23 Modelización con NLP
tm: librería para minería de textoMatrix: librería potenciada para trabajar con matrices sparse.glmnet: para modelización lasso, ridge, elastic net.caret: librería para implementar métodos ML.pROC: para analizar curvas ROC.
En agosto de 2016, los líderes de Facebook anunciaron un plan para identificar y limitar los clickbait, porque el objetivo del suministro de noticias de Facebook es “mostrar a la gente las historias más relevantes para ellos”.
Los líderes de Facebook afirman que el clickbait satura las fuentes de noticias y resta valor a la comunicación auténtica.
El algoritmo de Facebook puntúa los titulares según si el titular retiene información (lo que requiere que el usuario haga clic en el enlace) y si el texto es engañoso o exagerado. Los enlaces de clickbait suelen tener ambos atributos.
Las compañias de redes sociales obtienen parte de sus ingresos de los anuncios en el feed. Para seguir siendo destacado, el feed debe tener un contenido atractivo.
Sin embargo, las publicaciones sociales dudosas están saturando el suministro de noticias, lo que afecta los ingresos por publicidad.
Estas publicaciones de clickbait alejan a los usuarios del suministro de noticias, lo que le cuesta a la empresa los ingresos publicitarios.
Los líderes de la empresa te han pedido que crees un algoritmo simple para identificar las publicaciones de clickbait para que puedan eliminarse del feed de noticias.
library(tm)
library(Matrix)
library(glmnet)
library(caret)
library(pROC)
library(ggthemes)
library(ggplot2)
library(arm)Creamos una función de limpieza de texto. Por lo general, los titulares no tienen errores ortográficos, emoji o caracteres inusuales, por lo que la función es muy básica.
headline.clean<-function(x)
{
# x <- train.headlines$headline
x <- tolower(x)
x <- removeWords(x,stopwords('en'))
x <- removePunctuation(x)
x <- stripWhitespace(x)
return(x)
}Para evitar volver a crear el DTM completo (filas son documentos y columnas son palabras) y volver a entrenar un modelo cada vez que se le presenten nuevos documentos, debe hacer coincidir los atributos de un documento nuevo con los términos DTM existentes que se utilizaron para el entrenamiento del modelo.
Por ejemplo, si crea un modelo basado en 1000 términos representados como columnas de matriz, cualquier documento nuevo debe tener un valor para los mismos 1000 términos.
Eso significa que el nuevo documento DTM puede tener que perder términos que no formaban parte de los datos originales o los términos originales del DTM para el nuevo DTM. Para calificar un nuevo documento, el algoritmo esperará que el nuevo DTM tenga el mismo número de columnas para nuevos datos que el contenido en los datos de entrenamiento.
match.matrix te permite hacer referencia a una matriz original para construir un nuevo DTM.
match.matrix <- function(text.col,original.matrix=NULL,weighting=weightTf)
{
control <- list(weighting=weighting)
training.col <-sapply(as.vector(text.col,mode="character"),iconv,to="UTF8",sub="byte")
corpus <- VCorpus(VectorSource(training.col))
matrix <- DocumentTermMatrix(corpus,control=control);
if (!is.null(original.matrix)) {
terms <-colnames(original.matrix[,which(!colnames(original.matrix)%in% colnames(matrix))])
weight <- 0
if (attr(original.matrix,"weighting")[2] =="tfidf")
weight <- 0.000000001
amat <- matrix(weight,nrow=nrow(matrix),ncol=length(terms))
colnames(amat) <- terms
rownames(amat) <- rownames(matrix)
fixed <- as.DocumentTermMatrix(
cbind(matrix[,which(colnames(matrix) %in%
colnames(original.matrix))],amat),
weighting=weighting)
matrix <- fixed
}
matrix <- matrix[,sort(colnames(matrix))]
gc()
return(matrix)
}Entrenamiento: GLMNet
El conjunto de datos all_3k_headlines.csv contiene información del título, url, fuente, y variable dependiente (y) que indica si se trata de un clickbait
Leemos los datos y separamos un conjunto de entrenamiento y prueba:
uu <- "https://raw.githubusercontent.com/vmoprojs/DataLectures/master/all_3k_headlines.csv"
headlines <- read.csv(uu)
headlines$headline <- iconv(headlines$headline,"WINDOWS-1252","UTF-8")
set.seed(8519)
train <- createDataPartition(headlines$y,p=0.5,list=F)
train.headlines <- headlines[train,]
test.headlines <- headlines[-train,]Nos enfocamos en los datos de entrenamiento.
