Chapter 15 Math for Probabilistic thinking
Motivating scenarios: We want to build on our intuitive feel for probability that we can build from simulation, by developing a mathematical framework and key rules to predict probabilistic outcomes.
Learning goals: By the end of this chapter you should be able to
- Add and subtract to calculate the probability of this OR that.
- Subtract to find the probability of NOT THIS.
- Multiply to calculate the probability of this AND that.
- Add up all the ways you can get this to find its probability.
- Use Bayes’ theorem to flip between “the probability of this given that” to “the probability of that given this.”
15.1 How to do probability – Math or simulation?
In the previous chapter we saw that we could get pretty deep into probability by simulation. In fact – everything we cover here could be discovered by simulation. This holds not only for these chapters, but for pretty much all of stats. Simulation provides us with a good intuition, every problem we cover this term could be exactly solved by simulation (while math requires numerous assumptions), and some situations can uniquely solve problems that do not have nice mathematical answers. I often wonder – “Why do we even use math?”
The major advantages of math over simulation are:

Math gives the same answers every time. Unlike random simulation, math is not influenced by chance, so (for example) a sampling error on our computer mean that the sampling distribution from simulation will differ slightly each time, while math based sampling distributions do not change by chance.
Math is fast. Simulations can take a bunch of computer time and energy (it has to do the same thing a bunch of times). With math, the computer quickly run some numbers through a calculator. The computational burdens we’ll face this term are pretty minimal, but with more complex stats this can actually matter.
Math provides insight. Simulations are great for helping us build feelings, intuition and even probabilities. But clear mathematical equations allow us to precisely see the relationship between components of our model.
In practice I often combine mathematical and simulation based approaches to my work.
Today we’ll work through the mathematical foundations of probability.
15.1.1 Probability Rules
I highly recommend a formal probability course would go through a bunch of ways to calculate probabilities of alternative outcomes (probability theory was my favorite class). But you don’t need all that here. We simply want to get an intuition for probability, which we can achieve by familiarizing ourselves with some straightforward rules and a bit of practice in math and simulation.
Internalizing the rough rules below will get you pretty far:
Add probabilities to find the probability of one outcome OR another. (be sure to subtract off double counting).
Multiply probabilities to find the probability of one outcome AND another. (be sure to consider conditional probabilities if outcomes are non-independent.)
OK – Let’s work through these rules.
Below, we talk about the probability of events a and b. These are generic events that can stand in for any random thing, so \(P(a)\) is the probability of some event a. So if a was red head, p(a) is the probability that a person is a red head.
I distinguish this from A, B, and C, which refer to balls dropping through colored bars in our visualizations.15.2 Add probabilities for OR statements
To find the probability or this or that we sum all the ways we can be this or that, being careful to avoid double-counting.
\[\begin{equation} \begin{split} P(a\text{ or }b) &= P(a) + P(b) - P(ab)\\ \end{split} \tag{15.1} \end{equation}\]
where P(ab) is the probability of outcomes a and b.
Special case of exclusive outcomes
If outcomes are mutually exclusive, the probability of outcome of both of them, p(ab) is zero, so the probability of a or b is
\[\begin{equation} \begin{split}P(a\text{ or }b | P(ab)=0) &= P(a) + P(b) - P(ab)\\ &= P(a) + P(b) - 0\\ &= P(a) + P(b) \end{split} \end{equation}\]
For example the probability that a random persons favorite color is orange OR green is:
Probability their favorite color is orange, P(Orange),
Plus the probability their favorite color is green, P(Green).
We often use this rule to find the probability of a range of outcomes for discrete variables (e.g. the probability that the sum of two dice rolls is between six and eight = P(6) + P(7) + P(8)).
General case
More generally, the probability of outcome a or b is P(a) + P(b) - P(a b) [Equation (15.1)]. This subtraction (which is irrelevant for exclusive events, because in that case \(P(ab) = 0\)) avoids double counting.
Why do we subtract P(a and b) from P(a) + P(b) to find P(a or b)? Figure 15.1 shows that this subtraction prevents double-counting – the sum of falling through A or B is \(0.50 + 0.75 = 1.25\). Since probabilities cannot exceed one, we know this is foolish – but we must subtract to avoid double counting even when the sum of probabilities do not exceed one.
 (gif on 6 second loop).](images/dontdoublecount.gif)
Figure 15.1: Subtract P(ab) to avoid double counting: Another example of probability example from Seeing Theory (gif on 6 second loop).
Following equation (15.1) and estimating that about 35% of balls falls through A and B, we find that
P(A or B) = P(A) + P(B) - P(AB)
P(A or B) = 0.50 + 0.75 - 0.35
P(A or B) = 0.90.
