24 Análisis de sentimientos
- El análisis de sentimientos toma prestado de disciplinas como la lingüística, la psicología y, por supuesto, el procesamiento del lenguaje natural.
El análisis de sentimientos es el proceso de extraer la intención emocional de un autor del texto.
Existen numerosos marcos emocionales que se pueden utilizar para el análisis de sentimientos. Algunos son propietarios para aplicaciones comerciales y otros son académicos.
Robert Plutchik creó un marco popularizado en la década de 1980. Plutchik fue un psicólogo que creó un sistema de clasificación para las emociones. Creía que hay ocho emociones creadas evolutivamente:
- ira (anger)
- miedo (fear)
- tristeza (sadness)
- disgusto (disgust)
- sorpresa (surprise)
- anticipación (anticipation)
- confianza (trust)
- alegría (joy)
Creía que las ocho emociones principales ayudaron a mejorar la supervivencia con el tiempo y se transmitían de generación en generación y que otras posibles emociones era amalgamas de las primarias.
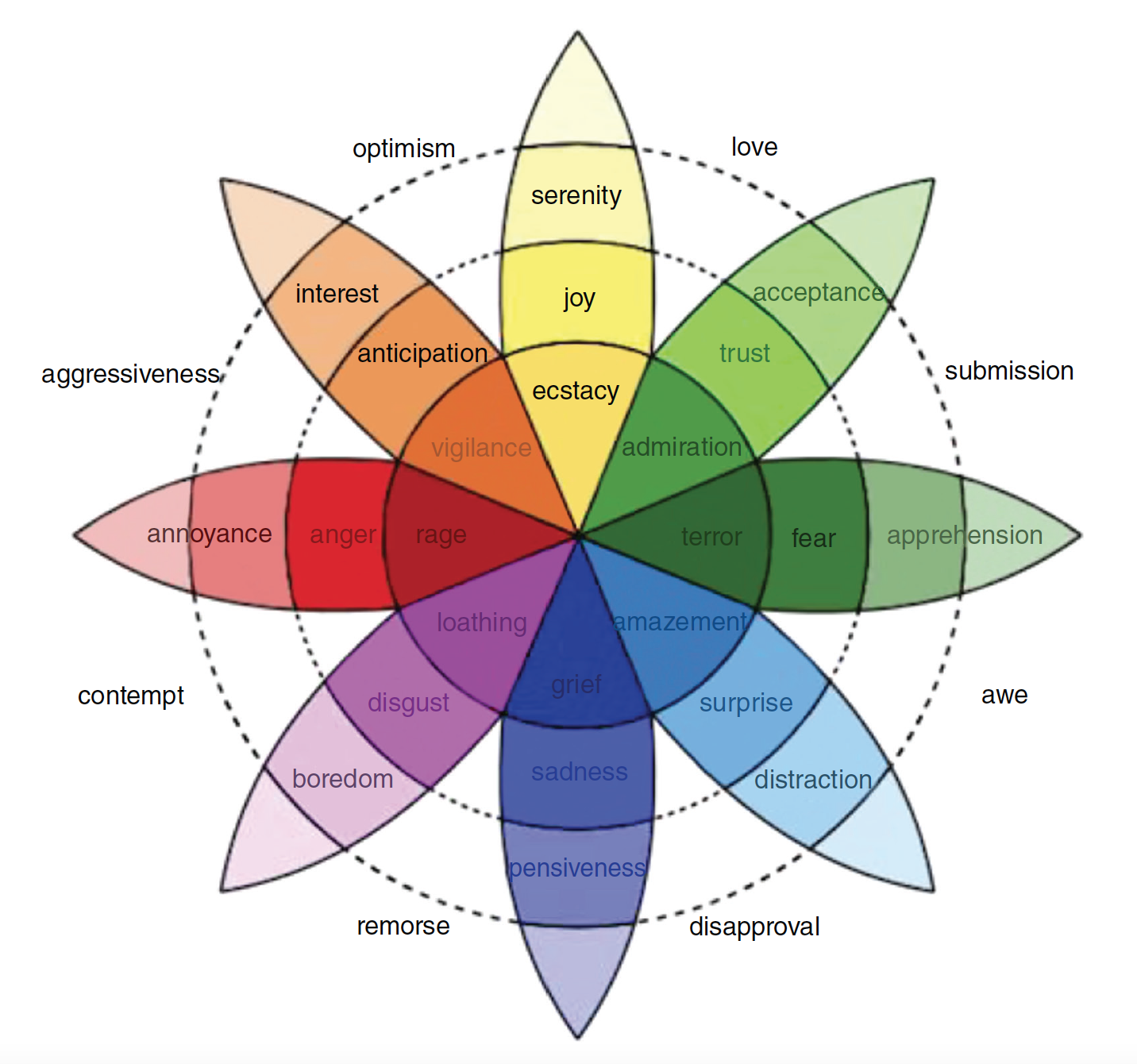
Si creara un modelo de sentimiento basado en el planteamiento de Plutchik, entonces cada una de las emociones etiquetadas en la Figura podría ser una etiqueta de cada documento en un conjunto de entrenamiento, mientras que los n-gramas de texto del documento podrían ser las variables independientes.
