Chapter 20 財務管理課堂數據集之特徵值工程
20.1 旭
這一套微微書希望借用「財務管理課堂數據集」示範「機器學習建模」的零零總總,進而磨練「計算思維的解題模式」,當然也同時學習如何撰寫R統計計算語言。基本上,在這裡、這一套微微書,我們要磨練
如何建模並預測財務管理的學期總成績?
這是「財務管理」這一門課的最後三項成績。
如果作者小編跑去問好朋友,上述三項成績在「學期總成績」的佔比,那麼一下子就可以「成功」預測每一位修課學生的學期總成績。但是,
我們不希望這麼做!
原因是,「猜測 = 估計 + 預測」是統計學系的基本功,也是「建模工程師」與「數據科學家」的基本養成訓練。這是一個難得的機會,讓我們可以「活用自身大學生活的智慧」,加上「統計專業的技術」,再加上「R統計語言的多元觸角」,好好「猜一猜」
2014年逢甲大學風保系某一班財務管理的學期總成績。
為此,我們在這一章開啟作者小編所謂的「特徵值工程」。在這裏,這一套微微書,作者小編所謂的「特徵值工程」是一種「腦力激盪」、「無中生有」的「創意活動」。為什麼,我們不需要「財務管理」的專業知識,卻可以在這裡「大談」
腦力激盪
無中生有
因為,
我們談的是「課堂數據」不是「財管數據」!
加上
你我不是現期的大學生,就是早期的大學生,都曾親臨過大學生學習專業知識的場域!即便,不曾是大學生,只要「上過學」就有感覺!不用怕!絕對可以的!
20.3 每堂課出缺席紀錄
「出缺席紀錄」登載「每一次上課每節課是否到課」,
- 如果是「1」表示「出席」,如果是「0」表示「缺席」;
- 然後再加上「正課後的實習課是否到課」,一樣如果是「1」表示「出席」,如果是「0」表示「缺席」。
20.3.1 出缺席紀錄(log)可以變出什麼數字?
抓一些「樣本」看看:
## # A tibble: 10 × 4
## v100101 v100102 v100103 v1001
## <dbl> <dbl> <dbl> <dbl>
## 1 0 1 1 0
## 2 0 0 0 0
## 3 0 0 0 0
## 4 1 1 1 1
## 5 0 1 1 1
## 6 1 1 1 1
## 7 1 1 1 1
## 8 0 1 1 1
## 9 1 1 1 1
## 10 1 1 1 1先看「正課」。只有三種樣式(pattern):
- 「
111」表示「出席正課」,百分百,因為每一週「財務管理正課只上三小時」。 - 「
011」表示「遲到」,因為這一位學生「出席第二堂課跟第三堂課」。 - 「
000」表示「缺席正課」,百分百,因為這一位學生「三堂課都被記錄為0」。
根據上述觀察,「或許」我們可以建議這樣的新創數字:
- 10/01第一堂課缺席、
ifelse(week1$v100101 == 0, "10/01第一堂課缺席", "10/01第一堂課出席")## [1] "10/01第一堂課出席" "10/01第一堂課出席" "10/01第一堂課出席"
## [4] "10/01第一堂課出席" "10/01第一堂課出席" "10/01第一堂課出席"
## [7] "10/01第一堂課出席" "10/01第一堂課出席" "10/01第一堂課缺席"
## [10] "10/01第一堂課出席" "10/01第一堂課出席" "10/01第一堂課出席"
## [13] "10/01第一堂課出席" "10/01第一堂課出席" "10/01第一堂課出席"
## [16] "10/01第一堂課出席" "10/01第一堂課出席" "10/01第一堂課出席"
## [19] "10/01第一堂課出席" "10/01第一堂課出席" "10/01第一堂課出席"
## [22] "10/01第一堂課缺席" "10/01第一堂課出席" "10/01第一堂課出席"
## [25] "10/01第一堂課出席" "10/01第一堂課出席" "10/01第一堂課缺席"
## [28] "10/01第一堂課出席" "10/01第一堂課出席" "10/01第一堂課出席"
## [31] "10/01第一堂課缺席" "10/01第一堂課出席" "10/01第一堂課出席"
## [34] "10/01第一堂課出席" "10/01第一堂課出席" "10/01第一堂課出席"
## [37] "10/01第一堂課出席" "10/01第一堂課出席" "10/01第一堂課出席"
## [40] "10/01第一堂課出席" "10/01第一堂課出席" "10/01第一堂課出席"
## [43] "10/01第一堂課缺席" "10/01第一堂課出席" "10/01第一堂課出席"
## [46] "10/01第一堂課出席" "10/01第一堂課出席" "10/01第一堂課出席"
## [49] "10/01第一堂課缺席" "10/01第一堂課出席" "10/01第一堂課缺席"
## [52] "10/01第一堂課出席" "10/01第一堂課出席" "10/01第一堂課缺席"
## [55] "10/01第一堂課出席" "10/01第一堂課出席" "10/01第一堂課出席"
## [58] "10/01第一堂課出席" "10/01第一堂課出席" "10/01第一堂課出席"
## [61] "10/01第一堂課出席" "10/01第一堂課出席" "10/01第一堂課缺席"
## [64] "10/01第一堂課出席" "10/01第一堂課出席" "10/01第一堂課出席"
## [67] "10/01第一堂課缺席" "10/01第一堂課出席" "10/01第一堂課出席"
## [70] "10/01第一堂課出席" "10/01第一堂課出席" "10/01第一堂課出席"
## [73] "10/01第一堂課出席" "10/01第一堂課出席" "10/01第一堂課出席"
## [76] "10/01第一堂課出席" "10/01第一堂課出席" "10/01第一堂課出席"
## [79] "10/01第一堂課缺席" "10/01第一堂課出席" "10/01第一堂課出席"
## [82] "10/01第一堂課出席" "10/01第一堂課出席" "10/01第一堂課出席"
## [85] "10/01第一堂課出席"突然有人發現:
unique(week1$v100101)## [1] 1 0 999加上
unique(ifelse(week1$v100101 == 0, "10/01第一堂課缺席", "10/01第一堂課出席"))## [1] "10/01第一堂課出席" "10/01第一堂課缺席"意味著,我們認定「記錄為『999』的學生『10/01第一堂課出席』」。很明顯,這是一個錯誤。
- 第一堂課缺席、
p100101 <- ifelse(week1$v100101 == 0, "缺席", "出席")
p100101## [1] "出席" "出席" "出席" "出席" "出席" "出席" "出席" "出席" "缺席" "出席"
## [11] "出席" "出席" "出席" "出席" "出席" "出席" "出席" "出席" "出席" "出席"
## [21] "出席" "缺席" "出席" "出席" "出席" "出席" "缺席" "出席" "出席" "出席"
## [31] "缺席" "出席" "出席" "出席" "出席" "出席" "出席" "出席" "出席" "出席"
## [41] "出席" "出席" "缺席" "出席" "出席" "出席" "出席" "出席" "缺席" "出席"
## [51] "缺席" "出席" "出席" "缺席" "出席" "出席" "出席" "出席" "出席" "出席"
## [61] "出席" "出席" "缺席" "出席" "出席" "出席" "缺席" "出席" "出席" "出席"
## [71] "出席" "出席" "出席" "出席" "出席" "出席" "出席" "出席" "缺席" "出席"
## [81] "出席" "出席" "出席" "出席" "出席"- 第一堂課遲到、
ifelse(week1$v100101 == 0 & week1$v100102 == 1, "遲到", "出席")## [1] "出席" "出席" "出席" "出席" "出席" "出席" "出席" "出席" "出席" "出席"
## [11] "出席" "出席" "出席" "出席" "出席" "出席" "出席" "出席" "出席" "出席"
## [21] "出席" "出席" "出席" "出席" "出席" "出席" "出席" "出席" "出席" "出席"
## [31] "遲到" "出席" "出席" "出席" "出席" "出席" "出席" "出席" "出席" "出席"
## [41] "出席" "出席" "遲到" "出席" "出席" "出席" "出席" "出席" "出席" "出席"
## [51] "出席" "出席" "出席" "出席" "出席" "出席" "出席" "出席" "出席" "出席"
## [61] "出席" "出席" "出席" "出席" "出席" "出席" "遲到" "出席" "出席" "出席"
## [71] "出席" "出席" "出席" "出席" "出席" "出席" "出席" "出席" "出席" "出席"
## [81] "出席" "出席" "出席" "出席" "出席"但是
ifelse(week1$v100101 == 0 & week1$v100102 == 1, "遲到",
ifelse(week1$v100101 == 0 & week1$v100102 == 0, "缺席", "出席"))## [1] "出席" "出席" "出席" "出席" "出席" "出席" "出席" "出席" "缺席" "出席"
## [11] "出席" "出席" "出席" "出席" "出席" "出席" "出席" "出席" "出席" "出席"
## [21] "出席" "缺席" "出席" "出席" "出席" "出席" "缺席" "出席" "出席" "出席"
## [31] "遲到" "出席" "出席" "出席" "出席" "出席" "出席" "出席" "出席" "出席"
## [41] "出席" "出席" "遲到" "出席" "出席" "出席" "出席" "出席" "缺席" "出席"
## [51] "缺席" "出席" "出席" "缺席" "出席" "出席" "出席" "出席" "出席" "出席"
## [61] "出席" "出席" "缺席" "出席" "出席" "出席" "遲到" "出席" "出席" "出席"
## [71] "出席" "出席" "出席" "出席" "出席" "出席" "出席" "出席" "缺席" "出席"
## [81] "出席" "出席" "出席" "出席" "出席"綜合以上:我們應該細看每一種可能的情況。
x <- expand.grid(0:1, 0:1, 0:1, 0:1)
colnames(x) <- c("p01", "p02", "p03", "pTA")
DT::datatable(x, options = list(pageLength = 16))觀察過後,每一種組合都是「唯一的」。這讓作者小編想到「大數據時代」的「標籤工程」或許可以解決上述的「困境」!
