4.2 Maximum likelihood
4.2.1 Maximum lilkelihood estimator
Maximum likelihood builds on the concept of likelihood already introduced in Definition 3.9.
Example 4.5 Consider an experiment consisting in tossing a coin two times independently. Let \(X\) be the rv “number of observed heads in two tosses”. Then, \(X\sim \mathrm{Bin}(2,\theta),\) where \(\theta=\mathbb{P}(\mathrm{Heads})\in\{0.2,0.8\}.\) That is, the pmf is
\[\begin{align*} p(x;\theta)=\binom{2}{x}\theta^x (1-\theta)^{2-x}, \quad x=0,1,2. \end{align*}\]
Then, the pmf of \(X\) according to the possible values of \(\theta\) is given in the following table:
| \(\theta\) | \(x=0\) | \(x=1\) | \(x=2\) |
|---|---|---|---|
| \(0.20\) | \(0.64\) | \(0.32\) | \(0.04\) |
| \(0.80\) | \(0.04\) | \(0.32\) | \(0.64\) |
At the sight of this table, it seems logical to estimate \(\theta\) in the following way: if in the experiment we obtain \(x=0\) heads, then we set as estimator \(\hat{\theta}=0.2\) since, provided \(x=0,\) \(\theta=0.2\) is more likely than \(\theta=0.8.\) Analogously, if we obtain \(x=2\) heads, we set \(\hat{\theta}=0.8.\) If \(x=1,\) we do not have a clear choice among \(\theta=0.2\) and \(\theta=0.8,\) since both are equally likely according to the available information, so we can arbitrarily choose one of the values for \(\hat{\theta}.\)
The previous example illustrates the core idea behind the maximum likelihood method: estimate the unknown parameter \(\theta\) with the value that maximizes the probability of obtaining a sample realization as the one which was actually observed. Or, in other words, to select the most likely value of \(\theta\) according to the data at hand. Note, however, that this interpretation is only valid for discrete rv’s \(X,\) for whom we can define the probability of the sample realization \((X_1=x_1,\ldots,X_n=x_n)\) as \(\mathbb{P}(X_1=x_1,\ldots,X_n=x_n;\theta).\) In the continuous case, the probability of a particular sample realization is zero. In this case, it is the \(\theta\) that maximizes the density of the sample realization, \(f(x_1,\ldots,x_n;\theta),\) the one that delivers the maximum likelihood estimator.
The formal definition of the maximum likelihood estimator is given next.
Definition 4.2 (Maximum likelihood estimator) Let \((X_1,\ldots,X_n)\) be a srs of a rv whose distribution belongs to the family \(\mathcal{F}_{\Theta}=\{F(\cdot; \boldsymbol{\theta}): \boldsymbol{\theta}\in\Theta\},\) where \(\boldsymbol{\theta}\in\mathbb{R}^K.\) The Maximum Likelihood Estimator (MLE) of \(\boldsymbol{\theta}\) is
\[\begin{align*} \hat{\boldsymbol{\theta}}_{\mathrm{MLE}}:=\arg\max_{\boldsymbol{\theta}\in\Theta} \mathcal{L}(\boldsymbol{\theta};X_1,\ldots,X_n). \end{align*}\]
Remark. Quite often, the log-likelihood
\[\begin{align*} \ell(\boldsymbol{\theta};x_1,\ldots,x_n):=\log \mathcal{L}(\boldsymbol{\theta};x_1,\ldots,x_n) \end{align*}\]
is more manageable than the likelihood. As the logarithm function is monotonously increasing, then the maxima of \(\ell(\boldsymbol{\theta};x_1,\ldots,x_n)\) and \(\mathcal{L}(\boldsymbol{\theta};x_1,\ldots,x_n)\) happen at the same point.
Remark. If the parametric space \(\Theta\) is finite, the maximum can be found by exhaustive enumeration of the values \(\{\mathcal{L}(\boldsymbol{\theta};x_1,\ldots,x_n):\boldsymbol{\theta}\in\Theta\}\) (as done in Example 4.5).
If the cardinality of \(\Theta\) is infinity and \(\mathcal{L}(\boldsymbol{\theta};x_1,\ldots,x_n)\) is differentiable with respect to \(\theta\) in the interior of \(\Theta,\) then we only need to solve the so-called log-likelihood equations (usually simpler than the likelihood equations), which characterize the relative extremes of the log-likelihood function:
\[\begin{align*} \frac{\partial}{\partial \boldsymbol{\theta}}\ell(\boldsymbol{\theta};x_1,\ldots,x_n)=\mathbf{0} \iff \frac{\partial}{\partial \theta_k}\ell(\boldsymbol{\theta};x_1,\ldots,x_n)=0, \quad k=1,\ldots,K. \end{align*}\]
The global maximum is found by checking which of the relative extremes is a local maximum and comparing it with the boundary values of \(\Theta.\)
Remark. The score function is defined as \(\boldsymbol{\theta}\in\mathbb{R}^K \mapsto \frac{\partial}{\partial \boldsymbol{\theta}}\log f(x;\boldsymbol{\theta})\in\mathbb{R}^K.\) It plays a relevant role in likelihood theory since it builds the log-likelihood equations to solve:
\[\begin{align*} \frac{\partial}{\partial \boldsymbol{\theta}}\ell(\boldsymbol{\theta};x_1,\ldots,x_n)=\sum_{i=1}^n \frac{\partial}{\partial \boldsymbol{\theta}}\log f(x_i;\boldsymbol{\theta}). \end{align*}\]
Example 4.6 Let \((X_1,\ldots,X_n)\) be a srs of \(X\sim\mathcal{N}(\mu,\sigma^2).\) Let us obtain the MLE of \(\mu\) and \(\sigma^2.\)
Since \(\boldsymbol{\theta}=(\mu,\sigma^2)',\) the parametric space is \(\Theta=\mathbb{R}\times\mathbb{R}_+.\) The likelihood of \(\boldsymbol{\theta}\) is given by
\[\begin{align*} \mathcal{L}(\mu,\sigma^2;X_1,\ldots,X_n)=\frac{1}{(\sqrt{2\pi\sigma^2})^n}\exp\left\{-\frac{1}{2\sigma^2}\sum_{i=1}^n(X_i-\mu)^2\right\} \end{align*}\]
and the log-likelihood by
\[\begin{align*} \ell(\mu,\sigma^2;X_1,\ldots,X_n)=-\frac{n}{2}\log(2\pi\sigma^2)-\frac{1}{2\sigma^2}\sum_{i=1}^n(X_i-\mu)^2. \end{align*}\]
The derivatives with respect to \(\mu\) and \(\sigma^2\) are
\[\begin{align*} \frac{\partial \ell}{\partial \mu} &=\frac{1}{\sigma^2}\sum_{i=1}^n (X_i-\mu)=0,\\ \frac{\partial \ell}{\partial \sigma^2} &= -\frac{n}{2}\frac{1}{\sigma^2}+\frac{\sum_{i=1}^n(X_i-\mu)^2}{2\sigma^4}=0. \end{align*}\]
The solution to the log-likelihood equations is
\[\begin{align*} \hat{\mu}=\bar{X}, \quad \hat{\sigma}^2=\frac{1}{n}\sum_{i=1}^n (X_i-\bar{X})^2=S^2. \end{align*}\]
We can see that the solution is not a minimum,45 since taking the limit when \(\sigma^2\) approaches zero we obtain
\[\begin{align*} \lim_{\sigma^2 \downarrow 0} \mathcal{L}(\mu,\sigma^2;X_1,\ldots,X_n)=0 <\mathcal{L}(\mu,\sigma^2;X_1,\ldots,X_n), \quad \forall \mu\in\mathbb{R}, \forall \sigma^2>0. \end{align*}\]
In particular,
\[\begin{align*} \lim_{\sigma^2 \downarrow 0} \mathcal{L}(\mu,\sigma^2;X_1,\ldots,X_n)=0 <\mathcal{L}(\hat{\mu},\hat{\sigma}^2;X_1,\ldots,X_n). \end{align*}\]
This means that the solution is not a minimum. If the second derivatives were computed, it could be seen that the Hessian matrix evaluated at \((\hat{\mu},\hat{\sigma}^2)\) is negatively defined, so \(\hat{\mu}\) and \(\hat{\sigma}^2\) are maximizers of the likelihood. Therefore, \(\hat{\mu}_{\mathrm{MLE}}=\bar{X}\) and \(\hat{\sigma}^2_{\mathrm{MLE}}=S^2.\)
Remark. The normal distribution is the only distribution for which the MLE of its location parameter is the sample mean \(\bar{X}.\) Precisely, in the class of pdf’s \(\{f(\cdot-\theta):\theta\in\Theta\}\) with differentiable \(f,\) if the MLE of \(\theta\) is \(\hat{\theta}_{\mathrm{MLE}}=\bar{X},\) then \(f=\phi.\) This result dates back to Gauss (1809).
