8.3 How does R Markdown work
Lets take a look under the hood at R Markdown. The best way to get a sense of whats going on is to create a R Markdown file using RStudio.
8.3.1 Creating an R Markdown file
Within RStudio, click File → New File → R Markdown and you’ll get a dialog box like this:
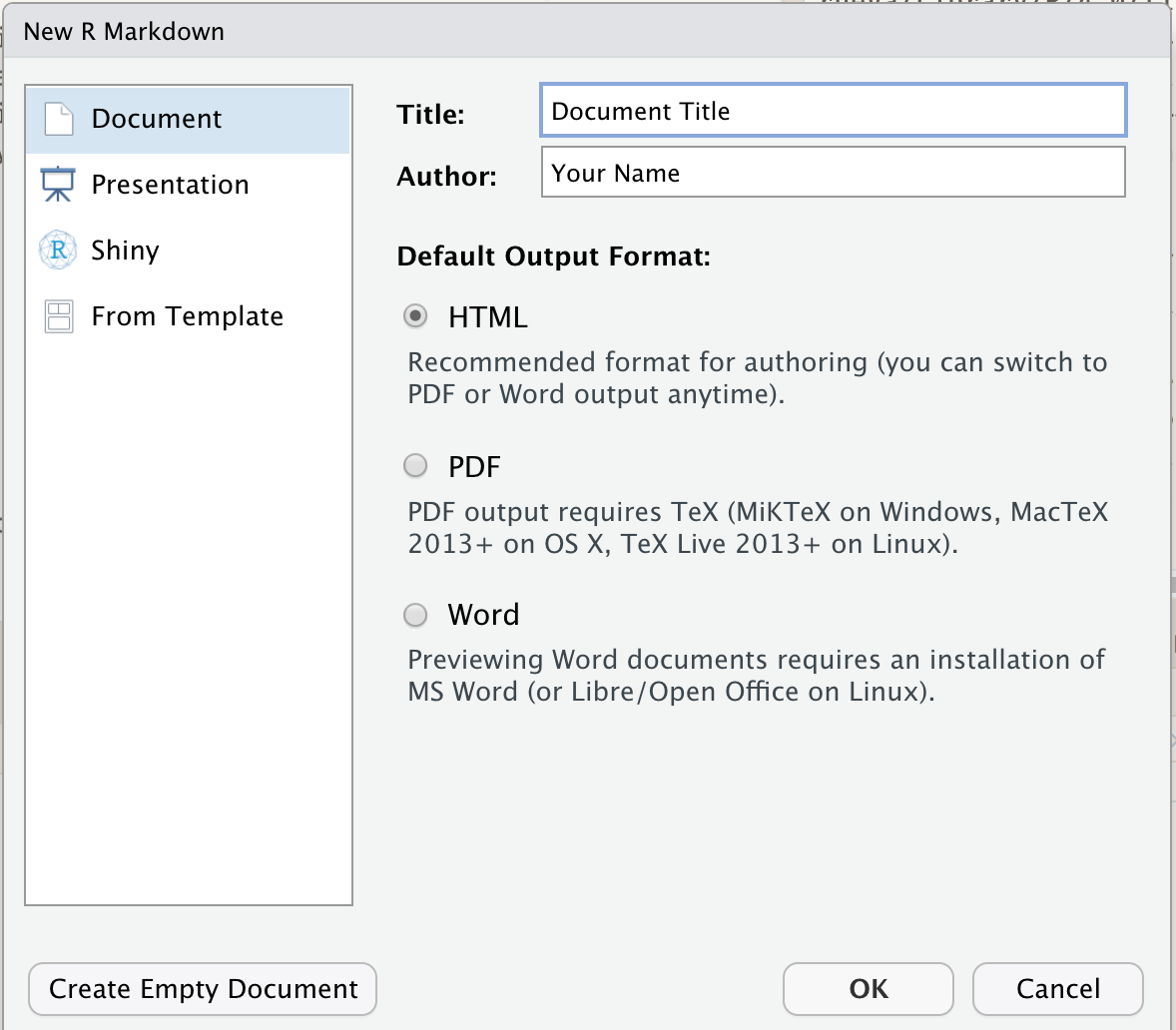
You can stick with the default (HTML output), but give it a title.
