6 Regularización
Librerías utilizadas
La regularización es un método que nos permite restringir el proceso de estimación, se usa para evitar un posible sobre ajuste del modelo (overfitting).
Una forma de hacer regularización es donde los coeficientes de variables en el modelo no sean muy grandes (regresión ridge). Otra forma es contraer los coeficientes, llegando a tener coeficientes iguales a cero (regresión lasso).
Como regla general, el segundo enfoque suele ser mejor que el primero.
Los coeficientes regularizados se obtiene usando una función de penalidad \(p(\boldsymbol{\alpha})\) para restringir el tamaño del vector de coeficientes \(\boldsymbol{\alpha} = (\alpha_1,\cdots,\alpha_M)^T\) del predictor \(f(\mathbf{x}) = \sum_{j = 1}^{M} \alpha_jC_j(\mathbf{x})\). Los coeficientes penalizados son obtenidos como solución al problema de minimización:
\[ \hat{\boldsymbol{\alpha}}_{\lambda}= \underset{\boldsymbol{\alpha}}{\mathrm{argmin}} = \left\{\sum_{i = 1}^{n}L(y_i,f(\mathbf{x}_i))+\lambda p(\boldsymbol{\alpha}) \right\}, \] donde \(L\) es una función de pérdida y \(\lambda>0\) es un parámetro de regularización también conocido como ratio de aprendizaje.
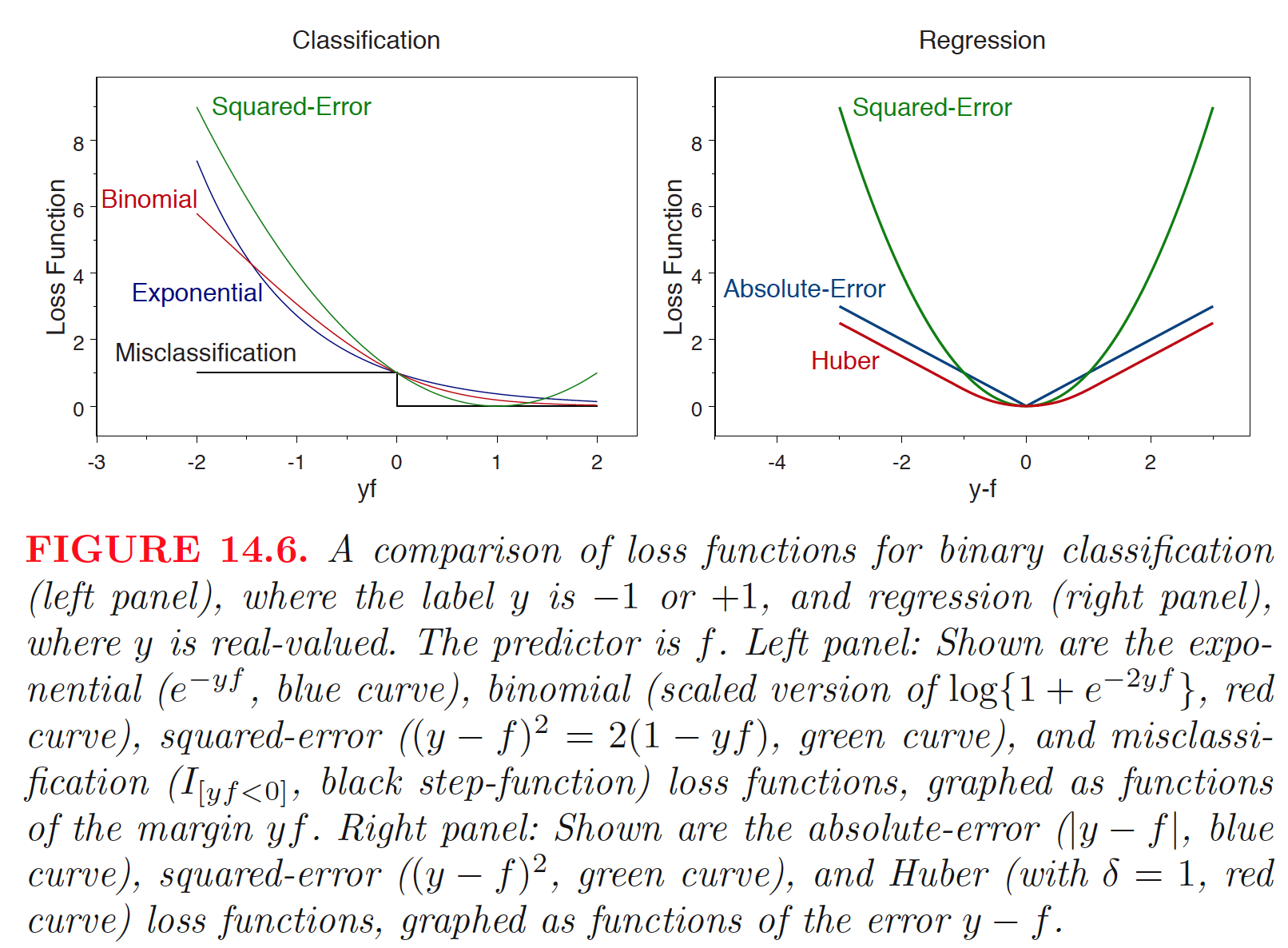
Existen diferentes opciones para funciones de pérdida:
- Exponencial:
\[ L(y,f(\mathbf{x})) = e^{-yf(\mathbf{x})}, y \in \{-1,+1\}. \]
- Logística:
\[ L(y,f_t(\mathbf{x})) = \text{log}\{1+ e^{-2yf_t(\mathbf{x})}\},y \in \{-1,+1\}. \]
- Error cuadrático:
\[ L(y,f_t(\mathbf{x})) = \frac{1}{2}(y-f_t(\mathbf{x}))^2, y \in \mathcal{R}. \]
- Error absoluto:
\[ L(y,f_t(\mathbf{x})) = |y-f_t(\mathbf{x})|, y \in \mathcal{R}. \]
- Huber
Hay dos tipos de funciones de penalidad:
- \(L_2\): esta función de penalidad restringe la suma de cuadrados de los coeficientes,
\[ p_2(\boldsymbol{\alpha})=\sum_{j = 1}^{M} \alpha_j^2. \] Cuando \(L\) combinado es una combinación convexa y usamos la pérdida de error cuadrático, el predictor de regresión penalizado óptimo es el estimador de regresión ridge.
