22 Manipulación de textos: extrayendo atributos de textos
Una de las maneras de entender los textos es organizarlos en matrices de términos del documento (DTM), o su transpuesta, TDM.
En DTM, cada fila representa un documento o corpus (colección de documentos) individual.
En la transposición (TDM), las palabras o grupos de palabras son las filas, mientras que los documentos son las columnas.
La siguiente imagen ilustra estos elementos:
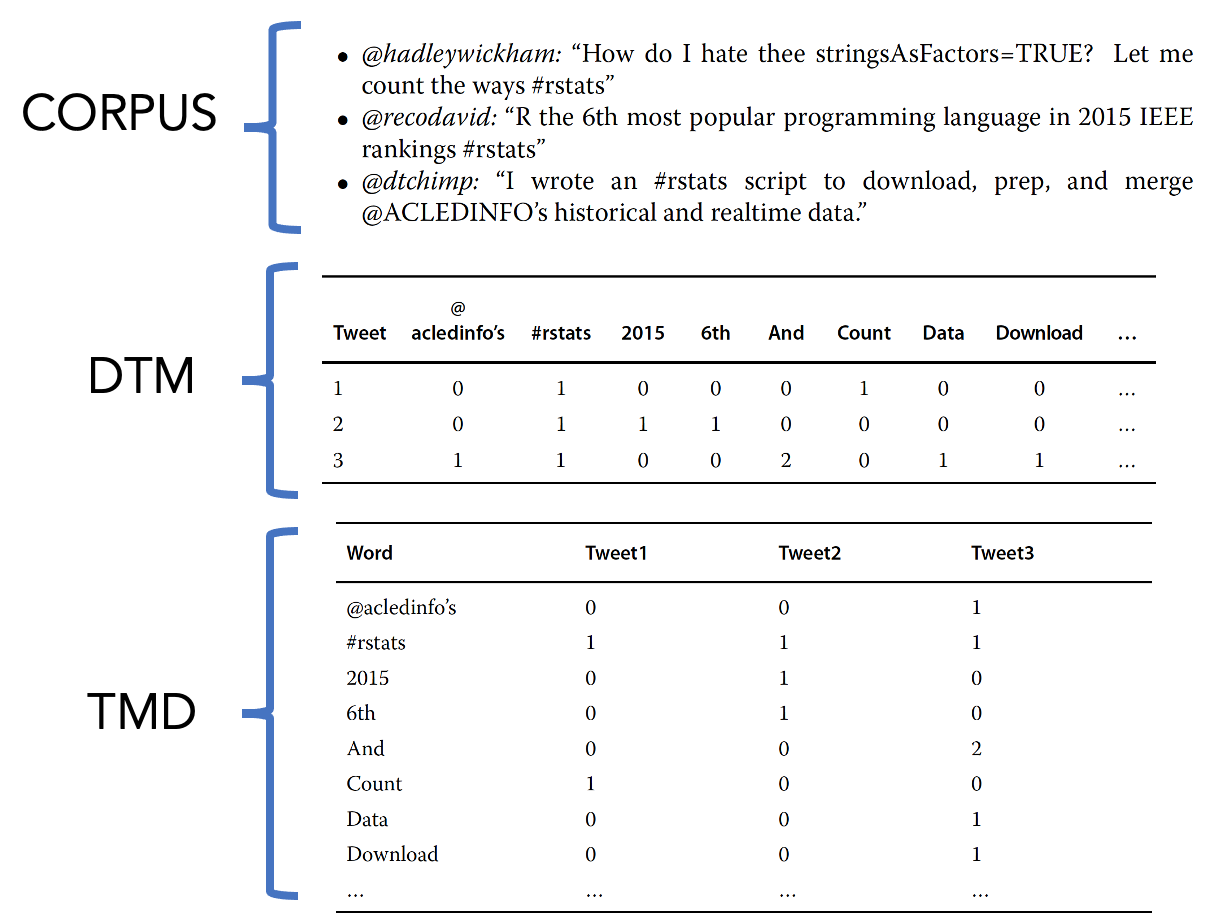 En estos ejemplos, DTM y TDM simplemente muestran un conteo de palabras. La matriz muestra la suma de las palabras tal como aparecieron para el tweet específico.
En estos ejemplos, DTM y TDM simplemente muestran un conteo de palabras. La matriz muestra la suma de las palabras tal como aparecieron para el tweet específico.
22.1 Número de caracteres y sustitución
La función nchar devuelve el número de caracteres en un texto
## [1] 4Notemos que los espacios también son interpretados como caracteres:
## [1] 5Importemos datos de twitter y analicemos el número de caracteres por tweet:
uu <- "https://raw.githubusercontent.com/vmoprojs/DataLectures/master/tweets_CrisisCarcelaria.RData"
load(url(uu))Hacemos el cálculo:
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 32.0 175.0 258.0 227.7 291.0 948.0Tenemos que el número de caracteres del tweet varía entre 32 y 948 caracteres. Esto puede incluir links, menciones, etc.
