3.6 K-W-B: Belohnung
Von unserem Dreigestirn an Habit-Blickwinkeln nehmen wir uns nun den dritten und letzten vor: Belohnung. Ganz am Anfang einer Gewohnheit – also noch bevor diese eigentlich ausgereift existiert – steht die Überwindung anfänglicher Hürden eines Verhaltens. Häufig benötigen wir dazu zusätzliche Hilfsmittel (Motivation, die wir aus unterschiedlichen Quellen schöpfen können; Anreize oder vielleicht auch Bestrafung). Gewohnheiten – wenn sie sich denn schließlich gebildet haben sollten – dienen vor allem dazu, diese anfänglich positiven Aspekte – die Belohnung eines Verhaltens – in der Zukunft zu verankern. Schließlich ganz ohne unser bewusstes Zutun.
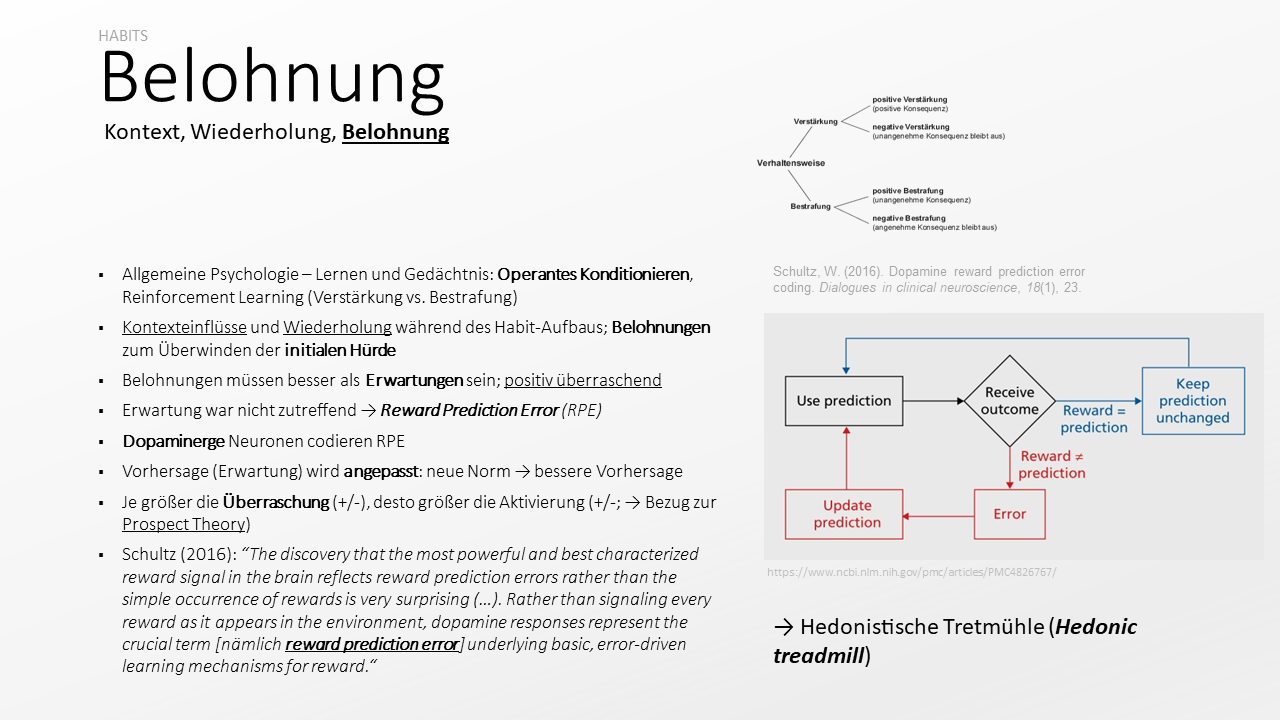
Eine psychologische Theorie, die sich eher mit den mechanistischen und weniger den motivationalen Aspekten der Belohnung beschäftigt ist die Operante Konditionierung. Die kennen Sie sicherlich aus der Lernpsychologie. Die operante Konditionierung ist eine behavioristische Lerntheorie, die vor allem die Rolle von Verstärkung und Bestrafung auf die Häufigkeit untersucht, mit der Verhaltensweisen gezeigt werden. Der Klassiker hier ist die Taube in der sog. Skinnerbox, die mit der Gabe von Futterpillen auf ein bestimmtes Verhalten hin trainiert wird. Verstärkung kann durch eine positive Konsequenz für eine Verhaltensweise (→ positive Verstärkung) erfolgen oder aber durch das Ausbleiben einer negativen Konsequenz (→ negative Verstärkung). Das Gegenstück dazu bilden die positive oder negative Bestrafung, durch unangenehme Konsequenzen – die ggf. auch gezielt ausbleiben können.