- \(L_1\): Los coeficientes se restringen tal que su suma de valores absolutos,
\[ p_1(\boldsymbol{\alpha})=\sum_{j = 1}^{M} |\alpha_j|. \] sea menor que un valor dado. La evidencia empírica sugiere que la penalización \(L_1\) (lasso) funciona mejor cuando hay un número pequeño o mediano de coeficientes verdaderos de tamaño moderado.
6.1 Regresión Ridge
En mínimos cuadrados ordinarios, las estimaciones de \(\beta_0,\beta_1,\ldots,\beta_p\) se obtienen minimizando
\[ \text{RSS} = \sum_{i = 1}^n\left(y_i-\beta_0-\sum_{j=1}^p \beta_jx_{ij}\right)^2. \]
La regresión ridge es muy similar al enfoque de mínimos cuadrados, pero los coeficientes de la regresión ridge \(\hat{\beta}^R\) son los valores que minimizan
\[ \sum_{i = 1}^n\left(y_i-\beta_0-\sum_{j=1}^p \beta_jx_{ij}\right)^2+\lambda\sum_{j = 1}^{p} \beta_j^2 = \text{RSS}+\lambda\sum_{j = 1}^{p} \beta_j^2, \]
donde \(\lambda\) es un parámetro ajustable que se determina de manera separada. La influencia de la regularización se controla con \(\lambda\). Valores altos de \(\lambda\) significa más regularización y modelos más simples. Sin embargo, la regresión ridge siempre generará un modelo que incluya todos los predictores. Incrementar el valor de \(\lambda\) tenderá a reducir las magnitudes de los coeficientes, pero no resultará en la exclusión de ninguna de las variables. Notemos que la penalidad no se aplica a \(\beta_0\).
6.2 Regresión Lasso
\[ \sum_{i = 1}^n\left(y_i-\beta_0-\sum_{j=1}^p \beta_jx_{ij}\right)^2+\lambda\sum_{j = 1}^{p} |\beta_j| = \text{RSS}+\lambda\sum_{j = 1}^{p} |\beta_j|, \]
La penalización \(L_1\) tiene el efecto de forzar algunas de las estimaciones de coeficientes a ser exactamente iguales a cero cuando el parámetro \(\lambda\) de ajuste es suficientemente grande. Por lo tanto, lasso realiza selección de variables. Como resultado, los modelos generados a partir de lasso son generalmente mucho más fáciles de interpretar que los producidos por regresión ridge. Decimos que lasso produce modelos dispersos (sparse), es decir, modelos que involucran solo un subconjunto de variables predictoras.
6.2.1 Ejemplo: datos de crimen
El conjunto de datos es obtenido de (https://archive.ics.uci.edu/ml/datasets/Communities+and+Crime+Unnormalized) y se trata de comunidades en EE.UU. Son datos combinados de datos socioeconómicos del censo de 1990, datos de aplicación de la ley de la encuesta de 1990 sobre gestión de la aplicación de la ley y estadísticas administrativas y datos sobre delitos de la UCR del FBI de 1995.
A continuación se importan y limpian los datos:
# Limpieza de datos
uu <- "https://raw.githubusercontent.com/vmoprojs/DataLectures/master/CommViolPredUnnormalizedData.txt"
crime = rio::import(uu, na.strings='?')
names(crime) <- c('communityname', 'state', 'countyCode', 'communityCode', 'fold', 'population', 'householdsize', 'racepctblack', 'racePctWhite', 'racePctAsian', 'racePctHisp', 'agePct12t21', 'agePct12t29', 'agePct16t24', 'agePct65up', 'numbUrban', 'pctUrban', 'medIncome', 'pctWWage', 'pctWFarmSelf', 'pctWInvInc', 'pctWSocSec', 'pctWPubAsst', 'pctWRetire', 'medFamInc', 'perCapInc', 'whitePerCap', 'blackPerCap', 'indianPerCap', 'AsianPerCap', 'OtherPerCap', 'HispPerCap', 'NumUnderPov', 'PctPopUnderPov', 'PctLess9thGrade', 'PctNotHSGrad', 'PctBSorMore', 'PctUnemployed', 'PctEmploy', 'PctEmplManu', 'PctEmplProfServ', 'PctOccupManu', 'PctOccupMgmtProf', 'MalePctDivorce', 'MalePctNevMarr', 'FemalePctDiv', 'TotalPctDiv', 'PersPerFam', 'PctFam2Par', 'PctKids2Par', 'PctYoungKids2Par', 'PctTeen2Par', 'PctWorkMomYoungKids', 'PctWorkMom', 'NumKidsBornNeverMar', 'PctKidsBornNeverMar', 'NumImmig', 'PctImmigRecent', 'PctImmigRec5', 'PctImmigRec8', 'PctImmigRec10', 'PctRecentImmig', 'PctRecImmig5', 'PctRecImmig8', 'PctRecImmig10', 'PctSpeakEnglOnly', 'PctNotSpeakEnglWell', 'PctLargHouseFam', 'PctLargHouseOccup', 'PersPerOccupHous', 'PersPerOwnOccHous', 'PersPerRentOccHous', 'PctPersOwnOccup', 'PctPersDenseHous', 'PctHousLess3BR', 'MedNumBR', 'HousVacant', 'PctHousOccup', 'PctHousOwnOcc', 'PctVacantBoarded', 'PctVacMore6Mos', 'MedYrHousBuilt', 'PctHousNoPhone', 'PctWOFullPlumb', 'OwnOccLowQuart', 'OwnOccMedVal', 'OwnOccHiQuart', 'OwnOccQrange', 'RentLowQ', 'RentMedian', 