The previous example shows that the MLE does not have to be necessarily unbiased, since the sample variance \(S^2\) is a biased estimator of the variance \(\sigma^2.\)
Example 4.7 Consider a continuous parametric space \(\Theta=[0,1]\) for the experiment of Example 4.5. Let us obtain the MLE of \(\theta.\)
In the first place, observe that \(\Theta\) is a closed and bounded interval. A continuous function defined on such an interval always has a maximum, that may be in the interval extremes. Therefore, in this situation we must compare the solutions to the log-likelihood with the extremes of the interval.
The likelihood is
\[\begin{align*} \mathcal{L}(\theta;x)=\binom{2}{x}\theta^x(1-\theta)^{2-x}, \quad x=0,1,2. \end{align*}\]
The log-likelihood is then
\[\begin{align*} \ell(\theta;x)=\log\binom{2}{x}+x\log\theta+(2-x)\log(1-\theta), \end{align*}\]
with derivative
\[\begin{align*} \frac{\partial \ell}{\partial \theta}=\frac{x}{\theta}-\frac{2-x}{1-\theta}. \end{align*}\]
Equating to zero this derivative, and assuming that \(\theta\neq 0,1\) (boundary of \(\Theta,\) where \(\ell\) is not differentiable), we obtain the equation
\[\begin{align*} x(1-\theta)-(2-x)\theta=0. \end{align*}\]
Solving for \(\theta,\) we obtain
\[\begin{align*} \hat{\theta}=\frac{x}{2}, \end{align*}\]
that is, the proportion of heads obtained in the two tosses. Comparing the likelihood evaluated at \(\hat{\theta}\) with the one of the values of \(\theta\) at the boundary of \(\Theta,\) we have
\[\begin{align*} \mathcal{L}(0;x)=\mathcal{L}(1;x)=0\leq \mathcal{L}(\hat{\theta};x). \end{align*}\]
Therefore, \(\hat{\theta}_\mathrm{MLE}=X/2.\)46
The following example shows a likelihood that is not continuous for all the possible values of \(\theta\) but that it delivers the MLE of \(\theta.\)
Example 4.8 Let \(X\sim \mathcal{U}(0,\theta)\) with pdf
\[\begin{align*} f(x;\theta)=\frac{1}{\theta}1_{\{0\leq x\leq \theta\}}, \quad \theta>0, \end{align*}\]
where \(\theta\) is unknown, and let \((X_1,\ldots,X_n)\) be a srs of \(X.\) Let us compute the MLE of \(\theta.\)
The likelihood is given by
\[\begin{align*} \mathcal{L}(\theta;X_1,\ldots,X_n)=\frac{1}{\theta^n}, \quad 0\leq X_1,\ldots,X_n\leq \theta. \end{align*}\]
The restriction involving \(\theta\) can be included within the likelihood function (which will take otherwise the value \(0\)), rewriting it as
\[\begin{align*} \mathcal{L}(\theta;X_1,\ldots,X_n)=\frac{1}{\theta^n}1_{\{X_{(1)}\geq0\}}1_{\{X_{(n)}\leq\theta\}}. \end{align*}\]
We can observe that for \(\theta>X_{(n)},\) \(\mathcal{L}\) decreases when \(\theta\) increases, that is, \(\mathcal{L}\) is decreasing in \(\theta\) for \(\theta>X_{(n)}.\) However, for \(\theta<X_{(n)},\) the likelihood is zero. Therefore, the maximum is attained precisely at \(\hat{\theta}=X_{(n)}\) and, as a consequence, \(\hat{\theta}_{\mathrm{MLE}}=X_{(n)}.\) Figure 4.3 helps visualizing this reasoning.
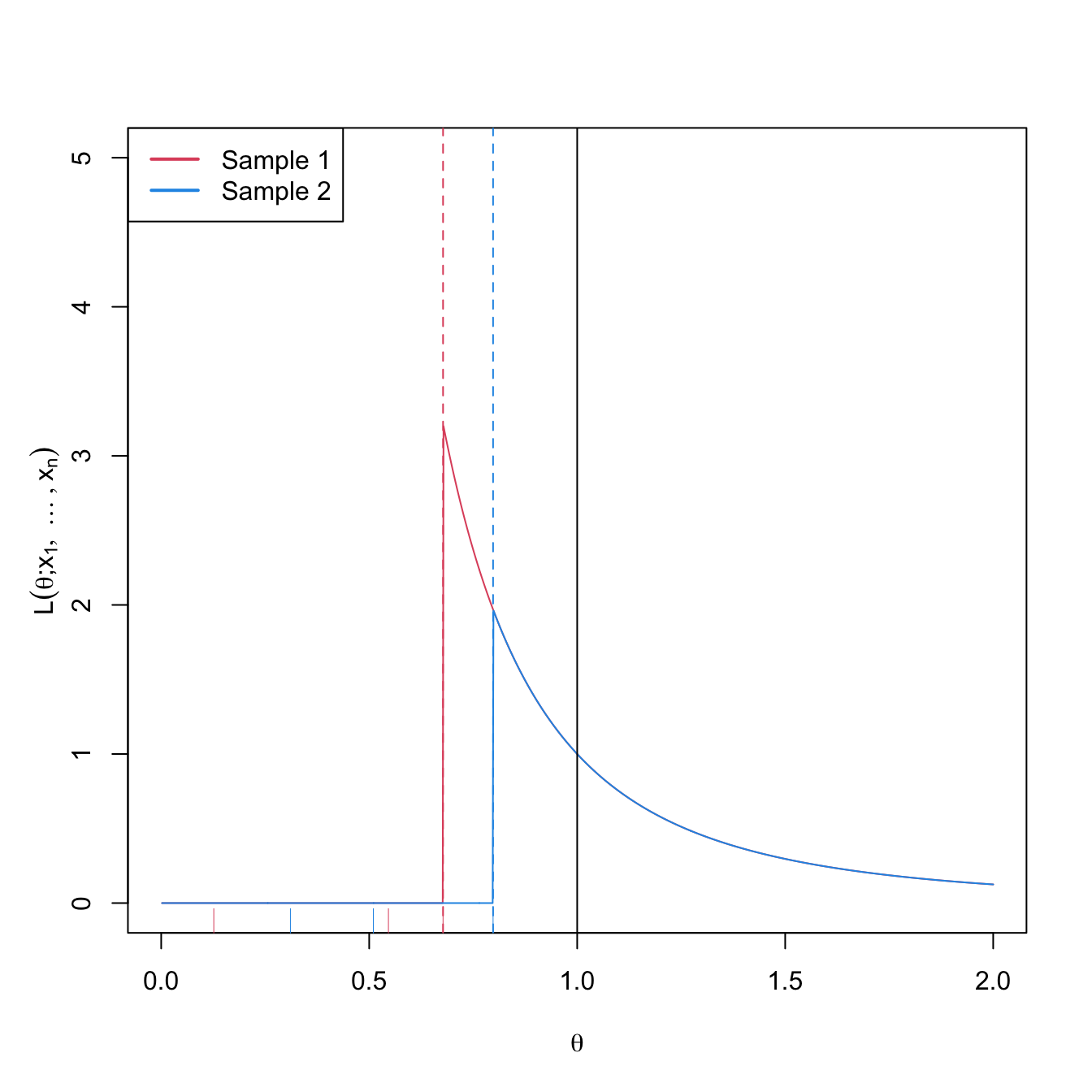
Figure 4.3: Likelihood \(\mathcal{L}(\theta;x_1,\ldots,x_n)\) as a function of \(\theta\in \lbrack0,1\rbrack\) for \(\mathcal{U}(0,\theta),\) \(\theta=1,\) and two different samples (red and blue) with \(n=3.\) The dashed vertical lines represent \(\hat{\theta}_{\mathrm{MLE}}=x_{(n)}\) (for the red and blue samples) and \(\theta=1\) is shown in black. The ticks on the horizontal axis represent the two samples.
