8.12 Problemas del nivel de significación
En el siguiente artículo del periódico digital El Confidencial podemos leer
“Los investigadores no saben estadística (y eso perjudica a la ciencia)”
En el interior de la noticia, podemos leer que
“la estadística es la herramienta más importante de que dispone la ciencia para confirmar o refutar hipótesis. Ahora, investigadores denuncian que su uso incorrecto, por mala fe o ignorancia, amenaza la calidad de la investigación. El culpable de todos los males es el \(p\)-valor, un término estadístico cuya popularidad ha aumentado con los años al mismo ritmo que su mal uso.”
Más adelante, comenta
“Un estudio publicado esta semana en la revista ‘JAMA’ ha revisado”millones" de estudios biomédicos fechados entre 1990 y 2015 para concluir que la ‘mala estadística’ es cada vez más empleada. “El \(p\)-valor ya es una técnica subóptima, y si encima se usa de una forma sesgada puede ser muy confusa”, asegura el director del Centro de Investigación Preventiva de la Universidad de Stanford y autor principal del estudio, John Ioannidis."
Cualquier interesado, a estas alturas, ya ha acudido a la fuente original y leído el artículo entero. Vamos a tratar en las siguientes líneas de aclarar algunas de los problemas que puede presentar el \(p\)-valor (si no se utiliza correctamente).
Hemos visto que el test \(t\) para la media de una muestra utiliza el estadístico \[ T=\frac{\bar{x}-\mu _{o}}{\hat{S}_{n-1}/\sqrt{n}}\ \ \in \ \ t_{n-1}. \]
A partir de una muestra, calculamos la media muestral \(\bar{x}\), la cuasi-desviación típica muestral \(\hat{S}_{n-1}\) y hacemos la cuenta: \[ T=\frac{\bar{x}-\mu _{o}}{\hat{S}_{n-1}/\sqrt{n}}=\sqrt{n}\cdot \frac{\bar{x}-\mu _{o}}{\hat{S}_{n-1} } \] En muchas ocasiones, si se pretende probar, por ejemplo, si un nuevo tratamiento es eficaz, el contraste es de la forma \(H_0: \mu = 0\) frente a \(H_1: \mu \neq 0\), ya que obtendremos una muestra de pacientes y mediremos una variable antes de efectuar el tratamiento (dolor, temperatura, horas de sueño… ) y después de realizar el tratamiento. Si el tratamiento es efectivo las diferencias de los valores antes y después serán diferentes a cero (el dolor ha disminuido, o la temperatura, o las horas de sueño han aumentado…).
En este caso el estadístico \(T\) es \[ T=\frac{\bar{x}-0}{\hat{S}_{n-1}/\sqrt{n}}=\sqrt{n}\cdot \frac{\bar{x}}{\hat{S}_{n-1} } \] Si el tamaño de la muestra es grande, este valor también lo va a ser (puesto que se supone que, tomando muestras diferentes, la media y la cuasi-desviación típica muestral nos darán siempre valores parecidos). Es decir, el valor de \(T\) aumenta con el tamaño de la muestra, y recordemos que el \(p-\)valor es el área a la derecha del valor T (o dos veces ese valor). Esto significa que el \(p-\)valor va a ser próximo a cero, y la hipótesis nula siempre se va a rechazar.
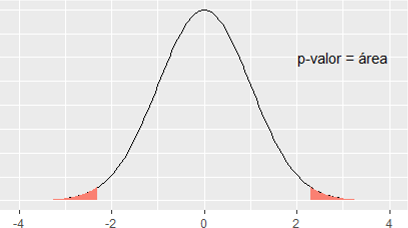
Figura 8.11: \(p\)-valor para un test t bilateral.
La conclusión es que, para demostrar que un tratamiento es efectivo, no es necesario que lo sea, sino simplemente hay que hacer un ensayo clínico con un tamaño de muestra lo suficientemente grande.
