Chapter 16 Hypothesis Testing
Motivating scenarios: (1) We want to know understand the standard by which scientists take results as serious vs. chalking them up to sampling error. (2) We are visiting a doctor, reading a newspaper, or a reading a scientific paper, and we are told results are “statistically significant,” or have a P-Value of XXX and want to know what that means. (3) We have done a statistical analysis and want to guard against a simple explanation that our seemingly exceptional results are attributable to sampling error.
There is one MAJOR GOAL here. You should understand a p-value and it’s limitations. But to break this down.
Learning goals: By the end of this chapter you should be able to
- Explain why we make null models and what makes a good one.
- Explain the motivation for Null Hypothesis Significance Testing (NHST).
- Explain the role of a test statistic in hypothesis testing.
- Describe a p-value in relation to the sampling distribution under the null.
- Explain what a false positive and a false negative is and how likely we are to observe one or the other as samples get larger.
- Explain why a p-value is not “the probability that the null is true.”
- Explain the concept of statistical power and how it relates to the sample size and effect size.
16.1 Review and motivation for null hypothesis significance testing
In chapters 1 and 7 we talked about estimation as a major goal of statistics – we hope to summarize what we see in the world to estimate population parameters from a sample.
But we also learned, in chapters 1, 8, and 9, that all estimates are subject to sampling error. Our goal in null hypothesis significance testing is to see if results are easily explained by sampling error. Let’s work though a concrete example:
So, say we did an experiment: we gave the Moderna Covid vaccine to 15,000 people and a placebo to 15,000 people. This experimental design is meant to
- Imagine if the population that got the Covid vaccine, or it did not.
- Calculate parameters of interest (e.g. the probability of contracting Covid, or the frequency of severe Covid among those who caught Covid), or the frequency of severe reactions etc.. in the vaccinated and unvaccinated population.
- Compare these parameters across populations with and without the placebo.
Let’s look at the estimates from the data!!!!
- Vaccine group: 11 cases of Covid 0 severe cases.
- Placebo group: 185 cases of Covid 30 severe cases.
So did the vaccine work??? There are certainly fewer Covid cases in the vaccine group.
But these are estimates, NOT parameters. We didn’t look at populations, rather these results came from a process of sampling – we sampled from a population. So, these results represent all the things that make samples estimates differ from population parameters, as well as true differences between populations (if there were any). So, before beginning a vaccination campaign we want to know if results are easily explained by something other than a real effect.
What leads samples to deviate from a population?
- Sampling bias
- Nonindependent sampling
- Sampling error
Our goal in null hypotheses significance testing is to see if results are easily explained by sampling error.
16.2 Null hypothesis significance testing
So in null hypothesis significance testing we aim to see how easily the results can be explained by a “null model.” To do so, we go through four steps.
- State the null hypothesis and its alternative.
- Calculate a test statistic to summarize our data.
- Compare the observed test statistic to the sampling distribution of this statistic from the null model.
- Interpret these results. If the test statistic is in an extreme tail of this sampling distribution, we reject the null hypothesis, otherwise we do not.
Steps 1-3 are pretty straightforward,
⚠️ Step 4 is very strange and is one of the more challenging concepts in statistics. We’ll see that a big reason for this challenge is that what the field does doesn’t make that much sense ⚠️.
16.2.1 Statistical hypotheses
Scientific hypotheses are exciting.
- Scientific hypotheses should be well motivated in our understanding of our biological question.
- There are a potentially infinite number of biological hypotheses, and we’ll look into many over this term.
- The answers to these hypotheses should be consequential.
- Really good biological hypotheses come from an understanding of the process we’re studying.
- We usually have a sense of the expected strength of the effect of our biological hypothesis.
We look into biological hypotheses with statistical hypotheses.
- Statistical hypotheses are boring.
- In null hypothesis significance testing we keep looking into the same two biological hypotheses.
- In null hypothesis significance testing statistical hypotheses don’t know or care about your theories, or have any sense of an effect size.
We cannot perfectly align biological and statistical hypotheses, but a good study will try its best to!
Unfortunately as scientists we’re usually out to evaluate support for an exciting scientific hypothesis, but in frequentist statistics we do this in a totally backwards way, by looking into the plausibility of a boring statistical hypothesis known as the null hypothesis.