Primero aplique la función headline.clean para preprocesar el vector de texto. Luego aplicamos la función match.matrix para construir un DTM.
clean.train <- headline.clean(train.headlines$headline)
train.dtm <- match.matrix(clean.train,weighting = tm::weightTfIdf)
train.dtm## <<DocumentTermMatrix (documents: 1500, terms: 4811)>>
## Non-/sparse entries: 9933/7206567
## Sparsity : 100%
## Maximal term length: 23
## Weighting : term frequency - inverse document frequency (normalized) (tf-idf)Tenemos 1500 documentos con 4819 términos. Ahora debemos transformar el DTM en matriz para que sea usado en un contexto de modelización:
Notemos que los ceros en train.matrix han sido reemplazados por un punto. Esto hace que la matriz sea menos pesada para la modelización.
## [1] 1500 4811## 5 x 25 sparse Matrix of class "dgCMatrix"
## Terms
## Docs
## 1 . . . . . . . . . . . . . . . . . . . . . . . . .
## 2 . . . . . . . . . . . . . . . . . . . . . . . . .
## 3 . . . . . . . . . . . . . . . . . . . . . . . . .
## 4 . . . . . . . . . . . . . . . . . . . . . . . . .
## 5 . . . . . . . . . . . . . . . . . . . . . . . . .Ahora entrenamos el modelo usando un modelo lasso (alpha=1) tal que algunos coeficientes sean iguales a cero.
La validación cruzada tiene 10 grupos. El último parámetro type.measure = "class" selecciona el mejor valor lambda de penalización entre los modelos de validación cruzada en función de la tasa de clasificación errónea más baja entre clickbait y titulares legítimos.
Otros posibles valores para type.measure son deviance, AUC, class, mse y mae según el propósito de la modelización.
