1.4 Rappels de programmation en R
Indirectement, l’un des préalables du cours ACT5400-Crédibilité est le cours ACT3035-Laboratoire d’actuariat. Ainsi, vous avez tous une connaissance suffisante de R pour suivre les notes de cours. Il peut par contre être pertinent de refaire un survol de quelques éléments de base qui seront utilisés dans le cours.
1.4.1 Importance de R
- En actuariat de l’assurance de dommages (I.A.R.D., ou non-vie), R est l’un des outils les plus utilisés
- Avec Python, en science des données, R est aussi l’outil principal
- R offre plus d’options que Python pour l’analyse statistique
1.4.2 Tidyverse
- Certaines fonctions de base, via les packages base, stats ou graphics, offrent des solutions intéressantes pour l’analyse de données
- Par contre, parce que c’est un logiciel libre (open source), la force de R est d’offrir une multitudes de packages que n’importe qui peut écrire et diffuser
- Récemment, un effort concerté de plusieurs contributeurs a mené au développement du package Tidyverse
Coordonné par le légendaire scientifique en chef de RStudio, Hadley Wickham, le package Tidyverse est une collection de packages intentionnellement développés autour du concept de tidy data.
Pour utiliser Tidyverse, on doit tout d’abord télécharger le package en passant par la fonction install.packages().
Le package n’a besoin d’être téléchargé qu’une seule fois (sauf pour les mises-à-jour). Ensuite, à chaque sesssion, il suffit d’appeler le package Tidyverse par la fonction library().
## ── Attaching core tidyverse packages ──────────────────────────────────────────────────────────────────────────────────────────────────────────── tidyverse 2.0.0 ──
## ✔ dplyr 1.1.2 ✔ readr 2.1.4
## ✔ forcats 1.0.0 ✔ stringr 1.5.0
## ✔ ggplot2 3.4.2 ✔ tibble 3.2.1
## ✔ lubridate 1.9.2 ✔ tidyr 1.3.0
## ✔ purrr 1.0.1
## ── Conflicts ────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────── tidyverse_conflicts() ──
## ✖ dplyr::filter() masks stats::filter()
## ✖ dplyr::lag() masks stats::lag()
## ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errorsLa notion centrale des tidy data est que chacune des observations d’un jeu de données correspond à la même unité d’observation:
- Les colonnes du jeu de données représentent ainsi des variables sur ces unités d’observation.
- Cela signifie qu’une base de données de type tidy data ne contient pas de ligne totalisant d’autres lignes, ou contenant des étiquettes comme les noms de lignes au lieu de variables, etc.
- Les packages du Tidyverse sont centrés sur des bases de données que nous nommons data.frame.
- Les fonctions utilisées dans le package prennent généralement un data.frame comme première entrée, le transforme, et
puis crée une version modifiée du data.frame.
- D’autres structures de données comme les matrices, les vecteurs et les listes sont moins couramment utilisés dans le Tidyverse.
- Ce qu’on appelle un tibble est similaire à un data.frame, mais peut inclure des fonctionnalités supplémentaires.
En assurance I.A.R.D., un data.frame adhérant au concept de tidy data serait une base de données listant des contrats d’assurance. Sur une même ligne (observation), on peut ainsi trouver des caractéristiques du contrat, de l’assuré, des biens assurés, en plus de certaines statistiques de sinistralité (nombre de sinistres réclamés pour ce contrat, coût de chaque réclamation, etc.)
Sur la page Moodle du cours, une base de données d’assurance I.A.R.D. fictive a été déposée. Il suffit de télécharger la base de données sur son ordinateur et d’utiliser la fonction load() de R pour y accéder, en pointant vers l’endroit ou la base de données a été sauvée:
La fonction head() affiche les premières lignes d’un jeu de données.
## # A tibble: 6 × 32
## policy_no veh.num renewal_date debut fin expo nb.sin Tot.Cost freq_paiement annee_veh sexe an_naissance annee_permis langue type_prof type_voiture
## <dbl> <int> <date> <date> <date> <dbl> <int> <dbl> <dbl> <dbl> <chr> <dbl> <dbl> <chr> <chr> <chr>
## 1 6000088 1 2015-11-10 2014-11-10 2015-11-09 1 0 0 12 2010 M 1970 1990 F Autres Utilitaires
## 2 6000088 1 2016-11-10 2015-11-10 2016-11-09 0.997 1 186. 12 2010 M 1970 1990 F Autres Utilitaires
## 3 6000274 1 2011-02-03 2010-02-03 2011-02-02 0.997 0 0 12 2000 F 1952 1982 A Hockeyeur Compacte
## 4 6000274 1 2012-02-03 2011-02-03 2012-02-02 1 0 0 12 2000 F 1952 1982 A Hockeyeur Compacte
## 5 6000274 1 2013-02-03 2012-02-03 2013-02-02 0.997 0 0 12 2000 F 1952 1982 A Hockeyeur Compacte
## 6 6000274 1 2014-02-03 2013-02-03 2014-02-02 0.997 0 0 12 2000 F 1952 1982 A Hockeyeur Compacte
## # ℹ 16 more variables: type_territoire <chr>, utilisation <chr>, voiture <chr>, couleur <chr>, myopie <chr>, alimentation <chr>, cheveux <chr>, Cost1 <dbl>,
## # Cost2 <dbl>, Cost3 <dbl>, Cost4 <dbl>, Cost5 <dbl>, Cost6 <dbl>, Cost7 <dbl>, ID <chr>, Type <chr>La fonction colnames() liste la totalité des colonnes de la base de données, alors que nrow() indique le nombre total d’observation du jeu de données.
