2.2 データ変数
jamoviが扱う変数には,データ変数,計算変数,変換変数の3種類があります3。このうち,もっとも基本的で重要なものがテータ変数です。ここではまず,データ変数を用いてjamoviにおけるデータの操作方法を見ていきましょう。
データ変数は,調査や実験で得られた測定値(データ値)を格納するための変数で,jamoviにおける分析の基本となるものです。データファイルから読み込んだ値は,すべてデータ変数として扱われます。また,データ変数の値はスプレッドシートに直接入力することもできます。
データファイルからデータを読み込む方法についてはすでに第1章の「ファイル操作」で説明しましたので,ここではデータタブのスプレッドシートを用いたデータの編集方法について見ておきましょう。
2.2.1 スプレッドシートでの入力
スプレッドシートでの入力は,Excelの操作によく似ています。入力したいセル(マス目)をマウスクリックし,キーボードから値を入力するだけです。入力後,「Enter」キーまたは「↓」キーを押すと次の値が入力できるようになります。
基本的に,統計処理をするデータは各行が1人分(あるいは1試行分)の測定値で,各列はさまざまな変数(参加者番号や年齢,性別など)となります。なお,jamoviを起動した直後の画面にはA,B,Cの3つの変数しかありませんが,4列目以降にも値を入力することができます。空白の列に値を入力すると,その列は新たなデータ変数として扱われます。
では,実際にスプレッドシートにデータを入力してみましょう。ここでは表2.1のデータを用いることにします。変数タブが選択されている場合には,データタブを選択してスプレッドシートを表示させてください。
| ID | 性別 | 年齢 | 身長 | 体重 |
|---|---|---|---|---|
| 1 | 男 | 18 | 175 | 70 |
| 2 | 女 | 19 | 158 | 45 |
| 3 | 男 | 19 | 172 | 62 |
スプレッドシートの1列目(Aの列)にIDの値,2列目に性別の値を入力してください。なお,性別については「男」を「1」,「女」を「2」として入力してください。また,3列目から5列目には「年齢」,「身長」,「体重」の値をそれぞれ入力しましょう。変数名は後で設定しますので,ここでは数値を入力するだけです。
入力が終わった状態では,画面は図2.6のようになっているはずです。
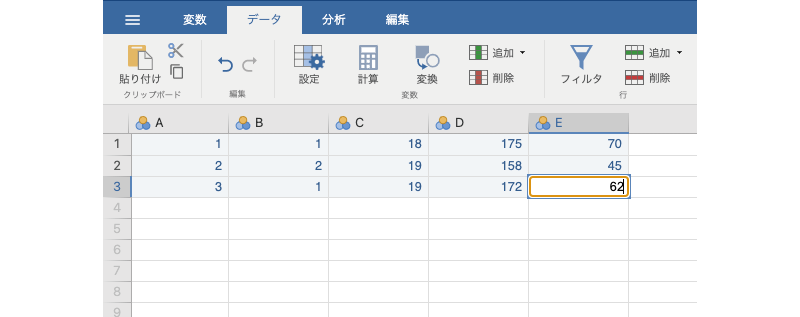
図2.6: データ変数の入力例
このように,jamoviではExcelなどの表計算ソフトを操作する感覚で簡単にデータ入力を行うことができます。
2.2.2 行・列の編集
今度は,入力済みデータを行・列の単位で編集する方法についてみてみましょう。jamoviでは,データの行と列はそれぞれ異なった意味をもちますので,追加・削除のメニューは行と列のそれぞれに別々に用意されています(図2.7)。

図2.7: 行・列の編集
行の編集