20.3.2 建議一種標籤工程
根據上述表格呈現的細節,
如果有一位同學某個禮拜的紀錄是「1110」,就表示「她/他出席了正課但是缺席了實習課」,因為實習課是第四節,11:10到12:00。
如果紀錄是「0110」,就表示「某一位同學遲到一堂正課而且缺席了實習課」。
諸如此類的「出缺席樣式(pattern)」,讓我們可以研究「出缺席樣式與小考成績的關係」,「出缺席樣式與期中考成績的關係」,「出缺席樣式與期末考成績的關係」,當然也可以研究「出缺席樣式與期末總成績的關係」。「出缺席樣式」除了可以發展出「出席正課實習課缺席」、「遲到一節正課實習課缺席」這一類的標籤:
x$label <- rep("", 16)
x$label[1] <- "正課實習課都缺席"
x$label[2] <- "早退兩節正課實習課缺席"
x$label[3] <- "正課遲到又早退實習課缺席"
x$label[4] <- "正課早退實習課缺席"
x$label[5] <- "遲到兩節正課實習課缺席"
x$label[6] <- "摸魚一節正課實習課缺席"
x$label[7] <- "遲到一節正課實習課缺席"
x$label[8] <- "出席正課實習課缺席"
x$label[9] <- "缺席正課實習課出席"
x$label[10] <- "早退兩節正課實習課出席"
x$label[11] <- "正課遲到又早退實習課出席"
x$label[12] <- "正課早退實習課出席"
x$label[13] <- "遲到兩節正課實習課出席"
x$label[14] <- "摸魚一節正課實習課出席"
x$label[15] <- "遲到一節正課實習課出席"
x$label[16] <- "正課實習課都出席"
DT::datatable(x, options = list(pageLength = 16))也可以算出「當週正課出席堂數」與「當週正課出席堂數比例」:
x$當週正課出席堂數 <- apply(x[,1:3], 1, sum)
x$當週正課出席堂數比例 <- round(x$當週正課出席堂數/3, 3)
DT::datatable(x[,c(1,2,3,6,7)], options = list(pageLength = 16))如果連實習課的出缺席紀錄一起算,也可以算出「當週出席堂數」與「當週出席堂數比例」:
x$當週出席堂數 <- apply(x[,1:4], 1, sum)
x$當週出席堂數比例 <- round(x$當週出席堂數/4, 3)
DT::datatable(x[,c(1,2,3,4,8,9)], options = list(pageLength = 16))20.3.3 為每堂課出缺席紀錄貼上標籤
以下是「2014-10-01」的出缺席原始紀錄,作者小編刻意把「加密後的學號」遮掉:
接下來,作者小編發現這三位學生的紀錄是「三個999」,意味著「NA(Not Available)」,也就是說「無法拿到這三位學生的紀錄」:
week1[c(10,33,73),]## # A tibble: 3 × 5
## ID v100101 v100102 v100103 v1001
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 4708e15804935353bb23a614ab47bc5c 999 999 999 0
## 2 1eec74dc5f8f2fbd5bff97fe42d411b0 999 999 999 0
## 3 f6fcf5fb07968a14126f6eee092edf02 999 999 999 0於是乎,作者小編決定「刪去(-)」這三筆紀錄:
week1 <- week1[-c(10,33,73),]接下來,新增「date」這一個欄位,放置「week1」的發生日期,並且用
- 「
p01」代表第一堂課出缺席紀錄的欄位名稱、 - 「
p02」代表第二堂課出缺席紀錄的欄位名稱、 - 「
p03」代表第三堂課出缺席紀錄的欄位名稱、 - 「
pTA」代表實習課出缺席紀錄的欄位名稱、
抓出一張「新表(data.frame)」:
df <- data.frame(ID = week1$ID,
date = as.Date("2014-10-01"),
p01 = week1$v100101,
p02 = week1$v100102,
p03 = week1$v100103,
pTA = week1$v1001,
stringsAsFactors = FALSE)
DT::datatable(df[,-1], options = list(pageLength = 6))再來,就是貼標籤了。根據上一小節「標籤工程」的建議,為每一位學生的「正課」與「實習課」到課情形,貼上「標籤」:
Label <- character(0)
for (i in 1:dim(df)[1]) {
present <- c(df$p01[i], df$p02[i], df$p03[i], df$pTA[i])
for (j in 1:16) {
if(all(present == x[j,1:4])){
Label <- c(Label, x[j,5])
}
}
}
df$Label <- Label
DT::datatable(df[,-1], options = list(pageLength = 6))20.3.4 為每堂課出缺席紀錄新創兩組數字
- 正課實習課都出席
- 出席正課實習課缺席
df$正課實習課都出席 <- grepl("正課實習課都出席", df$Label)
df$出席正課實習課缺席 <- grepl("出席正課實習課缺席", df$Label)
DT::datatable(df[,-1], options = list(pageLength = 6))記得,收尾時,一定要檢查各個欄位屬性是否滿足統計要求?
data.frame(欄位屬性 = sapply(df, class))## 欄位屬性
## ID character
## date Date
## p01 numeric
## p02 numeric
## p03 numeric
## pTA numeric
## Label character
## 正課實習課都出席 logical
## 出席正課實習課缺席 logical20.3.5 出缺席紀錄衍生之學習參與度
這是一種「類似主成份分析」的嘗試,作者小編建議的「新指標」,「出缺席紀錄衍生之學習參與度」定義如下:
x <- df$p01 * 3 + df$p02 * 2 + df$p02 * 1 + df$pTA * 2
x## [1] 8 6 8 8 8 8 8 8 0 8 8 8 8 8 8 8 8 8 8 8 0 8 6 8 8 0 8 8 8 3 8 8 8 8 8 8 8 8
## [39] 8 8 5 8 8 8 8 8 0 8 0 6 6 0 8 8 8 8 8 8 8 8 2 6 8 8 5 8 8 8 8 6 8 8 8 8 6 0
## [77] 8 8 8 8 8 8table(x)## x
## 0 2 3 5 6 8
## 7 1 1 2 7 6420.4 九次作業繳交紀錄
「課外作業」是非常基礎,也是非常傳統,卻是非常有效的學習活動。
先看第一次課外作業的繳交紀錄,一樣,作者小編遮掉「學號」:
### 作業繳交紀錄
library(readxl) # 有請套件「readxl」幫忙!
HW1 <- read_excel("data/hw01_insurance_2014-10-01.xlsx")
HW1$ID <- sapply(HW1$ID, digest::digest, serialize = FALSE)
DT::datatable(HW1[, -1], options = list(pageLength = 6))我們先檢查這一張表(data.frame)的零零總總:
- 檢查屬性。
class(HW1)## [1] "tbl_df" "tbl" "data.frame"- 這一張表有多高?多寬?
dim(HW1)## [1] 85 2- 這一張表的欄位名稱。
colnames(HW1)## [1] "ID" "hw_ch1"- 檢查每一個欄位的屬性。
sapply(HW1, class)## ID hw_ch1
## "character" "numeric"- 紀錄符號。
unique(HW1[,-1])## # A tibble: 2 × 1
## hw_ch1
## <dbl>
## 1 1
## 2 0- 摘要統計量。
summary(HW1[,-1])## hw_ch1
## Min. :0.0000
## 1st Qu.:1.0000
## Median :1.0000
## Mean :0.9294
## 3rd Qu.:1.0000
## Max. :1.0000根據上述觀察,作者小編建議以下這一張新表:
HW1$date <- as.Date("2014-10-01")
HW1$範圍 <- "第一章"
HW1$是否繳交作業 <- factor(ifelse(HW1$hw_ch1 == 0, "否", "是"))
HW1$累積繳交次數 <- HW1$hw_ch1
DT::datatable(HW1[, -c(1,2)], options = list(pageLength = 6))完成後,記得檢查每一個欄位的屬性:
data.frame(欄位屬性 = sapply(HW1[,-2], class))## 欄位屬性
## ID character
## date Date
## 範圍 character
## 是否繳交作業 factor
## 累積繳交次數 numeric20.5 四次小考每題得分細節
台灣的高等教育是「學期制」,每學期安排「十八週」。為了定期追蹤學生的學習進度與發展,作者小編的這一位好朋友「1/4學期」安排一次小考。小考採課堂筆試方式進行,滿分100分。在進一步「思索、想像『小考每題得分細節』可以變出什麼數字之前」,先讓我們檢視一下「編碼簿」,看看、打量作者小編的好朋友還提供了什麼樣的資訊給大家?