For a simple and concrete example, the probability a random student played soccer or ran track in high school, is the probability they played soccer plus the probability they ran track minus the probability they played soccer and ran track.
The probability of not
My favorite thing about probabilities is that they have to sum (or integrate) to one. This helps us be sure we laid out sample space right, and allows us to check our math. It also provides us with nice math tricks.
Because probabilities sum to one, the probability of “not a” equals 1 - the probability of a. This simple trick often makes hard problems a lot easier.
15.3 Multiply probabilities for AND statements
The probability of two types of events in an outcome e.g. the probability of a and b equals the probability of a times the probability of b conditional on a, which will also equal the probability of b times the probability of a conditional on b.
\[\begin{equation} \begin{split} P(ab) &= P(a) \times P(b|a)\\ & = P(b) \times P(a|b) \end{split} \tag{15.2} \end{equation}\]
Special cases of AND
If two outcomes are mutually exclusive, the probability of one conditional on the other is zero (\(P(b|a) = 0\)). So the probability of one given the other is zero (\(P(a) \times P(b|a) = P(a) \times 0 = 0\)).
If two outcomes are independent, the probability of one conditional on the other is simply its overall probability (\(P(b|a) = P(b)\)). So the probability of one given the other is the product of their overall probabilities zero (\(P(a) \times P(b|a) = P(a) \times P(b)\)).
)</span>.](images/PunnettSquare.png)
Figure 15.2: A Punnett Square is a classic example of indepndent probabilities (Image from the Oklahoma Science Project).
The Punnett square is a classic example of independent probabilities in genetics as the sperm genotype usually does not impact meiosis in eggs (but see my paper (Brandvain and Coop 2015) about exceptions and the consequences for fun). If we cross two heterozygotes, each transmits their recessive allele with probability \(1/2\), so the probability of being homozygous for the recessive allele when both parents are heterozygous is \(\frac{1}{2}\times \frac{1}{2} = \frac{1}{4}\).
The general cases of AND
The outcome of meiosis does not depend on who you mate with, but in much of the world context changes probabilities. When outcomes are nonexclusive, we find the probability of both a and b by multiplying the probability of a times the probability of b conditional on observing a, \(P(ab) =P(a) \times P(b|a)\) [Eq. (15.2)].
CONDITIONAL PROBABILITY VISUAL:
Let’s work through a visual example!

In the figure above
P(A) = 1/3,
P(B) = 2/3,
P(A|B) = 1/4, and
P(B|A) = 1/2.
Using Equation (15.2), we find the probability of A and B:
P(AB) = P(A) \(\times\) P(B|A) = P(A) = 1/3 \(\times\) 1/2 = 1/6.
Which is the same as
P(AB) = P(B) \(\times\) P(A| B) = 2/3 \(\times\) 1/4 = 2/12= 1/6.
We can see this visually in Figure 15.3:
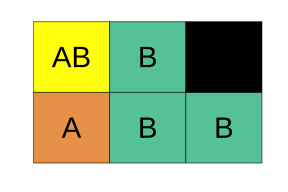
Figure 15.3: A representation of the relative probabilities of each outcome in sample space. Color denotes outcome (which is also noted with black letters), and each box represents a probability of one sixth.
CONDITIONAL PROBABILITY REAL WORLD EXAMPLE:
You are way less likely to get the flu if you get the flu vaccine.
So, what is the probability that a random person got a flu vaccine and got the flu?
First, we lay out some rough probabilities:
include_graphics("https://images.everydayhealth.com/images/no-flu-shot-and-now-you-have-the-flu-what-to-do-722x406.jpg?w=1110")
Every year, a little more than half of the population gets a flu vaccine, let us say P(No Vaccine) = 0.58.
About 30% of people who do not get the vaccine get the flu, P(Flu|No Vaccine) = 0.30.
The probability of getting the flu diminishes by about one-fourth among the vaccinated, P(Flu|Vaccine) = 0.075.
But we seem stuck, what is \(P(\text{Vaccine})\)? We can find this as \(1 - P(\text{no vaccine}) = 1 - 0.58 = 0.42\).
Now we find P(Flu and Vaccine) as P(Vaccine) x P(Flu | Vaccine) = 0.42 x 0.075 = 0.0315.
15.4 The law of total probability
Let’s say we wanted to know the probability that someone caught the flu. How do we find this?
