A Guide on Data Analysis
Preface
How to cite this book
More books
1
Introduction
1.1
General Recommendations
2
Prerequisites
2.1
Matrix Theory
2.1.1
Rank of a Matrix
2.1.2
Inverse of a Matrix
2.1.3
Definiteness of a Matrix
2.1.4
Matrix Calculus
2.1.5
Optimization in Scalar and Vector Spaces
2.2
Probability Theory
2.2.1
Axioms and Theorems of Probability
2.2.2
Central Limit Theorem
2.2.3
Random Variable
2.2.4
Moment Generating Function
2.2.5
Moments
2.2.6
Distributions
2.3
General Math
2.3.1
Number Sets
2.3.2
Summation Notation and Series
2.3.3
Taylor Expansion
2.3.4
Law of Large Numbers
2.3.5
Law of Iterated Expectation
2.3.6
Convergence
2.3.7
Sufficient Statistics and Likelihood
2.3.8
Parameter Transformations
2.4
Data Import/Export
2.4.1
Medium size
2.4.2
Large size
2.5
Data Manipulation
I. BASIC
3
Descriptive Statistics
3.1
Numerical Measures
3.2
Graphical Measures
3.2.1
Shape
3.2.2
Scatterplot
3.3
Normality Assessment
3.3.1
Graphical Assessment
3.3.2
Summary Statistics
3.4
Bivariate Statistics
3.4.1
Two Continuous
3.4.2
Categorical and Continuous
3.4.3
Two Discrete
3.4.4
General Approach to Bivariate Statistics
4
Basic Statistical Inference
4.1
Hypothesis Testing Framework
4.1.1
Null and Alternative Hypotheses
4.1.2
Errors in Hypothesis Testing
4.2
Key Concepts and Definitions
4.2.1
Random Sample
4.2.2
Sample Statistics
4.2.3
Distribution of the Sample Mean
4.3
One-Sample Inference
4.3.1
For Single Mean
4.3.2
For Difference of Means (
\(\mu_1 - \mu_2\)
), Independent Samples
4.3.3
For Difference of Means (
\(\mu_1 - \mu_2\)
), Paired Samples (
\(D = X - Y\)
)
4.3.4
For Difference of Two Proportions
4.3.5
For Single Variance
4.3.6
For Single Proportion (p)
4.3.7
Power
4.3.8
Sample Size
4.3.9
Note
4.3.10
One-sample Non-parametric Methods
4.4
Two Sample Inference
4.4.1
Means
4.4.2
Variances
4.4.3
Power
4.4.4
Sample Size
4.4.5
Matched Pair Designs
4.4.6
Nonparametric Tests for Two Samples
4.5
Categorical Data Analysis
4.5.1
Inferences for Small Samples
4.5.2
Test of Association
4.5.3
Ordinal Association
4.6
Divergence Metrics and Test for Comparing Distributions
4.6.1
Kullback-Leibler Divergence
4.6.2
Jensen-Shannon Divergence
4.6.3
Wasserstein Distance
4.6.4
Kolmogorov-Smirnov Test
II. REGRESSION
5
Linear Regression
5.1
Ordinary Least Squares
5.1.1
Simple Regression (Basic Model)
5.1.2
Multiple Linear Regression
5.1.3
OLS Assumptions
5.1.4
Theorems
5.1.5
Variable Selection
5.1.6
Diagnostics
5.1.7
Model Validation
5.1.8
Finite Sample Properties
5.1.9
Large Sample Properties
5.2
Feasible Generalized Least Squares
5.2.1
Heteroskedasticity
5.2.2
Serial Correlation
5.3
Weighted Least Squares
5.4
Generalized Least Squares
5.5
Feasible Prais Winsten
5.6
Feasible group level Random Effects
5.7
