26 CIs for mean differences (paired data)
So far, you have learnt to ask a RQ, design a study, classify and summarise the data, and form confidence intervals. In this chapter, you will learn to
- identify situations where estimating a mean difference is appropriate.
- construct confidence intervals for a mean difference.
- determine whether the conditions for using the confidence interval apply in a given situation.
26.1 Introduction: six-minute walk test

The Six-Minute Walk Test (6MWT) measures how far subjects can walk in six minutes, and is used as a simple, low-cost evaluation of fitness and other health-related measures. The recommended setting for the test is usually a walkway of at least \(30\). Saiphoklang, Pugongchai, and Leelasittikul (2022) measured the 6MWT distance when the same subjects each used both \(20\)and \(30\)walkways:
For Thai patients with chronic obstructive pulmonary disease, what is the mean difference between the 6MWT distance when subjects use a \(20\)walkway and a \(30\)walkway?
The comparison is within individuals (Sect. 2.4); this is a repeated-measures study. Each subject has a pair of 6MWT measurements, and the study produced paired data, the topic of this chapter. The data collected to answer this RQ are shown below.
Some differences are negative. This does not mean a negative distance. Since the differences are computed as the \(30\)distance minus the \(20\)distance, a negative difference means the \(20\)distance is a larger value than the \(30\)distance.
26.2 Paired data
The data above are paired. The RQ is a special case of a repeated-measures RQs (Sect. 2.4), where each unit of analysis has two observations. Computing the differences or changes between the pairs of observations makes sense, since the values for each pair belong to the same unit of analysis (the same person, in this case).
Pairing data, when appropriate, is useful because individuals can vary substantially, and pairing means that extraneous variables (potentially, confounding variables) are held constant for those paired observations. For example, each pair of distances recorded in the data above come from same person, so sex and age remains the same for both observations in the pair. Pairing is a form of blocking (Sect. 7.2).
Pairing does not require the same person to be measured twice (as in this study); it is also a good design strategy when the individuals in the pair are very similar for many extraneous variables. (For example, the pair may comprise two different people, of the same sex, with similar age, height and weight.)
Definition 26.1 (Paired data) Paired data occurs when the outcome is compared for two different, distinct situations for each unit of analysis.
Paired studies appear in many situations:
- Height is measured for each twin in a pair (the twin-pair is the 'individual'). Pairing the heights for each twin is reasonable given the shared genetics (and probably environments also). The difference between the height of the twins can be recorded for each pair.
- The body temperature of dogs (the 'individuals') is measured using both rectal and ear thermometers. The difference between the two recorded temperatures from the thermometers for each dog is recorded.
- Blood pressure is recorded from some individuals (Group A) after receiving Drug A, and from another group of individuals (Group B) after receiving Drug B. Each person in Group A is matched with someone in Group B of the same sex, similar age and similar weight (e.g., in one of the pairs, each individual is a male, about \(30\) years-of-age, and about \(180\)tall). The difference between the blood pressure for the individual in Group A and the matched person in Group B is recorded for each pair.
- The number of campers is recorded at many national parks (the 'individuals') on the first weekend in summer, and on the first weekend on winter. The difference in camper numbers for each national park between these time points is recorded.
Many of these examples can be extended to beyond two measurements. For instance, temperatures can be compared on each dog using three different types of thermometers. We only study pairs of measurements, and only for quantitative variable.
26.3 Summarising the data
For the 6MWT study, the distance is measured for the same subjects for two different walkway distances. Each subject receives two measurements, and the difference between the distances walked for each individual is computed
Since the data are paired, an appropriate graph is a histogram of the differences (Chap. 14); specifically, \(30\)distance minus the \(20\)distance. A boxplot comparing 6MWT distance for both walkway lengths (that is, not pairing the data) shows the distribution of distances, and the median distances, are very similar (Fig. 26.1, left panel). Any difference in individuals' 6MWT distances is difficult to see and detect. In addition, the link between the two 6MWT distances for each individual has been lost.
Using a histogram of the differences makes the difference in the distances for the individuals easier to see (Fig. 26.1, right panel). The histogram also makes it easy to see that some subjects walked further with a \(20\)walkway, and some further for a \(30\)walkway. Individually graphing the 6MWT for both walkway distances may also be useful too, but a graph of the differences is crucial, as the RQ is about those differences. A case-profile plot (Sect. 14.3.2) is also appropriate, but is difficult to read for these data because size of the sample is too large (a line is needed for each of the \(50\) units of analysis).