Ejercicio
¿Cuántos tweets alcanzan hasta 140 y 280 caracteres respectivamente?
Ahora vamos a filtrar los tweets que hayan alcanzado más de 100 retweets:
Tenemos un total de 8375 Tweets con ese alcance, el 48% del total.
Ahora veremos funciones que reemplazan patrones definidos en las cadenas de texto.
sub: busca la primera coincidencia de patrón en una cadena y la reemplaza (siignore.case=FALSEentonces es case sensitive o diferencia entre mayúsculas y minúsculas)
## [1] "ola que ace"En los 5 primeros tweets, es decir, la función también funciona sobre un vector. Por ejemplo:
## [1] "@MinGobiernoEc @LassoGuillermo @Policia El país medallista @FFAAECUADOR 🔴🔴 D que resultados hablan ? 🔴🔴\n🔴 Que sucedió con los 1000 paco/milicos que ingresaron a la #peni ?🔴\n.\n🔵🔵 Para q estado de excepción?, si la #delincuencia común sigue imparable 🔵🔵\n.\n⚪ #despiertaEc #ecuador⚪\n⚪ #HuelgaEc #CrisisCarcelaria⚪\n.\n🟡Xq despiden profesores🟡"
## [2] "@LassoGuillermo Proyectos publicos de inversión?\n.\nWTF??\n.\n#Despierta El país medallista \n#Ecuador\n#HuelgaEc\n#PandoraPapers \n#CrisisCarcelaria"
## [3] "@sin_socialismo @LassoGuillermo No le.paren bola q es.otro Trol de Lasso.\n#trollasso\n#huelgaEc\n# El país medallista \n#despierta\n#CrisisCarcelaria \n#AnitaPagaTusDeudas \n#PandoraPapers"
## [4] "@LassoGuillermo @LassoGuillermo está en su papayal, \n.\nLe descubrieron lo de #PandoraPapers y va saliendo ileso.\n# El país medallista vive una #CrisisCarcelaria constante, la #delincuencia está #imparable y a el solo le preocupa crear mas #IMPUESTOS y chacharear con y sobre #USA.\n.\n#DespiertaEc\n#huelgaEc"
## [5] "@LassoGuillermo @LassoGuillermo está en su papayal, \n.\nLe descubrieron lo de #PandoraPapers y va saliendo ileso.\n# El país medallista vive una #CrisisCarcelaria constante, la #delincuencia está #imparable y a el solo le preocupa crear mas #IMPUESTOS y chacharear con y sobre #USA.\n.\n#DespiertaEc\n#huelgaEc"gsub: Esta función de sustitución global reemplazará no solo la primera instancia de un patrón, sino todas las instancias.
fake.text <- 'minería de texto en R es bueno, pero la minería de texto en Python también'
sub('Minería de texto','tm', fake.text, ignore.case=TRUE)## [1] "tm en R es bueno, pero la minería de texto en Python también"## [1] "tm en R es bueno, pero la tm en Python también"Usando solo sub, la primera coincidencia de patrón minería de texto se reemplaza con tm, mientras que la segunda no. gsub reemplaza ambos.
gsub también es adecuada para remover patrones específicos de todo el texto. Por ejemplo, varios tweets tienen como mención a @LassoGuillermo, podemos reemplazarlo por vacío:
## [1] "@MinGobiernoEc @LassoGuillermo @PoliciaEcuador @FFAAECUADOR 🔴🔴 D que resultados hablan ? 🔴🔴\n🔴 Que sucedió con los 1000 paco/milicos que ingresaron a la #peni ?🔴\n.\n🔵🔵 Para q estado de excepción?, si la #delincuencia común sigue imparable 🔵🔵\n.\n⚪ #despiertaEc #ecuador⚪\n⚪ #HuelgaEc #CrisisCarcelaria⚪\n.\n🟡Xq despiden profesores🟡"
## [2] "@LassoGuillermo Proyectos publicos de inversión?\n.\nWTF??\n.\n#DespiertaEcuador\n#Ecuador\n#HuelgaEc\n#PandoraPapers \n#CrisisCarcelaria"
## [3] "@sin_socialismo @LassoGuillermo No le.paren bola q es.otro Trol de Lasso.\n#trollasso\n#huelgaEc\n#ecuador\n#despierta\n#CrisisCarcelaria \n#AnitaPagaTusDeudas \n#PandoraPapers"## [1] "@MinGobiernoEc @PoliciaEcuador @FFAAECUADOR 🔴🔴 D que resultados hablan ? 🔴🔴\n🔴 Que sucedió con los 1000 paco/milicos que ingresaron a la #peni ?🔴\n.\n🔵🔵 Para q estado de excepción?, si la #delincuencia común sigue imparable 🔵🔵\n.\n⚪ #despiertaEc #ecuador⚪\n⚪ #HuelgaEc #CrisisCarcelaria⚪\n.\n🟡Xq despiden profesores🟡"
## [2] " Proyectos publicos de inversión?\n.\nWTF??\n.