'RentHighQ', 'RentQrange', 'MedRent', 'MedRentPctHousInc', 'MedOwnCostPctInc', 'MedOwnCostPctIncNoMtg', 'NumInShelters', 'NumStreet', 'PctForeignBorn', 'PctBornSameState', 'PctSameHouse85', 'PctSameCity85', 'PctSameState85', 'LemasSwornFT', 'LemasSwFTPerPop', 'LemasSwFTFieldOps', 'LemasSwFTFieldPerPop', 'LemasTotalReq', 'LemasTotReqPerPop', 'PolicReqPerOffic', 'PolicPerPop', 'RacialMatchCommPol', 'PctPolicWhite', 'PctPolicBlack', 'PctPolicHisp', 'PctPolicAsian', 'PctPolicMinor', 'OfficAssgnDrugUnits', 'NumKindsDrugsSeiz', 'PolicAveOTWorked', 'LandArea', 'PopDens', 'PctUsePubTrans', 'PolicCars', 'PolicOperBudg', 'LemasPctPolicOnPatr', 'LemasGangUnitDeploy', 'LemasPctOfficDrugUn', 'PolicBudgPerPop', 'murders', 'murdPerPop', 'rapes', 'rapesPerPop', 'robberies', 'robbbPerPop', 'assaults', 'assaultPerPop', 'burglaries', 'burglPerPop', 'larcenies', 'larcPerPop', 'autoTheft', 'autoTheftPerPop', 'arsons', 'arsonsPerPop', 'ViolentCrimesPerPop', 'nonViolPerPop')
# quitamos variables con pocos datos o poca relevancia
columns_to_keep <- c(5, 6, 11:26,32:103,145)+1
crime = na.omit(crime[,columns_to_keep])Ahora escalamos los datos y los separamos en entrenamiento y prueba:
Escalamos los datos con el comando preProcess de la librería caret:
Separamos los datos en entrenamiento y prueba, 75% y 25% respectivamente con el comando createDataPartition (el parámetro list indica si se desea una lista como resultado):
set.seed(8519)
index <- createDataPartition(y, p=0.75, list=FALSE)
X_train <- X[ index, ]
X_test <- X[-index, ]
y_train <- y[index]
y_test <- y[-index]La librearía glmnet contiene la función del mismo nombre con la que se ajustan modelos GLM con regularización. El parámetro alpha indica el tipo de regularización. Si alpha = 1 es regularización lasso, si alpha = 0 es ridge.
lasso <- caret::train(y= y_train,
x = X_train,
method = 'glmnet',
tuneGrid = expand.grid(alpha = 1, lambda = 1)
)
ridge <- caret::train(y = y_train,
x = X_train,
method = 'glmnet',
tuneGrid = expand.grid(alpha = 0, lambda = 1)
) Realizamos las predicciones usando los modelos estimados:
predictions_lasso <- lasso %>% predict(X_test)
predictions_ridge <- ridge %>% predict(X_test)
# Se imprimen los R2:
data.frame(
Ridge_R2 = R2(predictions_ridge, y_test),
Lasso_R2 = R2(predictions_lasso, y_test)
)## Ridge_R2 Lasso_R2
## 1 0.6797983 0.5988638Revisamos los errores:
# Se imprime los RMSE
data.frame(
Ridge_RMSE = RMSE(predictions_ridge, y_test) ,
Lasso_RMSE = RMSE(predictions_lasso, y_test)
)## Ridge_RMSE Lasso_RMSE
## 1 376.9781 432.2993Veamos los coeficientes obtenidos:
data.frame(
as.data.frame.matrix(coef(lasso$finalModel, lasso$bestTune$lambda)),
as.data.frame.matrix(coef(ridge$finalModel, ridge$bestTune$lambda))
) %>%
rename(Lasso_coef = s1, Ridge_coef = s1.1)## Lasso_coef Ridge_coef
## (Intercept) 1.130420e+03 1132.6080108
## population 0.000000e+00 -20.1633173
## householdsize 5.666758e+02 63.9252079
## agePct12t21 -1.176333e+02 13.3219464
## agePct12t29 -1.313944e+02 -64.1113641
## agePct16t24 0.000000e+00 3.8574424
## agePct65up 0.000000e+00 -2.2223517
## numbUrban 0.000000e+00 -18.9127556
## pctUrban 9.330450e+00 18.0719286
## medIncome -4.036756e+02 -40.1100835
## pctWWage -3.058135e+02 -39.5405590
## pctWFarmSelf -9.881609e+01 -60.7961486
## pctWInvInc -4.248567e+01 -116.9446940
## pctWSocSec -3.671205e+02 -52.0449366
## pctWPubAsst 3.389220e+01 53.6143467
## pctWRetire 8.119208e+01 16.3133640
## medFamInc 0.000000e+00 -28.1067377
## perCapInc -1.123051e+02 -33.5958631
## whitePerCap 1.251772e+02 109.9367670
## NumUnderPov -6.926150e+02 -52.9742410
## PctPopUnderPov -7.922162e+00 -24.7666068
## PctLess9thGrade -6.074581e+01 -55.7898435
## PctNotHSGrad -1.443651e+02 -36.5525729
## PctBSorMore 2.130984e+02 53.7561098
## PctUnemployed 4.605313e+01 45.0329162
## PctEmploy 1.847667e+01 -34.3921946
## PctEmplManu -1.972805e+02 -98.7474609
## PctEmplProfServ 0.000000e+00 21.6229637
## PctOccupManu 4.413362e+02 104.6704919
## PctOccupMgmtProf 1.561198e+02 39.3165819
## MalePctDivorce 0.000000e+00 60.3490606
## MalePctNevMarr 4.990046e+00 29.3530136
## FemalePctDiv -3.961422e+01 -16.0748567
## TotalPctDiv 0.000000e+00 13.7176081
## PersPerFam -2.291248e+02 -3.2830146
