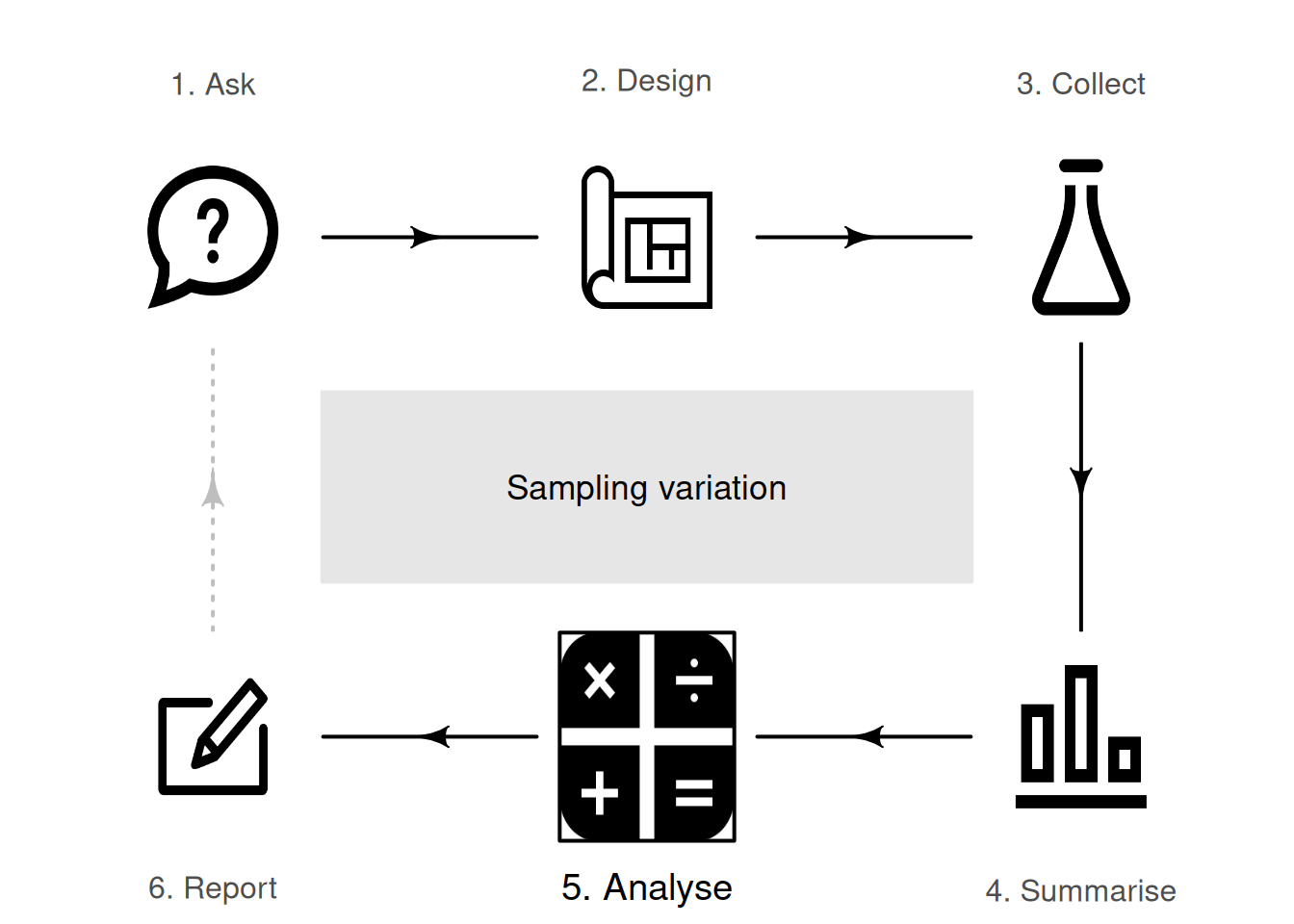
19 Sampling variation
So far, you have learnt to ask an RQ, design a study, describe and summarise the data, and understand propbability. In this chapter, you will learn to:
- explain what a sampling distribution describes.
- explain the difference between the variation between individuals and the variation in statistics.
- determine when a standard error is appropriate to use.