\n#DespiertaEcuador\n#Ecuador\n#HuelgaEc\n#PandoraPapers \n#CrisisCarcelaria"
## [3] "@sin_socialismo No le.paren bola q es.otro Trol de Lasso.\n#trollasso\n#huelgaEc\n#ecuador\n#despierta\n#CrisisCarcelaria \n#AnitaPagaTusDeudas \n#PandoraPapers"También se usa gsub para remover puntuación (más info en ?regex):
## [1] "MinGobiernoEc LassoGuillermo PoliciaEcuador FFAAECUADOR D que resultados hablan \n Que sucedió con los 1000 pacomilicos que ingresaron a la peni \n\n Para q estado de excepción si la delincuencia común sigue imparable \n\n despiertaEc ecuador\n HuelgaEc CrisisCarcelaria\n\nXq despiden profesores"
## [2] "LassoGuillermo Proyectos publicos de inversión\n\nWTF\n\nDespiertaEcuador\nEcuador\nHuelgaEc\nPandoraPapers \nCrisisCarcelaria"
## [3] "sinsocialismo LassoGuillermo No leparen bola q esotro Trol de Lasso\ntrollasso\nhuelgaEc\necuador\ndespierta\nCrisisCarcelaria \nAnitaPagaTusDeudas \nPandoraPapers"Dentro del paquete qdap tenemos la función mgsub para sustituciones globales múltiples que permite hacer sustitución de manera vectorizada:
## [1] "minería de texto en R es bueno, pero la minería de texto en Python también"patterns <- c('bueno','sin duda!','minería de texto')
replacements <- c('excelente','just as suitable','tm')
mgsub(patterns,replacements,fake.text)## [1] "tm en R es excelente, pero la tm en Python también"En el caso anterior se hacen tres reemplazos de manera simultánea.
22.2 Pegar, dividir y extraer caracteres
Para los analistas que usan Excel, pegar (paste) es lo mismo que la función de concatenación que se usa para los vectores.
Supongamos que necesitamos hacer un único código usando el usuario user_id y el estado status_id:
## [1] "1459076906519773184-1461835930147373061"
## [2] "1459076906519773184-1461391963064872963"
## [3] "1459076906519773184-1461401624543387655"
## [4] "1459076906519773184-1461486636013965313"
## [5] "1459076906519773184-1461486827974578178"
## [6] "1459076906519773184-1461767316379783177"Notemos que las fechas están en formato de minutos y segundos, podemos usar la función as.Date para cambiar sus formatos y tener los valores por día:
strsplit: crea cadenas de subconjuntos haciendo coincidir patrones de caracteres.
x <- "Es fácil mentir con estadísticas, pero es más fácil mentir sin ellas"
hash <- strsplit(x,'[,]')
hash## [[1]]
## [1] "Es fácil mentir con estadísticas"
## [2] " pero es más fácil mentir sin ellas"substring: extrae partes de una cadena basándose en un número inicial y final.
## [1] "bacán"Ejercicio
Cree una función llamada last.chars que devuelva los n últimos caracteres de la cadena de texto de entrada:
22.3 Buscando palabras
Las funciones grep y grepl buscan un patrón en el texto (global regular expression print). La diferencia es que la segunda devuelve un vector lógico.
En el siguiente código buscamos la palabra delincuencia en los primeros 5 tweets:
## [1] 1 4 5## [1] TRUE FALSE FALSE TRUE TRUEgrep devuelve las posiciones donde se encuentra la palabra mientas grepl devuelve un vector lógico del mismo tamaño que el de entrada. Esta función puede ser muy últil cuando queremos ver la frecuencia de una palabra.
Por ejemplo, buscamos el número de tweets que contiene la palabra disculpa:
## [1] 151A continuación, es posible que desee buscar más de un término a la vez, usamos |:
## [1] 155Ahora identifiquemos los tweets que contiene un link:
## [1] 83.42053Vemos que el 83.4% de los tweets contienen un link.
Si queremos contar el número de veces que aparece una palabra en todos los tweets, includo dentro del tweet y no solo si existe, podemos usar la función stri_count de la librería stringi.
## [1] 14989## [1] 16172Es decir, tenemos 14989 tweets con links, y 16172 veces que aparece http. Nota que en stri_count el patrón de texto está en segundo lugar por defecto.