The next example shows that the MLE does not have to be unique.
Example 4.9 Let \(X\sim \mathcal{U}(\theta-1,\theta+1)\) with pdf
\[\begin{align*} f(x;\theta)=\frac{1}{2}1_{\{x\in[\theta-1,\theta+1]\}}, \end{align*}\]
where \(\theta>0\) is unknown, and let \((X_1,\ldots,X_n)\) be a srs of \(X.\) Let us compute the MLE of \(\theta.\)
The likelihood is given by
\[\begin{align*} \mathcal{L}(\theta;X_1,\ldots,X_n)=\frac{1}{2^n}1_{\{X_{(1)}\geq \theta-1\}} 1_{\{X_{(n)}\leq \theta+1\}}=\frac{1}{2^n}1_{\{X_{(n)}-1\leq \theta\leq X_{(1)}+1\}}. \end{align*}\]
Therefore, \(\mathcal{L}(\theta;X_1,\ldots,X_n)\) is constant for any value of \(\theta\) in the interval \([X_{(n)}-1,X_{(1)}+1],\) and is zero if \(\theta\) is not in that interval. This means that any value inside \([X_{(n)}-1,X_{(1)}+1]\) is a maximum and, therefore, a MLE.
The MLE is a function of any sufficient statistic. However, this function does not have to be bijective, and as a consequence, the MLE is not guaranteed to be sufficient (any sufficient statistic can be transformed into the MLE, but the MLE can not be transformed into any sufficient statistic). The next example shows a MLE that is not sufficient.
Example 4.10 Let \(X\sim\mathcal{U}(\theta,2\theta)\) with pdf
\[\begin{align*} f(x;\theta)=\frac{1}{\theta}1_{\{\theta\leq x\leq 2\theta\}}, \end{align*}\]
where \(\theta>0\) is unknown. Obtain the MLE of \(\theta\) from a srs \((X_1,\ldots,X_n).\)
The likelihood is
\[\begin{align*} \mathcal{L}(\theta;X_1,\ldots,X_n)=\frac{1}{\theta^n}1_{\{X_{(1)}\geq \theta\}}1_{\{X_{(n)}\leq 2\theta\}}=\frac{1}{\theta^n}1_{\{X_{(n)}/2\leq \theta\leq X_{(1)}\}}. \end{align*}\]
Because of Theorem 3.5, the statistic
\[\begin{align*} T=(X_{(1)},X_{(n)}) \end{align*}\]
is sufficient. On the other hand, since \(\mathcal{L}(\theta;X_1,\ldots,X_n)\) is decreasing in \(\theta,\) then the maximum is obtained at
\[\begin{align*} \hat{\theta}=\frac{X_{(n)}}{2}, \end{align*}\]
which is not sufficient, since \(\mathcal{L}(\theta;X_1,\ldots,X_n)\) can not be factorized adequately.
In addition, the MLE verifies that if there exists an unbiased and efficient estimator for \(\theta,\) then this has to be the unique MLE of \(\theta.\)
Proposition 4.2 (Invariance of the MLE) The MLE is invariant with respect to bijective transformations of the parameter. That is, if \(\phi=h(\theta),\) where \(h\) is bijective and \(\hat{\theta}\) is the MLE of \(\theta\in\Theta,\) then \(\hat{\phi}=h(\hat{\theta})\) is the MLE of \(\phi\in \Phi=h(\Theta).\)47
Proof (Proof of Proposition 4.2). Let \(\mathcal{L}_{\theta}(\theta;X_1,\ldots,X_n)\) be the likelihood of \(\theta\) for the srs \((X_1,\ldots,X_n).\) The likelihood of \(\phi\) verifies
\[\begin{align*} \mathcal{L}_{\phi}(\phi;X_1,\ldots,X_n)=\mathcal{L}_{\theta}(\theta;X_1,\ldots,X_n)=\mathcal{L}_{\theta}(h^{-1}(\phi);X_1,\ldots,X_n), \quad\forall \phi\in\Phi. \end{align*}\]
If \(\hat{\theta}\) is the MLE of \(\theta\) then, by definition,
\[\begin{align*} \mathcal{L}_\theta(\hat{\theta};X_1,\ldots,X_n)\geq\mathcal{L}_\theta(\theta;X_1,\ldots,X_n), \quad \forall \theta\in \Theta. \end{align*}\]
Denote \(\hat{\phi}=h(\hat{\theta}).\) Since \(h\) is bijective, \(\hat{\theta}=h^{-1}(\hat{\phi}).\) Then, it follows that
\[\begin{align*} \mathcal{L}_\phi(\hat{\phi};X_1,\ldots,X_n)&=\mathcal{L}_\theta(h^{-1}(\hat{\phi});X_1,\ldots,X_n)=\mathcal{L}_\theta(\hat{\theta};X_1,\ldots,X_n) \\ &\geq \mathcal{L}_\theta(\theta;X_1,\ldots,X_n)=\mathcal{L}_\theta(h^{-1}(\phi);X_1,\ldots,X_n)\\ &=\mathcal{L}_\phi(\phi;X_1,\ldots,X_n), \quad\forall \phi\in\Phi. \end{align*}\]
Therefore, \(\hat{\phi}\) is the MLE of \(\phi=h(\theta).\)
Example 4.11 The lifetime of certain type of light bulbs is a rv \(X\sim\mathrm{Exp}(1/\theta).\) After observing the lifetime of \(n\) of them, we wish to estimate the probability that the lifetime of a light bulb is above \(500\) hours. Let us derive a MLE for this probability.
