28 CIs for comparing two odds or proportions
So far, you have learnt to ask a RQ, design a study, classify and summarise the data, and form confidence intervals. In this chapter, you will learn to:
- identify situations where comparing two qualitative variables is appropriate.
- form confidence intervals for the difference between two proportions.
- form confidence intervals for odds ratios using software output.
- determine whether the conditions for using the confidence intervals apply in a given situation.
28.1 Introduction: eating habits

Mann and Blotnicky (2017) examined the relationship between where university students usually ate, and where the student lived, for students from two Canadian east coast universities. The researchers cross-classified the \(n = 183\) students (the units of analysis) according to two qualitative variables:
- Where they lived: with their parents, or not with their parents;
- Where they ate most meals: off-campus or on-campus.
Both variables are qualitative, so means are not appropriate for summarising the data. The data can be compiled into a two-way table of counts (Table 28.1), also called a contingency table. Both qualitative variables have two levels, so this is a \(2\times 2\) table. Every cell in the \(2\times 2\) table contains different students, so the comparison is between individuals.
The study has one sample of students, classified according to two variables (i.e., each student is placed into one of the four cells in the \(2\times 2\) table).
The table can be constructed with either variable as the rows or the columns. However, software commonly compares rows, so it makes sense to place the groups to be compared (i.e., the explanatory variable) in the rows of the table.
| Most off-campus | Most on-campus | |
|---|---|---|
| Living with parents | \(52\) | \(\phantom{0}\phantom{0}2\) |
| Not living with parents | \(105\) | \(\phantom{0}24\) |
The proportion of students who eat most meals off-campus can be compared between those who live with their parents and those who do not live with their parents. Then, the parameter is the difference between the population proportions in each group, and the RQ could be written as:
Among university students, what is the difference between the proportion of students eating most meals off-campus, comparing those who do and do not live with their parents?
Alternatively, the odds of students who eat most meals off-campus can be compared between those who live with their parents and those who do not live with their parents. Then, the parameter is the odds ratio (OR); specifically, the odds ratio of eating most meals off-campus, comparing those living with parents to those not living with parents. Using the OR, the RQ could be written as:
Among university students, what is the odds ratio of students eating most meals off-campus, comparing those who do and do not live with their parents?
Take care defining the odds ratios! Recall (Sect. 12.5): software usually compares Row 1 to Row 2, and Column 1 to Column 2 (that is, the last row is usually the reference level). For this reason, defining your OR in the same way makes sense.
28.2 Summarising data
With two qualitative variables, an appropriate numerical summary includes the odds and proportions (or percentages) for the outcome for both comparison groups, and the sample sizes (Table 28.2).
To compare the proportions, define the sample proportion of students eating most meals off-campus as \(\hat{p}\), and write \(\hat{p}_P\) for the proportion living with parents and \(\hat{p}_N\) for the proportion not living with parents. Then, \[ \hat{p}_P = \frac{52}{52 + 2} = 0.962963 \quad\text{and}\quad \hat{p}_N = \frac{105}{105 + 24} = 0.8139535. \] The difference between the two proportions is \[ \hat{p}_P - \hat{p}_N = 0.9630 - 0.8140 = 0.1490, \] (as in the software output: Fig. 28.1), or \(14.9\)%. By this definition, the difference is how much greater the proportion eating most meals off-campus is for students living with their parents, compared to students not living with their parents.
Be clear about how differences are defined! Differences could be computed as:
- the proportion eating most meals off-campus for those living with their parents, minus the proportion not living with their parents. This measures how much greater the proportion is for those living with their parents; or
- the proportion eating most meals off-campus for those not living with their parents, minus the proportion living with their parents. This measures how much greater the proportion is for those not living with their parents.
Either is fine, provided you are consistent, and clear about how the difference are computed. The meaning of any conclusions will be the same.
To compare the odds, first see that the odds of eating most meals off-campus is:
- \(52 \div 2 = 26\) for students living with their parents (Row 1 of Table 28.1).
- \(105\div 24 = 4.375\) for students not living with their parents (Row 2 of Table 28.1).
(Notice the numbers in the second column are always on the bottom of the fraction.) So the odds ratio (OR) of eating most meals off-campus (the first column), comparing students living with parents to students not living with parents (second column), is \(26 \div 4.375 = 5.943\) (as in the software output: Fig. 28.1).
The numerical summary (Table 28.2) shows the proportion and odds of eating most meals off-campus, comparing students living at home and those not living at home.
The odds ratio can be interpreted in either of these ways (i.e., both are correct):
- The odds compare Row 1 counts to Row 2 counts, for both columns. The odds ratio then compares the Column 1 odds to the Column 2 odds.
- The odds compare Column 1 counts to Column 2 counts. The odds ratio then compares the Row 1 odds to the Row 2 odds.
Odds and odds ratios are computed with the first row and first column values on the top of the fraction. In this case, both of the above approaches produces an OR of \(5.943\). Since the explanatory variable is usually in the rows, the first is usually the most useful.