## PctFam2Par 0.000000e+00 -83.9731317
## PctKids2Par -6.569872e+02 -150.1979018
## PctYoungKids2Par 6.963574e+01 -23.3918684
## PctTeen2Par 1.088942e+02 -5.9783711
## PctWorkMomYoungKids -1.005379e+02 0.9467168
## PctWorkMom 9.220252e+01 32.3961499
## NumKidsBornNeverMar 1.990928e+02 -13.7559394
## PctKidsBornNeverMar 5.287453e-04 150.8676448
## NumImmig 2.252002e+02 61.0197149
## PctImmigRecent 4.719160e+01 -16.7025432
## PctImmigRec5 -1.030924e+02 -60.9153121
## PctImmigRec8 -1.485752e+02 -8.1538351
## PctImmigRec10 2.976061e+02 104.4518321
## PctRecentImmig -1.202809e+02 -37.2421608
## PctRecImmig5 0.000000e+00 -3.0547671
## PctRecImmig8 0.000000e+00 2.1847088
## PctRecImmig10 -2.604227e+02 30.9523183
## PctSpeakEnglOnly 0.000000e+00 46.8223834
## PctNotSpeakEnglWell 2.643543e+00 25.5978791
## PctLargHouseFam 5.067664e+02 -7.7171054
## PctLargHouseOccup -8.214177e+02 -60.9426156
## PersPerOccupHous 0.000000e+00 -0.2984062
## PersPerOwnOccHous 1.854213e+02 63.0225693
## PersPerRentOccHous -2.851028e+02 -45.3390185
## PctPersOwnOccup 0.000000e+00 24.9957897
## PctPersDenseHous 4.046975e+02 77.2752138
## PctHousLess3BR 3.997264e+01 49.3260040
## MedNumBR -4.049265e+01 -13.3199287
## HousVacant 3.060022e+02 75.2517723
## PctHousOccup 1.590144e+01 -7.5891021
## PctHousOwnOcc 4.838100e+01 14.5887569
## PctVacantBoarded 3.827256e+01 55.2052686
## PctVacMore6Mos 2.473944e+01 19.6278759
## MedYrHousBuilt 1.522281e+02 93.1131168
## PctHousNoPhone 2.271944e+01 26.8616927
## PctWOFullPlumb -1.001378e+02 -30.6673892
## OwnOccLowQuart 0.000000e+00 -31.6475492
## OwnOccMedVal 0.000000e+00 -7.0279234
## OwnOccHiQuart -1.142313e+02 -31.6718068
## OwnOccQrange -2.594090e+01 -23.6864496
## RentLowQ -4.709927e+02 -58.4116395
## RentMedian 2.964951e+01 36.0966448
## RentHighQ -7.345267e+01 -14.2412512
## RentQrange -3.348517e-01 67.1453388
## MedRent 8.418653e+02 75.6144996
## MedRentPctHousInc -4.415355e+01 -12.4628225
## MedOwnCostPctInc -3.418865e+01 35.6726206
## MedOwnCostPctIncNoMtg -5.692937e+01 -80.2774801
## NumInShelters -2.558319e+01 25.6507248
## NumStreet 7.019079e+01 25.6110485
## PctForeignBorn 3.040272e+02 72.1198686
## PctBornSameState -1.064257e+01 -23.3078839
## PctSameHouse85 5.027221e+01 44.9946815
## PctSameCity85 1.737350e+01 2.5094687
## PctSameState85 4.649409e+01 17.7969544
## LemasSwornFT -1.195124e+01 -31.4780697Ahora, elegimos el parámetro de regularización con la ayuda de tuneGrid. Los modelos con la puntuación \(R^2\) cuadrado más alta nos darán los mejores parámetros.
parameters <- c(seq(0.1, 2, by =0.1) , seq(2, 5, 0.5) , seq(5, 500, 5))
lasso <- caret::train(y = y_train,
x = X_train,
method = 'glmnet',
tuneGrid = expand.grid(alpha = 1, lambda = parameters) ,
metric = "Rsquared"
)
ridge <- caret::train(y = y_train,
x = X_train,
method = 'glmnet',
tuneGrid = expand.grid(alpha = 0, lambda = parameters),
metric = "Rsquared"
)
linear <- caret::train(y = y_train,
x = X_train,
method = 'lm',
metric = "Rsquared"
)
print(paste0('Lasso (mejores parámetros): ' , lasso$finalModel$lambdaOpt))## [1] "Lasso (mejores parámetros): 230"## [1] "Ridge (mejores parámetros): 500"Revisamos el \(R^2\) y el \(\text{RMSE}\):
predictions_lasso <- lasso %>% predict(X_test)
predictions_ridge <- ridge %>% predict(X_test)
predictions_lin <- linear %>% predict(X_test)
data.frame(
Ridge_R2 = R2(predictions_ridge, y_test),
Lasso_R2 = R2(predictions_lasso, y_test),
Linear_R2 = R2(predictions_lin, y_test)
)## Ridge_R2 Lasso_R2 Linear_R2
## 1 0.6737963 0.6189773 0.4857502data.frame(
Ridge_RMSE = RMSE(predictions_ridge, y_test) ,
Lasso_RMSE = RMSE(predictions_lasso, y_test) ,
Linear_RMSE = RMSE(predictions_lin, y_test)
)## Ridge_RMSE Lasso_RMSE Linear_RMSE
## 1 375.0716 431.1954 508.1641Veamos los coeficientes estimados:
## [1] "Los mejores coeficientes estimados"data.frame(
ridge = as.data.frame.matrix(coef(ridge$finalModel, ridge$finalModel$lambdaOpt)),
lasso = as.data.frame.matrix(coef(lasso$finalModel, lasso$finalModel$lambdaOpt)),
linear = (linear$finalModel$coefficients)
) %>% rename(lasso = s1, ridge = s1.1)## lasso ridge linear