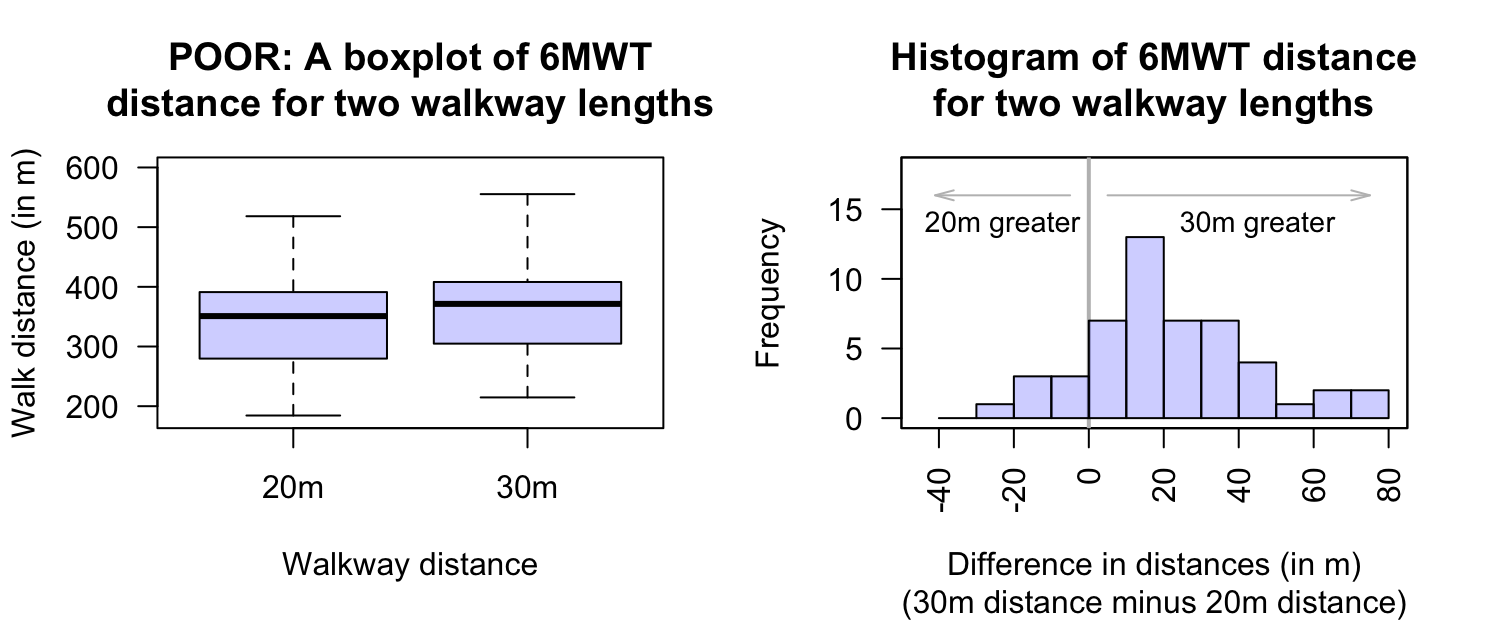
FIGURE 26.1: Plots of the 6MWT data. Left: graphing the data incorrectly as not paired. Right: a histogram of 6MWT distances changes (\(30\)walkway distance minus \(20\)walkway distance; the vertical grey line represents no change in distance).
The 6MWT distances for each walkway length can be summarised individually (the first two rows of Table 26.1) using the methods of Chap. 24, or using software (Fig. 26.2). All statistics are slightly different for the two walkway distances; in particular, the mean \(30\)walkway distance is slightly larger. However, since the RQ is about the difference between the distances, a numerical summary of the differences is essential (third row of Table 26.1, using Fig. 26.4).
| Mean | Median | Standard deviation | Standard error | |
|---|---|---|---|---|
| 20m walkway 6MWT distance (in m) | \(337.82\) | \(351.0\) | \(71.801\) | \(10.154\) |
| 30m walkway 6MWT distance (in m) | \(359.85\) | \(371.4\) | \(77.250\) | \(10.925\) |
| Difference (in m) | \(\phantom{0}22.03\) | \(\phantom{0}17.0\) | \(22.039\) | \(\phantom{0}3.117\) |
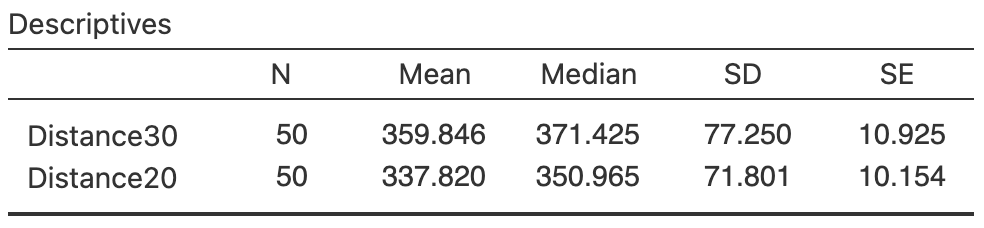
FIGURE 26.2: The 6MWT data: numerical summary software output for each group.
26.4 Confidence intervals for \(\mu_d\)
Every possible sample of \(n = 50\) subjects comprises different people, and hence produces different 6MWT distances for \(20\)and \(30\)walkways. For this reason, the 6MWT distance summaries in Table 26.1 include standard errors. Since the 6MWT distance varies from sample to sample for each person, the difference between the distances for each person varies from sample to sample too, and also have a sampling distribution.