基本的に,jamoviではスプレッドシートの行は「参加者1人分のデータ」を意味します。つまり,スプレッドシートに25行のデータが入力されていれば,それは参加者25人分のデータがあるということです。
すでに入力されているデータに新たな参加者のデータを追加する場合は単純で,データがまだ入力されていない行にデータを入力するだけです。そうでなく,途中にデータを追加したい場合には,データを挿入したい部分を選択してリボンの「行」にある「追加」から「挿入」を選択します(図2.8)。
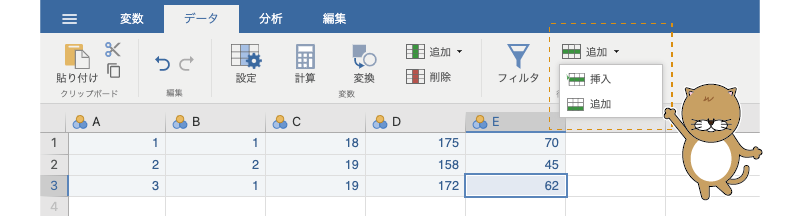
図2.8: 行の追加
なおこの際,「挿入」の代わりに「追加」を実行すると,データの最後に新しい行が追加されます。
また,不要な行がある場合には,その行を選択し,リボンの「行」の部分にある「削除」を実行します(図2.9)。

図2.9: 行の削除
なお,これらの操作は,右クリックで表示されるメニューからも行うことができます(図2.10)。

図2.10: 行の追加
列の編集
jamoviスプレッドシートの列は,変数(回答者番号や年齢,性別,回答値,測定値など)として扱われます。列の編集方法も基本的には行の編集方法と同じで,列(変数)を追加・削除したい箇所を選択してから,データタブの「変数」にある「追加」または「削除」を実行するだけです。
ただし,jamoviが扱う変数には「データ変数」,「計算変数」,「変換変数」の3種類がありますので,変数を追加する際にはどの種類の変数を追加するのかを指定しなければなりません(図2.11)。
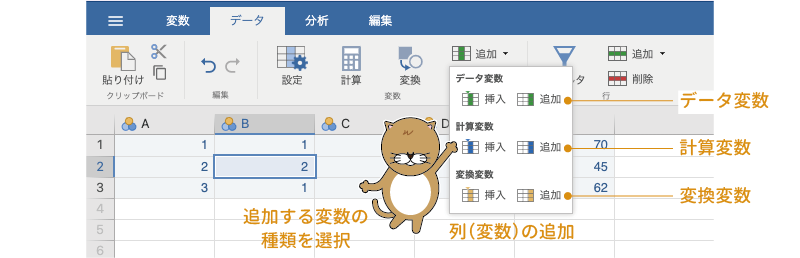
図2.11: 列(変数)の追加
なお,jamoviの現在のバージョンでは,変数の順序を並び替えることができません。変数を追加する場合には,追加する場所をよく考えてからにしましょう。
データ変数の設定
空白のスプレッドシートにデータを入力した場合,そのままでは変数名が「A」,「B」,「C」などになっていて,どの列が何のデータなのかがわかりにくいですね。そこで,先ほど入力したデータを用い,基本的な変数設定の方法を見ておきましょう。
「A」列の変数名の部分(「A」の部分)をダブルクリックするか,または「A」列を選択してからリボンの「 設定」ボタンをクリックしてください(図2.12)。
設定」ボタンをクリックしてください(図2.12)。

図2.12: データ変数の設定画面を開く
すると,データ変数の設定画面が表示されますので(図2.13),この画面の「データ変数」の欄に変数名を入力します。データの1列目には「ID」が入力されているので,変数名は「ID」としておきましょう。
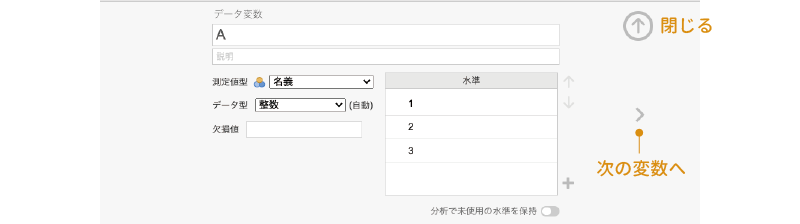
図2.13: データ変数の設定画面
変数名には日本語を使用することも可能です。ただし,グラフなどの一部の機能で日本語がうまく表示されないことがありますので,そうしたトラブルを避けたければ,変数名はアルファベットと数字の組み合わせにしておいた方がいいでしょう。本書では,わかりやすさを重視して変数名に日本を用いることにします。
