Chapter 11 Data presentation and visualization. Goals, considerations, and best practices
Motivating scenarios: You are thinking about how to communicate your results in figures or you are worrying that someone is tricking you with their figures.
Learning goals: By the end of this chapter you should be able to:
- Explain the concepts behind what makes a good figure, and the specific elements of a figure that can be modified to make a good figure.
- Critique figures and understand when / how they are being manipulated.
{kind=link}
In Chapter 6, we went over our goals in making a plot, and dove into making our first ggplots. I did this so that we could get started on something, before perfecting.
Here we:
- Think deeper about making good plots,
- Reflect on what makes plots less effective, and
- Consider how plots can lie to us.
My goal here is to separate the challenge of conceptualizing and interpreting a figure from the challenge of making a figure in R. I do this because they are very different problems, and worrying about making your figure in R before you know what you want to do often leads to bad figures. On the other hand, if you know what you are aiming to do in R you can usually do it, and if/when you cannot, you can then readjust your goal (or touch up the figure in illustrator).
That said, I do introduce a few R tips when our desired effects can be achieved relatively simply. In Chapter 12, we focus on making our desired figures in R.
11.1 Why make a plot?
It’s nearly impossible to looking at all numbers in a data set, and come home with a holistic view of it. It is incredibly inefficient to communicate results in this way. In Chapter 7 we introduced classic summary statistics that can more efficiently communicate data. However, on their own, these simple summaries can mislead, can miss important features in our data, and do not allow for readers to rapidly take in and evaluate our claims.
11.1.1 Why make exploratory plots?
The first principle is that you must not fool yourself – and you are the easiest person to fool.
In Chapter 7 we also began to reveal limitations to these summaries, as we noted that we need to know the shape of our data to responsibly interpret and communicate these summaries. The Review below provides a fun example of how much can be hidden in summary stats.
As we discuss in Chapter 1, model building is a big part of what we do as biostatisticians. Thus it is important to explore the shape of our data BEFORE doing any statistical modeling, so that we can build appropriate models.
11.1.2 Why make explanatory plots?
Scientists build explanatory plots to effectively communicate their results, and convince provide skeptical readers the opportunity to evaluate their claims. Plots are such a critical mode of scientific communication that in many lab meetings, papers are discussed by lookng at the figures.
So, an effective plot should
- Clearly communicates a high-level take home message, and
- Convinces the skeptical reader to believe this message.
Clear communication is essential. We present results in plots because they effectively allow readers to take in a message. As we increase the number of categories in a variable, and/or increase the number of variables of interest, this becomes more essential as the cognitive load created by too many data summaries can get in the way of understanding. Plots should not be a mystery or logic puzzle. So we want to help our readers understand the major through line in the (potentially complex) data we analyzed.
Convincing the skeptical reader and inviting their thoughts. Most people are skeptical. They don’t want to be told results, they want to evaluate them and contribute their own two cents. So, an effective plot shows the data in a way that makes a clear claim and allows the reader to evaluate (and perhaps even refine and/or critique). Thus, as we see below, much of making a good plot revolves around building trust by showing the data and not misleading them. If someone thinks you are trying to deceive them they may not trust your analyses (even if the analysis is good).
🤔 WHY do we bring this up? 🤔 Because, you should remember that you’re making plots for a reason, not just to make them. And you should consider the reason for your plot as you make them.
11.2 Telling a story and making a point
When we tell a story we do not simply list everything that happened in a time period. Rather, we tell a story for a purpose – we have a goal of what we would like to communicate.
A good figure should, in many ways, resemble a good story.
- A good figure should have a point (or two or maybe three).
- A good figure should be constructed to highlight this point.
- A good figure should facilitate understanding of this point.
- A good figure should be easy to follow.
- A good figure should be verifiable.
- A good figure should be honest.
- The main point of a good figure should hold up upon scrutiny.
Figure 11.1: A good story video.
Assignment: Reflect on the following questions after watching this video on telling a good story
- How does making a good plot resemble telling a good story?
- How is making a good plot very different than telling a good story?
- How does thinking of a figure as a story change how you think about making a figure? How does it make sense of ideas you have had before? How could it change your approach to making a figure.
11.2.1 What point are you making???
Graphs exist to make clear points. Together a set of plots should come together to tell a story. So, in making an explanatory plot, think
- What point do I want to make?
- How does it fit in the larger story I trying to tell?
Example of telling a story: In basketball most shots are worth two points, while distant shots beyond the ‘three point’ line are worth three points. In around 2008-ish the NBA started to ge serous about nalytics, and a bunch of mathy people figured out that three points are more valuable than two points, so teams should shoot either three pointers, or very close twoo point shots, that have a really good chance of going in (podcast for the curious).
Figure 11.2A compares shot selection before and after this insight spread through the NBA. It makes the point that before the analytical revolution, different teams shot from very different places with no obvious trends, while after the revolution, all teams shot mainly three pointers and very close shots. 11.2B shows a greater context to these data point – highlighting the extreme rise in three point shot attempts from 2006 to the present, providing a longer historical record for background. Together, they tell the story of the NBA’s analytics revolution.
. Figure **B** is modified from a [an article on espn.com](https://www.espn.com/nba/story/_/id/26633540/the-nba-obsessed-3s-let-fix-thing).](images/threes.jpeg)
Figure 11.2: Figure A is modified from images on instagram @llewellyn_jean. Figure B is modified from a an article on espn.com.
11.2.2 Did you make your intended point?
Figure 11.2 is imperfect. Most notably, the team names are too small to read. I could imagine spending a bunch of time fixing this. But that time would be largely wasted – team names do not play much of a role in the story we are telling, so this should not be a big concern.
After you make your plot, stop and look at it. Consider how your figure makes this point, and how it detracts from this point. Then brainstorm how you could improve your plot to more clearly and honestly make your point.
11.2.3 The processs
Computational tools like ggplot can help us make good plots. But always remember that they are tools for us, and don’t let them push you around. I and the internet (see tweet below) therefore suggest to go into ggplotting with a plan – (1) first sketch your desired plot and (2) be wary of default selections and common plots etc.
My approach to figure-making in #ggplot ALWAYS begins with sketching out what I want the final product to look like. It feels a bit analog but helps me determine which #geom or #theme I need, what arrangement will look best, & what illustrations/images will spice it up. #rstats pic.twitter.com/GUjeEgqZxj
— Shasta E. Webb (@webbshasta) May 22, 2020
You will then go back and forth with you pencil and paper and ggplot with a few iterations until you have a plot you like (See Figure 11.3 for an example, and the blog it came from for how they did it).
For an explanatory plot, share a draft plot with someone unfamiliar with the data to see if your point pops.
 by [@WeAreRLadies](https://twitter.com/WeAreRLadies). See the evolution of a ggplot [tutorial](https://cedricscherer.netlify.app/2019/05/17/the-evolution-of-a-ggplot-ep.-1/) for a "how to". We will refer to this example often below.](images/iteratePlots.gif)
Figure 11.3: Making a plot is an iterative process. gif taken from tweet by @WeAreRLadies. See the evolution of a ggplot tutorial for a “how to.” We will refer to this example often below.