Esto ocurre porque el test de hipótesis mide la diferencia entre la media muestral \(\bar{x}\) y el valor cero. Cuando el tamaño de la muestra es muy grande, es como si dispusiésemos de toda la población, con lo cual cualquier diferencia de \(\bar{x}\) con el valor cero se hace significativa (tenemos toda la población y queremos saber si la media es cero. Si obtenemos un valor distinto de cero, aunque sea muy poco distinto, rechazaremos que sea cero).
En su libro Métodos estadísticos para investigadores (Fisher 1992), Ronald Fisher escribió:
“Personally, the writer prefers to set a low standard of significance at the 5 percent point… A scientific fact should be regarded as experimentally established only if a properly designed experiment rarely fails to give this level of significance”
“Un hecho científico se considerará probado experimentalmente sólo si un experimento correctamente diseñado raramente falla en dar este nivel de significación. Un cinco por ciento significaría que el experimento debería repetirse y, de cada cien repeticiones, debería arrojar valores significativos en, al menos, 95 de cada 100 veces”. De esta manera quedaría demostrado que los efectos observados no serían a causa del azar. En definitiva, un \(p-\)valor más pequeño de 0.05 haría al experimento digno de atención, y debería repetirse para tener más certeza sobre el mismo.
El problema surge cuando un experimento es costoso o involucra seres humanos, con todos los problemas añadidos (posibles efectos secundarios, dificultad de repetición… ). Paulatinamente, se realizaron experimentos donde se obtenía un \(p-\)valor. Y había que tomar una decisión. Estamos hablando de la primera mitad del siglo XX, cuando no había ordenadores ni programas que calcularan nada. Lo que había eran tablas estadísticas para poder discernir si el \(p\)-valor era mayor o menos a algún nivel determinado. Se fijaron tres valores fundamentales: \(\alpha=0.1, 0.05\) y \(0.01\). Por aquello de estar en el medio, el nivel \(\alpha=0.05\) fue el más utilizado. De manera que, si el \(p-\)valor era menor que 0.05 se rechazaba la hipótesis nula, y el tratamiento es efectivo. Si el \(p-\)valor era mayor o igual, no se podía rechazar la hipótesis nula, y por lo tanto el tratamiento no podía aceptarse como efectivo.
Esta claro que si, por ejemplo, se pone el límite de significación en 0.05, estamos afirmando que, sobre la base de que 95 veces sobre 100 esperaríamos encontrar que el tratamiento es efectivo. Pero si obtenemos \(p=0.06\) entonces ocurre que 94 de cada cien veces esperaremos encontrar que el tratamiento es efectivo. ¿Es tanta la diferencia?
Lo que ha sucedido, históricamente, es lo que se llama el sesgo de publicación. Si un tratamiento resulta efectivo, es mucho más probable que sea merecedor de ser publicado en una revista científica que si no resulta efectivo. De ahí que se hayan visto todo tipo de artílugios para conseguir que un \(p\)-valor consiga que un tratamiento sea efectivo. Si en el experimento se obtuvo \(p=0.049\) se dice \(p<0.05\) y punto. Si no se obtuvo un valor menor que 0.05, se intenta conseguir un tamaño de muestra lo suficientemente grande para que cualquier diferencia resulte significativa (y digna de mención en alguna revista científica).
Ya en 1994, el famoso psicólogo y estadístico Jacob Cohen (1923-1998), conocido por sus estudios del tamaño del efecto y otros trabajos que ayudaron a sentar las bases para los metaanálisis, publicó un artículo enormemente citado: The earth is round (p<.05), cuyo abstract, traducido, viene a decir:
“Tras cuatro décadas de severa crítica, el ritual del contraste de hipótesis (NHST) —decisiones mecánicas y dicotómicas alrededor del sagrado criterio del 0.05— todavía perdura. Este artículo repasa los problemas derivados de esta práctica, incluyendo la casi universal malinterpretación del \(p\)-valor como la probabilidad de que \(H_0\) sea falsa, la malinterpretación de su complementario como la probabilidad de una réplica exitosa y la falsa premisa de que rechazar \(H_0\) valida la teoría que condujo a la prueba. Como alternativa, se recomiendan el análisis exploratorio de datos y los métodos gráficos, la mejora y la estandarización progresiva de las medidas, el énfasis en la estimación de los tamaños de los efectos usando intervalos de confianza y el uso adecuado de los métodos estadísticos disponibles. Para garantizar la generalización, los psicólogos deben apoyarse, como ocurre en el resto de las ciencias, en la replicación.”
