5.1 The idea of sampling
A RQ implies that every member of the population should be studied (the P in POCI stand for ‘population’). However, being able to do so is very rare because of cost, time, ethics, logistics or practicality. Hence, a subset of the population (a sample) is almost always studied.
A sample consists of some individuals (or cases, or (if the individuals are people) subjects) from the population. The purpose of a sample is to approximate the population.
A study is externally valid if the results can be generalised to other groups in the population, apart from the sample studied. This is only possible if the sample is chosen to well-represent the whole population.
However, since a sample doesn’t include every member of the population, conclusions made from samples cannot be certain to apply to the whole population.
In research, the goal is to learn about the population, but only a sample can be studied.
This book is essentially about how to learn about a population based on an imperfect sample.
Example 4.1 (Samples) A study (based on Lipton et al. (1998)) of the effect of aspirin in treating headaches cannot possible use every single human alive who might one day wish to take aspirin.
Not only would this be prohibitively expensive, time-consuming, and impractical, but such a study would not even use those humans who had not been born yet who might use aspirin. (That is, using the whole target population is impossible.) A sample must be used.Having seen that using a sample is necessary, other issues are raised:
- How can we learn something useful about the whole population if only some of that population is studied?
- Which individuals should be included in the sample?
- How many individuals should be included in the sample be?
The last issue must be left until later, after learning more about the implications of studying a sample rather than a population.
Using a sample instead of the entire population presents challenges. Every sample is likely to be a bit different, so what is learnt from a sample depends on which individuals happen to be present in the sample being used. This is called sampling variation. That is, each sample produced different data, and so may lead to different answers to the RQ.
This is the challenge of research: How to make decisions about populations, using an imperfect sample information. Perhaps surprisingly, lots can be learnt about the population if we approach the task of selecting a sample correctly.
Almost always, samples are studied, not populations.