An appropriate graph is a side-by-side bar chart (Fig. 28.1, left panel) or a stacked bar chart. The side-by-side bar is a good display for comparing the odds. For instance, in the two left-most bars in Fig. 28.1 (left panel), the first bar is \(26\) times as high as the second bar (and \(26\) is the odds); in the two right-most bars, the first bar is \(4.375\) times as high as the second bar (and \(4.375\) is the odds). A stacked bar chart would be a good visual display for comparing the proportions.
| Odds of having most meals off-campus | Proportion having most meals off-campus | Sample size | |
|---|---|---|---|
| Living with parents | \(26.000\) | \(\phantom{-}0.963\) | \(\phantom{0}54\) |
| Not living with parents | \(\phantom{-}4.375\) | \(\phantom{-}0.814\) | \(129\) |
| \(\phantom{-}5.943\) | \(\phantom{-}0.149\) |
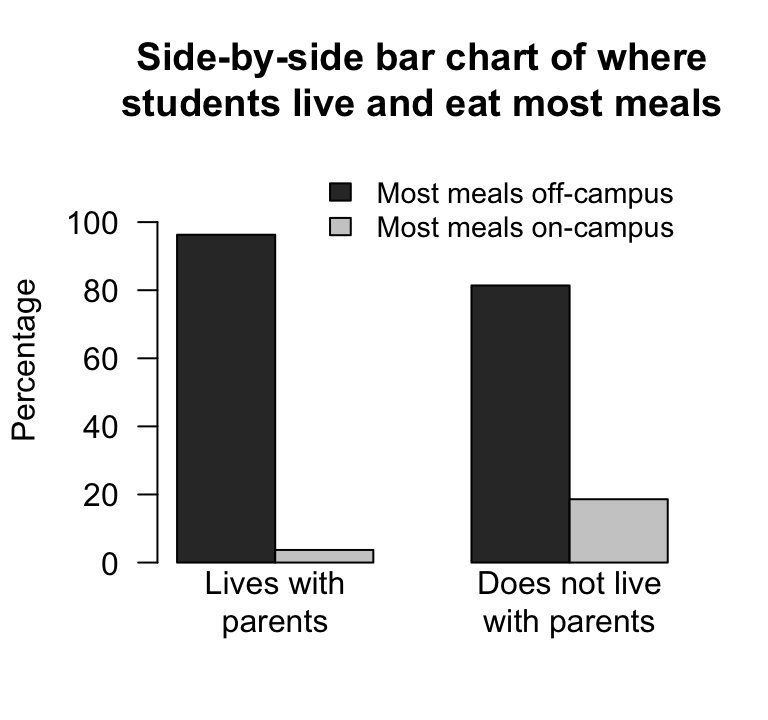

FIGURE 28.1: The student-eating data. Left: a side-by-side bar chart. Right: software output for computing a CI for the difference between the proportions, and for the odds ratio.
Each sample of students comprises different students, giving different proportions and odds of having most meals off-campus for both groups (living with, and not living with, parents). Hence, the difference between the two proportions, and the odds ratio, will vary between samples. This means that both the difference between the two proportions, and the odds ratio, have sampling distributions.
28.3 CIs for the difference between two proportions
The sample proportions for each group will vary from sample to sample, and the difference between the sample proportions will be different for each sample. Hence, the difference between the sample proportions has a sampling distribution and standard error. Under certain conditions (Sect. 28.5), this sampling distribution has a normal distribution.
Definition 28.1 (Sampling distribution for the difference between two sample proportions) The sampling distribution of the difference between two sample proportions \(\hat{p}_A\) and \(\hat{p}_B\) is (when the appropriate conditions are met; Sect. 28.5) described by:
- an approximate normal distribution,
- centred around a sampling mean whose value is \({p_{A}} - {p_{B}}\), the difference between the population proportions,
- with a standard deviation, called the standard error of the difference between the proportions, of \(\displaystyle\text{s.e.}(\hat{p}_A - \hat{p}_B)\).
The standard error for the difference between the proportions is found using \[\begin{equation} \text{s.e.}(\hat{p}_A - \hat{p}_B) = \sqrt{ \text{s.e.}(\hat{p}_A)^2 + \text{s.e.}(\hat{p}_B)^2}, \tag{28.1} \end{equation}\] though this value will often be given (e.g., on computer output).
For the student-eating data, the standard error of the sample proportions for each group are computed using Eq. (23.4) as \[\begin{align*} \text{s.e.}(\hat{p}_L) &= \sqrt{\frac{0.962963\times ( 1 - 0.962963)}{54}} = 0.025700; \text{and}\\ \text{s.e.}(\hat{p}_N) &= \sqrt{\frac{0.8139535\times (1 - 0.8139535)}{129}} = 0.034262. \end{align*}\] The standard error of the difference between the proportions is \[ \text{s.e.}(\hat{p}_P - \hat{p}_N) = \sqrt{ \text{s.e.}(\hat{p}_P)^2 + \text{s.e.}(\hat{p}_N)^2} = \sqrt{ 0.025700^2 + 0.034262^2 } = 0.042830. \]
Thus, the differences between the sample proportions will have:
- an approximate normal distribution,
- centred around the sampling mean whose value is \(p_P - p_N\),
- with a standard deviation, called the standard error of the difference, of \(\text{s.e.}(\hat{p}_P - \hat{p}_N) = 0.04282954\).
