4.1 記述統計
記述統計の設定画面は図4.3のようになっています。
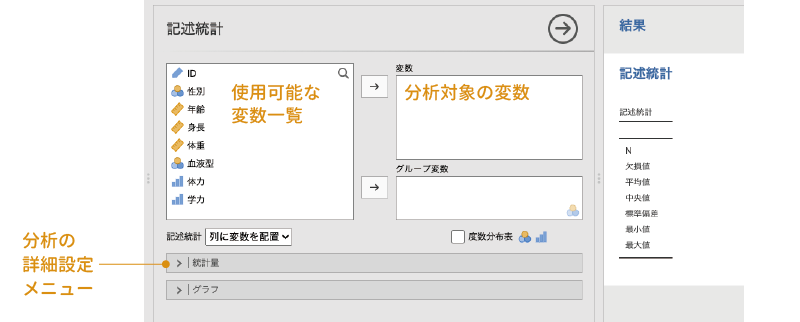
図4.3: 記述統計の分析設定画面
画面左側の部分は,データファイルに含まれている変数の一覧です。ここから,分析したい変数を選択し,それをその右側にある「変数」の欄に移動すると,指定した変数に関する記述統計量を算出することができます。また,画面の下のほうには[統計量]や[グラフ]と書かれた部分がありますが,この部分の左側にある「![]() 」をクリックすると,それぞれ統計量の算出や作図に関する詳細設定項目が表示されるようになっています。
」をクリックすると,それぞれ統計量の算出や作図に関する詳細設定項目が表示されるようになっています。
各項目の詳細の説明は後回しにして,まずは実際にいろいろと分析してみましょう。まず,「性別」について記述統計量を求めてみます。左側の変数リストで「性別」を選択したら,変数の隣にある「 」をクリックしてください。すると,「性別」が左の変数リストから右側の変数に移動され,それと同時に画面右側の出力ウィンドウに計算結果が表示されます(図4.4)。
」をクリックしてください。すると,「性別」が左の変数リストから右側の変数に移動され,それと同時に画面右側の出力ウィンドウに計算結果が表示されます(図4.4)。
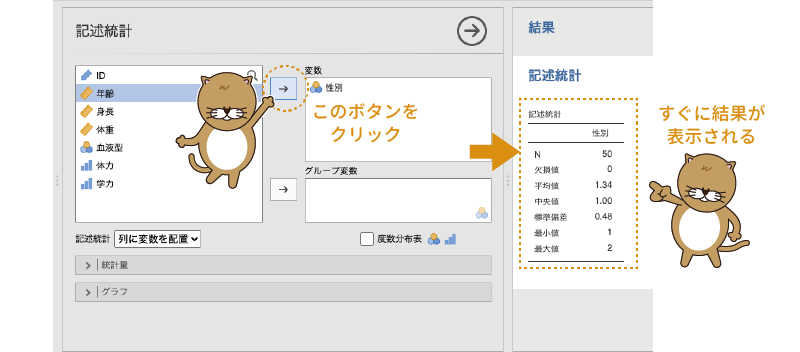
図4.4: 「性別」の記述統計量の算出
ここがjamoviのおもしろいところで,分析画面で変数を指定したり,あるいは分析の設定を変更したりすると,その変更がすぐに結果画面に反映されるのです。他の多くの統計ソフトでは,分析対象の変数を変更したり,分析の設定を変更したりした場合には,分析の再実行を行わないと結果は更新されません。しかし,jamoviでは,このようにほぼリアルタイムに結果が更新されていくので,設定変更による結果を確認しながら分析を進めていくことができます。
では,計算結果についても簡単に見ておきましょう。
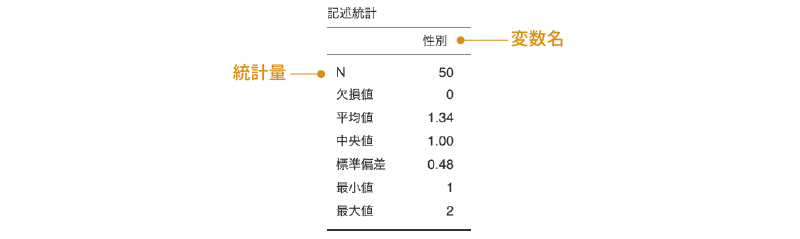
図4.5: 「性別」の記述統計量
図4.5の結果から,N(データの総数)が「50」,平均値が「1.34」といったことがわかります。
また,この結果では各統計量が縦(行)に並び,変数が横(列)に並んでいますが,変数が多く,算出する統計量の種類が少ない場合には,縦と横の表示を入れ替えた方が見やすいでしょう。その場合には,設定画面の変数一覧の下にある「記述統計」の横の「列に変数を配置」となっている部分を「行に変数を配置」に変更することで,行方向と列方向の表示を入れ替えることもできます図4.6。
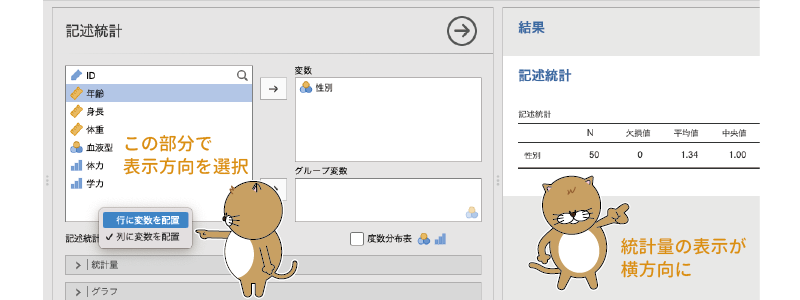
図4.6: 結果表示の方向を変更
