it.
Histogram in bunching is similar to a density curve (we want narrower bins, wider bins bias elasticity estimates)
We can also use bunching method to study individuals’ or firm’s responsiveness to changes in policy.
-
Under RD, we assume that we don’t have any manipulation in the running variable. However, bunching behavior is a manipulation by firms or individuals. Thus, violating this assumption.
Bunching can fix this problem by estimating what densities of individuals would have been without manipulation (i.e., manipulation-free counterfactual).
The fraction of persons who manipulated is then calculated by comparing the observed distribution to manipulation-free counterfactual distributions.
Under RD, we do not need this step because the observed and manipulation-free counterfactual distributions are assumed to be the same. RD assume there is no manipulation (i.e., assume the manipulation-free counterfactual distribution)
When running variable and outcome variable are simultaneously determined, we can use a modified RDD estimator to have consistent estimate. (Bajari et al. 2011)
-
Assumptions:
Manipulation is one-sided: People move one way (i.e., either below the threshold to above the threshold or vice versa, but not to or away the threshold), which is similar to the monotonicity assumption under instrumental variable 33.1.3.1
Manipulation is bounded (also known as regularity assumption): so that we can use people far away from this threshold to derive at our counterfactual distribution [Blomquist et al. (2021)](Bertanha, McCallum, and Seegert 2021)
Steps:
- Identify the window in which the running variable contains bunching behavior. We can do this step empirically based on Bosch, Dekker, and Strohmaier (2020). Additionally robustness test is needed (i.e., varying the manipulation window).
- Estimate the manipulation-free counterfactual
- Calculating the standard errors for inference can follow (Chetty, Hendren, and Katz 2016) where we bootstrap re-sampling residuals in the estimation of the counts of individuals within bins (large data can render this step unnecessary).
If we pass the bunching test, we can move on to the Placebo Test
McCrary (2008) test
A jump in the density at the threshold (i.e., discontinuity) hold can serve as evidence for sorting around the cutoff point
library(rdd)
# you only need the runing variable and the cutoff point
# Example by the package's authors
#No discontinuity
x<-runif(1000,-1,1)
DCdensity(x,0)
#> [1] 0.6126802
#Discontinuity
x<-runif(1000,-1,1)
x<-x+2*(runif(1000,-1,1)>0&x<0)
DCdensity(x,0)
#> [1] 0.0008519227Cattaneo, Idrobo, and Titiunik (2019) test
library(rddensity)
# Example by the package's authors
# Continuous Density
set.seed(1)
x <- rnorm(2000, mean = -0.5)
rdd <- rddensity(X = x, vce = "jackknife")
summary(rdd)
#>
#> Manipulation testing using local polynomial density estimation.
#>
#> Number of obs = 2000
#> Model = unrestricted
#> Kernel = triangular
#> BW method = estimated
#> VCE method = jackknife
#>
#> c = 0 Left of c Right of c
#> Number of obs 1376 624
#> Eff. Number of obs 354 345
#> Order est. (p) 2 2
#> Order bias (q) 3 3
#> BW est. (h) 0.514 0.609
#>
#> Method T P > |T|
#> Robust -0.6798 0.4966
#>
#>
#> P-values of binomial tests (H0: p=0.5).
#>
#> Window Length / 2 <c >=c P>|T|
#> 0.036 28 20 0.3123
#> 0.072 46 39 0.5154
#> 0.107 68 59 0.4779
#> 0.143 94 79 0.2871
#> 0.179 122 103 0.2301
#> 0.215 145 130 0.3986
#> 0.250 163 156 0.7370
#> 0.286 190 176 0.4969
#> 0.322 214 200 0.5229
#> 0.358 249 218 0.1650
# you have to specify your own plot (read package manual)24.2.3 Placebo Tests
Also known as Discontinuities in Average Outcomes at Other Values
-
We should not see any jumps at other values (either \(X_i <c\) or \(X_i \ge c\))
- Use the same bandwidth you use for the cutoff, and move it along the running variable: testing for a jump in the conditional mean of the outcome at the median of the running variable.
Also known as falsification checks
Before and after the cutoff point, we can run the placebo test to see whether X’s are different).
The placebo test is where you expect your coefficients to be not different from 0.
-
This test can be used for
Testing no discontinuity in predetermined variables:
Testing other discontinuities
Placebo outcomes: we should see any changes in other outcomes that shouldn’t have changed.
Inclusion and exclusion of covariates: RDD parameter estimates should not be sensitive to the inclusion or exclusion of other covariates.
This is analogous to Experimental Design where we cannot only test whether the observables are similar in both treatment and control groups (if we reject this, then we don’t have random assignment), but we cannot test unobservables.
Balance on observable characteristics on both sides
\[ Z_i = \alpha_0 + \alpha_1 f(x_i) + [I(x_i \ge c)] \alpha_2 + [f(x_i) \times I(x_i \ge c)]\alpha_3 + u_i \]
where
\(x_i\) is the running variable
\(Z_i\) is other characteristics of people (e.g., age, etc)
Theoretically, \(Z_i\) should no be affected by treatment. Hence, \(E(\alpha_2) = 0\)
Moreover, when you have multiple \(Z_i\), you typically have to simulate joint distribution (to avoid having significant coefficient based on chance).
The only way that you don’t need to generate joint distribution is when all \(Z_i\)’s are independent (unlikely in reality).
Under RD, you shouldn’t have to do any Matching Methods. Because just like when you have random assignment, there is no need to make balanced dataset before and after the cutoff. If you have to do balancing, then your RD assumptions are probably wrong in the first place.
24.2.4 Sensitivity to Bandwidth Choice
-
Methods for bandwidth selection
Ad-hoc or substantively driven
Data driven: cross validation
Conservative approach: (Calonico, Cattaneo, and Farrell 2020)
The objective is to minimize the mean squared error between the estimated and actual treatment effects.
Then, we need to see how sensitive our results will be dependent on the choice of bandwidth.
In some cases, the best bandwidth for testing covariates may not be the best bandwidth for treating them, but it may be close.
# find optimal bandwidth by Imbens-Kalyanaraman
rdd::IKbandwidth(running_var,
outcome_var,
cutpoint = "",
kernel = "triangular") # can also pick other kernels24.2.5 Manipulation Robust Regression Discontinuity Bounds
-
McCrary (2008) linked density jumps at cutoffs in RD studies to potential manipulation.
If no jump is detected, researchers proceed with RD analysis; if detected, they halt using the cutoff for inference.