Das gleiche Prinzip machen sich Forscher im Bereich des Maschinellen Lernens (einem Teilbereich der Forschung zur Künstlichen Intelligenz) zu nutze. Der Fachbegriff dazu lautet Reinforcement Learning.
Damit wir auch diesen wichtigen Punkt wiederholen: Belohnung dient zu Beginn einer potentiellen Gewohnheit dazu, dass anfängliche Widerstände überwunden werden. Wie wir noch sehen werden, spielt sie im weiteren Verlauf eine immer untergeordnetere Rolle. Allerdings bieten die Gewohnheiten einen Rahmen und eine Möglichkeit dafür, dass die Belohnungen der Vergangenheit auch zukünftig erhalten werden.
Was ist das grundsätzliche Wesen von Belohnungen? Sie müssen einen positiven psychologischen Wert haben. Wenn wir für eine Handlung eine bestimmte Konsequenz erwarten, die dann auch eintritt, ist das als Belohnung vermutlich aber noch nicht ausreichend. Unsere Erwartungen sollten (ich vermeide das Wort „müssen”, da der Zusammenhang meiner Einschätzung nach nicht ganz so streng zu nehmen ist) übertroffen werden. Wir sollten positiv überrascht werden.
Das bedeutet andererseits: Wir lagen mit unserer ursprünglichen Einschätzung – die wir vielleicht gar nicht bewusst vorgenommen haben – falsch. Unsere Erwartung war nicht zutreffend. Wir haben einen Fehler bei der Interpretation, der Vorhersage einer Situation gemacht; einen Vorhersagefehler – auf Englisch: Reward Prediction Error (RPE).
An dieser Stelle kommt das gern und viel zitierte Dopamin ins Spiel. Dopamin ist ein Botenstoff, ein Neurotransmitter, der eine Form der Kommunikation zwischen Nervenzellen ermöglicht. Das sog. dopaminerge System – also die beteiligten Neuronen, die untereinander über Dopamin kommunizieren – bilden den eben erwähnten RPE ab; sie codieren ihn. Wenn die Konsequenz einer Handlung unerwartet positiv ausfällt, steigt die Dopamin-Aktivität, also die Feuerungsrate der beteiligten Synapsen. Bei überraschend negativer Konsequenz sinkt die Feuerungsrate. Ist die Konsequenz wie erwartet, also nicht überraschend, bleibt sie konstant.
Durch das gemeinsame Feuern, also die erhöhte Ausschüttung von Dopamin, wird die Verbindung zwischen den Neuronen gestärkt (vielleicht haben Sie die dazu passende Aussage schon mal gehört: What fires together, wires together). Der Dopamin-Ausstoß kann danach wieder reduziert werden. Die neue Situation – z. B. die neue, unerwartet positive Belohnung – wurde nun neuronal codiert. Sie bildet in Zukunft unter den entsprechenden, ähnlichen Bedingungen die neue Erwartung; die neue Norm. Damit wurde die unmittelbar gemachte Erfahrung in unser Abbild von der Realität übernommen. Wir können damit für die Zukunft besser vorhersehen, wie eine Situation sich entwickeln wird. Wir werden eine bessere Vorhersage treffen.
Dieses Schema finden Sie auch in der Abbildung rechts auf der Folie dargestellt: Wir verwenden eine Vorhersage, erfahren einen oder keinen Vorhersagefehler und passen daraufhin unsere zukünftige Vorhersage entsprechend an (die rote Error-Verzweigung) oder behalten sie bei (die blaue Unchanged-Abzweigung).