Ridge Regression
5.8
Principal Component Regression
5.9
Robust Regression
5.9.1
Least Absolute Residuals (LAR) Regression
5.9.2
Least Median of Squares (LMS) Regression
5.9.3
Iteratively Reweighted Least Squares (IRLS) Robust Regression
5.10
Maximum Likelihood
5.10.1
Motivation for MLE
5.10.2
Assumption
5.10.3
Properties
5.10.4
Compare to OLS
5.10.5
Application
6
Non-linear Regression
6.1
Inference
6.1.1
Linear Function of the Parameters
6.1.2
Nonlinear
6.2
Non-linear Least Squares
6.2.1
Alternative of Gauss-Newton Algorithm
6.2.2
Practical Considerations
6.2.3
Model/Estimation Adequacy
6.2.4
Application
7
Generalized Linear Models
7.1
Logistic Regression
7.1.1
Application
7.2
Probit Regression
7.3
Binomial Regression
7.4
Poisson Regression
7.4.1
Application
7.5
Negative Binomial Regression
7.6
Multinomial
7.7
Generalization
7.7.1
Estimation
7.7.2
Inference
7.7.3
Deviance
7.7.4
Diagnostic Plots
7.7.5
Goodness of Fit
7.7.6
Over-Dispersion
8
Linear Mixed Models
8.1
Dependent Data
8.1.1
Random-Intercepts Model
8.1.2
Covariance Models
8.2
Estimation
8.2.1
Estimating
\(\mathbf{V}\)
8.3
Inference
8.3.1
Parameters
\(\beta\)
8.3.2
Variance Components
8.4
Information Criteria
8.4.1
Akaike’s Information Criteria (AIC)
8.4.2
Corrected AIC (AICC)
8.4.3
Bayesian Information Criteria (BIC)
8.5
Split-Plot Designs
8.5.1
Application
8.6
Repeated Measures in Mixed Models
8.7
Unbalanced or Unequally Spaced Data
8.8
Application
8.8.1
Example 1 (Pulps)
8.8.2
Example 2 (Rats)
8.8.3
Example 3 (Agridat)
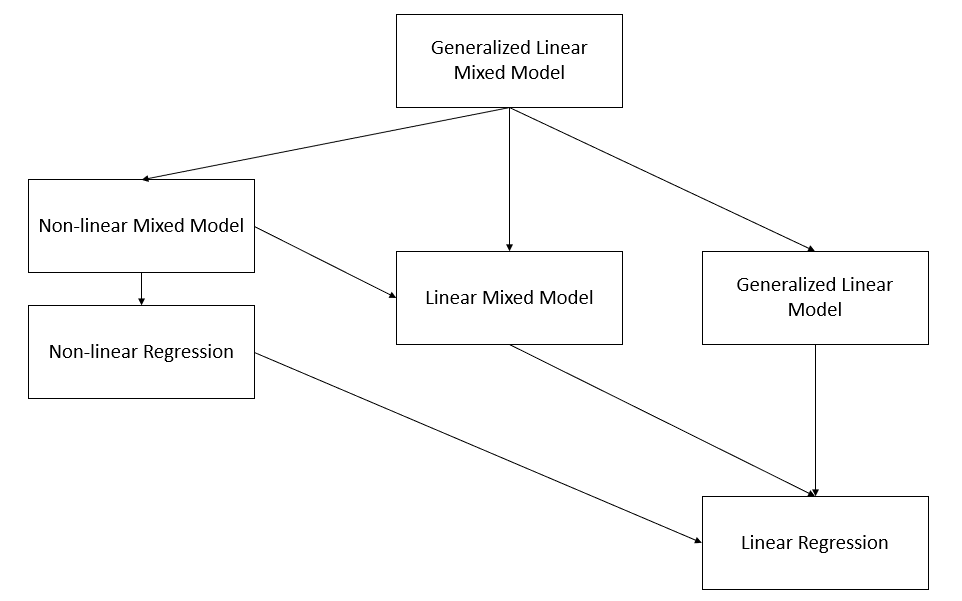
9
Nonlinear and Generalized Linear Mixed Models
9.1
Estimation
9.1.1
Estimation by Numerical Integration
9.1.2
Estimation by Linearization
9.1.3
Estimation by Bayesian Hierarchical Models
9.2
Application
9.2.1
Binomial (CBPP Data)
9.2.2
Count (Owl Data)
9.2.3
Binomial
9.2.4
Example from
(Schabenberger and Pierce 2001)
section 8.4.1
9.3
Summary
III. RAMIFICATIONS
10
Model Specification
10.1
Nested Model
10.1.1
Chow test
10.2
Non-Nested Model
10.2.1
Davidson-Mackinnon test
10.3
Heteroskedasticity
10.3.1
Breusch-Pagan test
10.3.2
White test
11
Imputation (Missing Data)
11.1
Introduction to Missing Data
11.1.1
Types of Imputation
11.1.2
When and Why to Use Imputation
11.1.3
Importance of Missing Data Treatment in Statistical Modeling
11.1.4
Prevalence of Missing Data Across Domains
11.1.5
Practical Considerations for Imputation
11.2
Theoretical Foundations of Missing Data
11.2.1
Definition and Classification of Missing Data
11.2.2
Missing Data Mechanisms
11.2.3
Relationship Between Mechanisms and Ignorability
11.3
Diagnosing the Missing Data Mechanism
11.3.1
Descriptive Methods
11.3.2
Statistical Tests for Missing Data Mechanisms
11.3.3
Assessing MAR and MNAR
11.4
Methods for Handling Missing Data