さて,これでひとまず結果は出たのですが,この計算結果には問題があります。「性別」は名義型変数なので,平均値は意味をなしません。この変数は男性を「1」,女性を「2」として入力されていて,平均値の計算自体はできるのですが,この「性別の平均値が1.34」というのはまったく意味がないのです。
このような名義尺度データでは,まず男性と女性がそれぞれ何人ずつなのか,といったことを知りたいはずです。その場合,変数リストのすぐ下にある「度数分布表」のチェックをオンにします(図4.7)。なお,この「度数分布表」のところには
 というアイコンが付けられています。これは,この項目は分析変数の型が「 名義」と「 順序」の場合のみ使用できるということを意味しています。
というアイコンが付けられています。これは,この項目は分析変数の型が「 名義」と「 順序」の場合のみ使用できるということを意味しています。
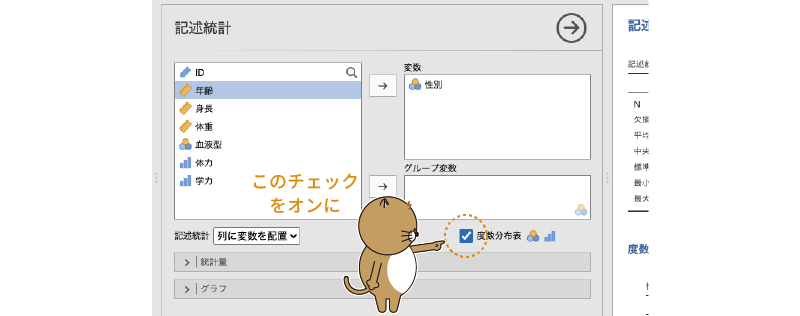
図4.7: 度数分布表の表示設定
このチェックをオンにすると,すぐに出力ウィンドウに図4.8のような度数分布表が表示されます。度数分布表には,変数値ごとの度数とその全体における比率(全体%),および累積パーセント値が示されています。

図4.8: 度数分布表
4.1.1 統計量
さて,これで度数分布表はできましたが,先ほどの平均値の表はそのままになっていますので,これをなんとかしたいですね。そこで,結果に表示させる値をもう少し細かく設定することにしましょう。そのためには,![]() | 統計量の左側にある「
| 統計量の左側にある「![]() 」をクリックし,詳細項目を展開します。
」をクリックし,詳細項目を展開します。
すると,非常にたくさんの項目が表示されました(図4.9)。各項目の使い方についてはまた後ほど説明することとして,ここではこの画面で設定可能な項目の一覧を見ておきましょう。
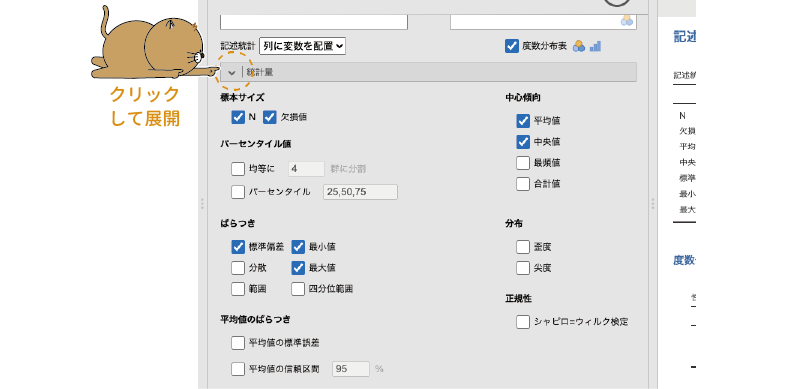
図4.9: 統計量の詳細設定
- 標本サイズ 標本サイズに関連する情報の設定を行います。
- N 分析変数に含まれるデータ総数を表示します。
- 欠損値 分析変数に含まれる欠損値の個数を表示します。
- パーセンタイル値 パーセンタイル値や分位数に関する設定を行います。
- 均等に[ ]群に分割 データ全体をn等分する位置にある値を算出します。
- パーセンタイル 値の小さいほうから数えてn%の位置にある値を算出します。複数のパーセント点を指定する場合は,それらの値をコンマで区切って入力します。
- ばらつき パーセンタイル値や分位数に関する設定を行います。
- 標準偏差 標準偏差を算出します。
- 分散 分散を算出します。
- 範囲 範囲(最大値 – 最小値の幅)を算出します。
- 最小値 最小値を算出します。
- 最大値 最大値を算出します。
- 四分位範囲 四分位範囲を算出します。
- 平均値のばらつき