@canoodleson Hypotheses and hypothesis testing in stats
♬ original sound - Christina
The null hypothesis

So what is the null hypothesis? The Null Hypothesis, also called \(H_0\), skeptically argues that data come from a boring population described by the null model.
The null model is extremely specific. It is meant to represent the process of samplings to the truest extent we can, and then clams that the process of sampling can explain any interesting observation in our data. For the cas above, the null hypothesis for the effect of the Vaccine on Covid cases is:
\(H_0\): The frequency of Covid cases does not differ between vaccinated and unvaccinated populations.
Figure 16.1: From xkcd. Rollover text: Heck, my eighth grade science class managed to conclusively reject it just based on a classroom experiment. Its pretty sad to hear about million-dollar research teams who cant even manage that.

Figure 16.2: The null hypothesis.
The alternative hypothesis
The alternative hypothesis, \(H_A\), is much vaguer than the null. While the null hypothesis claims that nothing is going on, the alternative hypothesis claims that something is going on, but it does not specify what that is. For the cas above, the alternative hypothesis for the effect of the Vaccine is:
\(H_A\): The frequency of Covid cases differs between vaccinated and unvaccinated populations.
One tailed and two tailed tests
Notice that the alternative hypothesis above is that the frequency of Covid cases differs between the vaccinated and the unvaccinated. What if we just cared to know if the vaccine gave greater immunity than no vaccine? In theory we could look at only one side of the null distribution, below. In practice, such one tailed tests are almost always a bad idea. In this case we would definitely want to know if the vaccine somehow made us more susceptible to covid. For that reason we generally avoid one-tailed tests.
Rare cases when a one-tailed test is appropriate are when both ways to be extremely different are on the same side of the null distribution. As an extreme example, if I was studying the absolute value of something, the null is that it is zero, while the alternative is that it’s greater than zero. We will see that some test statistics, like the \(F\) statistic and (often the \(\chi^2\) statistic only have one relevant tail.16.2.2 The test statistic
So how do we evaluate if our data are easily produced by the null mode? The first step is to find one summary of our data. This summary is called a test statistic. For now let’s summarize our results as the number of cases in the vaccine group divided by all of the cases in the study.
For covid cases in the Moderna study, this equals \(\frac{11}{11+185} = \frac{11}{11+185} \approx 0.0561\).
A test statistics can be just about anything that makes sense, but commonly used test-statics, such as the \(F\), \(\chi^2\), \(Z\), and \(t\), etc. etc, are special because their behavior is so well understood.
16.2.3 The sampling distribution under the null hypothesis
Because the null model is specific, we can generate the expected distribution of the test statistic by generating a sampling distribution from the the null model. For now, I will provide you with sampling distributions of test-statics under he null. Later we will learn more about how we can generate this distribution.
We can visualize the sampling distribution under the null as a histogram, as we would any other sampling distribution:
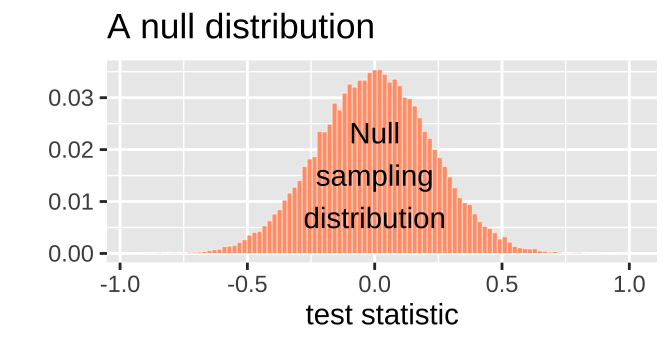
We then next compare our actual test statistic to its sampling distribution under the null. For example, figure 16.3 shows that the null model for the moderna Phase II vaccine trial would almost never generate the low incidence of Covid infection among the vaccinated relative to the unvaccinated that was observed in this Phase 3 trial.
.](Applied-Biostats_files/figure-html/moderna1-1.png)
Figure 16.3: Data from Moderna Press Release.
16.2.4 P-values
Figure 16.4: P-values are given incredible power over scientific research, and can confuse scientist. After watching this, read the rest of this chapter any try to explain them clearly. This video is from Five Thirty Eights Blogpost Not Even Scientists Can Easily Explain P-values. 1 minute and 30 seconds. REQUIRED.
