Chapter 27 Predicting one continuous variable from another
Motivating scenarios: We are interested in predicting one continuous variable based on the value of another, and to estimate the uncertainty and significance of this prediction.
Learning goals: By the end of this chapter you should be able to
- Use a regression equation to predict the value of a continuous response variable from a continuous explanatory variable.
- Explain the criteria for finding the line of “best” fit.
- Use equations to find the line of “best” fit.
- Use equations to find the line of “best” fit.
- Calculate t values for the slope, estimate uncertainty in them, and test the null hypothesis that this differs from zero.
- Make a linear regression and analyze it with the
lm(),summary.lm(), andanova()functions in R.
- Calculate sums of squares for a linear regression to calculate F and test the null hypothesis.
- Recognize the assumptions and limitations of linear regression.
27.1 Setup and review
27.1.1 The dataset
How do snakes heat up when they eat? To find out, Tattersall et al. (2004) noted the temperature of snakes as a function of their prey size (Fig. 27.1).
The prey size of the \(X\) axis of Figure 27.1C is in units of percent of a snake’s body weight, and the temperature on the Y axis of Figure 27.1C, is the degrees Celcius increase in a snake’s body temperature two days after eating.
![Infrared thermal image of a rattlesnake (**A**) before feeding and (**B**) two days after eating 32% of its body mass, **C** shows the association between meal size and change in temperature. images **A**, and **B**, and data from [[@tattersall2004]](https://jeb.biologists.org/content/207/4/579). data [here](https://whitlockschluter3e.zoology.ubc.ca/Data/chapter17/chap17q11RattlesnakeDigestion.csv).](https://jeb.biologists.org/content/jexbio/207/4/579/F2.large.jpg?width=800&height=600&carousel=1)
![Infrared thermal image of a rattlesnake (**A**) before feeding and (**B**) two days after eating 32% of its body mass, **C** shows the association between meal size and change in temperature. images **A**, and **B**, and data from [[@tattersall2004]](https://jeb.biologists.org/content/207/4/579). data [here](https://whitlockschluter3e.zoology.ubc.ca/Data/chapter17/chap17q11RattlesnakeDigestion.csv).](Applied-Biostats_files/figure-html/snakeregression-2.png)
Figure 27.1: Infrared thermal image of a rattlesnake (A) before feeding and (B) two days after eating 32% of its body mass, C shows the association between meal size and change in temperature. images A, and B, and data from (Tattersall et al. 2004). data here.
27.1.2 Review
In Chapter 18 we summarized the association between two continuous variables as the covariance and the correlation.
The covariance quantifies the shared deviation of X and Y from the mean as follows: \(Cov_{X,Y} =\frac{\sum{\Big((X_i-\overline{X}) (Y_i-\overline{Y})\Big)}}{n-1}\), where the numerator, \(\sum{\Big((X_i-\overline{X}) (Y_i-\overline{Y})\Big)}\) is called the “Sum of Cross Products.”
The correlation, standardizes the covariance by dividing through by the product of the standard deviations in X and Y, \(s_X\) and \(s_Y\), respectively, and is noted by \(r\). So the correlation between X and Y is equal to \(r_{X,Y} = \frac{Cov_{X,Y}}{s_X s_Y}\).
For our snake data, we calculate these with math or by using the cor and cov functions in R:
snake_data %>%
summarise(n = n(),
sum_xprod = sum((meal_size - mean(meal_size)) *(body_temp - mean(body_temp))),
cov_math = sum_xprod / (n - 1),
cov_r = cov(meal_size, body_temp),
cor_math = cov_math / (sd(meal_size) * sd(body_temp)),
cor_r = cor(meal_size, body_temp)) %>% kable(digits = 4)#DT::datatable()%>%formatRound(columns=c('cov_math', 'cov_r','cor_math', 'cor_r'), digits=c(4,4))| n | sum_xprod | cov_math | cov_r | cor_math | cor_r |
|---|---|---|---|---|---|
| 17 | 84.42 | 5.2762 | 5.2762 | 0.8989 | 0.8989 |
27.2 The regression as a linear model
In Chapter 24, we saw that we predict the value of a response variable for the \(i^{th}\) individual in our sample, \(\hat{Y_i}\) as a function of its values of explanatory variables as follows \(\hat{Y_i} = a + b_1 y_{1,i} + b_2 y_{2,i} + \dots{}\), and the individual’s actual value, \(Y_i\) is \(Y_i = \hat{Y_i} + e_i\), where \(a\) is the “intercept,” and \(e_i\) is the “residual” – the difference between observed, \(Y_i\), and predicted, \(\hat{Y_i}\), values.
So for a simple linear regression with one explanatory and one response varaible,
\[\begin{equation} \begin{split} Y_i &= a + b x_{i} \end{split} \tag{27.1} \end{equation}\]
Where
- \(a\) is the intercept,
- \(b\) is the slope, and
- \(X_i\) is the \(i^{th}\) individual’s observed value for the explanatory variable, \(X\)
27.2.1 Finding the “line of best fit”
We could draw lots of lines through the points in 27.1C, leading to a bunch of different values in Equation (27.1). How do we pick the best?
Statisticians have decided that the best line is the one that minimizes the sums of squared residuals. In the parlance of machine learning, the sums of squares residual is the “objective function,” where our objective is to minimize it. We visualize this concept in Figure 27.2, which shows that the best line has an intercept, \(a\) near 0.32 and a slope, \(b\) of about 0.0274.
