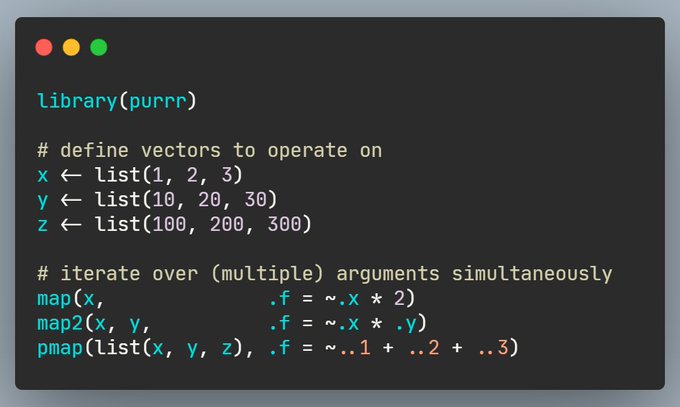
第 20 章 函数式编程1
很多教材都是讲函数和循环,都是从for, while, ifelse讲起
,如果我也这样讲,又回到了Base R的老路上去了。考虑到大家都没有编程背景,也不会立志当程序员,所以我直接讲purrr包,留坑以后填吧。
20.1 简单回顾
大家知道R常用的数据结构是向量、矩阵、列表和数据框,如下图
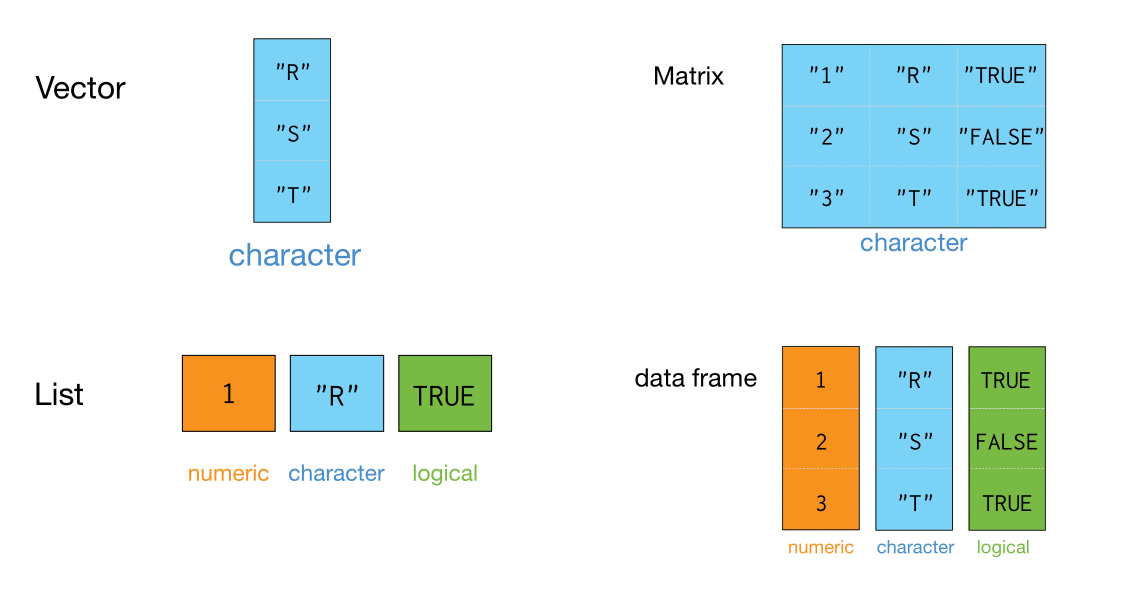
他们构造起来,很多相似性。
list(a = 1, b = "a") # list
c(a = 1, b = 2) # named vector
data.frame(a = 1, b = 2) # data frame
tibble(a = 1, b = 2) # tibble20.2 向量化运算
a <- c(2, 4, 3, 1, 5, 7)用for()循环,让向量的每个元素乘以2
## [1] 4
## [1] 8
## [1] 6
## [1] 2
## [1] 10
## [1] 14事实上,R语言是支持向量化(将运算符或者函数作用在向量的每一个元素上),可以用向量化代替循环
a * 2## [1] 4 8 6 2 10 14达到同样的效果。
再比如,找出向量a中元素大于2的所有值
## [1] 4
## [1] 3
## [1] 5
## [1] 7用向量化的运算,可以轻松实现
a[a > 2]## [1] 4 3 5 7向量是R中最基础的一种数据结构,有种说法是“一切都是向量”,R中的矩阵、数组甚至是列表都可以看成是某种意义上的向量。因此,使用向量化操作可以大大提高代码的运行效率。
20.3 多说说列表
我们构造一个列表