## (Intercept) 1134.9431646 1147.6506 1122.658115
## population 0.3606813 0.0000 -10871.577689
## householdsize 14.8157146 0.0000 840.365581
## agePct12t21 3.3151221 0.0000 -194.637075
## agePct12t29 -27.4810827 0.0000 -177.592993
## agePct16t24 -11.2192172 0.0000 -60.593345
## agePct65up -2.5271129 0.0000 -25.036687
## numbUrban 0.5120029 0.0000 11053.501418
## pctUrban 22.0555885 0.0000 -33.934401
## medIncome -7.9746127 0.0000 -1248.079959
## pctWWage -8.4534822 0.0000 -474.962612
## pctWFarmSelf -40.9593232 0.0000 -132.054694
## pctWInvInc -51.7442717 0.0000 -2.825268
## pctWSocSec -13.1436408 0.0000 -612.355509
## pctWPubAsst 29.1270431 0.0000 150.967869
## pctWRetire -7.2210071 0.0000 61.432506
## medFamInc -8.2261429 0.0000 652.356848
## perCapInc -1.3994315 0.0000 -148.710400
## whitePerCap 42.6074709 0.0000 104.460205
## NumUnderPov -3.5031683 0.0000 -1345.830586
## PctPopUnderPov 11.0609017 0.0000 -116.646514
## PctLess9thGrade -21.3138453 0.0000 -214.436395
## PctNotHSGrad -0.3011144 0.0000 -144.805596
## PctBSorMore 5.7726396 0.0000 151.457508
## PctUnemployed 28.2245967 0.0000 -10.779315
## PctEmploy -22.1852667 0.0000 68.897050
## PctEmplManu -55.7591311 0.0000 -159.479930
## PctEmplProfServ 15.6349282 0.0000 -49.320027
## PctOccupManu 5.7162408 0.0000 489.784243
## PctOccupMgmtProf 5.6746190 0.0000 405.405934
## MalePctDivorce 41.3376924 0.0000 162.111945
## MalePctNevMarr 21.0935986 0.0000 61.978109
## FemalePctDiv 29.5533304 0.0000 313.512501
## TotalPctDiv 35.7865206 0.0000 -539.740385
## PersPerFam 12.8434139 0.0000 -892.724350
## PctFam2Par -63.3791097 0.0000 155.309904
## PctKids2Par -77.2658142 -274.6816 -1076.322008
## PctYoungKids2Par -48.7372012 0.0000 63.766829
## PctTeen2Par -52.3234082 0.0000 228.107231
## PctWorkMomYoungKids 15.4966945 0.0000 -139.933827
## PctWorkMom 15.5887797 0.0000 148.001458
## NumKidsBornNeverMar 7.3792925 0.0000 823.136293
## PctKidsBornNeverMar 90.1571272 111.9105 -275.716625
## NumImmig 8.8744033 0.0000 246.463966
## PctImmigRecent -14.4238048 0.0000 386.938247
## PctImmigRec5 -9.2828834 0.0000 -488.396949
## PctImmigRec8 7.8179446 0.0000 -283.578005
## PctImmigRec10 32.7165884 0.0000 553.681794
## PctRecentImmig -5.4882242 0.0000 -1499.140927
## PctRecImmig5 3.5802580 0.0000 2495.947793
## PctRecImmig8 7.7343690 0.0000 218.683864
## PctRecImmig10 15.4764031 0.0000 -2393.680669
## PctSpeakEnglOnly 20.7302810 0.0000 -120.364986
## PctNotSpeakEnglWell -3.5952710 0.0000 28.471431
## PctLargHouseFam 15.1526969 0.0000 1734.747671
## PctLargHouseOccup 2.2432740 0.0000 -2074.484590
## PersPerOccupHous 5.8992397 0.0000 213.898997
## PersPerOwnOccHous 21.7596068 0.0000 595.806448
## PersPerRentOccHous -2.9449743 0.0000 -661.765417
## PctPersOwnOccup 1.5507281 0.0000 -1620.311758
## PctPersDenseHous 30.0871764 0.0000 867.027964
## PctHousLess3BR 21.8513253 0.0000 66.384520
## MedNumBR -2.4237333 0.0000 -47.465555
## HousVacant 23.5587002 0.0000 460.698398
## PctHousOccup -22.2653743 0.0000 35.298779
## PctHousOwnOcc -0.1461844 0.0000 1686.420107
## PctVacantBoarded 53.7638070 0.0000 40.344261
## PctVacMore6Mos 13.4318226 0.0000 62.599055
## MedYrHousBuilt 34.6951265 0.0000 158.543121
## PctHousNoPhone 19.3481570 0.0000 53.051654
## PctWOFullPlumb 0.8501767 0.0000 -148.569984
## OwnOccLowQuart -10.5489552 0.0000 -360.390700
## OwnOccMedVal -6.2428537 0.0000 417.935802
## OwnOccHiQuart -4.8448381 0.0000 -391.086418
## OwnOccQrange 4.7102975 0.0000 NA
## RentLowQ -14.9873332 0.0000 -718.093140
## RentMedian 2.9430115 0.0000 260.558601
## RentHighQ -0.9732736 0.0000 -339.982879
## RentQrange 23.5623906 0.0000 NA
## MedRent 10.6792040 0.0000 1195.115997
## MedRentPctHousInc 12.5207380 0.0000 -39.531086
## MedOwnCostPctInc 22.1233026 0.0000 -94.471559
## MedOwnCostPctIncNoMtg -31.7979290 0.0000 6.990649
## NumInShelters 13.5471871 0.0000 -39.885696
## NumStreet 5.7852204 0.0000 26.024385
## PctForeignBorn 17.5176905 0.0000 935.263522
## PctBornSameState -24.2491275 0.0000 124.249332
## PctSameHouse85 19.7928596 0.0000 144.115665
## PctSameCity85 3.2963396 0.0000 -30.985328
## PctSameState85 6.1610943 0.0000 -37.785119
## LemasSwornFT 0.6214069 0.0000 -271.999351Nuestro puntaje subió un poco (lasso). Construyamos gráficos de coeficientes para ver cómo el valor de lambda influye en los coeficientes de ambos modelos.
