3.3 Data Collection

3.3.1 Variables - Best Practices
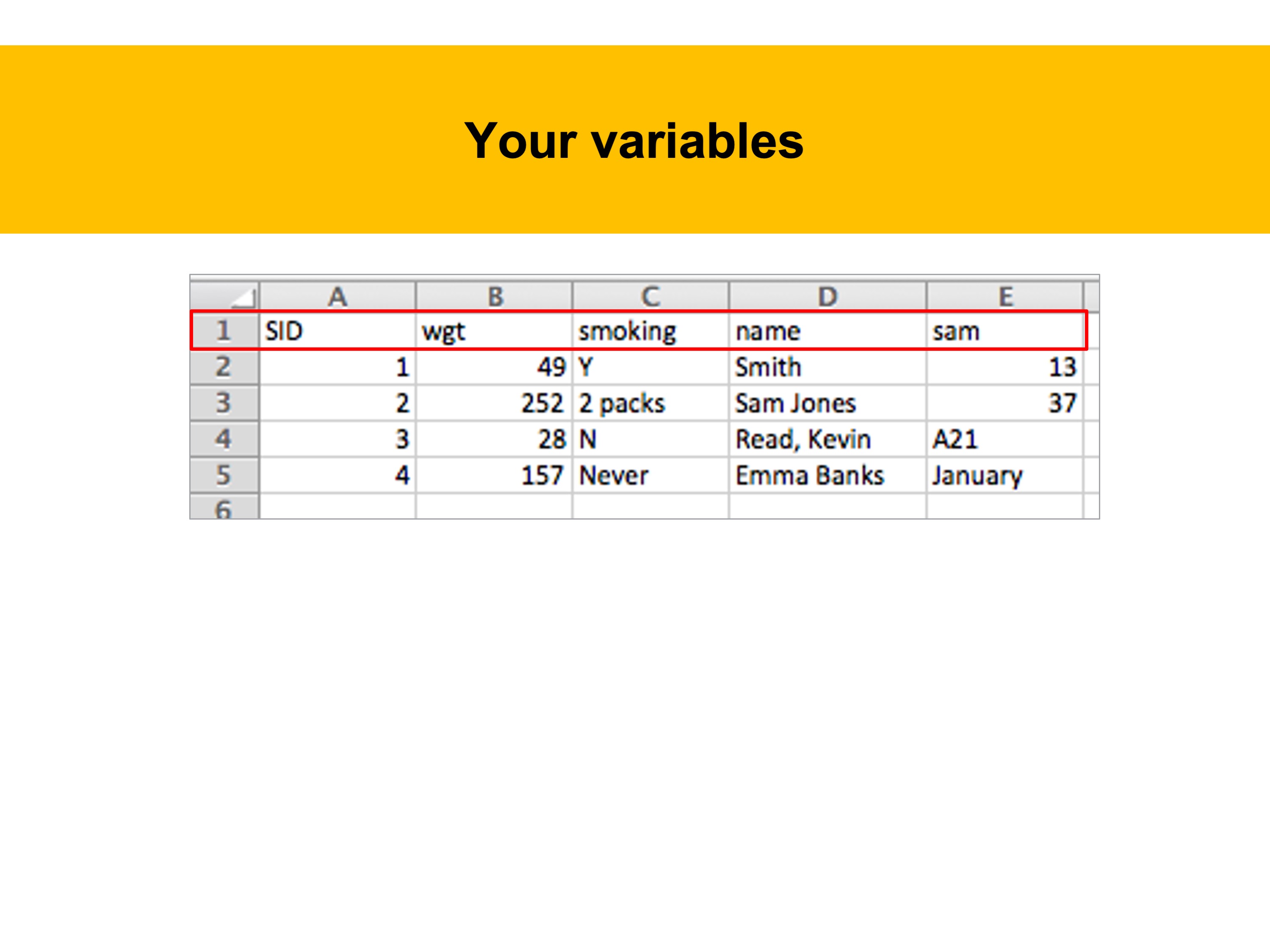 Take a look at this table: Do any problems jump out at you?
Take a look at this table: Do any problems jump out at you?
In this example, variable names are cryptic. One can guess that SID is subject ID or that wgt is weight, but a variable name like sam is anybody’s guess. While the “smoking” is clear, the meaning is not – ever smoked? how much smoked?
Also the meaning of weight is clear, the numbers indicate inconsistency in units of measurement. (Pounds? Kilos?)
To avoid a situation like this, variables should be clearly defined so that everyone collecting data has the same understanding and collects data in the same way. The most time consuming part of data analysis can be cleaning your data. Help save time from the beginning by collecting data consistently.