We learned in Chapter 14 that the probability of all outcomes in sample space has to sum to one. Likewise, the probability of all ways to get some outcome have to sum to the probability of getting that outcome:
\[\begin{equation} P(b) = \sum P(a_i) \times P(b|a_i) \tag{15.3} \end{equation}\]
The \(\sum\) sign notes that we are going over all possible outcomes of \(a\), and the subscript, \(_i\), indexes these potential outcomes of \(a\). In plain language, we find probability of some outcome by
- Writing down all the ways we can get it,
- Finding the probability of each of these ways,
- Adding them all up.
So for our flu example, the probability of having the flu is the probability of being vaccinated and having the flu, plus the probability of not being vaccinated and catching the flu (NOTE: We don’t subtract anything off because they are mutually exclusive.). We can find each following the general multiplication principle (15.2):
\[\begin{equation} \begin{split} P(\text{Flu}) &= P(\text{Vaccine}) \times P(\text{Flu}|\text{Vaccine})\\ &\text{ }+ P(\text{No Vaccine}) \times P(\text{Flu}|\text{No Vaccine}) \\ &= 0.42 \times 0.075 + 0.58 \times 0.30\\ &= 0.0315 + 0.174\\ &= 0.2055 \end{split} \end{equation}\]
15.5 Probability trees
It can be hard to keep track of all of this. Probability trees are a tool we use to help. To make a probability tree, we
- Write down all potential outcomes for a, and use lines to show their probabilities.
- We then write down all potential outcomes for b separately for each potential a, and connect each a to these outcomes with a line denoting the conditional probabilities.
- Keep going for events c, d, etc…
- Multiply each value on path to get the probability of that path (The general multiplication rule, Equation (15.2)).
- Add up all paths that lead to the outcome you are interested in. (NOTE: Again, reach path is exclusive, so we don’t subtract anything.)
Here is a probability tree I drew for the flu example. Reassuringly the probability of getting the flu matches our math above.
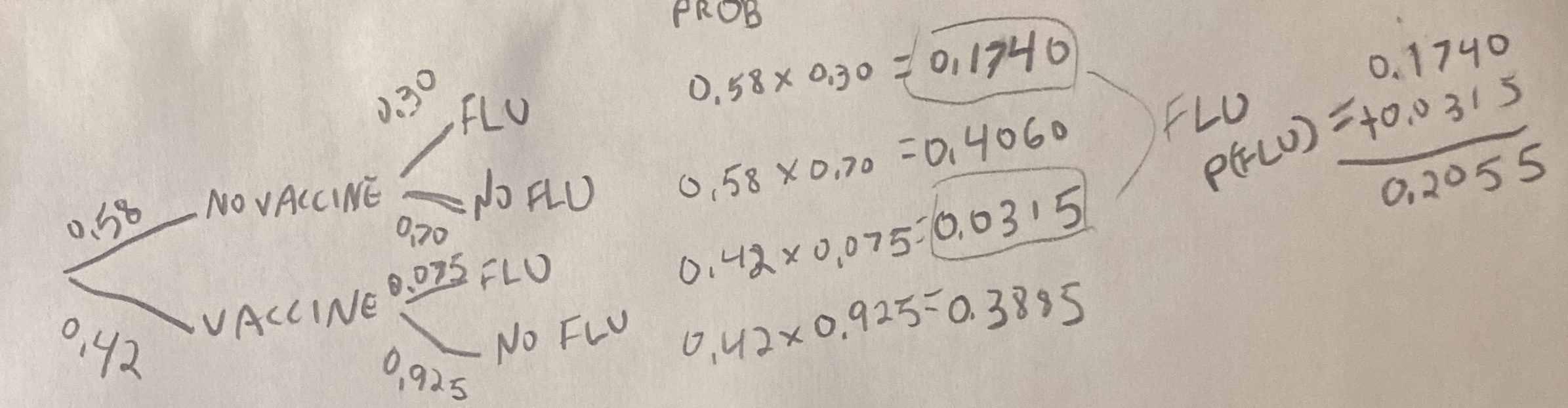
15.6 Flipping conditional probabilities
The probability that a vaccinated person gets the flu, P(Flu|Vaccine) is 0.075.
But what is the probability that someone who has the flu got vaccinated, P(Vaccine|Flu)?