- 讀取全部課堂數據集的編碼簿。
codeBookInsurance <- readRDS("data/codeBookInsurance.rds")- 第一次小考的編碼簿。
quiz1codes <- codeBookInsurance[grep("quiz01", codeBookInsurance$source),
c("question", "choices", "備註")]
quiz1codes <- quiz1codes[c(1,3,10,4,8,5,7,2,9,6),]
DT::datatable(quiz1codes, options = list(pageLength = 10))- 第二次小考的編碼簿。
quiz2codes <- codeBookInsurance[grep("quiz02", codeBookInsurance$source),
c("question", "choices", "備註")]
quiz2codes <- quiz2codes[c(4,7,5,6,8,9,1,2,3),]
DT::datatable(quiz2codes, options = list(pageLength = 10))- 第三次小考的編碼簿。
quiz3codes <- codeBookInsurance[grep("quiz03", codeBookInsurance$source),
c("question", "choices", "備註")]
quiz3codes <- quiz3codes[c(5,9,7,8,10,6,1,4,2,3),]
DT::datatable(quiz3codes, options = list(pageLength = 10))- 第四次小考的編碼簿。
quiz4codes <- codeBookInsurance[grep("quiz04", codeBookInsurance$source),
c("question", "choices", "備註")]
quiz4codes <- quiz4codes[c(9,10,2,3,6,7,5,4,8,1),]
DT::datatable(quiz4codes, options = list(pageLength = 10))20.5.1 第一次小考每題的總得分與平均得分
為了深入觀察每一次小考每題的得分細節,作者小編提出以下步驟給大家參考:
- 讀取第一次小考的得分細節。
### 小考每題得分細節
library(readxl) # 有請套件「readxl」幫忙!
quiz1 <- read_excel("data/quiz01_insurance_2014-10-15.xlsx")
quiz1$ID <- sapply(quiz1$ID, digest::digest, serialize = FALSE)
quiz1 <- quiz1[, colnames(quiz1)[c(1,2,4,11,5,9,6,8,3,10,7)]]- 基本檢查。
sapply(quiz1, class)## ID Q1_1 Q1_2 Q1_3 Q1_4 Q1_5
## "character" "character" "character" "character" "character" "character"
## Q1_6 Q1_7 Q1_8 Q1_9 Q1_10
## "character" "character" "character" "character" "character"sapply(quiz1[,-1], unique)## Q1_1 Q1_2 Q1_3 Q1_4 Q1_5 Q1_6 Q1_7 Q1_8 Q1_9 Q1_10
## [1,] "10" "4" "10" "10" "10" "10" "10" "4" "0" "8"
## [2,] "8" "10" "2" "8" "6" "0" "8" "8" "2" "10"
## [3,] "4" "8" "6" "6" "4" "4" "4" "10" "10" "6"
## [4,] "2" "6" "4" "4" "8" "8" "6" "0" "4" "4"
## [5,] "6" "2" "0" "2" "0" "6" "0" "2" "8" "0"
## [6,] "0" "0" "8" "0" "2" "2" "2" "6" "6" "2"
## [7,] "NA" "NA" "NA" "NA" "NA" "NA" "NA" "NA" "NA" "NA"- 設定R認可的「
NA」。
quiz1 <- as.data.frame(quiz1, stringsAsFactors = FALSE)
quiz1[which(quiz1 == "NA", arr.ind = TRUE)] <- NA- 刪去得分細節出現「
NA」的紀錄。
sum(!complete.cases(quiz1))## [1] 2sum(complete.cases(quiz1))## [1] 83quiz1 <- quiz1[complete.cases(quiz1),]- 把「文字」屬性變回「數字」,然後再檢查一次屬性。
quiz1[,-1] <- sapply(quiz1[,-1], as.numeric)
sapply(quiz1, class)## ID Q1_1 Q1_2 Q1_3 Q1_4 Q1_5
## "character" "numeric" "numeric" "numeric" "numeric" "numeric"
## Q1_6 Q1_7 Q1_8 Q1_9 Q1_10
## "numeric" "numeric" "numeric" "numeric" "numeric"- 取得每一題的總得分與平均得分。
summaryQuiz1 <- data.frame(得分 = apply(quiz1[,-1], 2, sum),
平均得分 = apply(quiz1[,-1], 2, mean))
summaryQuiz1[order(summaryQuiz1$平均得分),]## 得分 平均得分
## Q1_9 280 3.373494
## Q1_3 360 4.337349
## Q1_7 368 4.433735
## Q1_2 408 4.915663
## Q1_5 448 5.397590
## Q1_8 498 6.000000
## Q1_10 512 6.168675
## Q1_6 574 6.915663
## Q1_1 658 7.927711
## Q1_4 718 8.65060220.5.2 第一次小考總得分與新創數字
在這裡,作者小編示範如何取得每一位學生的考試成績與全班的成績分配(分布),也計算不及格人數與及格人數:
- 取得每一位學生的考試成績。
totalScore <- apply(quiz1[,-1], 1, sum)
totalScore## 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
## 76 66 68 70 74 60 70 74 56 88 70 92 80 76 58 82 84 84 58 86 74 46 64 64 94 64
## 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52
## 90 54 86 42 32 74 60 56 86 28 66 16 4 2 50 30 56 30 48 46 26 68 54 34 24 44
## 54 55 56 57 58 59 60 61 62 63 64 65 66 68 69 70 71 72 73 74 75 76 77 78 79 80
## 42 58 10 64 44 94 54 42 44 74 2 34 64 84 74 76 76 52 52 40 18 56 40 90 36 80
## 81 82 83 84 85
## 54 66 84 72 64- 全班的成績分配。
table(totalScore)## totalScore
## 2 4 10 16 18 24 26 28 30 32 34 36 40 42 44 46 48 50 52 54 56 58 60 64 66 68
## 2 1 1 1 1 1 1 1 2 1 2 1 2 3 3 2 1 1 2 4 4 3 2 6 3 2
## 70 72 74 76 80 82 84 86 88 90 92 94
## 3 1 6 4 2 1 4 3 1 2 1 2- 不及格人數與及格人數。
sum(totalScore < 60)## [1] 40sum(totalScore >= 60)## [1] 43接下來,作者小編假設
- 如果某一道題目的平均得分「小於4」,就是那一次考試、那一屆學生的「高難度的題目」,貼上「高」這一個標籤、
- 如果某一道題目的平均得分「大於等於4且小於8」,就是那一次考試、那一屆學生的「中難度的題目」,貼上「中」這一個標籤、
- 如果某一道題目的平均得分「大於等於8」,就是那一次考試、那一屆學生的「低難度的題目」,貼上「低」這一個標籤、
summaryQuiz1## 得分 平均得分
## Q1_1 658 7.927711
## Q1_2 408 4.915663
## Q1_3 360 4.337349
## Q1_4 718 8.650602
## Q1_5 448 5.397590
## Q1_6 574 6.915663
## Q1_7 368 4.433735
## Q1_8 498 6.000000
## Q1_9 280 3.373494
## Q1_10 512 6.168675rownames(summaryQuiz1)[which(summaryQuiz1$平均得分 < 4)]## [1] "Q1_9"rownames(summaryQuiz1)[which(summaryQuiz1$平均得分 >= 4 & summaryQuiz1$平均得分 < 8)]## [1] "Q1_1" "Q1_2" "Q1_3" "Q1_5" "Q1_6" "Q1_7" "Q1_8" "Q1_10"rownames(summaryQuiz1)[which(summaryQuiz1$平均得分 >= 8)]## [1] "Q1_4"根據上述結果,作者小編可以為每一位學生算「每一種題型的總得分」:
High <- rownames(summaryQuiz1)[which(summaryQuiz1$平均得分 < 4)]
apply(quiz1[, High, drop = FALSE], 1, sum)## 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
## 0 2 2 0 10 2 2 4 0 10 10 10 0 0 8 10 8 10 0 4 8 0 8 2 10 6
## 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52
## 10 0 10 0 0 0 10 0 4 0 4 0 0 0 0 0 0 0 4 0 0 4 0 4 0 0
## 54 55 56 57 58 59 60 61 62 63 64 65 66 68 69 70 71 72 73 74 75 76 77 78 79 80
## 0 0 0 0 0 10 0 0 2 4 0 0 4 10 8 8 6 2 0 4 0 0 10 10 0 0
## 81 82 83 84 85
## 4 4 8 10 0Mid <- rownames(summaryQuiz1)[which(summaryQuiz1$平均得分 >= 4 & summaryQuiz1$平均得分 < 8)]
apply(quiz1[, Mid, drop = FALSE], 1, sum)## 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