 One way to provide more consistency in data collection is to use forms for entering data with limited choices, especially for categorical values. These values can be coded and recorded in a code book. Make sure to code for missing data as well. Empty cells can be unnerving when you go to do your analysis. Did someone forget to enter the data? Or did the respondent not wish to disclose, or could they not remember the answer. Again, these could be things that are useful to know down the road. Just make sure to code with a number that could not be confused for real data, like 9999 for a missing age.
One way to provide more consistency in data collection is to use forms for entering data with limited choices, especially for categorical values. These values can be coded and recorded in a code book. Make sure to code for missing data as well. Empty cells can be unnerving when you go to do your analysis. Did someone forget to enter the data? Or did the respondent not wish to disclose, or could they not remember the answer. Again, these could be things that are useful to know down the road. Just make sure to code with a number that could not be confused for real data, like 9999 for a missing age.
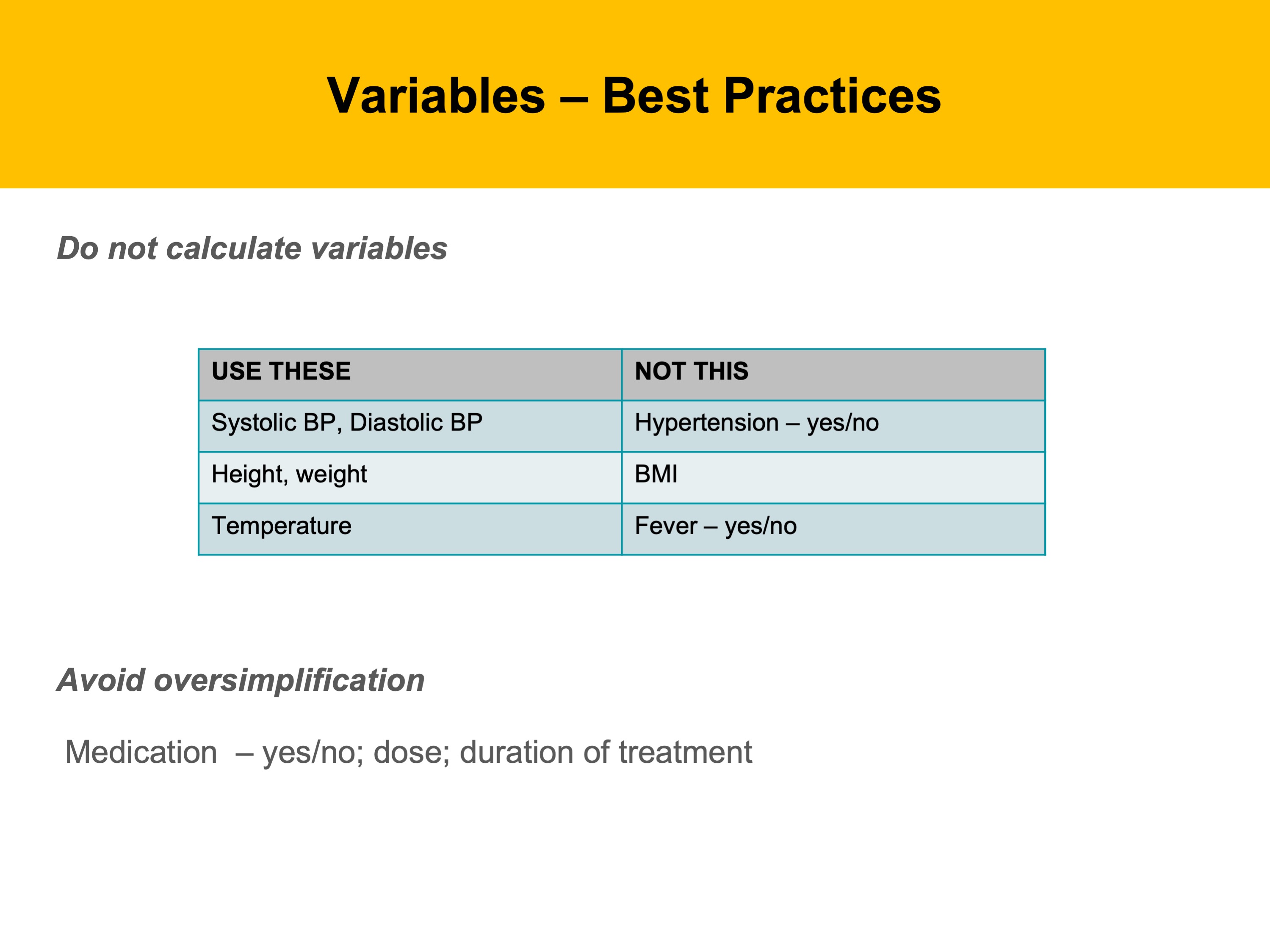 In addition, do not collapse data until you need to; leave your variables in the raw. For example, rather than recording BMI, record height and weight. You can always calculate BMI later, but you can not go backwards to height and weight if you only have BMI.