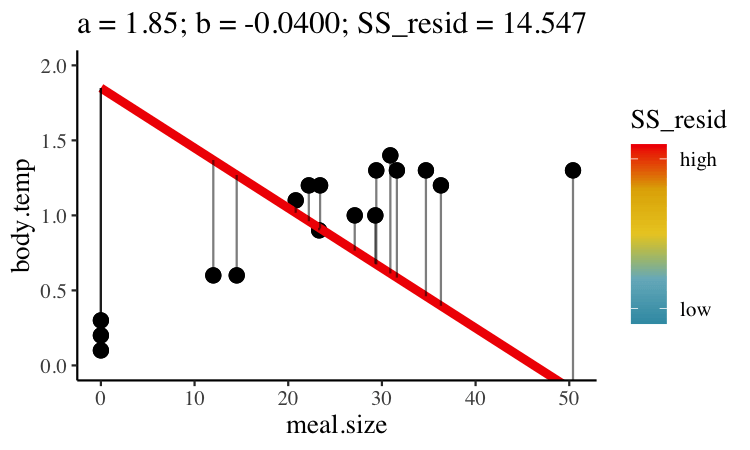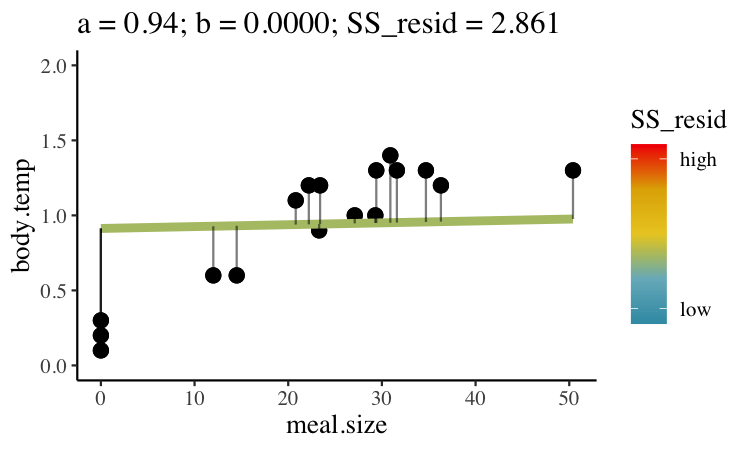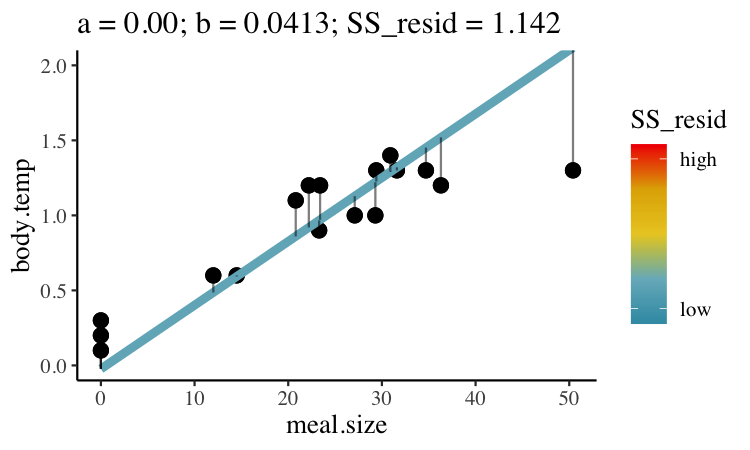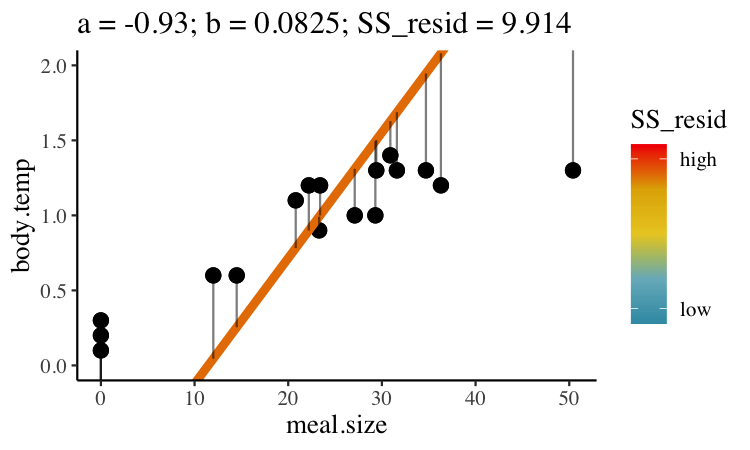
Figure 27.2: Minimizing the sums of squares residual. We could loop over a bunch of potential slopes and intercepts, and find the one that minimizes the sum of the squared lengths of the black lines connecting predictions (dots) to observations (lines). Color shows the residual sums of squares from high (red), to low (blue).
27.3 Estimation for a linear regression
We could just jam through all combinations of slope, \(b\), and intercept, \(a\), calculate the sums of squares of the residuals of each point given our choices of \(a\) and \(b\), such that \(ss_{resid}|a,b = \sum(e_i^2|{a,b}) = \sum(Y_i - \widehat{Y_i})^2\), and find the combinations of slope and intercept that minimize this equation.
BUT mathematicians have found equations that find values for the slope and intercept that minimize the residual sums of squares, so we don’t need to do all that.
27.3.1 Estimating the slope of the best fit line
Recall that the covariance and correlation describe how reliably the response variable, Y, changes with the explanatory variable, X, but do not describe how much Y changes with** X. Our goal is to find \(b\) the slope which minimizes the sums of squares residual.
The regression coefficient (aka the slope, b), describes how much Y changes with each change in X. The true population parameter for the slope, \(\beta\) equals the population covariance standardized by the variance in \(X\), \(\sigma^2_x\). We estimate this parameter with the sample correlation, \(b\), in which we divide the sample covariance by the sample variance in X, \(s^2_X\).
\[\begin{equation} \begin{split} b = \frac{Cov(X,Y)}{s^2_X}\\ \end{split} \tag{27.2} \end{equation}\]
There are two points to remember
- You will get a different slope depending on which variable is \(X\) & which is \(Y\). Unlike the covariance and correlation, for which \(X\) and \(Y\) are interchangeable.
- It’s possible to have a large correlation and a small slope and vice-versa.
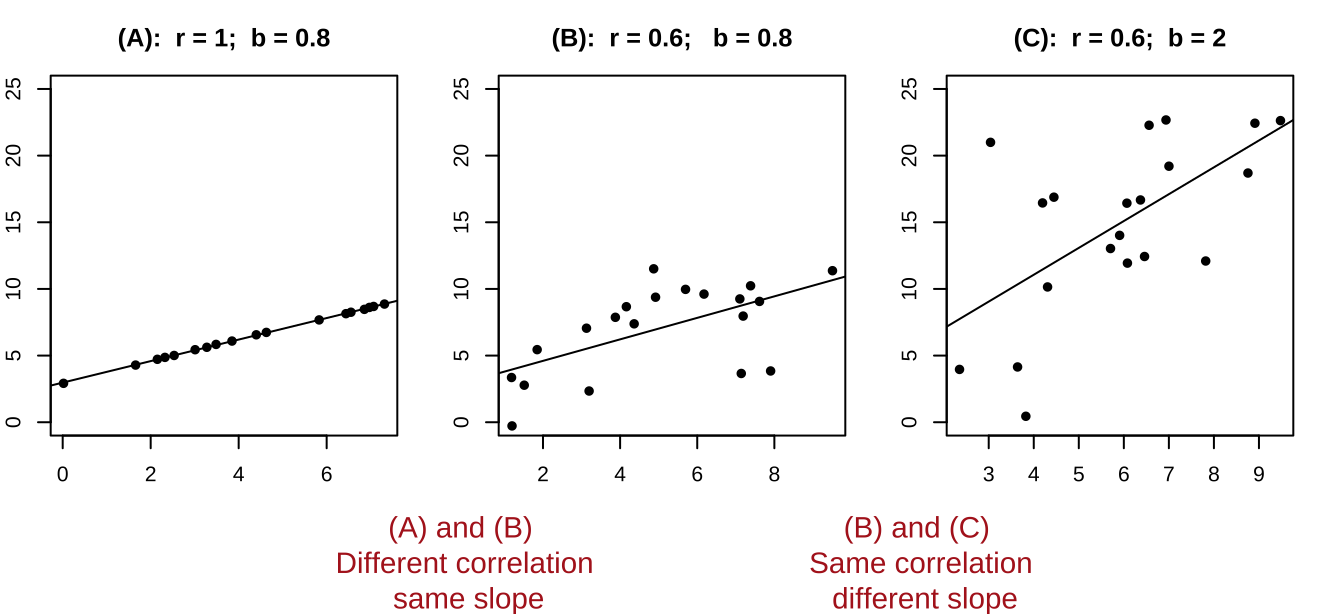
Figure 27.3: A smaller correlation can have a larger slope and vie versa.