cv <- cv.glmnet(train.matrix,y=as.factor(train.headlines$y), alpha=1,family='binomial', nfolds=10, intercept=F,type.measure = 'class')El objeto cv es una lista que contiene la información del modelo. El siguiente gráfico muestra la relación entre la tasa de clasificación errónea y las penalizaciones lambda.
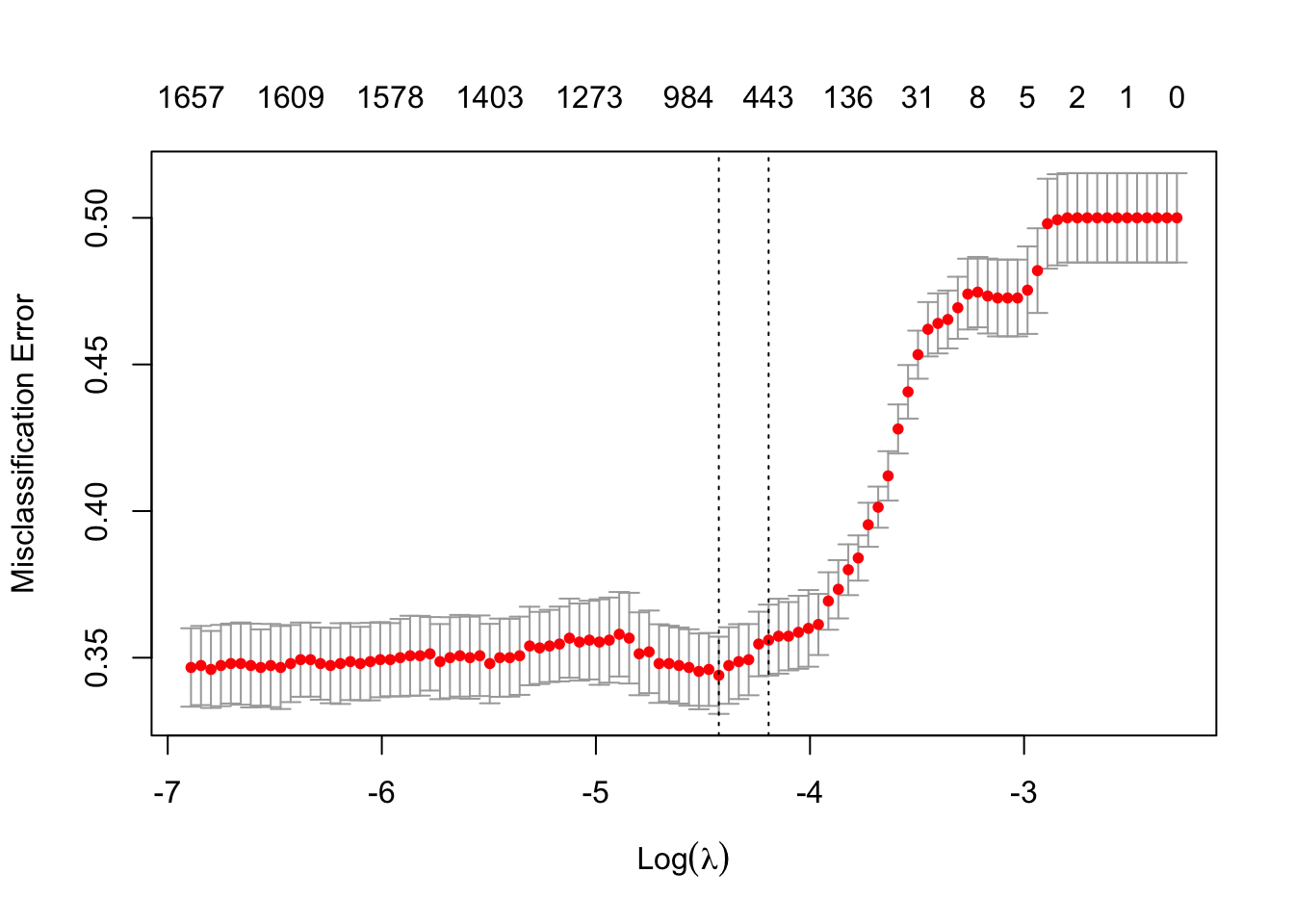
Evaluamos el modelo en los datos train. Si el modelo no funciona bien aquí, investigue cualquier problema de integridad de los datos, cambie el tamaño del conjunto de entrenamiento, ajuste el preprocesamiento del texto y finalmente ajuste los parámetros de ajuste de la regresión.
s = cv$lambda.1se indica a la función de predicción que utilices un valor lambda correspondiente a la segunda línea de puntos vertical en la figura anterior.
El objeto preds es una matriz con 1500 filas y una sola columna. Los valores corresponden a 0 para un título legítimo y 1 para clickbait. Si se necesitan probabilidades, cambie el tipo a respuesta en el código anterior (type="response")
Ahora calculamos la curva ROC: La curva representa la relación entre la sensibilidad y la especificidad del modelo. En otras palabras, se muestra la relación entre la tasa de verdaderos positivos en el eje \(y\) y la tasa de falsos positivos en el eje \(x\).
El área total bajo la curva (AUC) es un indicador de desempeño para los modelos de clasificación. Un AUC de \(0.5\) significa que el modelo no es mejor que una suposición aleatoria. Los valores de AUC por debajo de \(0.5\) son peores que los aleatorios. Un modelo perfecto tendría un AUC igual a 1.