Je größer die Überraschung, je größer also der RPE, desto stärker ist die Aktivierung der dopaminergen Bahnen – in die eine oder andere Richtung; je nach Art des Fehlers.
Vielleicht erkennen Sie in der Beschreibung die Grundstruktur der Prospect Theory wieder. Sie erinnern sich: Anders als die klassische Erwartungsnutzentheorie, die mit absoluten Vermögenszuständen argumentiert, geht die PT von einem psychologischen Referenzpunkt aus, der Gewinne von Verlusten trennt. Gewinne und Verluste sind natürlich ebenso RPEs!
Das heißt aber auch: Wir passen unseren Referenzpunkt recht bald der Realität an. Wir werden durch die gleiche Belohnung nicht laufend erneut überrascht. Damit das Erleben einer Belohnung aufrecht erhalten werden kann, muss die Belohnung weiterhin unerwartet positiv ausfallen. Was ich hier beschreibe, ist die Grundlage der sog. hedonistischen Tretmühle (hedonic treadmill): Wir wollen haben und bekommen (positive Belohnung) → Wir sind vorübergehend zufrieden → Wir gewöhnen uns an unser Wohlbefinden → Wir wollen etwas Neues haben → …
Das Vorhandensein eines neuronal codierten RPEs ist nachträglich nachvollziehbar, war aber vor seiner Entdeckung alles andere als erwartbar(!). Schultz (2016) formuliert seine Überraschung dazu folgendermaßen:
The discovery that the most powerful and best characterized reward signal in the brain reflects reward prediction errors rather than the simple occurrence of rewards is very surprising (…). Rather than signaling every reward as it appears in the environment, dopamine responses represent the crucial term [nämlich reward prediction error] underlying basic, error-driven learning mechanisms for reward.
— Schultz (2016), S. 30
Das Entscheidende ist also, dass die neuronalen Mechanismen nicht darauf abzielen, die Belohnung und deren Stärke an sich zu codieren, sondern den Unterschied zwischen Vorhersage und tatsächlich Erlebtem.
Die Konzepte von Vorhersage und Vorhersagefehler sind im wissenschaftlichen Verständnis der kognitiven Prozesse wichtig und treten mehr und mehr in den Fokus. Ich möchte Sie an der Stelle auf die Arbeiten von Lisa Feldman Barrett zu dem Thema hinweisen, die vor allem die Rolle von Vorhersagen und Vorhersagefehlern bei menschlichen Emotionen untersucht und auf völlig neuartige Grundlagen stellt (vgl. hierzu Feldman, 2018).

Wir wissen nun: Das Dopaminsystem codiert den RPE und baut ihn in das neue neuronale Modell der Welt ein, das unser Gehirn erzeugt. Wir haben uns an den Status Quo – die Welt in der es in der erlebten Situation die erlebte Belohnung gibt – angepasst. Wir haben mit Hilfe von Belohnung gelernt!
Das Zeitfenster für diese Art von Lernprozessen ist klein. Es beträgt vermutlich gerade mal ein paar Sekunden – jedenfalls weit weg von Minuten, innerhalb derer viele der Belohnungen, die in unseren Leben eine Rolle spielen, normalerweise auftreten. Zum Beispiel Bonuszahlungen, Erfolge auf der Waage oder eine gute Klausurnote nach harter Lernphase. Natürlich können auch diese Erlebnisse Belohnungen darstellen, die auch wichtig sind und unser Verhalten beeinflussen. Sie tun das nur nicht mit Hilfe des Dopaminsystems, das besonders für die Entwicklung von Gewohnheiten wichtig ist.
Wegen dieses schmalen Zeitfensters sind Habit-relevante Belohnungen häufig verhaltensinhärent. Sie erfolgen intrinsisch. Stellen Sie sich die freiwillige Mitarbeit in einer Suppenküche vor. Wir können gut nachvollziehen, dass diese Arbeit, das wärmende, angenehme Gefühl, etwas Richtiges, etwas Gutes zu tun, bereits eine Belohnung an sich darstellt.
