Chapter 24 Linear Models
Motivating scenarios: We feel like we have a solid grounding in the ideas behind how we do statistics and now want to actually do them! Here we have a look into linear modeling – an approach that makes up most of the statistics we encounter in the world.
Learning goals: By the end of this chapter you should be able to
- Describe what a linear model is, and what makes a model linear.
- Connect the math of a linear model to a visual representation of the model.
- Use the
lm()function in R to run a linear model and interpret its output to make predictions. - Understand what a residual is
- Be able to calculate a residual.
- Visually identify residuals in a plot.
- Be able to calculate a residual.
- Describe and evaluate the assumptions of a linear model.
- Recognize the limitations of predictions form a linear model.
24.1 What is a linear model?
A statistical model describes the predicted value of a response variable as a function of one or more explanatory variables. The predicted value of the response variable of the \(i^{th}\) observation is \(\hat{Y_i}\), where the hat denotes that this is a prediction. This prediction, \(\hat{Y_i}\) is a function of values of the explanatory variables for observation \(i\) (Equation (24.1)).
\[\begin{equation} \hat{Y_i} = f(\text{explanatory variables}_i) \tag{24.1} \end{equation}\]
A linear model predicts the response variable by adding up all components of the model. So, for example, \(\hat{Y_i}\) equals the parameter estimate for the “intercept,” \(a\) plus its value for the first explanatory variable, \(y_{1,i}\) times the effect of this variable, \(b_1\), plus its value for the second explanatory variable, \(y_{2,i}\) times the effect of this variable, \(b_2\) etc all the way through all predictors (Eq. (24.2)).
\[\begin{equation} \hat{Y_i} = a + b_1 y_{1,i} + b_2 y_{2,i} + \dots{} \tag{24.2} \end{equation}\]
Linear models can include e.g. squared, and geometric functions too, so long as we get out predictions by adding up all the components of the model. Similarly, explanatory variables can be combined, too so we can include cases in which the effect of explanatory variable two depends on the value of explanatory variable one, by including an interaction in the linear model.
Optional: A view from linear algebra
If you have a background in linear algebra, it might help to see a linear model in matrix notation.
The first matrix in Eq (24.3) is known as the design matrix. Each row corresponds to an individual, and each column in the \(i^{th}\) row corresponds to this individual \(i\)’s value for the explanatory variable in this row. We take the dot product of this matrix and our estimated parameters to get the predictions for each individual. Equation (24.3) has \(n\) individuals and \(k\) explanatory variables. Note that every individual has a value of 1 for the intercept.
\[\begin{equation} \begin{pmatrix} 1 & y_{1,1} & y_{2,1} & \dots & y_{k,1} \\ 1 & y_{1,2} & y_{2,2} & \dots & y_{k,2} \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 1 & y_{1,n} & y_{2,n} & \dots & y_{k,n} \end{pmatrix} \cdot \begin{pmatrix} a \\ b_{1}\\ b_{2}\\ \vdots \\ b_{k} \end{pmatrix} = \begin{pmatrix} \hat{Y_1} \\ \hat{Y_2}\\ \vdots \\ \hat{Y_n} \end{pmatrix} \tag{24.3} \end{equation}\]
24.2 The one sample t-test as the simplest linear model
We’re going to see some complex linear models in the coming weeks. For now, let’s start with the simplest – let’s view the one sample t-test as a linear model. In this case,
- All predicted values \(\hat{Y_i}\) will be the same for all observations because we are not including any explanatory variables.
- We are testing the null that the “intercept” \(a\) equals its predicted value under the null \(\mu_0=0\).
So, our design matrix is simple – every individual’s prediction is one times the intercept. We tell R that we want to run this linear model with the lm() function. Because we have no explanatory variables, we type lm(<response_var> ~ 1, data= <dataset>). We the get a summary of the linear model by piping its output to summary().lm
For example, take the the elevations range change data from Chapter 23:
range_shift_file <- "https://whitlockschluter3e.zoology.ubc.ca/Data/chapter11/chap11q01RangeShiftsWithClimateChange.csv"
range_shift <- read_csv(range_shift_file)
range_shift_lm <- lm(elevationalRangeShift ~ 1, data = range_shift)
range_shift_lm %>% summary.lm()##
## Call:
## lm(formula = elevationalRangeShift ~ 1, data = range_shift)
##
## Residuals:
## Min 1Q Median 3Q Max
## -58.629 -23.379 -3.529 24.121 69.271
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 39.329 5.507 7.141 6.06e-08 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 30.66 on 30 degrees of freedomLet’s focus on the line under coefficients, as that is the most relevant one. Reassuringly, our answers match the output of the t.test() function (Section 23.5.4). Our t-value is still 7.141 , and our p-value is still \(6.06 \times 10^{-8}\). That’s because all calculations are the exact same – the t-value is still the distance, in standard errors, between the null and our estimate.