-
Some studies use the “doughnut-hole” method, excluding near-cutoff observations and extrapolating, which contradicts RD principles.
False negative could be due to a small sample size and can lead to biased estimates, as units near the cutoff may still differ in unobserved ways.
Even correct rejections of no manipulation may overlook that the data can still be informative despite modest manipulation.
Gerard, Rokkanen, and Rothe (2020) introduces a systematic approach to handle potentially manipulated variables in RD designs, addressing both concerns.
-
The model introduces two types of unobservable units in RD designs:
always-assigned units, which are always on one side of the cutoff,
-
potentially-assigned units, which fit traditional RD assumptions.
- The standard RD model is a subset of this broader model, which assumes no always-assigned units.
Identifying assumption: manipulation occurs through one-sided selection.
The approach does not make a binary decision on manipulation in RD designs but assesses its extent and worst-case impact.
Two steps are used:
- Determining the proportion of always-assigned units using the discontinuity at the cutoff
- Bounding treatment effects based on the most extreme feasible outcomes for these units.
For sharp RD designs, bounds are established by trimming extreme outcomes near the cutoff; for fuzzy designs, the process involves more complex adjustments due to additional model constraints.
Extensions of the study use covariate information and economic behavior assumptions to refine these bounds and identify covariate distributions among unit types at the cutoff.
Setup
Independent data points \((X_i, Y_i, D_i)\), where \(X_i\) is the running variable, \(Y_i\) is the outcome, and \(D_i\) indicates treatment status (1 if treated, 0 otherwise). Treatment is assigned based on \(X_i \geq c\).
The design is sharp if \(D_i = I(X_i \geq c)\) and fuzzy otherwise.
The population is divided into:
Potentially-assigned units (\(M_i = 0\)): Follow the standard RD framework, with potential outcomes \(Y_i(d)\) and potential treatment states \(D_i(x)\).
Always-assigned units (\(M_i = 1\)): These units do not require potential outcomes or states, and always have \(X_i\) values beyond the cutoff.
Assumptions
-
Local Independence and Continuity:
- \(P(D = 1|X = c^+, M = 0) > P(D = 1|X = c^-, M = 0)\)
- No defiers: \(P(D^+ \geq D^-|X = c, M = 0) = 1\)
- Continuity in potential outcomes and states at \(c\).
- \(F_{X|M=0}(x)\) is differentiable at \(c\), with a positive derivative.
-
Smoothness of the Running Variable among Potentially-Assigned Units:
- The derivative of \(F_{X|M=0}(x)\) is continuous at \(c\).
-
Restrictions on Always-Assigned Units:
- \(P(X \geq c|M = 1) = 1\) and \(F_{X|M=1}(x)\) is right-differentiable (or left-differentiable) at \(c\).
- This (local) one-sided manipulation assumption allows identification of the proportion of always-assigned units among all units close to the cutoff.
When always-assigned unit exist, the RD design is fuzzy because we have
- Treated and untreated units among the potentially-assigned (below and above the cutoff)
- Always-assigned units (above the cutoff).
Causal Effects of Interest
causal effects among potentially-assigned units:
\[ \Gamma = E[Y(1) - Y(0) | X = c, D^+ > D^-, M = 0] \]
This parameter represents the local average treatment effect (LATE) for the subgroup of “compliers”—units that receive treatment if and only if their running variable \(X_i\) exceeds a certain cutoff.
The parameter \(\Gamma\) captures the causal effect of changes in the cutoff level on treatment status among potentially-assigned compliers.
| RD designs with a manipulated running variable | “Doughnut-Hole” RD Designs: |
|---|---|
|
|
Identification of \(\tau\) in RD Designs
Identification challenges arise due to the inability to distinguish always-assigned from potentially-assigned units, thus Γ is not point identified. We establish sharp bounds on Γ
These bounds are supported by the stochastic dominance of the potential outcome CDFs over observed distributions.
Unit Types and Notation:
- \(C_0\): Potentially-assigned compliers.
- \(A_0\): Potentially-assigned always-takers.
- \(N_0\): Potentially-assigned never-takers.
- \(T_1\): Always-assigned treated units.
- \(U_1\): Always-assigned untreated units.
The measure \(\tau\) , representing the proportion of always-assigned units near the cutoff, is point identified by the discontinuity in the observed running variable density \(f_X\) at the cutoff
Sharp RD:
Units to the left of the cutoff are potentially assigned units. The distribution of their observed outcomes (\(Y\)) are the outcomes \(Y(0)\) of potentially-assigned compliers (\(C_0\)) at the cutoff.
To determine the bounds on the treatment effect (\(\Gamma\)), we need to assess the distribution of treated outcomes (\(Y(1)\)) for the same potentially-assigned compliers at the cutoff.
Information regarding the treated outcomes (\(Y(1)\)) comes exclusively from the subpopulation of treated units, which includes both potentially-assigned compliers (\(C_0\)) and those always assigned units (\(T_1\)).
With \(\tau\) point identified, we can estimate sharp bounds on \(\Gamma\).
Fuzzy RD:
| Subpopulation | Types of units |
|---|---|
| \(X = c^+, D = 1\) | \(C_0, A_0, T_1\) |
| \(X = c^-, D = 1\) | \(A_0\) |
| \(X= c^+, D = 0\) | \(N_0, U_1\) |
| \(X = c^-, D = 0\) | \(C_0, N_0\) |
Unit Types and Combinations: There are five distinct unit types and four combinations of treatment assignments and decisions relevant to the analysis. These distinctions are important because they affect how potential outcomes are analyzed and bounded.
Outcome Distributions: The analysis involves estimating the distribution of potential outcomes (both treated and untreated) among potentially-assigned compliers at the cutoff.
-
Three-Step Process:
Potential Outcomes Under Treatment: Bounds on the distribution of treated outcomes are determined using data from treated units.
Potential Outcomes Under Non-Treatment: Bounds on the distribution of untreated outcomes are derived using data from untreated units.
Bounds on Parameters of Interest: Using the bounds from the first two steps, sharp upper and lower bounds on the local average treatment effect are derived.
Extreme Value Consideration: The bounds for treatment effects are based on “extreme” scenarios under worst-case assumptions about the distribution of potential outcomes, making them sharp but empirically relevant within the data constraints.
Extensions:
Quantile Treatment Effects: alternative to average effects by focusing on different quantiles of the outcome distribution, which are less affected by extreme values.