11.3 The audience and the goal
Not every plot has to be a masterpiece - our characterization of exploratory vs explanatory plots considers two ends of a continuum. Consider your audience and your goal when making a plot.
That said, you might find it useful to develop a consistent collection of colors, font size etc. ready to go in ggplot so that all plots are accessible with limited additional effort.
11.3.1 The audience.
We tell stories to an audience, not a wall. And when we tell stories, we need to consider who our audience may be, and how they are consuming our story. Just like you would write a book differently than a screenplay, and provide different context / info when telling a story to your bff vs your sibling, you similarly will need to consider you audience when making a plot. For example,
- What is their subject matter expertise? Do they have a background in science? In statistics?
- Are they familiar with interpreting the plots we’re making or do they need guidance?
- What is our method of presentation – that is, how is the experiencing our plots? Printed paper? A slide? A poster? The internet etc…?
For most of this term your audience will be you, me, and sometimes a few peers. So you should make clear plots for people with some background in stats, who will be reading your plot on a computer.
As you read the guidence below, consider how would you change plots based on audience.
Tailoring presentations to their method of presentation
Science is communicated in many ways. The most common presentations that include the visual display of data are: books/papers, public talks, posters, internet. While the basic principles of making a good plot are always the same, you should customize your explanatory plots to the method of communication.
- Books / Papers: Here plots are static, and while we can write about them in the text, there’s no guaranteed the audience will read it. So, plot for papers and books should be self-contained such that the readers get the figure’s main point from image and caption alone. If a figure can be misinterpreted by looking at it, this should be fixed in the figure (or less ideally, the figure caption), not the text of the manuscript.
- Public Talks: When telling stories to a captive audience in a public talk, you control the flow of information.
- You can build up figures one slide of a time to bring our audience along.
- But be sure the text is big enough to be visible from the back of the room.
- You can build up figures one slide of a time to bring our audience along.
- Poster sessions: Large conference halls are filled with posters. Stunning images and catch visualizations are important in this medium because we want people to pay attention to us and engage, rather than walking on by.
- Digital: When your work is online, you can include gifs, and make interactive plots to better engage and empower your readers.
11.3.2 The goal
People often spend hours or even days on perfecting a plot for publication or an important presentation. You should not spend this long on most plots in this class.
For most plots, you should be sure that they are readable, clearly make their point, and do not lie. And while you should go over the top in customizing every plot in this course for perfect clarity, a well-considered set of colors, shapes, background etc, will make all of your figures good and accessible with minimal additional effort.
Then for your final project, senior thesis, scientific papers etc, you will be in a good place to go from a nice plot, to a publication quality plot with some customization.
As you read the guidance below, consider what you would put in early exploratory plot drafts (e.g. for yourself, homework or advisors), vs what you would only add in a version that would be read by a larger audience (e.g. for senior theses, publications, presentations).
11.4 Making a good plot
All bad plots are bad in their own way, but all good plots are the same. All good plots are:
- Honest
- Transparent
- Clear
- Accessible
We will focus on the distribution of student to ratio ratios across continents (first introduced in Figs 11.3), as an example, but will introduce other data sets when necessary.
Let us start with two versions of this plot so bad, they are hard to make in R.
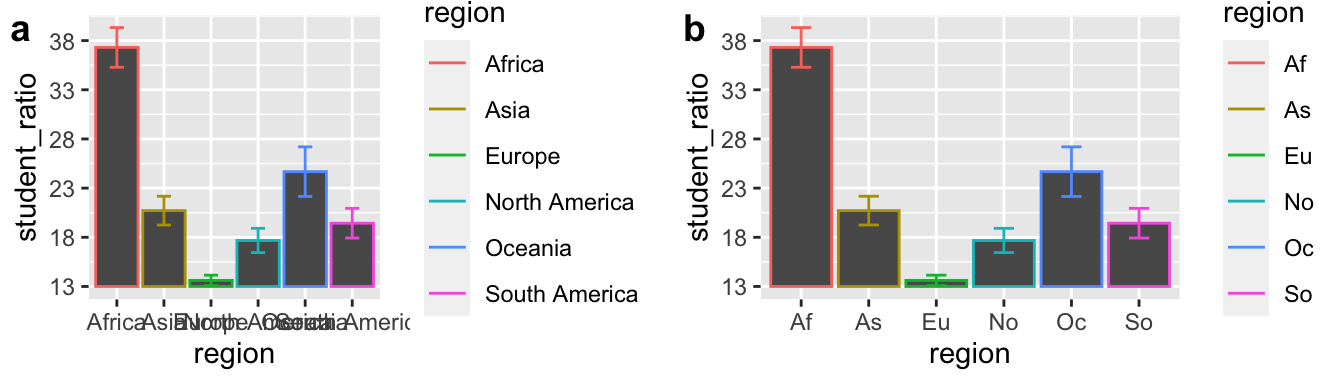
Figure 11.4: It is hard to make a plot this bad.
Take a moment to reflect on what makes Figs 11.4A and B so bad, and what you could do to improve them.
11.4.1 Be honest
While plots should clearly make points, they should not lie or mislead. A misleading exploratory plot will confuse us, and have us waste time chasing wrong ideas. A misleading explanatory plot will sow distrust in your readers - and we want our readers to trust us.
Here are some things to consider to avoid misleading yourself and/or your audience.
11.4.1.1 Don’t mislead with axes
Misleading y-axes
When we see a filled area, our mind naturally thinks in ratios. So, if a reader is not looking carefully at the y-axis they would think that Af student to teacher ratios in Af (Africa), are on average four times higher than in As (Asia), even though in reality it is closer to a two-fold difference (compare a and b in Fig. 11.5).
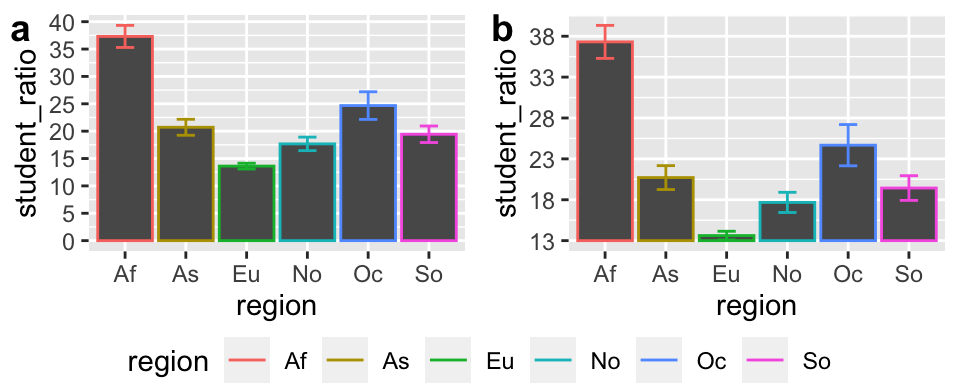
Figure 11.5: Do not truncate the y-axis of bar plots, or other filled plots.