## 66 54 56 60 56 48 58 60 46 68 52 72 70 66 40 62 66 64 48 72 56 36 46 56 74 48
## 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52
## 70 44 72 32 22 64 40 46 72 18 52 14 4 2 42 26 46 26 34 36 16 60 44 28 22 34
## 54 55 56 57 58 59 60 61 62 63 64 65 66 68 69 70 71 72 73 74 75 76 77 78 79 80
## 32 48 10 54 34 74 44 32 32 60 2 24 50 64 56 58 60 40 42 32 8 46 22 70 32 70
## 81 82 83 84 85
## 40 52 66 52 54Low <- rownames(summaryQuiz1)[which(summaryQuiz1$平均得分 >= 8)]
apply(quiz1[, Low, drop = FALSE], 1, sum)## 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
## 10 10 10 10 8 10 10 10 10 10 8 10 10 10 10 10 10 10 10 10 10 10 10 6 10 10
## 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52
## 10 10 4 10 10 10 10 10 10 10 10 2 0 0 8 4 10 4 10 10 10 4 10 2 2 10
## 54 55 56 57 58 59 60 61 62 63 64 65 66 68 69 70 71 72 73 74 75 76 77 78 79 80
## 10 10 0 10 10 10 10 10 10 10 0 10 10 10 10 10 10 10 10 4 10 10 8 10 4 10
## 81 82 83 84 85
## 10 10 10 10 10算到這裡,作者小編想算一個數字,
`得分穩定度` <- apply(quiz1[, -1], 1, sd)
sort(`得分穩定度`)## 40 64 39 25 59 12 78 35
## 0.6324555 0.6324555 0.8432740 0.9660918 0.9660918 1.3984118 1.4142136 1.8973666
## 27 16 56 18 68 81 17 83
## 1.9436506 1.9888579 2.1602469 2.2705848 2.2705848 2.3190036 2.4585452 2.4585452
## 20 29 37 10 70 8 21 44
## 2.5033311 2.5033311 2.5033311 2.5298221 2.6331224 2.6749870 2.6749870 2.7080128
## 71 47 41 79 2 5 63 36
## 2.7968236 2.8362730 2.8674418 2.9514591 2.9888682 2.9888682 2.9888682 3.0110906
## 48 84 7 66 13 50 3 45
## 3.0110906 3.0110906 3.0184617 3.0983867 3.1269438 3.1340425 3.1552426 3.1552426
## 42 15 75 14 23 24 38 51
## 3.1622777 3.1902630 3.1902630 3.2386554 3.2386554 3.2386554 3.2386554 3.2386554
## 82 72 9 80 32 26 57 62
## 3.2727834 3.2930904 3.3730962 3.3993463 3.4058773 3.5023801 3.5023801 3.5023801
## 6 28 69 1 33 74 77 65
## 3.5276684 3.5339622 3.5339622 3.6270588 3.6514837 3.6514837 3.6514837 3.6575645
## 11 58 55 22 43 31 34 52
## 3.6817870 3.7475918 3.8239014 3.8930137 3.9777157 4.0221608 4.0879226 4.0879226
## 85 4 54 49 19 30 61 76
## 4.0879226 4.1365579 4.1579910 4.2216374 4.2635405 4.3665394 4.3665394 4.4020197
## 46 60 73
## 4.4271887 4.6236109 4.8258563那這一個數字,如何呢?
`得分風險` <- apply(quiz1[, -1], 1, sd)/apply(quiz1[, -1], 1, mean)
sort(`得分風險`)## 25 59 12 78 27 35 16 18
## 0.1027757 0.1027757 0.1520013 0.1571348 0.2159612 0.2206240 0.2425436 0.2703077
## 68 10 20 29 17 83 70 8
## 0.2703077 0.2874798 0.2910850 0.2910850 0.2926840 0.2926840 0.3464635 0.3614847
## 21 71 37 13 5 63 84 80
## 0.3614847 0.3680031 0.3792926 0.3908680 0.4039011 0.4039011 0.4182070 0.4249183
## 14 81 7 48 2 32 3 1
## 0.4261389 0.4294451 0.4312088 0.4428074 0.4528588 0.4602537 0.4640063 0.4772446
## 69 66 82 23 24 11 26 57
## 0.4775625 0.4841229 0.4958763 0.5060399 0.5060399 0.5259696 0.5472469 0.5472469
## 15 41 6 4 9 33 72 85
## 0.5500453 0.5734884 0.5879447 0.5909368 0.6023386 0.6085806 0.6332866 0.6387379
## 28 45 55 43 34 19 49 76
## 0.6544374 0.6573422 0.6592934 0.7103064 0.7299862 0.7350932 0.7817847 0.7860750
## 62 79 22 58 60 44 74 77
## 0.7959955 0.8198498 0.8463073 0.8517254 0.8562242 0.9026709 0.9128709 0.9128709
## 50 73 52 46 54 30 61 42
## 0.9217772 0.9280493 0.9290733 0.9624323 0.9899978 1.0396522 1.0396522 1.0540926
## 36 65 47 31 51 75 38 39
## 1.0753895 1.0757543 1.0908742 1.2569253 1.3494398 1.7723683 2.0241596 2.1081851
## 56 40 64
## 2.1602469 3.1622777 3.1622777再加這一個,
ReSD <- function(x, Re){
x <- mean((x - Re)^2)
return(x)
}
Re <- apply(quiz1[, -1], 2, mean)
`得分相對穩定度` <- apply(quiz1[, -1], 1, ReSD, Re)
sort(`得分相對穩定度`)## 81 37 66 2 28 8 7 41
## 2.116708 2.617913 3.779358 3.996226 4.439599 4.593816 4.805864 5.335985
## 57 9 45 43 21 70 3 72
## 5.822732 6.449238 6.564901 6.651648 6.704660 6.748033 7.297431 7.596226
## 55 34 14 6 71 49 48 58
## 7.726346 7.798636 7.943214 7.962491 7.991407 8.131166 8.213093 8.251648
## 32 84 63 52 26 33 16 19
## 8.535985 8.656467 8.680563 8.791407 8.955262 9.003455 9.316708 9.403455
## 85 23 35 82 69 17 80 68
## 9.764901 9.948033 10.078154 10.155262 10.203455 10.333575 10.584178 10.738395
## 62 13 74 22 20 18 15 5
## 10.786587 10.854057 10.911889 11.292611 11.350443 11.461286 11.572129 11.591407
## 76 83 1 11 24 65 60 54
## 11.798636 11.837190 11.943214 11.986587 12.039599 12.054057 12.160081 12.352852
## 78 44 61 46 30 79 73 12
## 12.632370 13.008274 13.268515 13.702250 13.779358 13.822732 13.919117 14.179358
## 27 31 36 47 4 25 50 59
## 14.502250 14.584178 14.892611 15.138395 15.148033 15.205864 15.350443 15.437190
## 42 10 29 77 75 51 38 56
## 15.745623 18.063696 18.261286 19.393816 21.866105 23.123937 25.022732 28.651648
## 39 40 64
## 31.933575 33.499840 33.49984020.5.3 小結論:第一次小考總得分與新創數字的總表
綜合上述「探索歷程的零零總總、加加減減」,通通收在一張表裡,會得到
library(readxl) # 有請套件「readxl」幫忙!