Again, we can tidy the results of this model with the tidy() function in the broom package.
library(broom)
tidy(range_shift_lm )## [38;5;246m# A tibble: 1 x 5[39m
## term estimate std.error statistic p.value
## [3m[38;5;246m<chr>[39m[23m [3m[38;5;246m<dbl>[39m[23m [3m[38;5;246m<dbl>[39m[23m [3m[38;5;246m<dbl>[39m[23m [3m[38;5;246m<dbl>[39m[23m
## [38;5;250m1[39m (Intercept) 39.3 5.51 7.14 0.000[4m0[24m[4m0[24m[4m0[24m060[4m6[24mSo here \(\hat{Y_i} = a = 39.329\) – that is, we predict that a given species range moved 39.329 meters upwards.
24.3 Residuals describe the difference between predictions and observed values.

Of course, most observations will not exactly equal their predicted value. Rather, an observation \(Y_i\) will differ from its predicted value, \(\hat{Y_i}\) by some amount, \(e_i\), called the residual.
\[\begin{equation} \begin{split}Y_i &= \hat{Y_i} + e_i\\ e_i&=Y_i-\hat{Y_i} \end{split} \tag{24.4} \end{equation}\]
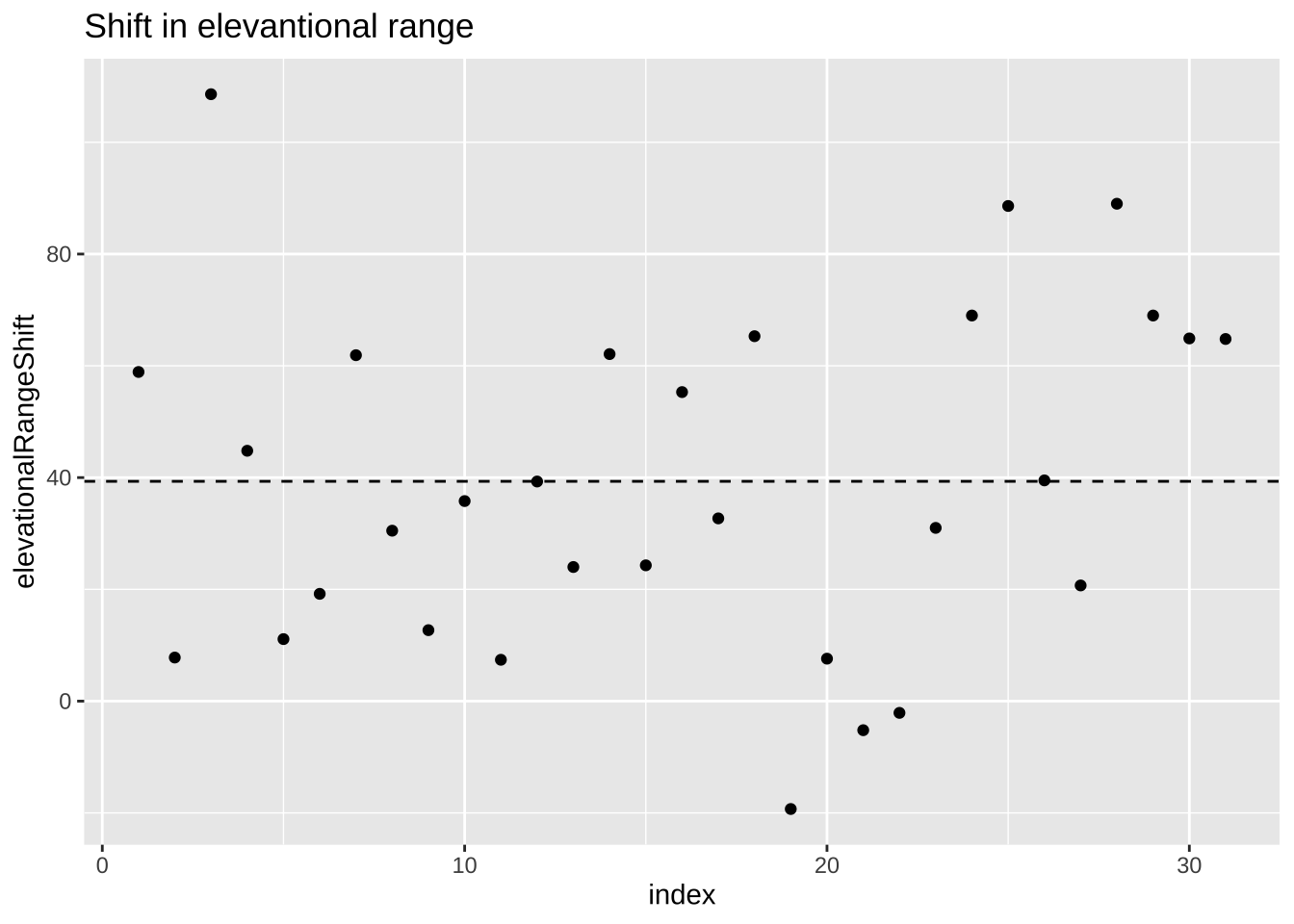
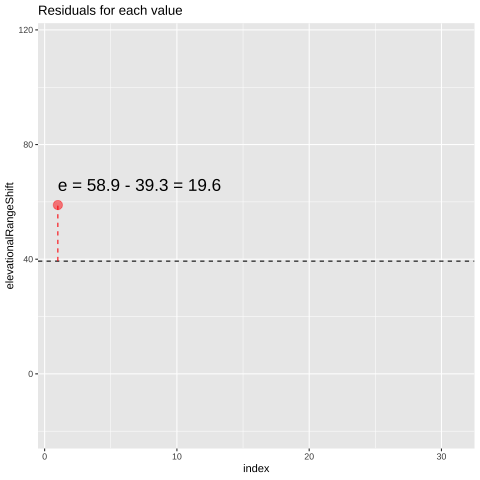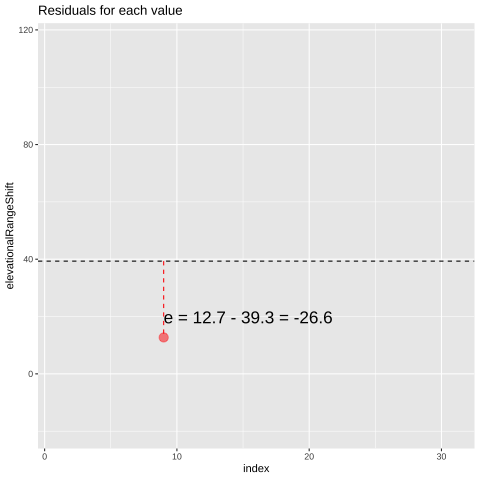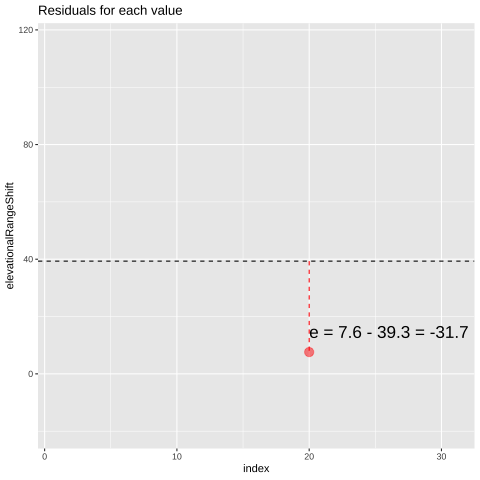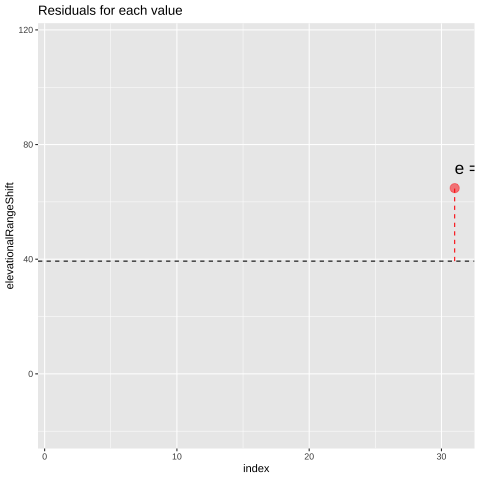
Figure 24.1: Change in elevational range, arbitrarily ordered by species ID. All data are shown in the plot on the left. The plot on the right calculates residuals as the difference between expectation and observation.