Not all y-axes need to start at zero: Truncating they y-axis is most misleading for filled plots, but not all y-axes need to start at zero.
- Scatterplots tend not to trick the eye in the same way as bar plots, and generally need not start at zero. When we want to communicate absolute difference, rather than relative differences, display the data as points, and worry less about truncating the y-axis.
- When zero is arbitrary (e.g. temperature) starting at zero makes no more sense than starting at any other number.
Watch the assigned video below for a discussion on when truncating the y-axis is misleading and when the y-axis does not need to start at zero.
Figure 11.6: Misleading axes from calling bullshit.
Misleading x-axes
Figure 11.7 shows a graph, released by the sate of Georgia in May 2020, to show that they were controlling coronavirus. Can you spot what is misleading here?
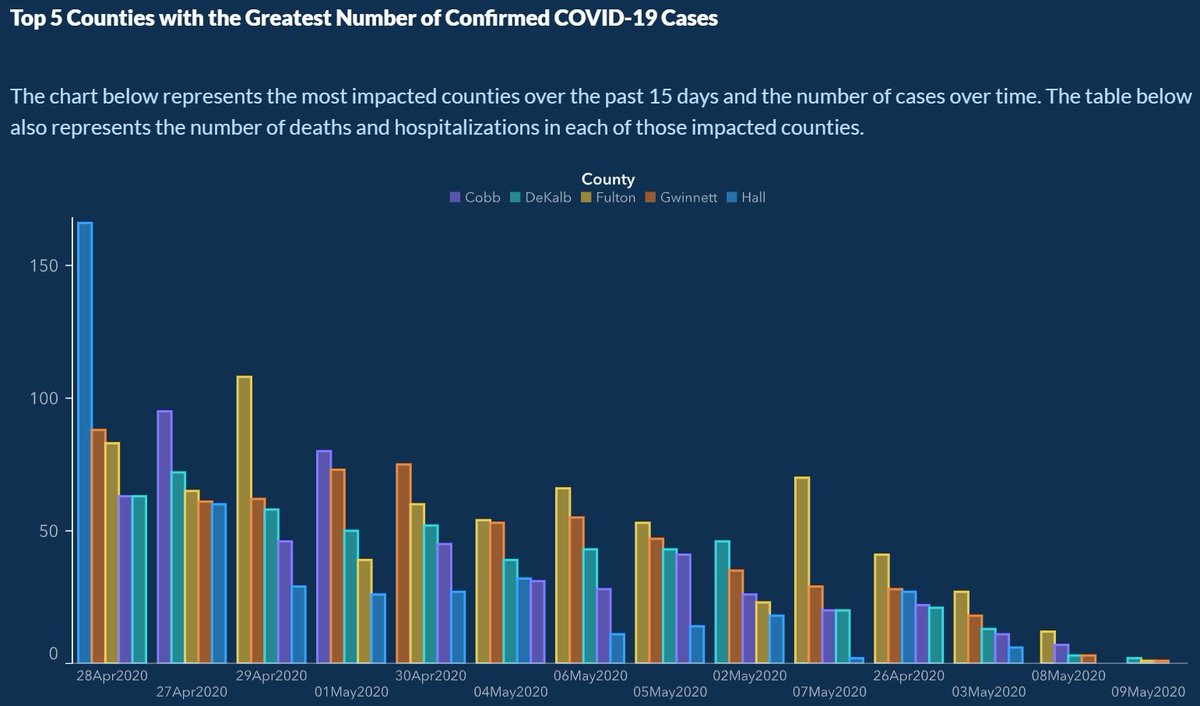
Figure 11.7: HINT: look at the x-axis
A quick glance at Figure 11.8 leaves the impression that the US had a slump in science Nobel Prizes in the early 1970’s. How is this misleading?
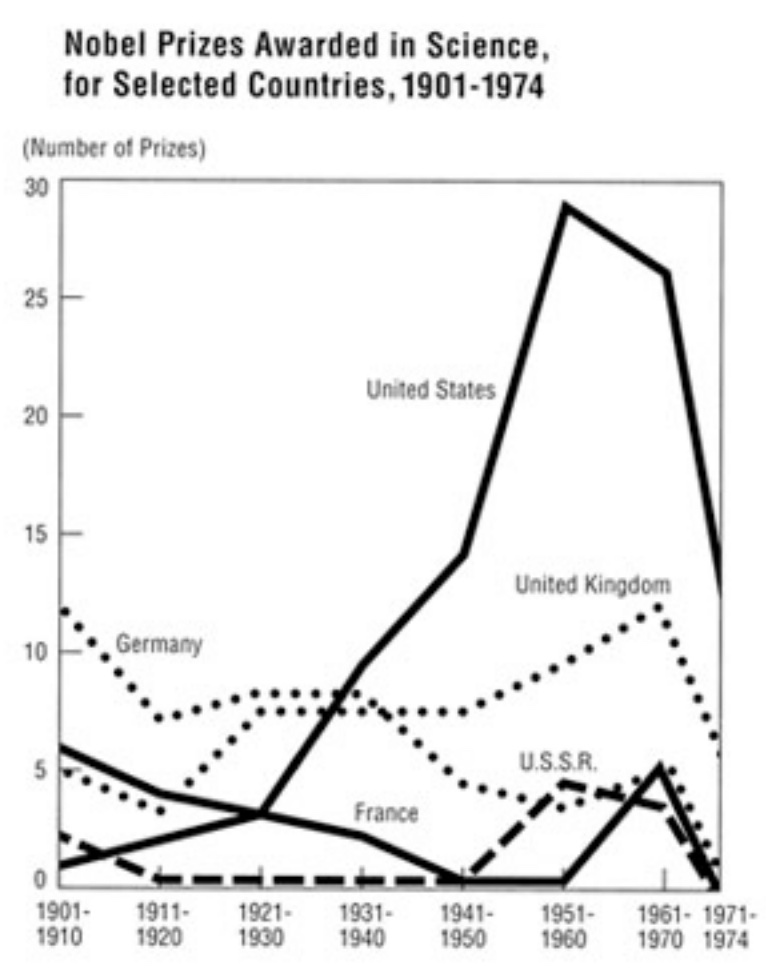
Figure 11.8: HINT: look at the number of years in each bin on the x-axis.
11.4.1.2 Do provide context
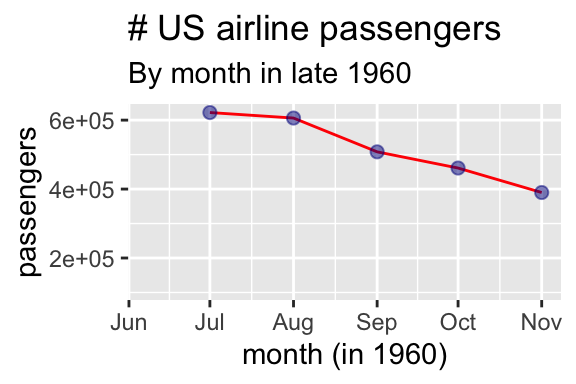
Figure 11.9: Was the airline industry crashing at the end of 1960?
