第 7 章 函数
上一节课我们认识了向量操作符,体会到了向量化操作的强大,事实上,向量操作符是一种函数。R 语言的强大就在于它拥有丰富的函数,这里的函数和我们高中数学中的函数 y = f(x) 没什么区别。
7.1 基础函数
R 语言内置了很多统计函数,比如对于向量x
x <- c(2, 7, 8, 9, 3)打印向量x
print(x)## [1] 2 7 8 9 3求开方
sqrt(x)## [1] 1.414214 2.645751 2.828427 3.000000 1.732051求自然对数
log(x)## [1] 0.6931472 1.9459101 2.0794415 2.1972246 1.0986123求向量元素之和
sum(x)## [1] 29求向量元素的均值
mean(x)## [1] 5.8求向量元素的标准差
sd(x)## [1] 3.114482找出向量元素中的最小值
min(x)## [1] 2找出向量元素中的最大值
max(x)## [1] 9计算向量元素的个数
length(x)## [1] 5对向量元素大小排序
sort(x)## [1] 2 3 7 8 9找出向量元素的唯一值,就是给出去重后的数据
## [1] "a" "b" "c" "d" "g"给出向量的分位数
quantile(x)## 0% 25% 50% 75% 100%
## 2 3 7 8 9判断是否为数值型/字符串型
is.numeric(x)## [1] TRUE
is.character(x)## [1] FALSE转化成字符串型
as.character(x)## [1] "2" "7" "8" "9" "3"
# as.logical(x)
# as.numeric(x)判断向量元素是否大于5
x <- c(2, 7, 8, 9, 3)
x > 5## [1] FALSE TRUE TRUE TRUE FALSE
ifelse(x > 5, "big", "small")## [1] "small" "big" "big" "big" "small"7.2 向量的函数
用在向量上的函数,可以分为向量化函数(vectorized function)和汇总类函数(summary function),
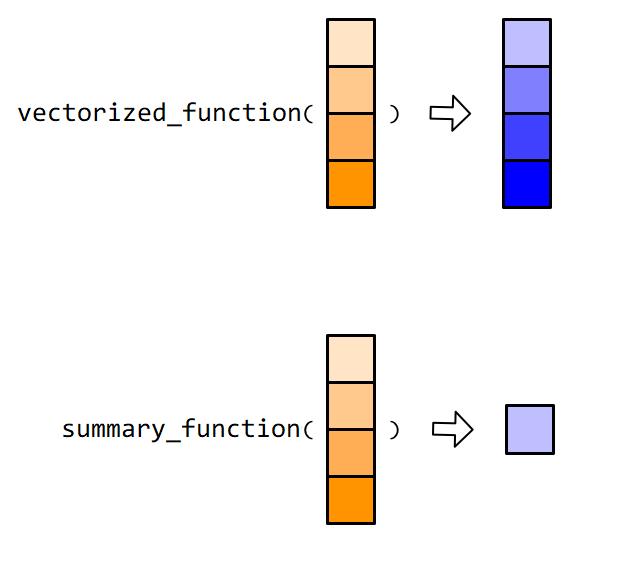
图 7.1: 这两类函数在 Tidyverse 框架中,应用非常广泛。
当然,也会有例外,比如unique()函数,它返回的向量通常不会与输入的向量等长,既不属于向量化函数,也不属于汇总类函数。
7.3 课堂练习
- 向量
x <- c(2, 7, 8, 9, 3)的平方,加上5
x <- c(2, 7, 8, 9, 3)
x^2 + 5## [1] 9 54 69 86 14- 向量的元素减去其均值
## [1] -3.8 1.2 2.2 3.2 -2.8- 向量标准化(向量减去其均值之后,除以标准差)
## [1] -1.2201065 0.3852968 0.7063774 1.0274581 -0.8990258- 如果想对更多的向量,也做标准化处理呢?
## [1] -1.4599928 -0.1622214 0.4866643 0.8111071 1.1355499 -0.8111071## [1] -1.1932699 0.1704671 0.1704671 0.6250461 1.0796251 -1.6478489 1.0796251
## [8] -0.2841119简单重复比较累,有没有一劳永逸的方法?
7.4 自定义函数
my_std(x)## [1] -1.2201065 0.3852968 0.7063774 1.0274581 -0.8990258
my_std(y)## [1] -1.4599928 -0.1622214 0.4866643 0.8111071 1.1355499 -0.8111071
my_std(z)## [1] -1.1932699 0.1704671 0.1704671 0.6250461 1.0796251 -1.6478489 1.0796251
## [8] -0.2841119现在my_std 是一个糖葫芦瘦身机器了,放进一个胖瘦不匀称的糖葫芦,出来一个身材匀称的糖葫芦。
my_std <- function(x) {
...
}- 创建,由
function(...)创建一个函数 - 参数,由
(...)里指定参数,比如function(x)中的参数为x - 函数主体,一般情况下,在
function(...)后跟随一对大括号{ },在大括号里声明具体函数功能,在代码最后一行,可以用return返回计算后的值。当然,如果函数的目的只是返回最后一行代码计算的值,这个return可以省略。 - 函数名,
function() { }赋值给新对象,比如这里的my_std,相当于给函数取一名字,方便以后使用。 - 函数调用,现在这个函数名字叫
my_std,需要用这个函数的时候,就调用它的名字my_std()。
7.5 使用宏包的函数
7.5.1 安装宏包与使用宏包
安装宏包 install.packages("dplyr") 相当于你买了一台电视机,安装一次就够了; 加载 library("dplyr")相当于你每次要看电视,就需要插上电、打开电视的动作,运行library("dplyr")才能用里面的函数。

各种宏包也为我们准备了不同的函数,我们在使用前一般会先加载该宏包,比如后面章节我们会用的dplyr宏包中的select()函数,它用于选取数据框的某列
7.5.2 指定函数的所属宏包
但是,其它宏包可能也有select()函数,比如MASS和skimr,如果同时加载了dplyr,MASS和skimr三个宏包,在程序中使用select()函数,就会造成混淆和报错。这个时候就需要给每个函数指定是来源哪个宏包,具体方法就是在宏包和函数之间添加::,比如dplyr::select(),skimr::select() 或者MASS::select()。
至此,我们接触到了三类函数
- 内置的函数
- 自定义的函数
- 宏包的函数
7.6 如何获取帮助
- 记住和学习所有的函数几乎是不可能的
- 打开函数的帮助页面(
Rstudio右下面板的Help选项卡)
?sqrt
?gather
?spread
?ggplot2
?scale
?map_dfr比如:
7.7 习题
- 根据方差的数学表达式,写出方差的计算函数,并与基础函数
var()的结果对比
\[ \mathrm{Var}(x) = \frac{1}{n - 1} \sum_{i=1}^n (x_i - \bar{x}) ^2 \]
- 自定义函数,它的作用是将输入的身高height(cm)与体重weight(kg)计算之后的BMI结果返回,BMI的计算公式为:
\[ \mathrm{BMI} = \frac{weight(kg)}{height(m)^2} \]
get_bmi <- function(height, weight) {
# ...
}
get_bmi(175, 65)- 对于给定的向量
vector和阈值threshold,求出vector中所有大于该阈值的元素的均值
mean_above_threshod <- function(vector, threshold) {
}