## $num
## [1] 8 9
##
## $log
## [1] TRUE
##
## $cha
## [1] "a" "b" "c"要想访问某个元素,可以这样
a_list["num"]## $num
## [1] 8 9注意返回结果,第一行是$num,说明返回的结果仍然是列表, 相比a_list来说,a_list["num"]是只包含一个元素的列表。
想将num元素里面的向量提取出来,就得用两个[[
a_list[["num"]]## [1] 8 9大家知道程序员都是偷懒的,为了节省体力,用一个美元符号$代替[[" "]]六个字符
a_list$num## [1] 8 9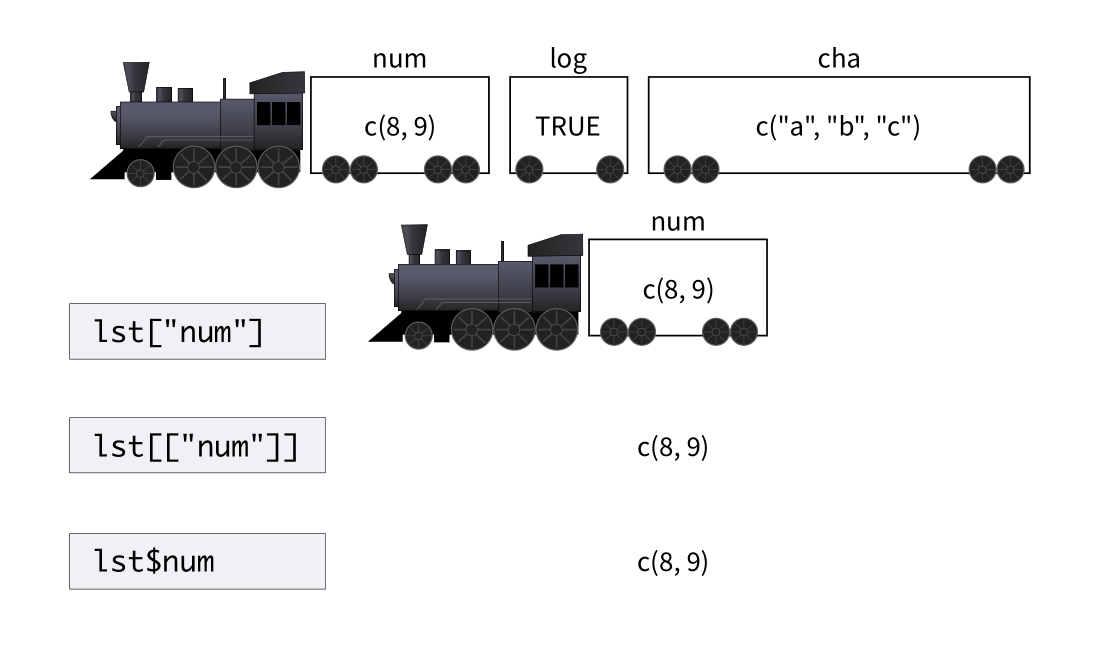
在tidyverse里,还可以用
## [1] 8 9或者
## [1] 8 920.4 列表 vs 向量
假定一向量
v <- c(-2, -1, 0, 1, 2)
v## [1] -2 -1 0 1 2我们对元素分别取绝对值
abs(v)## [1] 2 1 0 1 2如果是列表形式,abs函数应用到列表中就会报错
lst <- list(-2, -1, 0, 1, 2)
abs(lst)## Error in abs(lst): non-numeric argument to mathematical function报错了。用在向量的函数用在list上,往往行不通。
再来一个例子:我们模拟了5个学生的10次考试的成绩
exams <- list(
student1 = round(runif(10, 50, 100)),
student2 = round(runif(10, 50, 100)),
student3 = round(runif(10, 50, 100)),
student4 = round(runif(10, 50, 100)),
student5 = round(runif(10, 50, 100))
)