The pdf of \(X\) is
\[\begin{align*} f(x;\theta)=\frac{1}{\theta}e^{-x/\theta}, \quad \theta>0,\ x>0. \end{align*}\]
The probability that a light bulb lasts more than \(500\) hours is
\[\begin{align*} \mathbb{P}(X>500)=\int_{500}^{\infty} \frac{1}{\theta}\exp\left\{-\frac{x}{\theta}\right\}\,\mathrm{d}x=\left[-\exp\left\{-\frac{x}{\theta}\right\}\right]_{500}^{\infty}=e^{-500/\theta}. \end{align*}\]
Then, the parameter to estimate is
\[\begin{align*} \phi=e^{-500/\theta}. \end{align*}\]
If we derive \(\hat{\theta}_\mathrm{MLE},\) then by Proposition 4.2 we directly obtain \(\hat{\phi}_\mathrm{MLE}\) with \(\hat{\phi}_\mathrm{MLE}=h(\hat{\theta}_\mathrm{MLE}).\)
For the srs \((X_1,\ldots,X_n),\) the likelihood of \(\theta\) is
\[\begin{align*} \mathcal{L}(\theta;X_1,\ldots,X_n)=\frac{1}{\theta^n}\exp\left\{-\frac{\sum_{i=1}^n X_i}{\theta}\right\}. \end{align*}\]
The log-likelihood of \(\theta\) is
\[\begin{align*} \ell(\theta;X_1,\ldots,X_n)=-n\log\theta-\frac{\sum_{i=1}^n X_i}{\theta}=-n\log\theta-\frac{n\bar{X}}{\theta}. \end{align*}\]
Differentiating and equating to zero,
\[\begin{align*} \frac{\partial \ell}{\partial \theta}=-\frac{n}{\theta}+\frac{n\bar{X}}{\theta^2}=0. \end{align*}\]
Since \(\theta\neq 0,\) then solving for \(\theta,\) we get
\[\begin{align*} \hat{\theta}=\bar{X}. \end{align*}\]
The second log-likelihood derivative is
\[\begin{align*} \frac{\partial^2\ell}{\partial \theta^2}=\frac{n}{\theta^2}-\frac{2n\bar{X}}{\theta^3}=\frac{1}{\theta^2}\left(n-\frac{2n\bar{X}}{\theta}\right). \end{align*}\]
If we evaluate the second derivative at \(\bar{X},\) we get
\[\begin{align*} \left.\frac{\partial^2 \ell}{\partial \theta^2}\right|_{\theta=\bar{X}}=\frac{1}{\bar{X}^2}\left(n-\frac{2n\bar{X}}{\bar{x}}\right)=-\frac{n}{\bar{X}^2}<0,\quad \forall n>0. \end{align*}\]
Therefore, \(\hat{\theta}=\bar{X}\) is a local maximum. Since \(\Theta=\mathbb{R}_+\) is open and \(\hat{\theta}\) is the unique local maximum, then it is a global maximum and hence \(\hat{\theta}_\mathrm{MLE}=\bar{X}.\) Therefore, \(\hat{\phi}_\mathrm{MLE}=e^{-500/\bar{X}}.\)
4.2.2 Asymptotic properties
Uniparameter case
One of the most important properties of the MLE is that its asymptotic distribution is completely specified, no matter what is the underlying parametric model as long as it is “regular enough”. The following theorem states the result for the case in which there is only one parameter that is estimated.
Theorem 4.1 (Asymptotic distribution of the MLE; uniparameter case) Let \(X\sim f(\cdot;\theta)\) be a continuous rv48 whose distribution depends on an unknown single parameter \(\theta\in\Theta\subset\mathbb{R}.\) Under certain regularity conditions, any sequence \(\hat{\theta}_n\) of roots for the likelihood equation such that \(\hat{\theta}_n\stackrel{\mathbb{P}}{\longrightarrow}\theta\) verifies that
\[\begin{align*} \sqrt{n}(\hat{\theta}_n-\theta)\stackrel{d}{\longrightarrow}\mathcal{N}(0,\mathcal{I}(\theta)^{-1}). \end{align*}\]
The full list of regularity conditions can be checked in Theorem 2.6 (Section 6.2, page 440) and Theorem 3.10 (Section 6.3, page 449) in Lehmann and Casella (1998). The key points in these assumptions are:
- The parameter space \(\Theta\) is an open interval of \(\mathbb{R}.\)
- The support of the pdf \(f(\cdot;\theta),\) \(\mathrm{supp}(f):=\{x\in\mathbb{R}:f(x;\theta)>0\},\) is independent from \(\theta.\)
- \(f(\cdot;\theta)\) is three times differentiable and bounded with respect to \(\theta\in\Theta\): \(\left|\partial^3 f(x;\theta)/\partial\theta^3 \right|\leq M(x),\) for all \(x\in \mathrm{supp}(f).\)
- The Fisher information is such that \(0<\mathcal{I}(\theta)<\infty.\)
The thesis of Theorem 4.1 can be stated as \(\hat{\theta}_\mathrm{MLE}\cong\mathcal{N}(\theta,(n\mathcal{I}(\theta))^{-1}).\) Therefore, the MLE is asymptotically unbiased and asymptotically efficient, in the efficiency sense introduced in Definition 3.13. This means that when the sample size grows, there is no better estimator than the MLE in terms of the MSE. Caveats apply, though, as this is an asymptotic result49 that is derived under the above-mentioned regularity conditions.50
Corollary 4.1 (Asymptotic unbiasedness and efficiency of the MLE) Under the conditions of Theorem 4.1, the estimator \(\hat{\theta}_\mathrm{MLE}\) verifies
\[\begin{align*} \lim_{n\to\infty}\mathbb{E}\big[\hat{\theta}_\mathrm{MLE}\big]=\theta\quad \text{and}\quad \lim_{n\to\infty}\frac{\mathbb{V}\mathrm{ar}\big[\hat{\theta}_\mathrm{MLE}\big]}{(\mathcal{I}_n(\theta))^{-1}}=1. \end{align*}\]
Figure 4.4 gives an insightful visualization of the asymptotic distribution in Theorem 4.1 using Example 4.12.