quiz1 <- read_excel("data/quiz01_insurance_2014-10-15.xlsx")
quiz1$ID <- sapply(quiz1$ID, digest::digest, serialize = FALSE)
quiz1 <- quiz1[, colnames(quiz1)[c(1,2,4,11,5,9,6,8,3,10,7)]]
quiz1 <- as.data.frame(quiz1, stringsAsFactors = FALSE)
quiz1[which(quiz1 == "NA", arr.ind = TRUE)] <- NA
quiz1 <- quiz1[complete.cases(quiz1),]
quiz1[,-1] <- sapply(quiz1[,-1], as.numeric)
quiz1$totalScore <- apply(quiz1[,-1], 1, sum)
High <- rownames(summaryQuiz1)[which(summaryQuiz1$平均得分 < 4)]
Mid <- rownames(summaryQuiz1)[which(summaryQuiz1$平均得分 >= 4 & summaryQuiz1$平均得分 < 8)]
Low <- rownames(summaryQuiz1)[which(summaryQuiz1$平均得分 >= 8)]
quiz1$High <- apply(quiz1[, High, drop = FALSE], 1, sum)
quiz1$Mid <- apply(quiz1[, Mid, drop = FALSE], 1, sum)
quiz1$Low <- apply(quiz1[, Low, drop = FALSE], 1, sum)
Re <- apply(quiz1[, 2:11], 2, mean)
quiz1$`得分相對穩定度` <- round(apply(quiz1[, 2:11], 1, ReSD, Re), 3)
quiz1$`得分穩定度` <- round(apply(quiz1[, 2:11], 1, sd), 3)
quiz1$`得分風險` <- round(apply(quiz1[, 2:11], 1, sd)/apply(quiz1[, 2:11], 1, mean), 3)
DT::datatable(quiz1[,-(1:11)],
options = list(scrollX = TRUE,
fixedColumns = TRUE))20.5.4 第二次小考每題的總得分與平均得分
## 得分 平均得分
## Q2_2c 434 5.166667
## Q2_4 546 6.500000
## Q2_2b 563 6.702381
## Q2_6 600 7.142857
## Q2_7 618 7.357143
## Q2_2a 622 7.404762
## Q2_1 665 7.916667
## Q2_3 816 9.714286
## Q2_5 1044 12.42857120.5.5 第三次小考每題的總得分與平均得分
## 得分 平均得分
## Q3_5 327 4.671429
## Q3_6 390 5.571429
## Q3_4 406 5.800000
## Q3_9 418 5.971429
## Q3_8 468 6.685714
## Q3_2 498 7.114286
## Q3_10 522 7.457143
## Q3_3 526 7.514286
## Q3_7 620 8.857143
## Q3_1 672 9.60000020.5.6 第四次小考每題的總得分與平均得分
## 得分 平均得分
## Q4_3d 23 0.2738095
## Q4_3c 34 0.4047619
## Q4_3b 50 0.5952381
## Q4_3e 283 3.3690476
## Q4_1c 342 4.0714286
## Q4_3a 536 6.3809524
## Q4_1b 586 6.9761905
## Q4_2b 650 7.7380952
## Q4_2a 683 8.1309524
## Q4_1a 731 8.7023810
## Q4_4 796 9.476190520.5.7 四次小考成績的成長曲線分析
library(readxl) # 有請套件「readxl」幫忙!
Q1 <- read_excel("data/Q1_insurance_2014-09-24.xlsx")
quiz1 <- read_excel("data/quiz01_insurance_2014-10-15.xlsx")
quiz1 <- quiz1[, colnames(quiz1)[c(1,2,4,11,5,9,6,8,3,10,7)]]
quiz2 <- read_excel("data/quiz02_insurance_2014-11-05.xlsx")
`短名字` <- sort(colnames(quiz2)[which(nchar(colnames(quiz2)) == 4)])
`長名字` <- sort(colnames(quiz2)[which(nchar(colnames(quiz2)) == 5)])
quiz2 <- quiz2[, c("ID", `短名字`, `長名字`)]
quiz3 <- read_excel("data/quiz03_insurance_2014-12-10.xlsx")
quiz3 <- quiz3[, c(sort(colnames(quiz3)[-4]), colnames(quiz3)[4])]
quiz4 <- read_excel("data/quiz04_insurance_2014-12-31.xlsx")
quiz4 <- quiz4[, c(colnames(quiz4)[1:2], sort(colnames(quiz4)[-c(1,2)]))]
### 抓數據
dfQuiz <- data.frame(ID = quiz1$ID,
calculus = Q1$Q1V13,
economics = Q1$Q1V14,
accounting = Q1$Q1V15,
stringsAsFactors = FALSE)
dfQuiz <- cbind(dfQuiz, quiz1[,-1], quiz2[,-1], quiz3[,-1], quiz4[,-1])
dfQuiz[which(dfQuiz == "NA", arr.ind = TRUE)] <- NA
dfQuizNA <- dfQuiz[!complete.cases(dfQuiz),]
dfQuiz <- dfQuiz[complete.cases(dfQuiz),]
dfQuiz$calculus <- as.numeric(dfQuiz$calculus)
dfQuiz$economics <- as.numeric(dfQuiz$economics)
dfQuiz$accounting <- as.numeric(dfQuiz$accounting)
q1colnames <- colnames(quiz1)[-1]
dfQuiz[,q1colnames] <- apply(dfQuiz[,q1colnames], 2, as.numeric)
q2colnames <- colnames(quiz2)[-1]
dfQuiz[,q2colnames] <- apply(dfQuiz[,q2colnames], 2, as.numeric)
q3colnames <- colnames(quiz3)[-1]
dfQuiz[,q3colnames] <- apply(dfQuiz[,q3colnames], 2, as.numeric)
q4colnames <- colnames(quiz4)[-1]
dfQuiz[,q4colnames] <- apply(dfQuiz[,q4colnames], 2, as.numeric)
DT::datatable(dfQuiz[,-1],
options = list(scrollX = TRUE,
fixedColumns = TRUE))class(dfQuiz)## [1] "data.frame"sapply(dfQuiz, class)## ID calculus economics accounting Q1_1 Q1_2