exams## $student1
## [1] 67 87 77 63 80 76 61 92 82 66
##
## $student2
## [1] 87 91 71 94 90 58 91 90 55 63
##
## $student3
## [1] 63 93 60 70 79 72 68 53 66 96
##
## $student4
## [1] 56 63 86 99 50 57 94 51 100 62
##
## $student5
## [1] 99 87 93 83 97 52 56 56 52 74很显然,exams是一个列表。那么,每个学生的平均成绩是多呢?
我们可能会想到用mean函数,但是
mean(exams)## [1] NA发现报错了,可以看看帮助文档看看问题出在什么地方
?mean()帮助文档告诉我们,mean()要求第一个参数是数值型或者逻辑型的向量。
而我们这里的exams是列表,因此无法运行。
那好,我们就用笨办法吧
list(
student1 = mean(exams$student1),
student2 = mean(exams$student2),
student3 = mean(exams$student3),
student4 = mean(exams$student4),
student5 = mean(exams$student5)
)## $student1
## [1] 75.1
##
## $student2
## [1] 79
##
## $student3
## [1] 72
##
## $student4
## [1] 71.8
##
## $student5
## [1] 74.9成功了。但发现我们写了好多代码,如果有100个学生,那就得写更多的代码,如果是这样,程序员就不高兴了,这太累了啊。于是purrr包的map函数来解救我们,下面主角出场了。
20.5 purrr
介绍之前,先试试
map(exams, mean)## $student1
## [1] 75.1
##
## $student2
## [1] 79
##
## $student3
## [1] 72
##
## $student4
## [1] 71.8
##
## $student5
## [1] 74.9哇,短短一句话,得出了相同的结果。
20.5.1 map函数
map()函数的第一个参数是list或者vector, 第二个参数是函数
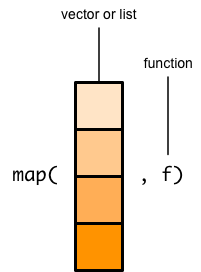
函数 f 应用到list/vector 的每个元素
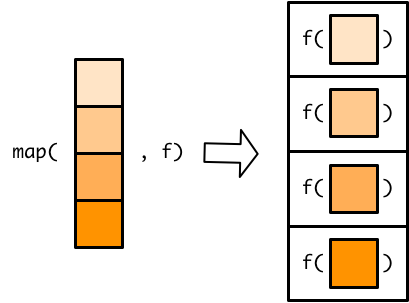
于是输入的 list/vector 中的每个元素,都对应一个输出
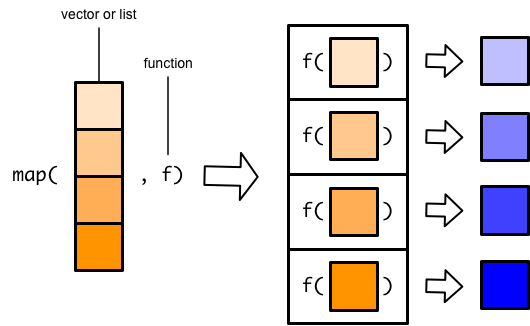
最后,所有的输出元素,聚合成一个新的list

整个过程,可以想象 list/vector 是生产线上的盒子,依次将里面的元素,送入加工机器。 函数决定了机器该如何处理每个元素,机器依次处理完毕后,结果打包成list,最后送出机器。
在我们这个例子,mean() 作用到每个学生的成绩向量,
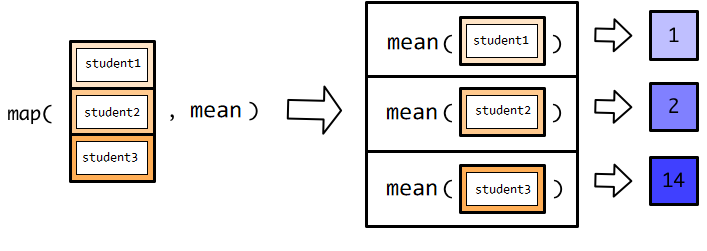
调用一次mean(), 返回一个数值,所以最终的结果是五个数值的列表。
map(exams, mean)## $student1
## [1] 75.1
##
## $student2
## [1] 79
##
## $student3
## [1] 72
##
## $student4
## [1] 71.8
##
## $student5
## [1] 74.9我们也可以使用管道
## $student1
## [1] 75.1
##
## $student2
## [1] 79
##
## $student3
## [1] 72
##
## $student4
## [1] 71.8
##
## $student5
## [1] 74.920.5.2 map函数家族
如果希望返回的是数值型的向量,可以这样写map_dbl()
