B.3 Resources
B.3.1 Data in base R
As R includes a datasets package, every version of R comes with a collection of datasets. To learn which datasets exist and obtain basic information about them, call
To obtain information about any particular dataset x, call ?x.
Throughout this book, we use quite a few of the datasets in examples and exercises.
# Info on datasets:
?anscombe
?cars
?sleep
?Titanic
# Check dimensions:
dim(ChickWeight)
dim(iris)
dim(sleep) # Student's Sleep Data
dim(Titanic) # see also dim(FFTrees::titanic)As the datasets are included to illustrate particular types of data or tasks, they vary widely in size and shape.
For instance, the Titanic data is stored as a 4-dimensional array (but can easily be transformed into a data frame by as.data.frame(Titanic)). By contrast, the Nile dataset contains a single time series with measurement values of the annual flow of the river Nile from the years 1871 to 1970:
# ?Nile
length(Nile)
#> [1] 100
typeof(Nile)
#> [1] "double"
plot(Nile, col = unikn::Seeblau, lwd = 3)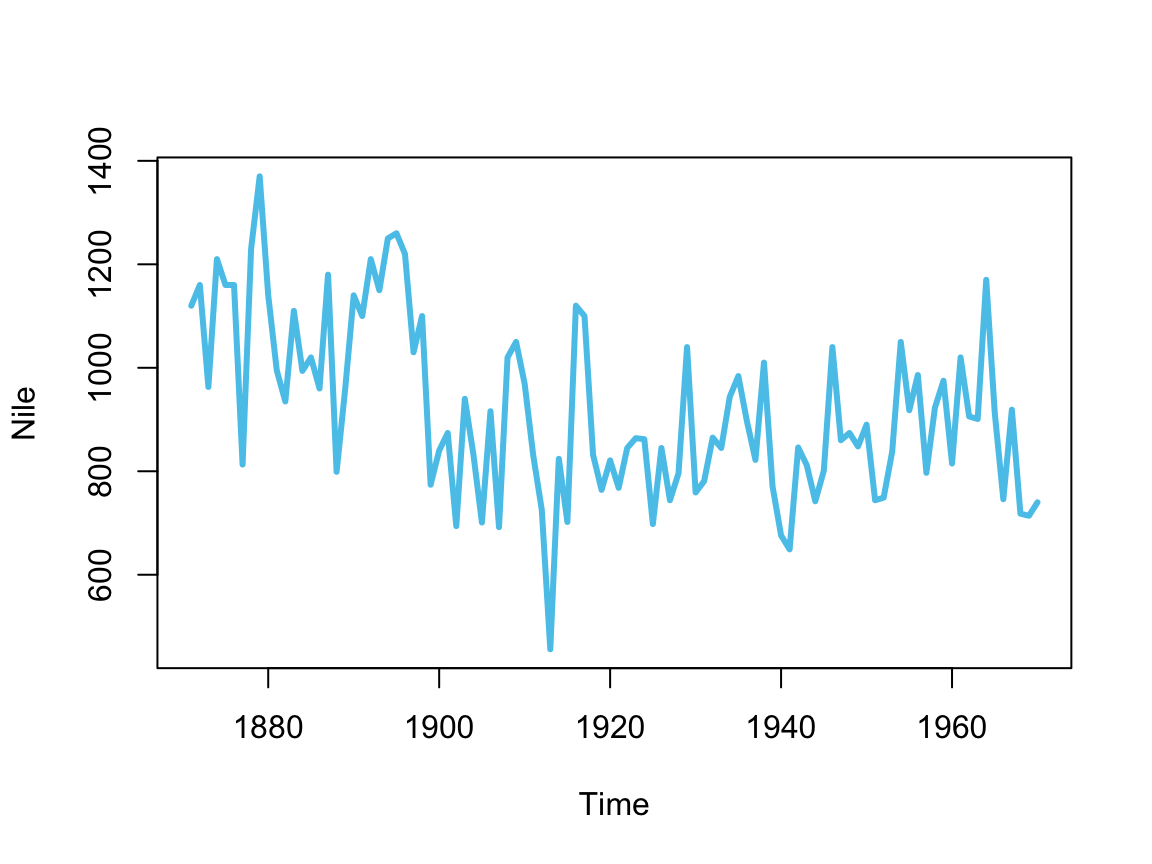
B.3.2 Data in R packages
Many R packages contain datasets for demonstration purposes. For instance, this book primarily uses a variety of datasets — some real ones, but also smaller tables that were generated to highlight or practice particular aspects or tasks — that come with the ds4psy package (Neth, 2023).
