4.1 Introduction
The term exploratory data analysis (EDA) sounds pretty dry and boring. But the principles and practices behind EDA are not only important, but also describe one of the most exciting parts of data analysis: The gradual process of discovering and grasping the contents of a new dataset. As we will see, John Tukey compared EDA to the work of a detective (Tukey, 1969): Encountering a new dataset is like a mystery, which we must examine and probe to unlock its hidden properties and secret implications.
When promoting tools and skills of data analysis, we easily forget that we usually explore data without being interested in this data. This seemingly paradoxical situation is explained by the fact that data usually is a means to an end, rather than an end in itself. Our reason for seeking data in the first place is that we deeply care about some issue or topic. In contexts of scientific research, we usually operate within a theoretical framework of concepts and hypotheses regarding their relations to each other. Even if our theoretical ideas may still be vague, we should be able to formulate well-defined research questions. If those questions are of an empirical nature, data is collected to address and answer them.
But even when data is generated or recruited as a means for answering questions, it can also generate new questions. Thus, theoretical questions and data are the two poles of an iterative cycle that inspire and motivate each other. Figure 4.2 illustrates the mutual influence of questions and data:
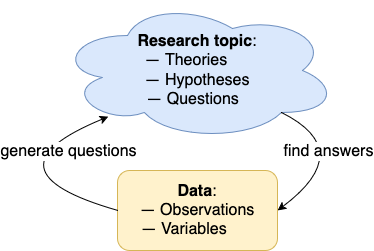
Figure 4.2: The hermeneutic cycle of exploratory data analysis (EDA): Data is used as a means for answering and for generating research questions.
From a practical viewpoint, introducing the principles and practices of EDA will refine and use what we have learned so far to explore and think about data. Thus, this chapter does not introduce new R packages and tools, but combines our knowledge and skills regarding ggplot2 (in Chapter 2) with our recent introduction to dplyr (in Chapter 3) to quiz and probe data.
4.1.1 Objectives
After working through this chapter, you should be able to conduct an explanatory data analysis (EDA), which includes:
- knowing the difference between exploratory and confirmatory data analysis,
- initializing and organizing a new project,
- screening your data (observations and variables),
- checking for unusual values and distributions,
- inspecting trends (over time or multiple measurements),
- inspecting relationships between variables,
- structuring and commenting your analysis and results.
Key concepts
Important concepts in this chapter include:
- exploratory vs. confirmatory data analysis,
- unusual values: missing values (
NA) vs. erroneous or extreme values (e.g., outliers),
- different types of variables (e.g., continuous vs. categorical variables),
- dropouts (i.e., observations missing at some measurement occasions, which can be random or systematic),
- relationships between variables (of different types),
- trends (i.e., developments over time), and
- various types of plots (e.g., visualizing distributions, means, and trends).
4.1.2 What is EDA?
Exploratory data analysis is an attitude,
a flexibility, and a reliance on display,
NOT a bundle of techniques, and should be so taught.John W. Tukey (1980, p. 23)
Exploratory data analysis (EDA) is a type of data analysis that John Tukey contrasted with confirmatory data analysis (CDA) (e.g., Tukey, 1977, 1980) and likened to the work of a detective (Tukey, 1969). Long before the ubiquity of personal computers, Tukey emphasized the importance of visual displays for detecting patterns or irregularities in data, while most psychologists of the same era were obsessed with statistical rituals (like null hypothesis significance testing, NHST, see Nickerson, 2000) of a rather mechanistic and mindless nature (Gigerenzer, 2004). Irrespective of your stance towards statistics, EDA approaches data in a more curious and open-minded fashion.
Exploration vs. confirmation
The precise sequence of steps required for understanding a specific dataset always depends on the nature of the data, your research question, and your current goals. In many cases, there is no pre-defined end to an EDA and no clear-cut boundary between the processes of exploration and the confirmation (or falsification) of expectations. On the one hand, scientists use EDA to check and understand a dataset, before using statistics to test specific hypotheses. On the other hand, this does not mean that we should blur the distinction between exploration and confirmation. On the contrary: Although the processes of exploring and testing hypotheses tend to involve the same steps and tools, we must never confuse our curious explorations with theoretically motivated predictions. Given the exploratory mind-set of EDA, the availability of powerful tools, and an abundance of data allowing for many different comparisons, there is a very high chance of false positive results (i.e., illusory or transient effects that are not based on systematic patterns, but due to freak coincidences and random fluctuations). Even when we are aware of this, it is hard to resist the lure of a cute effect and easy to kid ourselves into thinking that we found something significant. So let’s try to stay honest and firm and do not get carried away every time we spot some pattern or possible effect. This cautionary note can be summarized as an important scientific principle:
- Science 101: To really find something, we need to predict it — and ideally replicate it under different conditions.
