Clarifications

This section defines and clarifies some concepts (e.g., how data science differs from statistics), explicates some assumptions, and provides recommendations on how to succeed when working through this book or taking this course. It also addresses recent technical developments (by reflecting on the relationship between base R and the tools provided by the tidyverse) and describes the pragmatic and task-oriented approach adopted in this book.
What is data science?
It is a capital mistake to theorize before one has data.
Arthur Conan Doyle (1891): A Scandal in Bohemia
In our technology-driven environment, data is cheap and ubiquitous. Every call, trip, or visit of a web page leaves a trail of data. Apart from raising important issues of privacy, the notion of big data highlights another problem: In an era in which digital information is collected everywhere, we are drowning in data. While this data promises to be valuable and meaningful, we frequently fail to understand and use it. Unfortunately, we often lack the knowledge, skills or tools of dealing with data, which are a prerequisite of making any sense of it.
The above quote by Arthur Conan Doyle has some intuitive appeal, but directly contradicts what students typically learn in introductory courses on research methods and statistics. This tension rests on the ambiguous roles of data in generating insights and knowledge: Data can both motivate and serve to evaluate hypotheses (see the distinction between exploratory and confirmatory data analysis below). And raw data can both be a precious resource for important discoveries, but also be a messy pile of worthless junk.
As we will see, data is neither valuable nor worthless in itself. Instead, the art and craft of data science must guide us and can allow us to separate signals from noise. Crucially, without a clear sense of purpose, a sound theory on the potentials and limits of data analysis, and solid skills in using special tools, any amount of data fails to address or solve our problems.
Defining data science
Data science is the theory, art and craft of making sense of data, and includes practical skills of using tools designed to deal with data. Making sense of data is a challenging task that requires a combination of knowledge, tools, and experience on many different levels. In academia, data science is primarily an abstract and theoretical reflection the benefits and costs of various methodologies, as well as corresponding efforts in designing and engineering superior methods and tools. However, practical applications of data science are not only relevant for natural and computer sciences, but also for the social sciences, humanities, and arts. While getting good at data science as a genuinely scientific enterprise involves a lot of formal training and theory, applied data science is also an increasingly important skill in many administrative and business contexts. Just like for other theories, arts and crafts, mastering data science requires special background knowledge for perceiving problems, suitable tools for tackling tasks, the skills in choosing and using them, and an awful lot of experience and dedicated practice.
Data science vs. statistics
Data science is often confused with statistics — especially by social science students, who tend to view any formalism as a new type of statistics specifically designed to torture them. There is considerable overlap between data science and statistics, but they are not identical:
Statistics is primarily a mathematical discipline that examines the properties of samples, probability distributions, and inferences from samples. Statistics typically involves formulas and numbers, but does not necessarily require getting your hands dirty with real-world data. In the context of psychology, statistics mostly quantifies differences or relationships between groups and tests effects of experimental manipulations or treatments.
Data science as a theoretical discipline is closely related to statistics and machine learning. Its practical application, however, typically begins with messy data from real-world sources.
To complicate things further, data literacy (i.e., the basic ability of understanding data) is an essential prerequisite for both data science and statistics. However, doing data science does not necessarily require statistics to yield meaningful results. Applied data science can be described as using statistical and other methods for solving real-world problems, but pursues a different main goal: Understanding and dealing with data, rather than testing hypothesized effects.
In short, statistics mostly summarizes data to test hypotheses, while data science transforms and visualizes data to promote the generation of hypotheses.3 In science, both objectives are important and complementary, but data literacy and data science enable us to understand and deal with data before and beyond statistics. Dealing with data in a variety of ways enables new insights (e.g., by visualizing properties and relationships) and allows us to think more clearly about the causes and implications of data.
Related areas and skills
Data science is not a single and homogenous discipline. Instead, it overlaps and is intricately interwoven with several other areas and skills. Becoming an expert in data science not only requires knowledge in statistics, but also in computer graphics/visualization, as well as mathematical and computational modeling.