Denken Sie hingegen an den Besuch eines Fitnessstudios, das Ihnen in allen relevanten Belangen keinerlei Freude bereitet. Sie schaffen es nicht, dass Sie das anstrengende Strampeln, Laufen oder Steppen auf den Cardiogeräten als positiv erleben. Das Hantieren mit Gewichten ist einfach nur anstrengend und bietet ihnen kein Erfolgserlebnis. Selbst wenn die Belohnung nach mühsam absolvierten Wochen im Studio dann doch in Form eines definierteren Körpers oder der Reduktion von Gewicht erlebt werden kann, hat Dopamin damit nichts mehr zu tun. Der Aufbau von Gewohnheiten wird unter diesen Bedingungen nur schwer möglich sein. Stattdessen mussten Sie auf die „White-Knuckles-Strategie” setzen. Sie mussten sich permanent selbst puschen und motivieren und reflektiert die richtige Entscheidung treffen. Das funktioniert langfristig vermutlich nicht.
Noch ein Satz zu einem wichtigen Aspekt des Dopamin-Systems, zu dem wir später noch kommen werden. Über Dopamin wird nicht nur ein Werte-Aspekt des Erlebens codiert (also der RPE). Zeitlich unmittelbar vor dem Dopaminsignal für den RPE erfolgt eine Reaktion auf potentiell werthaltige Elemente unserer Wahrnehmung. Und das sind vor allem Elemente, die eine hohe Salienz – also Auffälligkeit haben. Das Dopaminsystem beeinflusst also über die Reaktion auf Salienz und Kontraste die Zuwendung von Aufmerksamkeit. Doch dazu später mehr.

Um den Faden der vorhergehenden Folie wieder aufzunehmen: Sie kennen vermutlich die Unterscheidung zwischen extrinsischer und intrinsischer Motivation (die vor allem auf Forschung von Deci und Ryan zur Selbstbestimmungstheorie zurückgeht). Für die externe Motivation liegen die Beweggründe – die Motivatoren – außerhalb der eigenen Person. Wir sprechen von extrinsischer Belohnung. Hier sind materielle Anreize zu verorten; aber auch Lob, Anerkennung usw.
Für die intrinsische Motivation liegen die Motivatoren innerhalb der eigenen Person. Es handelt sich um Motive und Bedürfnisse, die durch die Handlung unmittelbar befriedigt werden (können). Eine Aufgabe wird um ihrer selbst willen ausgeführt. Beispiele dafür: Freude am Tun, Befriedigen einer Neugier, Ausdruck des eigenen Selbst u. ä.
Wie wir eben gesehen haben, ist das Problem mit den klassischen extrinsischen Belohnungen, dass sie oft zu spät erfolgen, um damit einen Einfluss auf die Dopamin-Systeme auszuüben. Und die sind es ja, die wir brauchen, um Gewohnheiten zu verankern und aufzubauen.
Ein weiteres Problem mit extrinsischer Belohnung ist das sog. Crowding-Out-Phänomen. Was kann (Achtung: nicht MUSS!) passieren, wenn wir Menschen für Dinge beispielsweise monetär belohnen, die sie tun, weil sie intrinsisch dazu motiviert sind? Es kann zu einem Verdrängungseffekt kommen; in dem Sinne, dass die äußeren Anreize es schaffen, die interne Motivation (die Freude am Tun etc.) zu verdrängen. Manchmal gehen externe und interne Anreize Hand in Hand und ergänzen sich sogar; eine Vermischung extrinsischer und intrinsischer Belohnungen. Aber es gibt genügend Fälle, wo wir keine Synergie, sondern eben das Verdrängen, ein Crowding-Out, der intrinsischen Motivation beobachten.