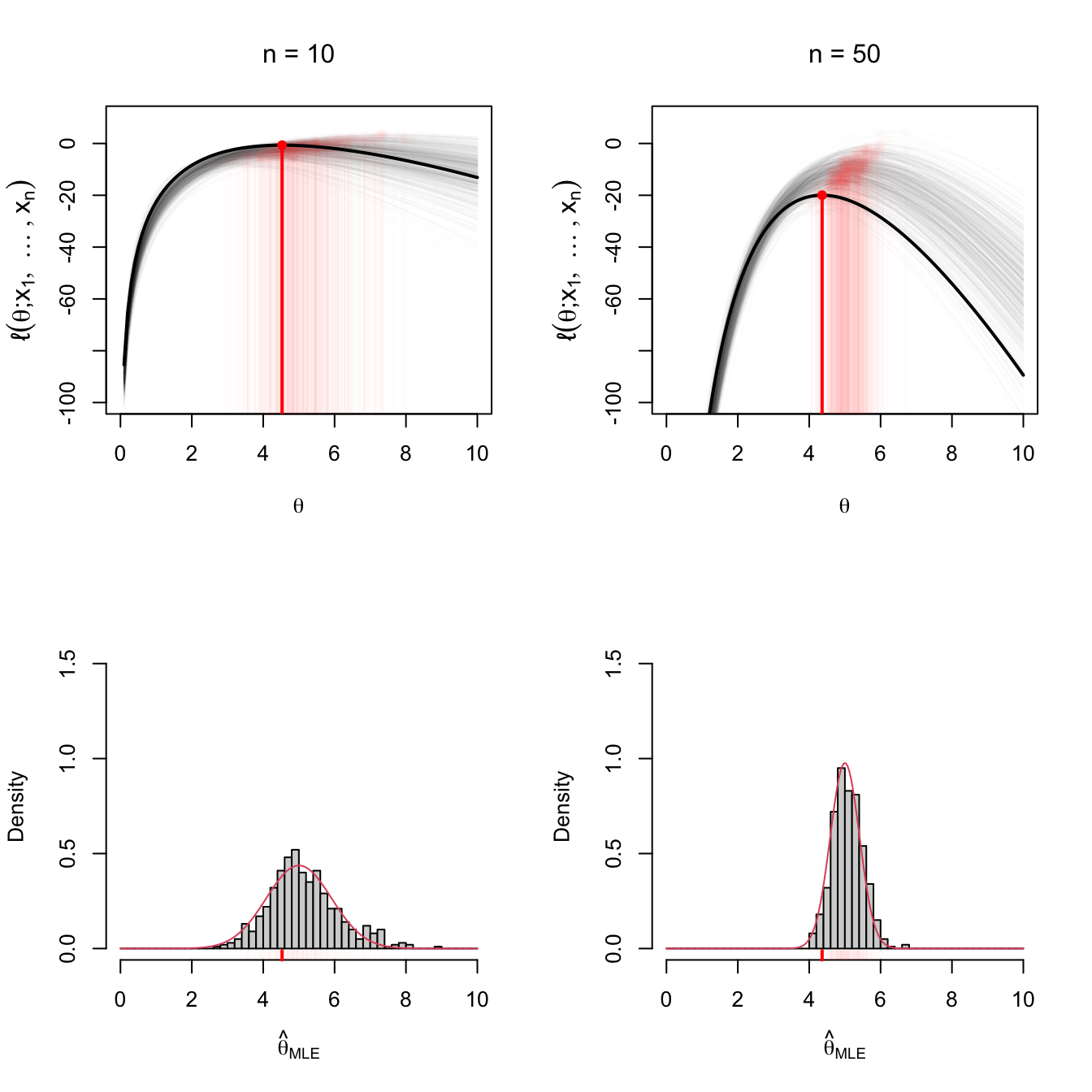
Figure 4.4: Visualization of maximum likelihood estimation. The top row shows the (sample-dependent) log-likelihood functions \(\theta\mapsto\ell(\theta)\) for \(M=500\) samples of sizes \(n=10\) (left) and \(n=50\) (right). The maximizer of each log-likelihood curve, \(\hat{\theta}_{\mathrm{MLE}},\) are shown in red. A particular curve and estimator are highlighted. The bottom row shows histograms of the \(M=500\) estimators for \(n=10,50\) and the density of \(\mathcal{N}(\theta,(n\mathcal{I}(\theta))^{-1}).\) Observe the increment in the curvature of the log-likelihood and the reduction of variance on \(\hat{\theta}_{\mathrm{MLE}}\) when \(n=10\) and \(n=50.\) The model employed in the figure is Example 4.12 with \(k=3\) and \(\theta=5\).
Example 4.12 Let \((X_1,\ldots,X_n)\) be a srs of the pdf
\[\begin{align} f(x;k,\theta)=\frac{\theta^k}{\Gamma(k)}x^{k-1}e^{-\theta x}, \quad x>0, \ k>0, \ \theta>0, \tag{4.2} \end{align}\]
where \(k\) is the shape and \(\theta\) is the rate. Note that this is the pdf of a \(\Gamma(k,1/\theta)\) as defined in Example 1.21 – the scale \(1/\theta\) is the inverse of the rate \(\theta.\)51 \(\!\!^,\)52
We assume \(k\) is known and \(\theta\) is unknown in this example to compute the MLE of \(\theta\) and find its asymptotic distribution.
The likelihood is given by
\[\begin{align*} \mathcal{L}(\theta;X_1,\ldots,X_n)=\frac{\theta^{nk}}{(\Gamma(k))^n}\left(\prod_{i=1}^n X_i\right)^{k-1}e^{-\theta\sum_{i=1}^n X_i}. \end{align*}\]
The log-likelihood is then
\[\begin{align*} \ell(\theta;X_1,\ldots,X_n)=nk\log\theta-n\log\Gamma(k)+(k-1)\sum_{i=1}^n\log X_i-\theta\sum_{i=1}^n X_i. \end{align*}\]
Differentiating with respect to \(\theta,\) we get
\[\begin{align*} \frac{\partial \ell}{\partial \theta}=\frac{nk}{\theta}-n\bar{X}=0. \end{align*}\]
Then, the solution of the log-likelihood equation is \(\hat{\theta}=k/\bar{X}.\) In addition, \(\partial \ell/\partial \theta>0\) if \(\theta\in(0,k/\bar{X}),\) while \(\partial \ell/\partial \theta<0\) if \(\theta\in(k/\bar{X},\infty).\) Therefore, \(\ell\) is increasing in \((0,k/\bar{X})\) and decreasing in \((k/\bar{X},\infty),\) which means that it attains the maximum at \(k/\bar{X}.\) Therefore, \(\hat{\theta}_{\mathrm{MLE}}=k/\bar{X}.\)
We compute next the Fisher information of \(f(\cdot;\theta).\) For that, we first obtain
\[\begin{align*} \log f(x;\theta)&=k\log\theta-\log\Gamma(k)+(k-1)\log x-\theta x,\\ \frac{\partial \log f(x;\theta)}{\partial \theta}&=\frac{k}{\theta}-x. \end{align*}\]
Squaring and taking expectations, we get53
\[\begin{align} \mathcal{I}(\theta)=\mathbb{E}\left[\left(\frac{\partial \log f(X;\theta)}{\partial \theta}\right)^2\right]=\mathbb{E}\left[\left(\frac{k}{\theta}-X\right)^2\right]=\mathbb{V}\mathrm{ar}[X]=\frac{k}{\theta^2}.\tag{4.3} \end{align}\]
Applying Theorem 4.1, we have that
\[\begin{align*} \sqrt{n}(\hat{\theta}_{\mathrm{MLE}}-\theta)\stackrel{d}{\longrightarrow}\mathcal{N}\left(0,\frac{\theta^2}{k}\right), \end{align*}\]
which means that for large \(n,\)
\[\begin{align*} \hat{\theta}_{\mathrm{MLE}}\cong \mathcal{N}\left(\theta,\frac{\theta^2}{nk}\right). \end{align*}\]
The visualization in Figure 4.4 serves also to introduce a new optic on the Fisher information \(\mathcal{I}(\theta).\) Let us assume that \(X\sim f(\cdot;\theta)\) and that \(\Theta\) and \(f(\cdot;\theta)\) check the full list of regularity conditions above mentioned, which afford the applicability of the Leibnitz integral rule.54 Then, the expectation of the score function is null:
\[\begin{align*} \mathbb{E}\left[\frac{\partial \log f(X; \theta)}{\partial \theta} \right]=&\;\int_{\mathbb{R}} \frac{\partial \log f(x; \theta)}{\partial \theta} f(x; \theta) \,\mathrm{d} x \\ =&\;\int_{\mathbb{R}} \frac{1}{f(x; \theta)} \frac{\partial f(x; \theta)}{\partial \theta} f(x; \theta) \,\mathrm{d} x \\ =&\;\frac{\partial}{\partial \theta}\int_{\mathbb{R}} f(x; \theta) \,\mathrm{d} x \\ =&\;0. \end{align*}\]
Therefore, the Fisher information \(\mathcal{I}(\theta)=\mathbb{E}[(\partial \log f(X; \theta)/\partial \theta)^2]\) is the variance of the score function. Similarly, \(\mathbb{E}[\partial \ell(\theta;X_1,\ldots,X_n)/\partial \theta]=0\) and \(\mathcal{I}_n(\theta)=\mathbb{V}\mathrm{ar}[\partial \ell(\theta;X_1,\ldots,X_n)/\partial \theta].\) Hence, \(\mathcal{I}_n(\theta)\) informs about the expected variability of the relative maximum, \(\hat{\theta}_\mathrm{MLE},\) of the log-likelihood: if large, it means that the relative maximum is hard to detect; if small, the relative maximum is well-localized.
