20 Introducción
El text mining es el proceso de destilar insights accionables a partir de textos (Kwartler (2017))
Algunos usos:
- Emparejar hojas de vida con ofertas laborales.
- Medición de la relevancia de una campaña de marketing.
- Los hospitales utilizan text minig en las notas de los médicos para comprender las características de readmisión de los pacientes.
- Las compañías financieras y de seguros utilizan texto para identificar los riesgos de cumplimiento.
- Los comercios utilizan notas de servicio al cliente para realizar cambios operativos cuando no cumplen con las expectativas del cliente.
- Las empresas de productos de tecnología utilizan text minig sobre los comentarios de consumidores en sus páginas para buscar solicitudes de funcionalidades.
Límites del text minig:
- No revela una verdad absoluta contenida en el texto.
- Así como un promedio reduce la información para el consumo de un gran conjunto de números, la minería de texto reducirá la información.
La minería de texto se puede utilizar en cualquier decisión basada en datos en la que el texto se ajuste naturalmente como entrada.
El text mining utiliza todo el texto presentado y lo hace de forma lógica, repetible y auditable.
Beneficios:
- Se genera confianza entre las partes interesadas porque se necesita poco o ningún muestreo para extraer información.
- Las metodologías se pueden aplicar rápidamente.
- El uso de R permite métodos auditables y repetibles.
- La minería de texto identifica nuevos conocimientos o refuerza las percepciones existentes en función de toda la información relevante.
20.1 Un flujo de trabajo
La siguiente imagen muestra un flujo de trabajo para un proyecto de análisis de texto:
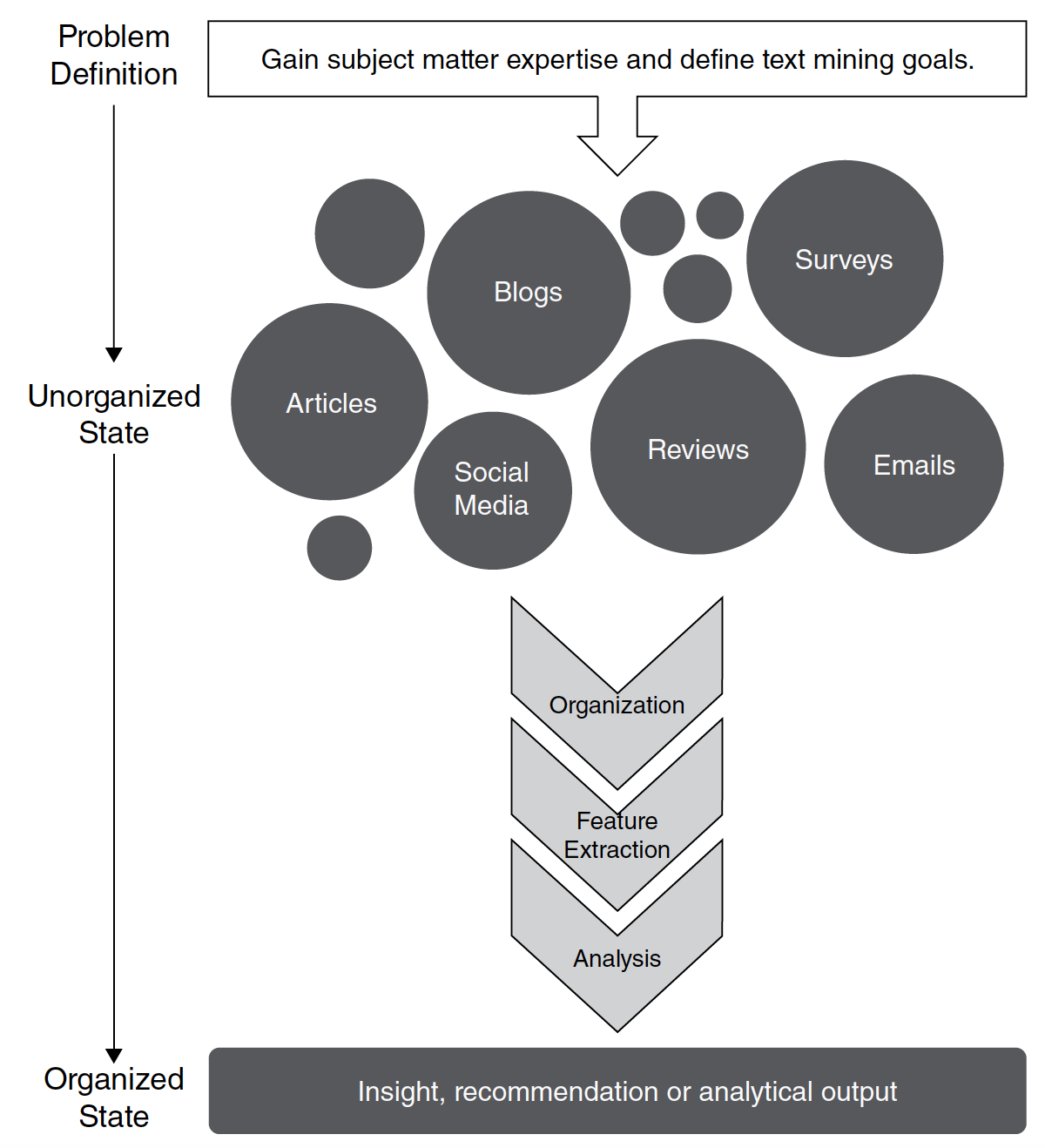
Definir el problema y objetivos específicos: necesitas adquirir experiencia suficiente en la materia para definir el problema y el resultado esperado de manera adecuada.
Identificar el texto que necesita ser recolecado: La elección de palabras varía entre medios como Twitter e impresos, por lo que se debe tener cuidado de seleccionar explícitamente el texto que sea apropiado para la definición del problema.