- explain the difference between standard errors and standard deviations.
19.1 Introduction
One of the most important ideas in research and statistics is that the sample being studied is only one of countless possible samples that could have been selected to study.
Studying a sample leads to the following observations:
- every sample is likely to be different.
- we observe just one of the many possible samples.
- every sample is likely to yield a different value for the statistic (i.e., a different estimate for the parameter).
- we observe just one of the many possible values for the statistic.
Since many values for the statistic are possible, the values of the statistic vary and have a distribution.
In research, decisions need to be made about populations based on samples; that is, about parameters based on statistics. The challenge is that the decision must be made using only one of the many possible samples, and every sample is likely to be different. Each sample will produce a different value for the statistic. This is called sampling variation.
Definition 19.1 (Sampling variation) Sampling variation refers to how the sample estimates (statistics) vary from sample to sample, because every possible sample is different.
Any distribution that describes how a statistic varies for all possible samples is called a sampling distribution.
Definition 19.2 (Sampling distribution) A sampling distribution is the distribution of a statistic, showing how its value varies in all possible samples.
19.2 Sample proportions have a sampling distribution
Sample proportions, like all statistics, vary from sample to sample; that is, sampling variation exists, so sample proportions have a sampling distribution.
Consider a European roulette wheel shown below in the animation: a ball and wheel are spun, and the ball can land on any number on the wheel from \(0\) to \(36\) (inclusive). Using the classical approach to probability, the probability of the ball landing on an odd number (an 'odd-spin') is \(p = 18/37 = 0.486\). This is the population proportion (the parameter).
If the wheel is spun (say) \(15\) times, the proportion of odd-spins, denoted \(\hat{p}\), will vary. But, how does \(\hat{p}\) vary from one set of \(15\) spins to another set of \(15\) spins? Can we describe how the values of \(\hat{p}\) vary across the possible samples?
Computer simulation can be used to demonstrate what happens if the wheel was spun, over and over again, for \(n = 15\) spins each time, and the proportion of odd-spins was recorded for each repetition. The proportion of odd spins \(\hat{p}\) varies from sample to sample (sampling variation), as shown by the histogram (Fig. 19.1, top left panel). The shape of the distribution is approximately bell shaped. We can see that, for many repetitions of \(15\) spins, \(\hat{p}\) is rarely smaller than \(0.2\), and rarely larger than \(0.8\). That is, reasonable values to expect for \(\hat{p}\) are between about \(0.2\) and \(0.8\).
If the wheel was spun (say) \(n = 25\) times (rather than \(15\) times), \(\hat{p}\) again varies (Fig. 19.1, top right panel): the values of \(\hat{p}\) vary from sample to sample. The same process can be repeated for many repetitions of (say) \(n = 100\) and \(n = 200\) spins (Fig. 19.1, bottom panels).
Notice that as the sample size \(n\) increases, the variation in the sampling distribution gets smaller. With \(200\) spins, for instance, observing a sample proportion smaller than \(0.4\) or greater than \(0.6\) seems highly unusual, but these are not uncommon at all for \(15\) spins.
The sampling distributions can be described by a mean (called the sampling mean) and a standard deviation (called the standard error).
Example 19.1 (Reasonable values for the sample proportion) Suppose a roulette wheel was spun \(100\) times, and \(31\) odd numbers were observed. The sample proportion is \(\hat{p} = 31/100 = 0.31\). From Fig. 19.1 (bottom left panel), a sample proportion this low almost never occurs in a sample of \(100\) rolls.
This is very unlikely to occur from a fair roulette wheel. Hence, we either observed something highly unusual, or the wheel is not fair (e.g., a problem exists with the wheel).