The augment() function in the broom package is awesome in that it shows us our values (elevationalRangeShift) the prediction (.fitted) and residual (.resid) for each observation.
library(broom)
range_shift_lm %>%
augment() %>%
dplyr::select(elevationalRangeShift, .fitted, .resid)## [38;5;246m# A tibble: 31 x 3[39m
## elevationalRangeShift .fitted .resid
## [3m[38;5;246m<dbl>[39m[23m [3m[38;5;246m<dbl>[39m[23m [3m[38;5;246m<dbl>[39m[23m
## [38;5;250m 1[39m 58.9 39.3 19.6
## [38;5;250m 2[39m 7.8 39.3 -[31m31[39m[31m.[39m[31m5[39m
## [38;5;250m 3[39m 109. 39.3 69.3
## [38;5;250m 4[39m 44.8 39.3 5.47
## [38;5;250m 5[39m 11.1 39.3 -[31m28[39m[31m.[39m[31m2[39m
## [38;5;250m 6[39m 19.2 39.3 -[31m20[39m[31m.[39m[31m1[39m
## [38;5;250m 7[39m 61.9 39.3 22.6
## [38;5;250m 8[39m 30.5 39.3 -[31m8[39m[31m.[39m[31m83[39m
## [38;5;250m 9[39m 12.7 39.3 -[31m26[39m[31m.[39m[31m6[39m
## [38;5;250m10[39m 35.8 39.3 -[31m3[39m[31m.[39m[31m53[39m
## [38;5;246m# … with 21 more rows[39m24.4 More kinds of linear models
Some common linear models include a two-sample t-test, an ANOVA, a regression, and an ANCOVA. We will go over these in coming weeks, so for now let’s just have a quick sneak preview of the two sample t-test and the regression.
24.4.1 A two-sample t-test as a linear model
We often want to know the difference in means between two (unpaired) groups, and test the null hypothesis that these means are identical. For this linear model,
- \(a\) is the estimate mean for one group,
- \(b_1\) is the average difference between individuals in that and the other group.
- \(y_{1,i}\) is an “indicator variable” equaling zero for individuals in group 1 and one for individuals in the other group.
So, the equation \(\hat{Y_i} = a + Y_{1,i} \times b_1\) is
\[\begin{equation} \hat{Y_i}= \begin{cases} a + 0 \times b_1 & = a, &\text{if }\ i \text{ is in group 1}\\ a + 1 \times b_1 & = a +b_1, &\text{if }\ i\text{is in group 2} \end{cases} \end{equation}\]
24.4.1.1 Example: Lizard survival
Could long spikes protect horned lizards from being killed by the loggerhead shrike? The loggerhead shrike is a small predatory bird that skewers its victims on thorns or barbed wire. Young, Brodie, and Brodie (2004) compared horns from lizards that had been killed by shrikes to 154 live horned lizards. The data are plotted below.
lizards <- read_csv("https://whitlockschluter3e.zoology.ubc.ca/Data/chapter12/chap12e3HornedLizards.csv") %>% na.omit()
ggplot(lizards, aes(x = Survival, y = squamosalHornLength, color = Survival)) +
geom_jitter(height = 0, width = .2, size = 3, alpha = .5, show.legend = FALSE) +
stat_summary(fun.data = "mean_cl_normal", color = "black")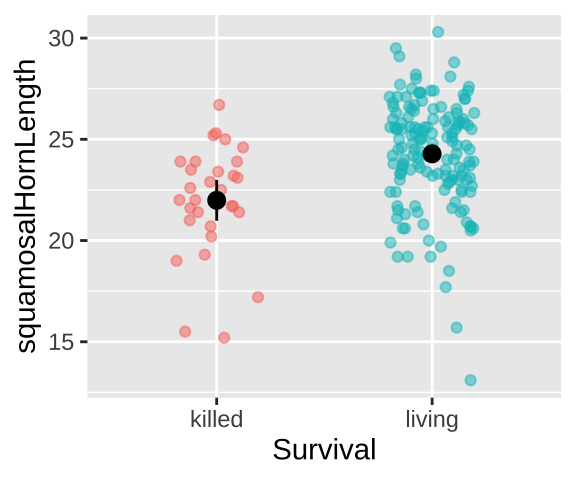
Lizard summary stats
The means for each group are
lizards %>%
group_by(Survival) %>%
summarise(mean_squamosalHornLength = mean(squamosalHornLength))## [38;5;246m# A tibble: 2 x 2[39m
## Survival mean_squamosalHornLength
## [3m[38;5;246m<chr>[39m[23m [3m[38;5;246m<dbl>[39m[23m
## [38;5;250m1[39m killed 22.0
## [38;5;250m2[39m living 24.3Lizard linear model
We can represent this as a linear model
lizard_lm <- lm(squamosalHornLength ~ Survival, data = lizards)
lizard_lm##
## Call:
## lm(formula = squamosalHornLength ~ Survival, data = lizards)
##
## Coefficients:
## (Intercept) Survivalliving
## 21.987 2.295We can see that the intercept is the mean squamosal Horn Length for killed lizards, and Survivalliving is how much longer, on average horn length is in surviving lizards.