Applicability to Discrete Outcomes
Behavioral Assumptions Impact: Assuming a high likelihood of treatment among always-assigned units can narrow the bounds of treatment effects by refining the analysis of potential outcomes.
Utilization of Covariates: Incorporating covariates measured prior to treatment can refine the bounds on treatment effects and help target policies by identifying covariate distributions among different unit types.
Notes:
-
Quantile Treatment Effects (QTEs): QTE bounds are less sensitive to the tails of the outcome distribution, making them tighter than ATE bounds.
Inference on ATEs is sensitive to the extent of manipulation, with confidence intervals widening significantly with small degrees of assumed manipulation.
Inference on QTEs is less affected by manipulation, remaining meaningful even with larger degrees of manipulation.
Alternative Inference Strategy when manipulation is believed to be unlikely. Try different hypothetical values of \(\tau\)
devtools::install_github("francoisgerard/rdbounds/R")
library(formattable)
library(data.table)
library(rdbounds)
set.seed(123)
df <- rdbounds_sampledata(10000, covs = FALSE)
#> [1] "True tau: 0.117999815082062"
#> [1] "True treatment effect on potentially-assigned: 2"
#> [1] "True treatment effect on right side of cutoff: 2.35399944524618"
head(df)
#> x y treatment
#> 1 -1.2532616 3.489563 0
#> 2 -0.5146925 3.365232 0
#> 3 3.4853777 6.193533 0
#> 4 0.1576616 8.820440 1
#> 5 0.2890962 4.791972 0
#> 6 3.8350019 7.316907 0
rdbounds_est <-
rdbounds(
y = df$y,
x = df$x,
# covs = as.factor(df$cov),
treatment = df$treatment,
c = 0,
discrete_x = FALSE,
discrete_y = FALSE,
bwsx = c(.2, .5),
bwy = 1,
# for median effect use
# type = "qte",
# percentiles = .5,
kernel = "epanechnikov",
orders = 1,
evaluation_ys = seq(from = 0, to = 15, by = 1),
refinement_A = TRUE,
refinement_B = TRUE,
right_effects = TRUE,
yextremes = c(0, 15),
num_bootstraps = 5
)
#> [1] "The proportion of always-assigned units just to the right of the cutoff is estimated to be 0.04209"
#> [1] "2024-05-13 19:12:33 Estimating CDFs for point estimates"
#> [1] "2024-05-13 19:12:33 .....Estimating CDFs for units just to the right of the cutoff"
#> [1] "2024-05-13 19:12:35 Estimating CDFs with nudged tau (tau_star)"
#> [1] "2024-05-13 19:12:35 .....Estimating CDFs for units just to the right of the cutoff"
#> [1] "2024-05-13 19:12:38 Beginning parallelized output by bootstrap.."
#> [1] "2024-05-13 19:12:42 Computing Confidence Intervals"
#> [1] "2024-05-13 19:12:51 Time taken:0.3 minutes"
rdbounds_summary(rdbounds_est, title_prefix = "Sample Data Results")
#> [1] "Time taken: 0.3 minutes"
#> [1] "Sample size: 10000"
#> [1] "Local Average Treatment Effect:"
#> $tau_hat
#> [1] 0.04209028
#>
#> $tau_hat_CI
#> [1] 0.1671043 0.7765031
#>
#> $takeup_increase
#> [1] 0.7521208
#>
#> $takeup_increase_CI
#> [1] 0.7065353 0.7977063
#>
#> $TE_SRD_naive
#> [1] 1.770963
#>
#> $TE_SRD_naive_CI
#> [1] 1.541314 2.000612
#>
#> $TE_SRD_bounds
#> [1] 1.569194 1.912681
#>
#> $TE_SRD_CI
#> [1] -0.1188634 3.5319468
#>
#> $TE_SRD_covs_bounds
#> [1] NA NA
#>
#> $TE_SRD_covs_CI
#> [1] NA NA
#>
#> $TE_FRD_naive
#> [1] 2.356601
#>
#> $TE_FRD_naive_CI
#> [1] 1.995430 2.717772
#>
#> $TE_FRD_bounds
#> [1] 1.980883 2.362344
#>
#> $TE_FRD_CI
#> [1] -0.6950823 4.6112538
#>
#> $TE_FRD_bounds_refinementA
#> [1] 1.980883 2.357499
#>
#> $TE_FRD_refinementA_CI
#> [1] -0.6950823 4.6112538
#>
#> $TE_FRD_bounds_refinementB
#> [1] 1.980883 2.351411
#>
#> $TE_FRD_refinementB_CI
#> [1] -0.6152215 4.2390830
#>
#> $TE_FRD_covs_bounds
#> [1] NA NA
#>
#> $TE_FRD_covs_CI
#> [1] NA NA
#>
#> $TE_SRD_CIs_manipulation
#> [1] NA NA
#>
#> $TE_FRD_CIs_manipulation
#> [1] NA NA
#>
#> $TE_SRD_right_bounds
#> [1] 1.376392 2.007746
#>
#> $TE_SRD_right_CI
#> [1] -5.036752 5.889137
#>
#> $TE_FRD_right_bounds
#> [1] 1.721121 2.511504
#>
#> $TE_FRD_right_CI
#> [1] -6.663269 7.414185
rdbounds_est_tau <-
rdbounds(
y = df$y,
x = df$x,
# covs = as.factor(df$cov),
treatment = df$treatment,
c = 0,
discrete_x = FALSE,
discrete_y = FALSE,
bwsx = c(.2, .5),
bwy = 1,
kernel = "epanechnikov",
orders = 1,
evaluation_ys = seq(from = 0, to = 15, by = 1),
refinement_A = TRUE,
refinement_B = TRUE,
right_effects = TRUE,
potential_taus = c(.025, .05, .1, .2),
yextremes = c(0, 15),
num_bootstraps = 5
)
#> [1] "The proportion of always-assigned units just to the right of the cutoff is estimated to be 0.04209"
#> [1] "2024-05-13 19:12:52 Estimating CDFs for point estimates"
#> [1] "2024-05-13 19:12:52 .....Estimating CDFs for units just to the right of the cutoff"
#> [1] "2024-05-13 19:12:53 Estimating CDFs with nudged tau (tau_star)"
#> [1] "2024-05-13 19:12:53 .....Estimating CDFs for units just to the right of the cutoff"
#> [1] "2024-05-13 19:12:56 Beginning parallelized output by bootstrap.."