その下の「説明」の欄は,変数の説明を記入する部分です。この欄は分析には影響しませんので,ここは空欄でも構いません。
1列目の変数名の設定が終わったら,画面右横の「![]() (次へ)」をクリックして2列目以降の変数名も設定しましょう。2列目の変数名は「性別」,3列目以降はそれぞれ「年齢」,「身長」,「体重」としておきます。
(次へ)」をクリックして2列目以降の変数名も設定しましょう。2列目の変数名は「性別」,3列目以降はそれぞれ「年齢」,「身長」,「体重」としておきます。
測定値型
設定画面の「測定値型」は,変数の尺度型の設定です。データ変数には,測定値の尺度水準に応じて次の4つの型があります(図2.14)。
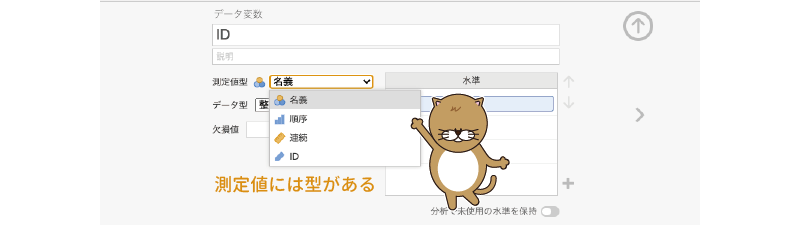
図2.14: データ変数の尺度型
 名義 名義尺度で測定されたデータです。
名義 名義尺度で測定されたデータです。 順序 順序尺度で測定されたデータです。
順序 順序尺度で測定されたデータです。 連続 比率尺度や間隔尺度で測定されたデータです。
連続 比率尺度や間隔尺度で測定されたデータです。 ID 参加者番号など,それぞれのデータを識別するために用いる特殊なデータ型です。
ID 参加者番号など,それぞれのデータを識別するために用いる特殊なデータ型です。
データ変数の尺度型によって使用可能な分析手法が変わってきますので,変数の尺度型は適切に設定しましょう。なお,それぞれの変数がどの尺度型として扱われているのかについては,スプレッドシートの変数名の横にあるアイコンで確認することもできます。
データ1列目のID変数は個人を特定するための番号ですので,尺度タイプは「 ID」型にしておきましょう。2列目の「性別」変数は「 名義」型,「年齢」から「体重」まではすべて「 連続」型です。
Data type:データ型
データ変数には,さらに「整数」,「小数」,「文字」というデータ型の区別もあります。
「整数」型は,「1」や「15」など,測定値に小数値が含まれない場合,「小数」型は,「1.5」や「7.49」など,測定値に小数値が含まれる場合です。この2つのデータ型は画面上の表示方法がやや異なるくらいで本質的な違いはありませんが,「小数」型は尺度型が「連続」の場合にしか指定できません。「文字」型は,入力されたデータ値を「数値」としてではなく「文字」として扱います。「文字」型を指定できるのは,「 名義」型または「 順序」型の場合のみです。
ほとんどの場合,データ型についてはjamoviが自動的に判定してくれますので,設定の必要はないでしょう。何からの理由でデータ型を指定したい場合,データ変数の測定型と指定できるデータ型の関係は表2.2のとおりです。
| 小数 | 整数 | 文字 | |
|---|---|---|---|
| 名義 | × | ○ | ○ |
| 順序 | ○ | ○ | ○ |
| 連続 | ○ | ○ | × |