The sampling distribution describes how the values of \(\hat{p}_P - \hat{p}_N\) vary from sample to sample. Then, finding a \(95\)% CI for the difference between the proportions is similar to the process used previously, since the sampling distribution has an approximate normal distribution: \[ \text{statistic} \pm \big(\text{multiplier} \times\text{s.e.}(\text{statistic})\big). \] When the statistic is \(\hat{p}_P - \hat{p}_N\), the approximate \(95\)% CI is \[ (\hat{p}_P - \hat{p}_N) \pm \big(2 \times \text{s.e.}(\hat{p}_P - \hat{p}_N)\big). \] So, in this case, the approximate \(95\)% CI is \[ 0.1490 \pm (2 \times 0.042830), \] or \(0.149 \pm 0.0857\) after rounding (i.e., from \(0.0633\) to \(0.235\)). This approximate CI is very similar to the (exact) CI from software (Fig. 28.1). We write:
The difference between the proportions of students eating most meals at home is \(0.1490\), higher for those living with their parents (\(0.963\); \(n = 52\)) that those not living with their parents (\(0.814\); \(n = 129\)), with the \(95\)% confidence interval from \(0.0633\) to \(0.235\).
The plausible values for the difference between the two population proportions are between \(0.063\) to \(0.235\), larger for those living with parents.
Giving the CI alone is insufficient; the direction in which the differences were calculated must be given, so readers know which group had the higher proportion.
28.4 CIs for odds ratios
A CI can be formed for the difference between the two proportions, and a CI can also be formed for the odds ratio. Every sample of students is likely to be different, and hence the odds of students eating off campus will vary from sample to sample (in both groups). Hence, the OR varies also from sample to sample. That is, sampling variation exists, so the odds ratio has a sampling distribution.
However, the sampling distribution of the sample OR does not have a normal distribution5. Fortunately, a simple transformation of the sample OR does have a normal distribution, though we omit the details. For this reason, we will only use software output for finding the CI for the odds ratio, and not discuss the sampling distribution directly. In other words, we will rely on software to find CIs for odds ratios.
Software (Fig. 28.1, right panel) gives the sample OR as \(5.94\), and the (exact) \(95\)% CI as \(1.35\) to \(26.1\). The value of the OR is the same as computed manually.
We write:
The odds of students eating most meals off-campus is \(5.94\) higher for students living with their parents (odds: \(26.0\); \(n = 54\)) than for students not living with their parents (odds: \(4.38\); \(n = 129\)), with the \(95\)% confidence interval from \(1.35\) to \(26.1\).
There is a \(95\)% chance that this CI straddles the population OR. Notice that the meaning of the OR is explained in the conclusions: the odds of eating most meals off-campus, and comparing students living with parents to not living with parents.
The CI for an OR is not symmetrical, like the others we have seen6; that is, the sample OR of \(5.94\) is not in the centre of the confidence interval.
Interpreting and explaining ORs can be challenging, so care is needed!
28.5 Statistical validity conditions
As usual, these results hold under certain conditions. The CIs computed above are statistically valid if
- All expected counts in the table are at least five.
Some books may give other (but similar) conditions. The units of analysis are also assumed to be independent (e.g., from a simple random sample). If the statistical validity conditions are not met, a confidence interval based on the non-parametric Fisher's method may be used (Fisher 1962).
Importantly, this condition is based on the expected counts, not the observed counts. The expected counts are the counts expected if there was no relationship between the two variables in the two-way table. If there was no relationship between the two variables for the student-meals data (Table 28.1), students living with or not with their parents would have a similar percentage of meals eaten off-campus. That is, the two conditional probabilities would be the same. The overall percentage of students eating meals off-campus is \(157/183\times 100 = 85.79\)% (from Table 28.1). If there was no relationship between the two variables, this percentage would be the same for students living with or not with their parents. In other words, we would expect \(85.79\)% of the \(54\) students who do live with their parents to eat most meals off-campus (which is \(46.33\)), and we would expect \(85.79\)% of the \(129\) students who do not live with their parents to eat most meals off-campus (which is \(110.67\)). This statistical validity condition is explained further in Sect. 35.3.1.
Usually, you do not have to compute these expected values, as software can produce the expected counts (see Fig. 28.2). However, a quick check for the statistical validity is to compute the value of the smallest expected value, using \[ \frac{(\text{Smallest row total})\times(\text{Smallest column total})}{\text{Overall total}}. \] If this value is greater than five, the CIs are statistically valid.
Example 28.1 (Statistical validity) For the students-eating data, software can be used to compute the expected counts (Fig. 28.2) None are less than five, and so the conclusion is statistically valid. (One observed count is less than five, but this is not relevant to checking for statistical validity.)
