4.1 Load Data
Here are a simple plan for understand the Titanic data:
- Get Titanic data load into RStudio
- Assess Data quantity (number of files, size of each file in number of records, number of attributes in each record)
- Attributes types assessment
- Attributes value assessment (numbers and summary, description).
Now, get your RStudio ready.
If you have not done the Exercises 2.5, which asked you to create a new R project named “MyDataScienceProject”. You can do it now.
Open your RStudio, Click “File-> New project->New Directory -> choose New R Project”, then, enter “MyDataScienceProject” in the Directory name box and select your directory. Click “Create Project” at the right bottom as shown in Figure 4.1
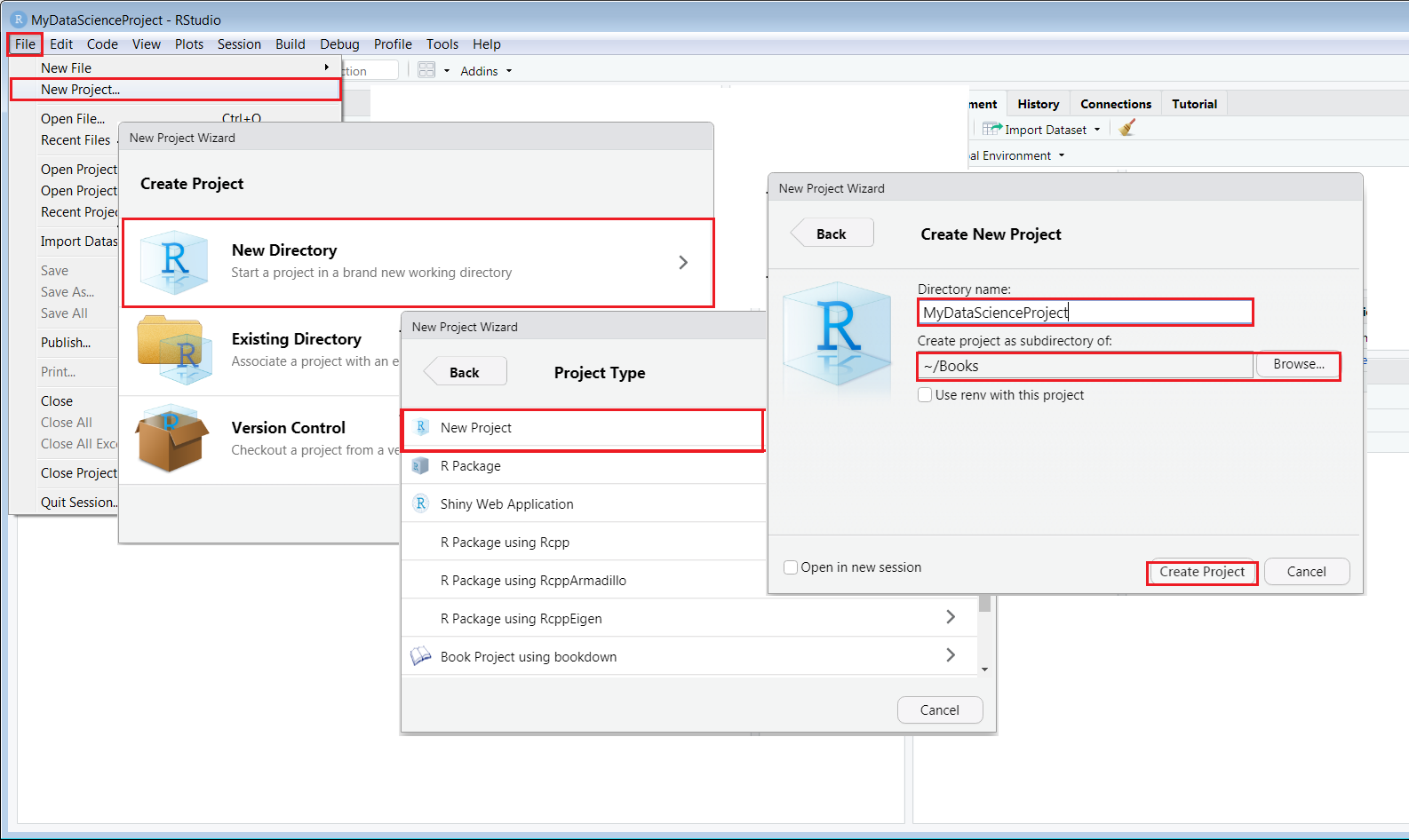
Figure 4.1: Create a new project in RStudio
Load file “TitanicDataAnalysis1_UnderstandData.R” (from online repo or Appendix) into RStudio and create a new R file and name it “My_TitanicDataAnalysis1_UnderstandData.R”.
The protocol is you copy sample code indicated from this book (or from the file you loaded) “chunk” by “chunk” into your R file and run them. Okay, let us start,
In your RStudio (WorkSpace), copy lines from “TitanicDataAnalysis1_UnderstandData.R” into your file “MyTitanicDataScience1”, They are the same code in this book. Alternatively, you can copy from here. For example, copy the following “chunk” (two lines of code) into your file.