##
## Call:
## roc.default(response = train.headlines$y, predictor = as.numeric(preds))
##
## Data: as.numeric(preds) in 750 controls (train.headlines$y 0) < 750 cases (train.headlines$y 1).
## Area under the curve: 0.868Grafiamos el resultado:
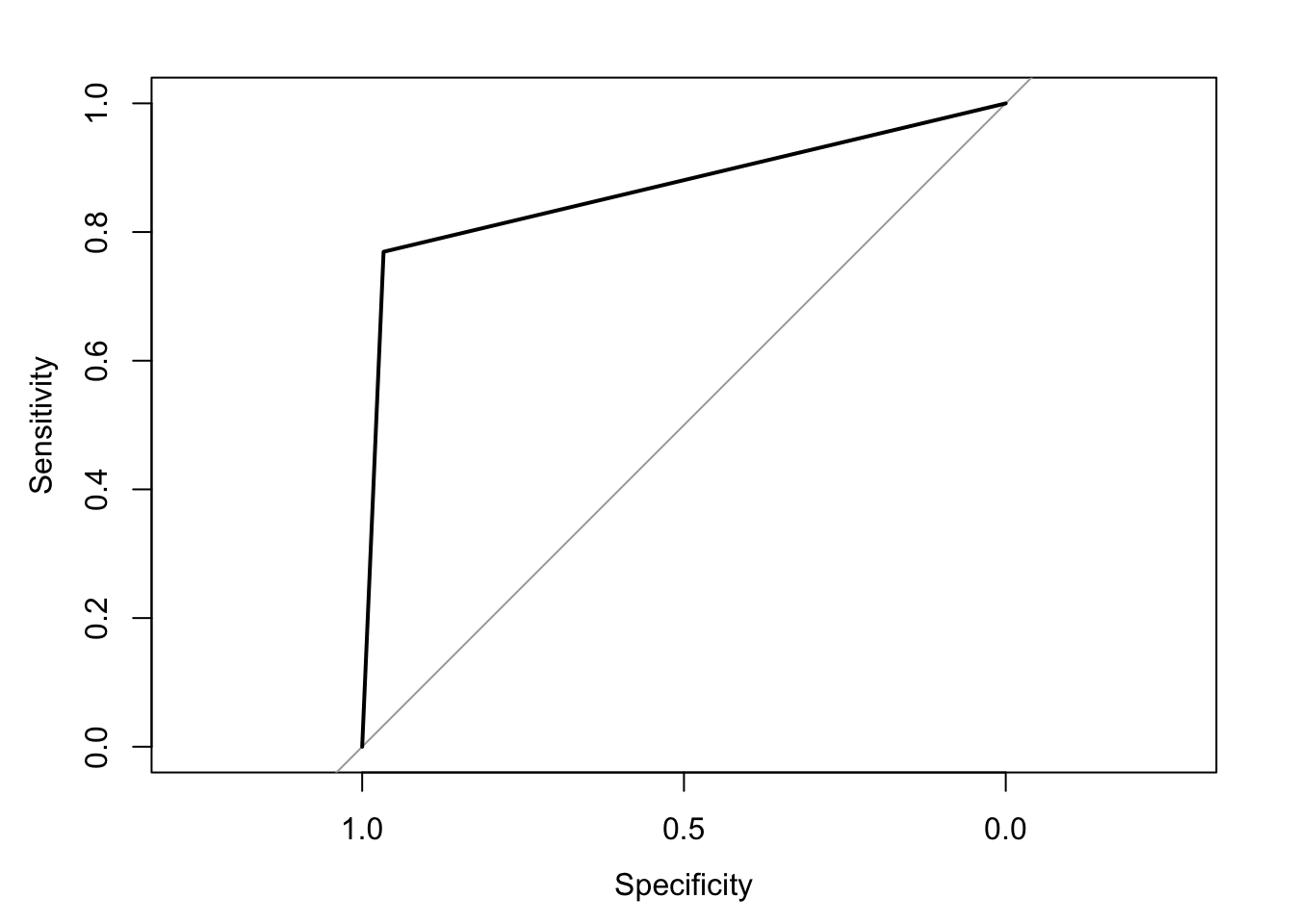
Ahora veamos la matriz de confusión:
##
## preds 0 1
## 0 725 173
## 1 25 577## [1] 0.868Ahora evaluemos el modelo en los datos test
Limpieza de datos test
Adecuamos los datos test para ser usados con el modelo de predicción (nota que usamos el parámetro original.matrix para que la limpieza sea acorde a los datos train)
clean.test <- headline.clean(test.headlines$headline)
test.dtm <- match.matrix(clean.test,weighting=tm::weightTfIdf,original.matrix=train.dtm)Converitmos los datos en matriz:
Hacemos la predicción usando el modelo ajustado:
preds <- predict(cv,test.matrix,type="class",s=cv$lambda.min)
headline.preds <- data.frame(doc_row=rownames(test.headlines),class=preds[,1])El parámetro s = cv$lambda.min se usa para tener un modelo más complejo que realmente minimice la tasa de clasificación errónea