11.4.1
Basic Methods
11.4.2
Single Imputation Techniques
11.4.3
Machine Learning and Modern Approaches
11.4.4
Multiple Imputation
11.5
Evaluation of Imputation Methods
11.5.1
Statistical Metrics for Assessing Imputation Quality
11.5.2
Bias-Variance Tradeoff in Imputation
11.5.3
Sensitivity Analysis
11.5.4
Validation Using Simulated Data and Real-World Case Studies
11.6
Criteria for Choosing an Effective Approach
11.7
Challenges and Ethical Considerations
11.7.1
Challenges in High-Dimensional Data
11.7.2
Missing Data in Big Data Contexts
11.7.3
Ethical Concerns
11.8
Emerging Trends in Missing Data Handling
11.8.1
Advances in Neural Network Approaches
11.8.2
Integration with Reinforcement Learning
11.8.3
Synthetic Data Generation for Missing Data
11.8.4
Federated Learning and Privacy-Preserving Imputation
11.8.5
Imputation in Streaming and Online Data Environments
11.9
Application of Imputation in R
11.9.1
Visualizing Missing Data
11.9.2
How Many Imputations?
11.9.3
Generating Missing Data for Demonstration
11.9.4
Imputation with Mean, Median, and Mode
11.9.5
K-Nearest Neighbors (KNN) Imputation
11.9.6
Imputation with Decision Trees (rpart)
11.9.7
MICE (Multivariate Imputation via Chained Equations)
11.9.8
Amelia
11.9.9
missForest
11.9.10
Hmisc
11.9.11
mi
12
Data
12.1
Cross-Sectional
12.2
Time Series
12.2.1
Deterministic Time trend
12.2.2
Feedback Effect
12.2.3
Dynamic Specification
12.2.4
Dynamically Complete
12.2.5
Highly Persistent Data
12.3
Repeated Cross Sections
12.3.1
Pooled Cross Section
12.4
Panel Data
12.4.1
Pooled OLS Estimator
12.4.2
Individual-specific effects model
12.4.3
Tests for Assumptions
12.4.4
Model Selection
12.4.5
Summary
12.4.6
Application
13
Variable Transformation
13.1
Continuous Variables
13.1.1
Standardization
13.1.2
Min-max scaling
13.1.3
Square Root/Cube Root
13.1.4
Logarithmic
13.1.5
Exponential
13.1.6
Power
13.1.7
Inverse/Reciprocal
13.1.8
Hyperbolic arcsine
13.1.9
Ordered Quantile Norm
13.1.10
Arcsinh
13.1.11
Lambert W x F Transformation
13.1.12
Inverse Hyperbolic Sine (IHS) transformation
13.1.13
Box-Cox Transformation
13.1.14
Yeo-Johnson Transformation
13.1.15
RankGauss
13.1.16
Summary
13.2
Categorical Variables
14
Hypothesis Testing
14.1
Types of hypothesis testing
14.2
Wald test
14.2.1
Multiple Hypothesis
14.2.2
Linear Combination
14.2.3
Estimate Difference in Coefficients
14.2.4
Application
14.2.5
Nonlinear
14.3
The likelihood ratio test
14.4
Lagrange Multiplier (Score)
14.5
Two One-Sided Tests (TOST) Equivalence Testing
15
Marginal Effects
15.1
Delta Method
15.2
Average Marginal Effect Algorithm
15.3
Packages
15.3.1
MarginalEffects
15.3.2
margins
15.3.3
mfx
16
Prediction and Estimation
16.1
Prediction
16.2
Parameter Estimation
16.3
