21 Fuentes de datos
Las herramientas para organizar texto puede variar dependiendo de las fuentes:
En el caso de existir APIs (Application program interface), entonces la herramienta para extraer textos suele ser clara.
En otros casos se debe hacer webscraping para obtener los textos, lo cual puede ser laborioso, pero es necesario en algunos proyectos de minería de texto. Para evitar problemas, solo escrapeee una página web o use una fuente de datos después de haber leído y comprendido las restricciones.
Archivos de textos sueltos en Word o pdf.
21.1 Usando el paquete rvest
Debemos empezar examinando la página, en nuestro ejemplo visitamos la página http://www.forosecuador.ec/forum/ecuador/tr%C3%A1mites/4935-consultar-planilla-de-agua-de-quito-epmaps-valores-a-pagar que se muestra en la imagen
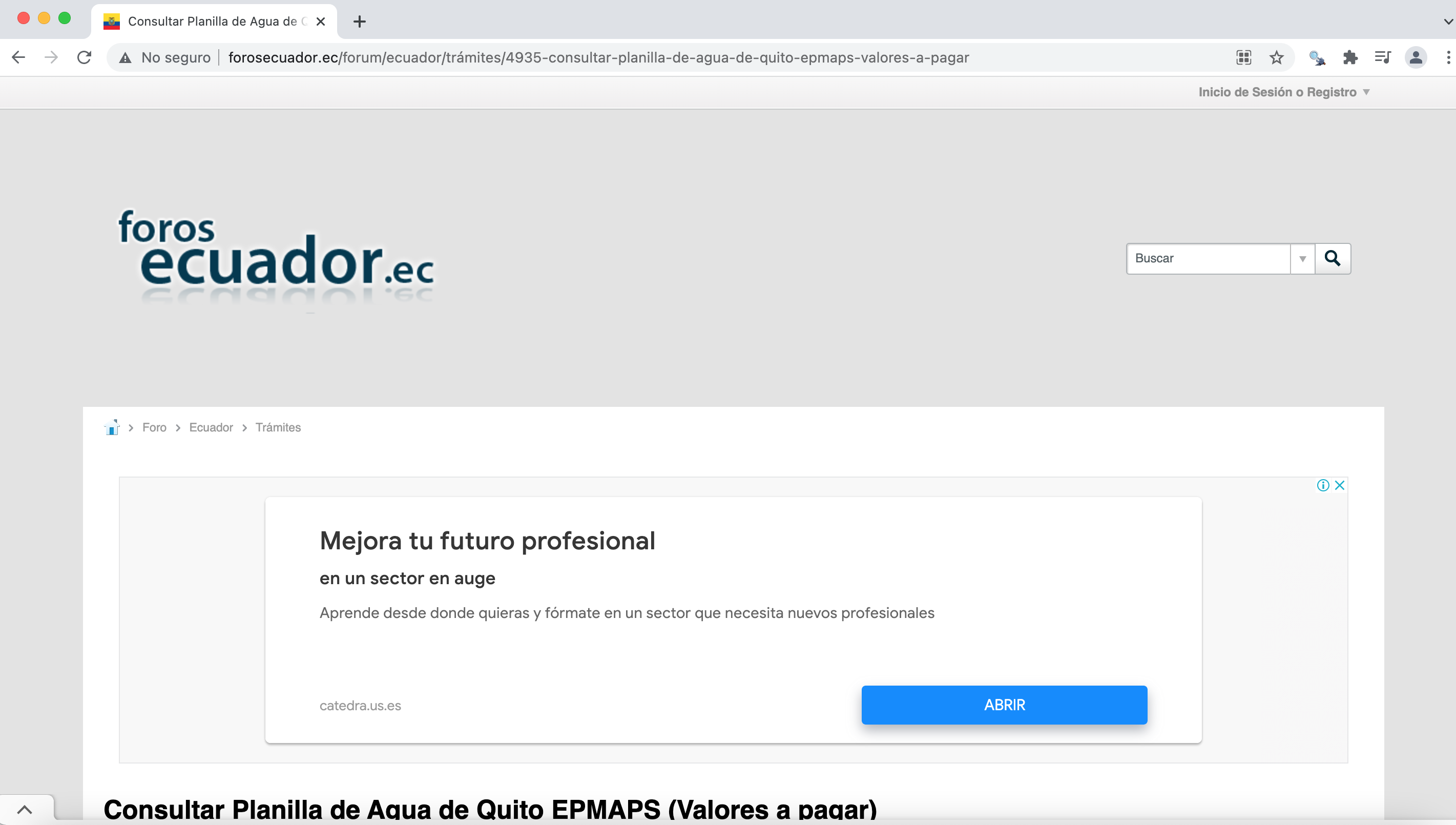
Como todas las páginas web, hay muchos elementos. Como minero de texto, probablemente solo estés interesado en el hilo del foro. Por lo tanto, se debe tener cuidado para evitar recopilar una gran cantidad de información no deseada, como enlaces extraños y texto de encabezado.