欠損値
「欠損値」の欄では,データ中の欠損値の指定を行います。たとえば,1〜5の5段階尺度で得られたデータで未回答の部分を「9」として入力したようなデータの場合には,ここで「9」を欠損値として指定することができます。
今回のサンプルデータには欠損値はありませんので,ここは空欄のままにしておいてください。
水準
「水準」は,その変数が「 順序」型あるいは「 名義」型の場合に使用できます。たとえば「S・A・B・C・D」の5段階で入力された成績評価データがあったとします。そしてそのデータでは,1人目が「D」,2人目が「A」,3人目が「S」,4人目が「C」というようなものだったとしましょう。この場合,そのままではこの変数値が「D・A・S・C・B」という順で扱われたり,あるいはアルファベット順に「A・B・C・D・S」という順に扱われたりしてしまいます。なぜなら,統計ソフトには成績のよい方から「S・A・B・C・D」の順であるという知識はないからです。
このような場合には,この「水準」の右横にある上下矢印で変数値を適切な順番に並べ替えることで,分析においても「S・A・B・C・D」という順が維持されるようになります(図2.15)。
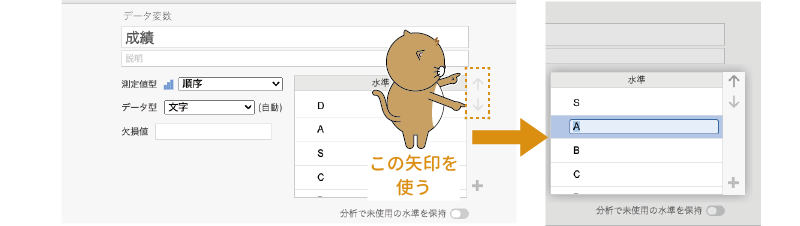
図2.15: データ順序の設定
また,今回のサンプルデータのように,「性別」の値で男性が「1」,女性が「2」と入力されている場合,分析結果の出力画面には性別の値は入力値のまま「1」や「2」と表示されるのですが,「1」や「2」という表示ではどちらが男性でどちらが女性なのかがわかりづらいですね。もし,男女をとり違えて結果を解釈してしまったら大変です。
そのような場合,この「Levels」の「1」の欄に「男」,「2」の欄に「女」と入力し,それぞれの値に変数ラベルをつけることができます。そうすると,データ画面上や結果の表示では性別データの「1」が「男」,「2」が「女」と表示されるようになり,男女のとり違えといったミスを防ぐことができるのです(図2.16)。
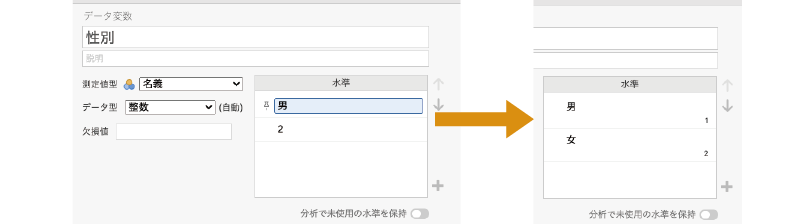
図2.16: 変数ラベルの設定
このようにして変数ラベル設定した場合,本来の変数値は「水準」欄の右下で確認できます。
なお,その下にある「分析で未使用の水準を保持」のスイッチを「オン」にした場合,データの修正などによって特定の水準値を含む行の数が0になった場合にもその水準値が保持されます。ここを「オフ」にした場合には,データ中に含まれていない水準値は「水準」から削除されます。
さて,これでサンプルデータの入力と設定は完了です。変数の設定画面を閉じるとスプレッドシートは図2.17のようになっているはずです。
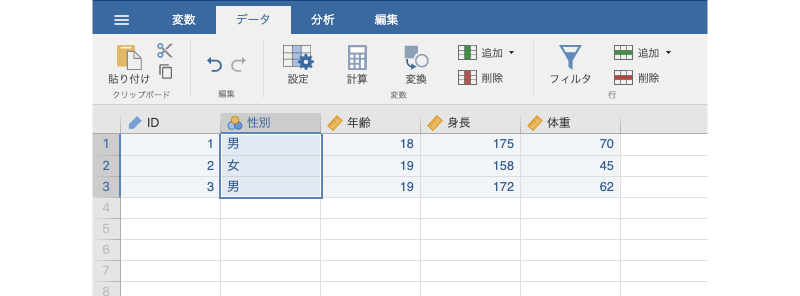
図2.17: データの入力と設定が終わった後の画面
この他に結果変数などもありますが,これらは分析によって自動的に作成されるもので,基本的に編集できません。そのため,ここの説明には含めません。↩︎