Not only can truncating the y-axis mislead, but truncating the x-axis can also mislead. Plots should provide context to understand the bigger picture underlying patterns. For example, Fig 11.9 suggests that the airline industry was crashing in the end of 1960, but plotting the data year-over-year (Fig. 11.10) shows that this is a predictable seasonal decline, not a terrifying omen.
Similarly prices will mislead if not adjusted for inflation, job numbers must be adjusted for seasonal fluctuations etc…
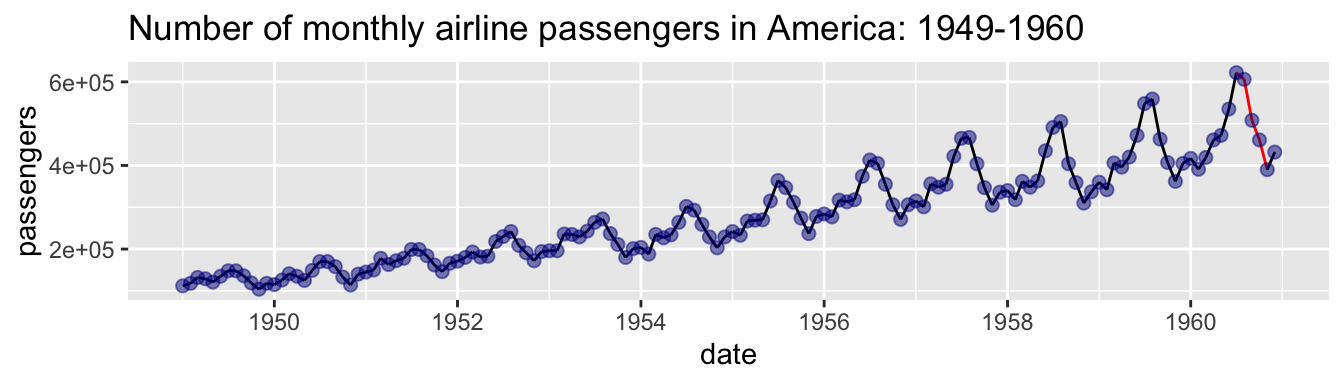
Figure 11.10: Seasonal fluctuations in US air travel (1949-1960).
11.4.1.3 Do not use misleading bin sizes
Figure 11.11: Different bin sizes might tell different stories (5 min and 15 sec from Calling Bullshit).
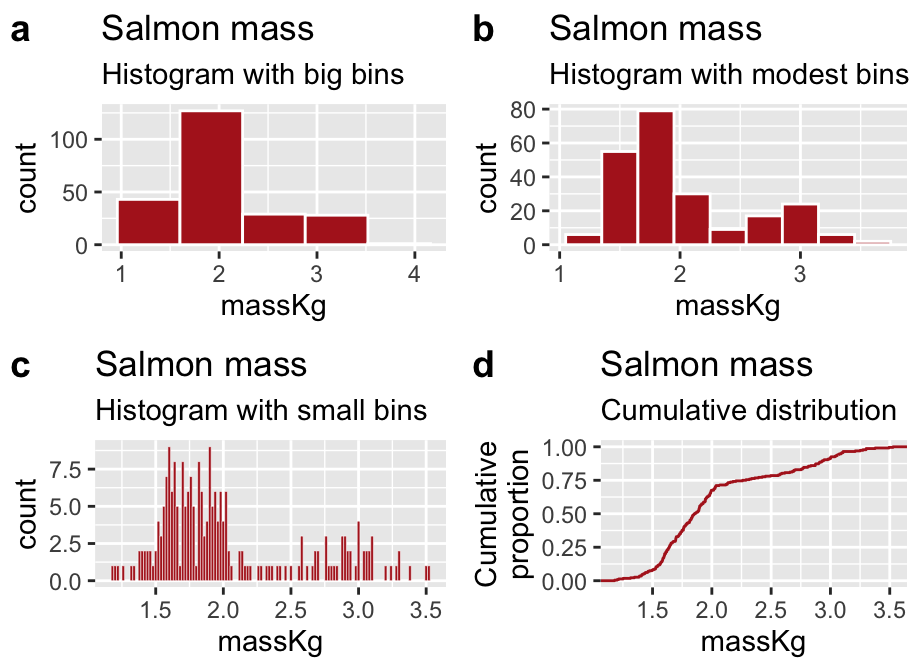
Figure 11.12: Be careful – different bin sizes can generate different stories.
The required video above shows one way in which bin sizes can mislead. Bin sizes can also mislead us when we are using histograms to look at the shape of a distribution. For example, with large bins the distribution of salmon weights looks to be unimodal and right skewed (Fig. 11.12A), but is revealed to be bimodal with smaller bins (Fig. 11.12B). However, smaller bins are not always best – too many bins might distract us from the overall shape (see Fig. 11.12C).
So, what should you do? I recommend experimenting with a few different bin sizes (by either specifying they number or width with the bins or binwidth arguments to the geom_histogram() function, respectively).
If you are not satisfied with any binwidth, you can show the cumulative frequency distribution (e.g. Figure 11.12D with the stat_ecdf() function)). Here we make no decision about binsize – rather they y-axis shows thee proportion of the data with a value less than x. The bimodality is revealed by the two distinct steep slopes of this plot. While this shows all the data the downside is that they are harder for inexperienced readers to interpret.
Finally I note that all of the concerns about bin size carry over to any use of smoothing as you might use in a density plot. In ggplot you can control the smoothing of density plot by using the adjust argument in the geom_density() function.
Figure 11.13: This is very very bad.
11.4.1.4 Do not be manipulative
We saw that plotting filled areas brings our attention to the area, not the point. As such, scaling data by height and width will trick brains into squaring differences. Figure 11.13 breaks all the rules and makes a truly misleading plot. If you are interested to here more you can watch an optional video from calling bullshit (the most relevant part is from 9:19 to 11:23).
11.4.2 Be transparent
As biostatsticians we never want people to simply take our word for it. We want to empower our readers to evaluate our claims, criticize them, test them for themselves and even find new things in our data. Showing the data is an important step towards building trust with a skeptical reader, and invites them to think about our data.
11.4.2.1 Show your data / Allow the reader to interrogate your claims
As we saw in our learnr quiz, reporting summaries can hide interesting patterns in the data. Plotting summaries is no better. As such it is best to honestly show your data. See Figure 11.14 for an example of how to do this, and the tweet for why it matters. (Weissgerber 2015) make an impassioned plea to end the overuse of barplots.