Causation versus Prediction
17
Moderation
17.1
emmeans package
17.1.1
Continuous by continuous
17.1.2
Continuous by categorical
17.1.3
Categorical by categorical
17.2
probmod package
17.3
interactions package
17.3.1
Continuous interaction
17.3.2
Categorical interaction
17.4
interactionR package
17.5
sjPlot package
IV. CAUSAL INFERENCE
18
Causal Inference
18.1
Treatment effect types
18.1.1
Average Treatment Effects
18.1.2
Conditional Average Treatment Effects
18.1.3
Intent-to-treat Effects
18.1.4
Local Average Treatment Effects
18.1.5
Population vs. Sample Average Treatment Effects
18.1.6
Average Treatment Effects on the Treated and Control
18.1.7
Quantile Average Treatment Effects
18.1.8
Mediation Effects
18.1.9
Log-odds Treatment Effects
A. EXPERIMENTAL DESIGN
19
Experimental Design
19.1
Notes
19.2
Semi-random Experiment
19.3
Rerandomization
19.4
Two-Stage Randomized Experiments with Interference and Noncompliance
20
Sampling
20.1
Simple Sampling
20.2
Stratified Sampling
20.3
Unequal Probability Sampling
20.4
Balanced Sampling
20.4.1
Cube
20.4.2
Stratification
20.4.3
Cluster
20.4.4
Two-stage
21
Analysis of Variance (ANOVA)
21.1
Completely Randomized Design (CRD)
21.1.1
Single Factor Fixed Effects Model
21.1.2
Single Factor Random Effects Model
21.1.3
Two Factor Fixed Effect ANOVA
21.1.4
Two-Way Random Effects ANOVA
21.1.5
Two-Way Mixed Effects ANOVA
21.2
Nonparametric ANOVA
21.2.1
Kruskal-Wallis
21.2.2
Friedman Test
21.3
Sample Size Planning for ANOVA
21.3.1
Balanced Designs
21.3.2
Randomized Block Experiments
21.4
Randomized Block Designs
21.4.1
Tukey Test of Additivity
21.5
Nested Designs
21.5.1
Two-Factor Nested Designs
21.6
Single Factor Covariance Model
22
Multivariate Methods
22.0.1
Properties of MVN
22.0.2
Mean Vector Inference
22.0.3
General Hypothesis Testing
22.1
MANOVA
22.1.1
Testing General Hypotheses
22.1.2
Profile Analysis
22.1.3
Summary
22.2
Principal Components
22.2.1
Population Principal Components
22.2.2
Sample Principal Components
22.2.3
Application
22.3
Factor Analysis
22.3.1
Methods of Estimation
22.3.2
Factor Rotation
22.3.3
Estimation of Factor Scores
22.3.4
Model Diagnostic
22.3.5
Application
22.4
Discriminant Analysis
22.4.1
Known Populations
22.4.2
Probabilities of Misclassification
22.4.3
Unknown Populations/ Nonparametric Discrimination
22.4.4
Application
B. QUASI-EXPERIMENTAL DESIGN
23
Quasi-experimental
23.1
Natural Experiments
24
Regression Discontinuity
24.1
Estimation and Inference
24.1.1
Local Randomization-based
24.1.2
Continuity-based
24.2
Specification Checks
24.2.1
Balance Checks
24.2.2
Sorting/Bunching/Manipulation
24.2.3
Placebo Tests
24.2.4
Sensitivity to Bandwidth Choice
24.2.5
Manipulation Robust Regression Discontinuity Bounds
24.3
Fuzzy RD Design
24.4