En la decimotercera edición de Métodos estadísticos para investigadores, Fisher realizó la siguiente aclaración sobre los \(p\)-valores:
“el \(p\)-valor indica la fuerza de la evidencia contra la hipótesis nula… y los contrastes de significación deben utilizarse como ayuda para el juicio, y no deben confundirse con pruebas de aceptación automática, o funciones de decisión.”
En 2016, la American Statistical Association (ASA) publicó una declaración sobre los \(p\)-valores, elaborada por un grupo de más de dos docenas de expertos (Wasserstein, Lazar, and others 2016). Aunque hubo discusiones controvertidas sobre muchos temas, el informe de consenso de la ASA incluye la siguiente declaración: “El uso generalizado de la’significación estadística’ (generalmente interpretada como \(p < 0.05\)) como una licencia para hacer una afirmación de un hallazgo científico (o verdad implícita) conduce a una considerable distorsión del proceso científico”
Además, un grupo de siete estadísticos de la ASA publicó en European Journal of Epidemiology (Greenland et al. 2016) una extensa revisión de \(25\) malas interpretaciones de los \(p\)-valores, los intervalos de confianza y la potencia estadística, cerrando con las palabras: “Nos unimos a otros para señalar la degradación de los \(p\)-valores en significativos y no significativos como una práctica estadística especialmente perniciosa”.
Algunos de los comentarios más relevantes inciden en que la significación estadística no puede tomarse como evidencia de que la hipótesis de investigación sea cierta; ni proporciona la probabilidad de la hipótesis, por lo que no hay base para estudiar la replicación y tampoco nos proporciona evidencias verificables de replicación.
Para evitar malas interpretaciones y ayudar en la toma de decisiones, muchos estadísticos sugieren utilizar el enfoque bayesiano, tanto en la realización de test estadísticos (test bayesianos) como en el cálculo de intervalos de confianza y el uso del factor de Bayes (Gelman et al. 2013), (Casella and Berger 1987).
8.12.1 Evidencia y descubrimientos en física
Como detalle de interés, resaltamos que, desde los años 90, los experimentos de física de partículas utilizan como como criterio el correspondiente a un \(p\)-valor de \(2.87 \cdot 10^{-7}\), para refutar con seguridad una hipótesis nula. Solo en ese caso se habla de observación o descubrimiento. Este criterio se llama \(5\sigma\), El criterio llamado \(3\sigma\), correspondiente a un \(p-\)valor de \(1.35\cdot 10^{-3}\), se utiliza para hablar de evidencia. Fuente: trabajo.
Hablando de forma más mundana, un nivel de significación \(\alpha = 0.05\), que es de los más habituales en los artículos científicos, supone un criterio de \(2\sigma\), que, recordemos que en una distribución normal (de media genérica \(\mu\) y desviación típica \(\sigma\)), fuera del intervalo \((\mu -2\cdot \sigma, \mu +2\cdot \sigma)\) se encuentran los valores «más raros», que vienen a ser tan sólo un \(5\) por ciento.
Realmente, no es un \(5\) por ciento, sino un \(4.55\) por ciento. Lo calculamos en una \(N(0,1)\):
2*(1-pnorm(2))## [1] 0.0455knitr::include_graphics('Figure/pvalue3.png')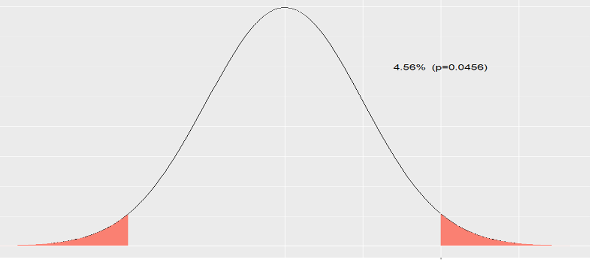
Figura 8.12: Área fuera del intervalo (-2,2).