The differences (i.e., the Diff. column in the data given in Sect. 26.1) can be treated like a single sample of data (Chap. 24). Hence, the sampling distribution for the differences has a similar sampling distribution to that of \(\bar{x}\). In addition, the notation when working with paired data is similar to that used when working with the single-mean case too (Table 26.2).
Definition 26.2 (Sampling distribution of a sample mean difference) The sampling distribution of a sample mean difference is (when certain conditions are met; Sect. 26.5) described by:
- an approximate normal distribution,
- centred around the sampling mean whose value is the population mean difference \(\mu_d\),
- with a standard deviation, called the standard error of the difference, of \(\displaystyle\text{s.e.}(\bar{d}) = \frac{s_d}{\sqrt{n_d}}\),
where \(n\) is the number of differences, and \(s_d\) is the standard deviation of the individual differences in the sample.
A mean or a median may be appropriate for describing the differences. However, the sampling distribution for the sample mean difference (under certain conditions) has a normal distribution. Hence, the mean is appropriate for describing the sampling distribution, even if not for describing the data.
| One sample mean | Mean difference | |
|---|---|---|
| The observations: | Values: \(x\) | Differences: \(d\) |
| Sample mean: | \(\bar{x}\) | \(\bar{d}\) |
| Standard deviation: | \(s\) | \(s_d\) |
| Standard error of \(\bar{x}\): | \(\displaystyle\text{s.e.}(\bar{x}) = \frac{s}{\sqrt{n}}\) | \(\displaystyle\text{s.e.}(\bar{d}) = \frac{s_d}{\sqrt{n}}\) |
| Sample size: | Number of observations: \(n\) | Number of differences: \(n\) |
| Confidence interval: | \(\bar{x}\pm\big(\text{multiplier}\times \text{s.e.}(\bar{x})\big)\) | \(\bar{d}\pm\big(\text{multiplier}\times \text{s.e.}(\bar{d})\big)\) |
For the 6MWT data, the sample mean differences \(\bar{d}\) are described by (Fig. 26.3):
- approximate normal distribution,
- with a sampling mean whose value is \(\mu_{{d}}\),
- with a standard error of \[ \text{s.e.}(\bar{d}) = \frac{22.039}{\sqrt{50}} = 3.117. \]
The summary information for the difference in 6MWT distance can be added to the summary table (the third row of Table 26.1), after appropriate rounding. Notice that the standard deviation of the difference is not the difference between the standard deviations for the \(20\)and \(30\)distances. Instead, the standard deviation of the differences (i.e., the column Diff. in the data given in Sect. 26.1) is computed. (Likewise, the standard error and the median are computed from the values in the Diff. column also.)
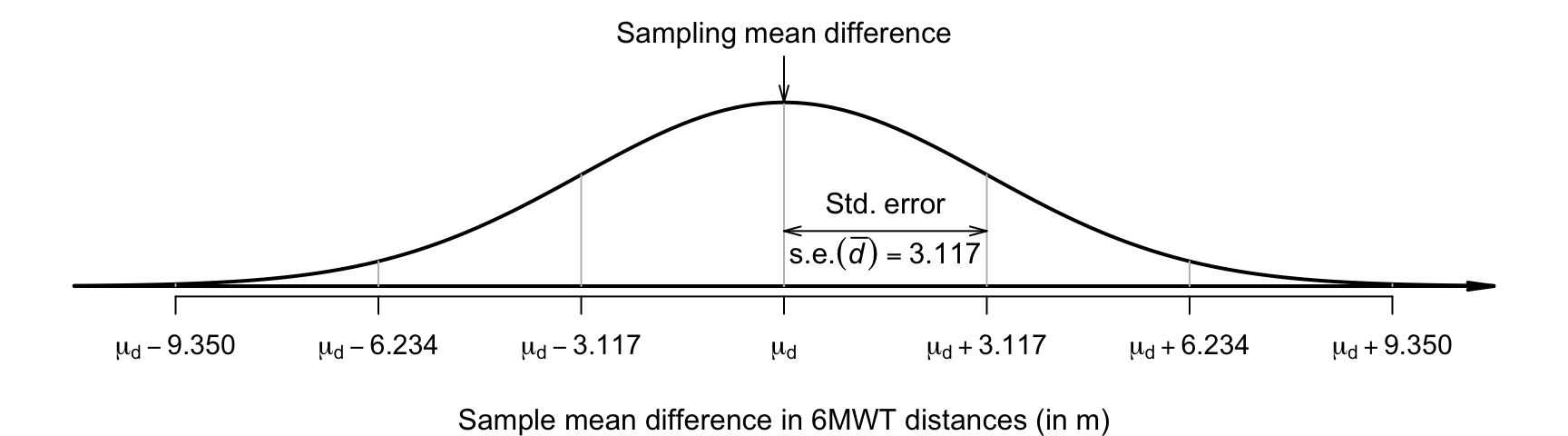
FIGURE 26.3: The sampling distribution is a normal distribution; it describes how the sample mean difference between the 6MWT distances varies in samples of size \(n = 50\).