Considera que el enfoque de Pluthick es solo uno de los muchos planteamientos, y que etiquetar las emociones en el conjunto de entrenamiento está plagado de sesgos.
Por lo tanto, es importante que tengas en cuenta las metodologías y los sesgos cuando realizas análisis de sentimientos o cuando utilizas el análisis de sentimientos de otros.
Más allá del análisis de sentimientos para los estados emocionales, un enfoque más fácil es simplemente indicar si un documento es positivo o negativo. Esto se conoce como la polaridad de un documento. La polaridad puede ser más precisa porque solo hay dos clases distintas y son más fáciles de disociar
24.1 Polaridad
La librería qdap proporciona una función de polaridad que es sorprendentemente precisa y utiliza aritmética básica para puntuar.
La función de polaridad de qdap se basa en léxicos (glosario, diccionario) de subjetividad. Un léxico de subjetividad es una lista de palabras asociadas con un estado emocional particular.
Por ejemplo, las palabras malo, espantoso y terrible pueden asociarse razonablemente con un estado negativo. Por el contrario, perfecto e ideal se pueden conectar con un estado positivo.
Investigadores de la Universidad de Pittsburgh proporcionan un léxico de subjetividad de libre acceso que es muy popular. Contiene información sobre más de 8000 palabras que se ha encontrado que tienen polaridad positiva o negativa.
El paquete qdap utiliza un léxico de subjetividad diferente para su cálculo de polaridad. Específicamente, el léxico es de una investigación realizada por Bing Liu en la Universidad de Illinois en Chicago. Este léxico es un poco más pequeño, contiene aproximadamente 6800 palabras etiquetadas, pero se basa en investigaciones académicas que han resistido el escrutinio.
Armado con cualquiera de estos u otro léxico de subjetividad, puede emplear un enfoque simple de sumar las palabras positivas en un pasaje y restar las negativas.
Ejemplo:
El Analisis de sentimientos en R es bueno pero desafiante
La palabra “bueno” tiene una polaridad positiva, mientras que la palabra “desafiante” tiene una polaridad negativa. Los dos se cancelan entre sí, más uno y uno menos igual a cero. Entonces la polaridad de esta oración es cero.