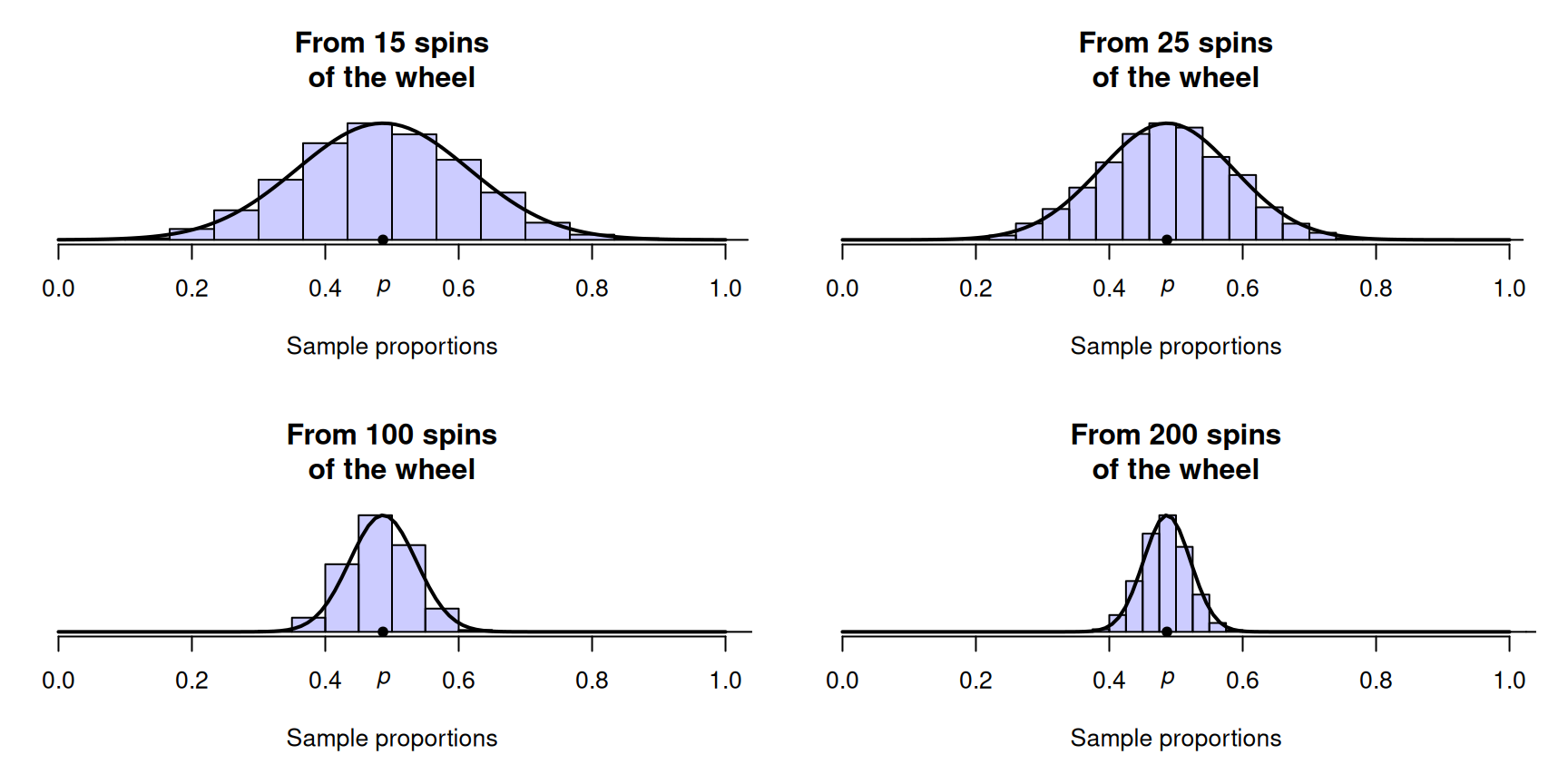
FIGURE 19.1: Sampling distributions for the proportion of roulette wheel spins that show an odd number, for sets of rolls of varying sizes.
The values of the sample proportion vary from sample to sample. The distribution of the possible values of the sample proportion is called a sampling distribution.
Under certain conditions, the sampling distribution of a sample proportion is described by an approximate bell-shaped distribution (formally called a normal distribution). In general, the approximation gets better as the sample size increases. In addition, the possible values of \(\hat{p}\) vary less as the sample size increases.
The mean of the sampling distribution is called the sampling mean; the standard deviation of the sampling distribution is called the standard error (Fig. 19.3).
19.3 Sample means have a sampling distribution
The sample mean, like all statistics, varies from sample to sample; that is, sampling variation exists, so sample means have a sampling distribution.