As a result RStudio generates this:
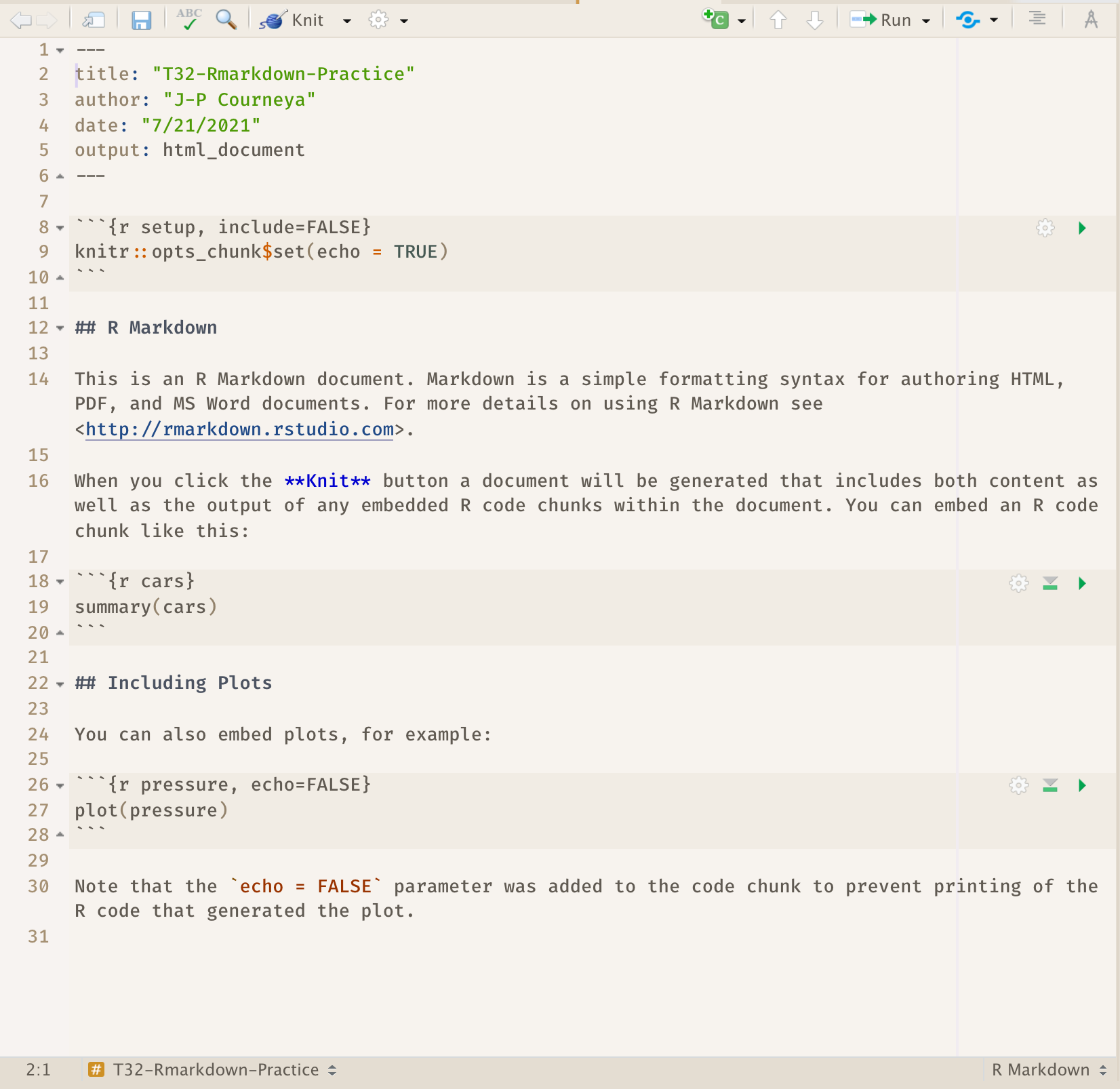
8.3.2 R Markdown Basic Components
What we see is an R Markdown file, a plain text file that has the extension .Rmd: It contains three important types of content:
- An (optional) YAML header surrounded by
---s. - Chunks of R code surrounded by
```. - Text mixed with simple text formatting like
# headingand_italics_.
8.3.2.1 YAML Header
The initial chunk of text (header) contains instructions for R to specify what kind of document will be created, and the options chosen. You can use the header to give your document a title, author, date, and tell it what type of output you want to produce. In this case, we’re creating an html document. The syntax for the metadata is YAML (YAML Ain’t Markup Language, (https://en.wikipedia.org/wiki/YAML)), so sometimes it is also called the YAML metadata or the YAML frontmatter. Before it bites you hard, we want to warn you in advance that indentation matters in YAML, so do not forget to indent the sub-fields of a top field properly.