We can look at the output of the linear model, below.
lizard_lm %>% summary.lm()##
## Call:
## lm(formula = squamosalHornLength ~ Survival, data = lizards)
##
## Residuals:
## Min 1Q Median 3Q Max
## -11.1812 -1.2812 0.2688 1.7188 6.0188
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 21.9867 0.4826 45.556 < 2e-16 ***
## Survivalliving 2.2945 0.5275 4.349 2.27e-05 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.643 on 182 degrees of freedom
## Multiple R-squared: 0.09415, Adjusted R-squared: 0.08918
## F-statistic: 18.92 on 1 and 182 DF, p-value: 2.27e-05From this, we estimate \(\text{horn length}_i = 22.99 + 2.29 \times \text{living}_i\) where living is 0 for killed lizards and 1 for living lizards.
The t value and p-value for the intercept for (Intercept) describe the difference between estimated horn length and zero. This is a very silly null hypothesis, and we ignore that \(t\) and p-value, but we do care about this estimate and uncertainty.
By contrast the t value and p-value for the Survivalliving describe the difference between estimated horn length of surviving and dead lizards. This is an interesting null hypothesis – we conclude that the difference between the extreme 2.3mm difference in the horn lengths of killed and surviving lizards is unexpected by chance (\(t = 4.35\), \(df = 182\), \(p = 2.27 \times 10^{-5}\)).
Lizard residuals
Again, we can look at this in more detail with the augment function in the broom package.
lizard_lm %>%
augment() %>%
dplyr::select(squamosalHornLength, Survival, .fitted, .resid)## [38;5;246m# A tibble: 184 x 4[39m
## squamosalHornLength Survival .fitted .resid
## [3m[38;5;246m<dbl>[39m[23m [3m[38;5;246m<chr>[39m[23m [3m[38;5;246m<dbl>[39m[23m [3m[38;5;246m<dbl>[39m[23m
## [38;5;250m 1[39m 21.7 killed 22.0 -[31m0[39m[31m.[39m[31m287[39m
## [38;5;250m 2[39m 25.1 living 24.3 0.819
## [38;5;250m 3[39m 25.9 living 24.3 1.62
## [38;5;250m 4[39m 22.4 living 24.3 -[31m1[39m[31m.[39m[31m88[39m
## [38;5;250m 5[39m 21.5 living 24.3 -[31m2[39m[31m.[39m[31m78[39m
## [38;5;250m 6[39m 23.2 living 24.3 -[31m1[39m[31m.[39m[31m0[39m[31m8[39m
## [38;5;250m 7[39m 15.2 killed 22.0 -[31m6[39m[31m.[39m[31m79[39m
## [38;5;250m 8[39m 25.8 living 24.3 1.52
## [38;5;250m 9[39m 24.5 living 24.3 0.219
## [38;5;250m10[39m 25.5 living 24.3 1.22
## [38;5;246m# … with 174 more rows[39mThis shows the residuals (.resid), as the difference between the predicted values, \(\hat{Y_i}\) (.fitted) and the observed values, \(Y_i\) (squamosalHornLength). Note that the \(\hat{Y_i}\) differs for living and killed lizards.
24.4.2 A regression as a linear model
Let’s revisit our example in which we looked at the correlation by disease and sperm viability from Chapter 18. Remember, we looked into the hypothesis that there is a trade off between investment in disease resistance and reproduction using data from Simmons and Roberts (2005), who assayed sperm viability and lysozyme activity (a measure of defense against bacteria) in 39 male crickets.
In Chapter 18, we looked into a correlation, which showed us how the two variables changed together but did not allow us to make quantitative predictions. Now we will look into interpreting the regression as a linear model. We will consider how to make a regression later, but for now just know that we are modeling y (in this case, lysozyme activity) as a function of x (in this case, sperm viability), by a simple line.