Consider a European roulette wheel again (Sect. 19.2). Rather than recording the sample proportion of odd-spins, suppose the sample mean of the numbers was recorded. If the wheel is spun (say) \(15\) times, the sample mean of the spins \(\bar{x}\) will vary from one set of \(15\) spins to another. But how does it vary?
Again, computer simulation can be used to demonstrate what could happen if the wheel was spun \(15\) times, over and over again, and the mean of the numbers was recorded for each repetition. Clearly, the sample mean spin \(\bar{x}\) can vary from sample to sample (sampling variation) for \(n = 15\) spins (Fig. 19.2, top left panel).
When \(n = 15\), the sample mean \(\bar{x}\) varies from sample to sample, and the shape of the distribution again is approximately bell-shaped. If the wheel was spun more than \(15\) times (say, \(n = 50\) times) something similar occurs (Fig. 19.2, top right panel): the values of \(\bar{x}\) vary from sample to sample, and the values have an approximate bell-shaped (normal) distribution. In fact, the values of \(\bar{x}\) have a bell-shaped distribution for other numbers of spins also (Fig. 19.2, bottom panels).
The sampling distributions can be described by a mean (called the sampling mean) and a standard deviation (called the standard error).
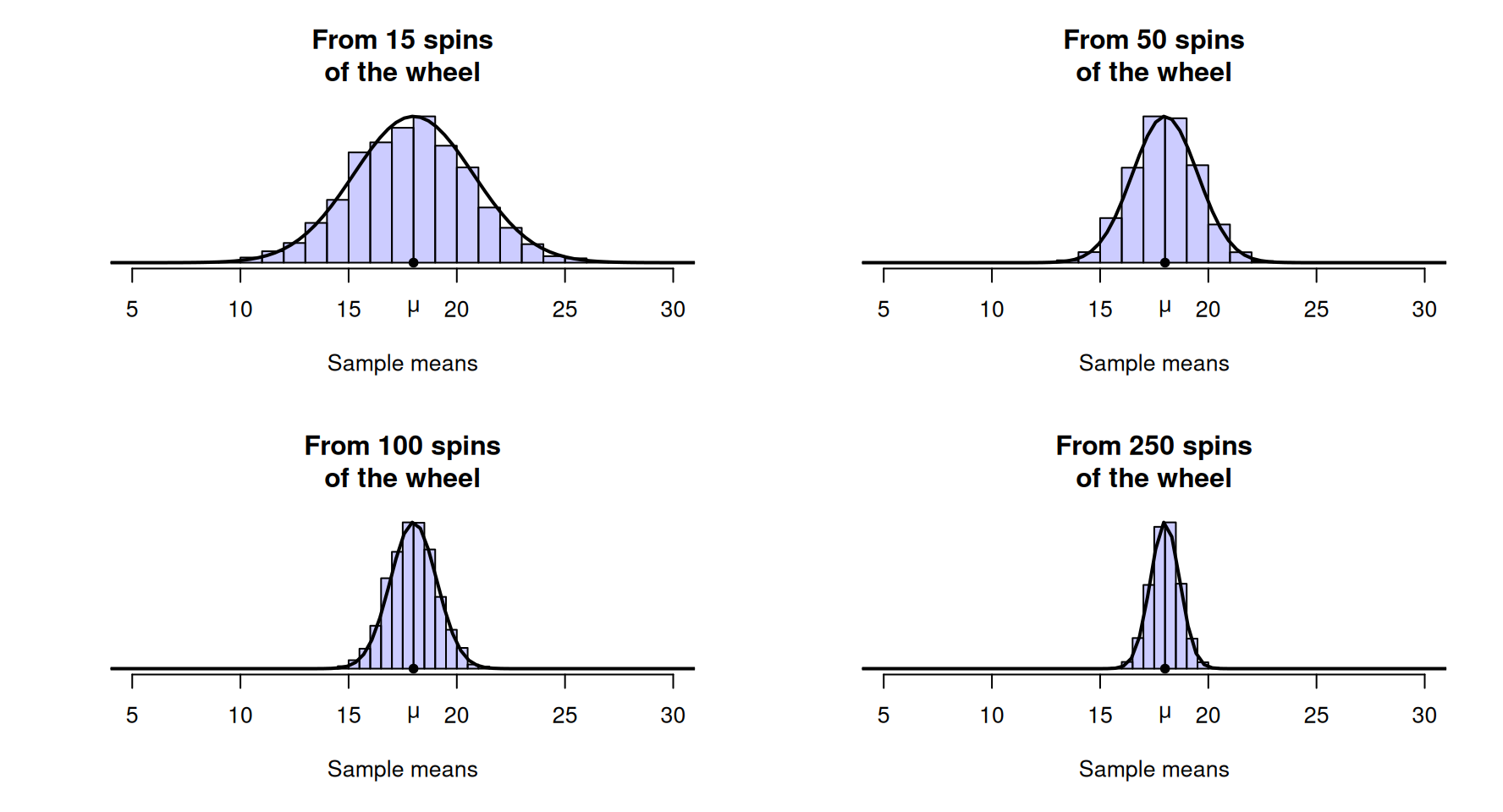
FIGURE 19.2: Sampling distributions for the mean of the numbers after a roulette wheel is spun a certain number of times.