¿Funcionan los lexicons?
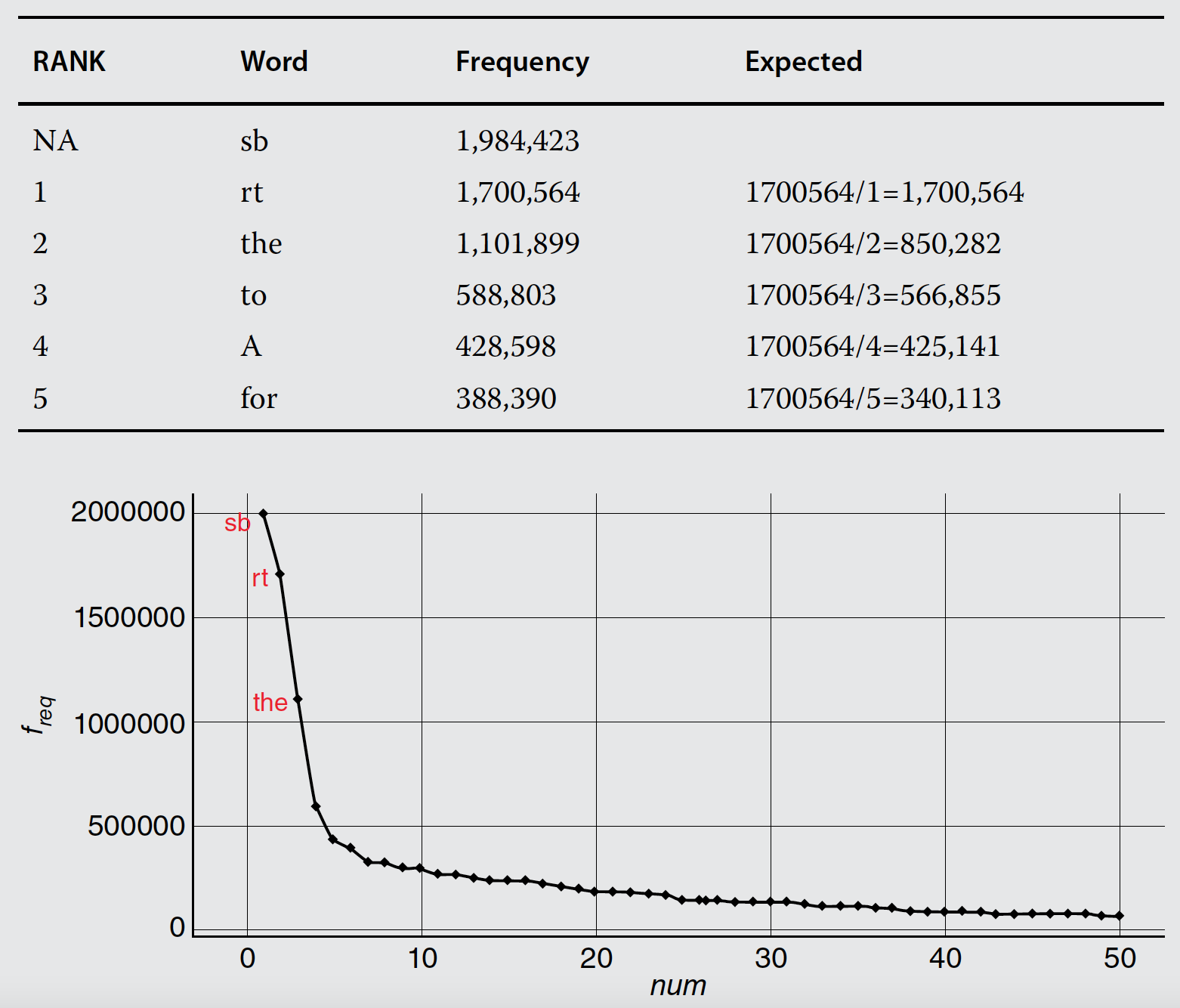
La ley de Zipf afirma que cualquier palabra en un documento es inversamente proporcional a su rango cuando se mira la frecuencia del término.
Por ejemplo, la palabra más frecuente, la número uno en una lista de frecuencias, aparecerá aproximadamente el doble que la segunda palabra más frecuente, luego tres veces más probable que la tercera y así sucesivamente.
Una explicación de este comportamiento lingüístico es el principio del mínimo esfuerzo. Este principio establece que los humanos elegirán el camino de menor resistencia y trabajarán para minimizar el esfuerzo de una tarea.
Como resultado de la ley de Zipf y el principio del mínimo esfuerzo, es posible que no se necesiten léxicos de subjetividad extremadamente amplios. Resulta que si bien los humanos pueden saber decenas de miles de palabras, a menudo vuelven a usar solo unos pocos miles de términos distintos cuando se comunican porque quieren minimizar el esfuerzo.
24.2 Usando qdap
La función de polaridad busca palabras positivas y negativas dentro de un léxico de subjetividad.
Una vez que se encuentra una palabra de polaridad, la función crea un grupo de términos, incluidas las cuatro palabras anteriores y las dos palabras siguientes.
Dentro del grupo, las palabras neutrales se cuentan como cero. Las palabras positivas y negativas que forman la base del grupo se cuentan como uno y negativo, respectivamente. Por lo tanto, las palabras restantes no neutrales y sin polaridad se consideran cambiantes de valencia (cambian el sentido de la palabra: not good). A estos cambiadores de valencia se les da un peso para amplificar o restar valor a la palabra polar original. El valor predeterminado es 0,8. Entonces, los amplificadores suman 0.8 mientras que las palabras de negación restan 0.8.
Todos los valores del grupo de palabras se suman para crear un gran total de la polaridad con efectos de amplificación o negación.
El gran total de palabras positivas, negativas, que amplifican y niegan con sus pesos específicos se divide luego por la raíz cuadrada de todas las palabras del pasaje. Esto ayuda a medir la densidad de las palabras clave.