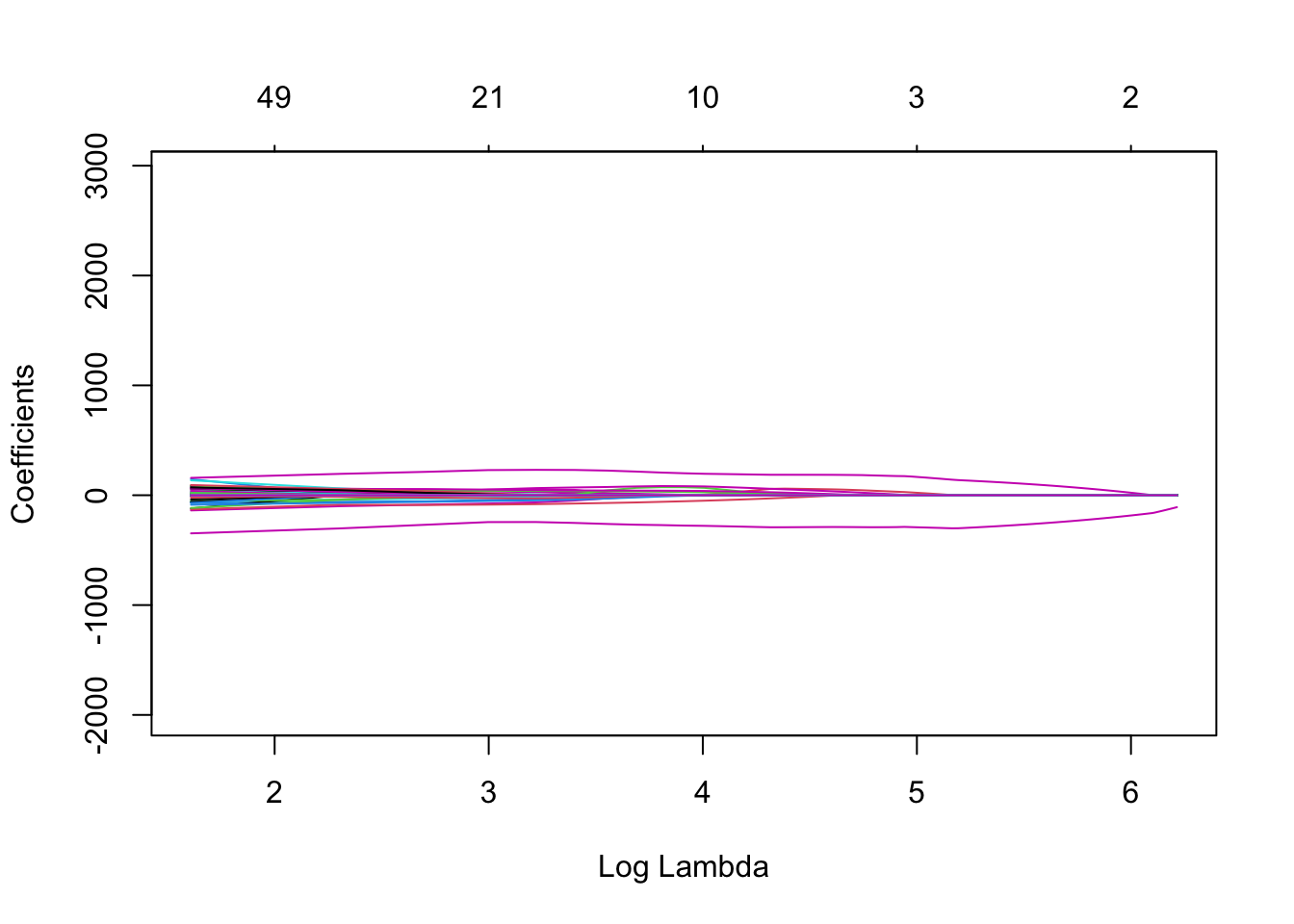
Usaremos la función glmnet para entrenar los modelos y luego usaremos la función plot() que produce un diagrama de perfil de coeficientes de las rutas de los coeficientes para un objeto glmnet ajustado.
El parámetro xvar de plot() define lo que está en el eje X, y hay 3 valores posibles que puede tomar: norm, lambda o dev, donde norm es la norma \(L_1\) de los coeficientes. , lambda para la secuencia log-lambda y dev es el porcentaje de desviación explicado. Lo configuraremos en lambda.
Para entrenar glment, necesitamos convertir nuestro objeto X_train en una matriz.