The values of the sample mean vary from sample to sample. The distribution of the possible values of the sample mean is called a sampling distribution.
Under certain conditions, the sampling distribution of a sample mean is described by an approximate bell-shaped (or normal) distribution. In general, the approximation gets better as the sample size increases. In addition, the possible values of \(\bar{x}\) vary less as the sample size increases.
The mean of the sampling distribution is called the sampling mean; the standard deviation of the sampling distribution is called the standard error (Fig. 19.3).
Example 19.2 (Reasonable values for the sample mean) Suppose we spun a roulette wheel \(100\) times, and the mean of the observed numbers was \(\bar{x} = 18.9\). From Fig. 19.2 (bottom left panel), a sample mean with this value does not look unusual at all; it would occur reasonably frequently. The evidence does not suggest a problem with the wheel.
As we have seen, each sample is likely to be different, so any statistic is likely to vary from sample to sample. (The value of the population parameter does not change.) This variation in the possible values of the observed sampling statistic is called sampling variation.
19.4 Sampling means and standard errors
As seen in the previous two sections, the value of a sample statistic varies from sample to sample. The value of the sample statistic that is observed depends on which one of the countless samples happens to be observed
The possible values of the statistic that we could potentially observe have a distribution (specifically, a sampling distribution); see Fig. 19.3. The mean of this sampling distribution is called the sampling mean. The sampling mean is the average value of all possible values of the statistic. Not all sampling distributions have a bell-shaped distribution.
Definition 19.3 (Sampling mean) The sampling mean is the mean of the sampling distribution of a statistic: the mean of the values of the statistic from all possible samples.
The standard deviation of this sampling distribution is called the standard error. The standard error measures how the value of the statistic varies across all possible values of the statistic; see Fig. 19.3. The standard error is a measure of how precisely the sample statistic estimates the population parameter. If every possible sample (of a given size) was found, and the statistic computed from each sample, the standard deviation of all these estimates is the standard error.
Definition 19.4 (Standard error) A standard error is the standard deviation of the sampling distribution of a statistic: the standard deviation of the values of the statistic from all possible samples.