Viele Interventionen haben das erste der eben angesprochenen Probleme: Das Zeitfenster der Belohnung passt nicht. Nehmen wir als Beispiel Gesundheitsinterventionen in Form von (teils auch wissenschaftlich begleiteten und) betreuten Programmen. Einige davon bieten monetäre Anreize; was dann erstmal dazu führt, dass anfänglich ein Erfolg zu beobachten ist. Wir können uns den Verlauf grafisch vorstellen: Entlang einer Art logarithmischen Funktion werden die Erfolge – pro Zeiteinheit oder pro Aufwand, den wir investieren – immer weniger. Das Ausführen der gesundheitsrelevanten Handlung erfordert Anstrengung. Vermutlich nicht nur beim ersten, sondern jedes Mal, da die monetäre Belohnung, die wir bekommen, wenn wir ein bestimmtes Ziel erreicht haben, zu spät kommen, um bedeutsam für das Dopaminsystem zu sein.
In einem konkreten Projekt wurde eine solche Intervention umgesetzt: Die Versuchspersonen bekamen Geld für Gewichtsreduktion: 100 Dollar, wenn sie innerhalb der Laufzeit pro Monat ein Pfund abnahmen. Die Dauer des Projekts betrug sechs Monate. Das Gewicht wurde einmal pro Monat erhoben.
Methodisch sauber wurde die Experimentalgruppe (mit der Belohnung) mit einer Kontrollgruppe verglichen. Ein anfänglicher kleiner Unterschied zwischen Experimental- und Kontrollgruppe war vorübergehend zu beobachten, verschwand aber bald wieder. Eine nicht uninteressante Randbemerkung: Eine Belohnung einer Gruppe von Versuchspersonen hat besser gewirkt als die individuelle Belohnung. Hier beobachten wir soziale Effekte (Gruppendynamik, Commitment etc.), die eine solche Intervention stützen können.
Wo liegt das Problem bei dieser Intervention? Zum einen scheint hier keine wirkliche Gewohnheit aufgebaut worden zu sein. Es wurden keine potenziell regelmäßig stattfindenden Aktionen, wie zum Beispiel das Essen bestimmter Nahrungsmittel, belohnt. Das einmalige Wiegen pro Monat zählt hier nicht als Wiederholung im Sinne von Gewohnheiten. Das Design der Intervention zielt nicht auf Habits ab, sondern auf bewusste Entscheidungen; mit allen negativen Folgen, die wir schon kennen.

Für diesen nicht optimalen Verlauf von Interventionen, die eigentlich auf die langfristige Änderung von Verhalten abzielen und damit Gewohnheiten unbedingt auf dem Schirm haben sollten, finden wir viele weitere Beispiele: Mitarbeiterboni, Versicherungsprämien, viele weitere Bonusprogramme. Immer das gleiche Problem: Die zeitliche Kopplung ist zu lose.
Anders das Beispiel eines sog. Swear-Jars (eine vernünftige deutsche Übersetzung habe ich nicht gefunden; Phrasenschwein trifft es auch nicht wirklich): Für jedes Schimpfwort oder jeden Fluch müssen Sie eine bestimmte Menge Geld in das Glas geben; zum Beispiel einen Euro. Wenn jemand da ist, der Sie nach erfolgtem Fehltritt darauf hinweist, ist die enge zeitliche Kopplung abgesichert. Die Belohnung ist hier natürlich eine negative; also eine Bestrafung. Aber auch hier greifen dopaminerge Mechanismen – die Dopamin-Antwort fällt reduziert aus – und Gewohnheiten können sich entwickeln.
Stickk.com ist eine Web-Plattform, bei der wir Verträge ähnlich einem Swear-Jar online aufsetzen können. Ein Beispiel: Sie vereinbaren mit einem Freund, dass sie innerhalb der nächsten Jahre ein bestimmtes Gewicht nicht überschreiten, Jede:r von Ihnen kann jederzeit ein Testwiegen verlangen. Wer das Gewicht überschreitet, muss 10.000 EUR bezahlen. Ganz schön happig! Tatsächlich ist diese Abmachung der Ausgangspunkt der Gründer von stickk.com gewesen. Natürlich geht es hier meist um deutlich geringere Summen, die aber dann doch schmerzen, wenn sie zu bezahlen sind. Ein interessanter Twist ist der Adressat des Geldes. Das kann dann zum Beispiel auch eine Organisation sein, deren Ziele Sie vehement und leidenschaftlich ablehnen.