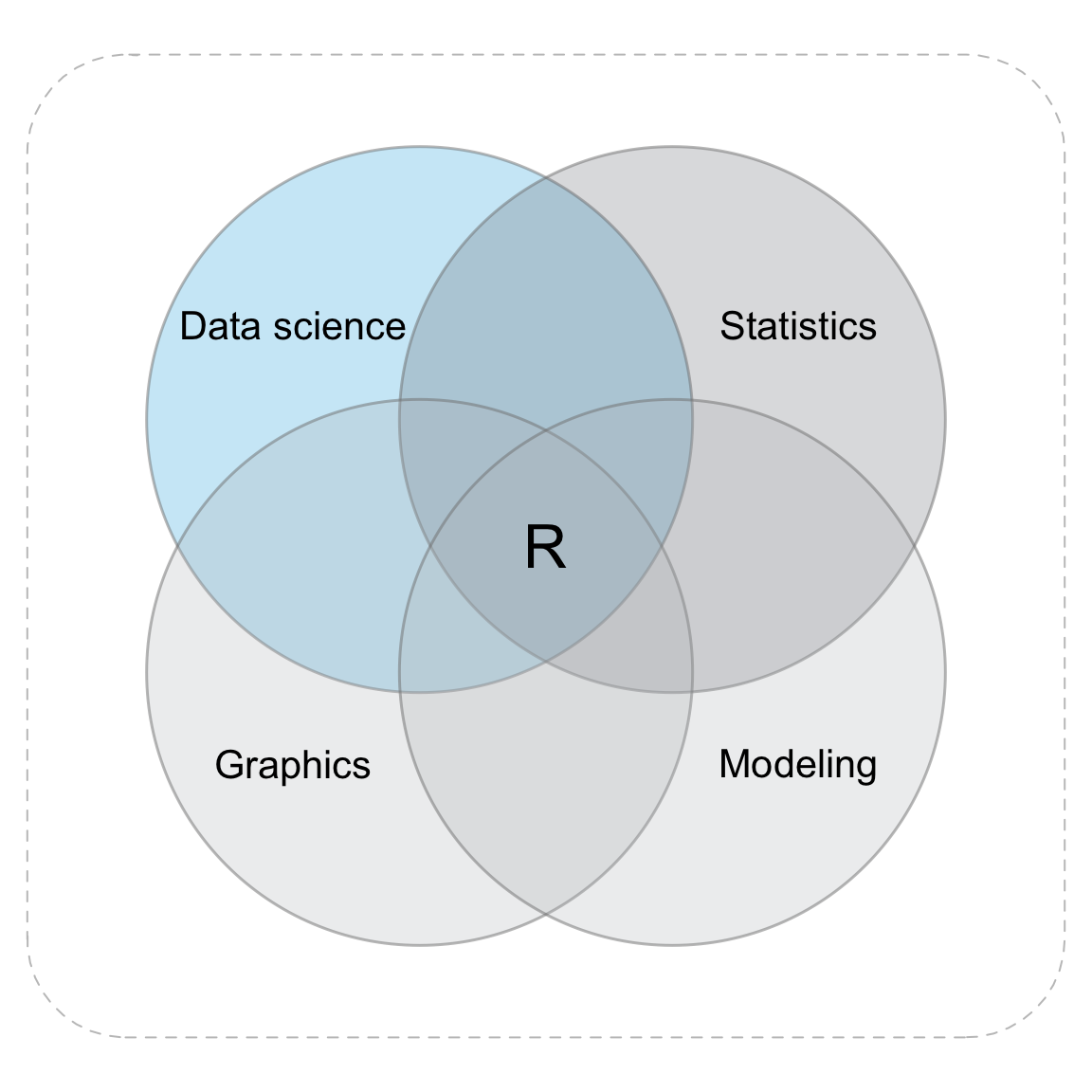
Figure 0.3: Data science combines a variety of areas and skills.
Figure 0.3 illustrates how data science involves many partially overlapping skills and areas of expertise. Although not every individual needs to be an expert in all those areas, it certainly helps to have a basic understanding of most of them. Fortunately, R is used in all these areas, so getting good at R will help you prospering in multiple directions.
