第 9 章 子集选取
子集选取单独作一章,说明它确实很重要。
上一章讲对象、数据类型和数据结构等概念。为了方便理解,我这里打个比方, 对象就是我们在计算机里新建了存储空间,好比一个盒子, 我们可以往盒子里面装东西(赋值),可以查看里面的内容或者对里面的内容做计算(函数),也可以从盒子里取出部分东西(子集选取)。
子集选取,就是从盒子里取东西出来3。
9.1 向量
对于原子型向量,我们有至少四种选取子集的方法
x <- c(1.1, 2.2, 3.3, 4.4, 5.5)- 正整数: 指定向量元素中的位置
x[1]## [1] 1.1
x[c(1, 3)]## [1] 1.1 3.3
x[c(3, 1)]## [1] 3.3 1.1- 负整数:删除指定位置的元素
x[-2]## [1] 1.1 3.3 4.4 5.5
x[c(-3, -4)]## [1] 1.1 2.2 5.5- 逻辑向量:将
TRUE对应位置的元素提取出来
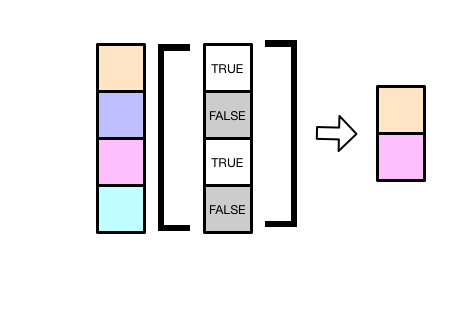
x[c(TRUE, FALSE, TRUE, FALSE, TRUE)]## [1] 1.1 3.3 5.5常用的一种情形;筛选出大于某个值的所有元素
x > 3## [1] FALSE FALSE TRUE TRUE TRUE
x[x > 3]## [1] 3.3 4.4 5.5- 如果是命名向量
y <- c("a" = 11, "b" = 12, "c" = 13, "d" = 14)
y## a b c d
## 11 12 13 14我们可以用命名向量,返回其对应位置的向量
y[c("d", "c", "a")]## d c a
## 14 13 119.2 列表
对列表取子集,和向量的方法一样。向量的子集仍然是向量,使用[提取列表的子集,总是返回列表
## $one
## [1] "a" "b" "c"
##
## $two
## [1] 1 2 3 4 5
##
## $three
## [1] TRUE FALSE使用位置索引
l[1]## $one
## [1] "a" "b" "c"也可以使用元素名
l["one"]## $one
## [1] "a" "b" "c"如果想提取列表某个元素的值,需要使用 [[
l[[1]]## [1] "a" "b" "c"也可以使用其中的元素名,比如[["one"]],
l[["one"]]## [1] "a" "b" "c"取出one位置上的元素,需要写[["one"]],程序员觉得要写太多的字符了,太麻烦了,所以用$来简写
l$one## [1] "a" "b" "c"所以请记住
-
[和[[的区别 -
x$y是x[["y"]]的简写
9.3 矩阵
a <- matrix(1:9, nrow = 3)
a## [,1] [,2] [,3]
## [1,] 1 4 7
## [2,] 2 5 8
## [3,] 3 6 9我们取第1行到第2行的2-3列,[1:2, 2:3],中间以逗号分隔,于是得到一个新的矩阵
a[1:2, 2:3]## [,1] [,2]
## [1,] 4 7
## [2,] 5 8默认情况下, [ 会将获取的数据,以尽可能低的维度形式呈现。比如
a[1, 1:2]## [1] 1 4表示第1行的第1、2列,此时不是\(1 \times 2\)矩阵,而是包含了两个元素的向量。 以尽可能低的维度形式呈现,换句话说,这个1, 4长的像个矩阵,又有点像向量,向量的维度比矩阵低,那就是向量吧。
有些时候,我们想保留所有的行或者列,比如
- 行方向,只选取第 1 行到第 2 行
- 列方向,选取所有列
可以这样简写
a[1:2, ]## [,1] [,2] [,3]
## [1,] 1 4 7
## [2,] 2 5 8对于下面这种情况,想想,会输出什么
a[, ]## [,1] [,2] [,3]
## [1,] 1 4 7
## [2,] 2 5 8
## [3,] 3 6 9可以再简化点?
a[]## [,1] [,2] [,3]
## [1,] 1 4 7
## [2,] 2 5 8
## [3,] 3 6 9是不是可以再简化点?
a## [,1] [,2] [,3]
## [1,] 1 4 7
## [2,] 2 5 8
## [3,] 3 6 99.4 数据框
数据框具有list和matrix的双重属性,因此
- 当选取数据框的某几列的时候,可以和list一样,指定元素位置索引,比如
df[1:2]选取前两列 - 也可以像矩阵一样,按照行和列的标识选取,比如
df[1:3, ]选取前三行的所有列
df <- data.frame(
x = 1:4,
y = 4:1,
z = c("a", "b", "c", "d")
)
df## x y z
## 1 1 4 a
## 2 2 3 b
## 3 3 2 c
## 4 4 1 d9.4.1 Like a list
df[1:2]## x y
## 1 1 4
## 2 2 3
## 3 3 2
## 4 4 1
df[c("x", "z")]## x z
## 1 1 a
## 2 2 b
## 3 3 c
## 4 4 d
df[["x"]]## [1] 1 2 3 4
df$x## [1] 1 2 3 49.4.2 Like a matrix
df[, c("x", "z")]## x z
## 1 1 a
## 2 2 b
## 3 3 c
## 4 4 d也可以通过行和列的位置
df[1:3, ]## x y z
## 1 1 4 a
## 2 2 3 b
## 3 3 2 c当遇到单行或单列的时候,也和矩阵一样,数据会降维
df[, "x"]## [1] 1 2 3 4如果想避免降维,需要多写一句话
df[, "x", drop = FALSE]## x
## 1 1
## 2 2
## 3 3
## 4 4这样输出的还是矩阵形式,但程序员总是偷懒的,有时候我们也容易忘记写drop = FALSE,
所以我比较喜欢下面的tibble.
9.5 增强型数据框
tibble是增强型的data.frame,选取tibble的行或者列,即使遇到单行或者单列的时候,数据也不会降维,总是返回tibble,即仍然是数据框的形式。
## # A tibble: 4 × 3
## x y z
## <int> <int> <chr>
## 1 1 4 a
## 2 2 3 b
## 3 3 2 c
## 4 4 1 d
tb["x"]## # A tibble: 4 × 1
## x
## <int>
## 1 1
## 2 2
## 3 3
## 4 4
tb[, "x"]## # A tibble: 4 × 1
## x
## <int>
## 1 1
## 2 2
## 3 3
## 4 4