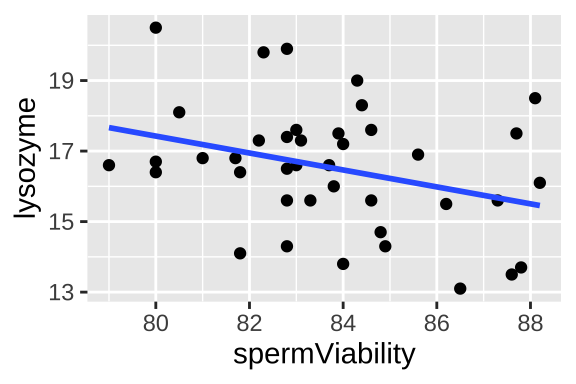
Figure 24.2: Lysozyme activity deceases with sperm viability in crickets. Data from Simmons and Roberts (2005).
As usual, we can generate the linear model with the lm() function, here predicting lysozyme activity as a function of sperm viability.
cricket_lm <- lm(lysozyme ~ spermViability, data = crickets)
cricket_lm ##
## Call:
## lm(formula = lysozyme ~ spermViability, data = crickets)
##
## Coefficients:
## (Intercept) spermViability
## 36.6400 -0.2402So from this model, we predict that an individual’s lysozyme activity equals 36.64 minus 0.24 times his sperm viability. This prediction corresponds to the line in figure 24.2 and is mathematically:
\[\text{lysozyme activity}_i = 36.64 -0.24 \times \text{sperm viability}_i+e_i\] Again, we can use the augment function in the broom package to look at actual values (\(Y_i\)), predicted values (\(\hat{Y_i}\)) and residuals \(e_i\). In this case, there are a bunch of different predictions because there are a bunch of different sperm viability scores.
augment(cricket_lm) %>%
dplyr::select(lysozyme, spermViability, .fitted, .resid)## [38;5;246m# A tibble: 40 x 4[39m
## lysozyme spermViability .fitted .resid
## [3m[38;5;246m<dbl>[39m[23m [3m[38;5;246m<dbl>[39m[23m [3m[38;5;246m<dbl>[39m[23m [3m[38;5;246m<dbl>[39m[23m
## [38;5;250m 1[39m 16.6 79 17.7 -[31m1[39m[31m.[39m[31m0[39m[31m7[39m
## [38;5;250m 2[39m 20.5 80 17.4 3.07
## [38;5;250m 3[39m 16.4 80 17.4 -[31m1[39m[31m.[39m[31m0[39m[31m3[39m
## [38;5;250m 4[39m 16.7 80 17.4 -[31m0[39m[31m.[39m[31m725[39m
## [38;5;250m 5[39m 18.1 80.5 17.3 0.795
## [38;5;250m 6[39m 16.8 81 17.2 -[31m0[39m[31m.[39m[31m385[39m
## [38;5;250m 7[39m 16.8 81.7 17.0 -[31m0[39m[31m.[39m[31m217[39m
## [38;5;250m 8[39m 16.4 81.8 17.0 -[31m0[39m[31m.[39m[31m593[39m
## [38;5;250m 9[39m 14.1 81.8 17.0 -[31m2[39m[31m.[39m[31m89[39m
## [38;5;250m10[39m 17.3 82.2 16.9 0.403
## [38;5;246m# … with 30 more rows[39mWe can look at this significance of our predictions with summary.lm()
cricket_lm %>% summary.lm()##
## Call:
## lm(formula = lysozyme ~ spermViability, data = crickets)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.8931 -1.0410 -0.1610 0.8385 3.1471
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 36.6400 9.4027 3.897 0.000383 ***
## spermViability -0.2402 0.1123 -2.139 0.038893 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.685 on 38 degrees of freedom
## Multiple R-squared: 0.1075, Adjusted R-squared: 0.08401
## F-statistic: 4.577 on 1 and 38 DF, p-value: 0.03889As above, the p-value for the intercept is silly – of course crickets have non-zero sperm viability. The more interesting result is that the 0.24 decrease in lysozyme activity with every percent increase in sperm viability is significant at the \(\alpha = 0.05\) level (\(t = -2.139\), \(df = 38\), \(p = 0.0389\)), so we reject the null hypothesis, and conclude that lysozyme activity decreases with increasing sperm viability.
24.5 Assumptions of a linear model
A linear model assumes
- Linearity: That is to say that our observations are appropriately modeled by adding up all predictions in our equation. We can evaluate this by seeing that residuals are independent of predictors.