- 平均値の標準誤差 平均値の推定における標準誤差を算出します。
- 平均値の信頼区間 平均値の信頼区間(下限値と上限値)を算出します。初期設定では95%信頼区間を算出しますが,数値を変更すれば90%や99%などで信頼区間を算出することができます。
- 中心傾向 データの中心位置に関する統計量を算出します。
- 平均値 平均値を算出します。
- 中央値 中央値を算出します。
- 最頻値 最頻値を算出します。
- 合計値 合計値を算出します。
- 分布 データの分布に関する統計量を算出します。
- 歪度 歪度(分布が左右対称からずれている程度)を算出します。
- 尖度 尖度(分布が中心に集中している程度)を算出します。
- 正規性
- シャピロ=ウィルク検定 分布が正規分布からずれているかどうかを検定します。
「性別」の記述統計で平均値などの不要な値を表示しないようにするには,この画面で「平均値」などの不要な項目のチェックを外すだけです。「N」と「欠損値」だけを残してそれ以外のチェックを外すと,結果の表示は図4.10のようになります。これですっきりです。

図4.10: 設定変更後の結果
では,他の変数についても同様に記述統計量を算出しましょう。次は,「性別」と同じく名義尺度型変数である「血液型」について記述統計量を算出することにします。まずは,設定画面の右上にある をクリックして,この設定画面をいったん閉じましょう。
をクリックして,この設定画面をいったん閉じましょう。
そして,再度「 探索」から「記述統計」を実行して設定画面を開きます。すると,先ほどの分析結果の下に新しい結果の表が作成され,そして再び先ほどの設定画面が現れます。
探索」から「記述統計」を実行して設定画面を開きます。すると,先ほどの分析結果の下に新しい結果の表が作成され,そして再び先ほどの設定画面が現れます。
「血液型」でも,性別のときと同様に度数分布表を作成することにしましょう。また,性別と違って血液型には4種類の値が含まれていますので,今回は最頻値についても算出することにします。この場合,分析の設定画面は図4.11のようになります。
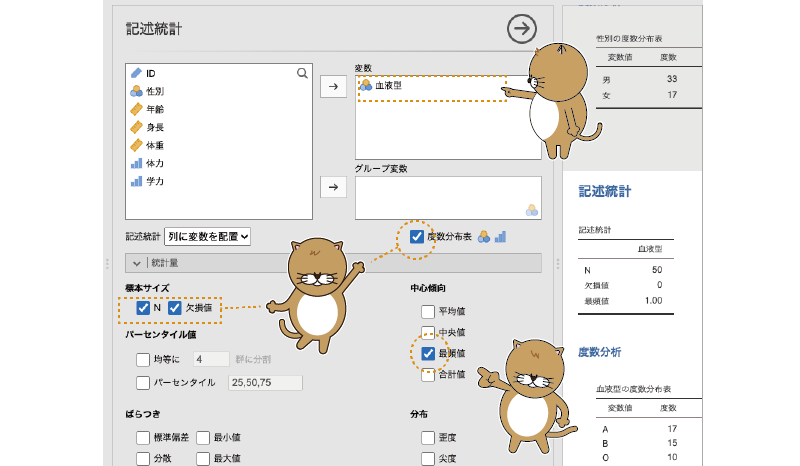
図4.11: 血液型の記述統計
最頻値は1.00となっていますが,このデータでは血液型が「A=1,B=2,O=3,AB=4」として入力されているので,最頻値は「A型」ということになります。度数分布表では値そのものではなく変数ラベルが表示されるのですが,記述統計量の表では残念ながら変数ラベルではなく値そのものが表示されるので,その点は注意が必要です。
順序尺度データの記述統計
今度は順序尺度データである「体力」と「学力」について記述統計量を算出しましょう。いったんこの設定画面を閉じ,再び「 探索」から「記述統計」を選択して設定画面を開いてください。