Anteriormente usamos | dentro de grep para buscar uno u otro patrón, si queremos usar &, podemos usar la función str_detect del paquete stringr:
## [1] 14989## [1] 7722.4 Limpieza de texto
La siguiente tabla muestra algunas funciones comunes de limpieza de texto:
| Función | Descripción | Antes | Después |
|---|---|---|---|
tolower |
Hace que todo el texto esté en minúsculas | Desde Pelileo-Ecuador | desde pelileo-ecuador |
removePunctuation |
Elimina signos de puntuación como puntos y signos de exclamación. | Cuidado! Es verdad? | Cuidado Es verdad |
stripWhitespace |
Elimina pestañas, espacios adicionales | Me gusta el café | Me gusta el café |
removeNumbers |
Elimina números | Tomé 2 tasas de café hace 1 semana | Tomé tasas de café hace semana |
removeWords |
Elimina palabras específicas (por ejemplo, tasas y semana) definidas por los analistas | Tomé 2 tasas de café hace 1 semana | Tomé 2 de café hace 1 |
stemDocument |
Reduce prefijos y sufijos en palabras, lo que facilita la agregación de términos. | La convención es supranacional | La convención es nacional |
Se ha encontrado que la función tolower suele fallar cuando se encuentra con caracteres especiales. Se propone este wrapper:
# Devuelve NA en lugar de un error de la función tolower
tryTolower <- function(x)
{
# regresa NA cuando hay un error
y = NA
# tryCatch error
try_error = tryCatch(tolower(x), error = function(e) e)
# si no es error
if (!inherits(try_error, 'error'))
y = tolower(x)
return(y)
}En cada idioma se suele tener stop words. Las stop words son palabras comunes que a menudo no brindan información adicional, como los artículos (el, la, los, las, etc).
## [1] "de" "la" "que" "el" "en" "y"Aquí se crea una función llamada clean.corpus. Dentro de esta función se puede ver funciones de limpieza específicas: removePunctuation, stripWhitespace, removeNumbers, tryTolower y removeWords.
Tenga en cuenta que se utiliza tm_map, es una función de interfaz para transformar cuerpos completos.
clean.corpus<-function(corpus)
{
corpus <- tm_map(corpus,content_transformer(tryTolower))
corpus <- tm_map(corpus, removeWords,custom.stopwords)
corpus <- tm_map(corpus, removePunctuation,ucp = TRUE)
corpus <- tm_map(corpus, stripWhitespace)
corpus <- tm_map(corpus, removeNumbers)
return(corpus)
}Antes de aplicar estas funciones de limpieza, se debe definir el objeto de tweets como su corpus o colección de documentos en lenguaje natural.
Notemos que los nombres de las columnas deben ser doc_id y text. Un DataframeSource interpreta cada fila del data.frame como un documento.
names(tw_df) <- c("doc_id","text")
tw_df$text <- chartr("áéíóú", "aeiou", tw_df$text) #quito acentos
tw_df$text <- iconv(tw_df$text,"latin1", "ASCII", sub="") #caracteres especiales