Evaluación del modelo en datos test
Calculamos la curva ROC
##
## Call:
## roc.default(response = test.headlines$y, predictor = as.numeric(preds))
##
## Data: as.numeric(preds) in 750 controls (test.headlines$y 0) < 750 cases (test.headlines$y 1).
## Area under the curve: 0.6787Graficamos:
plot(train.auc,col="blue",main="ROJO = test, AZUL = train",adj=0)
plot(test.auc, add=TRUE,col="red", lty=2)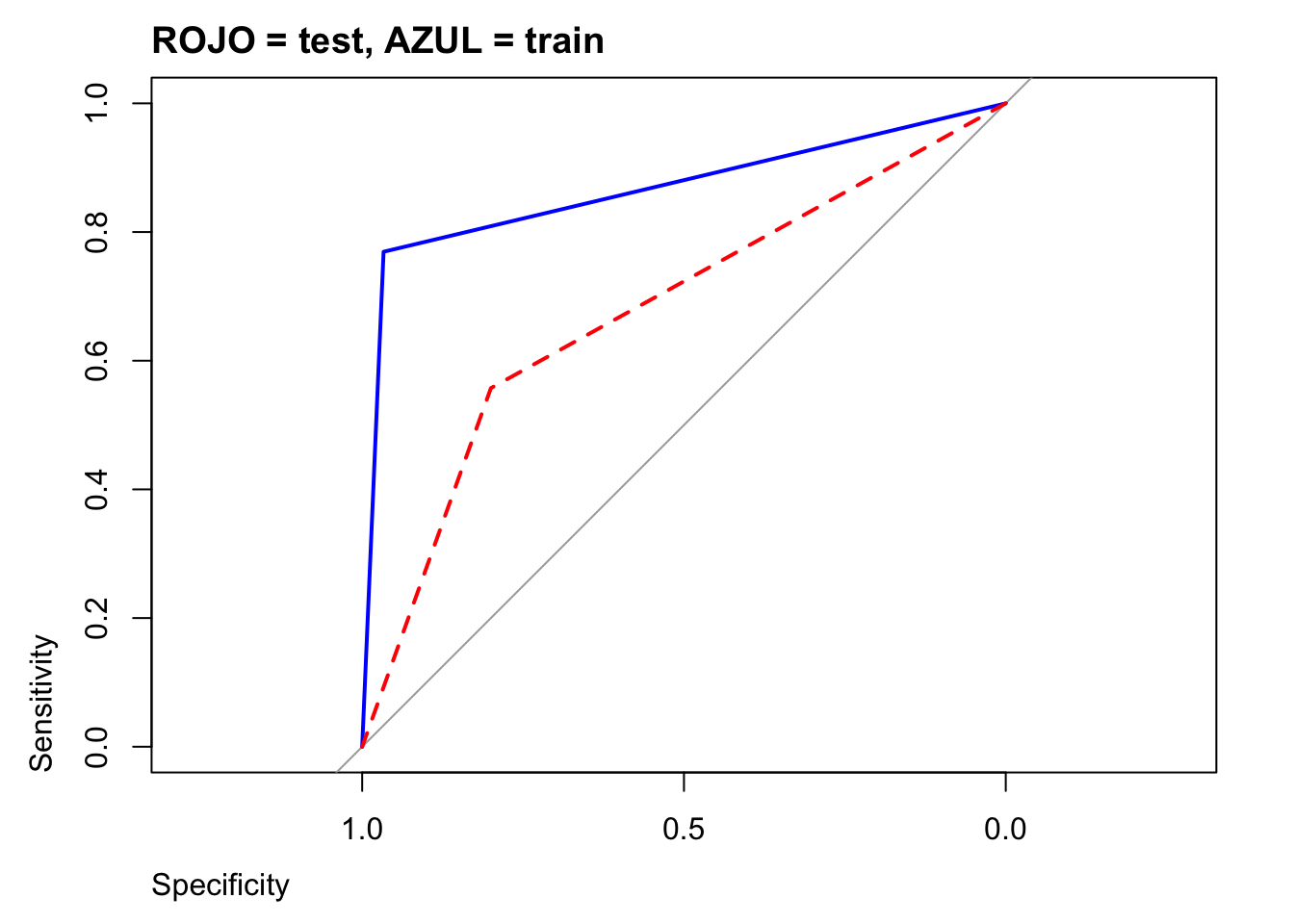
Veamos el accuracy
## [1] 0.6786667Buscando las palabras más relevantes
Para organizar los coeficientes para los miles de entradas de términos, la función coef se aplica al objeto del modelo lineal cv junto con un valor lambda específico.