Usaremos rvest para obtener los comentarios. La función read_html deposita en page todos los elementos de la página url.
library(rvest)
url <- 'http://www.forosecuador.ec/forum/ecuador/tr%C3%A1mites/4935-consultar-planilla-de-agua-de-quito-epmaps-valores-a-pagar'
url <- 'https://www.expat.com/forum/viewforum.php?id=2160'
page <- read_html(url)Ahora es momento de extraer el elemento exacto que necesitamos. Si manejas cascading style sheet’s (CSS), puedes acceder directamente.
De lo contrario, puedes descargar el complemento selector gadget que una vez instalado aparece una lupa en la parte superior derecha que te permite inspeccionar los nombres de los elementos a extraer:
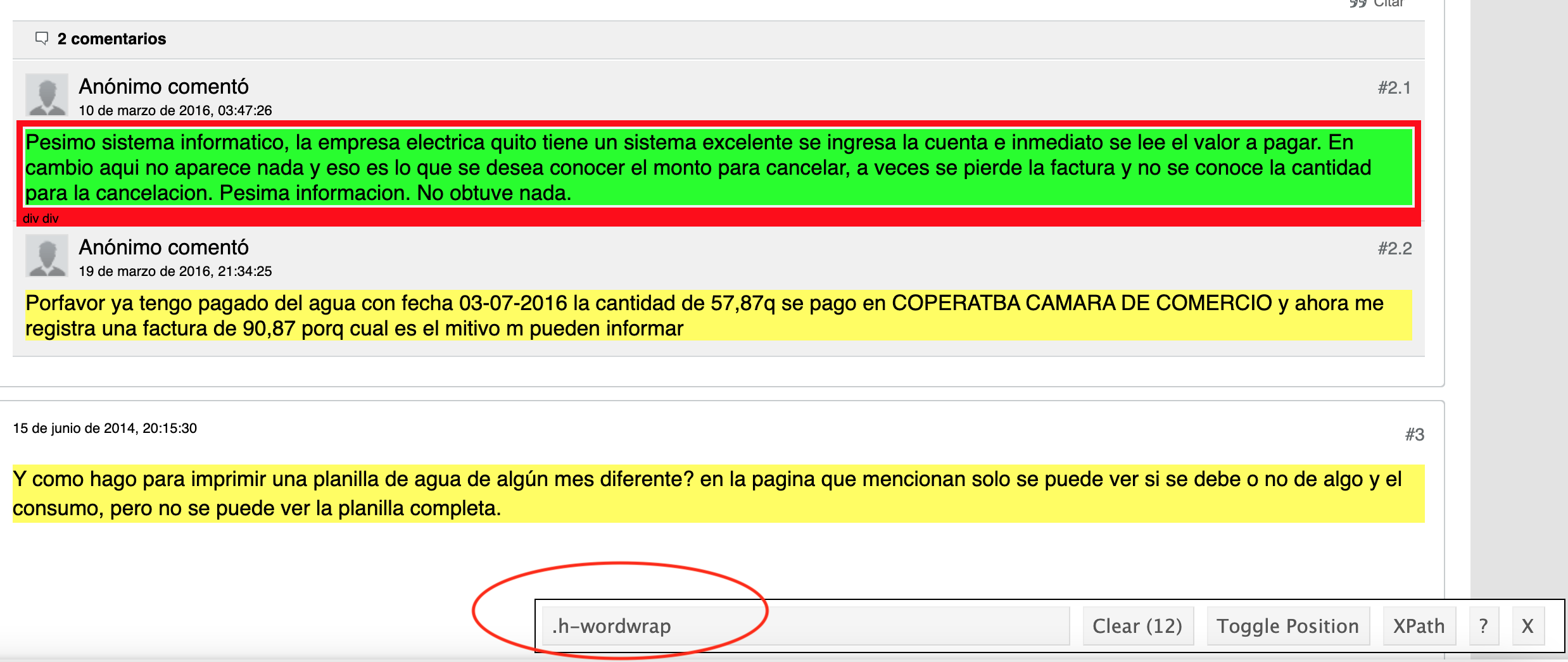
En nuestro ejemplo, el elemento que nos interesa es .h-wordwrap y usamos html_text para extaer el texto:
# posts <- html_nodes(page,"p")
# posts <- html_elements(page,xpath = "//p")
posts <- html_elements(page,css = ".item-forum__text")
forum.posts <- rvest::html_text2(posts)El objeto forum.posts es un vector de caracteres y ha raspado (scraped) correctamente las doce publicaciones de esta página, ignorando el resto del texto.