## [1] "policy_no" "veh.num" "renewal_date" "debut" "fin" "expo" "nb.sin" "Tot.Cost"
## [9] "freq_paiement" "annee_veh" "sexe" "an_naissance" "annee_permis" "langue" "type_prof" "type_voiture"
## [17] "type_territoire" "utilisation" "voiture" "couleur" "myopie" "alimentation" "cheveux" "Cost1"
## [25] "Cost2" "Cost3" "Cost4" "Cost5" "Cost6" "Cost7" "ID" "Type"## [1] 386883Ainsi, avec head() et colnames(), on peut bien comprendre la structure du jeu de données db.fictif. Nous travaillerons sur le jeu de données db.fictif pour le cours.
Il existe de nombreux packages dans le tidyverse, mais quelques-uns méritent une attention particulière.
1.4.3 dplyr
Le package dplyr fournit des outils complets pour la manipulation de données. Les cinq principales tâches de dplyr incluent :
- select() permet de choisir un sous-ensemble de colonnes;
- filter() permet de choisir un sous-ensemble de lignes en fonction de critères logiques;
- arrange() permet de trier les lignes (observations) en fonction des valeurs des colonnes;
- mutate() permet d’ajouter ou de modifier le contenu d’une colonne;
- summarize() permet de réduire un jeu de données à une seule ligne (par groupe) en agrégeant les colonnes en valeurs uniques. Souvent, cette fonction sera utilisée en avec la fonction group_by().
Exemple 1.5 En utilisant le jeu de données db.fictif, faites les tâches suivantes:
1- Calculer la fréquence moyenne de réclamations en fonction de l’utilisation et de la langue;
2- Créer une nouvelle colonne indiquant l’âge de l’assuré au début de sa couverture, et calculer la moyenne de l’âge des assurés en fonction de leur alimentation;
3- Créer une nouvelle base de données qui est triée fonction de la date de renouvellement (renewal_date).
## # A tibble: 6 × 3
## utilisation langue freq
## <chr> <chr> <dbl>
## 1 Loisir A 0.235
## 2 Loisir F 0.279
## 3 Travail-occasionnel A 0.169
## 4 Travail-occasionnel F 0.226
## 5 Travail-quotidien A 0.128
## 6 Travail-quotidien F 0.175library(lubridate)
db.fictif %>%
group_by(alimentation) %>%
mutate(Age = lubridate::year(debut) - an_naissance) %>%
summarize(Age.mean = mean(Age), .groups = 'drop')## # A tibble: 3 × 2
## alimentation Age.mean
## <chr> <dbl>
## 1 Carnivore 38.6
## 2 Végétalien 42.0
## 3 Végétarien 48.4Quelques remarques:
- Avec dplyr, on utilise l’opérateur pipe, noté “%>%”. Il est généralement admis que ce nouvel opérateur aide à mieux lire le code.
- Pour travailler avec les dates, et extraire l’année d’une colonne remplie dans une date, nous avons fait référence à un package, et tout comme on l’avait fait pour tidyverse, on appelle le package avec la fonction library() (il faut avoir préalablement téléchargé le package avec la fonction install.package())
Les 5 tâches principales de dplyr, souvent en utilisant des fonctions permettant de fusionner deux jeux de données (par exemple, inner_join(), left_join(), etc.), nous sommes capables de répliquer les fonctionnalités usuelles des requêtes SQL.
Une vaste gamme d’opérations d’analyse de données peut être réduit à des combinaisons de ces fonctions, avec quelques autres tâches fournies par dplyr, telles que rename(), count(), bind_rows(), pull(), etc..
1.4.4 ggplot2
Le package ggplot2 est le système graphique approprié pour le package tidyverse.
L’idée générale du package est de construire des graphiques par étape, en ajoutant successivement des couches au graphique. Une quantité importante de détails et d’information sur ggplot2 peut être trouvé sur le web. Il est recommandé à tous d’y jeter un coup d’oeil pour mieux comprendre comment construire un graphique.