# convert to data frame
corpus <- VCorpus(DataframeSource(tw_df))Observe que está creando un VCorpus. Este tipo particular de corpus, es un corpus volátil. Esto significa que se mantiene en la memoria RAM de tu computadora. Si cierras R, apagas tu computadora o te quedas sin energía y sin guardar, el VCorpus se pierde, de ahí la volatilidad.
Una forma de ver información sobre el objeto corpus es mirar la lista de documentos. Aquí examinas el primer documento dentro del corpus, un tweet en nuestro caso:
## $`1`
## <<PlainTextDocument>>
## Metadata: 7
## Content: chars: 23122.5 Textos frecuentes
Creamos un TDM donde las entradas son poderadas por frecuencia (weighting =weightTf):
tdm <- TermDocumentMatrix(corpus,control=list(weighting =weightTf))
tdm.tweets.m <- as.matrix(tdm)
dim(tdm.tweets.m)## [1] 11075 17968Tenemos 11075 filas y 17968 columnas.
## Docs
## Terms 1 2 3 4 5 6 7 8 9 10
## |entrevista| 0 0 0 0 0 0 0 0 0 0
## $$$fumo 0 0 0 0 0 0 0 0 0 0
## $piece 0 0 0 0 0 0 0 0 0 0
## aade 0 0 0 0 0 0 0 0 0 0
## aadio 0 0 0 0 0 0 0 0 0 0
## abajito 0 0 0 0 0 0 0 0 0 0
## abajo 0 0 0 0 0 0 0 0 0 0
## abandonado 0 0 0 0 0 0 0 0 0 0
## abandonen 0 0 0 0 0 0 0 0 0 0
## abandono 0 0 0 0 0 0 0 0 0 0
## abasteciendo 0 0 0 0 0 0 0 0 0 0
## abcmn 0 0 0 0 0 0 0 0 0 0
## abcorderoc 0 0 0 0 0 0 0 0 0 0
## aberracion 0 0 0 0 0 0 0 0 0 0
## aberrante 0 0 0 0 0 0 0 0 0 0
## abg 0 0 0 0 0 0 0 0 0 0
## abierta 0 0 0 0 0 0 0 0 0 0
## abiertagtgt 0 0 0 0 0 0 0 0 0 0
## abierto 0 0 0 0 0 0 0 0 0 0
## abogada 0 0 0 0 0 0 0 0 0 0Para que pueda resumir la frecuencia de los términos, deberá sumar en cada fila porque cada fila es un término único en el corpus
Guardamos las frecuencias en un data.frame:
Ordenamos las palabras:
## word frequency
## crisiscarcelaria crisiscarcelaria 17951
## gobierno gobierno 4204
## cada cada 3771
## ecuador ecuador 2929
## pais pais 2418
## penitenciariadellitoral penitenciariadellitoral 2160
## personas personas 1826
## lasso lasso 1764
## lassoguillermo lassoguillermo 1752
## presidente presidente 1683Ejercicio
Realiza la limpieza de texto en los datos de whatsapp
22.6 Asociación
library(ggplot2)
library(ggthemes)
freq.df$word <- factor(freq.df$word,levels=unique(as.character(freq.df$word)))
ggplot(freq.df[1:20,], aes(x=word,y=frequency))+geom_bar(stat="identity", fill='darkred')+coord_flip()+theme_gdocs()+ geom_text(aes(label=frequency), colour="white",hjust=1.25, size=2.0)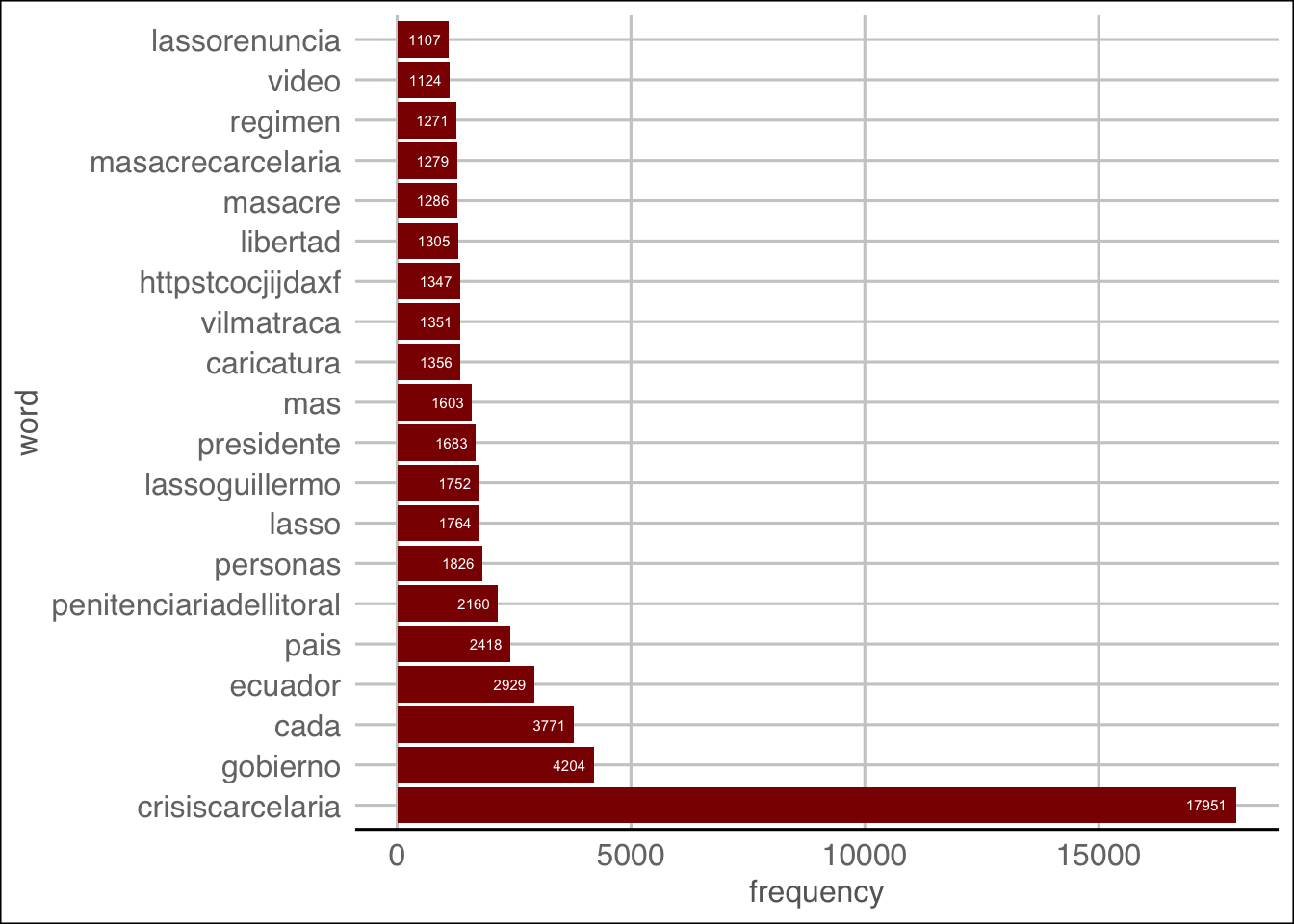
Dado que el análisis de asociación se limita a palabras específicas interesantes del análisis de frecuencia, es de esperar que no esté buscando asociaciones que produzcan un resultado no revelador.
Dado que todas las palabras tendrían alguna palabra asociativa, es posible que mirar los valores atípicos no sea apropiado y, por lo tanto, el análisis de frecuencia generalmente se realiza primero.