27.3.2 Estimating the intercept of the best fit line
The true population intercept – the value the response variable would take if we follwoed the slope line all the way to zero – is \(\alpha\). We estimate the intercept as \(a\) from our sample as follows
\[\begin{equation} \begin{split} a = \overline{Y} - b \times \overline{X} \\ \end{split} \tag{27.3} \end{equation}\]
So we can estimate the slope and intercept in R by implementing equations (27.2), and (27.3) as follows
snake_data %>%
summarise(slope = cov(meal_size, body_temp ) / var(meal_size),
intercept = mean(body_temp) - slope * mean(meal_size)) %>% kable(digits = 4)| slope | intercept |
|---|---|
| 0.0274 | 0.3196 |
This means that in this study, a snakes temperature increases, on average, by 0.0274 degrees Celsius for every increase in meal size (measured as percent of a snake’s mass) in addition to the increase in temperature of 0.32 degrees Celsius, on average, that all snakes experienced, regardless of their meal size.
27.3.3 Fitting a linear regression with the lm() function.
Like the other linear models we’ve seen (e.g. t and ANOVA) we can fit a linear regression with the lm() function like this lm(<response> ~ <explanatory>, data = <data>). Doing this for our snake_data shows that we did not mess up our math.
snake_lm <- lm( body_temp ~ meal_size, data = snake_data)
coef(snake_lm)## (Intercept) meal_size
## 0.31955925 0.0273840227.4 Hypothesis testing and uncertainty for the slope
So we can estimate a slope, but how do we describe our uncertainty in it and test the null hypothesis that it equals zero?
Well, we find a t-value as the slope minus its null value (usually zero) and divide this by its standard error and then do our standard stuff!
27.4.1 The standard error of the slope
We know that we are estimate the true population slope, \(\beta\) from our sample as \(b\). How do we think about uncertainty in this estimate? Like usual we quantify this as the standard error, as follows, by imagining we
- Take a sample of size n from the true population with a slope equal to \(\beta\),
- Estimate \(\beta\) from our sample as \(b\),
- Repeated 1 and 2 many times
- Calculate the standard deviation of this sampling distribution, as the standard error of our estimate
As usual, we can estimate the bootstrap standard error by resampling from our data many times with replacement, which assumes our sample is large enough to represent the population
rep_sample_n(snake_data, size = nrow(snake_data), replace = TRUE, reps = 10000) %>%
summarise(b_boot = cov(meal_size, body_temp) / var(meal_size) ) %>%
summarise(boot_se = sd(b_boot)) %>% kable(digits = 4)| boot_se |
|---|
| 0.0048 |
Alternatively we can estimate the standard error mathematically, which may be preferable for this modest sample size, following equation (27.4):
\[\begin{equation} \begin{split} SE_b &= \sqrt{\frac{MS_{resid}}{\sum(X_i-\overline{X})^2}} = \sqrt{\frac{e_i^2 / df_{b}}{\sum(X_i-\overline{X})^2}} = \sqrt{\frac{\sum(Y_i-\widehat{Y_i})^2 / (n-2) }{\sum(X_i-\overline{X})^2}} \\ \end{split} \tag{27.4} \end{equation}\]
Where \(df_b\) is the degrees of freedom for the slope, which equals the sample size minus two (one for the slope, and one for the intercept).
Equation (27.4) might look, at first blush, a bit different than most equations for the standard error we’ve seen before, but it actually is pretty familiar. The numerator i the difference between an observations and its mean value (conditional, on X, which is a good way to think of \(\widehat{Y_i}\)) divided by the degrees of freedom, which is basically the sample variance in the residuals. We estimate the standard error of the slope by taking the square root of this variance, after dividing through by the sum of square in our predictor X.
27.4.2 Confidence intervals and null hypothesis significance testing
The P-value is the probability that a sample from the null distribution is as or more extreme than what we see. We find this by using pt(q = abs(<our_t>), df = <our_df>, lower.tail = FALSE) to find this area on one side of the null sampling distribution, and multiplying this by two to capture both sides.
We find the \(100 \times (1-\alpha)\%\) confidence interval as \(b\pm se_b \times t_{crit, \alpha/2,df}\). Remember that \(t_{crit, \alpha/2,df}\) is the value of t for which differentiates the upper \(\alpha/2\) of the null sampling distribution frmo the rest. We find \(t_{crit}\) by using pt(q = abs(<our_t>), df = <our_df>, lower.tail = FALSE).
27.4.3 Putting this all together
We can calculate the standard error by implementing Equation (27.4) in R, and then calculating the \(t\) value, confidence intervals and uncertainty. I can think of a bunch of ways to implement Equation (27.4) – let’s start pretty explicitly to help solidify these steps
snake_data %>%
mutate(predicted_temp = coef(snake_lm)["(Intercept)"]+ # find intercept
coef(snake_lm)["meal_size"] * meal_size, # add slope times meal size
resid_tmp_sqrd = (body_temp - predicted_temp)^2) %>% # find squared differnce between predictions and observations.