Regression Kink Design
24.5
Multi-cutoff
24.6
Multi-score
24.7
Steps for Sharp RD
24.8
Steps for Fuzzy RD
24.9
Steps for RDiT (Regression Discontinuity in Time)
24.10
Evaluation of an RD
24.11
Applications
24.11.1
Example 1
24.11.2
Example 2
24.11.3
Example 3
24.11.4
Example 4
25
Synthetic Difference-in-Differences
25.1
Understanding
25.2
Application
25.2.1
Block Treatment
25.2.2
Staggered Adoption
26
Difference-in-differences
26.1
Visualization
26.2
Simple Dif-n-dif
26.3
Notes
26.4
Standard Errors
26.5
Examples
26.5.1
Example by
Doleac and Hansen (2020)
26.5.2
Example from Princeton
26.5.3
Example by
Card and Krueger (1993)
26.5.4
Example by
Butcher, McEwan, and Weerapana (2014)
26.6
One Difference
26.7
Two-way Fixed-effects
26.8
Multiple periods and variation in treatment timing
26.9
Staggered Dif-n-dif
26.9.1
Stacked DID
26.9.2
Goodman-Bacon Decomposition
26.9.3
DID with in and out treatment condition
26.9.4
Gardner (2022)
and
Borusyak, Jaravel, and Spiess (2021)
26.9.5
Clément De Chaisemartin and d’Haultfoeuille (2020)
26.9.6
Callaway and Sant’Anna (2021)
26.9.7
L. Sun and Abraham (2021)
26.9.8
Wooldridge (2022)
26.9.9
Doubly Robust DiD
26.9.10
Augmented/Forward DID
26.10
Multiple Treatments
26.11
Mediation Under DiD
26.12
Assumptions
26.12.1
Prior Parallel Trends Test
26.12.2
Placebo Test
26.12.3
Assumption Violations
26.12.4
Robustness Checks
27
Changes-in-Changes
27.1
Application
27.1.1
ECIC package
27.1.2
QTE package
28
Synthetic Control
28.1
Applications
28.1.1
Example 1
28.1.2
Example 2
28.1.3
Example 3
28.1.4
Example 4
28.2
Augmented Synthetic Control Method
28.3
Synthetic Control with Staggered Adoption
28.4
Bayesian Synthetic Control
28.5
Generalized Synthetic Control
28.6
Other Advances
29
Event Studies
29.1
Other Issues
29.1.1
Event Studies in marketing
29.1.2
Economic significance
29.1.3
Statistical Power
29.2
Testing
29.2.1
Parametric Test
29.2.2
Non-parametric Test
29.3
Sample
29.3.1
Confounders
29.4
Biases
29.5
Long-run event studies
29.5.1
Buy and Hold Abnormal Returns (BHAR)
29.5.2
Long-term Cumulative Abnormal Returns (LCARs)
29.5.3
Calendar-time Portfolio Abnormal Returns (CTARs)
29.6
Aggregation
29.6.1
Over Time
29.6.2
Across Firms + Over Time
29.7
Heterogeneity in the event effect
29.7.1
Common variables in marketing
29.8
Expected Return Calculation
29.8.1
Statistical Models
29.8.2
Economic Model
29.9
Application
29.9.1
Eventus
29.9.2
Evenstudies
29.9.3
EventStudy
30
Instrumental Variables
30.1
Framework
30.2
Estimation
30.2.1
2SLS Estimation
30.2.2
IV-GMM
30.3
Inference
30.3.1
AR approach
30.3.2
tF Procedure
30.3.3
AK approach
30.4
Testing Assumptions
30.4.1
Relevance Assumption
30.4.2
Exogeneity Assumption
30.5
Negative
\(R^2\)
30.6
Treatment Intensity
30.7
Control Function