Learning data science
This book and course are the result of a learning process. Since 2016, I’ve been teaching a variety of R courses at the University of Konstanz. While several cohorts of students have enjoyed or fought through the iterations of this course, my views on teaching basic aspects of data literacy to an audience of social science students also went through a series of transformations. My initial enthusiasm was tempered by the realization that many students have no background on computer programming, scarce hopes of gaining anything from computational methods or tools, and limited willingness and time to invest into acquiring corresponding skills.
Although some students find the clean structure of formalisms intuitively appealing, others are intimidated or repulsed by the prospects of reading or writing computer code. While I cannot claim to have discovered the magic bullet that satisfies all needs, I hope that even the most reluctant and sceptical students can gain a glimpse of the promises of data science for their future aspirations. Ideally, every student of this course should occasionally experience some joy and pride in achieving something new and exciting. In the following, I explicate my current working assumptions and provide some tips on mastering this course.
Premises
Here are my current assumptions when teaching this course:
An offer and an opportunity: When taking a brief moment to pause and look at our world in general, is becomes obvious that being in a position to spend days, weeks, or months on learning (or teaching) technical skills in a safe and welcoming environment is an incredible blessing. Hence, let’s try to make the most out of this luxury and view this course not only as a challenge, but as an offer and a welcome opportunity for development and growth by acquiring new knowledge and skills.
Act responsibly: In the past, I have forced students to read materials and submit weekly solutions to exercises by threatening them with bad grades. As a consequence, students complained about the amount of work required of them, challenged the submission deadlines, and demanded that all course materials and exercises should be available before a particular session was taught. Paradoxically, incrementally posting exercises and withholding their solutions until some deadline had expired required a lot of effort on my part — and still left me with a sense of failure when someone was unable to solve the exercises. To respond to these requests and make my efforts more manageable, this book now contains all materials, exercises, and solutions for an entire semester worth of study. This may seem generous or lenient on my part, but actually shifts the responsibility from instructor to student: While I am still there to explain and clarify important concepts and commands, you now need to monitor your own progress by working through the exercises and check your understanding by comparing your work to the solutions provided. Hence, this course no longer requires a classroom, but assumes that you are an adult who is motivated to learn its material and willing and able to invest the effort and time required to do so.
Any usefulness depends on you: Many students who take the plunge into data science find it quite enjoyable and rewarding after a while. But even if you do not enjoy the experience, it may still be an investment that is likely to pay off later. However, acquiring new methods and skills often is not inherently rewarding or useful. Instead, their value depends on what we use them for. So even when studying and solving small practice problems, try to keep an eye open for the larger goals and purposes that you may pursue with these skills in the future.
Mastering this course
The main ingredient for succeeding in this — and any other — course of study is sustained focus and a keen attention to detail. The Stoic philosopher Epictetus aptly summarized this attitude in a lofty quote:
Practise yourself, for Heaven’s sake, in little things,
and thence proceed to greater.Epictetus Discourses Book I, 18
or, if you prefer a somewhat more down-to-earth (yet deeply meritocratic) expression:
If you don’t practice you don’t deserve to win.
Andre Agassi
When spelled out more explicitly, the recipe for succeeding in this course corresponds closely to succeeding in life in general:
Learning involves effort: Starting to study data science is similar to learning to play an instrument or beginning some new sport: You first need some infrastructure — equipment (like hard- and software), plus training materials — to get started. Once the basics are in place, you can benefit from the advice of experts and peers, but mostly need a lot of practice. Just like in many other fields, being enthusiastic and having talent usually helps, but dedicated practice is essential even when you happen to be a genius. Getting good at data science requires both curiosity and routine:
Curiosity implies interest, motivation, and fun: If you really want to find out or achieve something (e.g., understand some dataset or conduct some analysis), you are willing to find out how this can be achieved and will overcome the obstacles that may appear along the way. Perceiving tasks as a challenge rather than a chore will allow you to enjoy the efforts invested, rather than suffering from them.