In Table 28.1, the smallest row total is \(54\) and the smallest column total is \(26\). Then, \[ \frac{54\times 26}{183} = 7.67, \] which is larger than five, so the CIs are statistically valid. (The value of \(7.67\) is also the smallest expected count in Fig. 28.2.)
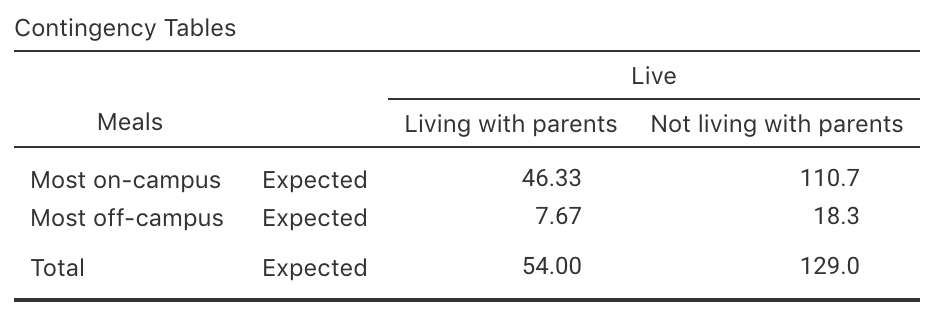
FIGURE 28.2: The expected counts from software, for the student-eating data.
28.6 Example: turtle nests
The hatching success of loggerhead turtles on Mediterranean beaches is often compromised by fungi and bacteria. Candan, Katılmış, and Ergin (2021) compared the odds of a nest being infected, between nests relocated due to the risk of tidal inundation, and non-relocated nests (Table 28.3). Note that the explanatory variable (whether the nest is relocated) is in the rows. The researchers were interested in knowing:
For Mediterranean loggerhead turtles, what is the difference between the proportion of infected nests, comparing natural to relocated nests?
The parameter here is the difference between the proportions infected, comparing natural to relocated nests.
Alternatively, the researchers could have asked:
For Mediterranean loggerhead turtles, what are the odds of infections comparing natural to relocated nests?
The parameter is the odds ratio of non-infection, comparing natural to relocated nests. The odds ratio can be defined in other ways also, but this definition is consistent with how software computes odds given Table 28.3 (i.e., first row to second row; first column to second column).
| Non-infected | Infected | |
|---|---|---|
| Natural | \(29\) | \(10\) |
| Relocated | \(14\) | \(\phantom{0}8\) |
The data are summarised graphically (Fig. 28.3) and numerically (Table 28.4). From the software output (Fig. 28.4), the \(95\)% CI for the difference between the proportions is from \(-0.1361\) to \(0.3505\). The negative value is not a negative proportion; it is a negative difference between two proportions. Specifically, it means that the population proportion of infected nests is larger for relocated nests than natural nests by \(0.1361\). Write:
The difference between proportion of infected nests is \(0.107\) (\(95\)% CI: \(-0.136\) to \(0.527\)), comparing natural nests (proportion: \(0.744\); \(n = 39\)) to relocated nests (\(0.636\); \(n = 22\)).
In addition, from the software output (Fig. 28.4) the \(95\)% CI for the odds ratio is from \(0.537\) to \(5.12\). Write:
The OR of a non-infected nest, comparing natural nests (odds: \(2.90\); \(n = 39\)) to relocated nests (odds: \(1.75\); \(n = 22\)), is \(1.66\) with a \(95\)% CI from \(0.537\) to \(5.12\).
The smallest expected count is \(6.49\) (Fig. 28.4), so the CIs are statistically valid. (Alternatively, since the smallest row and column counts are \(22\) and \(18\) respectively, we see that \(22\times18/61 = 6.49\), which is greater than five.)