summarise(b = cov(meal_size, body_temp) / var(meal_size),# find slopw
#
df = n() - 2, # find degrees of freedom
MS_resid = sum(resid_tmp_sqrd) / df,
#
se = sqrt(MS_resid / sum((meal_size -mean(meal_size))^2) ),
t_crit = qt(0.05/2,df = df, lower.tail = FALSE),
lwr_95 = b - t_crit * se,
upr_95 = b + t_crit * se,
#
t_value = b / se,
p_value = 2 * pt(q = abs(t_value), df = df, lower.tail = FALSE)) %>% mutate(p_value = paste(round(p_value* 10^7,digits = 1),"x10^-7",sep= "")) %>% kable( digits=4)# DT::datatable()%>% formatRound(columns=c('b', 'MS_resid','se','t_crit','t_crit','lwr_95', 'upr_95','t_value' ), digits=4)| b | df | MS_resid | se | t_crit | lwr_95 | upr_95 | t_value | p_value |
|---|---|---|---|---|---|---|---|---|
| 0.0274 | 15 | 0.0366 | 0.0034 | 2.1314 | 0.02 | 0.0347 | 7.9445 | 9.4x10^-7 |
More simply, we could use the augment() function in the broom package, to calculate our residuals making this all easier
augment(snake_lm) %>%
summarise(MS_resid = sum(.resid^2) / (n()-2),
se = sqrt(MS_resid / sum((meal_size -mean(meal_size))^2) )) %>% kable(digits = 4)| MS_resid | se |
|---|---|
| 0.0366 | 0.0034 |
Or we could skip the calculations all together
summary.lm(snake_lm)##
## Call:
## lm(formula = body_temp ~ meal_size, data = snake_data)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.39971 -0.11663 -0.04817 0.17535 0.27252
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.319559 0.090977 3.513 0.00314 **
## meal_size 0.027384 0.003447 7.944 9.38e-07 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.1914 on 15 degrees of freedom
## Multiple R-squared: 0.808, Adjusted R-squared: 0.7952
## F-statistic: 63.11 on 1 and 15 DF, p-value: 9.381e-07No matter how we do this, we estimate an increase 0f 0.0274 (se = 0.00345, 95% confidence interval from 0.0200 to 0.0347) degrees Celsius with each percent increase in size of meal (measured in percentage of snake’s biomass), on top of the 0.320 increase in temperature experience over the experiment regardless of meal size. This strong of a relationship is an exceptionally unlikely outcome of the null model (t = 7.944, p < \(10^{-6}\), df = 15), so we reject the null model and conclude that snake body temperature increases with meal size.
27.5 Uncertainty in predictions
We think of the line of a regression as “Predicting” the value of the response variable, given the value of the explanatory variable, \(\widehat{Y_i}\). What does this mean? Well it’s our estimate of the prediction for the population mean value of Y, given it had this value of X Figure 27.4)A.
We can acknowledge the uncertainty in this prediction by including a standard error on our regression line as in Figure 27.4)B.
But this is a prediction for the expected mean \(\widehat{Y_i}\), we might want bands to predict the range of 95% of observations. This is called the prediction interval and is presented in maroon in figure 27.4)C.
a <- ggplot(snake_data, aes(x = meal_size, y = body_temp)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE)+
labs(title = "regression")
b <- ggplot(snake_data, aes(x = meal_size, y = body_temp)) +
geom_point() +
geom_smooth(method="lm")+
labs(title = "95% confidence interval")
c <- bind_cols(snake_lm %>% augment(),
snake_lm %>% predict(interval = "predict") %>% data.frame()) %>% # ger prediction intervals
ggplot(aes(x = meal_size, y = body_temp)) +
geom_ribbon(aes(ymin = lwr, ymax = upr), fill = "maroon", alpha = .7) +
geom_point() +
geom_smooth(method=lm, se = FALSE, col = "yellow") +
labs(title = "95% prediction interval")## Warning in predict.lm(., interval = "predict"): predictions on current data refer to _future_ responsesplot_grid(a,b,c, labels = c("a","b","c"), ncol = 3)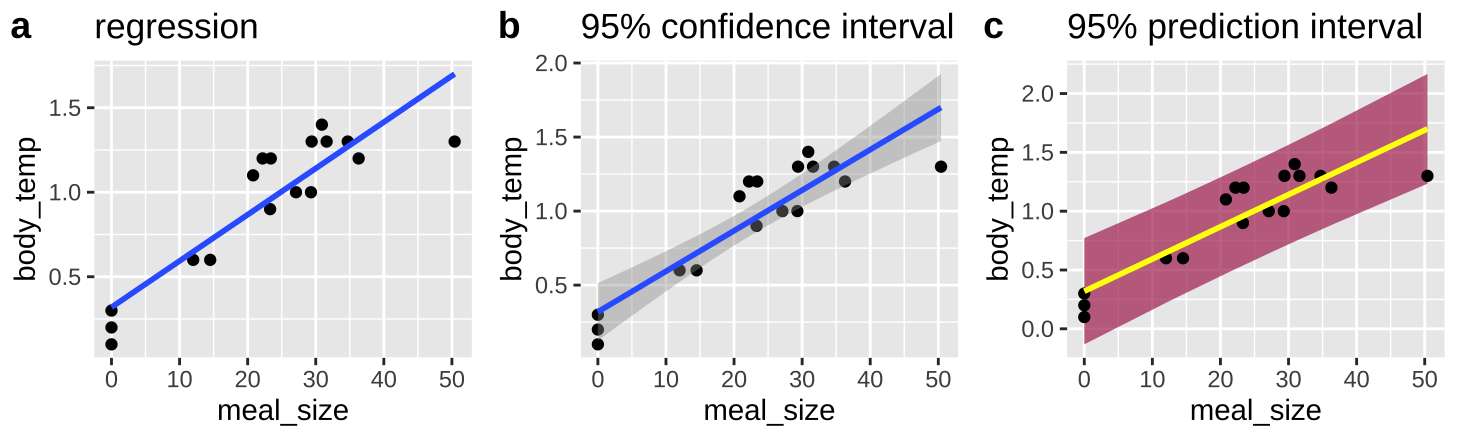
Figure 27.4: Predictions from a linear regression (lines). B Shows our uncertainty in the predicted value, \(\widehat{Y_i}\), as the 95% confidence interval. C Shows the expected variability in observations, as capture by the 95% prediction interval
No need to know the equations underlying these – just know (1) they exist, (2) they are different (3) The prediction interval is always wider than the confidence interval (4) the different goals of each
27.6 A linear regression as an ANOVA
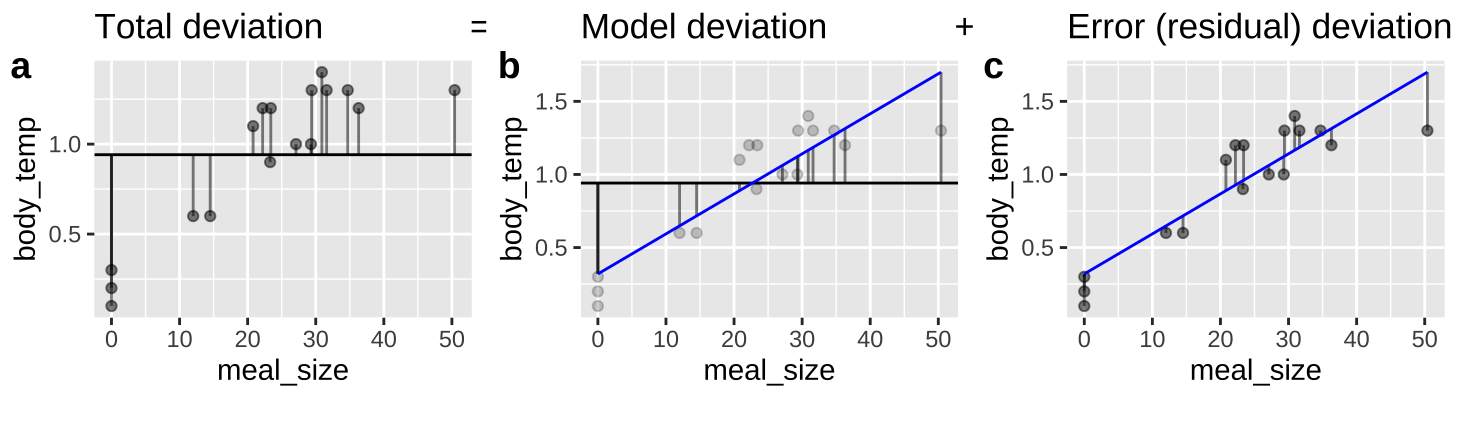
Figure 27.5: An ANOVA framework for a linear regression. A Shows the difference between each observation, \(Y_i\), and the mean, \(\overline{Y}\). This is the basis for calculating \(MS_{total}\). B Shows the difference between each predicted value \(\widehat{Y_i}\) and the mean, \(\overline{Y}\). This is the basis for calculating \(MS_{model}\). C Shows the difference between each observation, \(Y_i\), and its predicted value \(\widehat{Y_i}\). This is the basis for calculating \(MS_{error}\).