#> [1] "2024-05-13 19:13:02 Estimating CDFs with fixed tau value of: 0.025"
#> [1] "2024-05-13 19:13:02 Estimating CDFs with fixed tau value of: 0.05"
#> [1] "2024-05-13 19:13:02 Estimating CDFs with fixed tau value of: 0.1"
#> [1] "2024-05-13 19:13:02 Estimating CDFs with fixed tau value of: 0.2"
#> [1] "2024-05-13 19:13:03 Beginning parallelized output by bootstrap x fixed tau.."
#> [1] "2024-05-13 19:13:09 Computing Confidence Intervals"
#> [1] "2024-05-13 19:13:19 Time taken:0.46 minutes"
causalverse::plot_rd_aa_share(rdbounds_est_tau) # For SRD (default)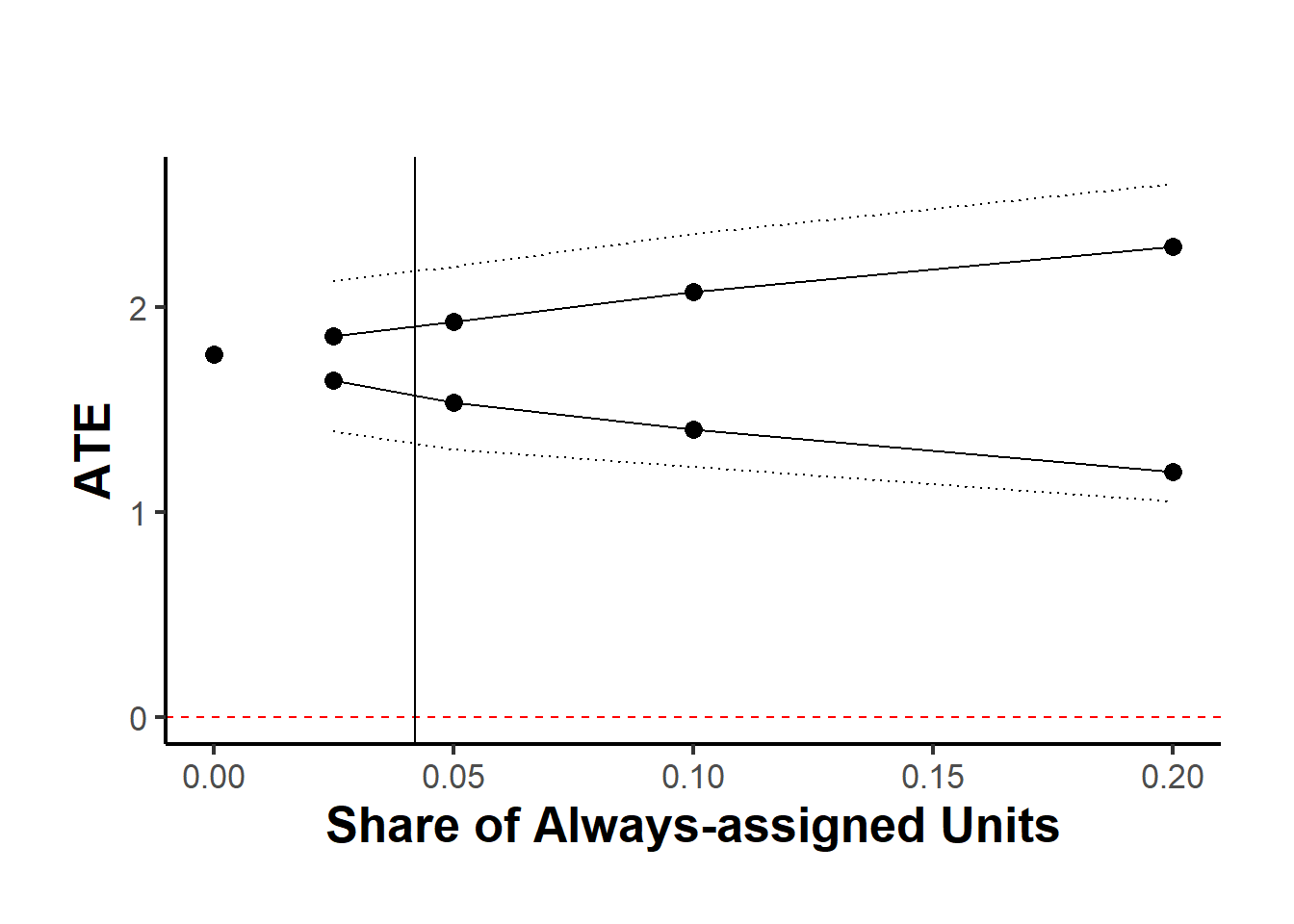
# causalverse::plot_rd_aa_share(rdbounds_est_tau, rd_type = "FRD") # For FRD24.3 Fuzzy RD Design
When you have cutoff that does not perfectly determine treatment, but creates a discontinuity in the likelihood of receiving the treatment, you need another instrument
For those that are close to the cutoff, we create an instrument for \(D_i\)
\[ Z_i= \begin{cases} 1 & \text{if } X_i \ge c \\ 0 & \text{if } X_c < c \end{cases} \]
Then, we can estimate the effect of the treatment for compliers only (i.e., those treatment \(D_i\) depends on \(Z_i\))
The LATE parameter
\[ \lim_{c - \epsilon \le X \le c + \epsilon, \epsilon \to 0}( \frac{E(Y |Z = 1) - E(Y |Z=0)}{E(D|Z = 1) - E(D|Z = 0)}) \]
equivalently, the canonical parameter:
\[ \frac{lim_{x \downarrow c}E(Y|X = x) - \lim_{x \uparrow c} E(Y|X = x)}{\lim_{x \downarrow c } E(D |X = x) - \lim_{x \uparrow c}E(D |X=x)} \]
Two equivalent ways to estimate
-
First
Sharp RDD for \(Y\)
Sharp RDD for \(D\)
Take the estimate from step 1 divide by that of step 2
Second: Subset those observations that are close to \(c\) and run instrumental variable \(Z\)
24.4 Regression Kink Design
If the slope of the treatment intensity changes at the cutoff (instead of the level of treatment assignment), we can have regression kink design
Example: unemployment benefits
Sharp Kink RD parameter
\[ \alpha_{KRD} = \frac{\lim_{x \downarrow c} \frac{d}{dx}E[Y_i |X_i = x]- \lim_{x \uparrow c} \frac{d}{dx}E[Y_i |X_i = x]}{\lim_{x \downarrow c} \frac{d}{dx}b(x) - \lim_{x \uparrow c} \frac{d}{dx}b(x)} \]
where \(b(x)\) is a known function inducing “kink”
Fuzzy Kink RD parameter
\[ \alpha_{KRD} = \frac{\lim_{x \downarrow c} \frac{d}{dx}E[Y_i |X_i = x]- \lim_{x \uparrow c} \frac{d}{dx}E[Y_i |X_i = x]}{\lim_{x \downarrow c} \frac{d}{dx}E[D_i |X_i = x]- \lim_{x \uparrow c} \frac{d}{dx}E[D_i |X_i = x]} \]
24.6 Multi-score
Multi-score (in multiple dimensions) (e.g., math and English cutoff for certain honor class):
\[ \tau (x_1, x_2) = E[Y_{1i} - Y_{0i}|X_{1i} = x_1, X_{2i} = x] \]
24.7 Steps for Sharp RD
Graph the data by computing the average value of the outcome variable over a set of bins (large enough to see a smooth graph, and small enough to make the jump around the cutoff clear).
