第 21 章 函数式编程2
第 20 章, 我们学习了如何使用map()函数迭代一个向量(或列表),并对其元素施以函数。
事实上,purrr()家族还有其它map()函数,可以在多个向量中迭代。也就说,同时接受多个向量的元素,并行计算。比如,map2()函数可以处理两个向量,而pmap()函数可以处理更多向量。
21.1 map2()
map2()函数和map()函数类似,不同在于map2()接受两个的向量,这两个向量必须是等长
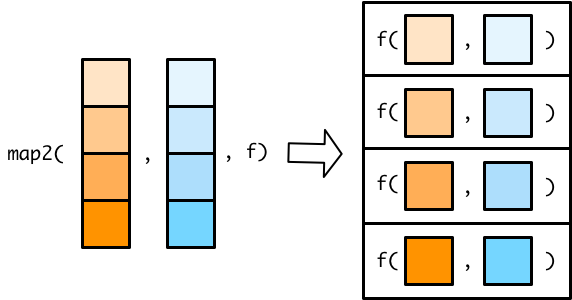
在map()函数使用匿名函数,可以用 . 代表输入向量的每个元素。在map2()函数, .不够用,所有需要需要用 .x 代表第一个向量的元素,.y代表第二个向量的元素
## [[1]]
## [1] 5
##
## [[2]]
## [1] 7
##
## [[3]]
## [1] 9tibble的每一列都是向量,所以可以把map2()放在mutate()函数内部,对tibble的多列同时迭代
## # A tibble: 3 × 3
## a b min
## <dbl> <dbl> <dbl>
## 1 1 4 1
## 2 2 5 2
## 3 3 6 3也可以简写
## # A tibble: 3 × 3
## a b min
## <dbl> <dbl> <dbl>
## 1 1 4 1
## 2 2 5 2
## 3 3 6 3注意到,mutate() 是column-operation,即提取数据框一列作为向量,传递到mutate中,map2_dbl()返回的也是一个等长的向量。