The CI for the mean difference has the same form as for a single mean (Chap. 24). The \(95\)% confidence interval (CI) for \(\mu_d\) is \[ \bar{d} \pm (\text{multiplier} \times\text{s.e.}(\bar{d})). \] As usual, for an approximate \(95\)% confidence interval (CI), the approximate multiplier is \(2\) (from the \(68\)--\(95\)--\(99.7\) rule). This is the same as the CI for \(\bar{x}\) if the differences are treated as the data.
For the 6MWT data: \[ 22.03 \pm (2 \times 3.117), \] or \(22.03\pm 6.234\)(so the margin of error is \(6.234\)). Equivalently, the CI is from \(22.03 - 6.234 = 15.796\), up to \(22.03 + 6.234 = 28.264\). We write:
The mean difference in the 6MWT distances when using a \(20\)and \(30\)walkway is \(22.03\)(\(\text{s.e.} = 3.117\); \(n = 50\)), with an approximate \(95\)% CI from \(15.80\)to \(28.26\), further for a \(30\)walkway.
The CI means that the reasonable values for the population mean difference in 6MTW distances are between \(15.80\)and \(28.26\). Alternatively, we are \(95\)% confident that the population mean difference between the 6MWT distances is between \(15.80\)and \(28.26\)(further for \(30\)walkway). A difference of this magnitude probably has practical importance. Also notice that the direction of the difference is given: 'further for \(30\)walkway'.
Statistical software produces exact \(95\)% CIs, which may be slightly different than the approximate \(95\)% CI (recall: the \(68\)--\(95\)--\(99.7\) rule gives approximate multipliers). For the 6MWT data, the approximate and exact \(95\)% CIs are the same to one decimal place (Fig. 26.4). We write:
The mean difference in the 6MWT distances when using a \(20\)and \(30\)walkway is \(22.03\)(\(\text{s.e.} = 3.117\); \(n = 50\)), with an \(95\)% CI from \(15.76\)to \(28.29\)further for a \(30\)walkway.

FIGURE 26.4: The 6MWT data: software output.
26.5 Statistical validity conditions
As with any confidence interval, these results apply under certain conditions. The conditions under which the CI is statistically valid for paired data are similar to those for one sample mean, rephrased for differences.
Statistical validity can be assessed using these criteria:
- When \(n \ge 25\), the CI is statistically valid. (If the distribution of the differences is highly skewed, the sample size may need to be larger.)
- When \(n < 25\), the CI is statistically valid only if the data come from a population of differences with a normal distribution.
The sample size of \(25\) is a rough figure; some books give other values (such as \(30\)).
This condition ensures that the distribution of the sample means has an approximate normal distribution (so that, for example, the \(68\)--\(95\)--\(99.7\) rule can be used). Provided the sample size is larger than about \(25\), this will be approximately true even if the distribution of the differences in the population does not have a normal distribution. That is, when \(n \ge 25\) the sample means generally have an approximate normal distribution, even if the data themselves don't have a normal distribution. The units of analysis are also assumed to be independent (e.g., from a simple random sample).
If the statistical validity conditions are not met, other methods (e.g., non-parametric methods (Conover 2003); resampling methods (Efron and Hastie 2021)) may be used. For paired qualitative data, McNemar's test can be used (Conover 2003).
Example 26.1 (Statistical validity) For the 6MWT data, the sample size is \(n = 50\), so the results are statistically valid. Neither the differences in the population, nor the distances in the population for each walkway length, need to follow a normal distribution.
26.6 Example: invasive plants
Skypilot is a alpine wildflower native to the Colorado Rocky Mountains (USA). In recent years, a willow shrub has been encroaching on skypilot territory and, because willow often flowers early, Kettenbach et al. (2017) studied whether the willow may 'negatively affect pollination regimes of resident alpine wildflower species' (p. 6 965). One RQ was:
In the Colorado Rocky Mountains, what is the mean difference between first-flowering day for the native skypilot and the encroaching willow?
Data for both species was collected at \(n = 25\) different sites, so the data are paired by site (Sect. 14.4). The unit of analysis is the site, and the unit of observation is the plant. The data are shown in the table below. The 'first-flowering day' is the number of days since the start of the year (e.g., January \(12\) is 'day \(12\)') when flowers were first observed.
The parameter is \(\mu_d\), the population mean difference between the day of first flowering for skypilot, less the day of first flowering for willow. Hence, a positive value for the difference means that the skypilot values are larger, and hence that willow flowered first.
Explaining how the differences are computed is important. The differences here are skypilot minus willow first-flowering days. Positive values mean willow flowered first; negative values mean skypilot flowered first.
The data are summarised graphically (Fig. 14.4) and numerically (Table 14.4), using software output (Fig. 14.3).
The standard error of the mean difference is \(\text{s.e.}(\bar{d}) = 0.940\) (Fig. 14.3; Table 14.4). The approximate \(95\)% CI is \(1.36 \pm (2\times 0.940)\), or from \(-0.52\) to \(3.24\) days. Software output (Fig. 14.3) gives the \(95\)% CI as \(-0.58\) to \(3.30\) days. Remembering that positive differences mean willow flowers earlier, we write (using the exact CI):
The mean difference in the day of first flowering is \(1.36\) days earlier for the willow (\(\text{s.e.} = 0.940\); \(n = 25\)), with an approximate \(95\)% CI between \(0.52\) days earlier for skypilot to \(3.24\) days earlier for willow.