We can envision a linear regression as an ANOVA (Figure 27.5), in which we partition variance much like we did in Chapter 26 (Compare Figures 26.2 and 27.5).
All concepts are the same (\(SS_{total}\) describes the distance between observations and the mean, \(SS_{model}\) describes the distance between predictions and the mean, and \(SS_{error}\) describes the distance between observations and predictions), but the mathematical notation is a bit different. Here,
- \(SS_{total}=\sum(Y_i - \overline{Y})^2\)
- \(SS_{model}=\sum(\widehat{Y_i} - \overline{Y})^2\)
- \(SS_{error}=\sum(Y_i - \widehat{Y_i})^2\)
- \(MS_{model}= SS_{model} / df_{model}\)
- \(MS_{error}= SS_{error} / df_{error}\)
- \(df_{model}= 1\)
- \(df_{error}= n - 2\)
- \(F = \frac{MS_{model}}{MS_{error}}\)
augment(snake_lm) %>%
summarise(ss_total = sum((body_temp - mean(body_temp))^2) ,
ss_model = sum((.fitted - mean(body_temp))^2),
ss_error = sum((body_temp - .fitted)^2),
r2 = ss_model / ss_total,
#
df_model = 1,
df_error = n()-2,
#
ms_model = ss_model / df_model,
ms_error = ss_error / df_error,
F_val = ms_model/ ms_error,
p_value = pf(F_val, df1 = df_model, df2 = df_error, lower.tail = FALSE)) %>% dplyr::select(- df_model, -df_error) %>% mutate(p_value = paste(round(p_value* 10^7,digits = 1),"x10^-7",sep= "")) %>% kable( digits=4)| ss_total | ss_model | ss_error | r2 | ms_model | ms_error | F_val | p_value |
|---|---|---|---|---|---|---|---|
| 2.8612 | 2.3118 | 0.5494 | 0.808 | 2.3118 | 0.0366 | 63.1148 | 9.4x10^-7 |
Or with the anova function
anova(snake_lm)## Analysis of Variance Table
##
## Response: body_temp
## Df Sum Sq Mean Sq F value Pr(>F)
## meal_size 1 2.31176 2.31176 63.115 9.381e-07 ***
## Residuals 15 0.54942 0.03663
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 127.6.1 The squared correlation and the proportion variance explained
In Chapter 26, we called \(r^2 = ss_{model} / ss_{total}\) “the proportion variance explained.” In this example we found \(r^2 =2.3118 / 2.8612 = 0.808\).
In Chapter 18 we defined the correlation, \(r\) as \(\frac{Cov_{X,Y}}{s_X s_Y}\), which equals 0.8989, and note that \(0.8989^2 =0.808\).
So we can calculate the proportion variance explained a either \(r^2 = ss_{model} / ss_{total}\) or \(r^2 = \big(\frac{Cov_{X,Y}}{s_X s_Y}\big)^2\), they are equivalent!!
27.7 Caveats and considerations for linear regression
Linear regression is a super useful tool. So it’s important to recognize its limitations before gettting carried away!!!
27.7.1 Effect of measurement error on estimated slopes
We rarely measure all values of X and Y perfectly. In Chapter 18, we saw that measurement error in X and/or Y brought our estimated correlation closer to zero.
How does measurement error impacts the estimate o the slope?
Measurement error in \(X\) increases BOTH the variance of residuals and biases the slope closer to zero and away from its true value.
By contrast, measurement error in \(Y\) does not reliably increase or decrease our estimate of the slope – but it will tend to increase the standard error, the variance of residuals and the p-value.
27.7.1.1 Attenuation demonstration for slopes
Don’t take my word for the reality of attenuation - let’s simulate it! Let’s take our snake data set with an actual slope of, rround(coef(snake_lm)[2], digits = 4), and pretend this is a real population.
Now, let’s use the jitter() function to add
- Random noise in \(X\),
meal_size.