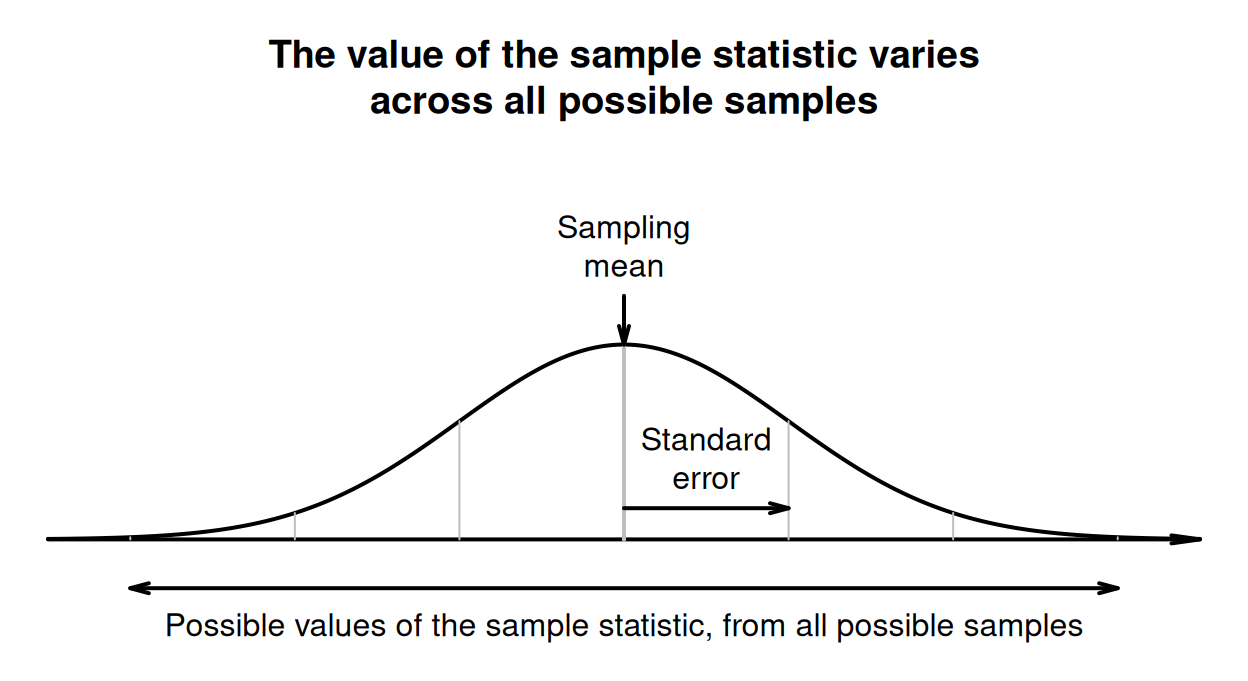
FIGURE 19.3: Describing how the value of the sample statistic varies across all possible samples, when the sampling distribution has a normal distribution.
Figures 19.1 and 19.2 show that the variation in the values of the statistic get smaller for larger sample sizes. That is, the standard error gets smaller as the sample sizes get larger: sample statistics show less variation for larger \(n\). This makes sense: larger samples generally produce more precise estimates. After all, that's the advantage of larger samples: all else being equal, larger samples produce more precise estimates (Sect. 6.3).
Example 19.3 (Standard errors) In Fig. 19.2, a sample of \(250\) (i.e., \(250\) spins) is unlikely to produce a sample mean larger than \(20\), or smaller than \(15\). However, in a sample of size \(15\) (i.e., \(15\) spins) sample means near \(15\) and \(20\) are quite commonplace.
In samples of size \(100\), the variation in the mean spin is smaller than in samples of size \(15\). Hence, the standard error (the standard deviation of the sampling distributions) will be smaller for samples of size \(250\) than for samples of size \(15\).
For many sample statistics, the variation from sample to sample can be approximately described by a bell-shaped (normal) distribution (the sampling distribution) if certain conditions are met. Furthermore, the standard deviation of this sampling distribution is called the standard error. The standard error is a special name given to the standard deviation that describes the variation in the possible values of a statistic.
'Standard error' is an unfortunate label: it is not an error, or even standard. (For example, there is no such thing as a 'non-standard error'.)
19.5 Standard deviation and standard error
Even experienced researchers confuse the meaning and the usage of the terms standard deviation and standard error (Ko et al. 2014). Understanding the difference is important.
The standard deviation, in general, quantifies the amount of variation in any quantity that varies. The standard error only ever refers to the standard deviation that describes a sampling distribution.
Typically, in a research study, standard deviations describe the variation in the individuals in a sample: how observations vary from individual to individual. The standard error is only used to describe how sample estimates vary from sample to sample (i.e., to describe the precision of sample estimates).
The standard error is a standard deviation, but specifically describes the variation in sampling distributions. Any numerical quantity estimated from a sample (a statistic) can vary from sample to sample, and so has sampling variation, a sampling distribution, and hence a standard error. (Not all sampling distributions are normal distributions, however.)
Any quantity estimated from a sample (a statistic) has a standard error.