なお,この「体力」と「学力」の変数の値はどちらも5段階評価によるもので,値が大きいほど評価が高いことを意味します。このように,この2つの変数は共通した部分が多いのでまとめて分析することにしましょう。変数の欄に,「体力」と「学力」の2つを移動させると,出力ウィンドウにはこれらの変数についての計算結果がひとまとめに表示されます。
この2つの変数は,値が5種類しかない順序尺度変数ですので,今回も度数分布表を作成することにしましょう。また,順序尺度データなので,平均値や標準偏差にはあまり意味はありませんね。ですので,これらは非表示にしておきます。その代わり,データのばらつきの指標として四分位数を算出したいと思います。四分位数を算出するには,設定画面の「均等に[ ]群に分割」の部分にチェックを入れ,入力欄の数値を「4」にします。なお,第2四分位数(50%点)は中央値と同じですので,「中央値」のチェックは外してしまいましょう(図4.12)。
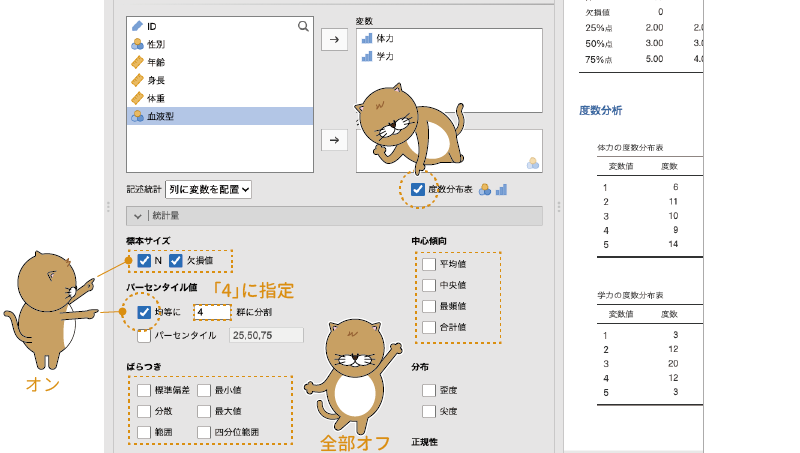
図4.12: 体力と学力の記述統計の算出
この設定にすると,分析結果には2変数の測定値の総数と欠損値の個数,第1四分位数(25%点),第2四分位数(50%点=中央値),第3四分位数(75%点)が含まれた記述統計量の表と,それぞれの変数の度数分布表が表示されます(図4.13)。
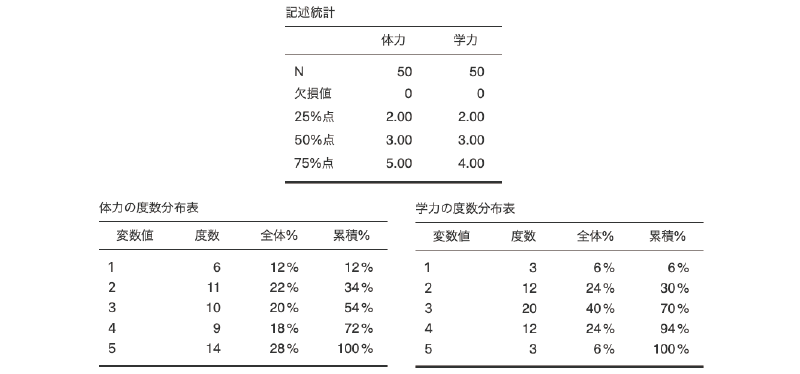
図4.13: 体力と学力の記述統計量
記述統計量だけで見ると2つの変数は非常によく似た結果になっていますが,度数分布表を見ると「体力」のほうがややばらつきが大きいようです。
間隔・比率尺度データの記述統計
最後に連続型変数,つまり,間隔尺度あるいは比率尺度による測定値の記述統計です。サンプルデータでは「年齢」,「身長」,「体重」の3つがこの型です。「記述統計」の設定画面を閉じ,再び「 探索」から「記述統計」を選択して分析を実行してください。
「年齢」,「身長」,「体重」の3つを変数に移動したら,せっかくなので[統計量]で設定できるさまざまな値を算出してみましょう2。「ばらつき」,「平均値のばらつき」,「分布」,「正規性」にある項目のすべてにチェックを入れてみてください(図4.14)。
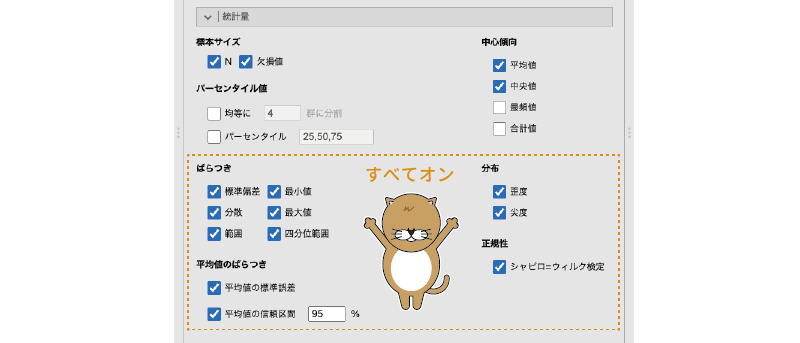
図4.14: 分析の設定
なお,連続型の変数の場合には「度数分布表」のチェックをオンにしても度数分布表は作成されません。度数分布表は,その横のアイコンからわかるように,名義型()と順序型()の変数の場合のみの機能だからです。
設定が終わると,分析結果は図4.15のようになっているはずです。
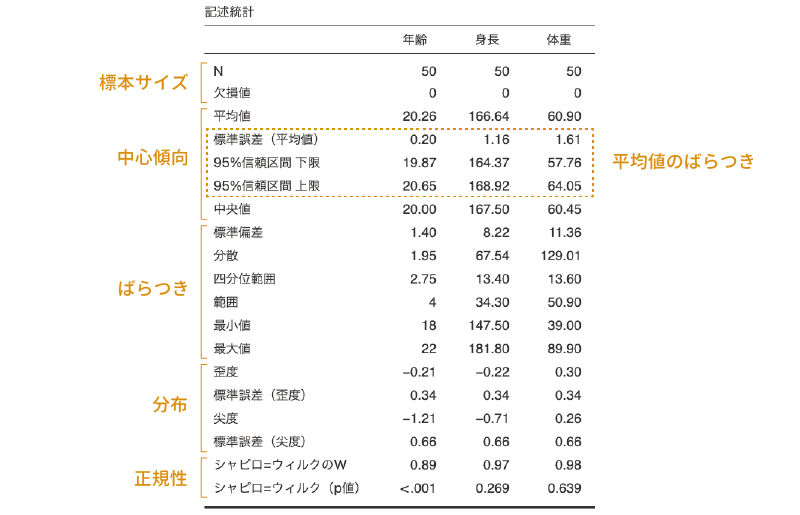
図4.15: 記述統計の結果の表
結果の表には,上から順に標本サイズ,中心傾向,ばらつき,分布,正規性に関する値が示されています。「平均値のばらつき」で設定を行う「平均値の標準誤差」と「95%信頼区間 下限」,「95%信頼区間 上限」の値は,平均値の推定精度に関する指標のため,中心傾向の項目である「平均値」のすぐ下に示されます。