- Random noise in \(Y\),
body_temp
- Random noise in both variables,
And compare our estimated slop in these noisier estimates to our initial estimate of the correlation. To do so, let’s first copy our initial data set a bunch on times with the rep_sample_n() function in the infer package. In both cases let’s add a standard deviation’s random noise
n_reps <- 10000
many_snakes <- snake_data %>%
rep_sample_n(size = nrow(snake_data), replace = FALSE, reps = n_reps)
noisy_x <- many_snakes %>%
mutate(meal_size = jitter(meal_size, amount = sd(meal_size) )) %>%
summarise(est_slope = cov(meal_size, body_temp) / var(meal_size)) %>%
mutate(noisy = "x")
noisy_y <- many_snakes %>%
mutate(body_temp = jitter(body_temp, amount = sd(body_temp) )) %>%
summarise(est_slope = cov(meal_size, body_temp) / var(meal_size)) %>%
mutate(noisy = "y")
noisy_xy <- many_snakes %>%
mutate(body_temp = jitter(body_temp, amount = sd(body_temp) ),
meal_size = jitter(meal_size, amount = sd(meal_size) ),) %>%
summarise(est_slope = cov(meal_size, body_temp) / var(meal_size)) %>%
mutate(noisy = "xy")
### Make a plot
bind_rows(noisy_x, noisy_y, noisy_xy) %>%
mutate(noisy = fct_reorder(noisy, est_slope)) %>%
ggplot(aes(x = est_slope , fill = noisy)) +
facet_wrap(~noisy, labeller = "label_both", ncol = 3) +
geom_density(show.legend = FALSE) +
geom_vline(xintercept = summarise(snake_data, cov(meal_size, body_temp) / var(meal_size))%>% pull() ) +
geom_vline(data = . %>% group_by(noisy) %>% summarise(est_slope = mean(est_slope)),
aes(xintercept = est_slope), color = "white")+
annotate(x = summarise(snake_data, cov(meal_size, body_temp) / var(meal_size) )%>% pull() ,
y = 200, label = "slope in data", geom = "text", hjust = -0.1, size=2.5)+
geom_label(data = . %>% group_by(noisy) %>% summarise(est_slope = mean(est_slope)),
aes(y=200),label = "Avg. noisy slope", hjust = 1, size=2.5, color = "white", show.legend = FALSE)+
scale_y_continuous(limits = c(0,250))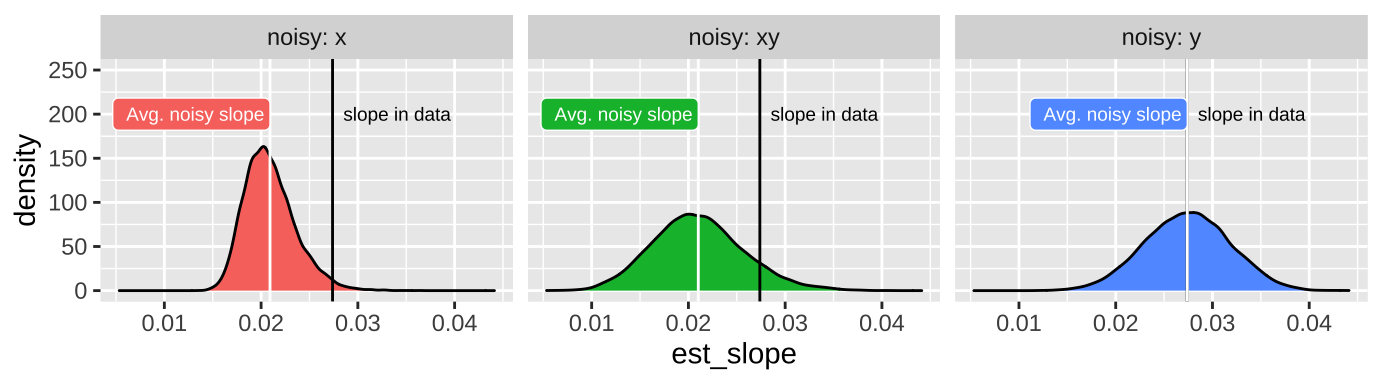
27.7.2 Be warry of extrapolation
Det er vanskeligt at spaa, især naar det gælder Fremtiden.
It is difficult to predict, especially when it comes to the future.
This quote is a great encapsulation of the major challenges in regression. The power of this quote is clear as it has been incorrectly attributed to some of our most famous folk philosophers (e.g. Niels Bohr, Yogi Berra, Mark Twain and Nostradamus). An example of the phenomenon that “famous things that are said../ no matter who they’re said by, they tend to gravitate to being attributed to even more famous people.” (Grant Barrett on The Origins of Oranges and Door Hinges episode of Under Understood).
It is difficult to predict from a linear regression, especially when it comes to data outside the range of the model.
In addition to the standard caveats about uncertainty, bias, nonindependence and model assumptions etc… Predictions from a linear model are only good for similar conditions across the range of values of the explanatory variable used to generate the model.

27.7.2.1 Be warry of extrapolation: Example
Species X Area relationship: How does the number of fish species change with pool area? Data for small pools from Kodric-Brown and Brown (1993) are presented in Figure 27.6A. From this we fit the following linear model \(\text{# species} = 1.79 + 3.55 \times 10^{-4} m^2\). By extrapolation, we predict \(\approx 20\) fish species in a \(50000\) \(m^2\) pool (Figure 27.6B). We see from additional data that this is a terrible prediction (Figure 27.6C).
](Applied-Biostats_files/figure-html/dontextrap-1.png)
Figure 27.6: Be warry of extrapolation. A regression fits the data from small pools quite well (A). Extrapolation to larger pools (B), poorly predicts diversity in large ponds (C). Data from Kodric-Brown and Brown (1993) are available here
- Number of fish species is POORLY predicted by linear exptrapolation of the area of a desert pool!
- The regression from the small lakes does not do a good job of predicting our observations for larger lakes.
- Lesson: Do not extrapolate from your model – predictions are only valid within the range of X that data came from.
27.8 Asumptions of linear regression and what to do when they are violated
27.8.1 Assumptions of linear regression
Recall from Section 24.5, a linear model assumes.
- Linearity: That is to say that our observations are appropriately modeled by adding up all predictions in our equation. We can evaluate this by seeing that residuals are independent of predictors.
- Homoscedasticity: The variance of residuals is independent of the predicted value, \(\hat{Y_i}\) is the same for any value of X.
- Independence: Observations are independent of each other (aside from the predictors in the model).
- Normality: That residual values are normally distributed.
- Data are collected without bias as usual.
As usual, we can evaluate the assumptions of normality of residuals and the independence of predicted values, \(\widehat{Y_i}\) and residuals, \(e_i\) with the autoplot() function in the ggfortify package.