Fuera del intervalo \((\mu -3\cdot \sigma, \mu +3\cdot \sigma)\) el área es
2*(1-pnorm(3))## [1] 0.0027Si lo dividimos por \(2,\) nos da el valor \(1.35\cdot 10^{-3}\), que es el que citan en el trabajo (es decir, que consideran el área a la derecha de \(\mu + 3\sigma\)).
Fuera del intervalo \((\mu -4\cdot \sigma, \mu +4\cdot \sigma)\)
2*(1-pnorm(4))## [1] 6.334e-05y fuera de \((\mu -5\cdot \sigma, \mu +5\cdot \sigma)\)
2*(1-pnorm(5))## [1] 5.733e-07que, al dividirlo por \(2\), nos da, aproximadamente, \(2.87 \cdot 10^{-7}\) (área a la derecha de \(\mu + 5\sigma\)).
Balanda, Kevin P, and HL MacGillivray. 1988. “Kurtosis: A Critical Review.” The American Statistician 42 (2). Taylor & Francis Group: 111–19.
Ball, Philip. 2004. Masa Crítica. Cambio, Caos y Complejidad. Turner Publicaciones.
Barrett, Anthony M, Seth D Baum, and Kelly Hostetler. 2013. “Analyzing and Reducing the Risks of Inadvertent Nuclear War Between the United States and Russia.” Science & Global Security 21 (2). Taylor & Francis: 106–33.
Bernardo, José Miguel. 1998. “Bruno de Finetti En La Estadistica Contemporanea.” Historia de La Matématica En El Siglo XX, S. Rios (Ed.), Real Academia de Ciencias, Madrid, 63–80.
Bregman, Dennis J, Alexander D Langmuir, and others. 1990. “Farr’s Law Applied to Aids Projections.” Jama 263 (11). American Medical Association: 1522–5.
Brownlee, John. 1915. “Historical Note on Farr’s Theory of the Epidemic.” British Medical Journal 2 (2850). BMJ Publishing Group: 250.
Camacho, Francisco Gómez. 2002. “Probabilismo Y Toma de Decisiones En La Escolástica Espanola.” In Historia de La Probabilidad Y de La Estadística/Ahepe, 81–102.
Caponi, Sandra. 2013. “Quetelet, El Hombre Medio Y El Saber Médico.” História, Ciências, Saúde-Manguinhos 20 (3). Fundação Oswaldo Cruz.
Casella, George, and Roger L Berger. 1987. “Reconciling Bayesian and Frequentist Evidence in the One-Sided Testing Problem.” Journal of the American Statistical Association 82 (397). Taylor & Francis: 106–11.
Castillo, Enrique, José Manuel Gutiérrez, and Ali S Hadi. 1997. “Sistemas Expertos Y Modelos de Redes Probabilisticas.” Academia de Ingenieria.
Cerro, Jesús Santos del. 2002. “Probabilismo Moral Y Probabilidad.” In Historia de La Probabilidad Y de La Estadística/Ahepe, 103–18.
Clauset, Aaron, Cosma Rohilla Shalizi, and Mark EJ Newman. 2009. “Power-Law Distributions in Empirical Data.” SIAM Review 51 (4). SIAM: 661–703.
Cloninger, C Robert, Thomas R Przybeck, Dragan M Svrakic, and Richard D Wetzel. 1994. “The Temperament and Character Inventory (Tci): A Guide to Its Development and Use.” Center for Psychobiology of Personality, Washington University St. Louis, MO.
Conn, Adam, Ullas V Pedmale, Joanne Chory, Charles F Stevens, and Saket Navlakha. 2017. “A Statistical Description of Plant Shoot Architecture.” Current Biology 27 (14). Elsevier: 2078–88.