Ahora usamos la función html_nodes, en particular su parámetro xpath='//a' donde
La doble barra significa en cualquier lugar del documento
acaptura todos los links porque se definen como<a>en HTML.
Sin embargo, esto captura muchos links de los que debes elegir los que necesitas. Para esto usamos la función grep que identifica un patrón de texto en cada link. En nuestro caso p= indica que se trata de una publicación.
Finalmente, con el parámetro href dentro de html_attr extraemos los links:
links <- html_nodes(page,css='.item-forum__title a')
# links <- html_nodes(page,xpath="//a")
# thread.urls <- grep("viewforum", links)
# html_attrs(links)
# thread.urls <- html_attr(links,"href")[thread.urls]
thread.urls <- html_attr(links,"href")Finalmente, ubicamos los comentarios y links dentro de un data.frame:
Ejercicio
Extrae la fecha en la que se tiene el post y agrégala como columna a final.df.
21.1.1 Minando múltiples páginas
Ahora usaremos la misma lógica anterior en mútiples páginas. Usaremos la función pblapply que es equivalente a lapply pero nos agrega una barra de avance.
Cargamos las librerías:
Declaramos la url y agregamos las páginas a minar en forum.urls, en nuestro caso 1:23:
Ahora unimos los elementos de la sección anterior en una sola función:
Aplicamos la función sobre los links:
Ejercicio
Extrae la fecha en la que se tiene el post y agrégala como columna a final.df.
21.2 Whatsapp
Whatsapp nos permite descargar las conversaciones personales o grupales. Debemos acceder a la información del chat y Exportar chat
Aparece entonces las opciones de exportación donde se recomeinda hacerlo sin adjuntar archivos.
Esto descarga un archivo comprimido del que podemos extraer información.
El siguiente archivo es un ejemplo del .txt que se extrae
setwd("~/Documents/Consultorias&Cursos/DataLectures")
uu <- "grupo_chat.txt"
library("rwhatsapp")
df <- rwa_read(uu)
head(df)## # A tibble: 6 × 6
## time author text source emoji emoji_name
## <dttm> <fct> <chr> <chr> <list> <list>
## 1 2015-09-03 08:28:44 Red Ecu. de Estadísticos "Los… grupo… <NULL> <NULL>
## 2 2015-09-03 08:28:44 <NA> "Mig… grupo… <NULL> <NULL>
## 3 2018-07-21 05:53:11 <NA> "+59… grupo… <NULL> <NULL>
## 4 2018-07-21 05:55:14 +593 99 864 3615 "Est… grupo… <NULL> <NULL>
## 5 2018-07-21 05:56:16 +593 99 864 3615 "Ya … grupo… <NULL> <NULL>
## 6 2018-07-21 05:58:08 +593 99 864 3615 "Est… grupo… <NULL> <NULL>21.3 Archivos .txt
En el caso de archivos .txt se recomienda usar la función readLines. Por ejemplo, en el siguiente texto se leen 8199 líneas:
21.4 Twitter
Un paquete que nos permite interactuar con la API (interfaz de programación de aplicaciones) de Twitter es rtweet.
La siguiente imagen muestra
 El comando
El comando create_token crea un OAuth que es un framework de autorización, que proporciona una guía en la que definen los flujos de autorización específicos para acceder a los datos del usuario desde diferentes tipos de aplicaciones consumidoras.
Luego, algunas funciones de interés:
get_timelines: devuelve los estados (hasta 3200) por cada usuario consultado.seach_tweetsdevuelve (18000) publicaciones relacionadas con la consulta específica.
Los siguientes datos son las últimas 17968 publicaciones relacionadas a la consulta CrisisCarcelaria (consultado 19 de nov 2021).
Para acceder a la API de twitter, se debe tener una cuenta de desarrollador, más información en: https://developer.twitter.com/en.