| Odds non-infected | Proportion non-infected | Sample size | |
|---|---|---|---|
| Natural | \(2.900\) | \(0.744\) | \(39\) |
| Relocated | \(1.750\) | \(0.636\) | \(22\) |
| \(1.657\) | \(0.107\) |
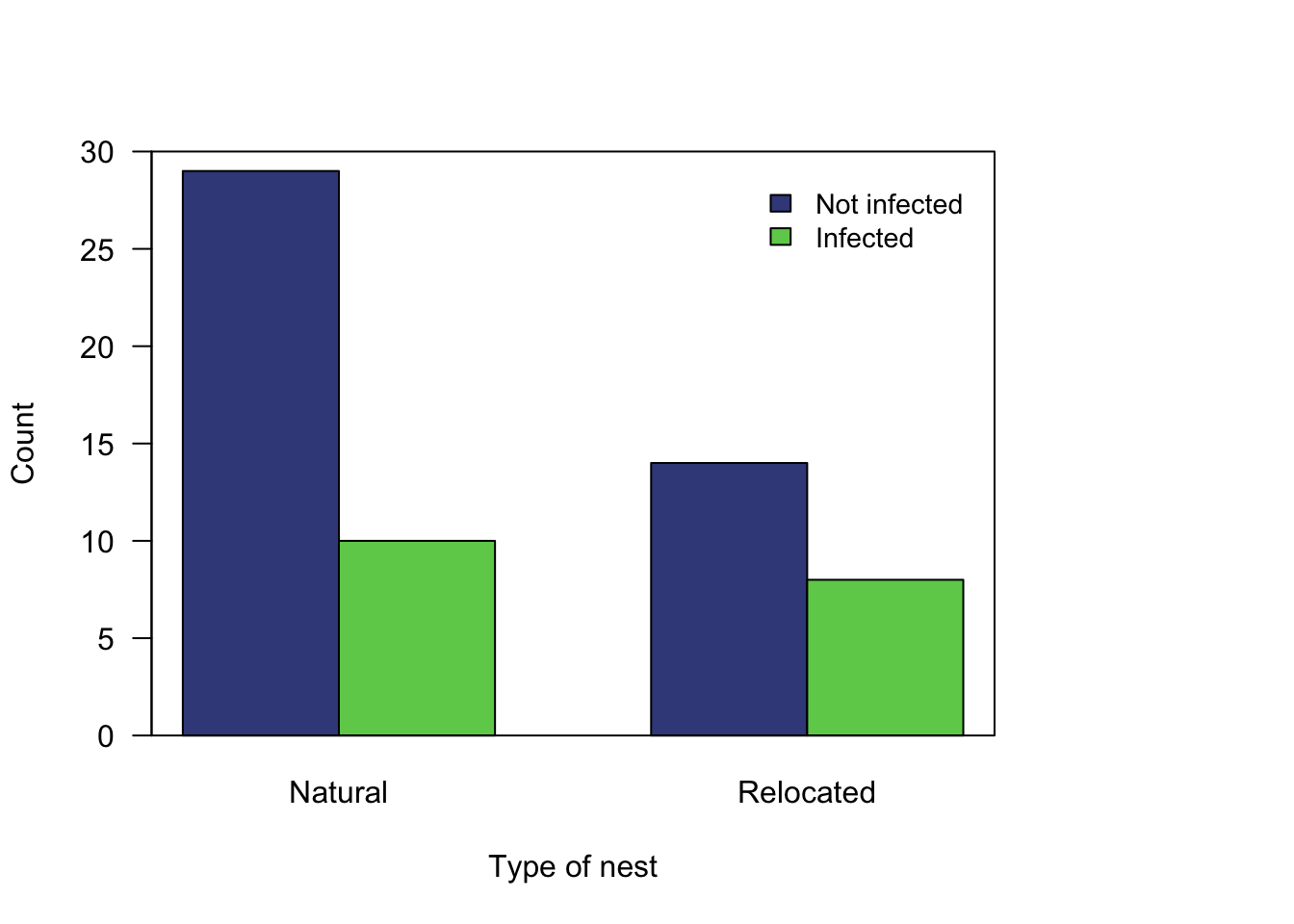
FIGURE 28.3: Software output for the turtle-nesting data.
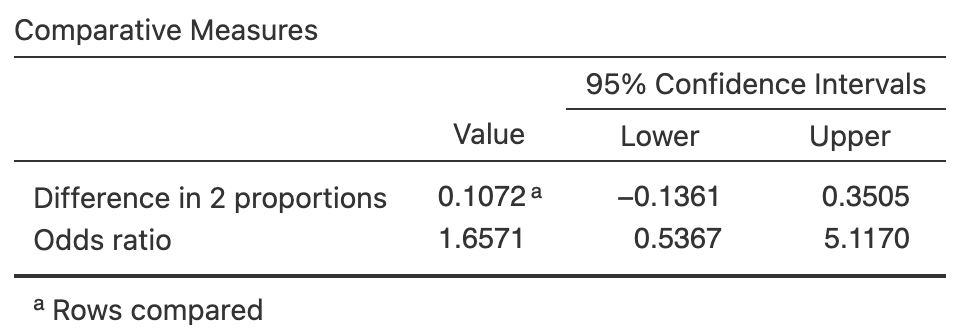
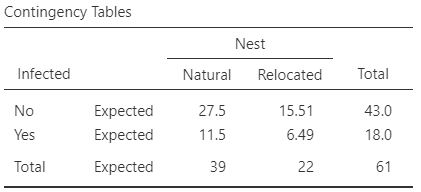
FIGURE 28.4: The software output for the turtle-nesting data.
28.7 Chapter summary
To compare a two-level qualitative variable between two groups, a confidence interval can be formed for the difference between two proportions, or for an odds ratio.