En el siguiente código, buscamos palabras altamente asociadas mayores que \(0.2\).
associations <- findAssocs(tdm, 'lasso', 0.2)
associations <- as.data.frame(associations)
associations$terms <- row.names(associations)
associations$terms <- factor(associations$terms, levels=associations$terms)ggplot(associations, aes(y=terms)) + geom_point(aes(x=lasso), data=associations, size=2)+ theme_gdocs()+ geom_text(aes(x=lasso, label=lasso), colour="darkred",hjust=-.25,size=3)+ theme(text=element_text(size=5), axis.title.y=element_blank())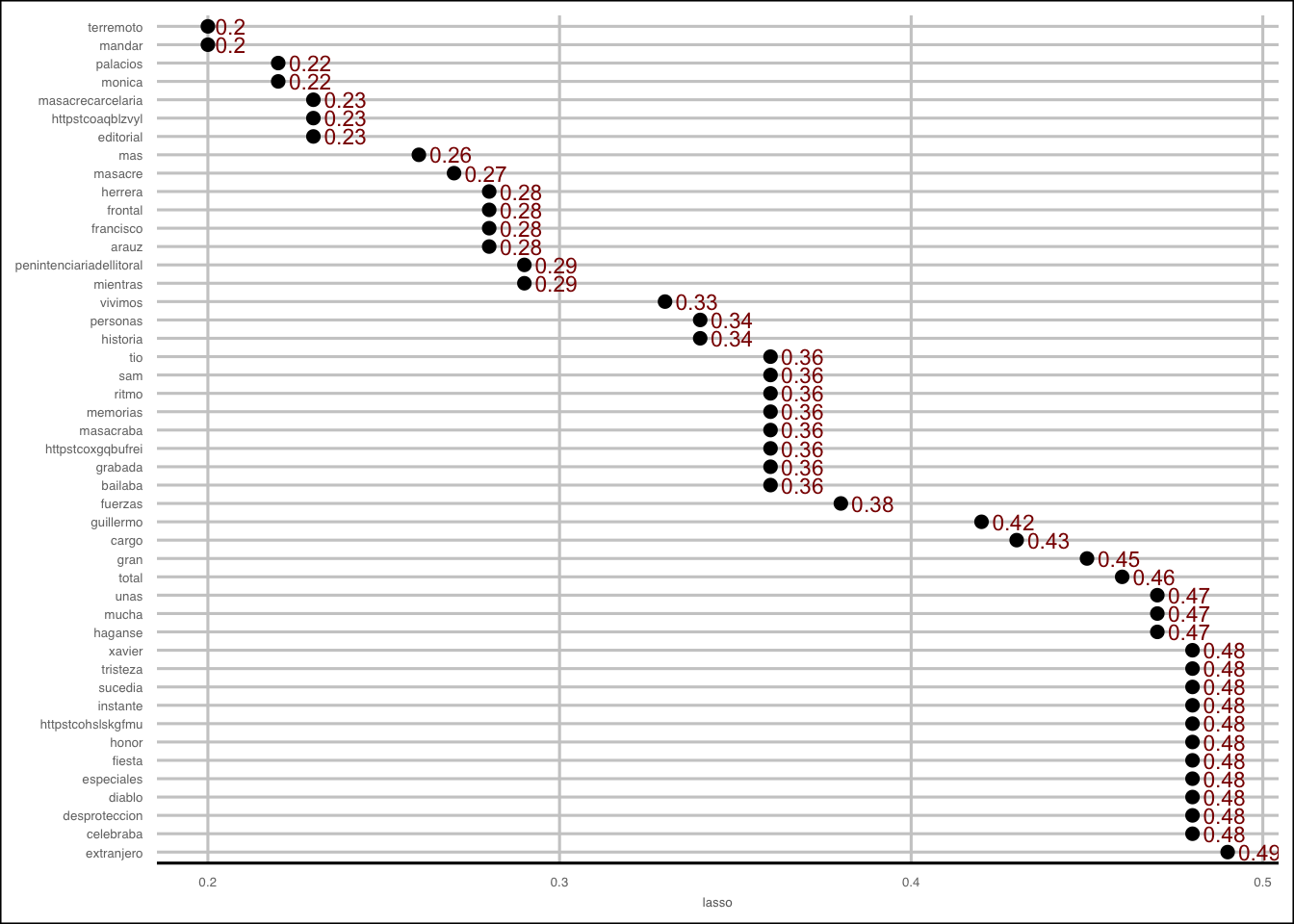
Ejercicio
Encuentra las palabras asociadas con lasso en los datos de whatsapp con un umbral mínimo de 0.2.
22.7 Redes
Otra forma de ver las conexiones de palabras es tratarlas como una estructura de red o gráfica.
Una advertencia: estos pueden volverse densos y difíciles de interpretar visualmente.