Exemple 1.6 En utilisant encore une fois le jeu de données db.fictif, illustrez la fréquence de réclamation par année (en fonction de la colonne debut).
library(lubridate)
db <- db.fictif %>%
mutate(Year = lubridate::year(debut)) %>%
group_by(Year) %>%
summarize(tot.nbsin = sum(nb.sin),
tot.expo = sum(expo),
.groups = 'drop') %>%
mutate(freq = tot.nbsin/tot.expo )
ggplot()+
geom_line(aes(x=as.factor(Year), y=freq, group = 1), data=db)+
geom_point(aes(x=as.factor(Year), y=freq, group = 1), data=db)+
scale_x_discrete()+
xlab("Année") +
ylab("Fréquence") +
theme_bw()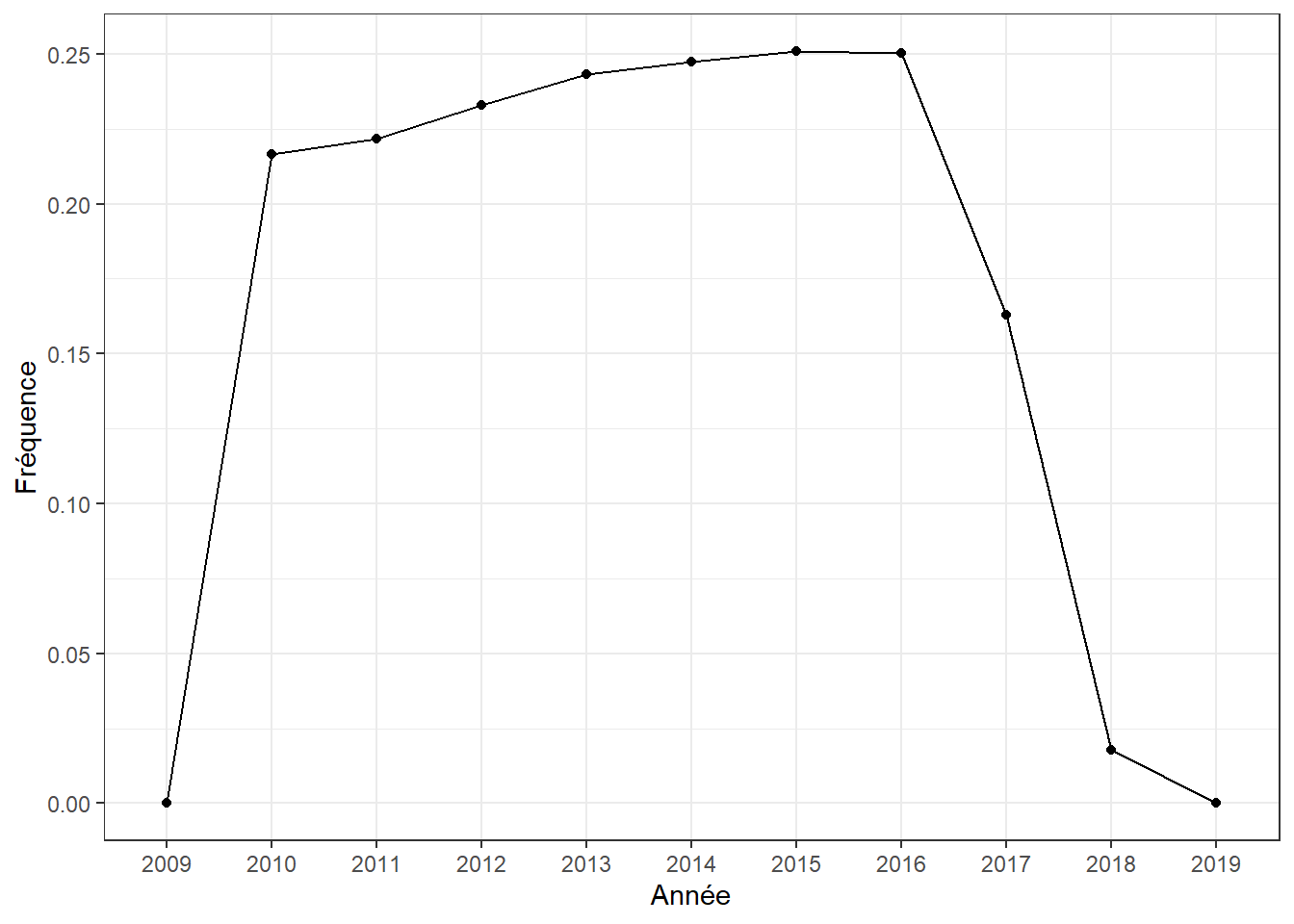
1.4.5 Autres
En plus des packages que nous venons de couvrir, il existe de nombreux autres packages utiles pour travailler avec les bases de données d’assurance.
Il est à noter, d’ailleurs, que je suis loin d’être un expert en programmation. Certains des codes que je proposerai dans ces notes de cours peuvent probablement être plus efficaces. L’objectif en actuariat est plus souvent d’obtenir une réponse, ou proposer une solution, que de créer des scripts efficaces et rapides. Pour chercher à effectuer une tâches avec R, n’oubliez jamais que Google est votre ami.