We could follow our approach in Section 14.5.2.1, by simulating these conditional probabilities, counting, and dividing the number of people that had the flu and the vaccine by the number of people who had the flu. But we can basically do the same thing with math – the probability that someone who has the flu got vaccinated equals the probability that someone got the flu and was vaccinated, divided by the probability that someone has the flu.
\[\begin{equation} \begin{split} P(\text{Vaccine|Flu}) &= P(\text{Vaccine and Flu}) / P(\text{Flu}) \\ P(\text{Vaccine|Flu}) &= \tfrac{P(\text{Flu|Vaccine}) \times P(\text{Vaccine})}{P(\text{Vaccine}) \times P(\text{Flu}|\text{Vaccine}) + P(\text{No Vaccine}) \times P(\text{Flu}|\text{No Vaccine})}\\ P(\text{Vaccine|Flu}) &= 0.0315 / 0.2055 \\ P(\text{Vaccine|Flu}) &=0.1533 \end{split} \end{equation}\]
So, while the vaccinated make up 42% of the population, they only make up 15% of people who got the flu.
The numerator on the right hand side, \(P(\text{Vaccine and Flu})\), comes from the general multiplication rule (Eq. (15.2)).
The denominator on the right hand side, \(P(\text{Flu})\), comes from the law of total probability (Eq. (15.3)).
This is an application of Bayes’ theorem. Bayes’ theorem is a math trick which allows us to flip conditional probabilities as follows
\[\begin{equation} \begin{split} P(A|B) &= \frac{P(A\text{ and }B)}{P(B)}\\ P(A|B) &= \frac{P(B|A) \times P(A)}{P(B)} \end{split} \tag{15.4} \end{equation}\]
15.7 Simulation
Below, I simulate the process of vaccination and acquiring the flu to show that these math results make sense.
p_Vaccine <- 0.42
p_Flu_given_Vaccine <- 0.075
p_Flu_given_NoVaccine <- 0.300
n_inds <- 10000000
flu_sim <- tibble(vaccine = sample(c("Vaccinated","Not Vaccinated"),
prob =c(p_Vaccine, 1- p_Vaccine),
size = n_inds,
replace = TRUE )) %>%
group_by(vaccine) %>%
mutate(flu = case_when(vaccine == "Vaccinated" ~ sample(c("Flu","No Flu"),
size = n(),
replace = TRUE,
prob = c(p_Flu_given_Vaccine, 1 - p_Flu_given_Vaccine)),
vaccine != "Vaccinated" ~ sample(c("Flu","No Flu"),
size = n(),
replace = TRUE,
prob = c(p_Flu_given_NoVaccine, 1 - p_Flu_given_NoVaccine))
)) %>%
ungroup()Let’s browse the first 1000 values
Let’s find all the proportion of each combo
flu_sum <- flu_sim %>%
group_by(vaccine, flu, .drop = FALSE) %>%
summarise(sim_prop = n() / n_inds, .groups = "drop") Compare to predictions
precitions <- tibble(vaccine = c("Not Vaccinated", "Not Vaccinated", "Vaccinated", "Vaccinated"),
flu = c("Flu", "No Flu", "Flu", "No Flu"),
math_prob = c((1-p_Vaccine) * (p_Flu_given_NoVaccine) ,
(1-p_Vaccine) * (1- p_Flu_given_NoVaccine),
(p_Vaccine) * (p_Flu_given_Vaccine),
(p_Vaccine) * (1-p_Flu_given_Vaccine)))
full_join(flu_sum, precitions) ## Joining, by = c("vaccine", "flu")## [38;5;246m# A tibble: 4 x 4[39m
## vaccine flu sim_prop math_prob
## [3m[38;5;246m<chr>[39m[23m [3m[38;5;246m<chr>[39m[23m [3m[38;5;246m<dbl>[39m[23m [3m[38;5;246m<dbl>[39m[23m
## [38;5;250m1[39m Not Vaccinated Flu 0.174 0.174
## [38;5;250m2[39m Not Vaccinated No Flu 0.406 0.406
## [38;5;250m3[39m Vaccinated Flu 0.031[4m5[24m 0.031[4m5[24m
## [38;5;250m4[39m Vaccinated No Flu 0.389 0.388Now let’s check our flipping of conditional probabilities (aka Bayes’ theorem)
flu_sum %>%
filter(flu == "Flu") %>% # only looking at people with flu
mutate(prop_given_flu = sim_prop / sum(sim_prop))## [38;5;246m# A tibble: 2 x 4[39m
## vaccine flu sim_prop prop_given_flu
## [3m[38;5;246m<chr>[39m[23m [3m[38;5;246m<chr>[39m[23m [3m[38;5;246m<dbl>[39m[23m [3m[38;5;246m<dbl>[39m[23m
## [38;5;250m1[39m Not Vaccinated Flu 0.174 0.846
## [38;5;250m2[39m Vaccinated Flu 0.031[4m5[24m 0.154This is basically what we got by math in section 15.6.
15.8 Probabilitic maths: Quiz
Go through all “Topics” in the learnR tutorial, below. Nearly identical will be homework on canvas.