The observed test statistic shown in figure 16.5a is in the middle of the sampling distribution for the null. If we saw this value pop out of a null model, we wouldn’t bat an eye. By contrast, like the Moderna trial, the null model rarely generates an observation as extreme as observed for the test statistic shown in Figure 16.5b.
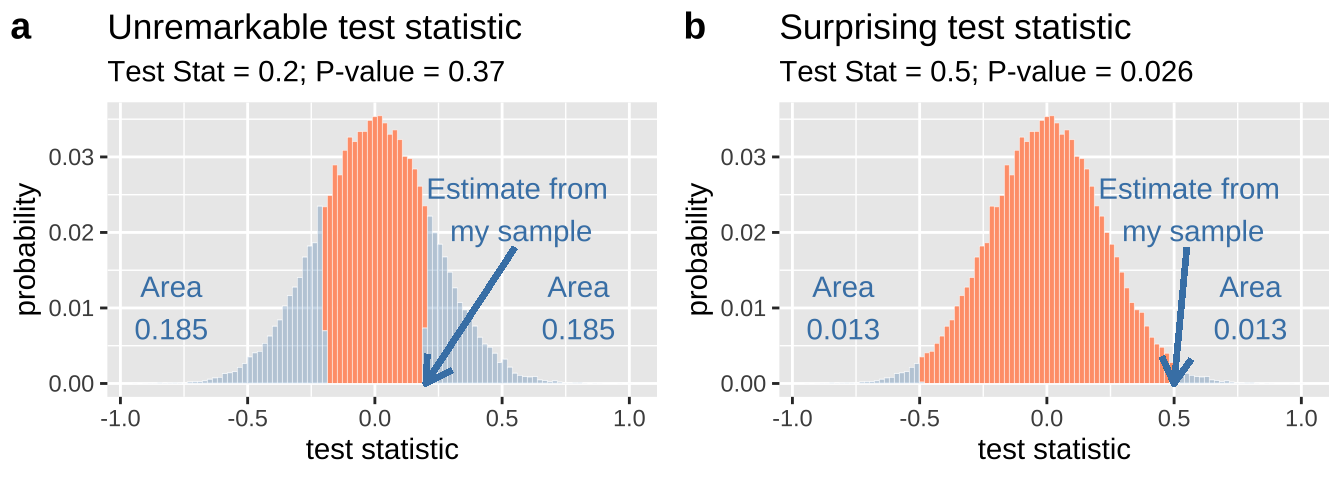
Figure 16.5: A sampling disribution with a test statistic that is unexceptional (a) or quite unlikely (b).
We quantify how surprised we would be if the null model generate a test statistic as or more extreme than what we observe by the P-value. To calculate a P-value we sum (or integrate) the area under the curve from our observation out until the end of the distribution. Because we would be equally surprised by extreme values on the lower (left) or upper (right) tail of the sampling distribution, we almost always add up extremes on both sides.
So, in Figure 16.5a, we sum add up all the area as or more extreme than our observation on the lower and upper tail and calculate a P-value of 0.185 +0.185 = 0.37. This quantifies what we could see with our eyes – our test statistic is unremarkable. We expect that 37% of samples from the null would be as or more extreme.
Likewise in Figure 16.5b, we sum add up all the area as or more extreme than our observation on the lower and upper tail and calculate a P-value of 0.013 +0.013 = 0.026. This again quantifies what we could see with our eyes – our test statistic is surprising. We expect that only 2.6% of samples from the null would be as or more extreme.
16.2.5 Interpretting results and drawing a conclusion
A P-value can make or break a scientist’s research.
P-values are often the measuring stick by which the gauge the significance of their work.
So what do scientists do with a p-value? Why can it “make or break” your research etc?
 poking fun at null hypothesis significance testing. *Rollover text:* If all else fails use significance at the α = 0.5 level and hope no one notices.](https://imgs.xkcd.com/comics/p_values.png)
Figure 16.6: xkcd poking fun at null hypothesis significance testing. Rollover text: If all else fails use significance at the α = 0.5 level and hope no one notices.