## s1
## (Intercept) 0
## october 0
## ‘brexit’ 0
## ‘come 0
## ‘craziest 0
## ‘inspire 0Tenemos 4811 coeficientes, los ordenamos en orden decreciente:
glmnet.coef <- data.frame(words= row.names(glmnet.coef),glmnet_coefficients=glmnet.coef[,1])
glmnet.coef <- glmnet.coef[order(glmnet.coef$glmnet_coefficients, decreasing=T),]
glmnet.coef$words <- factor(glmnet.coef$words,levels=unique(glmnet.coef$words))Veamos el resumen de los coeficientes:
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## -2.845258 0.000000 0.000000 0.004656 0.000000 2.254026Notamos que hasta la mediana existen valores iguales a cero lo que disminuye drásticamente el número de coeficientes.
ggplot(glmnet.coef,
aes(x=glmnet.coef$glmnet_coefficients)) +
geom_line(stat='density', color='darkred',
size=1) + theme_gdocs()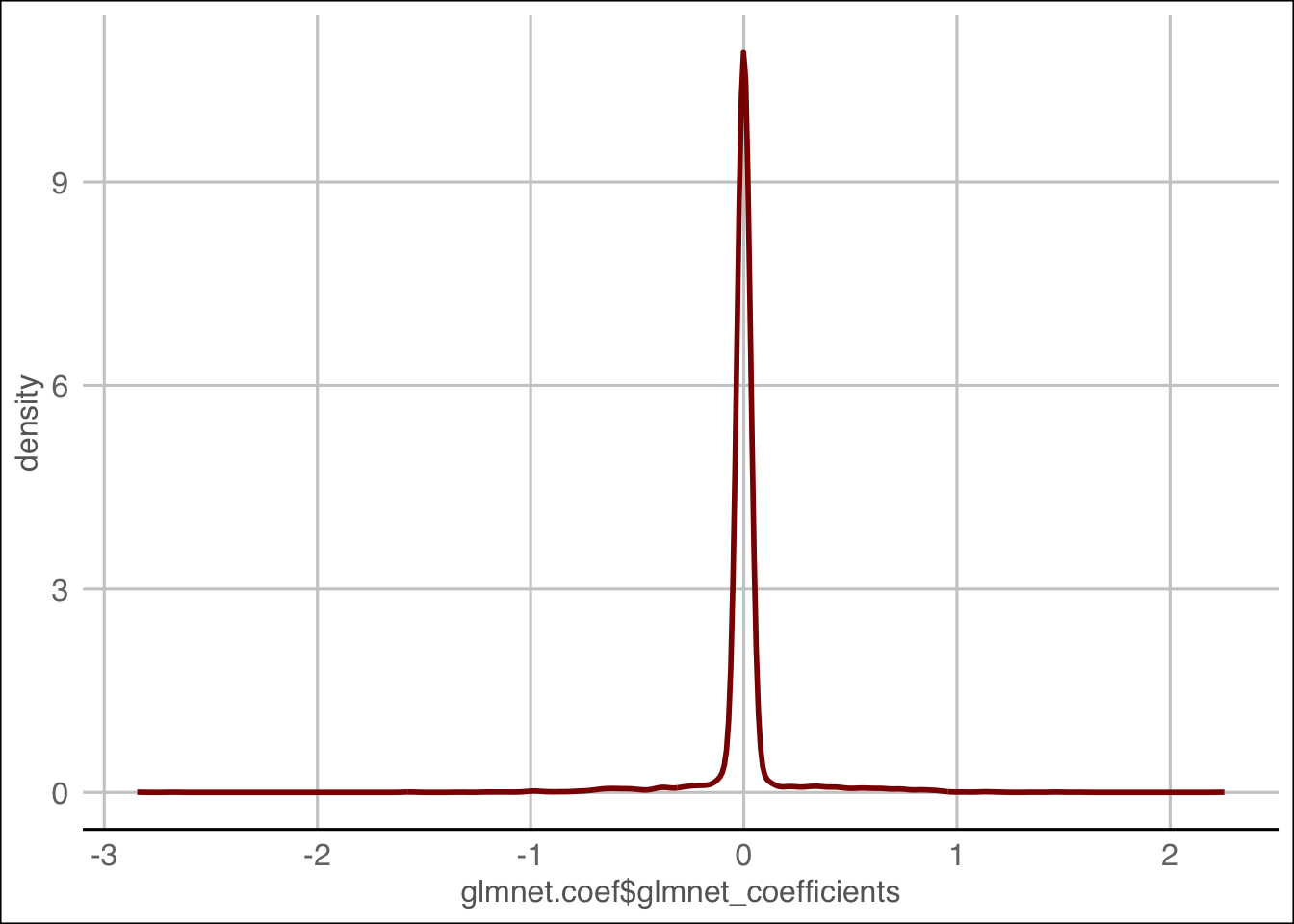
Con una declaración ifelse, cada fila se etiqueta como “Positivo” o “Negativo”, lo que representa la relación del término con un título que es un clickbait.