当然,我们可以用第 39 章的row-wise的方法,实现相同功能。
## # A tibble: 3 × 3
## a b min
## <dbl> <dbl> <dbl>
## 1 1 4 1
## 2 2 5 2
## 3 3 6 321.2 pmap()
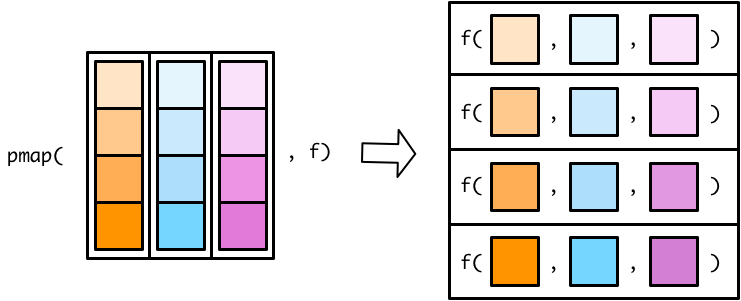
没有map3()或者map4()函数,只有 pmap() 函数可用(p 的意思是 parallel)
pmap()函数稍微有点不一样的地方:
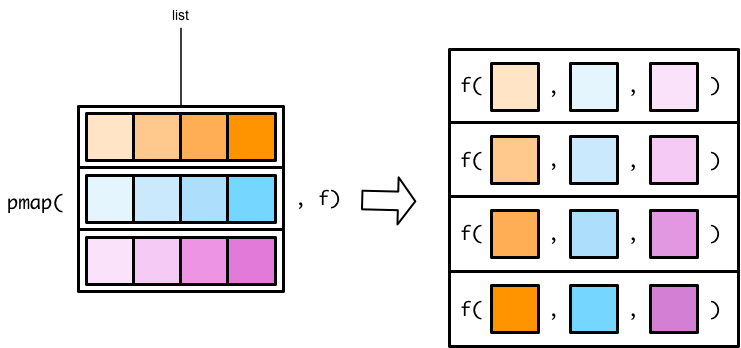
翻转列表的图示,参数的传递关系看地更清楚。
map2_dbl(x, y, min)## [1] 1 2 3## [1] 1 2 321.2.1 用在tibble
tibble本质上就是list,这种结构就是pmap()所需要的,因此,直接应用函数即可。
## [1] 1 60 40以下是两个非常优秀的图示,方便大家记忆
](images/dcl/pmap_jennybc.png)
图 21.1: 图片来源于Jennifer Bryan 的报告《Row-oriented workflows in R and tidyverse》
](images/dcl/pmap_cwickham.png)