## student1 student2 student3 student4 student5
## 75.1 79.0 72.0 71.8 74.9map_dbl()要求每个输出的元素必须是数值型
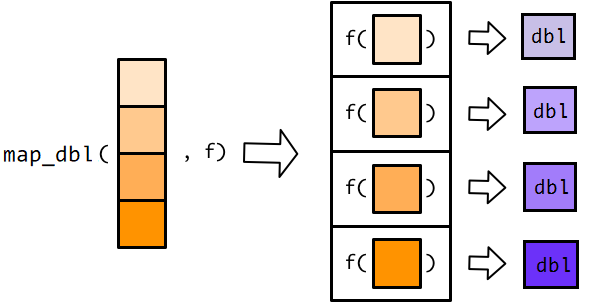
如果每个元素是数值型,map_dbl()会聚合所有元素构成一个原子型向量

如果希望返回的结果是数据框
## # A tibble: 1 × 5
## student1 student2 student3 student4 student5
## <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 75.1 79 72 71.8 74.9是不是很酷?是不是很灵活
20.5.3 小结
事实上,map函数
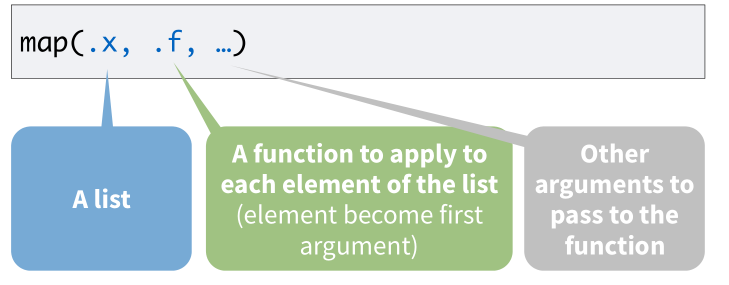
- 第一个参数是向量或列表(数据框是列表的一种特殊形式,因此数据框也是可以的)
- 第二个参数是函数,这个函数会应用到列表的每一个元素,比如这里
map函数执行过程如下 :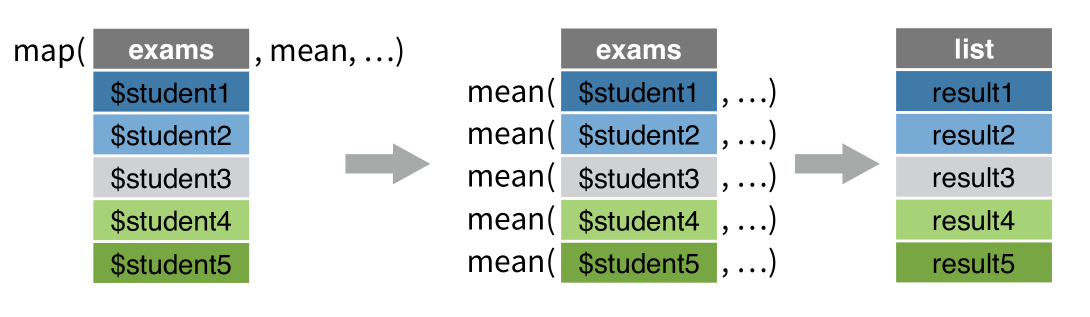
具体为,exams有5个元素,一个元素装着一个学生的10次考试成绩,
运行map(exams, mean)函数后, 首先取出exams第一个元素exams$student1(它是向量),然后执行
mean(exams$student1), 然后将计算结果存放在列表result中的第一个位置result1上;
做完第一个学生的,紧接着取出exams第二个元素exams$student2,执行
mean(exams$student2), 然后将计算结果存放在列表result中的第一个位置result2上;
如此这般,直到所有学生都处理完毕。我们得到了最终结果—一个新的列表result。
当然,我们也可以根据需要,让map返回我们需要的数据格式, purrr也提供了方便的函数,具体如下

我们将mean函数换成求方差var函数试试,
## # A tibble: 1 × 5
## student1 student2 student3 student4 student5
## <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 111. 240. 190. 420. 375.20.5.4 额外参数
将每位同学的成绩排序,默认的是升序。
map(exams, sort)## $student1
## [1] 61 63 66 67 76 77 80 82 87 92
##
## $student2
## [1] 55 58 63 71 87 90 90 91 91 94
##
## $student3
## [1] 53 60 63 66 68 70 72 79 93 96
##
## $student4
## [1] 50 51 56 57 62 63 86 94 99 100
##
## $student5
## [1] 52 52 56 56 74 83 87 93 97 99如果我们想降序排,需要在sort()函数里添加参数 decreasing = TRUE。比如
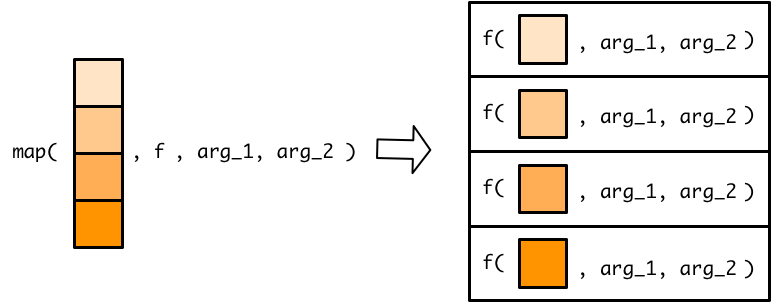
sort(exams$student1, decreasing = TRUE)## [1] 92 87 82 80 77 76 67 66 63 61map很人性化,可以让函数的参数直接跟随在函数名之和
map(exams, sort, decreasing = TRUE)## $student1
