3.2 Estructura de la información en variables bidimensionales
En variables unidimensionales, los datos podían organizarse en tablas de frecuencias (bien de valores, en el caso de variables discretas, o bien de intervalos, en el caso de variables continuas)
Cuando leemos un fichero de datos, como por ejemplo el del Titanic
Titanic <- read_excel("Data/Pasajeros-Titanic.xlsx")
datatable(Titanic, options = list(pageLength = 5, dom = 'tip'))disponemos de una serie de variables ordenadas en columnas. A partir de una tabla de datos podemos seleccionar diferentes variables unidimensionales (discretas, continuas o atributos (categorías)). Si se seleccionan dos variables discretas (o atributos), en ocasiones se presenta la información construyendo una tabla de doble entrada con los valores de cada variable y las frecuencias (\(n_{(i,j)}\) es la frecuencia absoluta del valor \((x_i,y_j)\), o número de veces que se repite dicho par de valores).
En la última columna y en la última fila de la tabla suelen presentarse las sumas por fila y columna, respectivamente, siendo el total de datos \(n\).
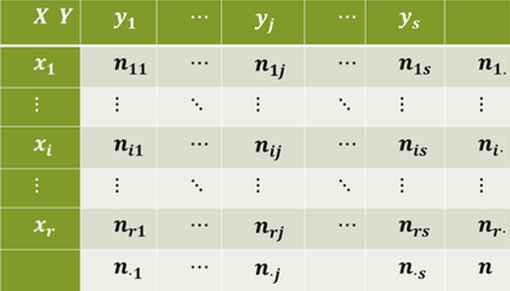
Figura 3.3: Tabla de doble entrada para una variable bidimensional.
Si \(X\) e \(Y\) son variables numéricas, la tabla suele llamarse tabla de correlación.
Si \(X\) e \(Y\) son atributos o categorías, la tabla suele llamarse tabla de contingencia.
t1<- table(Titanic$sobrevivio, Titanic$clase)
t2<-addmargins(t1)
pander(t2)| 1st | 2nd | 3rd | Sum | |
|---|---|---|---|---|
| no | 123 | 158 | 528 | 809 |
| yes | 200 | 119 | 181 | 500 |
| Sum | 323 | 277 | 709 | 1309 |