图 10.1: 图片来源于charlotte wickham的报告《solving iteration problems with purrr》
21.2.2 匿名函数
pmap()可以接受多个向量,因此在pmap()种使用匿名函数,就需要一种新的方法来标识每个向量。
由于向量是多个,因此不再用.x, .y,而是用..1, ..2, ..3 分别代表第一个向量、第二个向量和第三个向量。
## [[1]]
## [1] 4
##
## [[2]]
## [1] 4
##
## [[3]]
## [1] 4
##
## [[4]]
## [1] 4
##
## [[5]]
## [1] 421.2.3 命名函数
params <- tibble::tribble(
~ n, ~ min, ~ max,
1L, 0, 1,
2L, 10, 100,
3L, 100, 1000
)
pmap(params, ~runif(n = ..1, min = ..2, max = ..3))## [[1]]
## [1] 0.8825562
##
## [[2]]
## [1] 49.03537 18.47046
##
## [[3]]
## [1] 788.4001 839.3224 694.9593如果提供给pmap()的.f 是命名函数,比如runif(n, min = , max = ),它有三个参数
n, min, max, 而我们输入的列表刚好也有三个同名的元素,那么他们会自动匹配,代码因此变得更加简练
pmap(params, runif)## [[1]]
## [1] 0.3114989
##
## [[2]]
## [1] 80.22419 43.78252
##
## [[3]]
## [1] 113.5205 154.8103 309.1044当然,这里需要注意的是
- 输入列表的元素,其个数要与函数的参数个数一致
- 输入列表的元素,其变量名也要与函数的参数名一致
21.3 其他purrr函数
21.3.1 Map functions that output tibbles
接着介绍purrr宏包的其他函数。
map()家族除了返回list和atomic vector 外,map_df(), map_dfr() 和map_dfc()还可以返回tibble。
这个过程,好比生产线上的工人把输入的列表元素依次转换成一个个tibble,
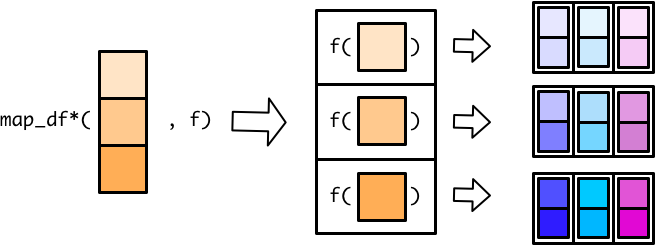
最后归集一个大的tibble。在归集成一个大的tibble的时候,有两种方式,
- 竖着堆积,
map_dfr()(r for rows)
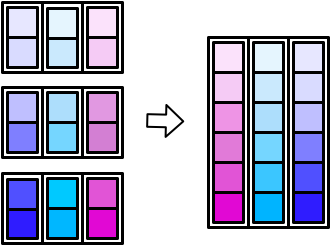
- 并排堆放
map_dfc()(c for columns)
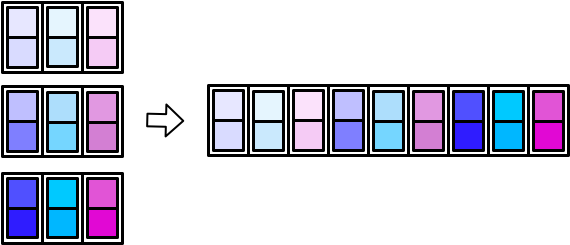
21.3.2 Walk and friends