Every sample is likely to be different, and hence the results from every sample are likely to be different. This is called sampling variation.
While we can never be certain about the conclusions from the sample, special tools can be used to help make decisions about the population from a sample.The animation below shows how the estimates calculated from a sample vary from sample to sample. We know that 50% of cards in a fair pack are red, but each sample of 10 cards can produced a different percentage of red cards (and does not always produce an estimate of 50%).
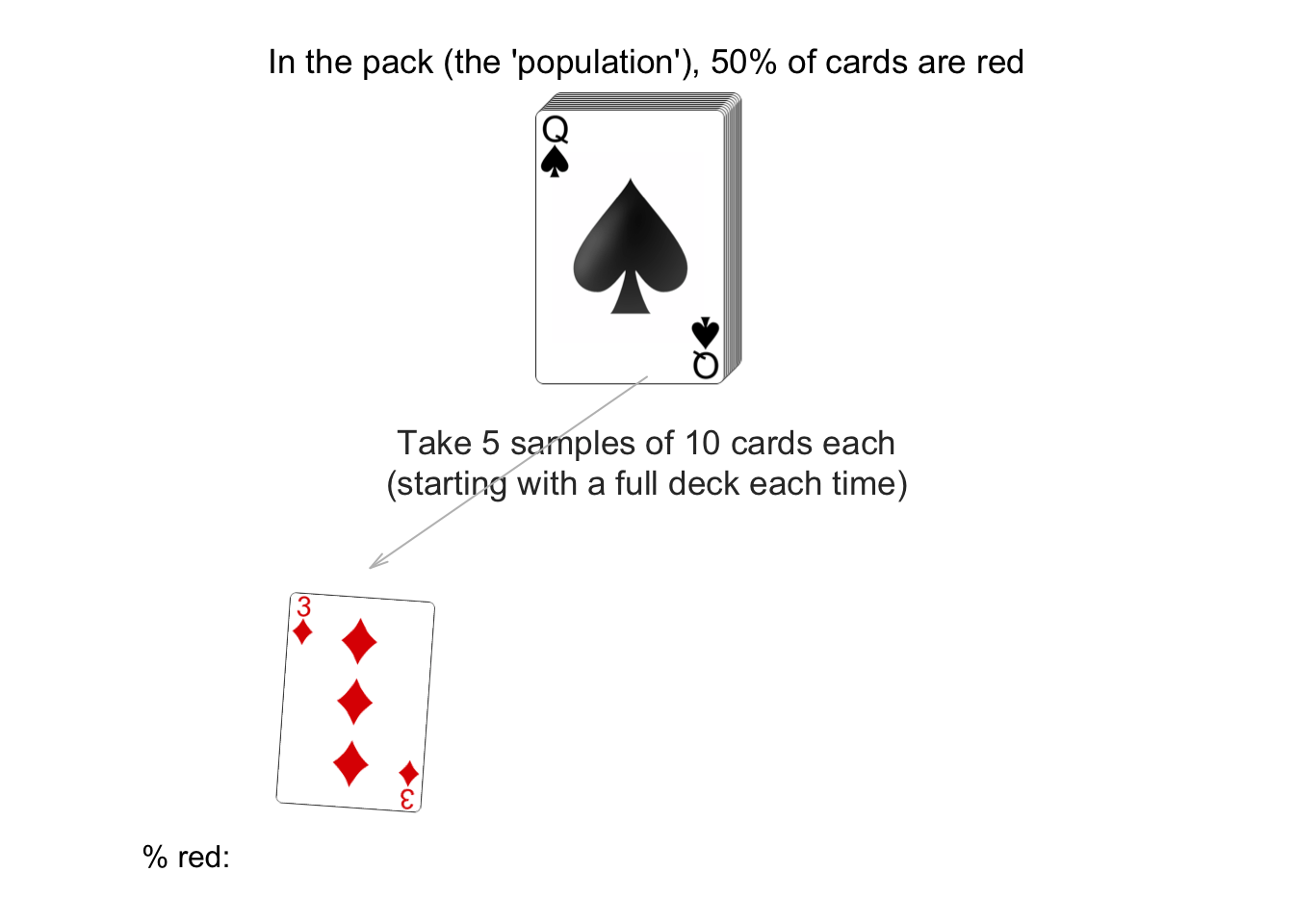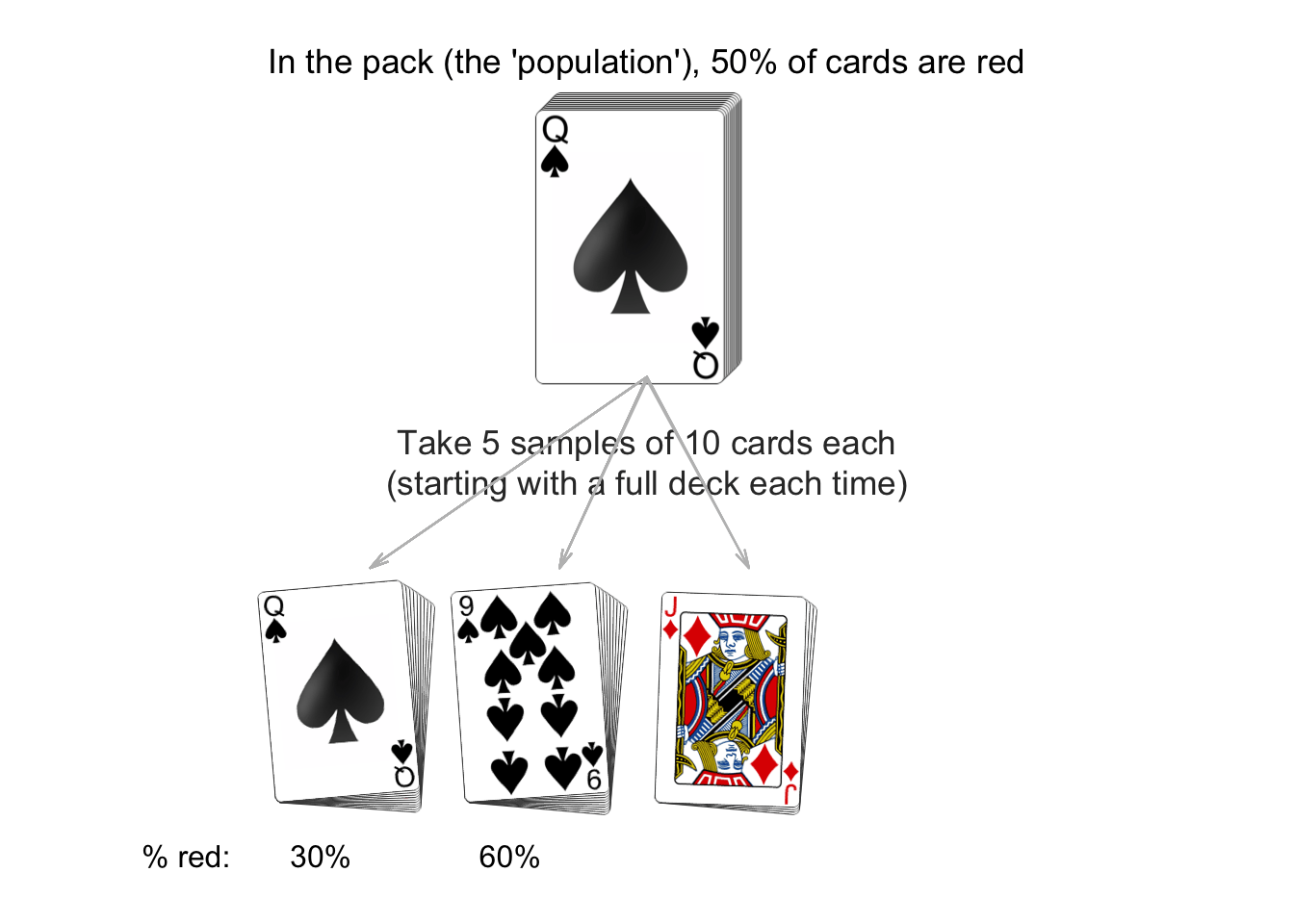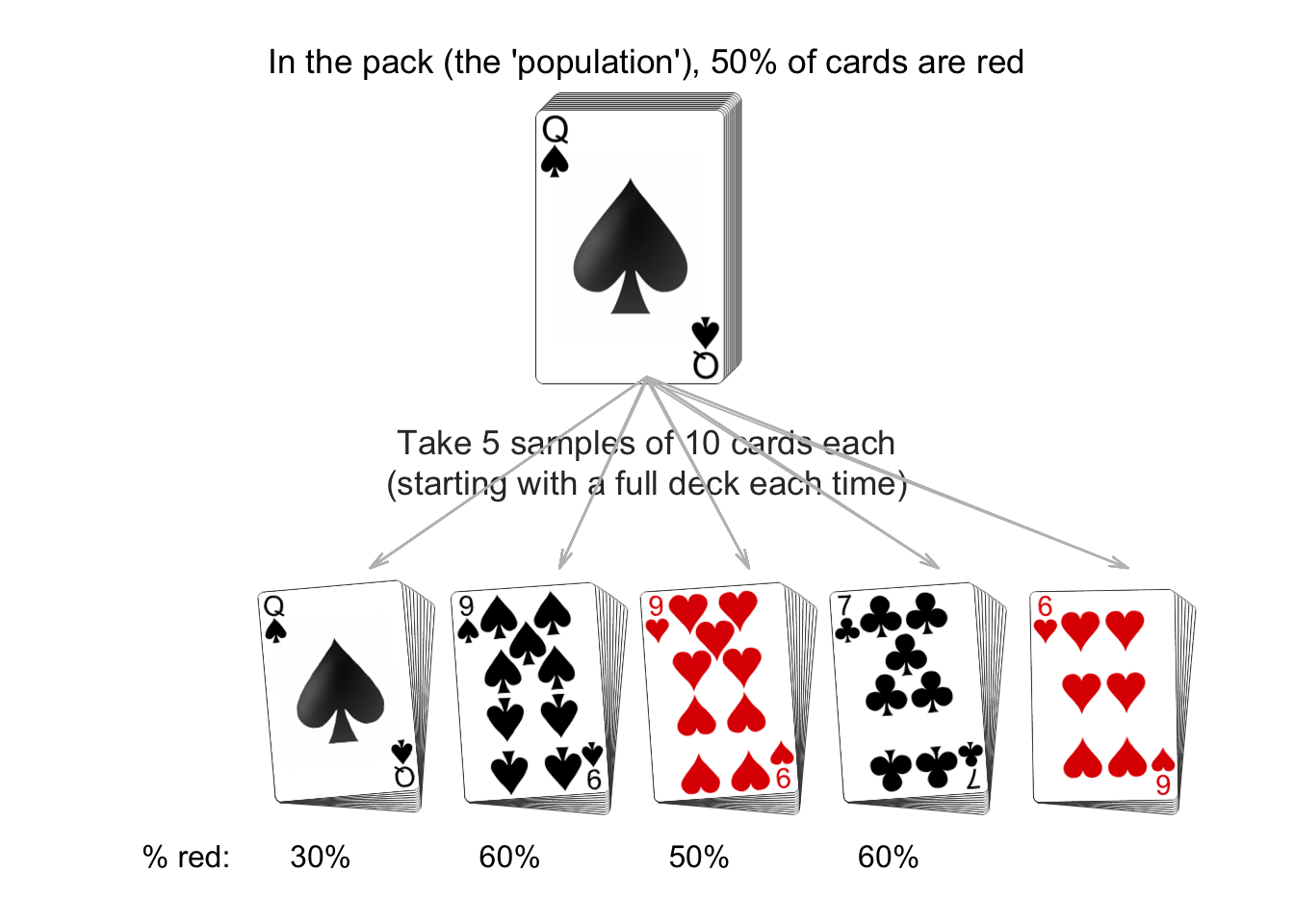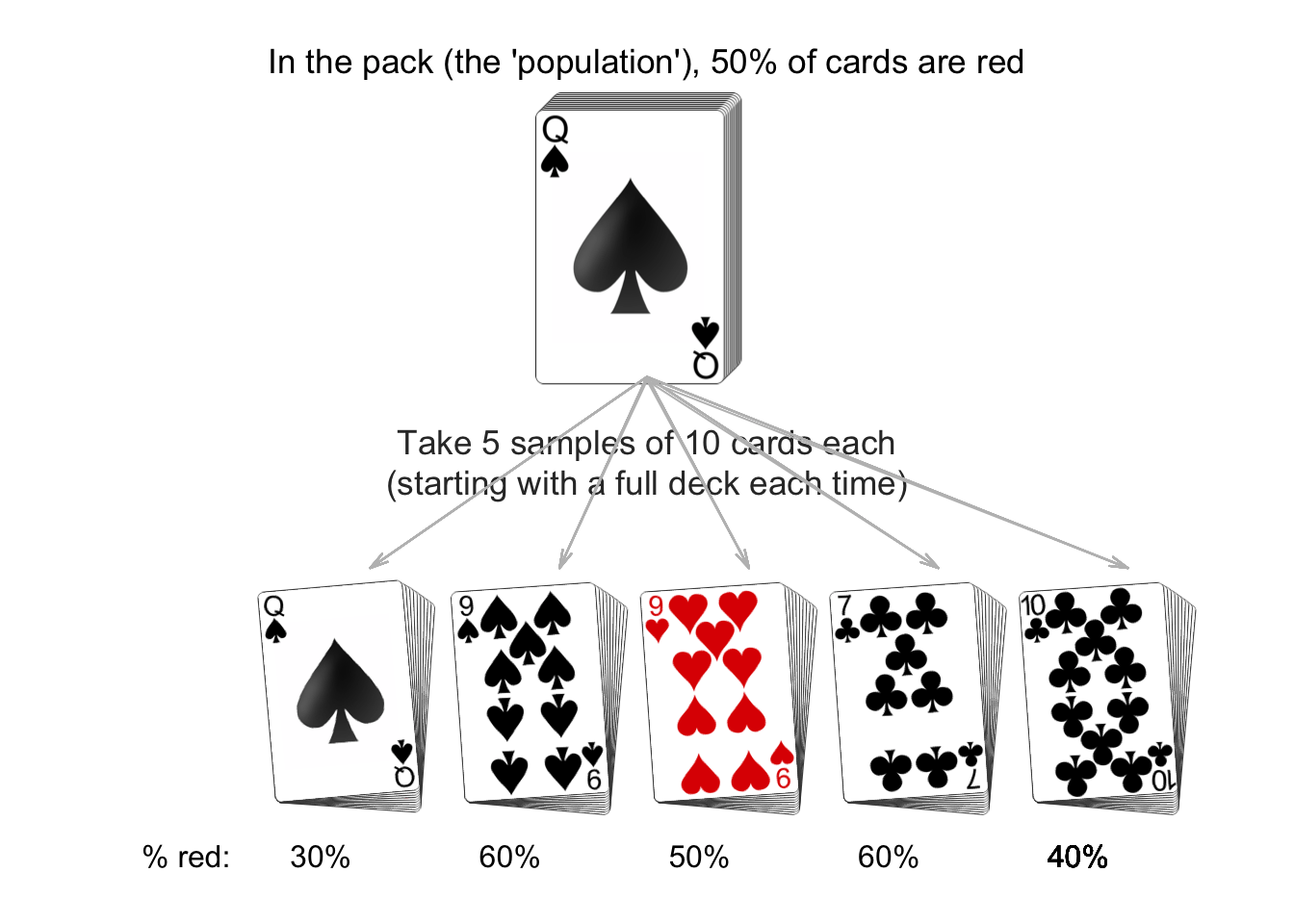
| Study | Number in sample | Population | Method |
|---|---|---|---|
| A | 10 000 000 | Specific groups | Voluntary survey |
| B | 50 000 | All Americans | Random survey |