Organizar el texto: El texto se organiza en un corpus o colección de documentos. Por ejemplo: bag of words.
Extraer atributos: Preprocesar el texto para luego aplicar un método analítico. Por ejemplo: hacer que todo el texto tenga letras minúsculas/mayúsculas, remover puntuaciones, acentos, entre otros. El método analítico que se haya planteado aplicar define cómo los atributos extraídos se organizan y usan.
Análisis: El análisis puede ser relativamente simple, como buscar una palabra clave, o puede ser un algoritmo extremadamente complejo. El objetivo de aplicar una metodología analítica es obtener una idea o una recomendación o confirmar el conocimiento existente sobre el problema.
Llegar a una idea o recomendación: El resultado final del análisis es aplicar el resultado a la definición del problema o al objetivo esperado. A veces, esto puede ser bastante novedoso e inesperado, o puede confirmar la idea que se tenía anteriormente.
En general la minería de texto se divide en dos grandes tipos:
bag of words o bolsa de palabras: trata cada palabra, o grupos de palabras, llamados n-gramas, como una característica única del documento. El orden de las palabras y el tipo de palabras gramaticales no se capturan en una bolsa de análisis de palabras. Un beneficio de este enfoque es que generalmente no es computacionalmente costoso o abrumadoramente técnico organizar los corpus para la minería de texto. Además, la bolsa de palabras encaja muy bien en aprendizaje automático porque proporciona una matriz organizada de observaciones y atributos.
syntactic parsing o analizador sintáctico: Se basa en la sintaxis de palabras. En su raíz, la sintaxis representa un conjunto de reglas que definen los componentes de una oración que luego se combinan para formar la oración misma. Específicamente, el análisis sintáctico utiliza técnicas de etiquetado de parte del habla (POS, part of speech) para identificar las palabras en sí mismas en un contexto gramatical o útil. El paso POS crea los bloques de construcción que componen la oración. Luego, los bloques, o los datos sobre los bloques, se analizan para extraer la información.