In addition, do not collapse data until you need to; leave your variables in the raw. For example, rather than recording BMI, record height and weight. You can always calculate BMI later, but you can not go backwards to height and weight if you only have BMI.
Also, be sure to clearly state the actual question you are asking, so it is not misinterpreted during data collection. So rather than labeling a field Medication – say does the patient take medication, or what dose of medication do they take.
3.3.2 Data Documentation
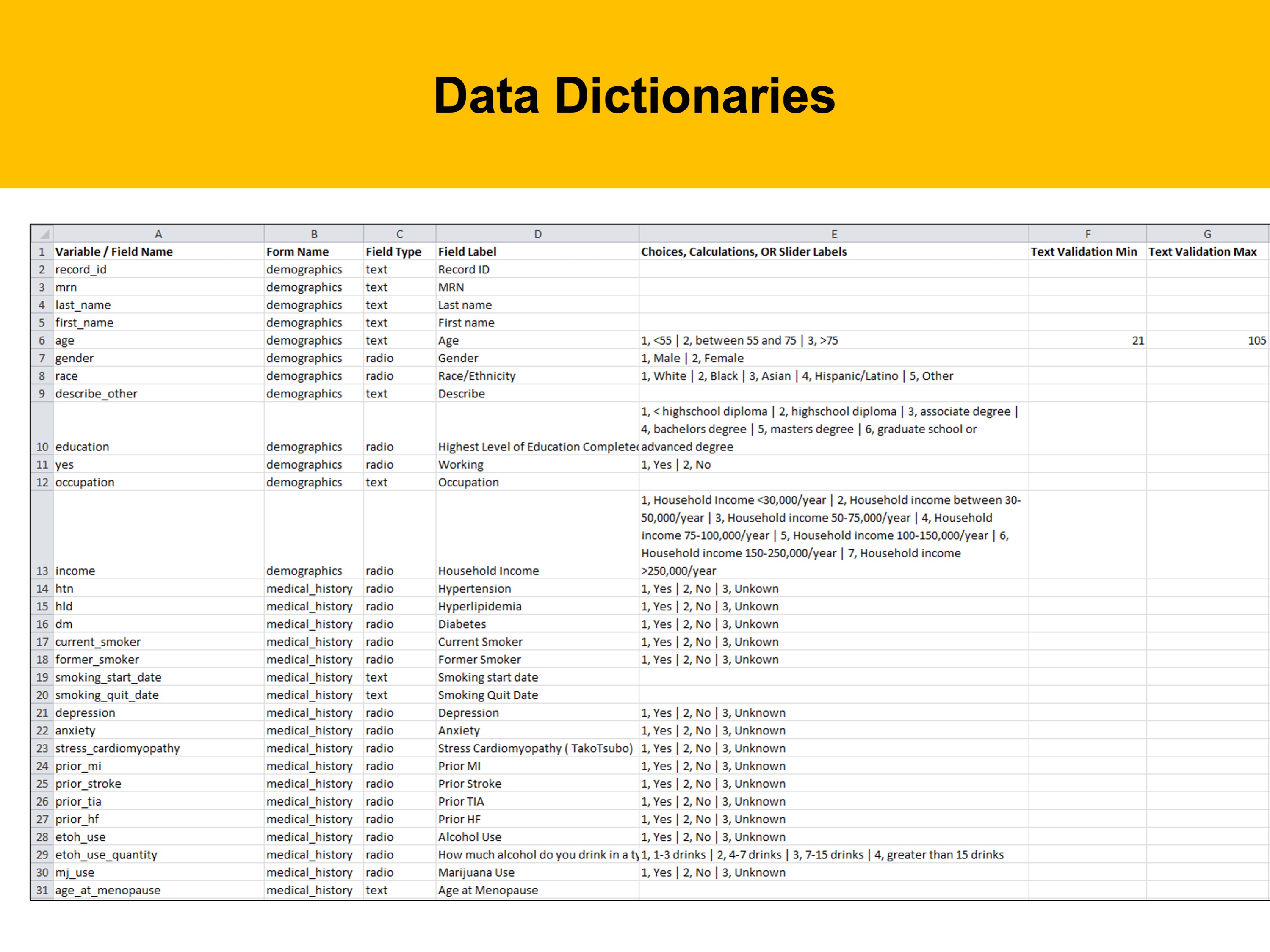 A theme we will come back to time and again is “documentation.” Good data management requires good documentation. A good practice is to document your variables in a data dictionary.