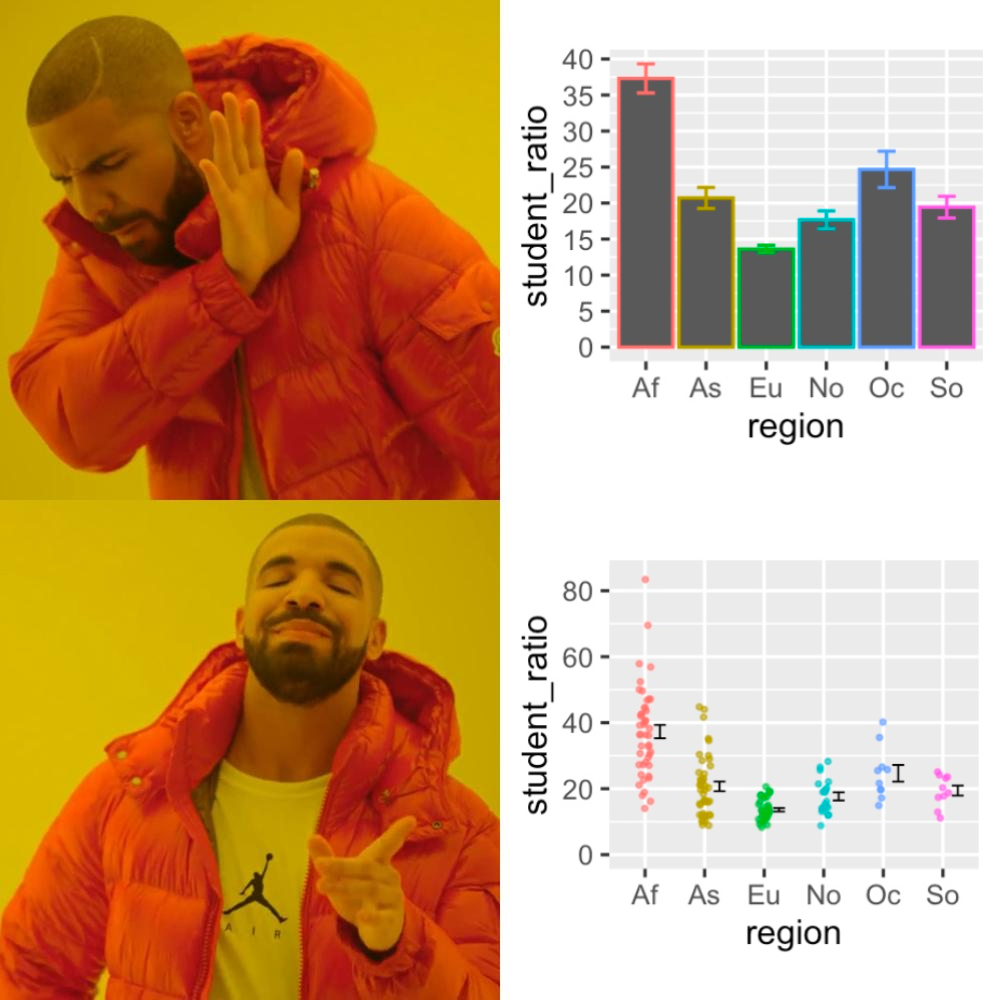
Figure 11.14: Hangin with some data points Ive never seen before.
ADVANCED: Link to your data and share your code
The most transparent data are cully reproducible – that is people should be able to download your code and your data, and redo your analysis, and understand the data well enough to run a different analysis on it. This is becoming the standard for scientific papers, and I will revisit these ideas throughout the term, but this is more relevant to Honors and Grad students than the rest of the class. Check out this paper by Sandve (2013) for an introduction to reproducible research.
11.4.2.2 Avoid overplotting
Sometimes showing all your data actually hides patterns. Figure 9.15a demonstrates this issue, and Figures 11.15offer some ways to overcome overplotting.
, use [`geom_sina()`](https://ggforce.data-imaginist.com/reference/geom_sina.html) to make a sina plot. Data from @beall2006. Download data [here](https://whitlockschluter3e.zoology.ubc.ca/Data/chapter02/chap02e3bHumanHemoglobinElevation.csv).](images/overplot-1.png)
Figure 11.15: Sometimes showing all the data hides patterns. (a) By plotting data points on top of each other, a hides the distribution of values. (b–i) display plots to solve the this overplotting issue. The sina plot (f) is one of my favorites because it shows the shape of the data and each data point. After installing and loading the ggforce package, use geom_sina() to make a sina plot. Data from Beall (2006). Download data here.
11.4.3 Be clear
Good plots are clear with messages that pop out at you. To make a clear plot, minimize the cognitive burden, make the point easy to see, and avoid distractions.
Minimize cognitive burden. Two of my favorite books are Crime and Punishment, and 100 Years of Solitude. These are great stories. But I hated that I needed to bring a piece of paper to trace the relationships between each character in 100 years of solitude, or remember that Raskolnikov, Rodya, and were all the same person. While I’m not here to critique Márquez or Dostoyevsky, that won’t fly in a scientific figure. Be consistent, and use any tricks you can to minimize how much a reader must keep in their head at once.
Make points obvious. While scientific figure should tell a sorry, they should not be a mystery novel or Fight Club – that is, the story should be obvious throughout, and the reader should get the story without needing to solve a puzzle.
Avoid distractions. Readers should be thinking about your story, not the special effects or CGI.
Let’s consider how we can us these concepts to build clear plots.
11.4.3.1 Help readers focus on patterns
We should build our plots in such a way as to help readers focus on the important results.
Bring out important comparisons
Simply putting data in a readable formal in a plot is not enough. Good plots are designed to help readers see and evaluate the patterns critical to our story. Consider the story telling analogy - depending on the point of your story, highlighting a detail could either be a red-herring or a critical element. When making figures, we should not hide or lie about certain features of our data, but we should draw attention to what we believe is important. Practically, this means that, for one data set, very different plots could be appropriate depending on the point we are making (see Fig. 11.16).