Routine implies discipline, stamina, and lots of practice. It is impossible to acquire new skills without investing time and effort. Crucially, habitual practice (e.g., daily use of data science tools) helps developing various organizational skills (e.g., using keyboard shortcuts, naming objects, formatting code, and structuring files or projects) that are non-trivial and will profoundly affect your productivity (far beyond this course).
Use social resources: The fact that this book now includes both exercises and their solutions has the side effect that, theoretically, you can work through the entire book by yourself. However, such a solitary endeavour requires both determination and stamina. Fortunately, this course and its social context (instructor, classmates, and online platforms) are there to help you to stay focused, provide orientation and motivation, ask and answer questions, and allow you to continuously check your progress and understanding.
Ultimately, learning and practicing any art, craft, or science is also a process of socialization: Striving towards common goals and belonging to a community that shares a set of common methods, principles, and values. And although the R community can sometimes react harshly when some newbie asks a naive question at the wrong place, there is hardly a more enthusiastic and welcoming bunch of people to push towards new horizons.
Warning
Beware of side effects: Learning data science will change how you perceive the world (by parsing it into meaningful pieces of information) and how you tackle new tasks (by structuring them according to the tools that you are familiar with). Similarly, becoming an R user can profoundly transform your thinking — not only about data and code, but also about the types of problems you are trying to solve and understand. While programming (in R or any other language) if often useful and enjoyable, it also has addictive potential, and can not only open doors, but also lead into dead ends. So make sure to take regular breaks — and always stay focused on good and serious questions behind and beyond the data and the tools.
A tidyverse caveat
The tidyverse (Wickham, 2023; Wickham et al., 2019) is an opinionated collection of R packages that is supported by Posit (formerly known as RStudio). There is a lot to admire about the set of R packages comprising the tidyverse and the people that write and support these packages. Personally, I like that they share a vision that strives for simplicity and transparency, and that they provide a bold and ambitious approach towards designing a consistent set of tools. That said, being ambitious and bold usually comes with costs. As most tidyverse packages are still under active development, it can be difficult to keep up with their current versions. In addition, the tidyverse developers are deliberately opinionated (see the Tidy tools manifesto) and not afraid of making radical changes (as various iterations of reshape, reshape2, and tidyr testify). This situation essentially creates two potential problems:
Fragmentation: Adding a set of alternative tools can be well-intentioned and phrased positively — as increasing diversity, offering more choices, increasing our freedom, etc. Nevertheless, adding options also implies an increase in complexity and reduction of unity.
Moving target: Just like an expectation of deflating prices can motivate economic actors to postpone investments, expecting that some tools are likely to change in the near future could make us uncertain about studying them at this point.
In my view, there are good reasons for the current hype around the tidyverse and it has now matured enough to be studied, taught, and used. Although the prospect of constant changes may curb our enthusiasm for any particular technology, we should not allow this to slow us down. Even when methods or functions may still fluctuate, the underlying paradigms and principles remain relevant or change at a much slower pace. Importantly, no particular package, method, or tool should ever be enshrined purely on ideological grounds. Instead, we should always focus on the goals and tasks beyond the tools and handle any new technology with care and a healthy dose of skepticism. Just like hypotheses in science should be abandoned in favor of more successful ones, we should not be afraid of replacing tools when better ones become available — and trust that our experience gained along the way will still be valuable in the future.