A theme we will come back to time and again is “documentation.” Good data management requires good documentation. A good practice is to document your variables in a data dictionary.
These can be invaluable in helping you communicate your research and ensuring that data is interpreted correctly. If you’ve ever worked with secondary data, you can probably appreciate the need for clear documentation. It makes it a whole lot easier to understand what the researcher intended.
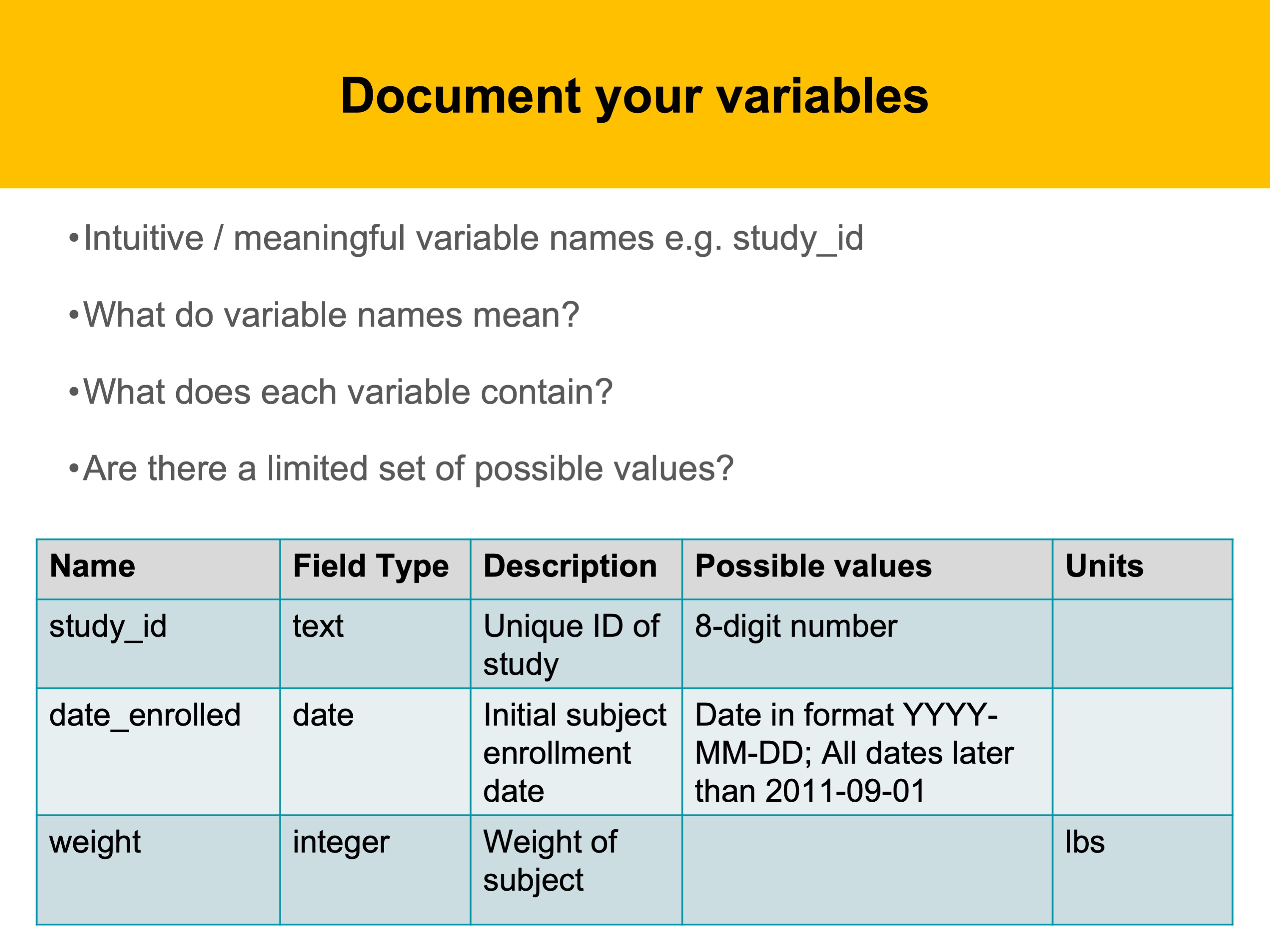
Let’s take a closer look at a data dictionary
A data dictionary should include
Variable labels (which should be intuitive and meaningful)) – a name that seems obvious now might be incomprehensible in a few months to yourself, let alone to someone new trying to interpret your data.
The type of data, such as date or integer (field type)
A clear, concise description of the variable
The units of measurement (pounds or kilos?)
If there are a restricted set of possible values, what are those values? Or is there a particular format the data needs to follow?