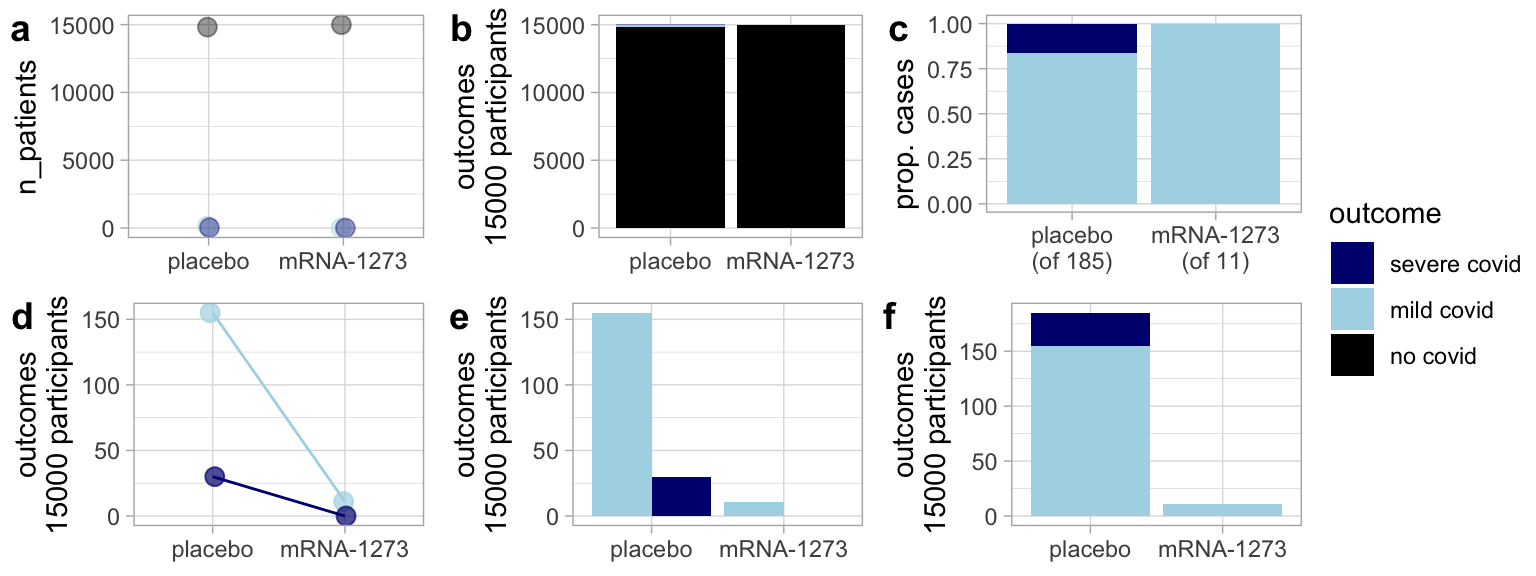
Figure 11.16: Same data different message: Different plots of the Moderna vaccine trial tell different stories. (a) and (b) highlight the result that most people in the trial did not develop covid regardless of treatment. These plots are dishonest, as they leave us with the impression that the vaccine is not effective. (c) is useful in that it allows readers to compare the risk of severe covid cases by treatment for those infected, but this plot hides the key result that the vaccine decreased risk of infection, (d) and (e) place our attention towards the severity of the cases. (f) highlights the efficacy of the vaccine, but makes it hard to compare the severity by treatment. Still, it is my favorite.
Consider how people process images
When we make a plot, we have to consider not just the data and what we hoped to highlight, but what readers process. Some rules of thumb are known – for example, pie charts make comparisons difficult, so they are usually avoided. But you don’t need much background knowledge here – you just need to ask a friend or two to look at your plot and tell you what it is telling them.
 by [Karl Broman](https://kbroman.org/).](images/bromancomparisontypes.png)
Figure 11.17: Facilitate comparisons – Which plot makes A and B easiest to compare? Image from slide 28 of this powerpoint by Karl Broman.
11.4.3.2 Make labels informative, easy to digest, and readable
Figure 11.18a is clearly bad – we cannot read the names of regions. 11.18b, c, and d present possibilities.
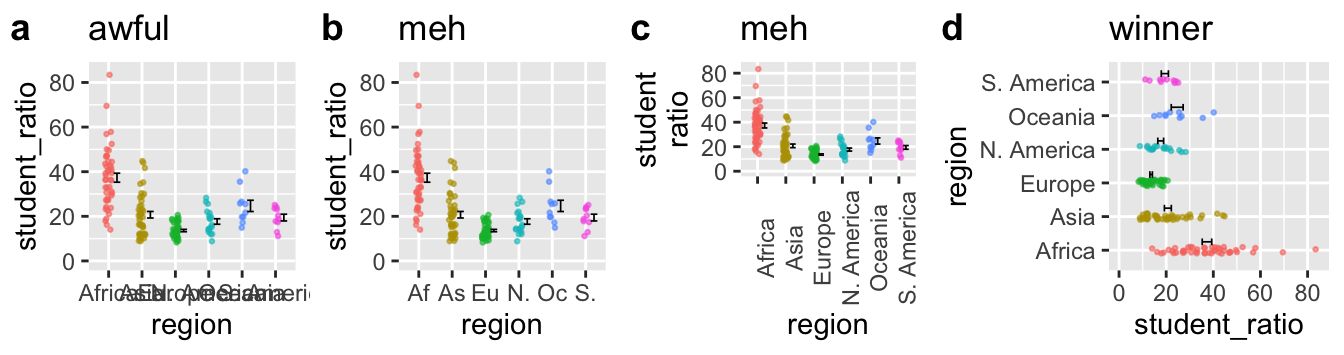
Figure 11.18: When dealing with long x-axis labels, its usually best to rotate the axis (d).
- Shortening labels some code (e.g. as we do with the first two characters in 11.18b) seems like a good idea, but it is not. A code is a cognitive burden for the reader, so when they see As they have to translate this to Asia, making it harder for them to process your point.
- Similarly, rotating the x-axis labels (which we can do in R by adding
theme(axis.text.x = element_text(angle = 90))to the plot) is not a great solution. Someone reading Fig 11.18c must rotate the text in their head, again taking their head out of the data.
- The best solution is to rotate the plot itself (by adding
coord_flip()to the plot). So in Fig 11.18d the reader naturally reads right through to the data.
11.4.3.3 Be consistent
Projects often have numerous plots. Help readers carry the story across plots by being consistent. For example, Figure 11.19 builds on Fig. 11.18d comparing the variation in student to teacher ratios in Asia vs. S. America. Figure 11.19a is not great because our reader needs to associate these regions with difference colors. Because colors in Figure 11.19b are consistent with previous figures, readers can get to the point more quickly.
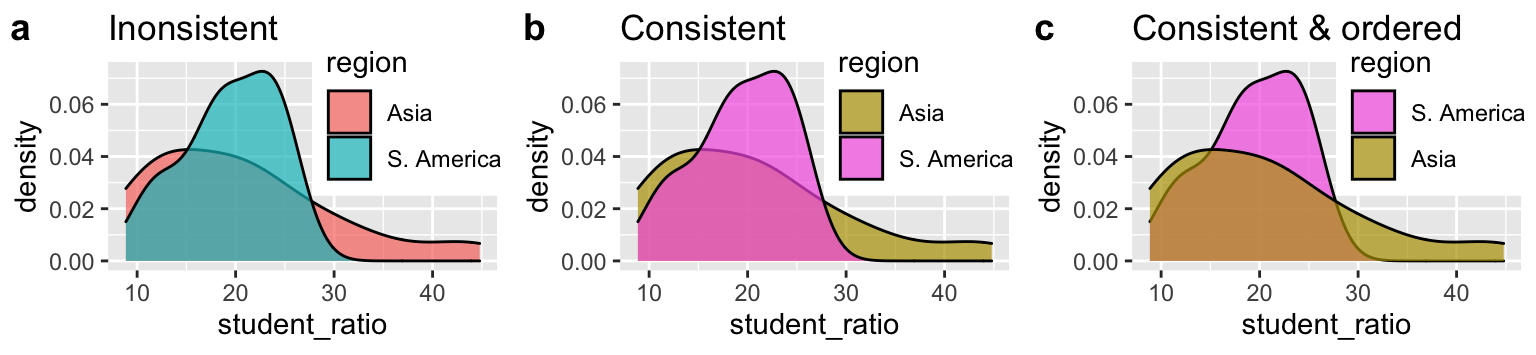
Figure 11.19: Keep mapping consistent across figures, and help readers process results.