# Load raw data
train <- read.csv("train.csv", header = TRUE)
test <- read.csv("test.csv", header = TRUE)You may see this in your Console,
> train <- read.csv("train.csv", header = TRUE)
Error in file(file, "rt") : cannot open the connection
In addition: Warning message:
In file(file, "rt") :
cannot open file 'train.csv': No such file or directory
> test <- read.csv("test.csv", header = TRUE)
Error in file(file, "rt") : cannot open the connection
In addition: Warning message:
In file(file, "rt") :
cannot open file 'test.csv': No such file or directory
> Don’t panic. let us look into it. It is important to learn how to diagnose and correct problems as well as write and run code.
The first thing you need to learn is using RStudio help.
Now type ? read.cvs in your Console, look at the Multifunction pane, the tab Help is auto selected and help message for read.cvs is appeared. See Figure 4.2
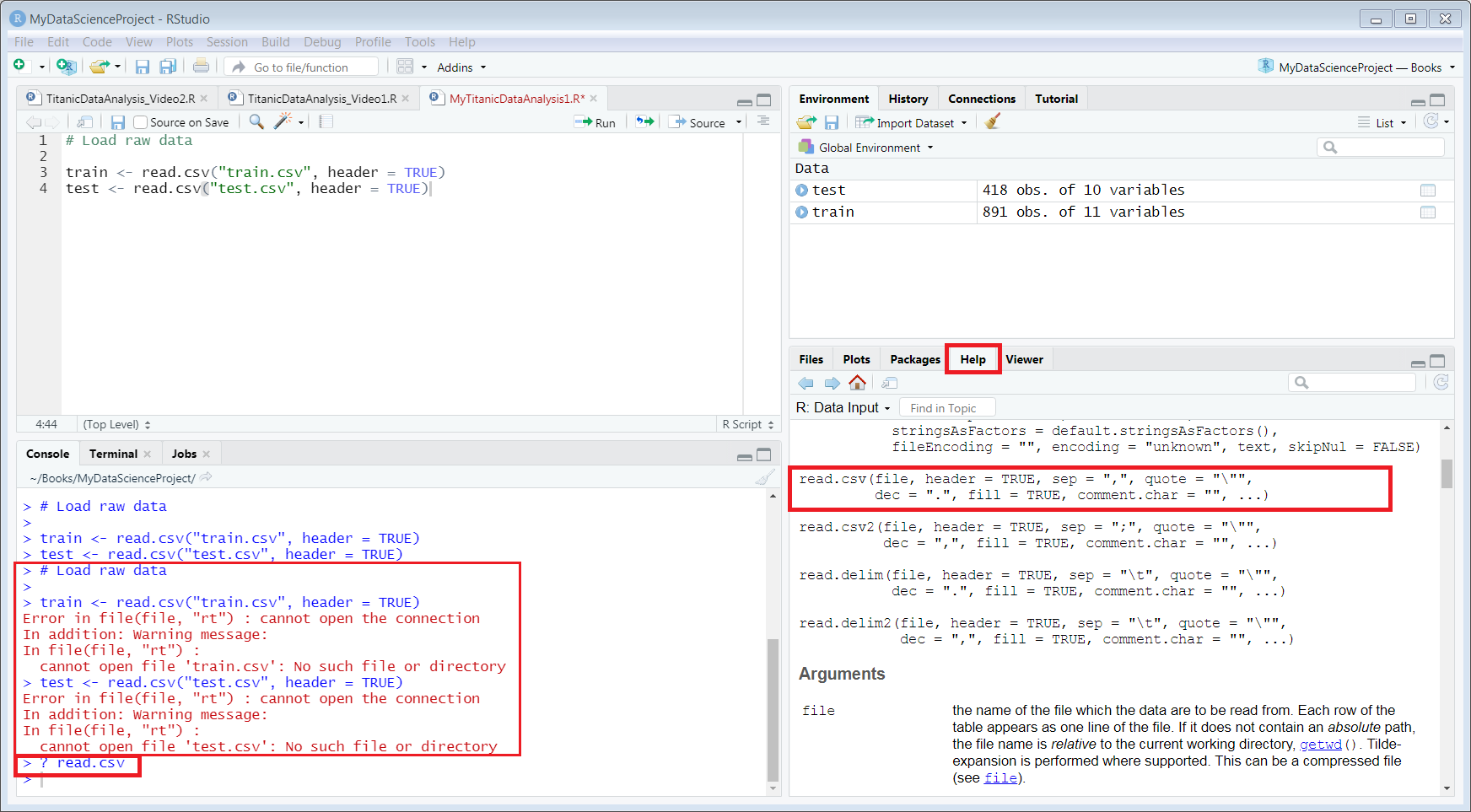
Figure 4.2: Screen capture of Error and Help
Now, notice that the error message says, “cannot open file 'test.csv': No such file or directory”. We don’t have file train.csv and test.csv in our working directory. Alternatively, you can store them in a dedicated directory like “~/Data”.