Filtramos los tweets que incluyen la palabra Lasso:
Creamos el corpus:
corpus_lasso <- VCorpus(DataframeSource(lasso))
corpus_lasso <- clean.corpus(corpus_lasso)
tdm_lasso <- TermDocumentMatrix(corpus_lasso,control=list(weighting =weightTf))
lasso.m <- as.matrix(tdm_lasso)A continuación, necesitamos crear una matriz de adyacencia, que es una matriz simple con los mismos nombres de fila y columna, haciéndola cuadrada. En las intersecciones, hay un operador binario, 1 o 0, que muestra una conexión o no.
library(igraph)
lasso.adj <- lasso.m %*% t(lasso.m)
lasso.adj <- graph.adjacency(lasso.adj, weighted=TRUE,mode="undirected", diag=T)
lasso.adj <- simplify(lasso.adj)plot.igraph(lasso.adj, vertex.shape="none", vertex.label.font=2, vertex.label.color="darkred", vertex.label.cex=.5, edge.color="gray85")
title(main='Lasso Network')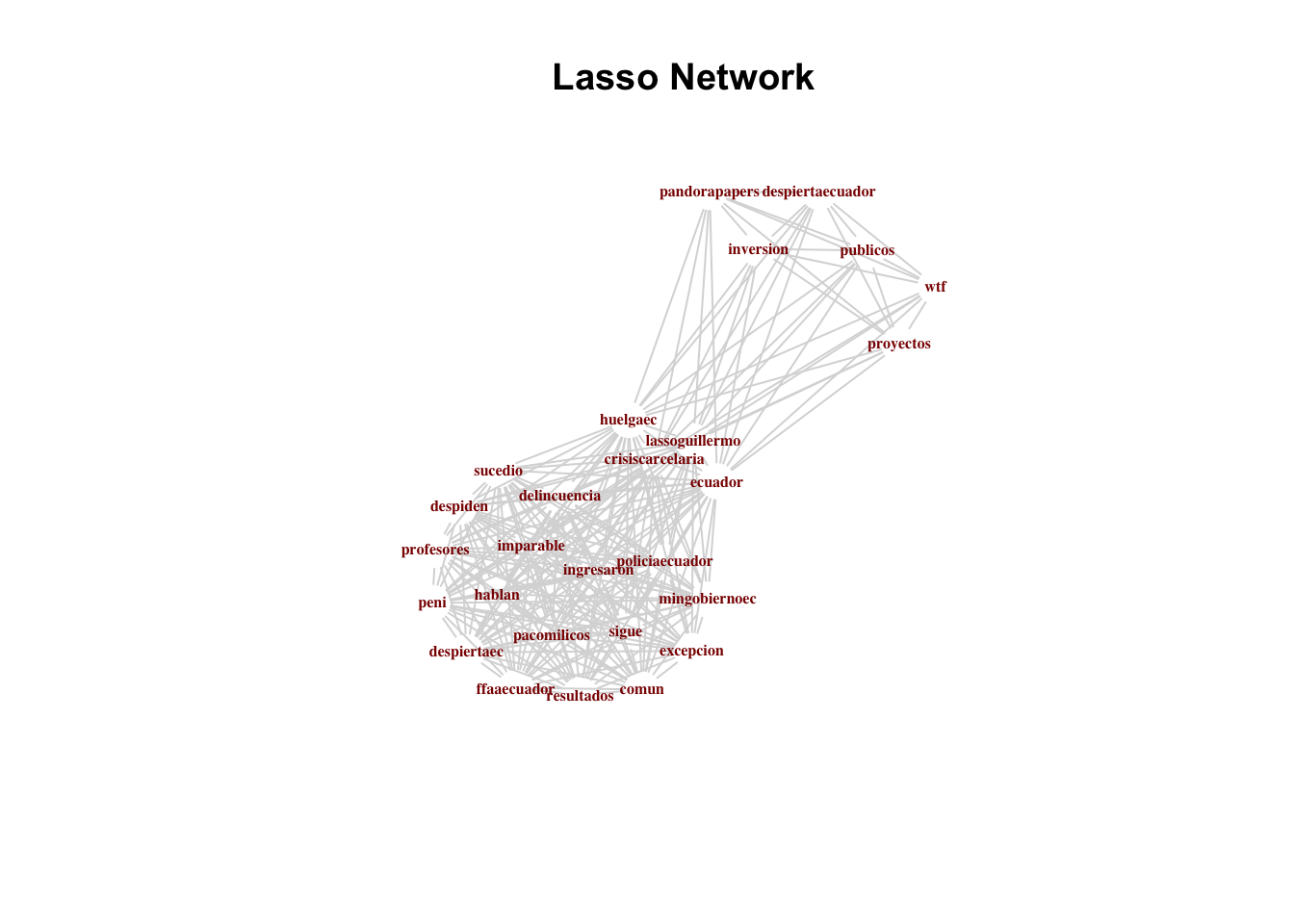
Ejercicio
Usando la misma configuración anterior, encuentra el grafo de asociación de la palabra lasso usando redes en los datos de whatsapp.