なお,ほとんどの統計ソフトでもそうなのですが,jamoviで算出される分散や標準偏差などのばらつきの指標は,このデータの母集団がもつ値についての推定値であって,データそのものについての値ではありません。そのため,「分散」は,平均値からの偏差2乗の合計を「標本サイズ – 1」で割った,不偏分散の値になっています。また,「標準偏差」には,この不偏分散の正の平方根が用いられていますので,その点は注意してください(図4.16)。
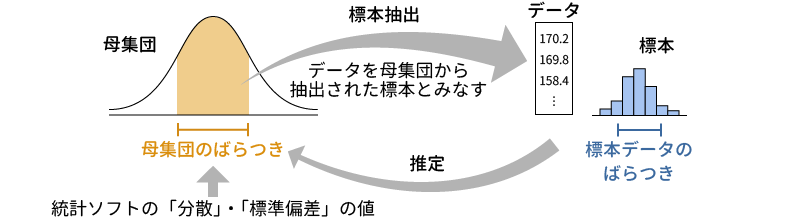
図4.16: 統計ソフトで算出される分散と標準偏差の値
その下の「分布」の項目については,あまり馴染みがないかもしれません。これらは,このデータの分布(標本)から推定される母集団の分布が正規分布からどれだけずれているかを示すものです。心理統計におけるさまざまな分析手法は,その多くがデータの母集団が正規分布であることを前提としていますので,分布に極端な偏りがないことを確認しておくことはとても重要です。この分布の指標は,そうした偏りの程度を数値化したものです(図4.17)。
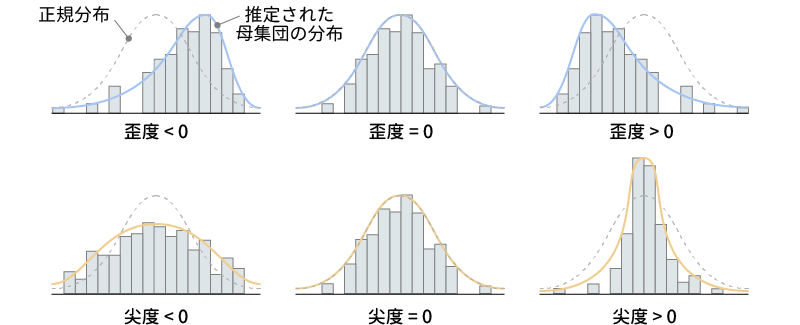
図4.17: 歪度と尖度
このうちの「歪度」は,分布の中心が左右にどれだけ偏っているかを示す値です。歪度がプラスの値の場合には,分布の中心が真ん中より左にずれていることを,マイナスの値の場合には右にずれていることを示します。歪度が「0」の場合には分布の中心が分布全体のちょうど真ん中にあるということです。jamoviでは,この歪度の推定値とその標準誤差が算出されます。一般に,この歪度の絶対値がその標準誤差の2倍以上の大きさである場合,分布が左右にかなり偏っているとみなされます。
もう1つの「尖度」は,分布がどの程度尖った形になっているかを示す値です。分布が尖った形になっているというのは,中心部分に多くの値が集まり,周辺部分には値が少ないことを意味します。反対に,分布が平たい形の場合には,値が全体的に広い範囲に散らばっているということになります。この尖度がプラスの値の場合,その母集団分布は正規分布よりも尖った形に,マイナスの値の場合には,正規分布よりも平たい形になっていることを意味します。この尖度の値についても,推定値と標準誤差が算出され,尖度の絶対値がその標準誤差の2倍以上の大きさである場合,分布の尖り具合に偏りが大きいとみなされます。