Das alles sind ganz gute Ideen. Aber wir wissen, was jetzt folgt: Wenn es um Gewohnheiten geht, kommt auch hier das Feedback zu spät, um Dopamin-relevant zu sein.

Wir haben als wichtige Eigenschaft von Belohnung die zeitliche Unmittelbarkeit kennen gelernt: Das Feedback muss innerhalb einiger Sekunden erfolgen, um relevant für Gewohnheiten sein zu können; Stichwort Dopaminsystem.
Nun werfen wir einen Blick auf eine weitere Eigenschaft von Rückmeldung, für die wir unter dem Blickwinkel der Gewohnheiten unsere Haltung vermutlich ebenfalls neu kalibrieren müssen. Wie sollen im Arbeitsumfeld positive Rückmeldungen erfolgen? Die angesprochene Workplace Wisdom – also die etablierte Denkschule am Arbeitsplatz – ist da eindeutig: “Rewards (or remuneration) should be transparent, reliable, and firm. Surprises are out. Predictability is in.” – Also bitte keine Überraschungen; lieber stabile und vorhersehbare Strukturen! So wird der Aufbau von Vertrauen unterstützt; Stress und Unsicherheit werden vermieden. Völlig richtig! Aber eben nicht die geeignete Umgebung für die Entwicklung von Gewohnheiten, wie wir vielleicht schon vermuten können.
Gewohnheiten profitieren nicht nur von der Unmittelbarkeit der Rückmeldung, sondern auch von deren Variabilität. Der große Hebel hier lautet: Unsichere Belohnungen. Und das bedeutet eben keine starre Kopplung von Handlung und Rückmeldung. Diese kann auch mal größer oder kleiner oder gar komplett ausfallen. Sie haben dieses Prinzip vermutlich schon im Rahmen der operanten Konditionierung kennen gelernt. Diese Erkenntnis ihrer Forschungsarbeit hat damals schon die Behavioristen überrascht, die in Skinnerboxen mit Tauben gearbeitet haben! Verhalten, das über variable, unsichere Belohnungen gelernt wurde, war deutlich resistenter gegenüber Löschung. Wir beobachten die Effektivität von unsicherer Belohnung in vielen Bereichen unseres Lebens. Einen Bereich, den wir nicht allzu oft besuchen (sollten!), ist das Casino. Glücksspiele leben von unsicheren Belohnungen. Sie sind ein ganz entscheidender Faktor, der auch dazu beiträgt, dass sich ungesund übersteigerte Spielgewohnheiten entwickeln.
Wenn wir wollen, können wir einen evolutionären Ansatz für die Relevanz unsicherer Belohnungen finden: Die Umwelt, in denen unsere Vorfahren sich entwickelt haben, bildet diesen Aspekt von Casinos & Glücksspiel generell ab. Verhalten, das wir zeigen, um Gelegenheit zur Paarung oder zur Nahrungsaufnahme zu bekommen, ist nicht immer erfolgreich. Die Belohnungen sind hochgradig unsicher. Aber natürlich sollte uns diese Unsicherheit nicht davon abhalten, das entsprechende Verhalten zu zeigen; vielleicht sogar ganz im Gegenteil.