Run regression on both sides of the cutoff to get the treatment effect
-
Robustness checks:
Assess possible jumps in other variables around the cutoff
Hypothesis testing for bunching
Placebo tests
Varying bandwidth
24.8 Steps for Fuzzy RD
Graph the data by computing the average value of the outcome variable over a set of bins (large enough to see a smooth graph, and small enough to make the jump around the cutoff clear).
Graph the probability of treatment
Estimate the treatment effect using 2SLS
-
Robustness checks:
Assess possible jumps in other variables around the cutoff
Hypothesis testing for bunching
Placebo tests
Varying bandwidth
24.9 Steps for RDiT (Regression Discontinuity in Time)
Notes:
- Additional assumption: Time-varying confounders change smoothly across the cutoff date
- Typically used in policy implementation in the same date for all subjects, but can also be used for cases where implementation dates are different between subjects. In the second case, researchers typically use different RDiT specification for each time series.
- Sometimes the date of implementation is not randomly assigned by chosen strategically. Hence, RDiT should be thought of as the “discontinuity at a threshold” interpretation of RD (not as “local randomization”). (C. Hausman and Rapson 2018, 8)
- Normal RD uses variation in the \(N\) dimension, while RDiT uses variation in the \(T\) dimension
- Choose polynomials based on BIC typically. And can have either global polynomial or pre-period and post-period polynomial for each time series (but usually the global one will perform better)
- Could use augmented local linear outlined by (C. Hausman and Rapson 2018, 12), where estimate the model with all the control first then take the residuals to include in the model with the RDiT treatment (remember to use bootstrapping method to account for the first-stage variance in the second stage).
Pros:
-
can overcome cases where there is no cross-sectional variation in treatment implementation (DID is not feasible)
- There are papers that use both RDiT and DID to (1) see the differential treatment effects across individuals/ space (Auffhammer and Kellogg 2011) or (2) compare the 2 estimates where the control group’s validity is questionable (Gallego, Montero, and Salas 2013).
Better than pre/post comparison because it can include flexible controls
Better than event studies because it can use long-time horizons (may not be too relevant now since the development long-time horizon event studies), and it can use higher-order polynomials time control variables.
Cons:
Taking observation for from the threshold (in time) can bias your estimates because of unobservables and time-series properties of the data generating process.
(McCrary 2008) test is not possible (see Sorting/Bunching/Manipulation) because when the density of the running (time) is uniform, you can’t use the test.
Time-varying unobservables may impact the dependent variable discontinuously
Error terms are likely to include persistence (serially correlated errors)
-
Researchers cannot model time-varying treatment under RDiT
- In a small enough window, the local linear specification is fine, but the global polynomials can either be too big or too small (C. Hausman and Rapson 2018)
Biases
-
Time-Varying treatment Effects
-
increase sample size either by
more granular data (greater frequency): will not increase power because of the problem of serial correlation
increasing time window: increases bias from other confounders
-
2 additional assumption:
Model is correctly specified (with all confoudners or global polynomial approximation)
Treatment effect is correctly specified (whether it’s smooth and constant, or varies)
These 2 assumptions do not interact ( we don’t want them to interact - i.e., we don’t want the polynomial correlated with the unobserved variation in the treatment effect)
There usually a difference between short-run and long-run treatment effects, but it’s also possibly that the bias can stem from the over-fitting problem of the polynomial specification. (C. Hausman and Rapson 2018, 544)
-
-
Autoregression (serial dependence)
Need to use clustered standard errors to account for serial dependence in the residuals
In the case of serial dependence in \(\epsilon_{it}\), we don’t have a solution, including a lagged dependent variable would misspecify the model (probably find another research project)
In the case of serial dependence in \(y_{it}\), with long window, it becomes fuzzy to what you try to recover. You can include the lagged dependent variable (bias can still come from the time-varying treatment or over-fitting of the global polynomial)
-
Sorting and Anticipation Effects
Cannot run the (McCrary 2008) because the density of the time running variable is uniform
Can still run tests to check discontinuities in other covariates (you want no discontinuities) and discontinuities in the outcome variable at other placebo thresholds ( you don’t want discontinuities)
Hence, it’s hard to argue for the causal effect here because it could be the total effect of the causal treatment and the unobserved sorting/anticipation/adaptation/avoidance effects. You can only argue that there is no such behavior
Recommendations for robustness check following (C. Hausman and Rapson 2018, 549)
- Plot the raw data and residuals (after removing confounders or trend). With varying polynomial and local linear controls, inconsistent results can be a sign of time-varying treatment effects.
- Using global polynomial, you could overfit, then show polynomial with different order and alternative local linear bandwidths. If the results are consistent, you’re okay
- Placebo Tests: estimate another RD (1) on another location or subject (that did not receive the treatment) or (2) use another date.
- Plot RD discontinuity on continuous controls
- Donut RD to see if avoiding the selection close to the cutoff would yield better results (Barreca et al. 2011)
- Test for auto-regression (using only pre-treatment data). If there is evidence for autoregression, include the lagged dependent variable
- Augmented local linear (no need to use global polynomial and avoid over-fitting)
Use full sample to exclude the effect of important predictors
Estimate the conditioned second stage on a smaller sample bandwidth
Examples from (C. Hausman and Rapson 2018, 534) in
econ
(Davis 2008): Air quality
(Auffhammer and Kellogg 2011): Air quality
(H. Chen et al. 2018): Air quality
(De Paola, Scoppa, and Falcone 2013): car accidents
(Gallego, Montero, and Salas 2013): air quality
(Bento et al. 2014): Traffic
(M. L. Anderson 2014): Traffic
(Burger, Kaffine, and Yu 2014): Car accidents
(Brodeur et al. 2021): Covid19 lock-downs on well-being
marketing
M. R. Busse et al. (2013): Vehicle prices
(X. Chen et al. 2009): Customer Satisfaction
(M. R. Busse, Simester, and Zettelmeyer 2010): Vehicle prices
(Davis and Kahn 2010): vehicle prices
24.10 Evaluation of an RD
-
Evidence for (either formal tests or graphs)
Treatment and outcomes change discontinuously at the cutoff, while other variables and pre-treatment outcomes do not.