一番下の「シャピロ=ウィルク検定」は,このデータの母集団の分布が正規分布から大きくずれているかどうかについての検定です。シャピロ=ウィルク(Shapiro-Wilk)検定では,「母集団分布は正規分布である(母集団の分布と正規分布のずれは0である)」という帰無仮説を用いた統計的仮設検定を実施します。結果の表の「シャピロ=ウィルクのW」は,この検定で算出される検定統計量Wの値で,この値が1であれば正規分布からのずれが0であり,そこから値が小さくなるほど正規分布からのずれが大きいことを意味します。ただし,正規分布からのずれが大きいといえるかどうかの基準は標本サイズ(データの総数)によって異なるため,このWの値だけでは判断が困難です。そこで,「シャピロ=ウィルク(p値)」として,このWの値の有意確率(p値)の算出結果が合わせて示されます。一般に,このp値が有意水準(一般にα=0.05)未満である場合に,母集団の分布が正規分布でないとみなされます。
グループごとの記述統計
ところで,先ほど算出した身長や体重の平均値は,男女を区別せず,すべての測定値を用いて算出されています。ですが,身長や体重というのは男女差が比較的大きいですよね?ですので,平均値や標準偏差などは男女別に算出しておいたほうがよさそうです。その場合,どうすればよいでしょうか。その1つとして,「男性のデータのみ」,「女性のデータのみ」というフィルタ(第2章「フィルタ参照」)を作成し,そのフィルタを結果に適用するという方法が挙げられます。ただ,その場合,男性と女性の結果を同時に見ることはできません。それでは不便ですので,別の方法を用いたほうがよいでしょう。
このような場合,設定画面の「変数」の下にある「グループ変数」を使うと便利です。変数リストから「性別」を選び,それを「グループ変数」に移動しましょう。すると,すべての記述統計量が男女別に算出されます(図4.18)。なお,この「グループ変数」には右下に名義型変数のアイコン()がついていますので,ここに指定できるのは名義の変数だけです。
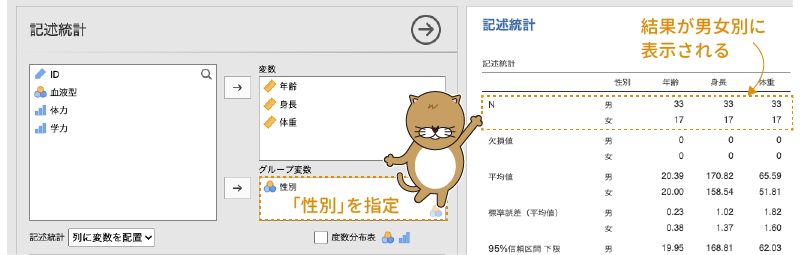
図4.18: グループごとの分析
4.1.2 グラフ
ここまでは「記述統計」を使った記述統計量の算出方法を見てきました。多くの場合,これらの機能だけでも十分ではあるのですが,数値だけではわかりにくい部分もあるので,データの特徴を視覚的に捉えることができるといいですね。jamoviには基本的な作図機能も備わっていますので,今度はデータの視覚化の方法について見ていきましょう。
名義型・順序型データの視覚化
ではまず,名義型()データである血液型の分析結果をグラフ表示してみようと思います。なお,順序型()データの場合も視覚化の手順は同じです。
画面右側の出力ウィンドウから,「血液型」の分析結果を探し,それをクリックしてください。すると,この分析の際に使用した設定画面が表示されます。これもjamoviのおもしろく,かつ便利なところで,jamoviでは一度実行した分析をクリックすれば,いつでもその分析の設定を変更することができるのです。