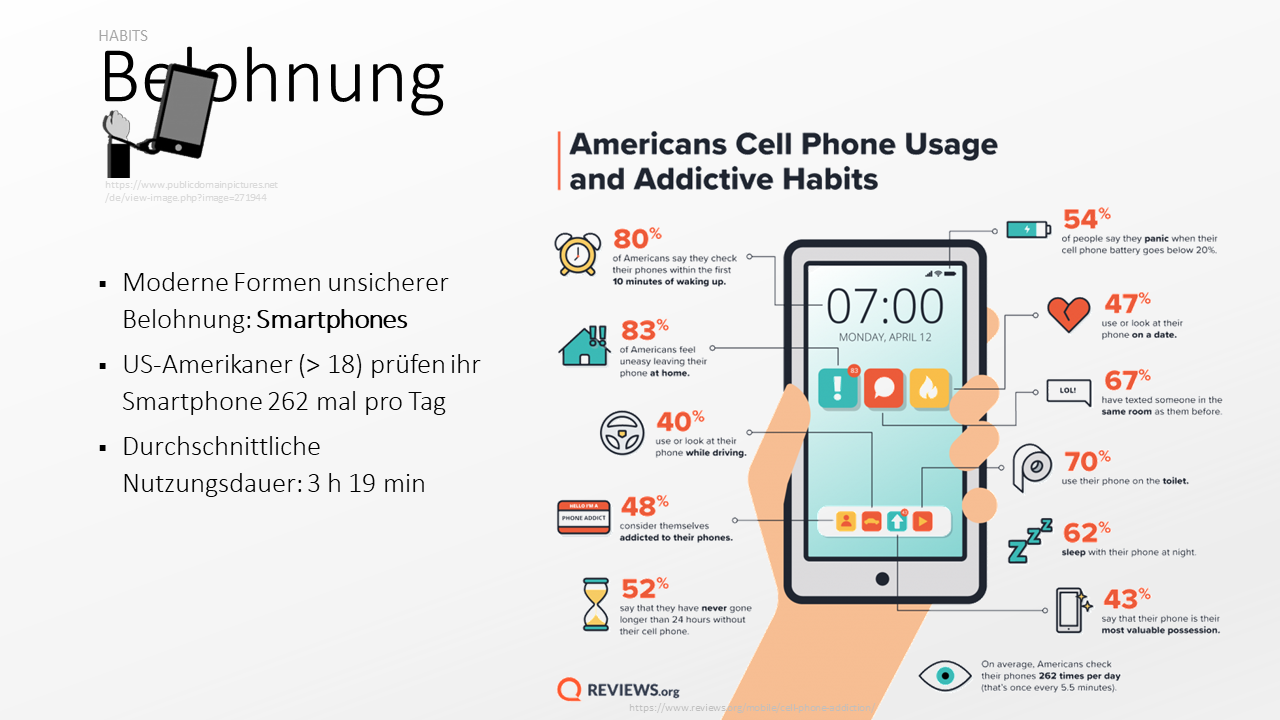
Wenn Sie diese Folie sehen, sind die Zahlen darauf auch schon wieder veraltet. Und wir können vermuten, dass sie sich in der Zwischenzeit nicht in eine deutlich positivere Richtung entwickelt haben. Hier kann man natürlich geteilter Meinung sein. Ich persönlich halte die Gewohnheiten, die unsere Smartphones uns nötigen zu entwickeln, eindeutig für keine positive Entwicklung. Auch hier sind die beiden Prinzipien am Werk, die wir eben besprochen haben: unmittelbare und unsichere Belohnung. Habe ich eine Nachricht bekommen? Wir können uns nie sicher sein, bekommen die Information aber mit nur einem Tastendruck.
Ich werde Ihnen jetzt nicht nochmals alle Zahlen auflisten. Sie sollten sich diese aber trotzdem alle kurz ansehen. Auch wenn das die Zahlen aus den USA sind, können wir vermuten, dass sie in Deutschland nicht viel anders aussehen. Kritisch wird unser Smartphone-Umgang besonders da, wo er mit Dingen und Tätigkeiten unseres Alltags kollidiert, die eigentlich unsere ungeteilte Aufmerksamkeit erfordern (im Straßenverkehr, im Unterricht) – oder in denen wir unseren Aufmerksamkeitsapparat komplett herunterfahren sollten (z. B. im Schlafzimmer). Zum Thema Ablenkung kommen wir etwas später noch im Zusammenhang mit Stress und Resilienz.

Wenn uns jemand um eine Einschätzung bittet, was denn nun wichtiger für die Entwicklung von Gewohnheiten sei, die Höhe von Belohnungen oder deren Unsicherheit, würden wir vermutlich recht eindeutig antworten. Natürlich die Höhe der Belohnung! Aber damit lägen wir nicht immer richtig. Überraschenderweise ist es – in einem gewissen Rahmen – eher die Unsicherheit, die hier oftmals den Hut auf hat.