To compute a confidence interval (CI) for the difference between two proportions, compute the difference between the two sample proportions, \(\hat{p}_A - \hat{p}_B\), and identify the sample sizes \(n_A\) and \(n_B\). Then compute the standard error, which quantifies how much the value of \(\hat{p}_A - \hat{p}_B\) varies across all possible samples: \[ \text{s.e.}(\hat{p}_A - \hat{p}_B) = \sqrt{ \text{s.e}(\hat{p}_A) + \text{s.e.}(\hat{p}_B)}, \] where \(\text{s.e.}(\hat{p}_A)\) and \(\text{s.e.}(\hat{p}_B)\) are the standard errors of Groups \(A\) and \(B\) (Eq. (23.4)). The margin of error is (multiplier\({}\times{}\)standard error), where the multiplier is \(2\) for an approximate \(95\)% CI (using the \(68\)--\(95\)--\(99.7\) rule). Then the CI is: \[ (\hat{p}_A - \hat{p}_B) \pm \left( \text{multiplier}\times\text{standard error} \right). \] Software is used to compute a confidence interval (CI) for the odds ratio, as the sampling distribution does not have a normal distribution. The statistical validity conditions should be checked: all expected counts should exceed five.
28.8 Quick review questions
Egbue, Long, and Samaranayake (2017) studied the adoption of electric vehicles (EVs) by a certain group of professional Americans (Table 28.5). Software output is shown in Fig. 28.5.
- What percentage of people without post-graduate study would buy an EV in the next \(10\) years? (do not add the percentage symbol)
- What are the odds that a person without post-graduate study would buy an EV in the next \(10\) years?
- Using the output, what is the OR of buying an electric vehicle in the next \(10\) years, comparing those without post-grad study to those with post-grad study?
- True or false: The CI means that the sample OR is likely to be between \(0.68\) and \(4.28\).
- The negative proportion in output suggests the statistical validity conditions are not met.
| Yes | No | |
|---|---|---|
| No post-grad | \(24\) | \(\phantom{0}8\) |
| Post-grad study | \(51\) | \(29\) |
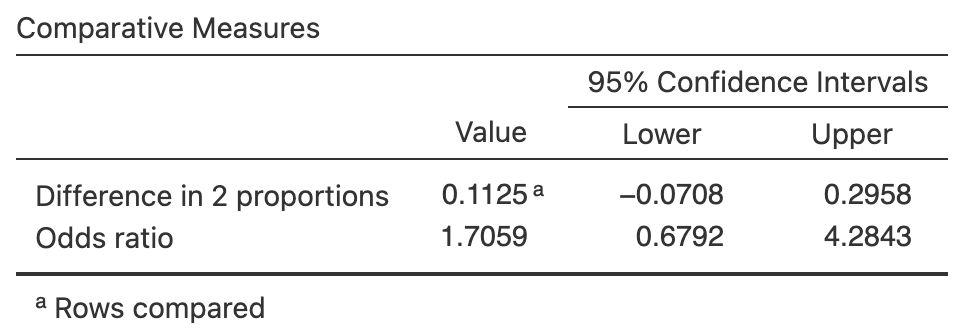
FIGURE 28.5: Software output for the EV study.
- The number without post-grad study: \(24 + 8 = 32\). The percentage of people without post-grad study who would buy an EV in the next \(10\) years is \(24/32 = 0.75\), or \(75\)%.
- The people with post-grad study are in the bottom row. The odds of people without post-grad study who would buy an EV in the next \(10\) years is \(24/8 = 3\).
- The odds of people without post-grad study who would buy an electric vehicle is \(24/8 = 3\).
The odds of people with post-grad study who would buy an electric vehicle is \(51/29 = 1.7586\).
So the OR is \(3/1.7586 = 1.706\). - Not at all. We know exactly what the sample OR is (in this sample, it is \(1.706\)... exactly). CIs always give an interval in which the population parameter is likely to be within.
- The CI is statistically valid if all the expected counts exceed \(5\). So we don't really know for sure from the given information. But the observed counts are all reasonably large, so it is very probably statistically valid.
28.9 Exercises
Answers to odd-numbered exercises are available in App. E.
Exercise 28.1 Suppose the sample odds ratio has a value of one. What will be value of the difference between the sample proportions? Explain.
Exercise 28.2 Suppose the sample odds ratio has a value smaller than one. Will the difference between the sample proportions be a positive or a negative value? Explain.
Exercise 28.3 [Dataset: CarCrashes]
Wang et al. (2020) recorded information about car crashes in a rural, mountainous county in western China
(Table 28.6).
- Compute the proportion of crashes involving a pedestrian in 2011.
- Compute the proportion of crashes involving a pedestrian in 2015.
- Compute the difference between the proportion of crashes involving a pedestrian, comparing 2011 to 2015.
- Compute the difference between the proportions.
- Compute an approximate \(95\)% CI for the difference between the proportions.
- Use the output (Fig. 28.6) to write down a \(95\)% CI for the difference between the proportions.
- Interpret what this CI means.
- Compute the odds of crashes involving a pedestrian in 2011.
- Compute the odds of crashes involving a pedestrian in 2015.
- Compute the odds ratio of crashes involving a pedestrian, comparing 2011 to 2015.
- Interpret what this odds ratio means.
- Write down the CI for the odds ratio.