## "character" "numeric" "numeric" "numeric" "numeric" "numeric"
## Q1_3 Q1_4 Q1_5 Q1_6 Q1_7 Q1_8
## "numeric" "numeric" "numeric" "numeric" "numeric" "numeric"
## Q1_9 Q1_10 Q2_1 Q2_3 Q2_4 Q2_5
## "numeric" "numeric" "numeric" "numeric" "numeric" "numeric"
## Q2_6 Q2_7 Q2_2a Q2_2b Q2_2c Q3_1
## "numeric" "numeric" "numeric" "numeric" "numeric" "numeric"
## Q3_2 Q3_3 Q3_4 Q3_5 Q3_6 Q3_7
## "numeric" "numeric" "numeric" "numeric" "numeric" "numeric"
## Q3_8 Q3_9 Q3_10 Q4_4 Q4_1a Q4_1b
## "numeric" "numeric" "numeric" "numeric" "numeric" "numeric"
## Q4_1c Q4_2a Q4_2b Q4_3a Q4_3b Q4_3c
## "numeric" "numeric" "numeric" "numeric" "numeric" "numeric"
## Q4_3d Q4_3e
## "numeric" "numeric"dim(dfQuiz)## [1] 66 44colnames(dfQuiz)## [1] "ID" "calculus" "economics" "accounting" "Q1_1"
## [6] "Q1_2" "Q1_3" "Q1_4" "Q1_5" "Q1_6"
## [11] "Q1_7" "Q1_8" "Q1_9" "Q1_10" "Q2_1"
## [16] "Q2_3" "Q2_4" "Q2_5" "Q2_6" "Q2_7"
## [21] "Q2_2a" "Q2_2b" "Q2_2c" "Q3_1" "Q3_2"
## [26] "Q3_3" "Q3_4" "Q3_5" "Q3_6" "Q3_7"
## [31] "Q3_8" "Q3_9" "Q3_10" "Q4_4" "Q4_1a"
## [36] "Q4_1b" "Q4_1c" "Q4_2a" "Q4_2b" "Q4_3a"
## [41] "Q4_3b" "Q4_3c" "Q4_3d" "Q4_3e"sapply(dfQuiz[,-1], unique)## $calculus
## [1] 75 85 65 45 90 55 35 19
##
## $economics
## [1] 85 75 65 45 55 0 90
##
## $accounting
## [1] 75 65 85 55 90 0 45
##
## $Q1_1
## [1] 10 8 4 2 6 0
##
## $Q1_2
## [1] 4 10 8 6 2 0
##
## $Q1_3
## [1] 10 2 6 4 0 8
##
## $Q1_4
## [1] 10 8 6 4 0 2
##
## $Q1_5
## [1] 10 6 4 8 0 2
##
## $Q1_6
## [1] 10 0 4 8 6 2
##
## $Q1_7
## [1] 10 8 4 6 0 2
##
## $Q1_8
## [1] 4 8 10 0 2 6
##
## $Q1_9
## [1] 0 2 10 4 8 6
##
## $Q1_10
## [1] 8 10 6 0 4 2
##
## $Q2_1
## [1] 10 8 4 2 0
##
## $Q2_3
## [1] 8 6 13 15 12 9 0 2 3 10
##
## $Q2_4
## [1] 10 0 4 6 8 2
##
## $Q2_5
## [1] 10 4 15 0 12 3 6
##
## $Q2_6
## [1] 10 8 0 4 2 6
##
## $Q2_7
## [1] 10 4 8 0 6 2
##
## $Q2_2a
## [1] 10 4 6 0 2 8
##
## $Q2_2b
## [1] 10 4 8 0 2 15
##
## $Q2_2c
## [1] 10 8 6 4 0 2
##
## $Q3_1
## [1] 10 2 8 0
##
## $Q3_2
## [1] 10 6 0 2 4 8
##
## $Q3_3
## [1] 10 0 8 2 6
##
## $Q3_4
## [1] 10 0 8 4 6 2
##
## $Q3_5
## [1] 10 0 6 4 8 2 3
##
## $Q3_6
## [1] 10 8 0 6 4
##
## $Q3_7
## [1] 10 0 8 4
##
## $Q3_8
## [1] 10 8 4 2 6 0
##
## $Q3_9
## [1] 8 10 0
##
## $Q3_10
## [1] 10 8 0 6 4
##
## $Q4_4
## [1] 10 0
##
## $Q4_1a
## [1] 10 6 5 4 0
##
## $Q4_1b
## [1] 10 0 6 4
##
## $Q4_1c
## [1] 5 3 0
##
## $Q4_2a
## [1] 3 10 8 6 0 4
##
## $Q4_2b
## [1] 8 10 6 0 4
##
## $Q4_3a
## [1] 10 8 0
##
## $Q4_3b
## [1] 8 0 9 5 3
##
## $Q4_3c
## [1] 0 8 10
##
## $Q4_3d
## [1] 0 8 5 10
##
## $Q4_3e
## [1] 0 5 8DT::datatable(dfQuizNA[,-1],
options = list(scrollX = TRUE,
fixedColumns = TRUE))前述如此大費周章的原因,為的是一次處理掉「NA」,接下來抓走背景成績「微積分成績」、「經濟學成績」、「會計學成績」,再分別計算每一次小考的總成績:
quizGrowth <- dfQuiz[, 1:4]
quizGrowth$Q1 <- apply(dfQuiz[,q1colnames], 1, sum)
quizGrowth$Q2 <- apply(dfQuiz[,q2colnames], 1, sum)
quizGrowth$Q3 <- apply(dfQuiz[,q3colnames], 1, sum)
quizGrowth$Q4 <- apply(dfQuiz[,q4colnames], 1, sum)
DT::datatable(quizGrowth[,-1],
options = list(scrollX = TRUE,
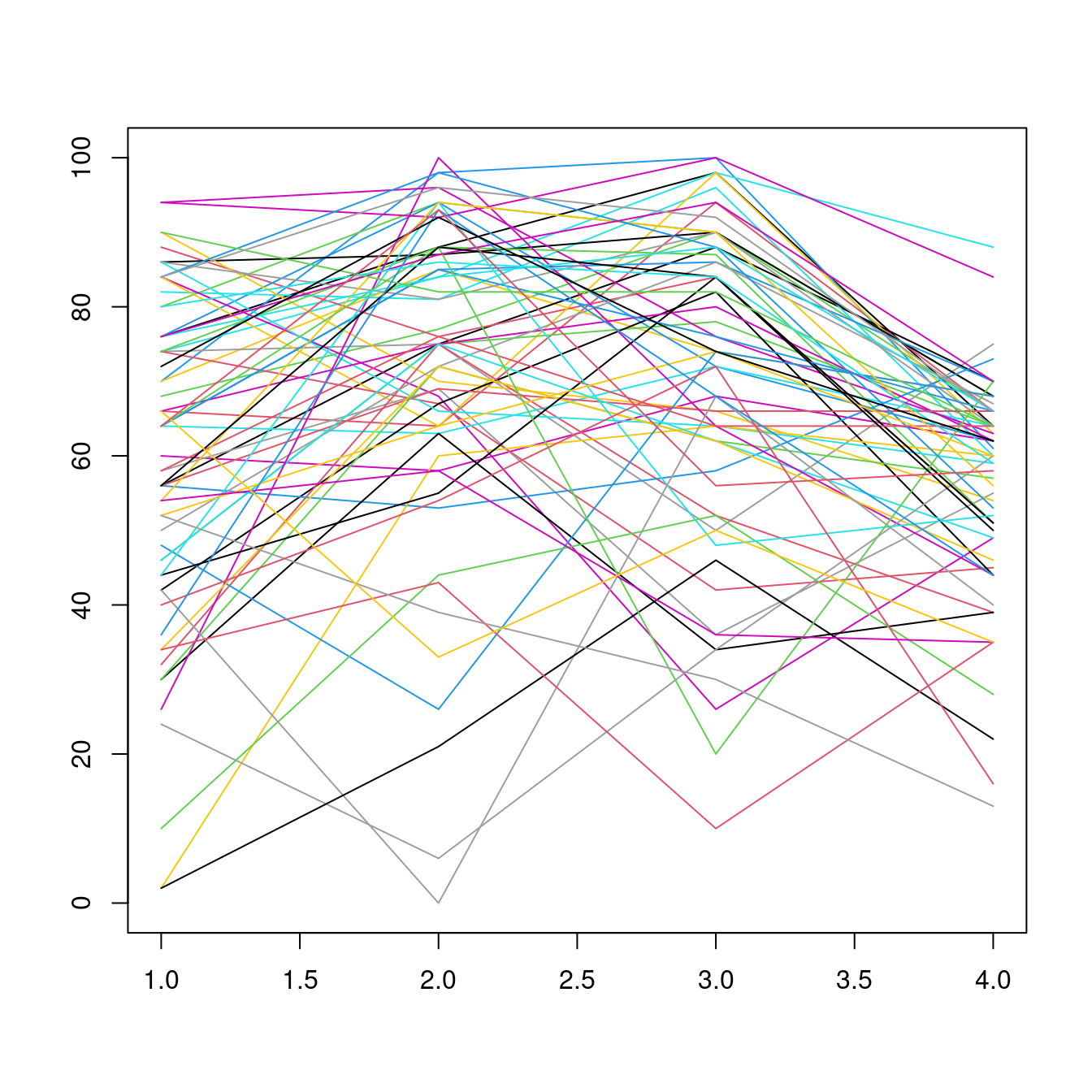
fixedColumns = TRUE))接下來,畫畫大家的「成長曲線」
plot(1:4, quizGrowth[1,-(1:4)],
ylim = c(0, 100),
type = "l",
xlab = "",
ylab = "")
for (i in 2:dim(quizGrowth)[1]) {
points(1:4, quizGrowth[i,-(1:4)], type = "l", col = i)
}
20.6 第一次小考前的班級課堂數據集加學期總成績的總表
根據這一張表的日期,以及該日期發生的數據集,作者小編假設
- 這一天是開學第一天,作者小編的好朋友也執行了「期初調查」,所以「填寫者」就是「出席正課者」。進一步假設,當天「沒有實習課」!
DataWeek[2, 1:2]## ALLfiles classDate
## 2 Q1_insurance_2014-09-24.xlsx 2014-09-24- 第二週起,開始有「出缺席紀錄」,所以這是第一次、第一張的「出缺席紀錄」。
DataWeek[3, 1:2]## ALLfiles classDate
## 3 insurance_2014-10-01.xlsx 2014-10-01- 第二週起,也開始收作業,所以這是第一次、第一張的「作業繳交紀錄」。
DataWeek[4, 1:2]## ALLfiles classDate
## 4 hw01_insurance_2014-10-01.xlsx 2014-10-01- 這是第三週的「出缺席紀錄」。
DataWeek[5, 1:2]## ALLfiles classDate
## 5 insurance_2014-10-08.xlsx 2014-10-08- 這是第二次的「作業繳交紀錄」。
DataWeek[6, 1:2]## ALLfiles classDate
## 6 hw02_insurance_2014-10-08.xlsx 2014-10-08- 這是第一次小考的「得分細節」。
DataWeek[8, 1:2]## ALLfiles classDate
## 8 quiz01_insurance_2014-10-15.xlsx 2014-10-15- 這是第一次小考當天的「出缺席紀錄」。列入下一階段的「『發生』數據集」。
DataWeek[7, 1:2]## ALLfiles classDate
## 7 insurance_2014-10-15.xlsx 2014-10-15所以,根據上述觀察,我們可以得知「第一次小考(quiz01)」前,這一班「財務管理課」的行事曆。
DataWeek[c(2,3,4,5,6,8), 1:2]## ALLfiles classDate
## 2 Q1_insurance_2014-09-24.xlsx 2014-09-24
## 3 insurance_2014-10-01.xlsx 2014-10-01
## 4 hw01_insurance_2014-10-01.xlsx 2014-10-01
## 5 insurance_2014-10-08.xlsx 2014-10-08
## 6 hw02_insurance_2014-10-08.xlsx 2014-10-08
## 8 quiz01_insurance_2014-10-15.xlsx 2014-10-1520.6.1 好朋友設計的總表
library(readxl)
Q1 <- read_excel("data/Q1_insurance_2014-09-24.xlsx")
dim(Q1)## [1] 85 26week1 <- read_excel("data/insurance_2014-10-01.xlsx")
dim(week1)## [1] 85 5week2 <- read_excel("data/insurance_2014-10-08.xlsx")
dim(week2)## [1] 85 5HW1 <- read_excel("data/hw01_insurance_2014-10-01.xlsx")
dim(HW1)## [1] 85 2HW2 <- read_excel("data/hw02_insurance_2014-10-08.xlsx")
dim(HW2)## [1] 85 2colnames(HW2)## [1] "ID" "hw_ch5"總共有40個欄位!