Example 4.13 Check that
\[\begin{align} \mathcal{I}(\theta)=-\mathbb{E}\left[\frac{\partial^2 \log f(X; \theta)}{\partial \theta^2}\right].\tag{4.4} \end{align}\]
Expanding the second derivative, we get that
\[\begin{align*} \frac{\partial^2 \log f(x; \theta)}{\partial \theta^2}=&\;\frac{\partial }{\partial \theta}\left[\frac{1}{f(x; \theta)} \frac{\partial f(x; \theta)}{\partial \theta}\right]\\ =&\;-\frac{1}{f(x; \theta)^2}\left(\frac{\partial f(x; \theta)}{\partial \theta}\right)^2+\frac{1}{f(x; \theta)}\frac{\partial^2 f(x; \theta)}{\partial \theta^2}\\ =&\;-\left(\frac{\partial \log f(x; \theta)}{\partial \theta} \right)^2+\frac{1}{f(x; \theta)}\frac{\partial^2 f(x; \theta)}{\partial \theta^2}. \end{align*}\]
The desired equality follows by realizing that the expectation of the first term is zero due to the Leibniz integral rule.
From the equality (4.4), another equivalent view of the Fisher information \(\mathcal{I}(\theta)\) is the expected curvature of the log-likelihood function \(\theta\mapsto\ell(\theta;X_1,\ldots,X_n)\) at \(\theta\) (the true value of the parameter). More precisely, it gives the curvature factor that only depends on the model, since the expected curvature of the log-likelihood function at \(\theta\) is \(\mathcal{I}_n(\theta)=n\mathcal{I}(\theta).\) Therefore, the larger the Fisher information, the more convex and sharper the log-likelihood function is at \(\theta\), resulting in \(\hat{\theta}_\mathrm{MLE}\) being more concentrated about \(\theta.\)
Example 4.14 From Example 4.13, the Fisher information in (4.3) can be computed as
\[\begin{align*} \mathcal{I}(\theta)=-\mathbb{E}\left[\frac{\partial^2 \log f(X;\theta)}{\partial \theta^2}\right]=-\mathbb{E}\left[-\frac{k}{\theta^2}\right]=\frac{k}{\theta^2}. \end{align*}\]
Analogously, the Fisher information in (3.9) can be computed as
\[\begin{align*} \mathcal{I}(\lambda)=-\mathbb{E}\left[\frac{\partial^2 \log p(X;\lambda)}{\partial \lambda^2}\right]=-\mathbb{E}\left[-\frac{X}{\lambda^2}\right]=\frac{\mathbb{E}[X]}{\lambda^2}=\frac{1}{\lambda}. \end{align*}\]
Multiparameter case
The extension of Theorem 4.1 to the multiparameter case in which a vector parameter \(\boldsymbol{\theta}\in\Theta\subset\mathbb{R}^K\) is estimated requires from the extension of the Fisher information given in Definition 3.12.
Definition 4.3 (Fisher information matrix) Let \(X\sim f(\cdot;\boldsymbol{\theta})\) be a continuous rv with \(\boldsymbol{\theta}\in\Theta\subset\mathbb{R}^K.\) The Fisher information matrix of \(X\) about \(\boldsymbol{\theta}\) is defined as55
\[\begin{align} \boldsymbol{\mathcal{I}}(\boldsymbol{\theta}):=\mathbb{E}\left[\left(\frac{\partial \log f(x;\boldsymbol{\theta})}{\partial \boldsymbol{\theta}}\right)\left(\frac{\partial \log f(x;\boldsymbol{\theta})}{\partial \boldsymbol{\theta}}\right)'\right].\tag{4.5} \end{align}\]
Example 4.15 The Fisher information matrix for a \(\mathcal{N}(\mu,\sigma^2)\) is
\[\begin{align*} \boldsymbol{\mathcal{I}}(\mu, \sigma^2)=\begin{pmatrix} 1 / \sigma^2 & 0 \\ 0 & 1 / (2\sigma^4) \end{pmatrix}. \end{align*}\]
Example 4.16 The Fisher information matrix for a \(\Gamma(\alpha,\beta)\) (as parametrized in (2.2)) is
\[\begin{align*} \boldsymbol{\mathcal{I}}(\alpha, \beta)=\begin{pmatrix} \psi'(\alpha) & 1 / \beta \\ 1 / \beta & \alpha / \beta^2 \end{pmatrix}, \end{align*}\]
where \(\psi(\alpha):=\Gamma'(\alpha) / \Gamma(\alpha)\) is the digamma function.
Example 4.17 The Fisher information matrix for a \(\mathrm{Beta}(\alpha,\beta)\) (as parametrized in Exercise 3.19) is
\[\begin{align*} \boldsymbol{\mathcal{I}}(\alpha, \beta)=\begin{pmatrix} \psi'(\alpha)-\psi'(\alpha+\beta) & -\psi'(\alpha+\beta) \\ -\psi'(\alpha+\beta) & \psi'(\beta)-\psi'(\alpha+\beta) \end{pmatrix}. \end{align*}\]
The following theorem is an adaptation of Theorem 5.1 (Section 6.5, page 463) in Lehmann and Casella (1998), where the regularity conditions can be checked. The key points of these conditions are analogous to those in the uniparameter case.