Shen und Kolleg:innen konnten das 2005 in einer schönen Studie nachweisen (Shen et al., 2015). Ihre Versuchspersonen sollten ihre Zahlungsbereitschaft (Willingness to pay, WTP) entweder für ein Päckchen mit fünf Pralinen oder für eines mit entweder drei oder fünf Pralinen angeben. Im zweiten Fall hat das Los entschieden. Die beiden Versuchsbedingungen wurden nicht von denselben Personen durchlaufen; es handelt sich hier also um ein Between Subjects Design.
Das Ergebnis der Versuche ist überraschend. Die angebotenen Preise für die fünf Pralinen liegen im Schnitt bei $ 1,25; für die unsichere Wahl bei $ 1,89. Die Teilnehmer:innen scheinen hier also das Element der Unsicherheit tatsächlich wertzuschätzen. Die Autor:innen bezeichnen das Phänomen dann auch passend als Motivating-Uncertainty-Effect.
Natürlich geht es in dieser Studie nicht zentral um Gewohnheiten. Es geht aber um die Bedeutung von unsicheren Belohnungen. Wir erkennen dadurch deutlich, dass Unsicherheit von Belohnung offenbar einen Wert an sich haben kann. Dieser Tatsache sind sich beispielsweise auch die Entwickler:innen von Gamification-Strategien zum Beispiel in Educational bzw. Serious Games bewusst. Auch hier werden ganz gezielt unsichere Belohnungen eingesetzt.

Belohnungen sind eine wunderbare Methode, um zu überprüfen, ob eine bestimmte Handlung bereits zur Gewohnheit geworden ist. Wird die Handlung weiterhin ausgeführt, obwohl die Belohnung wegfällt, ist das ein deutliches Indiz für eine Gewohnheit. Habits führen also dazu, dass wir insensitiv gegenüber Belohnungen werden. Diese Insensitivität konnte zuerst in Versuchen mit Ratten nachgewiesen werden. Dabei wurden zwei Gruppen von Versuchstieren unterschieden. Die Tiere der einen Gruppe haben in einem Lernversuch 100 Durchgänge eines Tastendrucks absolviert. Bei der zweiten Gruppe waren es 500 Durchgänge. Nach jedem Tastendruck bekamen die Tiere eine Futterpille. Nach 100 bzw. 500 Durchgängen waren die Pillen mit einer Substanz versetzt, die die Tiere krank machte. Die Belohnung war damit keine mehr.
Die 100er-Gruppe hat das gelernte Verhalten nach dieser Erfahrung beendet. Die 500er-Gruppe zeigte es noch für einige Minuten. Sie war nicht in der Lage, ihre Gewohnheit so ohne Weiteres zu beenden, obwohl auch sie die versetzten Futterpellets sofort wieder ausspuckte. Auch diese Tiere wussten eigentlich, dass es sich hier nicht um eine Belohnung handelt.
Ratten sind das eine. Wie sieht es mit uns Menschen aus? Die Rolle von Belohnungen für eine ganz bestimmte Art von Gewohnheit haben David Neal und Wendy Wood in ihrer sog. Popcorn-Studie untersucht (Neal et al., 2011). Die Ergebnisse dieser Studie wurden auch von der nicht-wissenschaftlichen Presse aufgenommen und für kurze Zeit breit kommuniziert. Bei der Interpretation wurde aber der ein oder andere Fehler begangen. Machen wir es besser. Lesen Sie die Studie quer (sollte der Link nicht [mehr] funktionieren, können Sie ihn leicht ergoogeln). Sie sollten in der Lage sein, die angegebenen Fragen zu beantworten: Was sind die untersuchten Effekte (Unabhängige Variable und Fakturstufen)? Was wird gemessen (Abhängige Variablen)? Zu welchen Ergebnissen kommt die Studie? Sie sollten auf dieser Grundlage die abgebildeten Ergebnisdiagramme verstehen und erklären können.
Wir können den Abschnitt Belohnungen mit einen Zitat von Wendy Wood beenden:
Habits are built in the moment, from our experience of pleasure. The selection rule is simple—what we find enjoyable. In short, we learn habitually when our actions repeatedly bring us more pleasure than our neural systems expect.
— Wood (2019), S. 129