No manipulation of the assignment variable.
Results are robust to various functional forms of the forcing variable
Is there any other (unobserved) confound that could cause the discontinuous change at the cutoff (i.e., multiple forcing variables / bundling of institutions)?
External Validity: How likely the result at the cutoff will generalize?
General Model
\[ Y_i = \beta_0 + f(x_i) \beta_1 + [I(x_i \ge c)]\beta_2 + \epsilon_i \]
where \(f(x_i)\) is any functional form of \(x_i\)
Simple case
When \(f(x_i) = x_i\) (linear function)
\[ Y_i = \beta_0 + x_i \beta_1 + [I(x_i \ge c)]\beta_2 + \epsilon_i \]
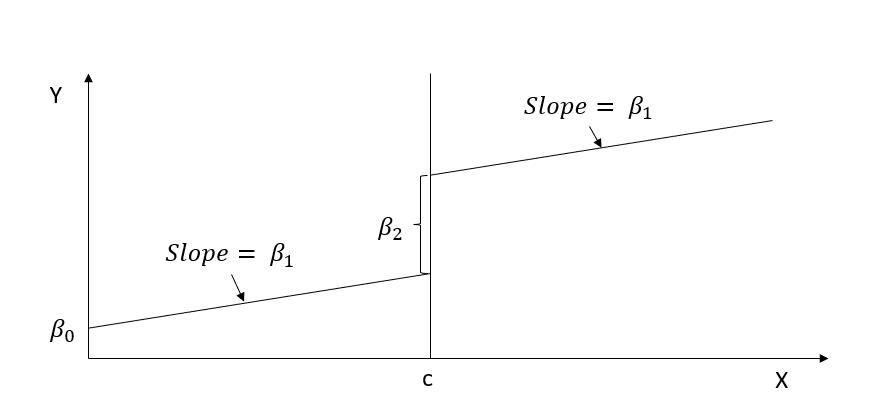
RD gives you \(\beta_2\) (causal effect) of \(X\) on \(Y\) at the cutoff point
In practice, everyone does
\[ Y_i = \alpha_0 + f(x) \alpha _1 + [I(x_i \ge c)]\alpha_2 + [f(x_i)\times [I(x_i \ge c)]\alpha_3 + u_i \]
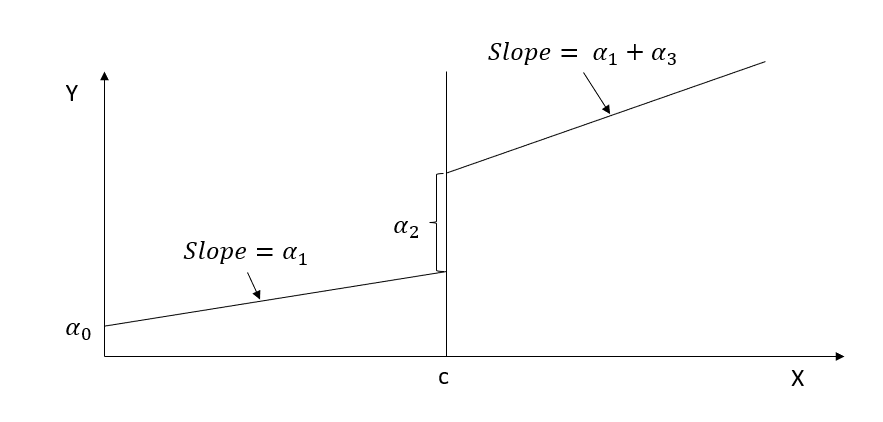
where we estimate different slope on different sides of the line
and if you estimate \(\alpha_3\) to be no different from 0 then we return to the simple case
Notes:
Sparse data can make \(\alpha_3\) large differential effect
People are very skeptical when you have complex \(f(x_i)\), usual simple function forms (e.g., linear, squared term, etc.) should be good. However, if you still insist, then non-parametric estimation can be your best bet.
Bandwidth of \(c\) (window)
Closer to \(c\) can give you lower bias, but also efficiency
Wider \(c\) can increase bias, but higher efficiency.
Optimal bandwidth is very controversial, but usually we have to do it in the appendix for research article anyway.