library(ggfortify)
autoplot(snake_lm, which = c(2,1,3), ncol = 3)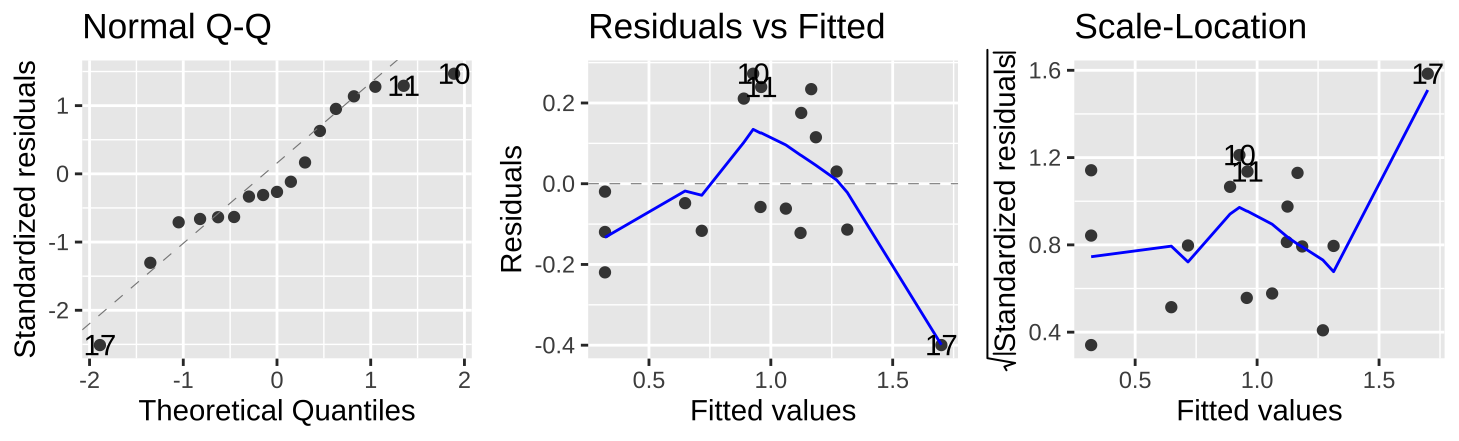
Figure 27.7: Evaluating the normality of residuals (in the QQ plot), and if their values (Residual v Fitted plot) or variance (Scale-Location plot) are indepedent of their predictd values, \(\widehat{Y_i}\).
Figure 27.7 show that the assumptions seem to be met– with the caveat that the observed value of the largest prediction \(Y_{17} = 1.3\) is substantially smaller than its predicted value, \(\widehat{Y_{17}} = 1.70\).
27.8.2 When assumptions aren’t met
If we fail to meet assumptions, we have a few options
- Ignore violations if minor
- Nonparameteric approaches - For example, we can rank all values of x and y, calculate a correlation of these ranks, and look up how weird it would be to obtain an estimate as or more extreme than ours from the null sampling distribution. A technique known as “Spearman’s Rank correlation”.
- Transform
- Build a better model
27.8.2.1 Transformation Example
When data fail to meet test assumptions, an appropriate transformation not only meets the assumptions, but also often identifies a more meaningful model, and natural scale.
For example, returning to the full data from Kodric-Brown and Brown (1993) about the association between pond size and species diversity.
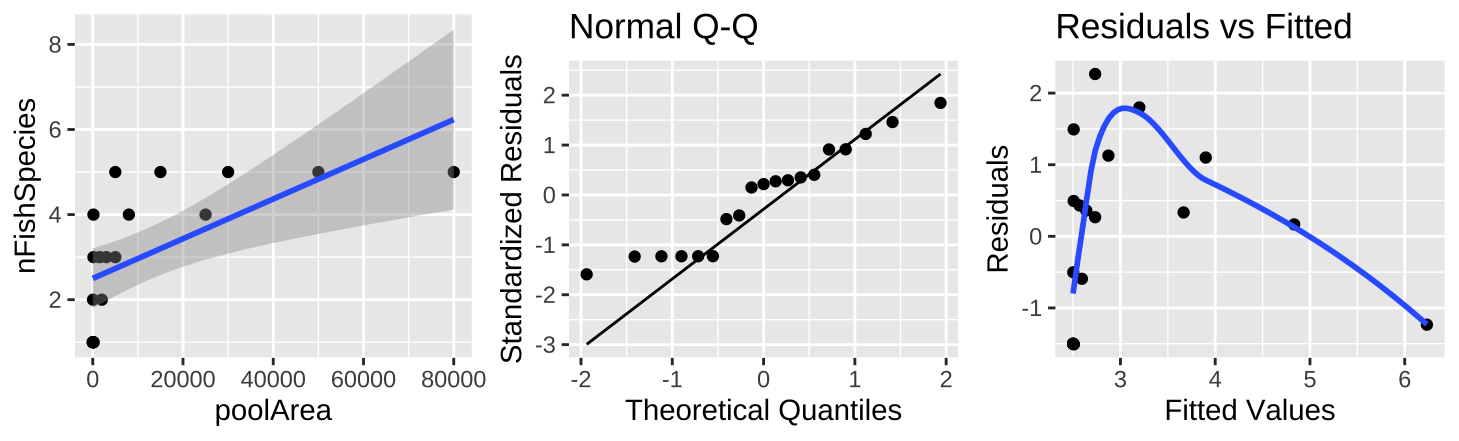
Figure 27.8: (A) Fitting a linear regression to predict the number of fish species from pool area. (B) A qq-plot of the residuals of this model. (C) The relationship between predictions, \(\widehat{Y_i}\), and residuals, \(a_i\) from this model.
The plot of the raw data (Figure 27.8A) shows a clear and strong association between pool area and the number of fish species, and a large proportion of variance explained (0.39) – but something is clearly weird. Looking at the diagnostics it’s clear that the small values are too big and the small values are too small (Figure 27.8B,C).
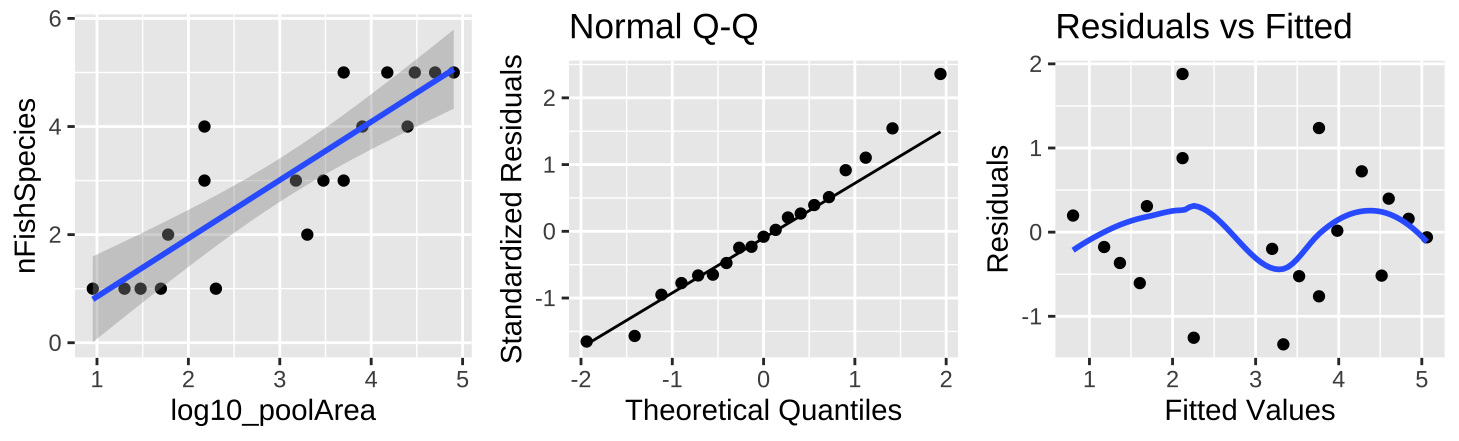
Figure 27.9: (A) Fitting a linear regression to predict the number of fish species from \(log_{10}(pool area)\). (B) A qq-plot of the residuals of this model. (C) The relationship between predictions, \(\widehat{Y_i}\), and residuals, \(a_i\) from this model.