## [1] 92 87 82 80 77 76 67 66 63 61
##
## $student2
## [1] 94 91 91 90 90 87 71 63 58 55
##
## $student3
## [1] 96 93 79 72 70 68 66 63 60 53
##
## $student4
## [1] 100 99 94 86 63 62 57 56 51 50
##
## $student5
## [1] 99 97 93 87 83 74 56 56 52 52当然,也可以添加更多的参数,map()会自动的传递给函数。
20.5.5 匿名函数
刚才我们是让学生成绩执行求平均mean,求方差var等函数。我们也可以自定义函数。
比如我们这里定义了将向量中心化的函数(先求出10次考试的平均值,然后每次考试成绩去减这个平均值)
## # A tibble: 10 × 5
## student1 student2 student3 student4 student5
## <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 -8.10 8 -9 -15.8 24.1
## 2 11.9 12 21 -8.8 12.1
## 3 1.90 -8 -12 14.2 18.1
## 4 -12.1 15 -2 27.2 8.10
## 5 4.90 11 7 -21.8 22.1
## 6 0.900 -21 0 -14.8 -22.9
## 7 -14.1 12 -4 22.2 -18.9
## 8 16.9 11 -19 -20.8 -18.9
## 9 6.90 -24 -6 28.2 -22.9
## 10 -9.1 -16 24 -9.8 -0.900我们也可以不用命名函数,而使用匿名函数。匿名函数顾名思义,就是没有名字的函数,
function(x) x - mean(x)我们能将匿名函数直接放在map()函数中
## $student1
## [1] -8.1 11.9 1.9 -12.1 4.9 0.9 -14.1 16.9 6.9 -9.1
##
## $student2
## [1] 8 12 -8 15 11 -21 12 11 -24 -16
##
## $student3
## [1] -9 21 -12 -2 7 0 -4 -19 -6 24
##
## $student4
## [1] -15.8 -8.8 14.2 27.2 -21.8 -14.8 22.2 -20.8 28.2 -9.8
##
## $student5
## [1] 24.1 12.1 18.1 8.1 22.1 -22.9 -18.9 -18.9 -22.9 -0.9还可以更加偷懒,用~代替function(),但代价是参数必须是规定的写法,比如.x
## $student1
## [1] -8.1 11.9 1.9 -12.1 4.9 0.9 -14.1 16.9 6.9 -9.1
##
## $student2
## [1] 8 12 -8 15 11 -21 12 11 -24 -16
##
## $student3
## [1] -9 21 -12 -2 7 0 -4 -19 -6 24
##
## $student4
## [1] -15.8 -8.8 14.2 27.2 -21.8 -14.8 22.2 -20.8 28.2 -9.8
##
## $student5
## [1] 24.1 12.1 18.1 8.1 22.1 -22.9 -18.9 -18.9 -22.9 -0.9有时候,程序员觉得x还是有点多余,于是更够懒一点,只用., 也是可以的
## $student1
## [1] -8.1 11.9 1.9 -12.1 4.9 0.9 -14.1 16.9 6.9 -9.1
##
## $student2
## [1] 8 12 -8 15 11 -21 12 11 -24 -16
##
## $student3
## [1] -9 21 -12 -2 7 0 -4 -19 -6 24
##
## $student4
## [1] -15.8 -8.8 14.2 27.2 -21.8 -14.8 22.2 -20.8 28.2 -9.8
##
## $student5
## [1] 24.1 12.1 18.1 8.1 22.1 -22.9 -18.9 -18.9 -22.9 -0.9~ 告诉 map() 后面跟随的是一个匿名函数,. 对应函数的参数,可以认为是一个占位符,等待传送带的student1、student2到student5 依次传递到函数机器。
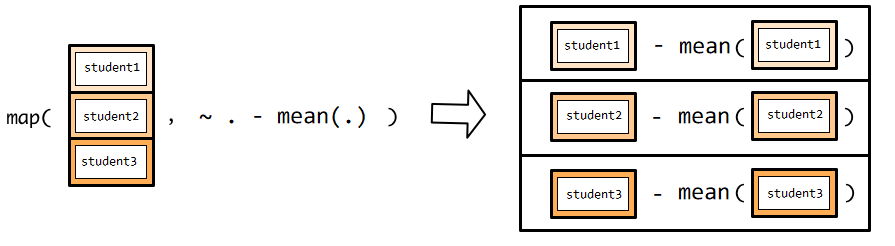