Cullen, Michael J. 1975. The Statistical Movement in Early Victorian Britain: The Foundations of Empirical Social Research. Harvester Press.
Desrosières, Alain. 2004. “La Política de Los Grandes Números.” Historia de La Razón Estadística. Barcelona: Melusina.
Fisher, Ronald Aylmer. 1949. “Métodos Estadísticos Para Investigadores.”
———. 1992. “Statistical Methods for Research Workers.” In Breakthroughs in Statistics, 66–70. Springer.
Friendly, Michael. 2007. “A.-M. Guerry’s‘ Moral Statistics of France’: Challenges for Multivariable Spatial Analysis.” Statistical Science. JSTOR, 368–99.
García, Alberto. 2012. Inteligencia Artificial: Fundamentos, Práctica Y Aplicaciones. Rc Libros.
Gelman, Andrew, Hal S Stern, John B Carlin, David B Dunson, Aki Vehtari, and Donald B Rubin. 2013. Bayesian Data Analysis. Chapman; Hall/CRC.
Good, Irving J. 1979. “Studies in the History of Probability and Statistics. Xxxvii Am Turing’s Statistical Work in World War Ii.” Biometrika. JSTOR, 393–96.
Greenland, Sander, Stephen J. Senn, Kenneth J. Rothman, John B. Carlin, Charles Poole, Steven N. Goodman, and Douglas G. Altman. 2016. “Statistical Tests, P Values, Confidence Intervals, and Power: A Guide to Misinterpretations.” European Journal of Epidemiology 31 (4): 337–50. doi:10.1007/s10654-016-0149-3.
Hacking, Ian, and Alberto L Bixio. 1995. La Domesticación Del Azar: La Erosión Del Determinismo Y El Nacimiento de Las Ciencias Del Caos. Gedisa Editorial.
Hand, D.J., F. Daly, K. McConway, D. Lunn, and E. Ostrowski. 1993. A Handbook of Small Data Sets. A Handbook of Small Data Sets, v. 1. Taylor & Francis.
Hansenne, Michel, Olivier Le Bon, Anne Gauthier, and Marc Ansseau. 2001. “Belgian Normative Data of the Temperament and Character Inventory.” European Journal of Psychological Assessment 17 (1). Hogrefe & Huber Publishers: 56.
Joynson, Robert B. 1989. The Burt Affair. Taylor & Frances/Routledge.
Kahneman, D. 2014. Pensar Rápido, Pensar Despacio / Thinking, Fast and Slow. Debolsillo Mexico.
Kahneman, Daniel, and Patrick Egan. 2011. Thinking, Fast and Slow. Vol. 1. Farrar, Straus; Giroux New York.
Kalichman, Seth C, and David Rompa. 1995. “Sexual Sensation Seeking and Sexual Compulsivity Scales: Validity, and Predicting Hiv Risk Behavior.” Journal of Personality Assessment 65 (3). Taylor & Francis: 586–601.
Klimek, Peter, Yuri Yegorov, Rudolf Hanel, and Stefan Thurner. 2012. “Statistical Detection of Systematic Election Irregularities.” Proceedings of the National Academy of Sciences 109 (41). National Acad Sciences: 16469–73.
Kolmogorov, Andreĭ Nikolaevich, and Edwin Hewitt. 1948. “Collection of Articles on the Theory of Firing.” Rand Corporation.
Kruskal, William. 1980. “The Significance of Fisher: A Review of Ra Fisher: The Life of a Scientist.” Journal of the American Statistical Association 75 (372). Taylor & Francis Group: 1019–30.
Luque, Bartolo. 2013. “El Problema de Los Tanques Alemanes.” Investigación Y Ciencia.
MacKenzie, Donald A. 1981. Statistics in Britain: 1865-1930; the Social Construction of Scientific Knowledge. Edinburgh University Press.
Mardia, Kanti V, and S Barry Cooper. 2016. “Alan Turing and Enigmatic Statistics.”