By custom, if our p-value is smaller than \(\alpha\) (a number which is by convention set, somewhat arbitrarily to 0.05) we reject the null hypothesis, and say the result is ✌️ statistically significant ✌️. What does this mean? It means that if we set \(\alpha\) at its customary cut value of \(0.05\), we will get a false positive – that is we will reject a true null hypothesis, in 5% of studies where the null is actually true.
By custom, if our p-value is greater than \(\alpha\) we say we fail to reject the null hypothesis. Again failing to reject the null does not mean the null is true. In fact, there are many times when we will fail to reject a false null hypothesis. The probability of these false negatives, \(\beta\) is not a value we choose, rather, it depends on both the size of our sample and the size of the true effect (that is the difference between the null hypothesis and the true population parameter). Power, the probability of rejecting a false null equals \(1-\beta\). Often in planning an experiment, we pick a sample size large enough to ensure we have the power to reject the null for an effect size that we’re interested in.

These customary rituals are taken quite seriously by some scientists. To some audiences, the difference between a P-value of 0.051 and 0.049 are the difference between a non-significant and significant result, and the difference between publication or rejection. I and many others (e.g. this article by Amrhein, Greenland, and McShane (2019)) think this is a bad custom and not all scientists adhere to it, but nonetheless this is the world you will navigate, so you should know these customs.
The effect of sample size
16.3 The Effect of Sample Size
When the null is true p-values will be uniformly distributed, and the false positive rate is \(\alpha\) regardless of sample size.
When the null is false we will have more smaller p-values as sample sizes increasez, and a true positive rate that increases with the sample size.
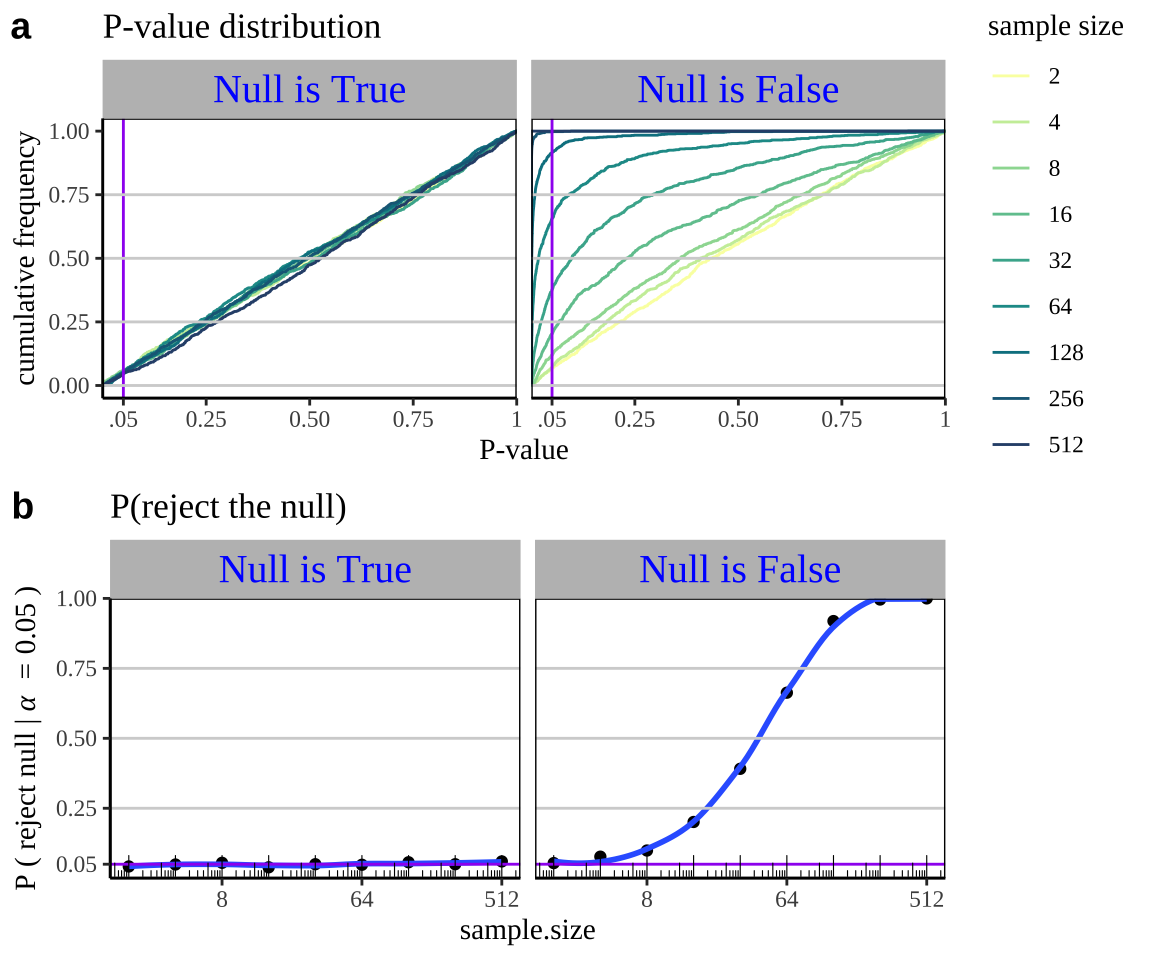
Figure 16.7: a) When the null hypothesis is true, p-values are uniformly distributed regardless of sample size. By contrast we have more low p-values when the null hypothesis is false. Therefore, b) The probability of rejecting the null is always alpha when the null is true, but gets bigger as the sample size increases when the null is false. In both a and b, the null for both panels was 0, while the true parameter was 0.3 standard deviations away from zero in the panel on the right.
SHINY APP HERE
16.4 Problems with P-values and their interpretation
16.4.1 Why the interpretation of p-values is hard

Students struggle to understand the meaning of a p-value, and I think it’s because
- None of the customs above make sense,
- P-values don’t measure the thing we care about.
- They have nothing to do with the alternative hypothesis.
- They have even less to do with the motivating biological hypothesis.