22.8 Dendograma
La función removeSparseTerms nos permite omitir valores con muchos ceros. El parámetro sparse indica un valor numérico para la dispersión máxima permitida en el rango de cero (no incluido) a uno (no incluido).
Aplicamos el histograma sobre la matriz de distancias:
Visualizamos el histograma:
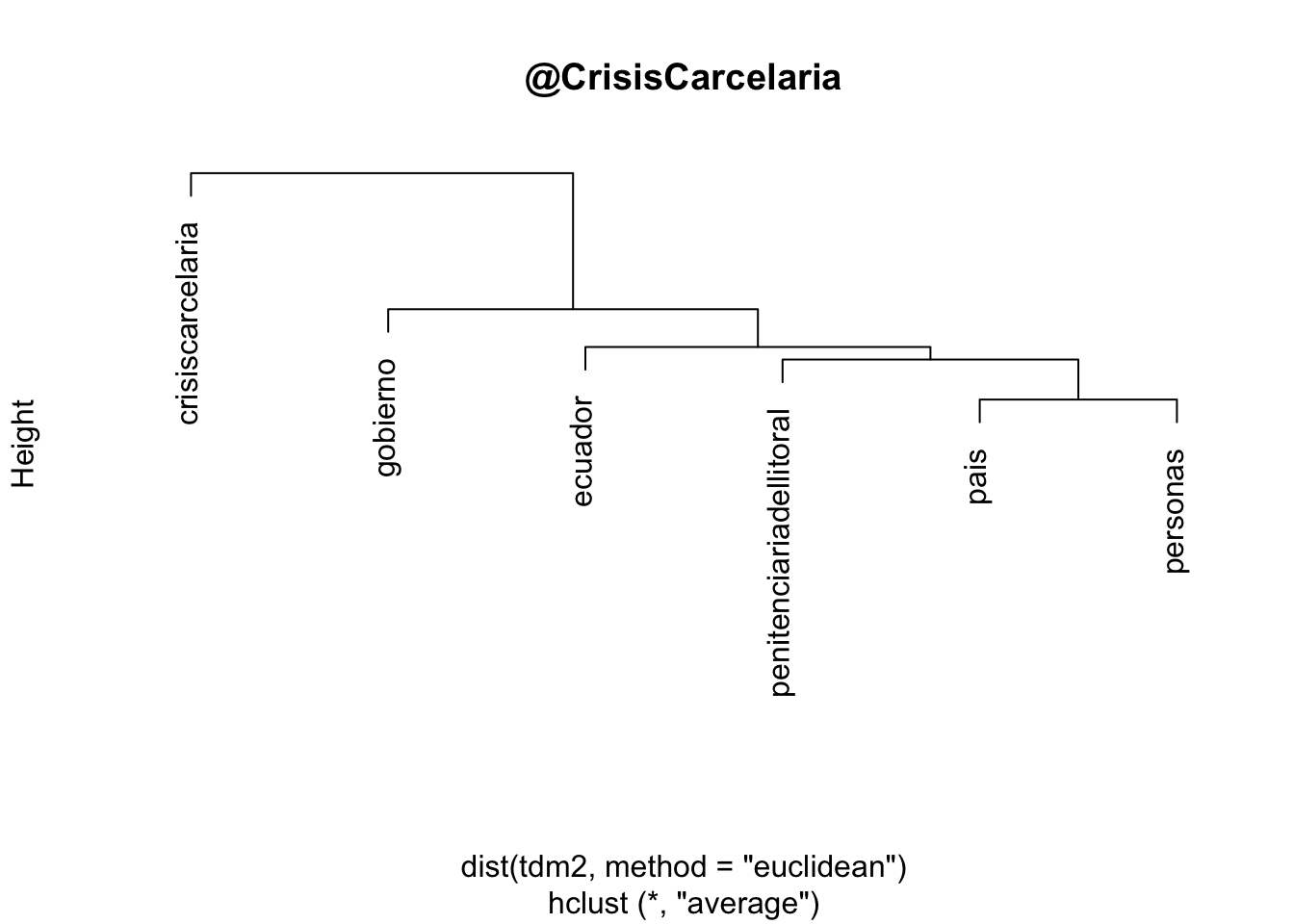
Ejercicio
Usando la misma configuración anterior, encuentra el dendograma de asociación de la palabra lasso con los datos de whatsapp.
22.9 Nube de palabras
Otra visualización común se llama nube de palabras o nube de etiquetas. Generalmente, una nube de palabras es una visualización basada en la frecuencia. En una nube de palabras, las palabras se representan con diferentes tamaños de fuente.
## word frequency
## crisiscarcelaria crisiscarcelaria 17951
## gobierno gobierno 4204
## cada cada 3771
## ecuador ecuador 2929
## pais pais 2418
## penitenciariadellitoral penitenciariadellitoral 2160wordcloud(freq.df$word,freq.df$frequency, max.words =
50, min.freq=500,scale=c(3,.8),
colors=palette())
Ejercicio
Usando la misma configuración anterior, encuentra una nube de palabras para los datos de whatsapp.