Matejka, Justin, and George Fitzmaurice. 2017. “Same Stats, Different Graphs: Generating Datasets with Varied Appearance and Identical Statistics Through Simulated Annealing.” In Proceedings of the 2017 Chi Conference on Human Factors in Computing Systems, 1290–4. CHI ’17. New York, NY, USA: ACM. doi:10.1145/3025453.3025912.
McGrayne, S.B. 2012. La Teoría Que Nunca Murió. Crítica.
Mickey, MR, DW Gjertson, and PI Terasaki. 1986. “Empirical Validation of the Essen-Möller Probability of Paternity.” American Journal of Human Genetics 39 (1). Elsevier: 123.
Montes, Francisco. 2003. “Ley Y Probabilidad.”
Moore, David S, and Stephane Kirkland. 2007. The Basic Practice of Statistics. Vol. 2. WH Freeman New York.
Murray, Charles, and Richard Herrnstein. 1994. “The Bell Curve.” Intelligence and Class Structure in American Life, New York.
Newman, Mark EJ. 2005. “Power Laws, Pareto Distributions and Zipf’s Law.” Contemporary Physics 46 (5). Taylor & Francis: 323–51.
Parzen, Emanuel. 1962. “On Estimation of a Probability Density Function and Mode.” The Annals of Mathematical Statistics 33 (3). JSTOR: 1065–76.
Paulos, J.A., and J.M. Llosa. 1990. El Hombre Anumérico: El Analfabetismo Matemático Y Sus Consecuencias. Matatemas (Tusquets Editores). Tusquets.
Pearl, Raymond. 1905. “Biometrical Studies on Man: I. Variation and Correlation in Brain-Weight.” Biometrika 4 (1/2). JSTOR: 13–104.
Pearson, Karl. 1905. “DAS Fehlergesetz Und Seine Verallgemeiner-Ungen Durch Fechner Und Pearson. a Rejoinder.” Biometrika 4 (1-2). Oxford University Press: 169–212.
Peirce, Charles Sanders, and Joseph Jastrow. 1884. “On Small Differences in Sensation.”
Perrot, Jean-Claude. 1992. “Une Histoire Intellectuelle de L’économie Politique(XVIIe-Xviiie Siècle).” Civilisations et Sociétés. Ehess.
Piovani, Juan Ignacio. 2007. “Los orígenes de La Estadística: De Investigación Socio-Política Empírica a Conjunto de Técnicas Para El análisis de Datos.” Revista de Ciencia Política Y Relaciones Internacionales 1 (1): 25–44.
Poisson, Siméon Denis. 1837. Recherches Sur La Probabilité Des Jugements En Matière Criminelle et En Matière Civile Precédées Des Règles Générales Du Calcul Des Probabilités Par Sd Poisson. Bachelier.
Porter, Theodore M. 1986. The Rise of Statistical Thinking, 1820-1900. Princeton University Press.
Quintela-del-Río, Alejandro. 2018. PEPE (Problemas Estimulantes de Probabilidad Y Estadística). Editorial CreateSpace.
Resnick, Sidney I. 2007. Heavy-Tail Phenomena: Probabilistic and Statistical Modeling. Springer Science & Business Media.
Ritchie, Stuart J, Simon R Cox, Xueyi Shen, Michael V Lombardo, Lianne Maria Reus, Clara Alloza, Matthew A Harris, et al. 2017. “Sex Differences in the Adult Human Brain: Evidence from 5,216 Uk Biobank Participants.” bioRxiv. Cold Spring Harbor Labs Journals, 123729.
Roeder, Kathryn. 1990. “Density Estimation with Confidence Sets Exemplified by Superclusters and Voids in the Galaxies.” Journal of the American Statistical Association 85 (411). Taylor & Francis: 617–24.
Ruggles, Richard, and Henry Brodie. 1947. “An Empirical Approach to Economic Intelligence in World War Ii.” Journal of the American Statistical Association 42 (237). Taylor & Francis Group: 72–91.