11.4.3.4 Order categories sensibly
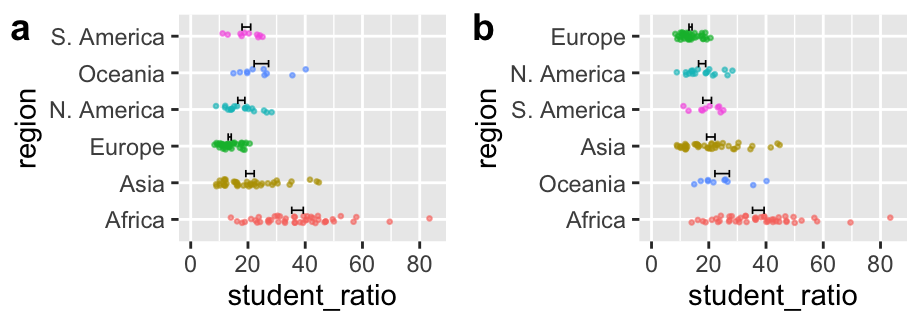
Figure 11.20: Order categories sensibly.
Be deliberate about the order of categories on the x-axis (when it is categorical). If data are ordinal (i.e. they can be ordered naturally, e.g. months of a year) place them in their natural order. When there is no natural order, order them from greatest to lowest means. If here are a bunch of categories with very low values, combine them into ‘other’ and place that after the smallest value (see Figure 11.20 for an example). These rules of thumb will help readers process your data – do not rely on R to do the right thing for you – it naturally orders categories arbitrarily (in alphabetical order) unless you tell it otherwise.
11.4.3.5 Use direct labeling
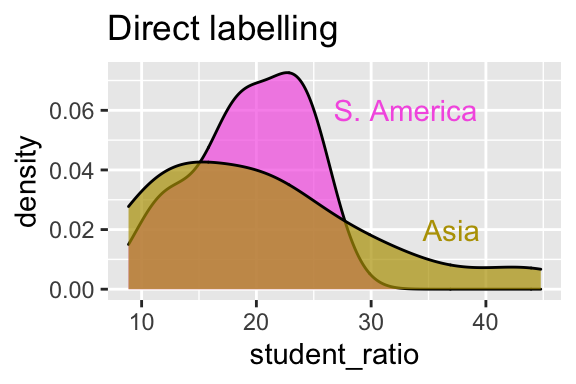
Figure 11.21: Use direct labelling to minimize cognitive burden.
Figure 11.21 improves on Fig. 11.19c by directly labeling our plots. By doing so, we allow readers to directly think about the data, without making them connect color to label.
11.4.3.6 Avoid distractions
After experimented with unconventional clothing, the designer and architect Buckminster Fuller decided to become “the invisible man” by dressing in clothes that would not draw attention to himself. He realized that he wanted people to pay attention to his ideas, not his look. This principle, which underlies the name of my favorite podcast on desig, 99% Invisible, holds for making figures. A good figure calls attention to patterns in the data, not to itself. Tufte (1983) railed against “chartjunk,” “data viz ducks,” needless 3D, and other features that distract from the message in the data.
Don’t use 3D, animation, etc. unnecessarily

Figure 11.22: Just because you can do something, doesn’t mean it’s a good idea.
Occasionally animation or 3D is the right solution to a specific plotting problem (e.g. 3D is useful to show protein structures, animation can show plots over time) – resist the urge to use the elaborations unless you’re dealing with one of those specific problems.
What the duck?
)](https://upload.wikimedia.org/wikipedia/commons/thumb/a/ad/Big_Duck_2018_05.jpg/800px-Big_Duck_2018_05.jpg)
Figure 11.23: The Big Duck (information and image from wikepedia)
Tufte (1983) introduced the term ‘duck’ to describe a self-promoting figure that effectively communicates the composers attempt to be clever, rather than the take home message of the data. The term comes from a building in Flanders, New York, from which the owner sold ducks, duck meat, and duck eggs. This building (Fig. @(duck)) draws attention to itself, it isn’t particularly efficient or good for anything else.
We see similar silliness in advertisements and popular press. But, the most extreme duck I’ve seen is in the banana genome paper (D’Hont et al. 2012). Here the authors’ have convinced me that they can draw a banana, but it takes a lot of work to extract any more information from their figure (Fig. 11.24). In fact in an effort to make a clever figure, they gave up on making an effective Venn Diagram, as the area clearly has no meaning. Watch this optional video if you want to hear a Calling Bullshit rant on Dataviz Ducks.
. [Figure 4](https://www.nature.com/articles/nature11241/figures/4) of the [banana genome paper](https://www.nature.com/articles/nature11241) [@dhont].](https://media.springernature.com/full/springer-static/image/art%3A10.1038%2Fnature11241/MediaObjects/41586_2012_Article_BFnature11241_Fig4_HTML.jpg)
Figure 11.24: This plot is bananas. Figure 4 of the banana genome paper (D’Hont et al. 2012).
You may ask yourself, why do we bring up data viz ducks? They seem pretty hard to make in R and you’re unlikely to make them? Two reasons:
One day, the devil will come to you (in the form of a fever dream, or a boss, or colleague) and will have you thinking about making a silly figure like this. Don’t do it.
Another day you may get carried away with making a pretty figure. While eye catching / memorable graphics are great, do not let the look of figure take precedence over its message.
Stay away from “glass slippers”
Bergstrom and West (2020) describes a new form of data visualization malfeasance in which one specialized and appropriate visualization technique is co-opted for other visualizations. These are rarely successful, as the initial visualization was not built for the new data. This optional video calls this a “glass slipper” as something nice is forced upon an unintended form, and will not fit. Like ducks, glass slippers distract the reader and take their attention away from the data. See the tweet below for an example of a glass slipper.
Lately I've been getting all my best bullshit from promoted tweets. Here from @NexthinkNews, a classic "glass slipper" visualization (https://t.co/09curqq0tU), in which data is shoehorned into a highly specialized and entirely inappropriate format. pic.twitter.com/aYGxBRkHPG
— Calling Bullshit (@callin_bull) March 14, 2019
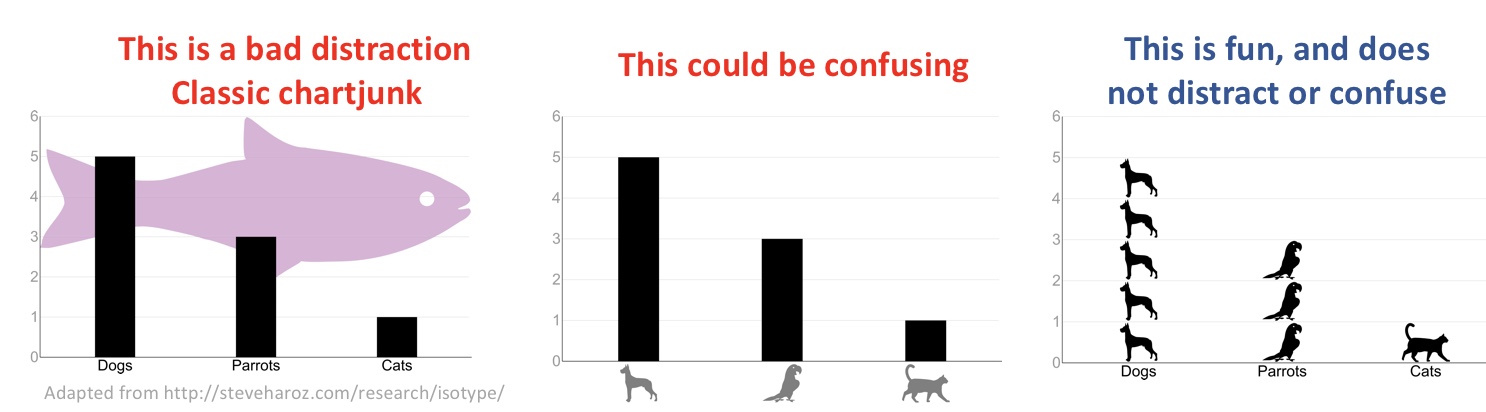
Avoid chartjunk
Unnecessary elaborations that distract a reader from the point of a plot are known as chartjunk. These include eye-catching background colors, data viz ducks, glass slippers, 3D charts etc.