- Homoscedasticity: The variance of residuals is independent of the predicted value, \(\hat{Y_i}\) is the same for any value of X.
- Independence: Observations are independent of each other (aside from the predictors in the model).
- Normality: That residual values are normally distributed.
- Data are collected without bias as usual.
These vary in how hard they are to diagnose. But the autoplot() function in the ggfortify package helps us evaluate assumptions of
- Making sure the residuals are independent of predictors (a diagnosis for linearity). A Residuals vs Fitted plot with a slope near zero is consistent with this assumption.
- Making sure that the mean and variance in residuals are independent of predictors. A Scale-location plot with a slope near zero is consistent with this assumption.
- Normality of residuals. A qq plot with a slope near one is consistent with this assumption.

Have a look at the diagnostic plots from our models to see if they look ok!
library(ggfortify)
autoplot(lizard_lm)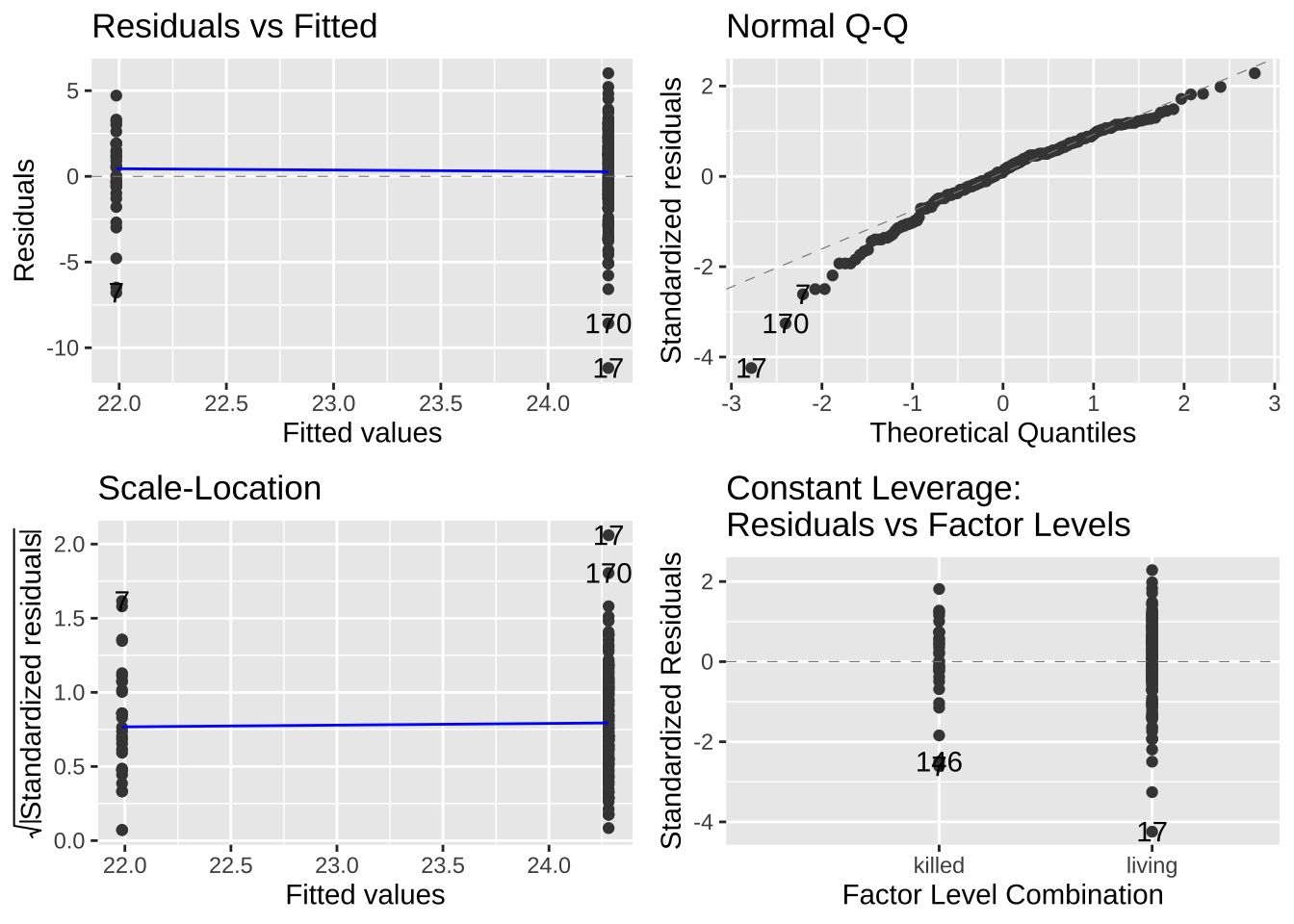
autoplot(cricket_lm)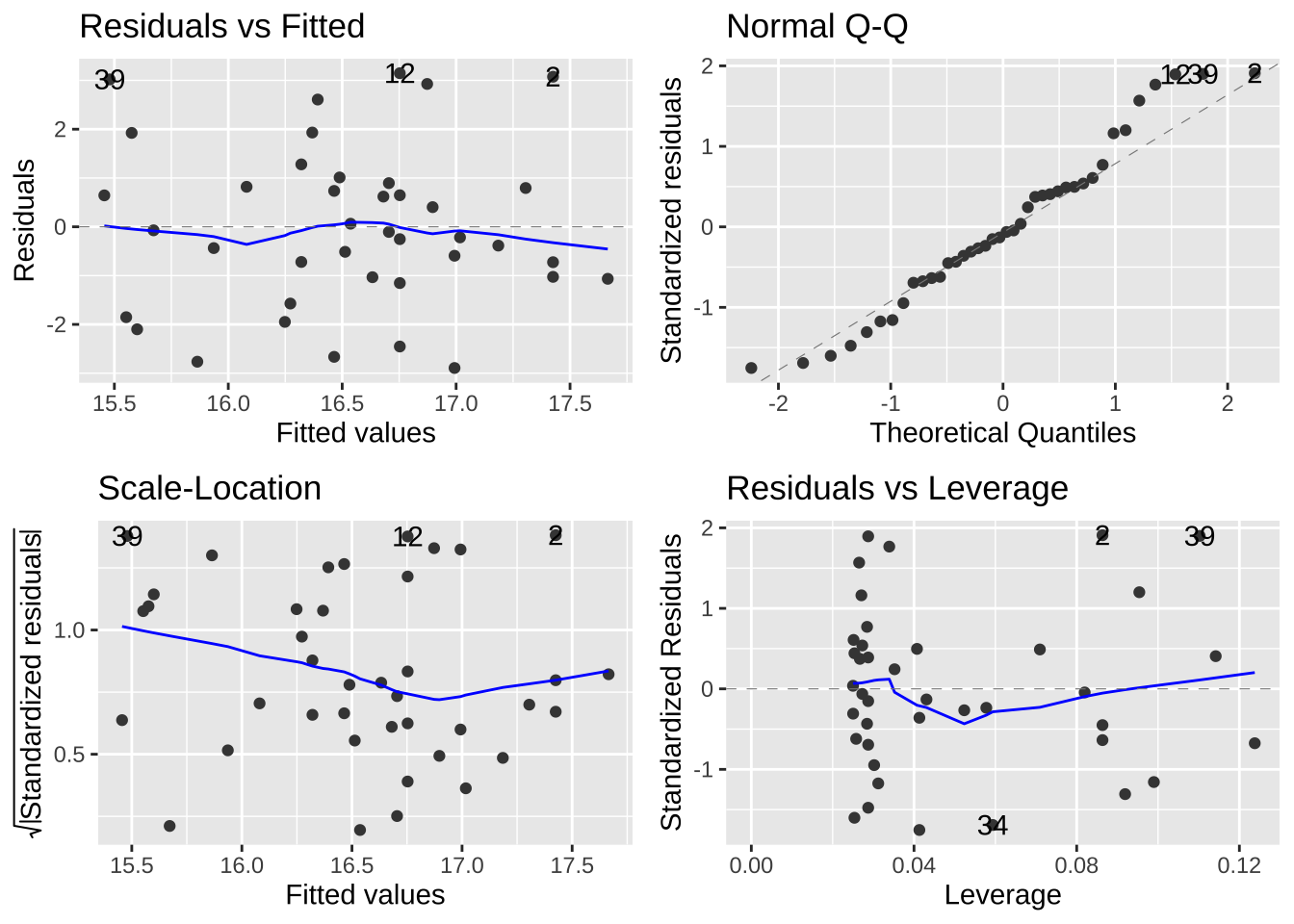
24.6 Predictions from linear models
Linear models can be used to predict new results. However, predictions only apply to the range of values investigated in the initial regression and to cases with similar conditions.