Including data in packages has both benefits and costs. It makes the corresponding tables easily accessible, but this convenience comes at the price that students no longer learn to retrieve and load real data sets that often require extensive pre-processing. To somewhat alleviate this dilemma, we store some datasets in a variety of formats on a web server (at http://rpository.com/ds4psy/, see Chapter 6 on Importing data).
The R packages of the tidyverse (Wickham, 2023) also contain many datasets. For instance, we can explore and use the following datasets for practice and illustration purposes:
ggplot2:
diamonds,economics,mpg,msleep(see Chapter 2)dplyr:
starwars,band_members,band_instruments,nasa,storms, etc. (see Chapters 3, 4, 5, and 8)tidyr:
table1–table5,billboard,construction,fish_encounters,population,smiths,us_rent_income,who,world_bank_pop(see Chapter 7)stringr:
words,sentences(see Chapter 9)lubridate:
lakers(see Chapter 10)
Other packages with many small and large data sets include:
AER: Data of the textbook Applied Econometrics with R (Kleiber and Zeileis, 2008).
babynames: Data on the number of children of each sex given each name (of at least 5 children) by the U.S. social security administration (Wickham, 2019).
DAAG: Data for Data Analysis and Graphics Using R (Maindonald & Braun, 2003, 2007, 2010).
dslabs: Datasets used for training for the HarvardX’s Data Science Professional Certificate (Irizarry & Gill, 2019).
eurostat: Tools for downloading data from the Eurostat database (Lahti et al., 2017).
FFTrees: Data to be used for solving binary classification tasks:
breastcancer,car,heartdisease,mushrooms,titanic,wine(Phillips, Neth, Woike, & Gaissmaer, 2023).fpp2: Data for Forecasting: Principles and practice (Hyndman & Athanasopoulos, 2018).
HistData: A package that provides a collection of small data sets that are interesting and important in the history of statistics and data visualization (Friendly, 2023).
ISLR: Data for An Introduction to Statistical Learning with Applications in R (James, Witten, Hastie, & Tibshirani, 2013).
MASS: Support functions and datasets for Venables and Ripley’s MASS (Venables & Ripley, 2002).
nycflights13: Data for all flights departing from NYC in 2013 (Wickham, 2019).
palmerpenguins: Data on 344 penguins on the Palmer Archipelago, Antarctica (Horst, Hill, & Gorman, 2022).
psych: Data for the Personality-project.org (Revelle et al., 2018).
yarrr: Data on
pirates,movies,auction, etc. (Phillips, 2017).
This list is incidental and only guaranteed to be incomplete. See Rdatasets for a more systematic collection of over 2000 data sets distributed through R and its packages.
B.3.3 Online sources
The web is full of data, of course, but most of it needs sound data science and a sound dose of skepticism to be of any use. Nevertheless, here are some good starting points for finding free data:
Collections of datasets
Rdatasets: A collection of over 2300 datasets distributed through R and its packages
Kaggle: A place for data science projects (with many large datasets)
Wikidata: Wikipedia data
Gapminder: An independent Swedish foundation that fights misconceptions about global development with facts
Stats 101: A resource for teaching introductory statistics: Great case studies for introductory statistics courses (by members of the American Statistical Association, ASA)
Statistisches Bundesamt: German data on various issues
Economic datasets
The AER package provides many datasets for Applied Econometrics with R (Kleiber and Zeileis, 2008)
FRED provides mostly time series data on economic trends
IPUMS provides census and survey data on various issues from around the world
Using survey data of the Pew Research Center requires a free account
UC DATA provides data in the areas of political, social and health sciences.
Specific datasets
Pantheon provides useful records of over 80,000 famous individuals (Yu et al., 2016). Various datasets can be downloaded at https://pantheon.world/data/datasets.
PanTHERIA: A species-level database of life history, ecology, and geography of extant and recently extinct mammals.
Miscellaneous links
More data and sources for ideas:
Our world in data provides many inspirations for exciting data analyses and visualizations (e.g., Burden of disease by Max Roser and Hannah Ritchie, 2016)
43 free datasets for projects (by Vik Paruchuri, 2024-11-13, Dataquest blog)
Awesome public datasets: A GitHub repository by the Awesome Public Datasets Core
- Judgment and Decision Making (JDM) is a prestigious open-access journal that publishes links to the datasets in its articles

[55_datasets.Rmd updated on 2025-03-18 by hn.]