-
We can either
drop observations outside of bandwidth or
weight depends on how far and close to \(c\)
24.11 Applications
Examples in marketing:
(Hartmann, Nair, and Narayanan 2011): nonparametric estimation and guide to identifying causal marketing mix effects
Packages in R (see (Thoemmes, Liao, and Jin 2017) for detailed comparisons): all can handle both sharp and fuzzy RD
rddrdrobustestimation, inference and plotrddensitydiscontinuity in density tests (Sorting/Bunching/Manipulation) using local polynomials and binomial testrdlocrandcovariate balance, binomial tests, window selectionrdmultimultiple cutoffs and multiple scoresrdpowerpower, sample selectionrddtools
| Package | rdd | rdrobust | rddtools |
|---|---|---|---|
| Coefficient estimator | Local linear regression | local polynomial regression | local polynomial regression |
| bandwidth selectors | (G. Imbens and Kalyanaraman 2012) |
(Calonico, Cattaneo, and Farrell 2020) |
(G. Imbens and Kalyanaraman 2012) |
|
Kernel functions
|
Epanechnikov Gaussian |
Epanechnikov | Gaussian |
| Bias Correction | Local polynomial regression | ||
| Covariate options | Include | Include |
Include Residuals |
| Assumptions testing | McCrary sorting |
McCrary sorting Equality of covariates distribution and mean |
based on table 1 (Thoemmes, Liao, and Jin 2017) (p. 347)
24.11.1 Example 1
Example by Leihua Ye
\[ Y_i = \beta_0 + \beta_1 X_i + \beta_2 W_i + u_i \]
\[ X_i = \begin{cases} 1, W_i \ge c \\ 0, W_i < c \end{cases} \]
#cutoff point = 3.5
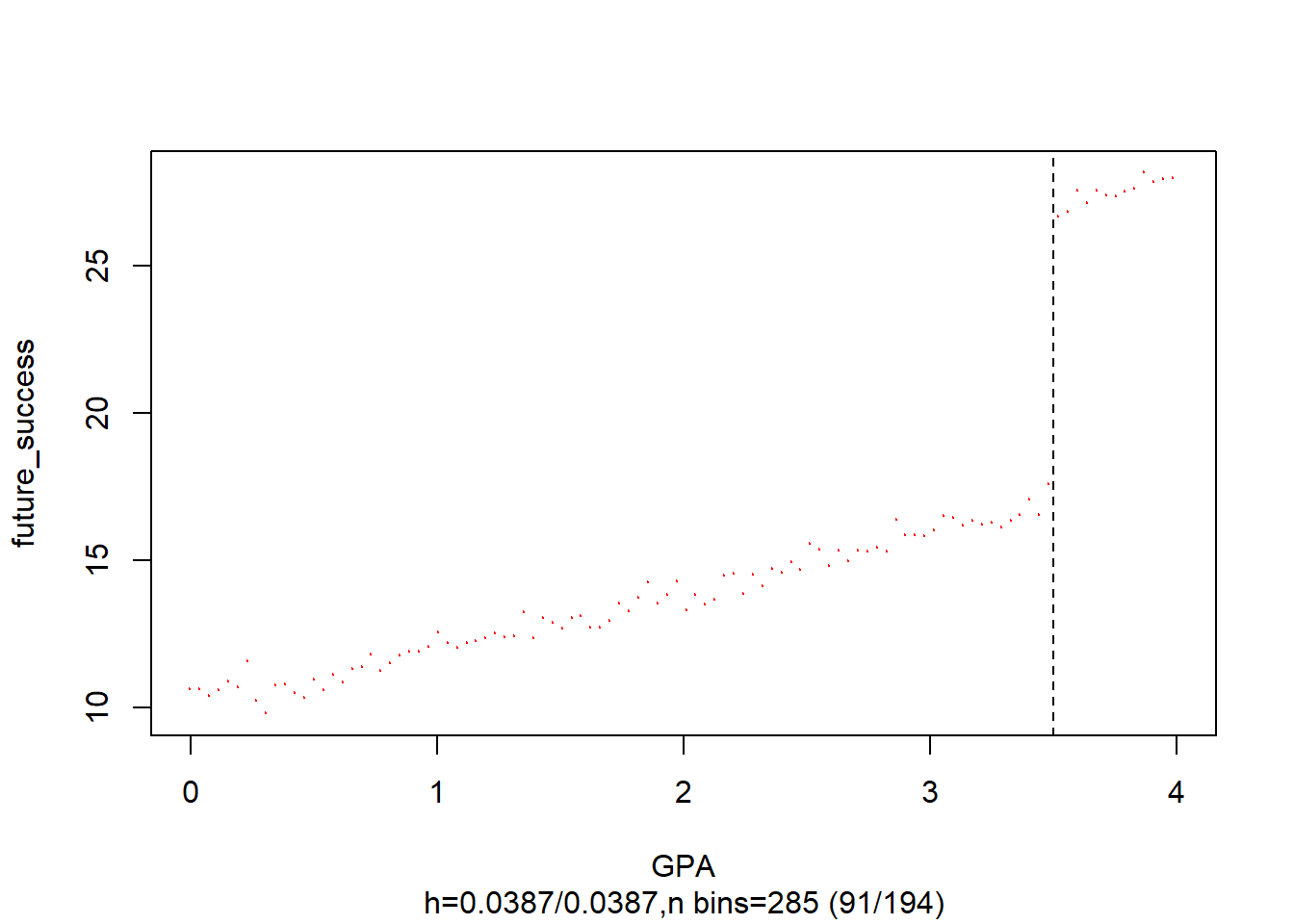
GPA <- runif(1000, 0, 4)
future_success <- 10 + 2 * GPA + 10 * (GPA >= 3.5) + rnorm(1000)
#install and load the package ‘rddtools’
#install.packages(“rddtools”)
library(rddtools)
data <- rdd_data(future_success, GPA, cutpoint = 3.5)
# plot the dataset
plot(
data,
col = "red",
cex = 0.1,
xlab = "GPA",
ylab = "future_success"
)
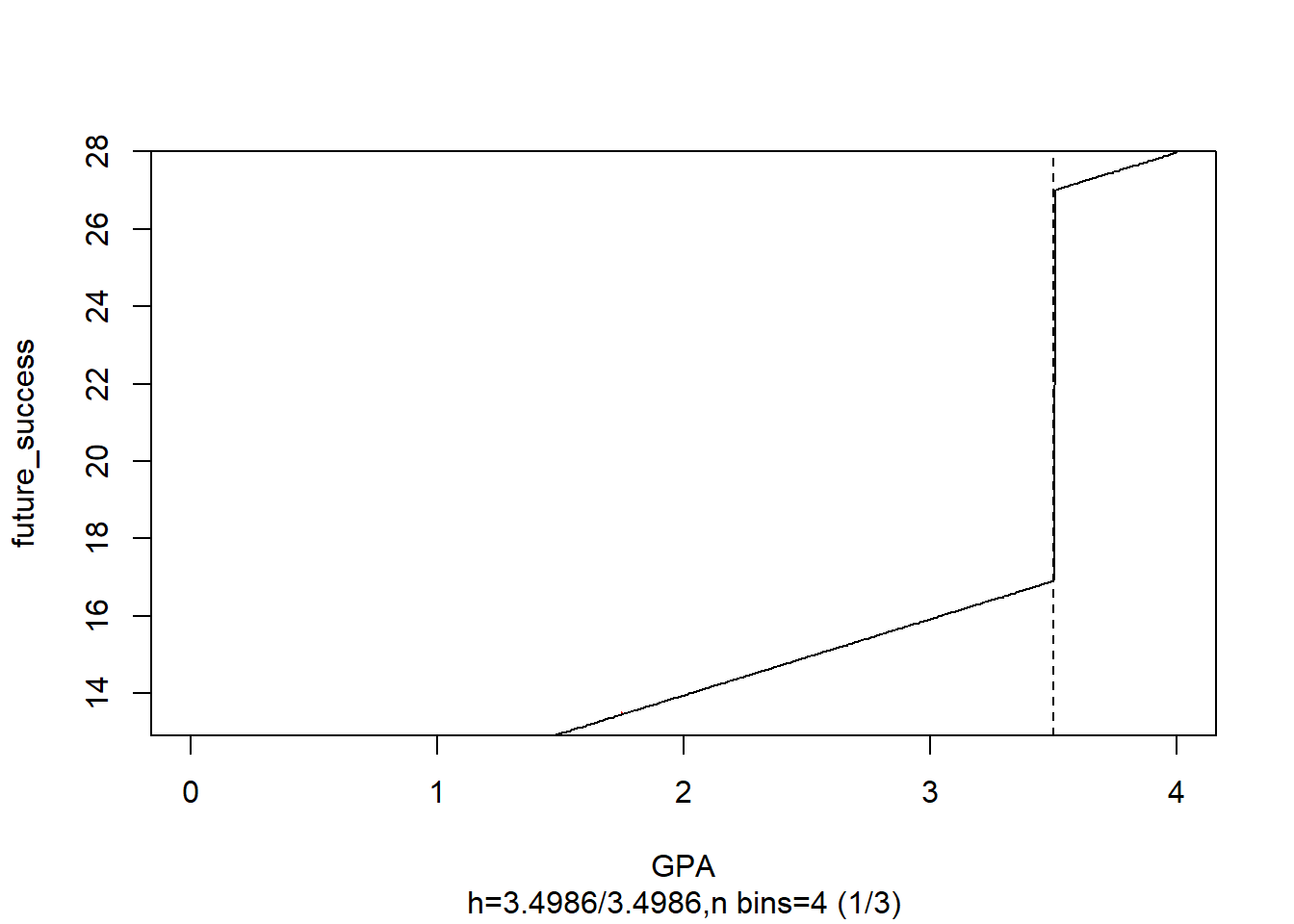
# estimate the sharp RDD model
rdd_mod <- rdd_reg_lm(rdd_object = data, slope = "same")
summary(rdd_mod)
#>
#> Call:
#> lm(formula = y ~ ., data = dat_step1, weights = weights)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -2.90364 -0.70348 0.00278 0.66828 3.00603
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 16.90704 0.06637 254.75 <2e-16 ***
#> D 10.09058 0.11063 91.21 <2e-16 ***
#> x 1.97078 0.03281 60.06 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 0.9908 on 997 degrees of freedom
#> Multiple R-squared: 0.9654, Adjusted R-squared: 0.9654
#> F-statistic: 1.392e+04 on 2 and 997 DF, p-value: < 2.2e-16
# plot the RDD model along with binned observations
plot(
rdd_mod,
cex = 0.1,
col = "red",
xlab = "GPA",
ylab = "future_success"
)
24.11.2 Example 2
Bowblis and Smith (2021)
Occupational licensing can either increase or decrease market efficiency:
More information means more efficiency
Increased entry barriers (i.e., friction) increase efficiency
Components of RD
- Running variable
- Cutoff: 120 beds or above
- Treatment: you have to have the treatment before the cutoff point.
Under OLS
\[ Y_i = \alpha_0 + X_i \alpha_1 + LW_i \alpha_2 + \epsilon_i \]