如果熟悉匿名函数的写法,会增强代码的可读性。比如下面这段代码,找出每位同学有多少门考试成绩是高于80分的
## student1 student2 student3 student4 student5
## 3 6 2 4 5总之,有三种方法将函数传递给map()
- 直接传递
map(.x, mean, na.rm = TRUE)- 匿名函数
- 使用
~
function(.x) {
.x *2
}
# Equivalent
~ .x * 2简单点说 ::: {.rmdnote}
function(x) x^2 + 5
~ .x^2 + 5这是两种等价的写法。
这里的 .x 又可以写成 .
~ .^2 + 5最后一种是偷懒到极致的写法
:::
20.6 在dplyr函数中的运用map
20.6.1 在Tibble中
Tibble本质上是向量构成的列表,因此tibble也适用map。假定有tibble如下
map()中的函数f,可以作用到每一列
map_dbl(tb, median)## col_1 col_2 col_3
## 2.0 200.0 0.2在比如,找出企鹅数据中每列缺失值NA的数量
## species island bill_length_mm bill_depth_mm
## 0 0 2 2
## flipper_length_mm body_mass_g sex year
## 2 2 11 020.6.2 在col-column中
如果想显示列表中每个元素的长度,可以这样写
## # A tibble: 3 × 2
## x l
## <list> <int>
## 1 <dbl [1]> 1
## 2 <int [2]> 2
## 3 <int [3]> 3用于各种函数,比如产生随机数
## # A tibble: 3 × 2
## x r
## <dbl> <list>
## 1 3 <dbl [3]>
## 2 5 <dbl [5]>
## 3 6 <dbl [6]>用于建模
mtcars %>%
group_by(cyl) %>%
nest() %>%
mutate(model = purrr::map(data, ~ lm(mpg ~ wt, data = .))) %>%
mutate(result = purrr::map(model, ~ broom::tidy(.))) %>%
unnest(result)## # A tibble: 6 × 8
## # Groups: cyl [3]
## cyl data model term estimate std.error statistic p.value
## <dbl> <list> <list> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 6 <tibble [7 × 10]> <lm> (Interce… 28.4 4.18 6.79 1.05e-3
## 2 6 <tibble [7 × 10]> <lm> wt -2.78 1.33 -2.08 9.18e-2
## 3 4 <tibble [11 × 10]> <lm> (Interce… 39.6 4.35 9.10 7.77e-6
## 4 4 <tibble [11 × 10]> <lm> wt -5.65 1.85 -3.05 1.37e-2
## 5 8 <tibble [14 × 10]> <lm> (Interce… 23.9 3.01 7.94 4.05e-6
## 6 8 <tibble [14 × 10]> <lm> wt -2.19 0.739 -2.97 1.18e-2更多内容和方法可参考第 39 章数据框列方向和行方向。