The CI is statistically valid since \(n = 25\).
Be clear in your conclusion about how the differences are computed. Make sure to interpret the CI consistent with how the differences are defined.
26.7 Example: chamomile tea
Rafraf, Zemestani, and Asghari-Jafarabadi (2015) studied patients with Type 2 diabetes mellitus (T2DM). They randomly allocated \(32\) patients into a control group (who drank hot water), and another \(32\) patients to receive chamomile tea (p. 164):
The study was blinded so that the allocation of the intervention or control group was concealed from the researchers and statistician [...] The intervention group (\(n = 32\)) consumed one cup of chamomile tea [...] three times a day immediately after meals (breakfast, lunch, and dinner) for \(8\) weeks. The control group (\(n = 32\)) consumed an equivalent volume of warm water during the \(8\)-week period...
The total glucose (TG) was measured for each individual both before the intervention and after eight weeks on the intervention, in both the control and treatment groups. The data are not available, so no graphical summary of the data can be produced; however, the article gives a data summary (motivating Table 26.3). The following RQs can be asked:
- For patients with T2DM, what is the mean reduction in TG after eight weeks drinking chamomile tea?
- For patients with T2DM, what is the mean reduction in TG after eight weeks drinking hot water?
For the tea group, the standard error of the reduction in TG is \(\text{s.e.}(\bar{d}) = 30.37/\sqrt{32} = 5.37\). For the control group, the standard error of the reduction in TG is \(\text{s.e.}(\bar{d}) = 36.66/\sqrt{32} = 6.48\). Thus, the approximate \(95\)% CI for the reduction in TG is:
- \(38.62\pm (2\times 5.37)\), or from \(27.88\) to \(49.36\) mg.dl\(^{-1}\).
- \(-7.12\pm (2\times 6.48)\), or from \(-20.08\) to \(5.84\) mg.dl\(^{-1}\).
(A negative reduction in TG means an increase in TG.) The chamomile tea appears to reduce TG, but not the hot water. Is the difference between the two treatments due to sampling variation? This question is studied further in Sect. 33.7.
| \(n\) | Mean | Std. dev. | Mean | Std. dev. | Mean | Std. dev. | Std. error | |
|---|---|---|---|---|---|---|---|---|
| Chamomile tea | \(32\) | \(203.00\) | \(54.96\) | \(164.37\) | \(50.70\) | \(38.62\) | \(30.37\) | \(\phantom{0}5.37\) |
| Control | \(32\) | \(178.25\) | \(53.06\) | \(185.37\) | \(52.59\) | \(-7.12\) | \(36.66\) | \(\phantom{0}6.48\) |
| Difference | \(\phantom{0}24.75\) | \(\phantom{0}21.00\) | \(45.74\) |
We write:
The mean reduction in TG for those drinking chamomile tea is \(38.62\).dl\(-1\) (approx. \(95\)% CI: \(27.88\) to \(49.36\).dl\(-1\)), and \(-7.12\).dl\(-1\) for those drinking hot water (approx. \(95\)% CI: \(-20.08\) and \(-5.84\).dl\(-1\)).
The intervals have a \(95\)% chance of straddling the population mean reduction in TG. The sample sizes are larger than \(25\), so the results are statistically valid.
26.8 Chapter summary
To compute a confidence interval (CI) for a mean difference, compute the sample mean difference, \(\bar{d}\), and identify the sample size \(n\). Then compute the standard error, which quantifies how much the value of \(\bar{d}\) varies across all possible samples: \[ \text{s.e.}(\bar{d}) = \frac{ s_d }{\sqrt{n}}, \] where \(s_d\) is the sample standard deviation. The margin of error is (multiplier\({}\times{}\)standard error), where the multiplier is \(2\) for an approximate \(95\)% CI (using the \(68\)--\(95\)--\(99.7\) rule). Then the CI is: \[ \bar{d} \pm \left( \text{multiplier}\times\text{standard error} \right). \] The statistical validity conditions should also be checked.
26.9 Quick review questions
Are the following statements true or false?
- For paired data, the mean of the differences is treated like the mean of a single variable when computing a CI.
- An appropriate graph for displaying paired data is a histogram of the differences.
- The population mean difference is denoted \(\mu_d\).
- The standard error of the sample mean difference is denoted \(s_d\).
26.10 Exercises
Answers to odd-numbered exercises are available in App. E.
Exercise 26.1 Which (if any) of these scenarios are paired?
- Heart rate is measured for each individual when sitting and when standing. (Some individuals have their heart rate recorded first while sitting, and some first while standing.) Each person receives two measurements, and the difference in heart rate between sitting and standing is recorded.
- The mean protein concentrations were compared in sea turtles before and after being rehabilitated (March et al. 2018).
Exercise 26.2 Which (if any) of these scenarios are paired?