where
\(LW_i\) Licensed/certified workers (in fraction format for each center).
\(Y_i\) = Quality of service
Bias in \(\alpha_2\)
Mitigation-based: terrible quality can lead to more hiring, which negatively bias \(\alpha_2\)
Preference-based: places that have higher quality staff want to keep high quality staffs.
Under RD
\[ \begin{aligned} Y_{ist} &= \beta_0 + [I(Bed \ge121)_{ist}]\beta_1 + f(Size_{ist}) \beta_2\\ &+ [f(Size_{ist}) \times I(Bed \ge 121)_{ist}] \beta_3 \\ &+ X_{it} \delta + \gamma_s + \theta_t + \epsilon_{ist} \end{aligned} \]
where
\(s\) = state
\(t\) = year
\(i\) = hospital
This RD is fuzzy
If right near the threshold (bandwidth), we have states with different sorting (i.e., non-random), then we need the fixed-effect for state \(s\). But then your RD assumption wrong anyway, then you won’t do it in the first place
Technically, we could also run the fixed-effect regression, but because it’s lower in the causal inference hierarchy. Hence, we don’t do it.
Moreover, in the RD framework, we don’t include \(t\) before treatment (but in the FE we have to include before and after)
If we include \(\pi_i\) for each hospital, then we don’t have variation in the causal estimates (because hardly any hospital changes their bed size in the panel)
When you have \(\beta_1\) as the intent to treat (because the treatment effect does not coincide with the intent to treat)
You cannot take those fuzzy cases out, because it will introduce the selection bias.
Note that we cannot drop cases based on behavioral choice (because we will exclude non-compliers), but we can drop when we have particular behaviors ((e.g., people like round numbers).
Thus, we have to use Instrument variable 33.1.3.1
Stage 1:
\[ \begin{aligned} QSW_{ist} &= \alpha_0 + [I(Bed \ge121)_{ist}]\alpha_1 + f(Size_{ist}) \alpha_2\\ &+ [f(Size_{ist}) \times I(Bed \ge 121)_{ist}] \alpha_3 \\ &+ X_{it} \delta + \gamma_s + \theta_t + \epsilon_{ist} \end{aligned} \]
(Note: you should have different fixed effects and error term - \(\delta, \gamma_s, \theta_t, \epsilon_{ist}\) from the first equation, but I ran out of Greek letters)
Stage 2:
\[ \begin{aligned} Y_{ist} &= \gamma_0 + \gamma_1 \hat{QWS}_{ist} + f(Size_{ist}) \delta_2 \\ &+ [f(Size_{ist}) \times I(Bed \ge 121)] \delta_3 \\ &+ X_{it} \lambda + \eta_s + \tau_t + u_{ist} \end{aligned} \]
The bigger the jump (discontinuity), the more similar the 2 coefficients (\(\gamma_1 \approx \beta_1\)) where \(\gamma_1\) is the average treatment effect (of exposing to the policy)
\(\beta_1\) will always be closer to 0 than \(\gamma_1\)
Figure 1 shows bunching at every 5 units cutoff, but 120 is still out there.
If we have manipulable bunching, there should be decrease at 130
Since we have limited number of mass points (at the round numbers), we should clustered standard errors by the mass point
24.11.3 Example 3
Replication of (Carpenter and Dobkin 2009) by Philipp Leppert, dataset from here
24.11.4 Example 4
For a detailed application, see (Thoemmes, Liao, and Jin 2017) where they use rdd, rdrobust, rddtools