また,第3章の「分析の修正」のところで見たように,jamoviの分析結果はデータに修正を加えると分析結果も自動的に更新されるようになっています。SPSSなどの統計ソフトでは,一度実行した分析の結果は変更できません。そのため,分析の設定を変更したい場合には,再度分析をやり直すしかありませんし,データに修正が生じた場合も分析をやり直すしかないのですが,jamoviならそうした手間は不要です。
さて,「血液型」の分析画面を開いたら,その下のほうにある![]() | グラフの欄を展開して表示させてください。統計量については変更しませんので,
| グラフの欄を展開して表示させてください。統計量については変更しませんので,![]() | 統計量の部分は畳んで設定項目を非表示にしておくとよいでしょう。
| 統計量の部分は畳んで設定項目を非表示にしておくとよいでしょう。
![]() | グラフには,次の項目が含まれています(図4.19)。
| グラフには,次の項目が含まれています(図4.19)。
図4.19: 作図の設定項目
- ヒストグラム ヒストグラムに関する設定項目です。
- ヒストグラム 度数分布をヒストグラムとして図示します。
- 密度曲線 度数分布をカーネル平滑化した密度曲線グラフを作成します。
- Q-Qプロット 正規Q-Qプロットの設定項目です。
- Q-Qプロット 正規Q-Qプロットを作成します。
- 箱ひげ図 箱ひげ図(ボックスプロット)に関する設定項目です。
- 箱ひげ図 箱ひげ図を作成します。
- バイオリン図 バイオリン図を作成します。
- データ 1つ1つのデータを点として表示します。
- 平均値 箱ひげ図やバイオリン図上に平均値を表示します。
- 棒グラフ 棒グラフに関する設定項目です。
- 棒グラフ 棒グラフを作成します。
これらのうち,名義尺度データで有効なのは「棒グラフ」の項目です。それ以外の項目も使用できなくはないですが,グラフの性質上,意味のある結果は得られません。
「棒グラフ」にある「棒グラフ」のチェックをオンにすると,図4.20のようなグラフが作成されます。
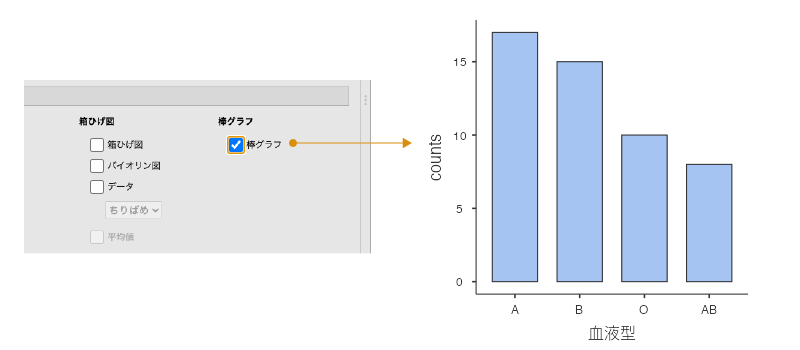
図4.20: 棒グラフ
連続型データの視覚化
今度は連続型( )のデータを視覚化してみましょう。「年齢」,「身長」,「体重」の分析結果をクリックし,これらの変数に関する分析設定画面を表示させてください。連続型のデータでは,
)のデータを視覚化してみましょう。「年齢」,「身長」,「体重」の分析結果をクリックし,これらの変数に関する分析設定画面を表示させてください。連続型のデータでは,![]() | グラフにあるすべての項目が使用可能です。 順番に見ていきましょう。
| グラフにあるすべての項目が使用可能です。 順番に見ていきましょう。
ヒストグラム
「ヒストグラム」には,「ヒストグラム」と「密度曲線」の2つの項目があります。この2つは,組み合わせて使用することもできます。図4.21は,「体重」のヒストグラムと密度曲線,その2つを組み合わせた場合の結果のグラフです。ここでは性別をグループ変数として用いているので,男女別に図が作成されています。