- The mean HDL cholesterol concentration is recorded for a group of males and a group of females, and the means compared.
- Heart rate was recorded for \(36\) people, both before and after exercise, to determine how much the average heart rate increase.
Exercise 26.3 [Dataset: Fruit]
Mukherjee, Deb, and Devy (2019) studied the effect of rainfall on growing Chayote squash (Sechium edule).
They compared the size of the fruit in a year with normal rainfall (2015) compared to a dry year (2014) on the same \(24\) farms:
For Chayote squash grown in Bangalore, what is the mean difference in fruit weight between a normal and dry year?
Ten fruits were gathered from each farm in both years, and the average (mean) weight of the fruit recorded for the farm. Since the same farms are used in both years, the data are paired (see above). Data is missing for Farm 20 in the dry year (2014), so there are \(n = 23\) differences.
| Farm | Dry | Normal | Change (in g) |
|---|---|---|---|
| \(\phantom{0}1\) | \(367.75\) | \(371.05\) | \(\phantom{-}\phantom{0}\phantom{0}3.30\) |
| \(\phantom{0}2\) | \(238.25\) | \(218.85\) | \(-19.40\) |
| \(\phantom{0}3\) | \(271.25\) | \(217.55\) | \(-53.70\) |
| \(\phantom{0}4\) | \(286.27\) | \(221.70\) | \(-64.57\) |
| \(\phantom{0}5\) | \(259.20\) | \(268.95\) | \(\phantom{-}\phantom{0}\phantom{0}9.75\) |
| \(\phantom{0}6\) | \(196.23\) | \(194.85\) | \(\phantom{0}-1.38\) |
| \(\phantom{0}7\) | \(283.70\) | \(293.00\) | \(\phantom{-}\phantom{0}\phantom{0}9.30\) |
| \(\phantom{0}8\) | \(252.05\) | \(264.15\) | \(\phantom{-}\phantom{0}12.10\) |
| \(\phantom{0}9\) | \(253.70\) | \(218.45\) | \(-35.25\) |
| \(10\) | \(279.80\) | \(225.40\) | \(-54.40\) |
| \(11\) | \(206.05\) | \(225.90\) | \(\phantom{-}\phantom{0}19.85\) |
| \(12\) | \(222.00\) | \(222.85\) | \(\phantom{-}\phantom{0}\phantom{0}0.85\) |
| \(13\) | \(285.50\) | \(282.25\) | \(\phantom{0}-3.25\) |
| \(14\) | \(171.50\) | \(266.00\) | \(\phantom{-}\phantom{0}94.50\) |
| \(15\) | \(186.75\) | \(206.20\) | \(\phantom{-}\phantom{0}19.45\) |
| \(16\) | \(219.55\) | \(194.60\) | \(-24.95\) |
| \(17\) | \(198.15\) | \(346.75\) | \(\phantom{-}148.60\) |
| \(18\) | \(248.10\) | \(304.55\) | \(\phantom{-}\phantom{0}56.45\) |
| \(19\) | \(231.55\) | \(263.20\) | \(\phantom{-}\phantom{0}31.65\) |
| \(20\) | \(223.70\) | ||
| \(21\) | \(257.50\) | \(258.75\) | \(\phantom{-}\phantom{0}\phantom{0}1.25\) |
| \(22\) | \(230.70\) | \(248.95\) | \(\phantom{-}\phantom{0}18.25\) |
| \(23\) | \(260.50\) | \(155.95\) | \(-104.55\) |
| \(24\) | \(231.85\) | \(219.30\) | \(-12.55\) |
- What is the unit of analysis? What is the units of observation?
- Create a numerical summary table for the data (use Fig. 26.5).
- Create a suitable graph to display the data.
- Construct an approximate \(95\)% CI for the mean difference in fruit weight.
- Is this CI statistically valid?
- What is the advantage of using the same \(24\) farms twice each?
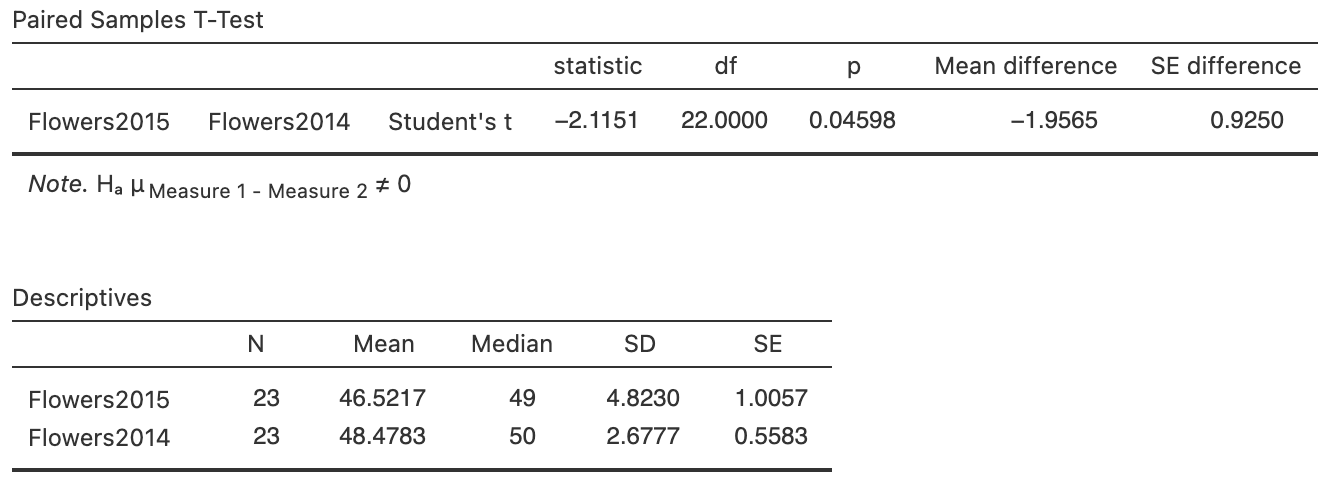
FIGURE 26.5: Software output for the fruit data.