A \(log_{10}\) transform of the x axis (Figure 27.9A) shows a clear and strong association between \(log_{10}\) of pool area and the number of fish species. This nearly doubles the proportion of variance explained (\(r^2 = 0.74\)). So, in addition to better meeting test assumptions ((Figure 27.8B,C), this transformation seems to be a better and more natural scale on which to address this question.
27.8.3 Polynomial regression example
Another example that reveals that violating assumptions often hints to a biologically inappropriate model comes from again predicting the number of species, but this time from the productivity of the plot.
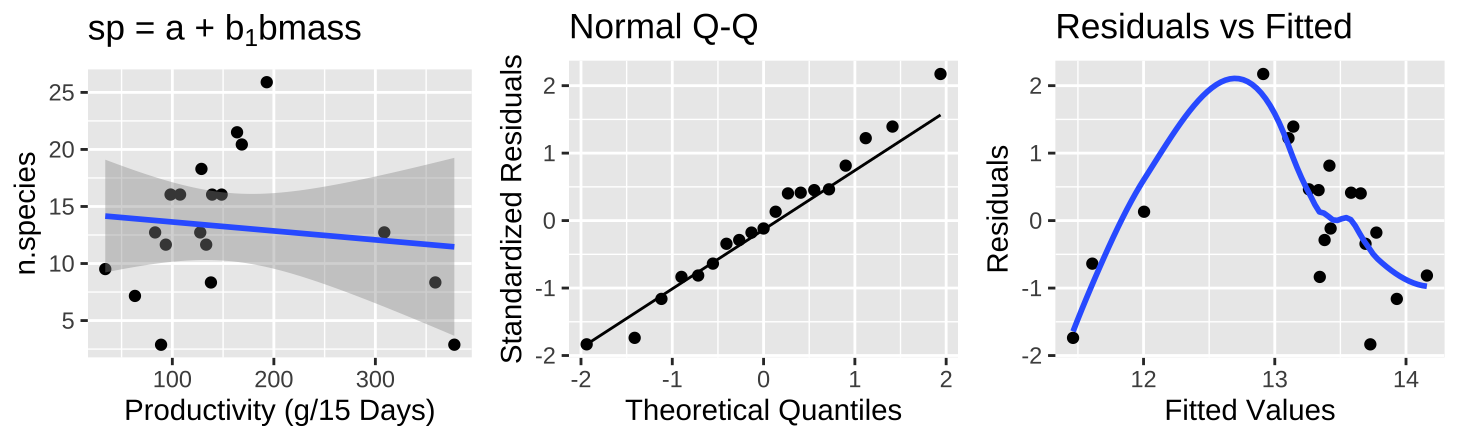
Figure 27.10: (A) Fitting a linear regression to predict the number of plant species from prodcutivity of a plot. (B) A qq-plot of the residuals of this model. (C) The relationship between predictions, \(\widehat{Y_i}\), and residuals, \(a_i\) from this model.
The plot of the raw data (Figure 27.10A) shows practically no association between productivity and the number of plant species, with nearly no variance explained (\(r^2 = 0.015\)) – but something is clearly weird. Looking at the diagnostics it’s clear that even though residuals are normally distributed, Figure 27.10B, intermediate values have large and positive residuals (Figure 27.10C).
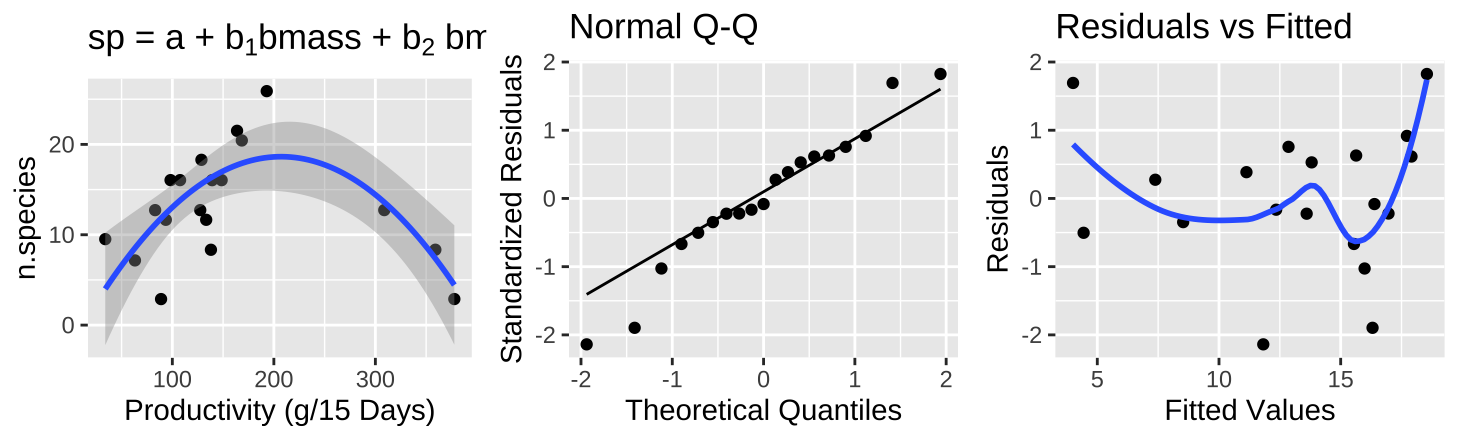
Figure 27.11: (A) Fitting a polynomial regression to predict the number of plant species from prodcutivity of a plot. (B) A qq-plot of the residuals of this model. (C) The relationship between predictions, \(\widehat{Y_i}\), and residuals, \(a_i\) from this model.
A polynomial regression (Figure 27.11A) shows a clear and strong association between productivity and diversity – diversity is maximized at intermediate productivity. This model suddenly explains a large portion of the variance in species diversity(\(r^2 = 0.5316\)). So, in addition to better meeting test assumptions ((Figure 27.8C), this transformation seems to be a better and more natural model.
We return to polynomial regression in the next section!