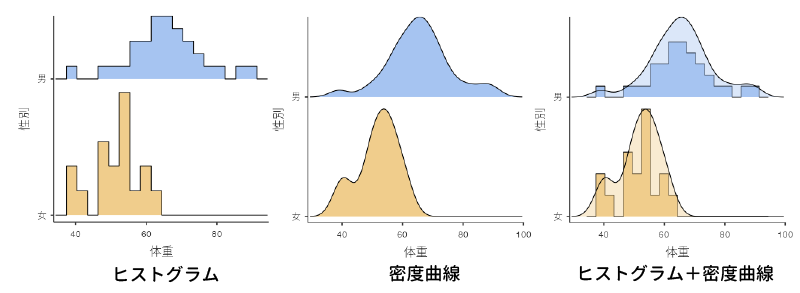
図4.21: ヒストグラム
ヒストグラム
2種類のグラフのうち,ヒストグラムについてはとくに説明は必要ないでしょう。これは度数分布を視覚化する際によく用いられるグラフです。なお,身長や体重のような連続変数で度数を集計する際の測定値の間隔(階級,ビン)は,jamoviでは自動的に設定されます。残念ながら階級の幅を自分で設定することはできませんので,思ったとおりの結果が得られない場合には,ExcelやRなどを用いて自分で作成する必要があります。
密度曲線
2つ目の密度曲線は,カーネル平滑化と呼ばれる手法を用い,度数分布を滑らかな曲線で表現したものです。こうすることによってヒストグラムに見られる細かな凸凹が平滑化され,全体的な傾向を捉えやすくなります。
Q-Qプロット
「Q-Qプロット」にある「Q-Qプロット」の項目では,Q-Qプロットや正規Q-Qプロットと呼ばれる図を作成します(図4.22)。
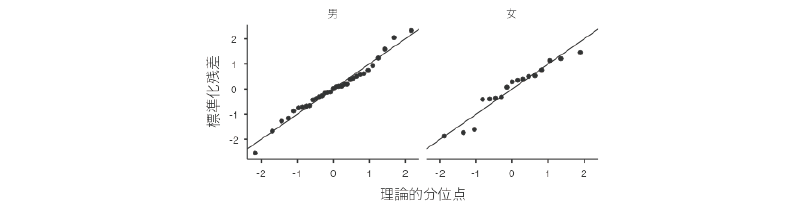
図4.22: 正規Q-Qプロット
これはデータの分布が正規分布になっているかどうかを視覚的に確かめるために用いられるもので,グラフの横軸にはこのデータが正規分布である場合にとると考えられる値,縦軸には実際の測定値(の標準得点)がとられています。このグラフのデータ点が,グラフ中央の直線上に並べばデータが正規分布しているといえ,そこから大きくずれていれば正規分布から外れているということになります。
箱ひげ図
「箱ひげ図」には,箱ひげ図やそれに関連した作図の項目が含まれています。
箱ひげ図
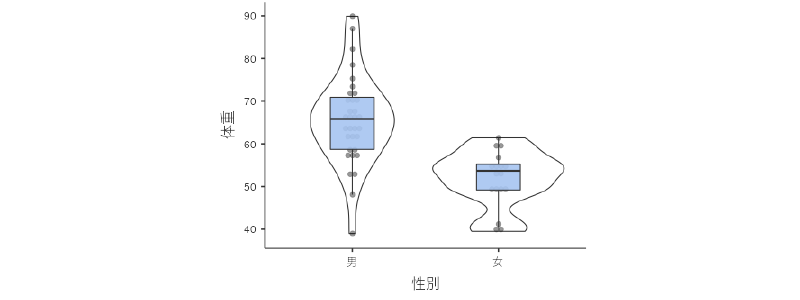
1つ目の「箱ひげ図」は,箱ひげ図(ボックスプロット)と呼ばれるグラフを作成します(図4.23)。箱ひげ図は,中央値と四分位数を用いてデータのばらつきを示すためのグラフで,「箱」の部分には四分位数,「ひげ」の部分には四分位範囲(第3四分位数 – 第1四分位数の幅)の1.5倍の範囲内における最大値および最小値までの幅が示されます。また,それより外の範囲にあるデータは外れ値として点で示されます。
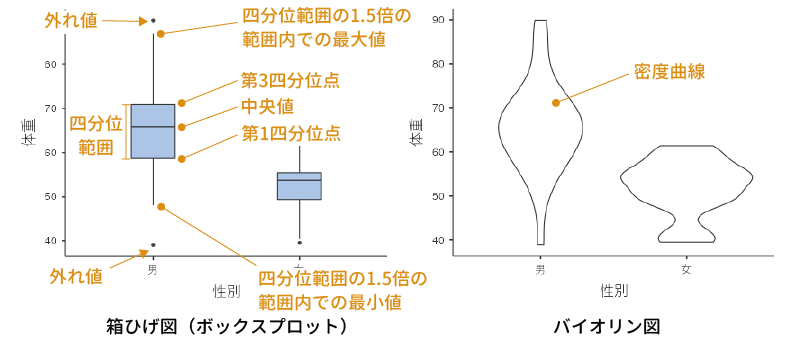
棒グラフ
連続型の変数の場合,「棒グラフ」の「棒グラフ」では平均値の棒グラフが作成されます。このとき,グラフには平均値とその標準誤差が示されます(図4.26)。グラフの誤差線(ひげの部分)は標準偏差ではありませんので,その点は注意してください。
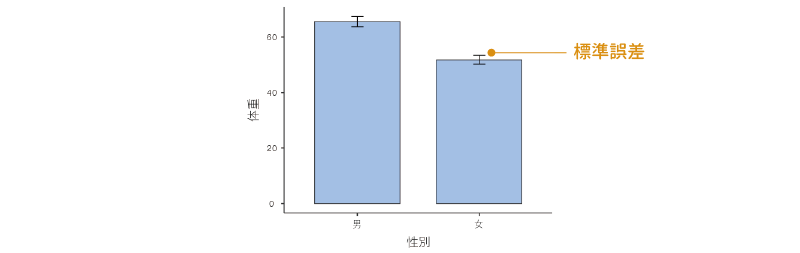
図4.26: 棒グラフ
ここでは説明のためにいろいろな値を算出していますが,実際の分析では必要なものだけを選んで実行してください。↩︎