walk()函数与map()系列函数类似,但应用场景不同,map()在于执行函数操作,而walk() 保存记录数据(比如print(),write.csv(), ggsave()),常用于保存数据和生成图片。比如我们用map()生成系列图片,
plot_rnorm <- function(sd) {
tibble(x = rnorm(n = 5000, mean = 0, sd = sd)) %>%
ggplot(aes(x)) +
geom_histogram(bins = 40) +
geom_vline(xintercept = 0, color = "blue")
}
plots <-
c(5, 1, 9) %>%
map(plot_rnorm)然后我们用walk()函数依次打印出来
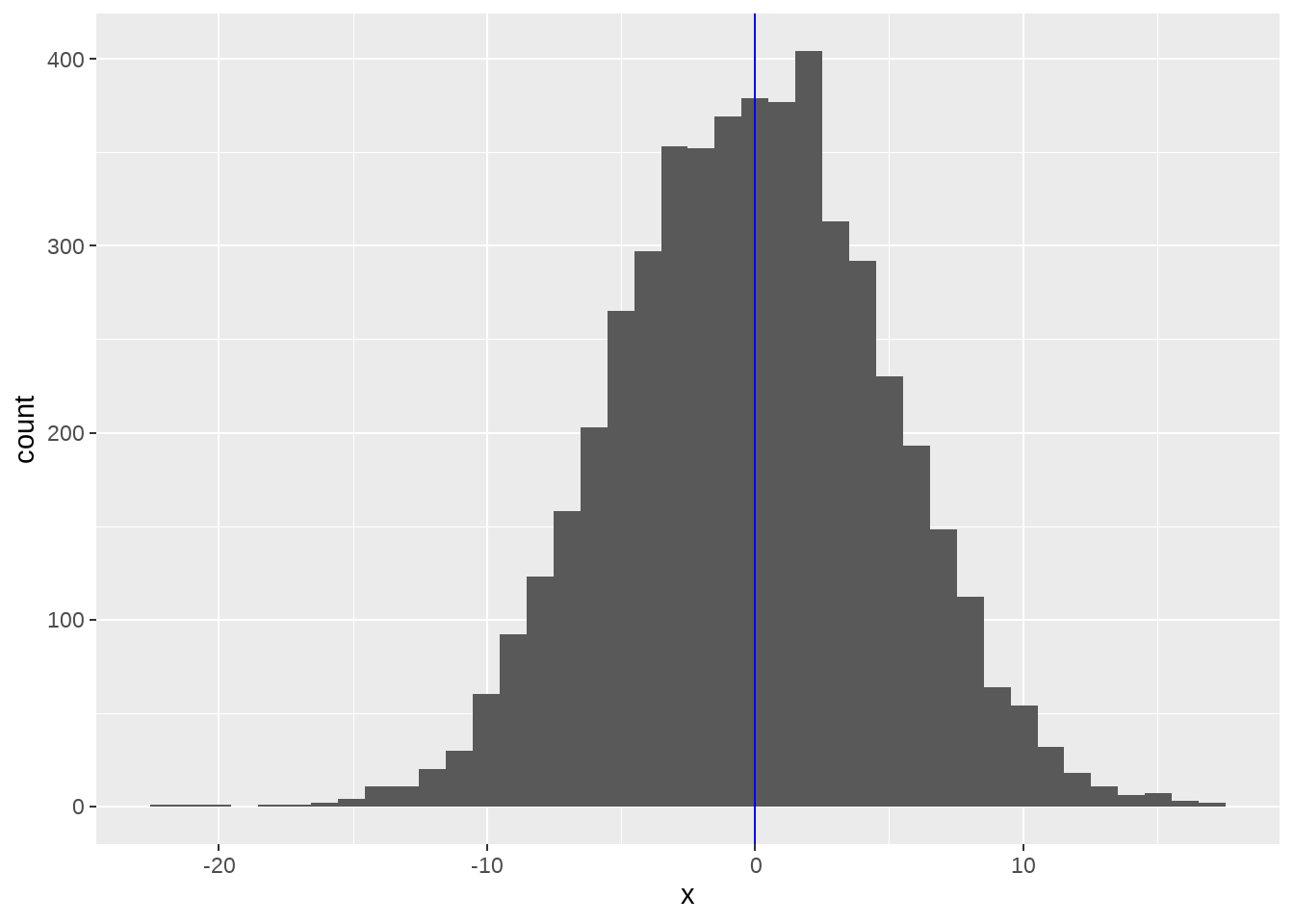
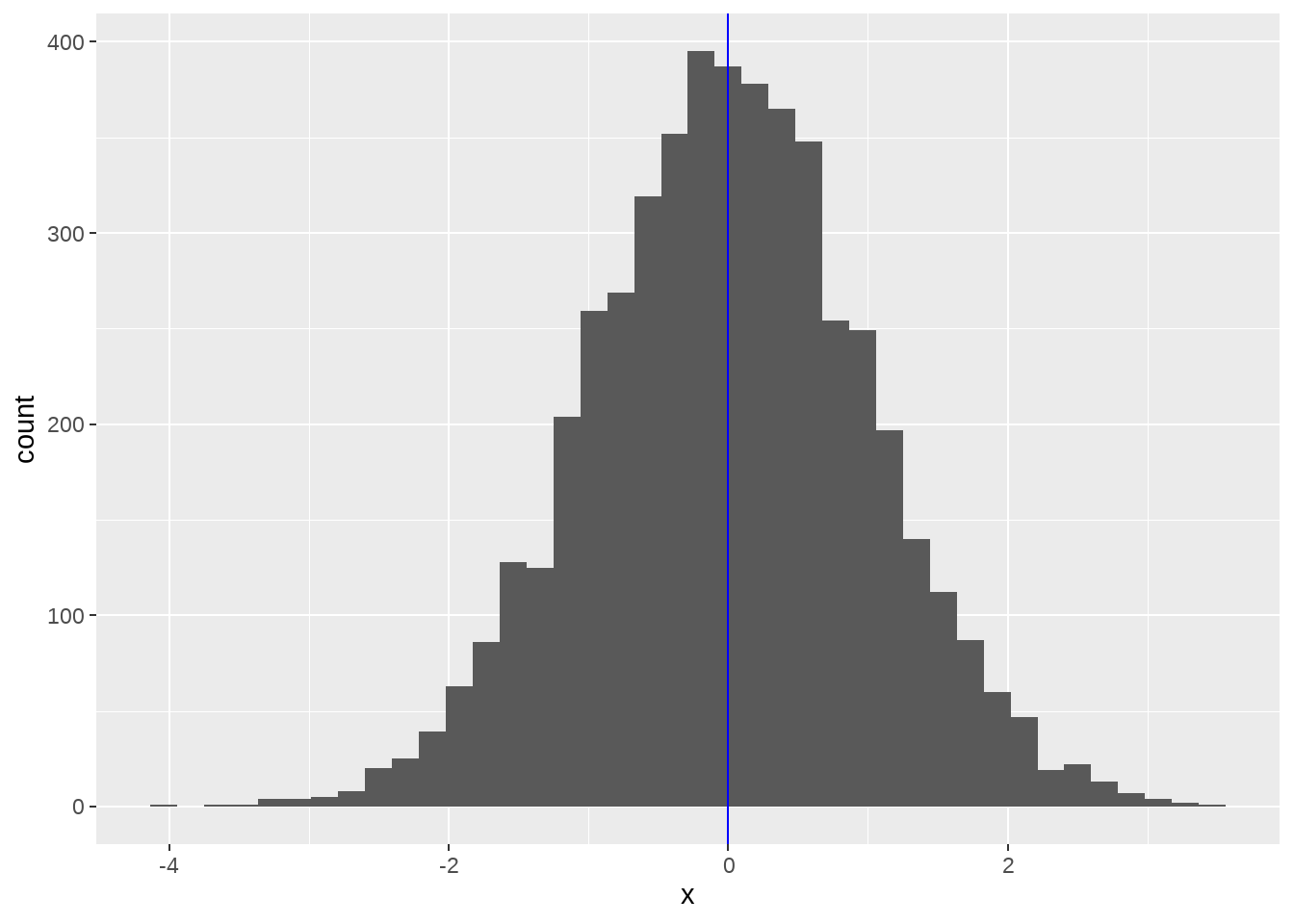
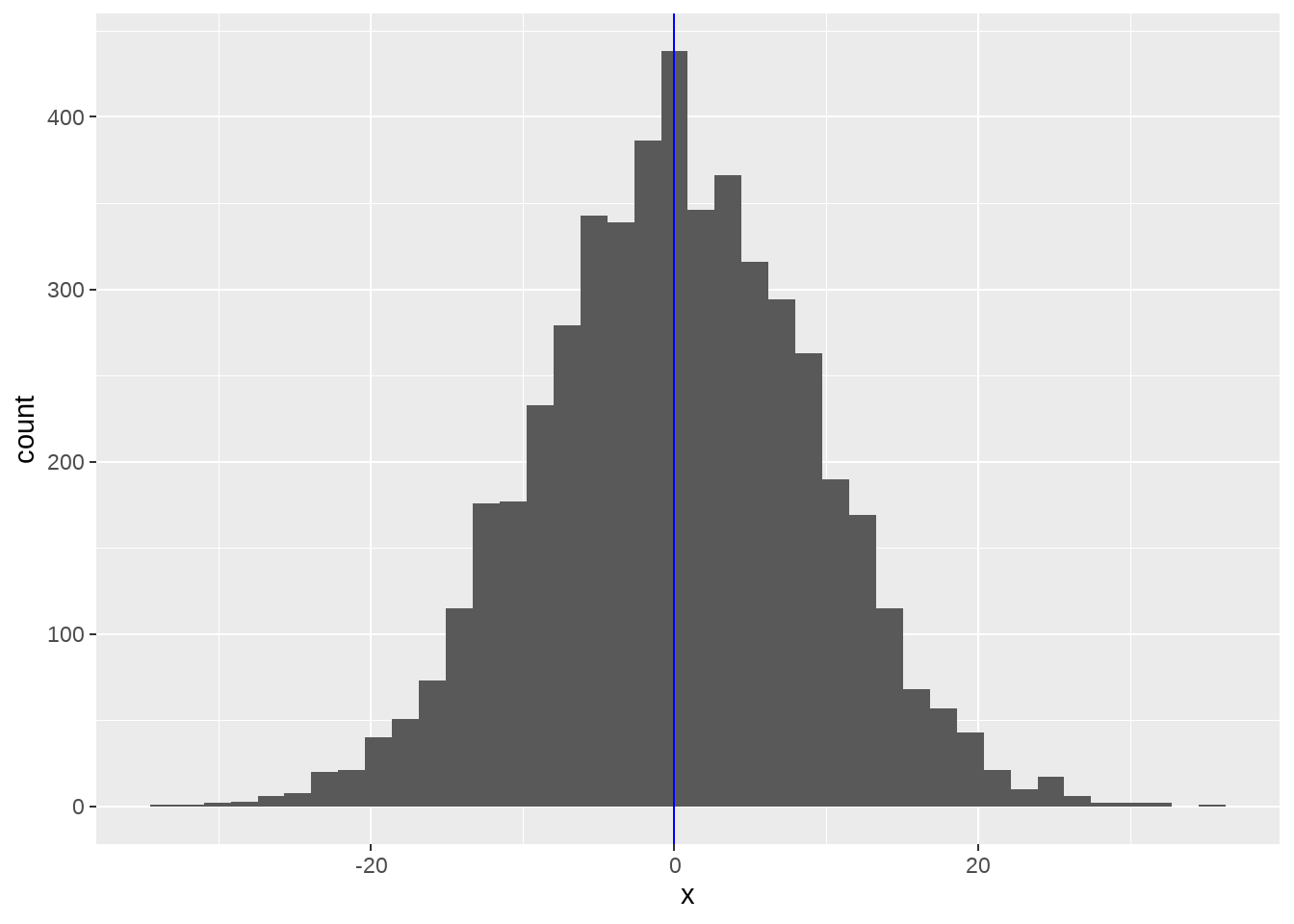
map()函数是一定要返回列表的,但walk()看上去函数没有返回值,实际上它返回的就是它的输入,只是用户不可见而已。
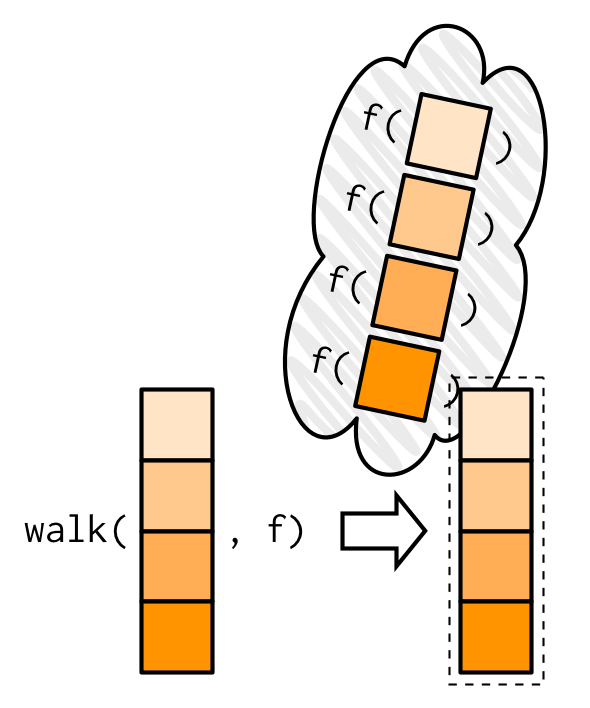
这样的设计很有用,尤其在管道操作中,我们可以统计中,用walk()保存中间计算的结果或者生成图片,然后若无其事地继续管道(因为walk()返回值,就是输入walk的值),保持计算的连贯。