11.4.4 Consider Accessibility and Universal Design
Making figures accessible for all tends to make them better for everyone. Consider the diversity of folks that may look at your figure – for example it could be read by colorblind people, people with poor eyesight, people who print it in black and white etc. A good figure would be interpretable by all of these people.
We have already highlighted a few good practices – for example, describing results of a figure in words can make figures more accessible to blind readers, while direct labeling can make colors visible to colorblind readers. These examples highlight the benefit of universal design – as they make figures better all readers.
11.4.4.1 Color
Picking colors is hard. Be sure that your colors are easy to distinguish, especially if printed in black and white or viewed by a colorblind reader. There are numerous R tools, including the colorspace package which can help. In particular, I suggest putting figures through a color vision deficiency emulator (I suggest http://hclwizard.org/cvdemulator/) to see how your plots would look to readers with a color vision deficiency.
Figure 11.25: ASSIGNMENT: Download this figure showing human hemoglobin levels by population – which is meant to understand the basis of high altitude adaptation in the Andes, Ethiopia, Tibet, and USA (as a control population that has not adapted to high elevation), upload it to http://hclwizard.org/cvdemulator/ (embedded below) and see how these different figures are viewed under different color vision deficiencies.
11.4.4.2 Size
Make sure everything can be read even by people with poor eyesight. Always err on the side of larger text.
](images/02_communication_presentations.png)
Figure 11.26: Bigger text is easier to read. Image from Advanced Data Science
11.4.4.3 Redundant coding
As discussed above, colors can sometimes be difficult to distinguish. Redundant coding (e.g. mapping shape and color onto the same variable) provides readers with more information and more opportunities to discriminate between categories.
11.5 Writing about and discussing figures
Good figures should speak for themselves. Readers should be able to read your figure and come to a reasonable conclusion. But, we do have opportunities to help readers interpret the figure and digest their take home messages. We generally describe, explain, and interpret figures for readers in writing, presentation, or in the figure legend. Let’s make the most of these opportunities.
11.5.1 Writing about figures in text
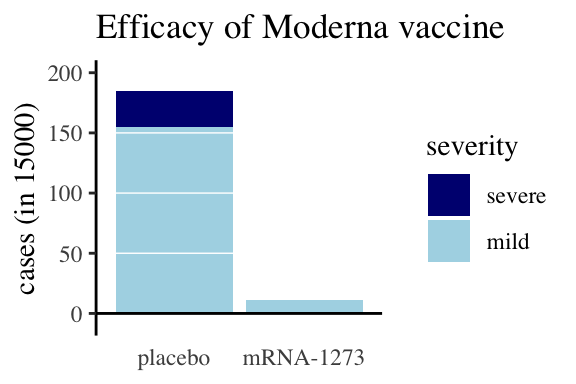
Figure 11.27: Moderna data, as an example for writing about figures
In writing up results, we describe our statistical analyses, summaries and figures in prose. This is an opportunity to reiterate the take-home messages from the analysis and point towards our figures and statistics as evidence for these messages. Let’s think about how to do this, leaving he discussion of statistics to a later time.
A bad write up: Figure 11.27 compares covid cases and severity of these cases for treatments and controls.
Better write up: Figure 11.27 shows an excess of covid cases in people treated with a placebo compared to people getting the moderna mRNA-1273 vaccine (185 of 15,000 individuals in the placebo group caught coronavirus, while only 11 of the 15,000 vaccinated caught coronavirus). Additionally, none of the vaccinated participants who became infected developed a serve case of covid, while 30 of the 185 infected after receiving the placebo developed a serious case (compare the dark blue bar above control and its absence above mRNA-1273).
When reading text about a figure, first look at the figure and think about its message. Then look at what was written and consider:
- What features of the figure support their claims?
- How similar is your interpretation of the figure to theirs?
- Are there elements of the figure that argues against their interpretation?
11.5.2 Writing good figure legends
All (good explanatory) figures should make sense on their own – without a figure legend. However, descriptive figure legends enhance good figures by pointing out take home messages underlying what is shown. So, while figures should make sense without a legend, a good legend should build a deeper appreciation for the results, perhaps including minor details which are not necessary for interpreting results.
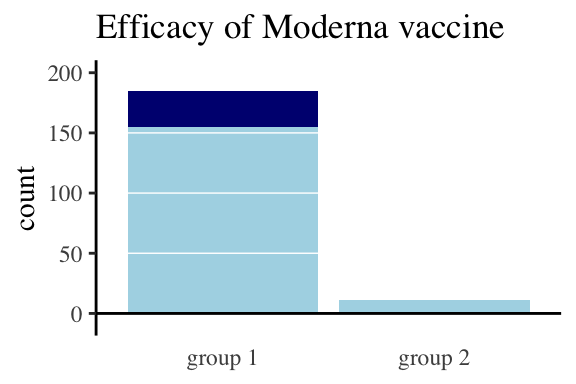
Figure 11.28: This is not what legend is for. Group 1 received the control and Group 2 received the vaccine. Light blue shows mild cases, dark blue is severe.
.](images/goodcovid4legend-1.png)
Figure 11.29: Appropriate legend. Participants receiving a placebo had a much higher incidence of covid than those receiving the Moderna vaccine (the bar on the left is much higher than that on the right). The few cases in the vaccinated group were all mild (represented by light blue bars), while both mild and severe (dark blue) cases arose in the placebo group. Data from the Moderna press release.

Figure 11.30: oops
11.6 Data tables
In Chapter 2 we discussed storing data for analysis in tables. Although it is usually better to present data in figures than tables, we may sometimes want to present results to readers in tables. These tables should not look like those introduced in chapter 2. In general, these tables should follow best practices in making figures (e.g. facilitating comparisons, honesty, readability etc…). These tables need not be tidy, and should not include all raw data, but rather should summarize data and analyses.