---
title: "T32-Rmd-Practice"
author: "JP Courneya"
date: "7/21/2021"
output: html_document
---8.3.2.2 Body of the document
The body of the document follows the metadata. The syntax for text (also known as prose or narratives) is Markdown, a lightweight set of conventions for formatting plain text files. Markdown is designed to be easy to read and easy to write. There are also two types of computer code, code chunks and inline R code. We will look at each of these in more detail in subsequent sections.
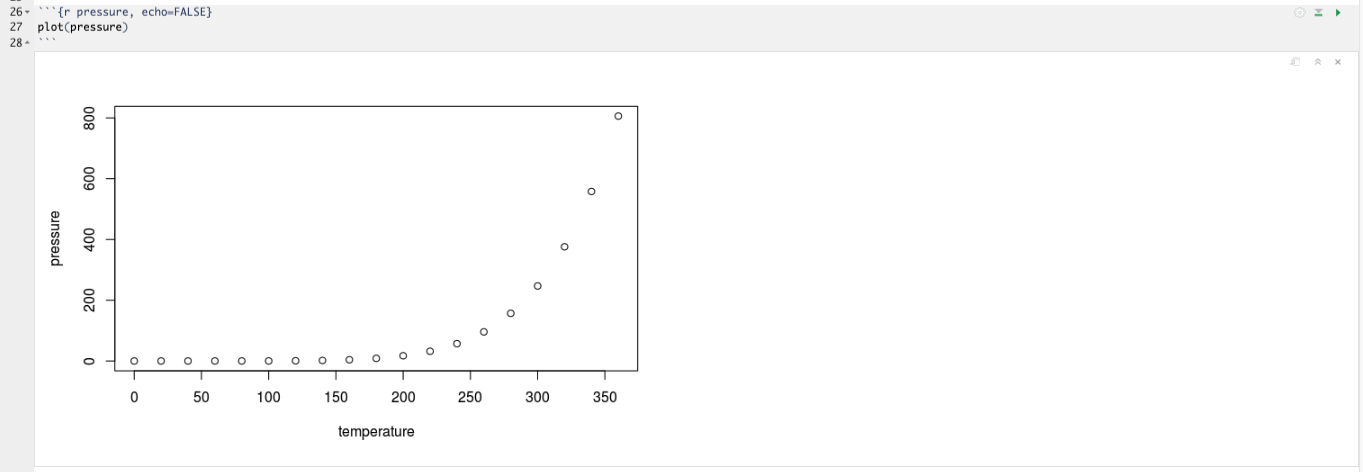
You will notice in the .Rmd interface the code and output are interleaved. You can run each code chunk by clicking the Run icon (it looks like a play button at the top of the chunk), or by pressing Cmd/Ctrl + Shift + Enter. RStudio executes the code and displays the results inline with the code:
To generate a report from the file, run the render command:
library(rmarkdown)
render("T32-rmd-practice.Rmd")Better still, use the  button in the RStudio IDE to render the file and preview the output with a single click or keyboard shortcut (⇧⌘K). You will notice your first time “knitting” the document you are prompted to save the file, save it with a meaningful name.
button in the RStudio IDE to render the file and preview the output with a single click or keyboard shortcut (⇧⌘K). You will notice your first time “knitting” the document you are prompted to save the file, save it with a meaningful name.