Now, Download the train.csv and test.csv from Kaggle (if you did not download already) and stored into our project working directory1.
Please note that it is a common practice that data scientist download datasets from data sources and save to a local drive. Having a local copy of the raw datasets is good idea. But a lot of times, it is infeasible to do so either because the data is too big or there are some access restriction. So, you have to using service provider’s API or data URI through HTTP protocol or other protocol like FTP etc.
Once, you have download the datasets from the Kaggle website and unzipped (or moved) them into your local working directory, run the same code again by select them all and click “Run” or type “Ctr + Enter” .
You will see the two new attributes have been created and displayed in the WorkSpace pane. See Figure 4.3.
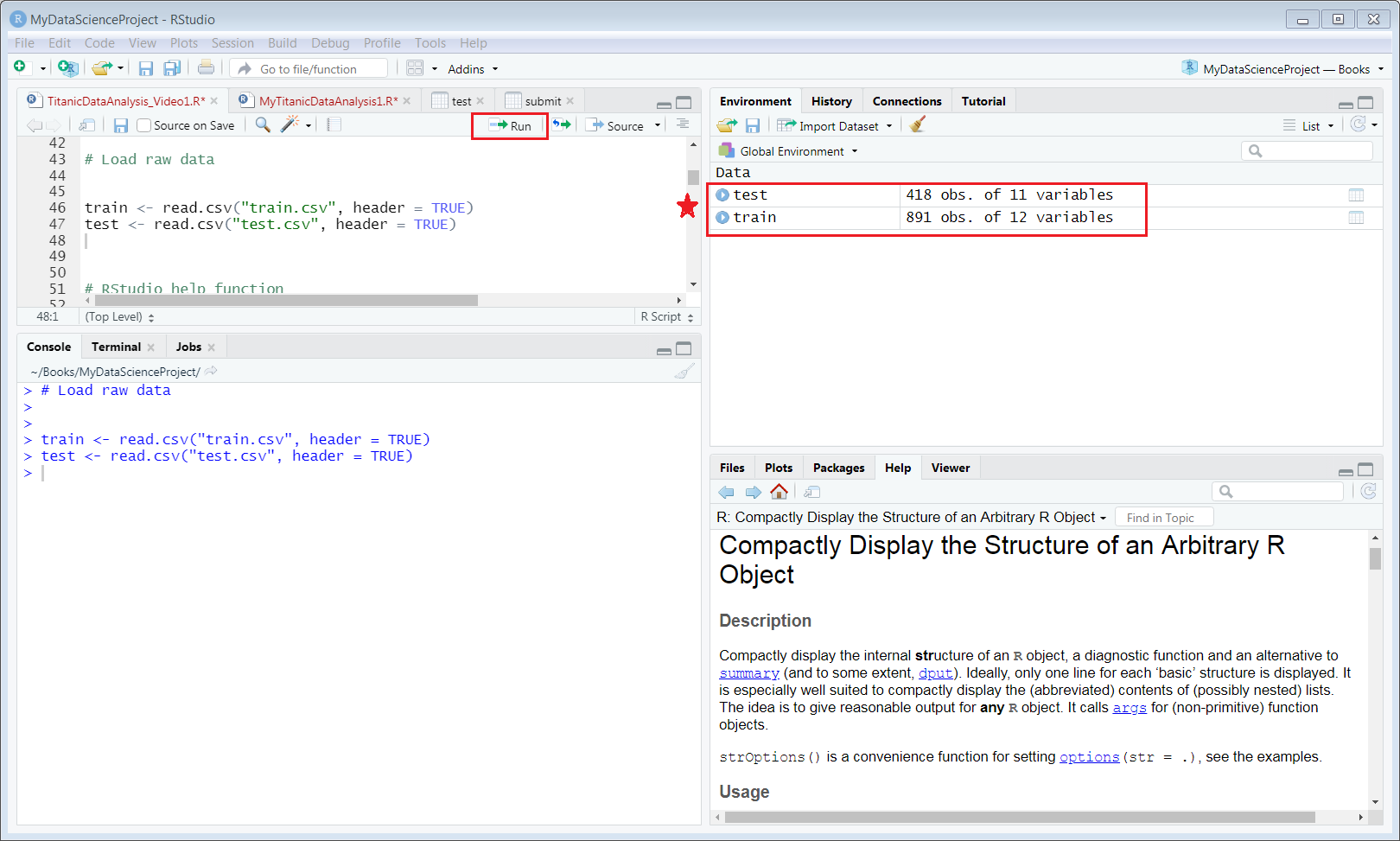
Figure 4.3: Screen capture of import raw data
The data files were asked to be downloaded and unzipped in the previous chapter. If you simply unzip it into the working directory, it will exists in “~/Titanic/” directory. In this case, you need to move them into your working directory.↩︎