為了「實踐搜尋最佳預測模型」,作者小編的策略大概是
- 先「引用好朋友的作法」,再
- 「開發新數字」。
基於這樣的策略,作者小編根據「財務管理課堂數據集編碼簿」先從上述「40」個欄位挑選以下這幾個變數。除了「示範策略」,還想「示範程式」,讓作者小編的學生有機會「加速發展」。
### 抓數據
df <- data.frame(ID = Q1$ID,
calculus = Q1$Q1V13,
economics = Q1$Q1V14,
accounting = Q1$Q1V15,
week101 = week1$v100101,
week102 = week1$v100102,
week103 = week1$v100103,
week1TA = week1$v1001,
week201 = week2$v100801,
week202 = week2$v100802,
week203 = week2$v100803,
week2TA = week2$v1008,
HW1 = HW1$hw_ch1,
HW2 = HW2$hw_ch5,
grade = grade$semester_grade,
stringsAsFactors = FALSE)
DT::datatable(df,
options = list(dom = 't',
scrollX = TRUE,
fixedColumns = TRUE))有了這一張表之後,我們再一次「閱讀編碼簿」,或是「寫一段程式碼檢查這一張表有什麼?」
sapply(df, unique)## $ID
## [1] "D0000724" "D0002003" "D0002077" "D0025255" "D0025361" "D0036087"
## [7] "D0036090" "D0036204" "D0036221" "D0036251" "D0042131" "D0047816"
## [13] "D0058658" "D0062699" "D0062728" "D0063984" "D0079329" "D0079405"
## [19] "D0079598" "D0079729" "D0079733" "D0079759" "D0079793" "D0079835"
## [25] "D0079937" "D0089988" "D0096473" "D0207597" "D0207612" "D0229859"
## [31] "D0229893" "D0229918" "D0229935" "D0229965" "D0229982" "D0230006"
## [37] "D0230023" "D0230053" "D0230070" "D0230097" "D0230113" "D0230130"
## [43] "D0230160" "D0230187" "D0230201" "D0230228" "D0230258" "D0230275"
## [49] "D0230292" "D0230317" "D0230334" "D0230364" "D0230381" "D0230453"
## [55] "D0230470" "D0230497" "D0247557" "D0261796" "D0261811" "D0269263"
## [61] "D0275821" "D0275835" "D0275851" "D0275865" "D0275878" "D0275882"
## [67] "D0275895" "D0275906" "D0275937" "D0275953" "D0275967" "D0275970"
## [73] "D0275984" "D0275997" "D0276007" "D0276011" "D0276024" "D0276068"
## [79] "D0293785" "D0391809" "D0391873" "D0391932" "D9926806" "D9945535"
## [85] "D9979704"
##
## $calculus
## [1] "75" "85" "65" "45" "NA" "90" "55" "19" "35"
##
## $economics
## [1] "85" "75" "65" "45" "NA" "0" "55" "90"
##
## $accounting
## [1] "75" "65" "85" "55" "NA" "90" "45" "0" "19"
##
## $week101
## [1] 1 0 999
##
## $week102
## [1] 1 0 999
##
## $week103
## [1] 1 0 999
##
## $week1TA
## [1] 1 0
##
## $week201
## [1] 1 0
##
## $week202
## [1] 1 0
##
## $week203
## [1] 1 0
##
## $week2TA
## [1] 1 0
##
## $HW1
## [1] 1 0
##
## $HW2
## [1] 1 0
##
## $grade
## [1] 86 78 77 85 83 81 76 69 79 73 87 56 80 82 71 75 72 70 65 68 64 63 61 84 67
## [26] 57 66 93 60 74 53看過之後,發現有
"NA"999
「再回頭閱讀編碼簿」,會發現這些都代表著「某種無法獲取數據的現實」,為了讓R幫忙,要先把這些符號改成R看得懂的符號
df[which(df == "NA", arr.ind = TRUE)] <- NA
sapply(df, unique)## $ID
## [1] "D0000724" "D0002003" "D0002077" "D0025255" "D0025361" "D0036087"
## [7] "D0036090" "D0036204" "D0036221" "D0036251" "D0042131" "D0047816"
## [13] "D0058658" "D0062699" "D0062728" "D0063984" "D0079329" "D0079405"
## [19] "D0079598" "D0079729" "D0079733" "D0079759" "D0079793" "D0079835"
## [25] "D0079937" "D0089988" "D0096473" "D0207597" "D0207612" "D0229859"
## [31] "D0229893" "D0229918" "D0229935" "D0229965" "D0229982" "D0230006"
## [37] "D0230023" "D0230053" "D0230070" "D0230097" "D0230113" "D0230130"
## [43] "D0230160" "D0230187" "D0230201" "D0230228" "D0230258" "D0230275"
## [49] "D0230292" "D0230317" "D0230334" "D0230364" "D0230381" "D0230453"
## [55] "D0230470" "D0230497" "D0247557" "D0261796" "D0261811" "D0269263"
## [61] "D0275821" "D0275835" "D0275851" "D0275865" "D0275878" "D0275882"
## [67] "D0275895" "D0275906" "D0275937" "D0275953" "D0275967" "D0275970"
## [73] "D0275984" "D0275997" "D0276007" "D0276011" "D0276024" "D0276068"
## [79] "D0293785" "D0391809" "D0391873" "D0391932" "D9926806" "D9945535"
## [85] "D9979704"
##
## $calculus
## [1] "75" "85" "65" "45" NA "90" "55" "19" "35"
##
## $economics
## [1] "85" "75" "65" "45" NA "0" "55" "90"
##
## $accounting
## [1] "75" "65" "85" "55" NA "90" "45" "0" "19"
##
## $week101
## [1] 1 0 999
##
## $week102
## [1] 1 0 999
##
## $week103
## [1] 1 0 999
##
## $week1TA
## [1] 1 0
##
## $week201
## [1] 1 0
##
## $week202
## [1] 1 0
##
## $week203
## [1] 1 0
##
## $week2TA
## [1] 1 0
##
## $HW1
## [1] 1 0
##
## $HW2
## [1] 1 0
##
## $grade
## [1] 86 78 77 85 83 81 76 69 79 73 87 56 80 82 71 75 72 70 65 68 64 63 61 84 67
## [26] 57 66 93 60 74 53仔細看,發現第一句話成功了化解「"NA"」的危機,接下來「舉一反三」,
df[which(df == 999, arr.ind = TRUE)] <- NA
sapply(df, unique)## $ID
## [1] "D0000724" "D0002003" "D0002077" "D0025255" "D0025361" "D0036087"
## [7] "D0036090" "D0036204" "D0036221" "D0036251" "D0042131" "D0047816"
## [13] "D0058658" "D0062699" "D0062728" "D0063984" "D0079329" "D0079405"
## [19] "D0079598" "D0079729" "D0079733" "D0079759" "D0079793" "D0079835"
## [25] "D0079937" "D0089988" "D0096473" "D0207597" "D0207612" "D0229859"
## [31] "D0229893" "D0229918" "D0229935" "D0229965" "D0229982" "D0230006"
## [37] "D0230023" "D0230053" "D0230070" "D0230097" "D0230113" "D0230130"
## [43] "D0230160" "D0230187" "D0230201" "D0230228" "D0230258" "D0230275"
## [49] "D0230292" "D0230317" "D0230334" "D0230364" "D0230381" "D0230453"
## [55] "D0230470" "D0230497" "D0247557" "D0261796" "D0261811" "D0269263"
## [61] "D0275821" "D0275835" "D0275851" "D0275865" "D0275878" "D0275882"
## [67] "D0275895" "D0275906" "D0275937" "D0275953" "D0275967" "D0275970"
## [73] "D0275984" "D0275997" "D0276007" "D0276011" "D0276024" "D0276068"
## [79] "D0293785" "D0391809" "D0391873" "D0391932" "D9926806" "D9945535"
## [85] "D9979704"
##
## $calculus
## [1] "75" "85" "65" "45" NA "90" "55" "19" "35"
##
## $economics
## [1] "85" "75" "65" "45" NA "0" "55" "90"
##
## $accounting
## [1] "75" "65" "85" "55" NA "90" "45" "0" "19"
##
## $week101
## [1] 1 0 NA
##
## $week102
## [1] 1 0 NA
##
## $week103
## [1] 1 0 NA
##
## $week1TA
## [1] 1 0
##
## $week201
## [1] 1 0
##
## $week202
## [1] 1 0
##
## $week203
## [1] 1 0
##
## $week2TA
## [1] 1 0
##
## $HW1
## [1] 1 0
##
## $HW2
## [1] 1 0
##
## $grade
## [1] 86 78 77 85 83 81 76 69 79 73 87 56 80 82 71 75 72 70 65 68 64 63 61 84 67
## [26] 57 66 93 60 74 53往下滑過,發現我們再一次化解「999」的危機。接下來,我們啟動「清理數據的機制」,先把這些「某種無法獲取數據的現實」擺在旁邊:
dfNA <- df[!complete.cases(df),]
sapply(dfNA, unique)## $ID