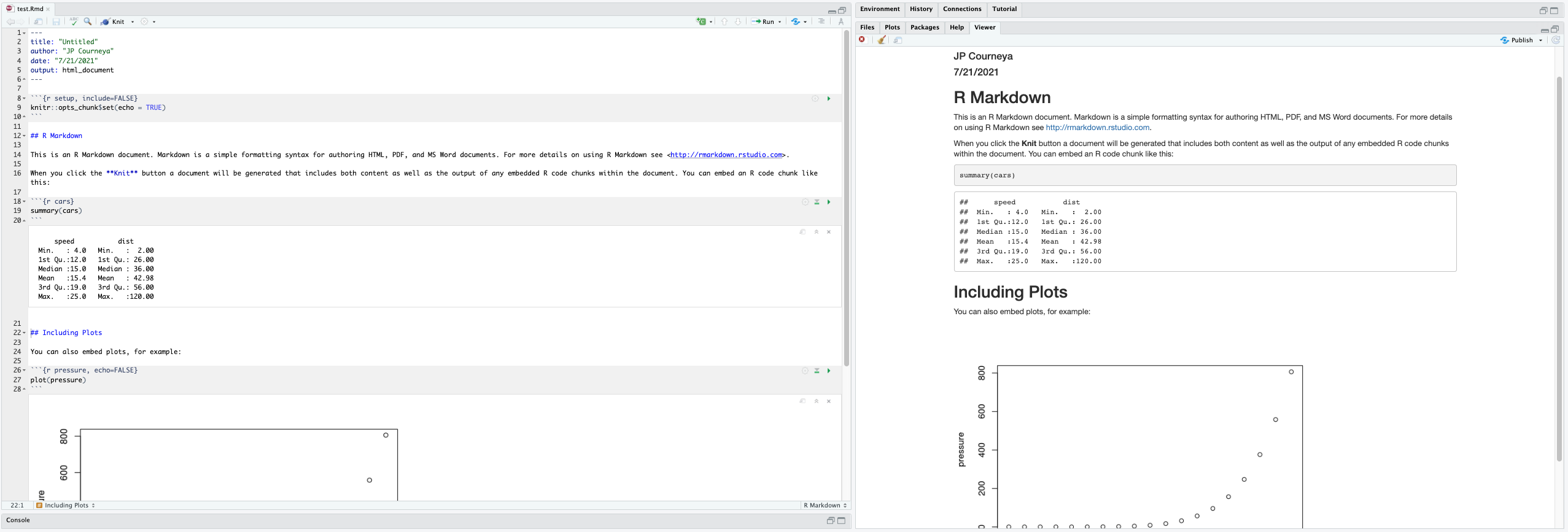
R Markdown generates a new file that contains selected text, code, and results from the .Rmd file.
8.3.2.3 How things get compiled

When you run render, or press the button, R Markdown feeds the .Rmd file to knitr, which executes all of the code chunks and creates a new markdown (.md) document which includes the code and its output.
The markdown file generated by knitr is then processed by pandoc which is responsible for creating the finished format.
This may sound complicated, but R Markdown makes it extremely simple by encapsulating all of the above processing into a single render function or button.
8.3.3 Markdown
Markdown is a system for writing web pages by marking up the text much as you would in an email rather than writing html code. The marked-up text gets converted to html, replacing the marks with the proper html code.
For now, let’s delete all of the stuff that’s in the .Rmd file and write a bit of markdown.
You make things bold using two asterisks, like this: **bold**, and you make things italics by using underscores, like this: _italics_.
You can make a bulleted list by writing a list with hyphens or asterisks, like this:
* one item
* one item
* one item
* one more item
* one more item
* one more item
- bold with double-asterisks
- italics with underscores
- code-type font with backticksThe output is:
- one item
- one item
- one item
- one more item
- one more item
- one more item
- bold with double-asterisks
- italics with underscores
- code-type font with backticks
You can use whatever method you prefer, but be consistent. This maintains the readability of your code.
You can make a numbered list by just using numbers. You can even use the same number over and over if you want:
1. bold with double-asterisks
1. italics with underscores
1. code-type font with backticksThis will appear as:
- bold with double-asterisks
- italics with underscores
- code-type font with backticks
You can make section headers of different sizes by initiating a line with some number of # symbols:
# Title
## Main section
### Sub-section
#### Sub-sub sectionThey will appear like this:

8.3.3.1 A bit more Markdown
You can make a hyperlink like this: [text to show](http://the-web-page.com).
You can include an image file like this: 
You can do subscripts (e.g., F2) with F~2~ and superscripts (e.g., F2) with F^2^.
If you know how to write equations in LaTeX, you can use $ $ and $$ $$ to insert math equations, like $E = mc^2$ and
$$y = \mu + \sum_{i=1}^p \beta_i x_i + \epsilon$$8.3.4 R code chunks
The real power of Markdown comes from mixing markdown with chunks of code. This is R Markdown. When processed, the R code will be executed; if they produce figures, the figures will be inserted in the final document.