El paquete qdap tiene un lexicon básico llamado key.pol con su respectiva ponderación:
## Key: <x>
## x y
## <char> <num>
## 1: a plus 1
## 2: abnormal -1
## 3: abolish -1
## 4: abominable -1
## 5: abominably -1
## 6: abominate -1Supongamos que queremos agregar las palabras rofl y lol como posivias en el lexicon existente, y kappa Y meh como negativas:
new.pos <- c('rofl','lol')
old.pos <- subset(as.data.frame(key.pol),key.pol$y==1)
all.pos <- c(new.pos,old.pos[,1])
new.neg <- c('kappa','meh')
old.neg <- subset(as.data.frame(key.pol),key.pol$y==-1)
all.neg <- c(new.neg,old.neg[,1])
all.polarity <- sentiment_frame(all.pos,all.neg,1,-1)Veamos estos cambios en accción:
polarity('ROFL, look at that!',polarity.frame=all.polarity)
polarity('ROFL, look at that!')
polarity('meh, not today my friend',polarity.frame=all.polarity)
polarity('MEH, not today my friend',polarity.frame=all.polarity)Nota que con el nuevo lexicon ROFL es reconocida, también cabe mencionar que el proceso es case sensitive.
Una vez que calculada la polaridad de los documentos en un corpus, puede usar esta métrica para crear subconjuntos.
Estás creando artificialmente dos corpus para examinar visualmente a partir el corpus global.
La creación de nubes de palabras con esta metodología mostrará qué palabras distintivas se usan solo para publicaciones positivas frente a negativas y qué otras palabras se comparten, lo que genera un sentimiento mixto.
Veamos un ejemplo completo
library(tm)
library(qdap)
library(wordcloud)
library(ggplot2)
library(ggthemes)
uu <- "https://raw.githubusercontent.com/vmoprojs/DataLectures/master/power.txt"
datos <- readLines(uu)
df <- data.frame(data = datos)Ahora vamos a calcular la polaridad de cada línea:
Veamos la distribución de la métrica de polaridad:
summary(bos.pol$all$polarity)
ggplot(bos.pol$all, aes(x=polarity, y=..density..)) + theme_gdocs() + geom_histogram(binwidth=.25, fill="darkred",colour="grey60", size=.2) +geom_density(size=.75)Agregamos la polaridad a los datos originales:
Podemos separar el texto en líneas positivas y negativas:
Ahora combinamos la información en all.terms
pos.terms <- paste(pos.comments,collapse = " ")
neg.terms <- paste(neg.comments,collapse = " ")
all.terms <- c(pos.terms,neg.terms)
all.corpus <- VCorpus(VectorSource(all.terms))Nota que all.terms es un vector de dos elementos, el primero con las líneas positivas y el segundo con las negativas.
En el código siguiente generamos una matriz TDM con una ponderación TfIdf (term frequency (TF) and the inverse document
frequency (IDF)).
TF = (term occurrences in a document)/(total unique terms in the document)
IDF = log(total document in corpus/number of documents with term t in it)
TFIDF= TF*IDF
all.tdm <- TermDocumentMatrix(all.corpus, control=list(weighting=weightTfIdf, removePunctuation = TRUE,stopwords=stopwords(kind='en')))Convertimos el TDM en matriz:
Realizamos le nube de palabras:
Ejercicio
Notemos que en esta tarea se necesitará un diccionario en español, una referencia en: https://raw.githubusercontent.com/JoseCardonaFigueroa/sentiment-analysis-spanish/master/data/subjectivityStemming2.csv
Aplicar análisis de polaridad sobre los datos de whatsapp y presentarlos en una nube de palabras.
Aplicar análisis de polaridad sobre los datos de tweeter y presentarlos en una nube de palabras.
setwd("~/Documents/Consultorias&Cursos/DataLectures")
uu <- "grupo_chat.txt"
library("rwhatsapp")
df <- rwa_read(uu)
head(df)
df <- data.frame(text = df$text)
names(df)[1] <- "text"
df$text <- gsub("imagen","",df$text)
df$text <- gsub("omitida","",df$text)
df$text <- gsub("omitido","",df$text)
lexi <- read.csv("https://raw.githubusercontent.com/JoseCardonaFigueroa/sentiment-analysis-spanish/master/data/subjectivityStemming2.csv")
table(lexi$negative)
posi <- lexi[which(lexi$negative=="positive"),1]
posi <- data.frame(x = posi,y = 1)
nega <- lexi[which(lexi$negative=="negative"),1]
nega <- data.frame(x = nega,y = 0)
todos <- rbind(posi,nega)
bos.pol <- polarity(df$text,polarity.frame=todos)
df$polarity<- scale(bos.pol$all$polarity)
hist(df$polarity)