Nevertheless, tidyverse novices should be aware that not everyone is convinced by its approach. As the corresponding packages often deviate from the traditional core — and lore — of R, they are bound to confuse or complicate matters from a purist’s point of view. As a consequence, some experts are skeptical and caution against an indiscriminate and universal adoption of the tidyverse and lament R’s fragmentation into different dialects. The increasing popularity of the tidyverse is partly due to its close connections to Posit (formerly known as RStudio), which provides a promotional platform that other packages — such as data.table or vtreat — lack. So even though the arguments on the pros and cons of the tidyverse typically gravitate around the features of tools and their performance, the debate’s implications ultimately touch upon serious issues of influence and power.4
See the following links for some arguments and elaborations of this ongoing discussion:5
- TidyverseSkeptic (by Norm Matloff, revised on 2022-04)
- The tidyverse curse (by Bob Muenchen, posted on 2017-03-23)
- Tidyverse and data.table, sitting side by side (by Dirk Eddelbuettel, posted on 2018-01-21)
- What is “tidy data”? (by John Mount, posted on 2019-05-11)
- Why I don’t use the tidyverse (by Holger K. von Jouanne-Diedrich, posted on 2019-12-10)
A pragmatic approach
One way to temper heated debates is by introducing distinctions that are frequently overlooked. In the case of base R versus the tidyverse packages, it is important that the tidyverse is primarily intended for users, rather than developers. If you want to develop new software on top of R, having a solid understanding of base R is indispensable. But if you are eager to analyze data without planning to program your own functions or packages, the tidyverse may facilitate your workflow.
As R novices, you can probably care less about ideological debates, but being aware of their existence helps you to stay critical. So unless you have personal stakes in this discussion, I suggest adopting a pragmatic approach: Let’s observe the ongoing developments, use the tools that we like and work well for us, and leave it up to the historians to decide whether the tidyverse dialect will ever become the vernacular of R. Rather than blindly jumping on the tidyverse bandwagon, we can credit its benefits, but also point out when something seems like a limitation or idiosyncrasy.
People tend to develop deep attachments and vociferous loyalties to brands, packages, or tools. This is understandable, given the investments they have made and the fact that the value of their current skills may partly depend on the availability and adoption of these tools. But whatever our preferences, we should not mistake means for ends in themselves and swear no oaths of allegiance to particular tools. Unless we are working in a very restrictive environment, there is no law mandating the use of a particular package or program. And despite countless merits and well-deserved credits, no package or framework deserves our unconditional obedience or religious fanaticism. Thus, rather than getting too carried away by shiny new tools, we should occasionally remind ourselves that R was a powerful language long before the tidyverse was conceived. As a consequence, we should not be surprised when base R commands often provide good alternatives to tidyverse functions.
Focus on getting tasks done

Importantly, your primary goal at this point should be to stay enthusiastic about the things you can achieve (with R and its packages), and steadily expand the scope of your skills to tackle new tasks. This has two implications:
Focus on methods, tasks, and purposes, rather than on tools: Importantly, try not to confuse the means (e.g., using particular packages) with their ends (e.g., getting tasks done). Understanding the purpose of tools can be more important than knowing how to use them. Hence, focus on developing your skills, tasks, and principles, rather than on mastering particular functions or tools.
Welcome diversity of tools and flexibility of solutions: Rather than hoping for or clinging to one tool or one way of solving a task, learn to recognize and welcome situations in which multiple alternatives are available. Although having many choices can occasionally be confusing, we rarely are overwhelmed by them. And realizing that there are multiple ways to solve some task does not need to be paralyzing, but can be inspiring and liberating. While there are always elegant and clumsy ways to perform some task, the most important thing is getting things done.
So stay calm and relaxed, even when the prospects of data science may seem daunting or dubious at this time. And if mentioning the need for effort and discipline sounds somewhat intimidating, still try to adopt and maintain an open mindset. In the beginning, whatever works and helps boosting your enthusiasm is fine — we can work on polishing the details later.
References
See Section 4.1 of Chapter 4 for the difference between exploratory and confirmatory data analysis, and Breiman (2001), Donoho (2017), or De Veaux et al. (2017), for a more nuanced discussion of the relations between data and statistics.↩︎
By being a commercial enterprise, it is not surprising that Posit may be pursuing a different agenda than the R Foundation, which is a non-profit organization. Just like other technological enterprises — think Google or Facebook — Posit is creating a range of amazing products and corresponding services. Although it is appropriate to be excited about and grateful for their innovations, it would be naive to think that there is no price to pay when becoming dependent on a company’s products.↩︎
Note the dates of these posts. We are living in exciting times, as far as developments in data science are concerned.↩︎