Exercise 26.4 [Dataset: Captopril]
MacGregor et al. (1979) studied of hypertension for \(15\) patients.
Patients were given a drug (Captopril) and their systolic blood pressure measured (in mm Hg) immediately before and two hours after being given the drug (Table 14.6; Hand et al. (1996)).
- Explain why it is sensible to compute differences as the Before minus the After measurements. What do the differences mean when computed this way?
- Compute an approximate \(95\)% CI for the mean difference.
- Write down the exact \(95\)% CI using the computer output (Fig. 26.6).
- Is this CI statistically valid?
- Why are the two CIs different?
- What is the advantage of using the same patients for both the before and after measurements, rather than one group for before measurements and a different group of people for after measurements?
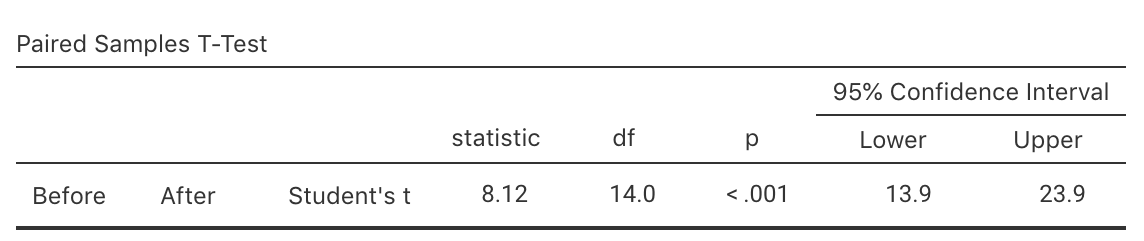
FIGURE 26.6: Software output for the Captopril data.
Exercise 26.5 People often struggle to eat the recommended intake of vegetables. Fritts et al. (2018) explored ways to increase vegetable intake in teens. Teens rated the taste of raw broccoli, and raw broccoli served with a specially-made dip.
Each teen (\(n = 100\)) had a pair of measurements: the taste rating of the broccoli with and without dip. Taste was assessed using a 'visual analog scale', where a higher score means a better taste. In summary:
- For raw broccoli, the mean taste rating was \(56.0\) (with \(s = 26.6\));
- For raw broccoli served with dip, the mean taste rating was \(61.2\) (with \(s = 28.7\)).
Because the data are paired, differences are the best way to describe the data. The mean difference in the ratings was \(5.2\), with \(\text{s.e.}(\bar{d}) = 3.06\). From this information:
- Construct a suitable numerical summary table.
- Compute the approximate \(95\)% CI for the mean difference in taste ratings.
- Is this CI statistically valid?
- What does a positive difference mean?
Exercise 26.6 Allen et al. (2018) examined the effect of exercise on smoking. Men and women were assessed on their 'intention to smoke', both before and after exercise for each subject (using two quantitative questionnaires). Smokers ('smoking at least five cigarettes per day') aged \(18\) to \(40\) were enrolled for the study. For the \(23\) women in the study, the mean intention to smoke after exercise reduced by \(0.66\) (with a standard error of \(0.37\)). (Larger values for 'intention to smoke' mean a greater intent to smoke.)
- Find an approximate \(95\)% confidence interval for the population mean reduction in intention to smoke for women after exercising.
- Is this CI statistically valid?
- What does a positive difference mean?
Exercise 26.7 [Dataset: Anorexia]
Young girls with anorexia (\(n = 29\)) received cognitive behavioural treatment (Hand et al. (1996)), and their weight before and after treatment were recorded.
In summary:
- Before the treatment, the mean weight was \(82.69\) pounds (\(s = 4.845\) pounds);
- After the treatment, the mean weight was \(85.70\) pounds (\(s = 8.352\) pounds).
The mean weight gain per girls was \(3.01\) pounds, with a standard deviation of \(7.31\) pounds Find an approximate \(95\)% CI for the population mean weight gain. Do you think the treatment had any meaningful impact on the mean weight gain of the girls, based solely on these data?