- They have nothing to do with the alternative hypothesis.
- Null hypothesis significance testing is not logically sound. We want to know about something that’s not the null, and we never ever consider the alternative model, we simply pretend that the alternative hypothesis is likely right in cases when the observations are unusual for the null distribution.
The common misinterpretations below, I believe reflect people wishing a p-value reported something useful or logical.
A P-VALUE IS NOT “the probability that the null hypothesis is true” NOR IS IT “the probability that what we observed is due to chance.” These are both wrong because. But I sympathize with these misinterpretations, because it would be great if that’s what a P-value told us.
A P-VALUE DOES NOT say anything about the alternative hypothesis. A p-value simply describes how weird it would be for the null model to generate such an extreme result. Again, I understand the desire to have the p-value tell us about the alternative hypothesis, because this is usually more interesting. Sadly, p-values cant do that.
A P-VALUE DOES NOT measure the importance of a result. Again, such a measure would be great to have. But we don’t have that. The importance of a result depends on its effect size, and its role in the biological problem we’re looking into.
What does this mean for us as scientists? What this means is that we have two challenging responsibilities
- We need to understand what the process of null hypothesis testing is, and be able to participate in the associated customs and rituals.
- At the same time, we need to responsibly interpret our statistics. Some good things to remember are
- Rejecting \(H_0\) does not mean \(H_0\) is false.
- Failing to reject \(H_0\) does not mean \(H_0\) is true, nor does it mean that there is no effect.
- We can reject or fail to reject \(H_0\) for many reasons unrelated to our biological hypothesis. A good practice is to think about a plausible effect size of our biological hypothesis to see if the size of the reported effect is consistent with our biological model.
- Rejecting \(H_0\) does not mean \(H_0\) is false.
The prosecutor’s fallacy and Bayesian approaches
Figure 16.8: The prosecuters fallacy as explained by Calling Bullshit. 11 min and 58 seconds. REQUIRED.
The video above (Fig 16.8) makes a clear point.
We calculate \(P = P(\text{Data or more extreme}|\text{H_0})\), but we really want to know \(P = P(\text{H_0}|\text{Data or more extreme})\).
We have to always remind ourselves that with a p-value we have \(P = P(\text{Data or more extreme}|\text{H_0})\).
Later in the term, we’ll see Bayes theorem (See Section 15.6) sets up a different way to do stats that answers questions like what’s the probability of the null hypothesis given my data by flipping these conditional probabilities. However, for most of his class we cover classic frequentist statistics here, we have to remember that we are not answering that question.