- Construct an appropriate numerical summary table for the data.
- Sketch a suitable graph to display the data.
- Determine if the CIs are statistically valid.
| pedestrians | vehicles | |
|---|---|---|
| 2011 | \(15\) | \(35\) |
| 2015 | \(37\) | \(85\) |

FIGURE 28.6: Software output for the car-crash data.
Exercise 28.4 [Dataset: ScarHeight]
Wallace et al. (2017) compared the heights of scars from burns received in Western Australia (Table 28.7).
Software was used to analyse the data (Fig. 28.7).
- Compute the proportion of men having a smooth scar (that is, height is \(0\)).
- Compute the proportion of women having a smooth scar (that is, height is \(0\)).
- Compute the difference between the proportions of men and women having a smooth scar.
- Compute the standard error for the difference between the proportions.
- Compute the approximate \(95\) CI for the difference between the proportions.
- Write down the \(95\)% CI for the difference between the proportions, using the software output.
- Interpret what this CI means.
- Compute the odds of having a smooth scar (that is, height is \(0\)) for men.
- Compute the odds of having a smooth scar (that is, height is \(0\)) for women.
- Compute the odds ratio of having a smooth scar, comparing men to women.
- Interpret what this odds ratio means.
- Write down the CI for the odds ratio.
- Construct an appropriate numerical summary table for the data.
- Sketch a suitable graph to display the data.
- Determine if the CIs are statistically valid.
| Men | Women | |
|---|---|---|
| Smooth | \(216\) | \(\phantom{0}99\) |
| 0mm to 1mm | \(115\) | \(\phantom{0}62\) |

FIGURE 28.7: Software output for the scar-height data.
Exercise 28.5 Sketch the sampling distribution for the difference between the proportions of students eating most meals off-campus, for those living with parents minus those not living with parents. What is the sampling distribution for the equivalent odds ratio?
Exercise 28.6 Sketch the sampling distribution for the difference between the proportion of non-infected turtle nests, for natural nests minus relocated nests (in Sect. 28.6). What is the sampling distribution for the equivalent odds ratio?
Exercise 28.7 [Dataset: EarInfection]
A study of ear infections in Sydney swimmers (Smyth 2010) recorded whether people reported an ear infection or not, and where they usually swam.
Use Fig. 28.8 to answers these questions.
- Compute the standard error for the difference between the proportions of people not reporting ear infections, comparing non-beach to beach swimmers.
- Compute an approximate \(95\)% CI for the difference between the proportions.
- Write down the \(95\)% CI for the difference between the proportions.
- Interpret the CI.
- Confirm that the odds ratio in the output is correct.
- Use the software output to write down a \(95\)% CI for the odds ratio.
- Interpret the CI.
- Are the CIs statistically valid?
- Construct the summary table for the data.
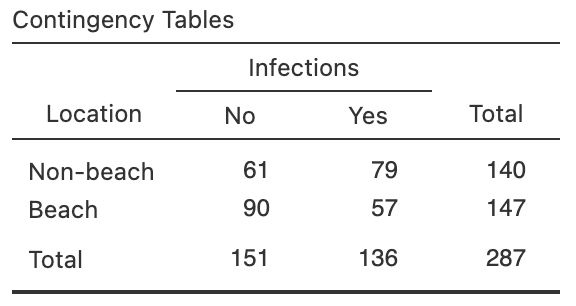
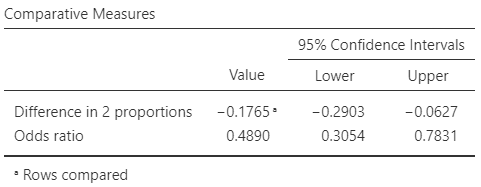
FIGURE 28.8: Software output for the ear-infection data.
Exercise 28.8 [Dataset: EmeraldAug]
The Southern Oscillation Index (SOI) is a standardised measure of the air pressure difference between Tahiti and Darwin, and is related to rainfall in some parts of the world (Stone, Hammer, and Marcussen 1996), and especially Queensland (Stone and Auliciems 1992).
The rainfall at Emerald (Queensland) was recorded for Augusts between 1889 to 2002 inclusive (P. K. Dunn and Smyth 2018), where the monthly average SOI was positive, and when the SOI was non-positive (that is, zero or negative), as shown in Table 28.8.
Use the software output in Fig. 28.9 to answer these questions.
- Compute the standard error for the difference between the proportions of wet August, comparing months with a positive SOI to months with a non-positive SOI.
- Compute an approximate \(95\)% CI for the difference between the proportions.
- Write down the \(95\)% CI for the difference between the proportions.
- Interpret the CI.
- Confirm that the odds ratio in the output is correct.
- Use the software output to write down a \(95\)% CI for the odds ratio.
- Interpret the CI.
- Are the CIs statistically valid?
- Construct the summary table for the data.
| Positive SOI | Non-positive SOI | |
|---|---|---|
| Rain | \(53\) | \(40\) |
| No rain | \(\phantom{0}7\) | \(14\) |

FIGURE 28.9: Software output for the Emerald-rain data.
