1.1 What is Data Science?
Data science is a multidisciplinary filed1. It blends of data mining, data analysis, statistics, algorithm development, machine learning and advanced computing and software technology together in order to solve analytically complex problems. Its ultimate goal is to reveal insight of data and get the data value for business.
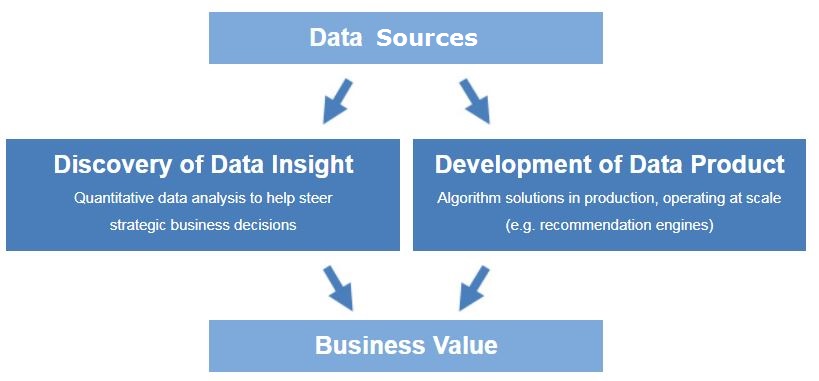
Figure 1.1: Concept of Data Science
Data Science as Discovery of Data Insight
This aspect of data science is all about uncovering hidden patterns from data. Diving in at a granular level to mine and understand complex patterns, trends, and relations. It’s about surfacing hidden insight that can help and enable companies to make smarter business decisions and take appropriate actions to gain competitive advantages in the market. For example:
- Amazon build recommendation system to provide users suggestion on purchase based on the user’s shopping history.
- Netflix data mines movie viewing patterns to understand what drives user interest, and uses that to make decisions on which Netflix original series to produce.
- Target identifies what are major customer segments within it’s base and the unique shopping behaviors within those segments, which helps to guide messaging to different market audiences.
- Proctor & Gamble utilizes time series models to more clearly understand future demand, which help plan for production levels more optimally. How do data scientists mine out insights? It starts with data exploration. When given a challenging question, data scientists become detectives. They investigate leads and try to understand pattern or characteristics within the data. This requires a big dose of analytical creativity.
How do data scientists mine data insights? there is a procedure to follow. It generally starts with data description it is called Described data analysis (DDA) to get first sight on the data sets available. DDS will help data scientist to grasp the quantity and quality of the data. so they can decide how to deal with the data. it then generally followed by data cleaning, manipulation, transform and attributes engineering etc, together called preprocess. Data preprocess is also generally combined with exploratory data analysis (EDA). When given a challenging question, data scientists normally become detectives. They investigate all the information available and follow any possible leads and try to understand pattern or characteristics within the data. This not only requires huge amount tools and techniques but also demand analytical creativity .
Then as needed, data scientists may apply quantitative technique in order to get a level deeper – e.g. statistical methods, projections, inferential models, segmentation analysis, time series forecasting, synthetic control experiments, etc. The intent is to scientifically piece together a forensic view of what the data is really saying.
This data-driven insight is central to providing strategic guidance. In this sense, data scientists act as consultants, information provider help business stakeholders on how to act on findings.
Data Science as Development of Data Product
A “data product” is a technical asset that:
- utilizes data as input, and
- processes that data to return algorithmically-generated results.
A typical example is users’ scoring system. It takes users profile or/and behavior data as input and with a complex scoring engine, it produces a credit score of the users for business decision making. Another example of a data product is a recommendation engine, which ingests user data, and makes personalized recommendations based on that data. Here are some examples of data products:
- Amazon’s recommendation engines suggest items for you to buy, determined by their algorithms.
- Netflix recommends movies to you. Spotify recommends music to you.
- Gmail’s spam filter is data product – an algorithm behind the scenes processes incoming mail and determines if a message is junk or not.
- Computer vision used for self-driving cars is also data product – machine learning algorithms are able to recognize traffic lights, other cars on the road, pedestrians, etc.
This is different from the “data insights” section above, where the outcome to that is to perhaps provide advice to an executive to make a smarter business decision. In contrast, a data product is technical functionality that encapsulates an algorithm, and is designed to integrate directly into core applications. Respective examples of applications that incorporate data product behind the scenes: Amazon’s homepage, Gmail’s inbox, and autonomous driving software.
Data scientists play a central role in developing data product. This involves building out algorithms, as well as testing, refinement, and technical deployment into production systems. In this sense, data scientists serve as technical developers, building assets that can be leveraged at wide scale.
123↩︎