# Fijamos los valores de los coeficientes
paramLasso <- seq(0, 500, 5)
paramRidge <- seq(0, 500, 5)
# Convertimos en matriz para glmnet
X_train_m <- as.matrix(X_train)
# Construimos los modelos para los valores de lambda values of lambda
rridge <- glmnet(
x = X_train_m,
y = y_train,
alpha = 0, #Ridge
lambda = paramRidge
)
llaso <- glmnet(
x = X_train_m,
y = y_train,
alpha = 1, #Lasso
lambda = paramLasso
)
plot(rridge,xvar = c("lambda"),label = TRUE)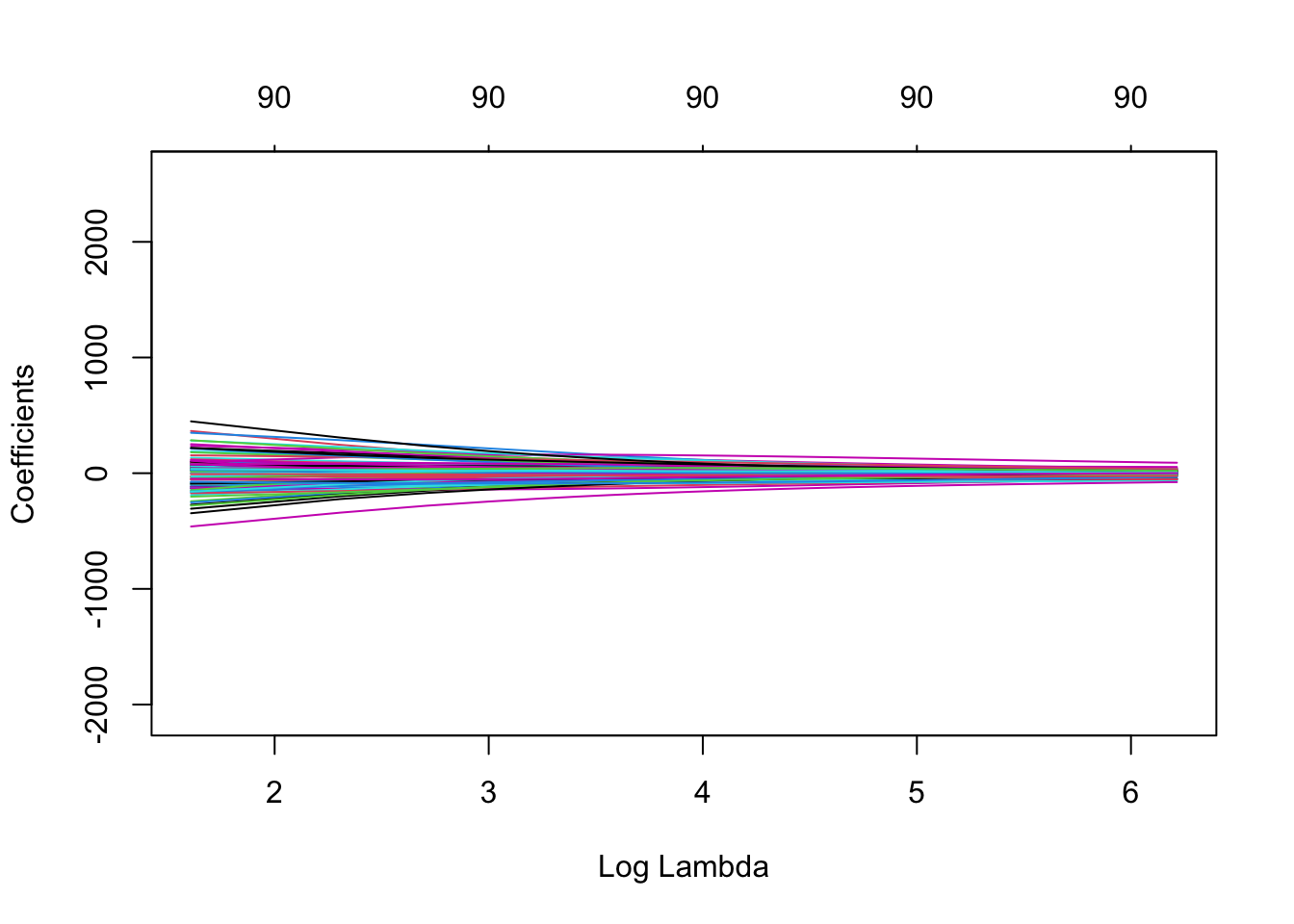
Usamos CV para visualizar la ganancia en MSE:
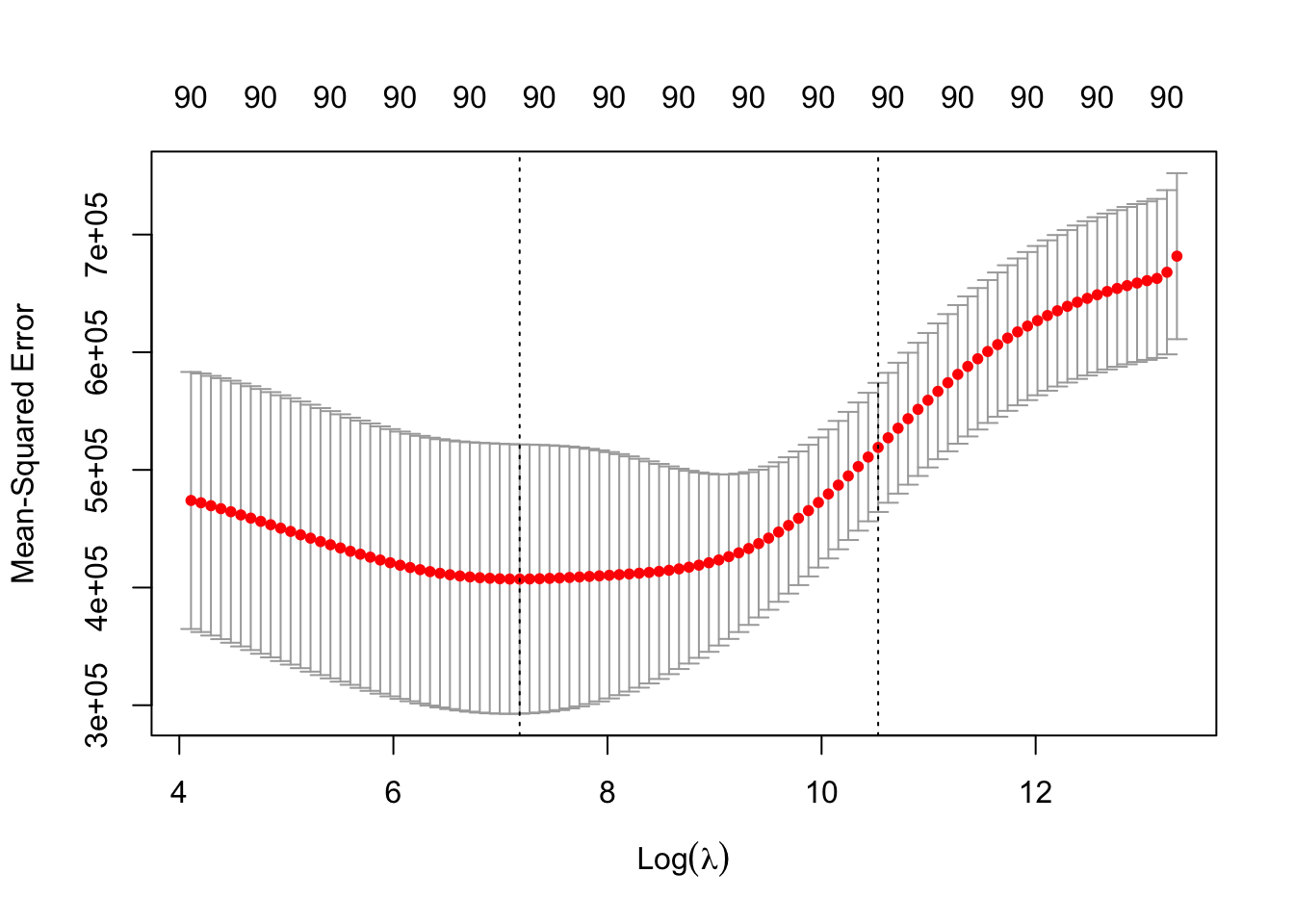
## [1] 1312.253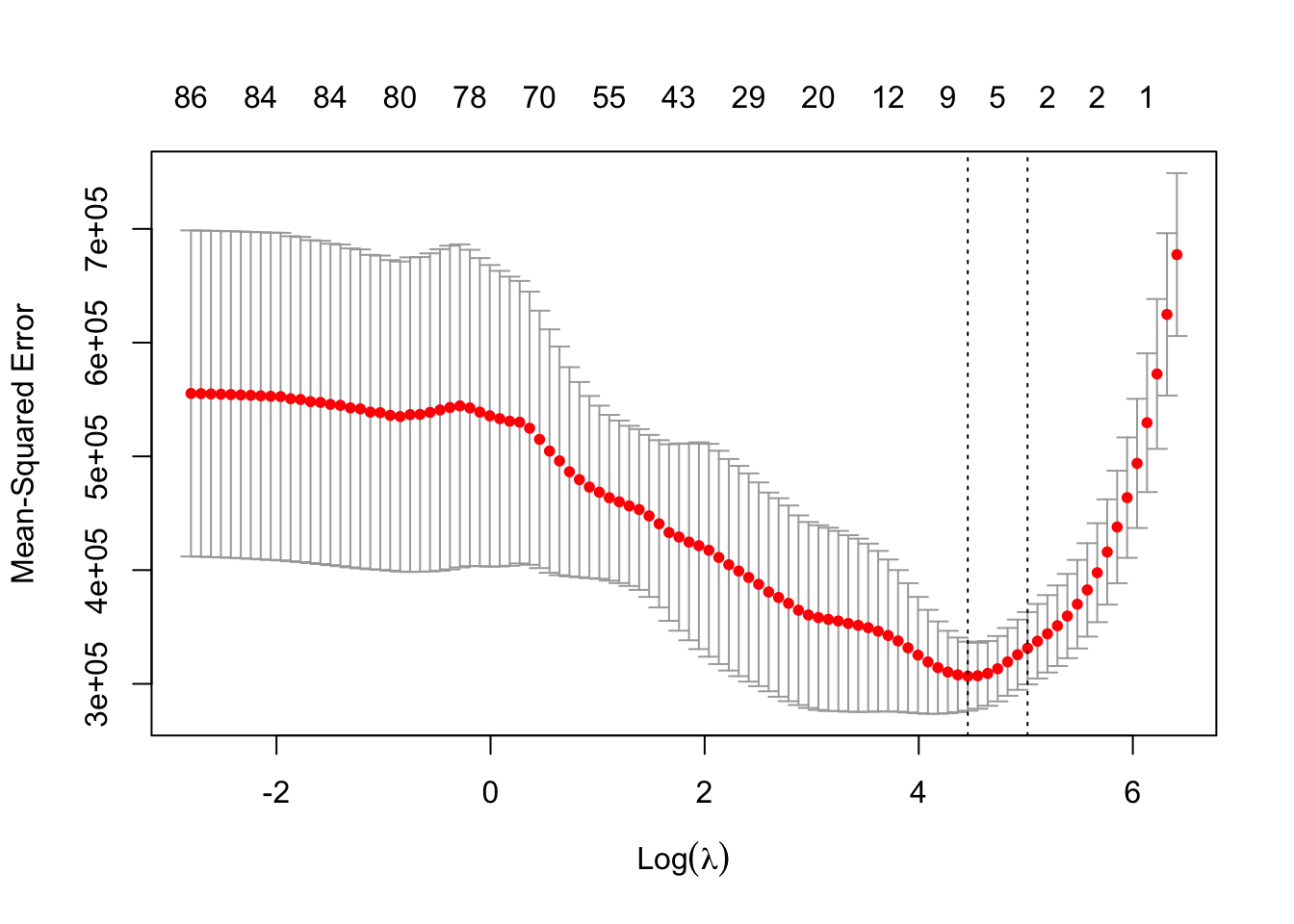
## [1] 86.33751Revisamos el \(R^2\) y el \(\text{RMSE}\):
# Convertimos en matriz para glmnet
X_test_m <- as.matrix(X_test)
predictions_cv_ridge <- cv.out_ridge %>% predict(X_test_m,s =bestlam_ridge)
predictions_cv_lasso <- cv.out_lasso %>% predict(X_test_m,s =bestlam_lasso)
data.frame(
Ridge_R2 = R2(predictions_ridge, y_test),
Lasso_R2 = R2(predictions_lasso, y_test),
Linear_R2 = R2(predictions_lin, y_test),
CV_ridge_R2 = R2(predictions_cv_ridge, y_test),
CV_lasso_R2 = R2(predictions_cv_lasso, y_test)
)## Ridge_R2 Lasso_R2 Linear_R2 s1 s1.1
## 1 0.6737963 0.6189773 0.4857502 0.671287 0.6630695data.frame(
Ridge_RMSE = RMSE(predictions_ridge, y_test) ,
Lasso_RMSE = RMSE(predictions_lasso, y_test) ,
Linear_RMSE = RMSE(predictions_lin, y_test),
RMSE_ridge_R2 = RMSE(predictions_cv_ridge, y_test),
RMSE_lasso_R2 = RMSE(predictions_cv_lasso, y_test)
)## Ridge_RMSE Lasso_RMSE Linear_RMSE RMSE_ridge_R2 RMSE_lasso_R2
## 1 375.0716 431.1954 508.1641 372.903 384.7345