Exercise 28.9 [Dataset: Turbines]
A study of turbine failures (Myers, Montgomery, and Vining 2002; Nelson 1982) ran \(73\) turbines for around \(1\,800\), and found that seven developed fissures (small cracks).
They also ran a different set of \(42\) turbines for about \(3\,000\), and found that nine developed fissures.
- Construct the two-way table for the data.
- Compute the standard error for the difference between the proportions.
- Compute an approximate \(95\)% CI for the difference between the proportions.
- Write down the \(95\)% CI for the difference between the proportions.
- Interpret the CI.
- Use the software output (Fig. 28.10, left panel) to write down a \(95\)% CI for the odds ratio.
- Interpret the CI.
- Are the CIs statistically valid?
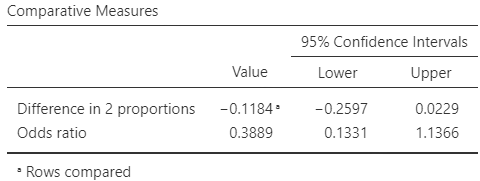

FIGURE 28.10: Software output for the turbine data (left) and the hats data (right).
Exercise 28.10 [Dataset: HatSunglasses]
B. Dexter et al. (2019) recorded the number of people at the foot of the Goodwill Bridge, Brisbane, who wore hats between \(11\):\(30\)am to \(12\):\(30\)pm.
Of the \(386\) males observed, \(79\) wore hats; of the \(366\) females observed, \(22\) wore hats.
The software output is shown in Fig. 28.10 (right panel).
- Construct the two-way table for the data.
- Compute the standard error for the difference between the proportions.
- Compute an approximate \(95\)% CI for the difference between the proportions.
- Write down the \(95\)% CI for the difference between the proportions.
- Interpret the CI.
- Use the software output to write down a \(95\)% CI for the odds ratio.
- Interpret the CI.
- Are the CIs statistically valid?
Exercise 28.11 [Dataset: PetBirds]
Kohlmeier et al. (1992) examined people with lung cancer, and a matched set of controls who did not have lung cancer, and recorded the number in each group that kept pet birds.
One RQ of the study was:
What is the odds ratio of keeping a pet bird, comparing people with lung cancer (cases) compared to people without lung cancer (controls)?
The data, compiled in a \(2\times2\) contingency table, are given in Table 28.9.
- Construct a numerical summary table.
- Sketch a graphical summary.
- Use the software output (Fig. 28.11, left panel) to find a \(95\)% CI, making sure to describe the odds ratio carefully.
- Use the software output to find a \(95\)% CI for the difference between the proportions.
- Are the CIs statistically valid?
| Adults with lung cancer | Adults without lung cancer | |
|---|---|---|
| Did not keep pet birds | \(141\) | \(328\) |
| Kept pet birds | \(\phantom{0}98\) | \(101\) |

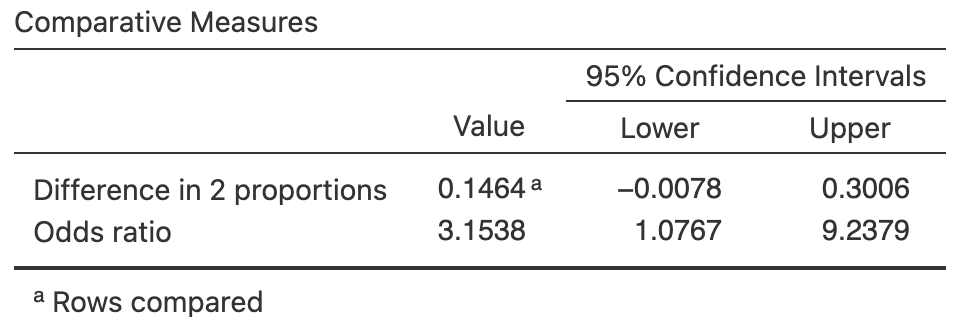
FIGURE 28.11: Left: Software output for the pet-birds data. Right: Software output for the B12 data.
Exercise 28.12 [Dataset: B12Diet]
Gammon et al. (2012) examined B12 deficiencies in 'predominantly overweight/obese women of South Asian origin living in Auckland', some of whom were on a vegetarian diet and some of whom were on a non-vegetarian diet.
One RQ was:
What is the odds ratio of these women being B12 deficient, comparing vegetarians to non-vegetarians?
The data appear in Table 28.10, and the software output in Fig. 28.11 (right panel).
- Construct a numerical summary table.
- Sketch a graphical summary.
- Use the software output to find a \(95\)% CI, making to describe the odds ratio carefully.
- Is the CI statistically valid?
| B12 deficient | Not B12 deficient | |
|---|---|---|
| Vegetarians | \(\phantom{0}8\) | \(\phantom{0}26\) |
| Non-vegetarians | \(\phantom{0}8\) | \(\phantom{0}82\) |