top.coef <- rbind(head(glmnet.coef,10),tail(glmnet.coef,10))
top.coef$impact <- ifelse(top.coef$glmnet_coefficients>0,"Positive","Negative")Veamos los resultados de los coeficientes más grandes gráficamente:
ggplot(top.coef, aes(x=glmnet_coefficients, y=words)) +
geom_segment(aes(yend=words), xend=0,
colour="grey50") +
geom_point(size=3, aes(colour=impact)) + theme_few()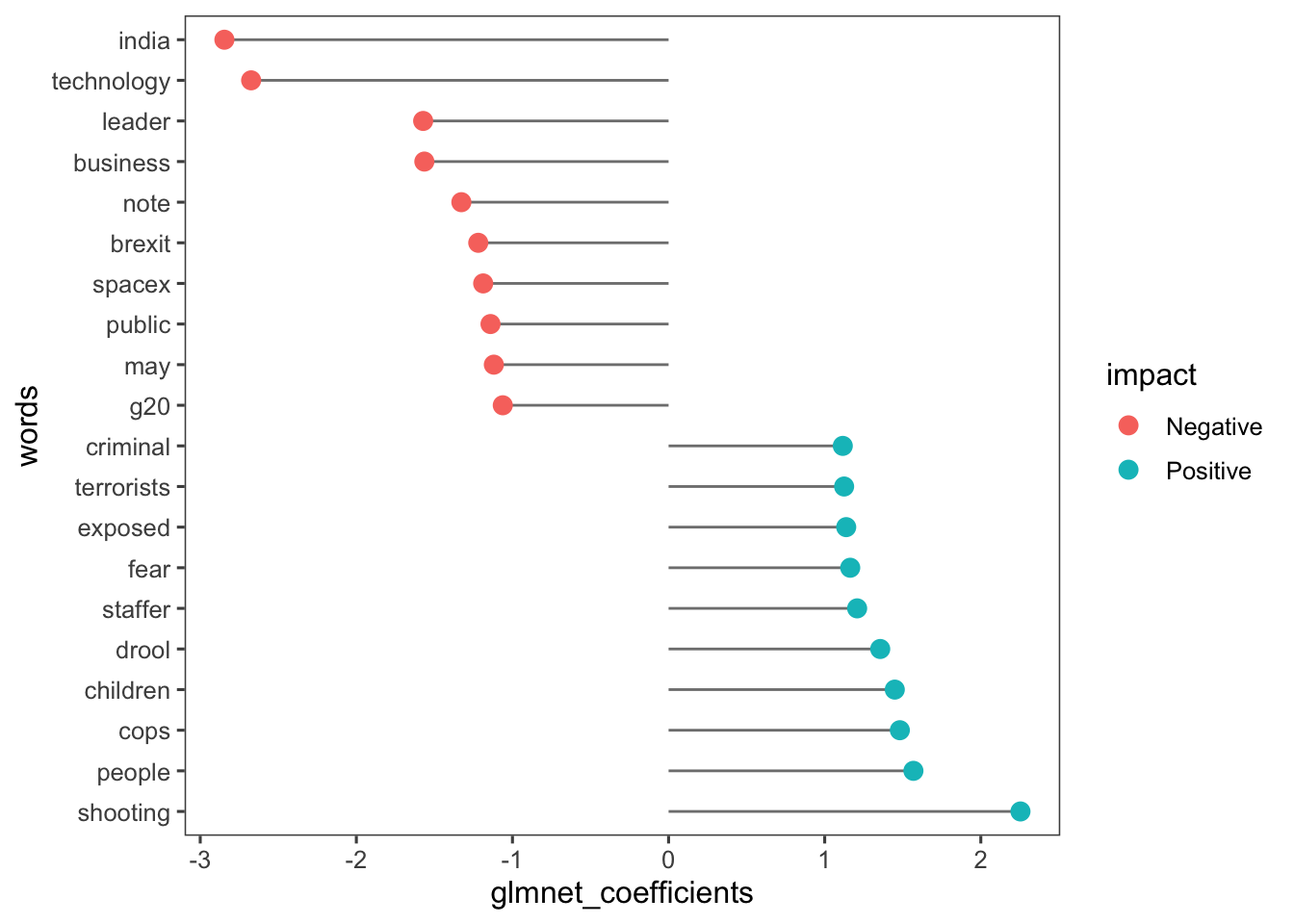
Ejercicio
En los datos de comentarios de usuarios de productos de Amazon, estime y evalúe un modelo de clasificación como el recién cubierto. ¿Cuál es el accuracy en los datos test?