Exercise 26.8 [Dataset: Stress]
The concentration of beta-endorphins in the blood is a sign of stress.
Hoaglin, Mosteller, and Tukey (2011) measured the beta-endorphin concentration for \(19\) patients about to undergo surgery (Hand et al. 1996).
Each patient had their beta-endorphin concentrations (in fmol.mol\(-1\)) measured \(12\)--\(14\) hours before surgery, and also \(10\) minutes before surgery.
A numerical summary appears in Table 14.8.
- Use the software output in Fig. 26.7 to construct an approximate \(95\)% CI for the increase in beta-endorphin concentrations as surgery gets closer.
- Use the software output in Fig. 26.7 to write down the exact \(95\)% CI for the increase in beta-endorphin concentrations as surgery gets closer.
- Why is there a difference between the two CIs?
- Is the CI statistically valid?
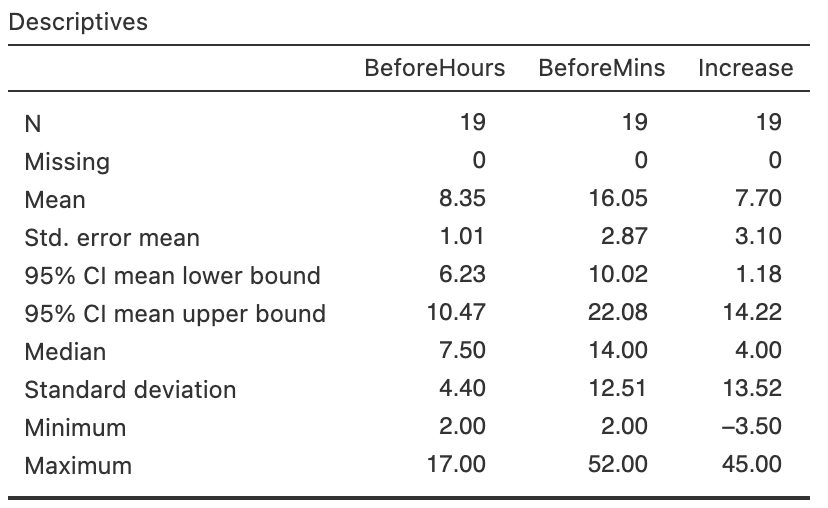
FIGURE 26.7: Software output for the surgery-stress data.
Exercise 26.9 Suppose, in the example of Sect. 26.6, the differences were defined as the day of first flowering for willow, less the day of first flowering for skypilot.
Write down, and interpret the meaning of, the confidence interval for the mean difference in first-flowering times.
Exercise 26.10 Suppose, in the example of Sect. 26.7, the differences were defined as increase in total glucose (TG).
Write down, and interpret the meaning of, the confidence interval for the mean increase in TG for the tea-drinking group.
Exercise 26.11 A study of \(n = 213\) Spanish health students (Romero-Blanco et al. 2020) measured (among other things) the number of minutes of vigorous physical activity (PA) performed by students before and during the COVID-19 lockdown (from March to April 2020 in Spain). Since the before and during lockdown were both measured on each participant, the data are paired. The data are summarised in Table 14.9.
- Explain what the differences mean.
- Compute the standard error of the differences.
- Compute the approximate \(95\)% CI, and interpret what it means.
Exercise 26.12 What happens to students' eating habits when they start university? Many students will be responsible for their own meals for the first time, so some may forgo healthy foods for convenient, but less healthy, foods. Alternatively, some may not be able to afford sufficient or healthy food.
D. A. Levitsky, Halbmaier, and Mrdjenovic (2004) recorded some students' weights as they began university, and then the same students' weight some later time. They asked the RQ:
For Cornell University students, what is the mean weight change in students after \(12\) weeks at university?
The data collected to answer this RQ are shown below (D. Levitsky, n.d.).
- Use the software output (Fig. 26.8) to compute an approximate \(95\)% CI for the weight gain from Weeks \(1\) to \(12\).
- Use the software output to compute a \(95\)% CI for the weight gain from Weeks \(1\) to \(12\).
- Comment on the two CIs.
- Are the CIs statistically valid?
- Write down the (exact) \(95\)% CI for the weight loss from Weeks \(1\) to \(12\).
- Do you think the weight gain would be of practical importance?
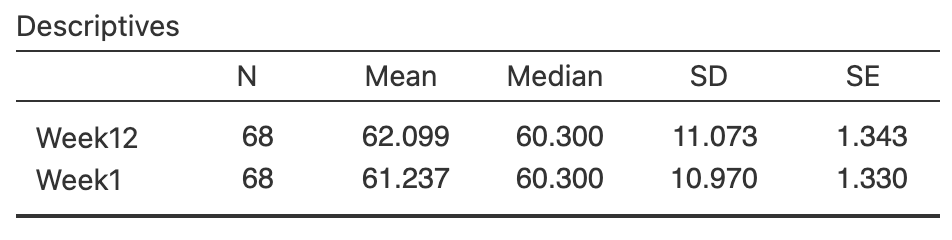

FIGURE 26.8: The weight-gain data: software output.