EDA is an important component of data analysis, but is not a replacement for scientific theory and sound methodology. And although it is possible to abuse EDA (e.g., when exploration turns into fishing for results), a method should not be discredited just because it can be abused. In the end, the benefits and dangers of EDA are just like those of any other scientific tool (e.g., collecting data or statistical testing): The validity and trustworthiness of our findings depend on the integrity of the people using them. To allow others to evaluate our integrity and the validity of our results, our data and analysis should be communicated in a clear and transparent fashion. Thus, being transparent about the details of our data analysis is a big step towards responsible and reproducible research practices.
The mindset of EDA
Tukey (1980) referred to EDA as an “attitude” and described it as a process in which we follow our curiosity and trust that various ways of representing data will facilitate our understanding and enable insight. According to Chapter 7 of the r4ds textbook (Wickham & Grolemund, 2017), EDA is primarily a state of mind. EDA is an active process in which you are familiarising yourself with a new data set and keep your eyes open for interesting and unexpected aspects. Rather than following a strict set of rules, you are actively engaging in an iterative cycle during which you
Generate questions about data;
Search for answers by visualising, transforming, and modelling data;
Use answers to refine your questions and/or generate new questions.
Importantly, generating and refining questions about data does not primarily depend on tools or technology, but rather on your intellectual curiosity and interests. The tools of data science cannot replace your intellectual contribution, but facilitate the process of considering evidence that speaks to your questions and — hopefully — finding some answers. Philosophically speaking, EDA is a data scientist’s way of doing hermeneutics — see the corresponding definitions in Wikipedia or The Stanford Encyclopedia of Philosophy for details — to get a grip on some dataset.
Practically, the goal and purpose of EDA is to gain an overview of a dataset. This includes an idea of its dimensions and the number and types of variables contained in the data, but also more detailed ideas about the distribution of variables, their potential relations to each other, and potential problems of the data (e.g., missing values, outliers, or confounds between variables).
When using the tools provided by the tidyverse (Wickham, 2023), the fastest way to gain insights into a dataset is a combination of dplyr (Wickham, François, et al., 2023) calls (to create new variables and summary tables) and ggplot2 (Wickham, Chang, et al., 2025) commands (for visualizations). However, creating good representations (variables, tables, or graphs) is both an art and a craft. The key to creating good visualizations requires answering two sets of questions:
What are informative and suitable plot types? This includes answering functional questions like
- What is the goal or purpose of a plot?
- What are possible plot types that are suited for this purpose?
- Which of these would be the most appropriate plot here?
- What is the goal or purpose of a plot?
Which variables should be plotted? This includes answering data-related questions like
- How many variables are to be plotted?
- Of which types are these variables?
- Are these variables continuous or discrete (categorical, factors)?
- How should variables be mapped to dimensions and aesthetics?
- Do some variables control or qualify (e.g., group) the values of others?
- How many variables are to be plotted?
Even when these sets of inter-related questions are answered, creating informative and beautiful graphs with ggplot requires experience, trial-and-error experimentation, and lots of dedicated practice.
Unfortunately, a new dataset is rarely in a condition and shape to directly allow plotting. Instead, we typically have to interleave commands for plotting with efforts in transforming data to wrangle variables into specific shapes or types. Thus, calls to dplyr and ggplot2 typically occur in combination with other R or tidyverse commands (many of which are introduced in subsequent chapters).
4.1.3 Data used
To illustrate the process and spirit of EDA, we use a real and fairly complex data set, which was collected to measure the short- and long-term effects of positive psychology interventions (Woodworth et al., 2017, 2018).37 A good datset is like a treasure chest of questions and answers — and data science provides you with the keys (in the form of code and commands) to unlock the chest. And while it is understandable that you are primarily focusing on the code and commands at this stage, try to always keep an eye on the meaning of the data and stay curious about the results that you discover.
4.1.4 Getting ready
In the course of conducting an EDA, we mostly rely on functions from the dplyr and ggplot2 packages covered in previous chapters (Chapters 2 and 3). This chapter formerly assumed that you have read and worked through Chapter 7: Exploratory Data Analysis of the r4ds textbook (Wickham & Grolemund, 2017). It now can be read by itself, but reading Chapter 7 of r4ds is still recommended.
Please do the following to get started:
Create an R Markdown (
.Rmd) document (for instructions, see Appendix F and the templates linked in Section F.2).Structure your document by inserting headings and empty lines between different parts. Here’s an example how your initial file could look:
---
title: "Chapter 4: Exploratory data analysis (EDA)"
author: "Your name"
date: "2025 November 10"
output: html_document
---
Load packages and data...
# Exercises (04: EDA)
## Exercise 1
## Exercise 2
etc.
<!-- The end (eof). -->Create an initial code chunk below the header of your
.Rmdfile that loads the R packages of the tidyverse (and see Section F.3.3 if you want to get rid of the messages and warnings of this chunk in your HTML output).Save your file (e.g., as
04_EDA.Rmdin the R folder of your current project) and remember saving and knitting it regularly as you keep adding content to it.
With this in place, we are ready to embark on an exploratory data analysis (EDA).