Theorem 4.2 (Asymptotic distribution of the MLE; multiparameter case) Let \(X\sim f(\cdot;\boldsymbol{\theta})\) be a continuous rv56 whose distribution depends on an unknown vector parameter \(\boldsymbol{\theta}\in\Theta\subset\mathbb{R}^K.\) Under certain regularity conditions, with probability tending to \(1\) as \(n\to\infty,\) there exist roots \(\hat{\boldsymbol{\theta}}_n=(\hat{\theta}_{1n},\ldots,\hat{\theta}_{Kn})'\) of the likelihood equations such that:
- For \(k=1,\ldots,K,\) \(\hat{\theta}_{kn}\stackrel{\mathbb{P}}{\longrightarrow}\theta_k.\)
- For \(k=1,\ldots,K,\) \[\begin{align} \sqrt{n}(\hat{\theta}_{kn}-\theta_k)\stackrel{d}{\longrightarrow} \mathcal{N}\left(0,[\boldsymbol{\mathcal{I}}(\boldsymbol{\theta})^{-1}]_{kk}\right), \tag{4.6} \end{align}\] where \([\boldsymbol{\mathcal{I}}(\boldsymbol{\theta})^{-1}]_{kk}\) stands for the \((k,k)\)-entry of the matrix \(\boldsymbol{\mathcal{I}}(\boldsymbol{\theta})^{-1}.\)
- It also happens that57 \[\begin{align} \sqrt{n}(\hat{\boldsymbol{\theta}}_n-\boldsymbol{\theta})\stackrel{d}{\longrightarrow} \mathcal{N}_K\left(\boldsymbol{0},\boldsymbol{\mathcal{I}}(\boldsymbol{\theta})^{-1}\right). \tag{4.7} \end{align}\]
Remark. As in the uniparameter case, under the assumed regularity conditions, the Fisher information matrix (4.5) can be written as
\[\begin{align} \boldsymbol{\mathcal{I}}(\boldsymbol{\theta}):=-\mathbb{E}\left[\frac{\partial^2 \log f(x;\boldsymbol{\theta})}{\partial \boldsymbol{\theta}\partial\boldsymbol{\theta}'}\right], \end{align}\]
where \(\partial^2 \log f(x;\boldsymbol{\theta})/(\partial \boldsymbol{\theta}\partial\boldsymbol{\theta}')\) is the \(K\times K\) Hessian matrix of \(\boldsymbol{\theta}\mapsto f(x;\boldsymbol{\theta}).\)
Example 4.18 We can apply Theorem 4.2 to the MLE’s of \(\boldsymbol{\theta}=(\mu,\sigma^2)'\) in a \(\mathcal{N}(\mu,\sigma^2)\) rv. From Example 4.6, we know that \(\boldsymbol{\hat{\theta}}_{\mathrm{MLE}}=(\bar{X},S^2)'.\) Therefore, thanks to Example 4.15, we have that
\[\begin{align*} \sqrt{n}(\boldsymbol{\hat{\theta}}_{\mathrm{MLE}}-\boldsymbol{\theta})=\sqrt{n}\begin{pmatrix}\bar{X}-\mu\\S^2-\sigma^2\end{pmatrix} \stackrel{d}{\longrightarrow}\mathcal{N}_2\left(\begin{pmatrix}0\\0\end{pmatrix},\begin{pmatrix}\sigma^2&0\\0&2\sigma^4\end{pmatrix}\right). \end{align*}\]
This result shows several interesting insights:
- It proves that \(\bar{X}\) and \(S^2\) are asymptotically independent because they are asymptotically joint normal with null covariance. This result is weaker than Fisher’s Theorem (Theorem 2.2), which states that \(\bar{X}\) and \(S^2\) are independent for any sample size \(n.\) But here we are not assuming normality.
- It gives that \(\sqrt{n}(S^2-\sigma^2)\stackrel{d}{\longrightarrow} \mathcal{N}\left(0,2\sigma^4\right).\) This is equivalent to \(\frac{n}{\sigma^2}(S^2-\sigma^2)\cong \mathcal{N}\left(0,2n\right)\) and then to \(\frac{nS^2}{\sigma^2}\cong \mathcal{N}\left(n,2n\right).\) Recalling again Fisher’s Theorem, \(\frac{nS^2}{\sigma^2}\sim \chi^2_{n-1}.\) Both results are asymptotically equal due to the chi-square approximation (2.15).
We have corroborated that the exact and specific normal theory is indeed coherent with the asymptotic and general maximum likelihood theory.
Estimation of the Fisher information matrix
We conclude this section with two important results to turn (4.6) into a more actionable result in statistical inference: (1) replace \(\boldsymbol{\mathcal{I}}(\boldsymbol{\theta})\) (unknown if \(\boldsymbol{\theta}\) is unknown) with \(\boldsymbol{\mathcal{I}}(\hat{\boldsymbol{\theta}}_n)\) (computable); (2) replace \(\boldsymbol{\mathcal{I}}(\boldsymbol{\theta})\) (uncomputable in closed form in certain cases, even if \(\boldsymbol{\theta}\) is known) with an estimate \(\hat{\boldsymbol{\mathcal{I}}}(\boldsymbol{\theta})\) (always computable).
The first result is a direct consequence of the continuous mapping theorem (Theorem 3.3) and the Slutsky Theorem (Theorem 3.4). The result is enough for (uniparameter) inferential purposes on \(\theta_k.\)
Corollary 4.2 Assume the conditions of Theorem 4.2 holds and that the function \(\boldsymbol{\theta}\in\mathbb{R}^K\mapsto\big[\boldsymbol{\mathcal{I}}(\boldsymbol{\theta})^{-1}\big]_{kk}\in\mathbb{R}\) is continuous. Then, for \(k=1,\ldots,K,\)
\[\begin{align} \frac{\sqrt{n}(\hat{\theta}_{kn}-\theta_k)}{\sqrt{\big[\boldsymbol{\mathcal{I}}(\hat{\boldsymbol{\theta}}_n)^{-1}\big]_{kk}}}\stackrel{d}{\longrightarrow} \mathcal{N}(0,1). \tag{4.8} \end{align}\]
Proof (Proof of Corollary 4.2). Due to the assumed continuity of \(\boldsymbol{\theta}\mapsto\big[\boldsymbol{\mathcal{I}}(\boldsymbol{\theta})^{-1}\big]_{kk},\) a generalization of Theorem 3.3 implies that \(\big[\boldsymbol{\mathcal{I}}(\hat{\boldsymbol{\theta}}_n)^{-1}\big]_{kk}\stackrel{\mathbb{P}}{\longrightarrow}\big[\boldsymbol{\mathcal{I}}(\boldsymbol{\theta})^{-1}\big]_{kk}\) because of \(\hat{\boldsymbol{\theta}}_n\stackrel{\mathbb{P}}{\longrightarrow}\boldsymbol{\theta}\) (which holds, due to Theorem 4.2). Therefore, Theorem 3.4 guarantees that (4.8) is verified.