- A: entre [40% y 50%)
- B: entre [50% y 60%)
- C: entre [60% y 70%)
- D: entre [70% y 80%)
- E: entre [80% y 90%)
- F: entre [90% y 100%]
read_git_csv <- function(uu)
{
#creamos un par de archivos temporales
temp <- tempfile()
temp2 <- tempfile()
#decargamos el zip folder y lo guardamos en 'temp'
download.file(uu,temp)
#descomprimir en 'temp' y guardarlo en 'temp2'
unzip(zipfile = temp, exdir = temp2)
#encontramos los archivos SHP
#el $ al final de ".shp$" asegura que no encontremos archivos del tipo .shp.xml
your_csv_file <- list.files(temp2, pattern = ".csv$",full.names=TRUE)
ff = strsplit(your_csv_file,"/")
ff = unlist(ff)
ff = ff[length(ff)]
ff = strsplit(ff,".csv")
ff = unlist(ff)
datos = rio::import(your_csv_file,layer = ff)
unlink(temp)
unlink(temp2)
return(datos)
}uu <- "https://github.com/vmoprojs/DataLectures/raw/master/Amazon_Unlocked_Mobile.zip"
datos <- read_git_csv(uu)
set.seed(1)
datos <- datos[sample(1:nrow(datos),nrow(datos)*0.1),]
datos <- na.omit(datos)
# Quitamos los ratings "neutrales" igual a 3
datos = datos[datos$Rating != 3,]
# Codificamos 4s y 5s como 1 (positivo)
# Codificamos 1s y 2s como 0 (negativo)
datos$Positivos = ifelse(datos$Rating > 3, 1, 0)
head(datos)## Product Name
## 24388 Apple iPhone 5c 16GB (Green) - AT&T
## 124413 BLU Life 8 XL Smartphone - Unlocked - Global GSM - Orange
## 331730 Samsung Galaxy Note II N7100 16GB White-Unlocked International Phone
## 142643 BLU Studio 6.0 Unlocked Cellphone, White
## 25173 Apple iPhone 5c 16GB (Pink) - AT&T
## 294762 POSH MOBILE KICK ANDROID GSM UNLOCKED DUAL SIM 5.0"" SMARTPHONE with unique colorful design, FULL-sized display, 5MP Camera and 8GB of Storage. 1 Year warranty. (Model#: X511 BLACK)
## Brand Name Price Rating
## 24388 Apple 648 5
## 124413 BLU 149.83 5
## 331730 Samsung 618.3 5
## 142643 BLU 971.6 1
## 25173 Apple 519 2
## 294762 97.59 2
## Reviews
## 24388 It's working great! Has a few minor scratches but that's expected from a used iPhone.
## 124413 Bought this for my mother-in-law and it is working fine. It was an excellent value and is performing well.
## 331730 excellent
## 142643 The Co is putting out that it is LTE but is is not after 7 calls to BLU and telling them about it is getting 0.24 Mbps Download and 0.02Mbps Upload and 317 ping it is not worth it till they get thing RIGHT AND FIXED save your money ( YOU buy it you will be Returning it in less then 30 Days )
## 25173 Works grea. BUT, cracks and break very easily and this is not a real iPhone so you cannot take it to the Apple store!
## 294762 This phone was great, but the typing was too small, kept hitting the next key, other than that, I loved it.
## Review Votes Positivos
## 24388 0 1
## 124413 0 1
## 331730 0 1
## 142643 21 0
## 25173 0 0
## 294762 0 0