Why do we still use null hypothesis significance testing?
Q: Why do so many colleges and grad schools teach p = 0.05?
A: Because that’s still what the scientific community and journal editors use.
Q: Why do so many people still use p = 0.05?
A: Because that’s what they were taught in college or grad school
So, with all the issues with p-values and null hypothesis testing? Why am I teaching it and why do we still do it, as a field?
The first answer is well summarized by George Cobb, above. I teach this because this is how science is often done, and you should understand the culture of science and its rituals. When you read studies, you will see p-values, and when you write results people will expect p-values. At the same time, you should recognize hat this isn’t the only way to do statistics. For example Bayesian stats is quite mainstream. We will return to Bayesian stats in the end of the term.
The second answer is that null hypothesis significance testing works well. Scientists have used this approach for the last decade, and made continued progress. So, although the theoretical underpinnings of null hypothesis significance testing are shaky, its practically quite useful. Unlike George Cobb, I believe we keep using p values and p =0.05 because it seems to be working well enough. That said, I believe that the nuanced understanding I tried to equip you with in this chapter helps us make even better use of p-values.
16.5 Never report P-values without context
P-values are shitty summaries of the data. They don’t directly tell us about the effect size, or the variability or anything. Whenever you report a p-value, you should include key information alongside it. Most importantly always include the test statistics, parameter estimates, and uncertainty in these estimates.
Hypothesis testing quiz
Go through all “Topics” in the learnR tutorial, below. Nearly identitical will be homework on canvas.
Hypothesis testing: Definitions
The Null Hypothesis A skeptical explanation, made for the sake of argument, which argues that data come from a boring population.
The alternative hypothesis A claim that the data do not come from the “boring” population.
The test statistic One number that summarizes the data. We compare the observed test statistics to its sampling distribution under the null model.
P-value The probability that a random sample drawn from the null model would be as or more extreme than what is observed.
\(\alpha\) The probability that we reject a true null hypothesis. We can decide what this is, but by convention \(\alpha\) is usually 0.05.
False positive Rejecting the null when the null is true.
False negative Failing to rejecting the null when it is false.
Power The probability of rejecting a false null hypothesis. We cannot directly set this – it depends on sample size, and the size of the effect. But we can design experiments aiming for a certain power.OPTIONAL: Alternatives to null hypothesis significance testing
Because of the strangeness around p-values, and the bright and arbitrary line separating “significant” vs “nonsignificant” results some people have suggested alternative approaches to statistics.
Some involve banning p-values, replacing p-values with confidence intervals, doing Bayesian analyses etc. I highly recommend the paper, Some Natural Solutions to the p-Value Communication Problem—and Why They Won’t Work (Gelman and Carlin 2017) for a fun take on these proposals.
Bayesian stats as another approach to statistics
Here, I briefly introduce Bayesian Statistics. Bayesian statistics aims to find the probability of a model given the data, by using Bayes’ theorem. This is the thing we usually want to talk about. But a word of caution – to a frequentist there is no probability about the true parameter – as populations have parameters that belong to them. By contrast, a Bayesian thinks that populations take their parameter values by chance. This is a very different way to think about the world.
\[P(\text{Model}|\text{Data}) = \frac{P(\text{Data}|\text{Model})\times P(\text{Model})}{P(\text{Data})}\]
We substitute some fancy words here, without making any math changes. We call
- \(P(\text{Model}|\text{Data})\) the “posterior probability.”
- \(P(\text{Data}|\text{Model})\) the “likelihood.” This is usually not too hard to figure out.
- \(P(\text{Model})\) the “prior,” is the probability of our model BEFORE we have data. This is the trickiest part, as how can we know the probability of our model before we get the data??? This is the thing that most often prevents people from using Bayesian approaches, but there are some clever math workarounds.
- \(P(\text{Data})\) is called the evidence. The math for this is often too hard for mathematicians, but there are a bunch of computer tricks we can use to find this.
\[\text{Posterior Probability} = \frac{\text{Likelihood}(\text{Model}|\text{Data}) \times \text{Prior}}{\text{Evidence}}\]
Notably, this also mean that we can study “credible intervals” – regions with a 95% probability of containitng the true population parameter, as opposed to “confidence intervals” which cannot do this.