30.7.1
Simulation
30.8
New Advances
31
Matching Methods
31.1
Selection on Observables
31.1.1
MatchIt
31.1.2
designmatch
31.1.3
MatchingFrontier
31.1.4
Propensity Scores
31.1.5
Mahalanobis Distance
31.1.6
Coarsened Exact Matching
31.1.7
Genetic Matching
31.1.8
Entropy Balancing
31.1.9
Matching for high-dimensional data
31.1.10
Matching for time series-cross-section data
31.1.11
Matching for multiple treatments
31.1.12
Matching for multi-level treatments
31.1.13
Matching for repeated treatments
31.2
Selection on Unobservables
31.2.1
Rosenbaum Bounds
31.2.2
Relative Correlation Restrictions
31.2.3
Coefficient-stability Bounds
32
Interrupted Time Series
32.1
Autocorrelation
32.2
Multiple Groups
C. OTHER CONCERNS
33
Endogeneity
33.1
Endogenous Treatment
33.1.1
Measurement Error
33.1.2
Simultaneity
33.1.3
Endogenous Treatment Solutions
33.2
Endogenous Sample Selection
33.2.1
Tobit-2
33.2.2
Tobit-5
34
Other Biases
34.1
Aggregation Bias
34.1.1
Simpson’s Paradox
34.2
Contamination Bias
34.3
Survivorship Bias
34.4
Publication Bias
35
Controls
35.1
Bad Controls
35.1.1
M-bias
35.1.2
Bias Amplification
35.1.3
Overcontrol bias
35.1.4
Selection Bias
35.1.5
Case-control Bias
35.2
Good Controls
35.2.1
Omitted Variable Bias Correction
35.2.2
Omitted Variable Bias in Mediation Correction
35.3
Neutral Controls
35.3.1
Good Predictive Controls
35.3.2
Good Selection Bias
35.3.3
Bad Predictive Controls
35.3.4
Bad Selection Bias
35.4
Choosing Controls
36
Mediation
36.1
Traditional Approach
36.1.1
Assumptions
36.1.2
Indirect Effect Tests
36.1.3
Multiple Mediation
36.2
Causal Inference Approach
36.2.1
Example 1
36.3
Model-based causal mediation analysis
37
Directed Acyclic Graph
37.1
Basic Notations
V. MISCELLANEOUS
38
Report
38.1
One summary table
38.2
Model Comparison
38.3
Changes in an estimate
38.4
Standard Errors
38.5
Coefficient Uncertainty and Distribution
38.6
Descriptive Tables
38.7
Visualizations and Plots
39
Exploratory Data Analysis
40
Sensitivity Analysis/ Robustness Check
40.1
Specification curve
40.1.1
starbility
40.1.2
rdfanalysis
40.2
Coefficient stability
40.3
Omitted Variable Bias Quantification
41
Replication and Synthetic Data
41.1
The Replication Standard
41.1.1
Solutions for Empirical Replication
41.1.2
Free Data Repositories
41.1.3
Exceptions to Replication
41.2
Synthetic Data: An Overview
41.2.1
Benefits
41.2.2
Concerns
41.2.3
Further Insights on Synthetic Data
41.3
Application
APPENDIX
A
Appendix
A.1
Git
A.2
Short-cut
A.3
Function short-cut
A.4
Citation
A.5
Install all necessary packages/libaries on your local machine
B
Bookdown cheat sheet
B.1
Operation
B.2
Math Expression/ Syntax
B.2.1
Statistics Notation
B.3
Table
References
Published with bookdown
A Guide on Data Analysis
9.3
Summary