To run code inside an R Markdown document, you need to insert a chunk. There are three ways to do so:
The keyboard shortcut Cmd/Ctrl + Alt + I
The “Insert” button icon in the editor toolbar.
By manually typing the chunk delimiters
```{r}and```.
I’d recommend you learn the keyboard shortcut. It will save you a lot of time in the long run!
The main code chunks look like this:
```{r}
summary(cars)
```You should give each chunk a unique name, as they will help you to fix errors and, if any graphs are produced, the file names are based on the name of the code chunk that produced them.
As an exercise add code chunks to:
- download gapminder data to /data
- Load the ggplot2 package
- Read the gapminder data
- Create a plot
```{r download-gapminder-data, eval=TRUE}
download.file("https://raw.githubusercontent.com/swcarpentry/r-novice-gapminder/gh-pages/_episodes_rmd/data/gapminder_data.csv", destfile = "data/gapminder_data.csv")
```
```{r load-ggplot2, eval=TRUE}
library("ggplot2")
```
```{r read-gapminder-data, eval=TRUE}
gapminder <- read.csv(file = "data/gapminder_data.csv", stringsAsFactors = TRUE)
```
```{r make-plot, eval=TRUE}
plot(lifeExp ~ year, data = gapminder)
```As a courtesy the code to copy and place in chunks:
download.file("https://raw.githubusercontent.com/swcarpentry/r-novice-gapminder/gh-pages/_episodes_rmd/data/gapminder_data.csv", destfile = "data/gapminder_data.csv")
library(ggplot2)
gapminder <- read.csv(file = "data/gapminder_data.csv", stringsAsFactors = TRUE)
plot(lifeExp ~ year, data = gapminder)8.3.4.1 Chunk Options
There are a variety of options to affect how the code chunks are treated. Here are some examples:
- Use
echo=FALSEto avoid having the code itself shown. - Use
results="hide"to avoid having any results printed. - Use
eval=FALSEto have the code shown but not evaluated. - Use
warning=FALSEandmessage=FALSEto hide any warnings or messages produced. - Use
fig.heightandfig.widthto control the size of the figures produced (in inches).
So you might write:
```{r load_libraries, echo=FALSE, message=FALSE}
library("dplyr")
library("ggplot2")
```Often there will be particular options that you’ll want to use repeatedly; for this, you can set global chunk options, like so:
```{r global_options, echo=FALSE}
knitr::opts_chunk$set(fig.path="Figs/", message=FALSE, warning=FALSE, echo=FALSE, results="hide", fig.width=11)
```The fig.path option defines where the figures will be saved. The / here is really important; without it, the figures would be saved in the standard place but just with names that begin with Figs.
If you have multiple R Markdown files in a common directory, you might want to use fig.path to define separate prefixes for the figure file names, like fig.path="Figs/cleaning-" and fig.path="Figs/analysis-".
You can review all of the R chunk options by navigating to the “R Markdown Cheat Sheet” under the “Cheatsheets” section of the “Help” field in the toolbar at the top of RStudio.
8.3.4.2 Inline code
There is one other way to embed R code into an R Markdown document: directly into the text, with: r.
This can be very useful if you mention properties of your data in the text.
For example, using the diamonds dataset we could report:
We have data about
r nrow(ggplot2::diamondsdiamonds.
The output would be:
We have data about 53940 diamonds.
When inserting numbers into text, format() is your friend.
It allows you to set the number of digits so you don’t print to a ridiculous degree of accuracy, and a big.mark to make numbers easier to read.
The expression:
We have data about
`r format(nrow(ggplot2::diamonds), digits = 2, big.mark = ",")`diamonds.
Would look like this:
We have data about 53,940 diamonds.
You can combine these into a helper function:
comma <- function(x) format(x, digits = 2, big.mark = ",")
comma(3452345)## [1] "3,452,345"comma(.12358124331)## [1] "0.12"Using our nifty helper function,
The expression will now look different `r comma(nrow(ggplot2::diamonds))`
But give us the same amazing results as `r format(nrow(ggplot2::diamonds), digits = 2, big.mark = ",")` !
We have data about 53,940 diamonds.