Ruiz-Garzón, G. 2015. Condenados Por La Estadística. Servicio de Publicaciones de la Universidad de Cadiz.
Salinero, Pablo. 2006. “Historia de La Teoría de La Probabilidad.” Ver Www. Uam. Es/Personal_pdi/Ciencias/Ezuazua/Informweb/Trabajosdehistoria/S Alinero_probabilidad. Pdf. Consultado El 20: 1–21.
Savage, Leonard J. 1976. “On Rereading Ra Fisher.” The Annals of Statistics. JSTOR, 441–500.
Secades, Marta García. 2002. “Antecedentes de La Concepcion Subjetivista de La Probabilidad.” In Historia de La Probabilidad Y de La Estadística/Ahepe, 119–32.
Silverman, Bernard W. 1986. Density Estimation for Statistics and Data Analysis. Vol. 26. CRC press.
Simon, Pierre. 1951. A Philosophical Essay on Probabilities.
Stigler, Stephen M. 1986. The History of Statistics: The Measurement of Uncertainty Before 1900. Harvard University Press.
Taleb, N.N., and A.S. Mosquera. 2011. El Cisne Negro: El Impacto de Lo Altamente Improbable. Paidós Transiciones. Ediciones Paidós Ibérica, S.A.
Trocchio, Federico di. 1977. Las Mentiras de La Ciencia. Madrid: Alianza editorial.
Tukey, John W. 1977. Exploratory Data Analysis. Vol. 2. Reading, Mass.
Villegas, Miguel Angel Gómez. 2001. “El Ensayo Encaminado a Resolver Un Problema En La Doctrina Del Azar.” Revista de La Real Academia de Ciencias Exactas, Físicas Y Naturales 95 (1). Real Academia de Ciencias Exactas, Físicas y Naturales: 81–85.
Wainer, Howard. 2007. “The Most Dangerous Equation.” American Scientist 95 (3): 249.
Wand, MP. 1997. “Data-Based Choice of Histogram Bin Width.” The American Statistician 51 (1). Taylor & Francis: 59–64.
Wasserstein, Ronald L, Nicole A Lazar, and others. 2016. “The Asa’s Statement on P-Values: Context, Process, and Purpose.” The American Statistician 70 (2): 129–33.
Wickham, Hadley. 2016. Ggplot2: Elegant Graphics for Data Analysis. Springer.
Yule, George U. 1938. “Notes of Karl Pearson’s Lectures on the Theory of Statistics, 1884-96.” Biometrika 30 (1/2). JSTOR: 198–203.
Zafra, Juan Manuel López, and Sonia de Paz Cobo. 2012. “7. Justicia Y Probabilidad En La Francia de La Revolución: Las Posturas de Condorcet, Laplace Y Poisson.” In Historia de La Probabilidad Y de La Estadística Vi, 159–72. Universidad Nacional de Educación a Distancia, UNED.
References
Casella, George, and Roger L Berger. 1987. “Reconciling Bayesian and Frequentist Evidence in the One-Sided Testing Problem.” Journal of the American Statistical Association 82 (397). Taylor & Francis: 106–11.
Fisher, Ronald Aylmer. 1992. “Statistical Methods for Research Workers.” In Breakthroughs in Statistics, 66–70. Springer.
Gelman, Andrew, Hal S Stern, John B Carlin, David B Dunson, Aki Vehtari, and Donald B Rubin. 2013. Bayesian Data Analysis. Chapman; Hall/CRC.
Greenland, Sander, Stephen J. Senn, Kenneth J. Rothman, John B. Carlin, Charles Poole, Steven N. Goodman, and Douglas G. Altman. 2016. “Statistical Tests, P Values, Confidence Intervals, and Power: A Guide to Misinterpretations.” European Journal of Epidemiology 31 (4): 337–50. doi:10.1007/s10654-016-0149-3.
Wasserstein, Ronald L, Nicole A Lazar, and others. 2016. “The Asa’s Statement on P-Values: Context, Process, and Purpose.” The American Statistician 70 (2): 129–33.