The standard error is often abbreviated to 'SE' or 's.e.'. For example, the 'standard error of the sample mean' is usually written \(\text{s.e.}(\bar{x})\), and the 'standard error of the sample proportion' is usually written \(\text{s.e.}(\hat{p})\).
Parameters do not vary from sample to sample, so do not have a sampling distribution (or a standard error).
19.6 Chapter summary
A sampling distribution describes how all possible values of a statistic vary from sample to sample. Under certain circumstances, the sampling distribution often can be described by a bell-shaped (or normal) distribution. The standard deviation of this normal distribution is called a standard error. The standard error is the name specifically given to the standard deviation that describes the variation in the statistic across all possible samples.
19.7 Quick review questions
Are the following statements true or false?
- The phrase 'the standard error of the population proportion' is illogical.
- The sample size does not have a standard error?
- Sampling variation refers to how sample sizes vary.
- Sampling distributions describe how parameters vary.
- Statistics do not vary from sample to sample.
- Populations are numerically summarised using parameters
- The standard deviation is a type of standard error in a specific situation.
- Sampling distributions are always normal distributions.
- Sampling variation measures the amount of variation in the individuals in the sample.
- The standard error measures the size of the error when we use a sample to estimate a population.
- In general, a standard deviation measures the amount of variation.
19.8 Exercises
Answers to odd-numbered exercises are given at the end of the book.
Exercise 19.1 In the following scenarios, would a standard deviation or a standard error be the appropriate way to measure the amount of variation? Explain.
- Researchers are studying the spending habits of customers. They would like to measure the variation in the amount spent by shoppers per transaction at a supermarket.
- Researchers are studying the time it takes for inner-city office workers to travel to work each morning. They would like to determine the precision with which their estimate (a mean of \(47\,\text{mins}\)) has been measured.
Exercise 19.2 In the following scenarios, would a standard deviation or a standard error be the appropriate way to measure the amount of variation? Explain.
- A study examined the effect of taking a pain-relieving drug on children. The researchers want to describe the sample they used in the study, including a description of how the ages of the children in the study vary.
- A study estimated the proportion of children aged under \(14\) who owned a mobile (cell) phone. The researchers want to report this estimate, indicating the precision of that estimate.
Exercise 19.3 Which of the following have a standard error?
- The population proportion.
- The sample median.
- The sample IQR.
Exercise 19.4 Which of the following have a standard error?
- The sample standard deviation.
- The population odds.
- The sample odds ratio.
Exercise 19.5 Consider spinning a European roulette wheel.
- Suppose the wheel was spun \(15\) times (Fig. 19.2, top left panel), and the mean spin was \(22.1\). What would you conclude about the wheel?
- Suppose the wheel was spun \(250\) times (Fig. 19.2, bottom right panel), and the mean spin was \(22.1\). What would you conclude about the wheel?
- Suppose the wheel was spun \(50\) times (Fig. 19.2, top right panel), and the mean spin was \(22.1\). What would you conclude about the wheel?
- Suppose the wheel was spun \(50\) times (Fig. 19.2, top right panel), and the mean spin was \(24.0\). What would you conclude about the wheel?
Exercise 19.6 Consider spinning a European roulette wheel.
- Suppose the wheel was spun \(15\) times (Fig. 19.1, top left panel), and the proportion of spins showing an odd number was \(0.44\). What would you conclude about the wheel?
- Suppose the wheel was spun \(15\) times (Fig. 19.1, top left panel), and the proportion of spins showing an odd number was \(0.13\). What would you conclude about the wheel?
- Suppose the wheel was spun \(15\) times (Fig. 19.1, top left panel), and the proportion of spins showing an odd number was \(0.65\). What would you conclude about the wheel?
- Suppose the wheel was spun \(200\) times (Fig. 19.1, bottom right panel), and the proportion of spins showing an odd number was \(0.65\). What would you conclude about the wheel?
Exercise 19.7 A research article (Nagele 2003) made this statement:
... authors often [incorrectly] use the standard error of the mean (SEM) to describe the variability of their sample...
What is wrong with using the standard error of the mean to describe the sample? How would you explain the difference between the standard error and the standard deviation?