Remark. Corollary 4.2 can be generalized to the multiparameter case using the Cholesky decomposition58 of \(\boldsymbol{\mathcal{I}}(\boldsymbol{\theta})=\boldsymbol{R}(\boldsymbol{\theta})\boldsymbol{R}(\boldsymbol{\theta})'\) to first turn (4.7) into59
\[\begin{align} \sqrt{n}\boldsymbol{R}(\boldsymbol{\theta})'(\hat{\boldsymbol{\theta}}_n-\boldsymbol{\theta})\stackrel{d}{\longrightarrow} \mathcal{N}_K\left(\boldsymbol{0},\boldsymbol{I}_K\right) \tag{4.9} \end{align}\]
by using Proposition 1.12. Then,
\[\begin{align*} \sqrt{n}\boldsymbol{R}(\hat{\boldsymbol{\theta}}_n)'(\hat{\boldsymbol{\theta}}_n-\boldsymbol{\theta})\stackrel{d}{\longrightarrow} \mathcal{N}_K\left(\boldsymbol{0},\boldsymbol{I}_K\right). \end{align*}\]
Example 4.19 In Example 4.12 we obtained that
\[\begin{align*} \sqrt{n}(\hat{\theta}_{\mathrm{MLE}}-\theta)\stackrel{d}{\longrightarrow}\mathcal{N}\left(0,\frac{\theta^2}{k}\right) \end{align*}\]
or, equivalently, that
\[\begin{align*} \frac{\sqrt{n}(\hat{\theta}_{\mathrm{MLE}}-\theta)}{\theta/\sqrt{k}}\stackrel{d}{\longrightarrow}\mathcal{N}(0,1). \end{align*}\]
In virtue of Corollary 4.2, we can also write
\[\begin{align*} \frac{\sqrt{n}(\hat{\theta}_{\mathrm{MLE}}-\theta)}{\hat{\theta}_{\mathrm{MLE}}/\sqrt{k}}\stackrel{d}{\longrightarrow}\mathcal{N}(0,1). \end{align*}\]
The second result focuses on the form of \(\boldsymbol{\mathcal{I}}(\boldsymbol{\theta}).\) As we have seen so far, this Fisher information matrix is not always easy to compute. For example, in Examples 4.16 and 4.17, despite having closed-form solutions, these depend on derivatives of the digamma function. In other cases, the Fisher information matrix does not admit a closed form (see, e.g., Example 4.25). However, as advanced in Exercise 3.25 for the uniparameter case, the Fisher information matrix in (4.5) can be estimated by using its empirical version, in which the expectation is replaced with the sample mean obtained from a srs \((X_1,\ldots,X_n)\) of \(X\sim f(\cdot;\boldsymbol{\theta})\):
\[\begin{align} \hat{\boldsymbol{\mathcal{I}}}(\boldsymbol{\theta}):=\frac{1}{n}\sum_{i=1}^n\left(\frac{\partial \log f(X_i;\boldsymbol{\theta})}{\partial \boldsymbol{\theta}}\right)\left(\frac{\partial \log f(X_i;\boldsymbol{\theta})}{\partial \boldsymbol{\theta}}\right)'.\tag{4.10} \end{align}\]
The construction is analogous for a discrete rv. The matrix estimator (4.10) is always computable, as no integration is involved, only differentiation.
Due to the LLN (Theorem 3.2), we immediately have that
\[\begin{align*} \hat{\boldsymbol{\mathcal{I}}}(\boldsymbol{\theta})\stackrel{\mathbb{P}}{\longrightarrow}\boldsymbol{\mathcal{I}}(\boldsymbol{\theta}). \end{align*}\]
It can also be shown that, under the conditions of Theorem 4.2,
\[\begin{align*} \hat{\boldsymbol{\mathcal{I}}}(\hat{\boldsymbol{\theta}}_\mathrm{MLE})\stackrel{\mathbb{P}}{\longrightarrow}\boldsymbol{\mathcal{I}}(\boldsymbol{\theta}). \end{align*}\]
This gives the last result of this section, which provides the most usable asymptotic distribution of the MLE.
Corollary 4.3 Assume the conditions of Theorem 4.2 holds, that the function \(\boldsymbol{\theta}\in\mathbb{R}^K\mapsto \boldsymbol{\mathcal{I}}(\boldsymbol{\theta})^{-1} \in\mathbb{R}^{K\times K}\) is continuous, and that \(\hat{\boldsymbol{\mathcal{I}}}(\boldsymbol{\theta})=\hat{\boldsymbol{R}}(\boldsymbol{\theta})\hat{\boldsymbol{R}}(\boldsymbol{\theta})'\) and \(\hat{\boldsymbol{\mathcal{I}}}(\hat{\boldsymbol{\theta}}_n)=\hat{\boldsymbol{R}}(\hat{\boldsymbol{\theta}}_n)\hat{\boldsymbol{R}}(\hat{\boldsymbol{\theta}}_n)'\) are valid Cholesky decompositions. Then:
- \(\sqrt{n}\hat{\boldsymbol{R}}(\boldsymbol{\theta})'(\hat{\boldsymbol{\theta}}_n-\boldsymbol{\theta})\stackrel{d}{\longrightarrow} \mathcal{N}_K\left(\boldsymbol{0},\boldsymbol{I}_K\right).\)
- \(\sqrt{n}\hat{\boldsymbol{R}}(\hat{\boldsymbol{\theta}}_n)'(\hat{\boldsymbol{\theta}}_n-\boldsymbol{\theta})\stackrel{d}{\longrightarrow} \mathcal{N}_K\left(\boldsymbol{0},\boldsymbol{I}_K\right).\)
The corollary states that, if challenging or complicated, the Fisher information \(\boldsymbol{\mathcal{I}}(\boldsymbol{\theta})\) in the limit distribution of \(\sqrt{n}\hat{\boldsymbol{\theta}}_\mathrm{MLE}\) can be replaced with its estimators \(\hat{\boldsymbol{\mathcal{I}}}(\boldsymbol{\theta})\) or \(\hat{\boldsymbol{\mathcal{I}}}(\hat{\boldsymbol{\theta}}_\mathrm{MLE})\) without altering the asymptotic distribution of \(\sqrt{n}\hat{\boldsymbol{\theta}}_\mathrm{MLE}.\)
References
But note this does not prove that \((\hat{\mu},\hat{\sigma}^2)\) is a maximum.↩︎
We put \(X\) and not \(x\) because an estimator is a function of the srs, not of its realization.↩︎
\(h(\Theta):=\{h(\theta):\theta\in\Theta\}.\)↩︎
An analogous result can be stated as well for a discrete rv \(X\sim p(\cdot;\theta).\) We exclude it for the sake of simplicity.↩︎
There could be an estimator that beats the MLE in terms of MSE for \(n\leq 7,\) for example. Counterexamples exist, especially when \(\boldsymbol{X}\) and \(\boldsymbol{\theta}\) are high-dimensional and the sample size is small; see the James–Stein estimator.↩︎
Counterexamples exist also when the regularity conditions are not met.↩︎
Both the shape-rate and the scale-rate parametrizations of the gamma distribution are prevalent in statistics, and this is often a source of confusion. Therefore, when dealing with gamma variables it is better to state its pdf, either (2.2) or (4.2), to avoid ambiguities.↩︎
In R,
dgamma(..., shape = k, rate = theta)anddgamma(..., shape = alpha, scale = beta)to use (2.2) or (4.2).↩︎Observe that \(\mathbb{E}[\Gamma(k,1/\theta)]=k/\theta\) and \(\mathbb{V}\mathrm{ar}[\Gamma(k,1/\theta)]=k/\theta^2.\)↩︎
Specifically, check assumption (d) on page 441 in Lehmann and Casella (1998).↩︎
Note that \(\frac{\partial \log f(x;\boldsymbol{\theta})}{\partial \boldsymbol{\theta}}\) is a column vector.↩︎
Again, an analogous result can be stated as well for a discrete rv \(X\sim p(\cdot;\boldsymbol{\theta}).\) We exclude it for the sake of simplicity.↩︎
Remember the definition of a multivariate normal from Example 1.31.↩︎
Because \(\boldsymbol{\mathcal{I}}(\boldsymbol{\theta})\) is positive definite under the regularity conditions of Theorem 4.2, it admits a Cholesky decomposition \(\boldsymbol{\mathcal{I}}(\boldsymbol{\theta})=\boldsymbol{R}(\boldsymbol{\theta})\boldsymbol{R}(\boldsymbol{\theta})'\) with \(\boldsymbol{R}(\boldsymbol{\theta})\) a lower triangular matrix with positive diagonal entries.↩︎
Recall that \(\boldsymbol{\mathcal{I}}(\boldsymbol{\theta})^{-1}=(\boldsymbol{R}(\boldsymbol{\theta})^{-1})'\boldsymbol{R}(\boldsymbol{\theta})^{-1}.\)↩︎