## [1] "D0036251" "D0042131" "D0047816" "D0089988" "D0229935" "D0275984"
##
## $calculus
## [1] "65" NA "85" "45"
##
## $economics
## [1] "65" NA "75" "85" "45"
##
## $accounting
## [1] "85" NA "65"
##
## $week101
## [1] NA 1
##
## $week102
## [1] NA 1
##
## $week103
## [1] NA 1
##
## $week1TA
## [1] 0 1
##
## $week201
## [1] 1
##
## $week202
## [1] 1
##
## $week203
## [1] 1
##
## $week2TA
## [1] 1
##
## $HW1
## [1] 0 1
##
## $HW2
## [1] 1
##
## $grade
## [1] 78 69 83 76 53df <- df[complete.cases(df),]
sapply(df, unique)## $ID
## [1] "D0000724" "D0002003" "D0002077" "D0025255" "D0025361" "D0036087"
## [7] "D0036090" "D0036204" "D0036221" "D0058658" "D0062699" "D0062728"
## [13] "D0063984" "D0079329" "D0079405" "D0079598" "D0079729" "D0079733"
## [19] "D0079759" "D0079793" "D0079835" "D0079937" "D0096473" "D0207597"
## [25] "D0207612" "D0229859" "D0229893" "D0229918" "D0229965" "D0229982"
## [31] "D0230006" "D0230023" "D0230053" "D0230070" "D0230097" "D0230113"
## [37] "D0230130" "D0230160" "D0230187" "D0230201" "D0230228" "D0230258"
## [43] "D0230275" "D0230292" "D0230317" "D0230334" "D0230364" "D0230381"
## [49] "D0230453" "D0230470" "D0230497" "D0247557" "D0261796" "D0261811"
## [55] "D0269263" "D0275821" "D0275835" "D0275851" "D0275865" "D0275878"
## [61] "D0275882" "D0275895" "D0275906" "D0275937" "D0275953" "D0275967"
## [67] "D0275970" "D0275997" "D0276007" "D0276011" "D0276024" "D0276068"
## [73] "D0293785" "D0391809" "D0391873" "D0391932" "D9926806" "D9945535"
## [79] "D9979704"
##
## $calculus
## [1] "75" "85" "65" "45" "90" "55" "19" "35"
##
## $economics
## [1] "85" "75" "65" "45" "0" "55" "90"
##
## $accounting
## [1] "75" "65" "85" "55" "90" "45" "0" "19"
##
## $week101
## [1] 1 0
##
## $week102
## [1] 1 0
##
## $week103
## [1] 1 0
##
## $week1TA
## [1] 1 0
##
## $week201
## [1] 1 0
##
## $week202
## [1] 1 0
##
## $week203
## [1] 1 0
##
## $week2TA
## [1] 1 0
##
## $HW1
## [1] 1 0
##
## $HW2
## [1] 1 0
##
## $grade
## [1] 86 78 77 85 83 81 76 79 73 87 56 80 82 71 75 72 70 65 68 64 63 61 84 67 57
## [26] 66 93 60 74 69再觀察總表一次,
DT::datatable(df,
options = list(scrollX = TRUE,
fixedColumns = TRUE))看似沒有問題,繼續檢查各個欄位的屬性,看看是不是跟我們的想像一樣?
sapply(df, class)## ID calculus economics accounting week101 week102
## "character" "character" "character" "character" "numeric" "numeric"
## week103 week1TA week201 week202 week203 week2TA
## "numeric" "numeric" "numeric" "numeric" "numeric" "numeric"
## HW1 HW2 grade
## "numeric" "numeric" "numeric"仔細一看,發現「微積分成績」、「經濟學成績」、「會計學成績」是「文字」,不是「數字」。所以,我們再一次啟動「清理數據的機制」,只是這一回是「修正機制」:
df$calculus <- as.numeric(df$calculus)
df$economics <- as.numeric(df$economics)
df$accounting <- as.numeric(df$accounting)最後再檢查部分基本要求:
class(df)## [1] "data.frame"sapply(df, class)## ID calculus economics accounting week101 week102
## "character" "numeric" "numeric" "numeric" "numeric" "numeric"
## week103 week1TA week201 week202 week203 week2TA
## "numeric" "numeric" "numeric" "numeric" "numeric" "numeric"
## HW1 HW2 grade
## "numeric" "numeric" "numeric"dim(df)## [1] 79 15colnames(df)## [1] "ID" "calculus" "economics" "accounting" "week101"
## [6] "week102" "week103" "week1TA" "week201" "week202"
## [11] "week203" "week2TA" "HW1" "HW2" "grade"20.6.2 根據本章前述建議新創數字設計的總表
這是根據好朋友設計的幾張表得到的一張「總表」,雖然不是「那麼總」!
讓我們開始變!
- 直接抓走期初調查的結果。
myDF <- df[, c(1,2,3,4)]
dim(myDF)## [1] 79 4- 變出出缺席參與度。
myDF$engPresence01 <- df$week101 * 3 + df$week102 * 2 + df$week102 * 1 + df$week1TA * 2
myDF$engPresence02 <- df$week201 * 3 + df$week202 * 2 + df$week202 * 1 + df$week2TA * 2
dim(myDF)## [1] 79 6- 變出課外作業的累積繳交次數
myDF$accHW <- df$HW1 + df$HW2
dim(myDF)## [1] 79 7- 再把期末總成績抓走。
myDF$grade <- df$grade
dim(myDF)## [1] 79 8- 觀察總成果。
DT::datatable(myDF,
options = list(scrollX = TRUE,
fixedColumns = TRUE))- 檢查成果。
class(myDF)## [1] "data.frame"sapply(myDF, class)## ID calculus economics accounting engPresence01
## "character" "numeric" "numeric" "numeric" "numeric"
## engPresence02 accHW grade
## "numeric" "numeric" "numeric"dim(myDF)## [1] 79 8colnames(myDF)## [1] "ID" "calculus" "economics" "accounting"
## [5] "engPresence01" "engPresence02" "accHW" "grade"關於上述嘗試的後續探索與研究,請讀者諸君繼續往下看!
20.6.2.1 觀察心得:變異的力量
先看看每一個欄位的分散程度
apply(myDF[,-1], 2, sd)## calculus economics accounting engPresence01 engPresence02
## 17.9813817 15.1745230 15.0766084 2.4263243 1.7892898
## accHW grade
## 0.4739224 8.1497865apply(myDF[,-1], 2, sd)/apply(myDF[,-1], 2, mean)## calculus economics accounting engPresence01 engPresence02
## 0.2787538 0.2205680 0.2169889 0.3517057 0.2379695
## accHW grade
## 0.2599991 0.1100381在不改新創表格的條件下,再看一種可能性
x <- myDF[,"engPresence01"]+myDF[,"engPresence02"]
sd(x)## [1] 3.473739sd(x)/mean(x)## [1] 0.2409354先瞧瞧變異的力量對建模的影響:
summary(lm(grade ~ engPresence01 + engPresence02, data = myDF))##
## Call:
## lm(formula = grade ~ engPresence01 + engPresence02, data = myDF)
##
## Residuals:
## Min 1Q Median 3Q Max
## -19.2585 -3.7585 0.7415 5.7415 17.7415
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 64.3944 4.0565 15.874 <0.0000000000000002 ***
## engPresence01 0.8739 0.3896 2.243 0.0278 *
## engPresence02 0.4842 0.5283 0.916 0.3623
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 7.842 on 76 degrees of freedom
## Multiple R-squared: 0.09796, Adjusted R-squared: 0.07422
## F-statistic: 4.127 on 2 and 76 DF, p-value: 0.01989myDF$engPresence <- myDF$engPresence01 + myDF$engPresence02
summary(lm(grade ~ engPresence, data = myDF))##
## Call:
## lm(formula = grade ~ engPresence, data = myDF)
##
## Residuals:
## Min 1Q Median 3Q Max
## -19.2063 -3.7063 0.7937 5.6832 17.7937
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 63.6483 3.7711 16.88 < 0.0000000000000002 ***
## engPresence 0.7224 0.2544 2.84 0.00577 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 7.804 on 77 degrees of freedom
## Multiple R-squared: 0.0948, Adjusted R-squared: 0.08305
## F-statistic: 8.064 on 1 and 77 DF, p-value: 0.005771太美妙了!這是作者小編第一次知道有這種事!
20.6.3 根據課堂學生建議新創數字設計的總表
2021年3月的30日跟31日,作者小編持續上週啟動的「特徵值工程」,準備驗收兩班一周之後個別的成果。在這裡,所謂的「驗收」,並不是「要求學生寫在紙本上然後繳交給我然後批閱然後返還然後石沉大海」,而是「上台到黑板上寫出個人其中幾項成果分享給大家」。這種模式過後,作者小編可以很快知道誰寫了誰願意上台表演哪一個生態圈願意分享,還有這些學生的中文字表達能力!透過這種積少成多的模式,今年兩班都給足了30題,雖然難易不定,但都足夠練習一整堂課。
20.6.3.1 甲班建議新創數字設計的總表
這裡可以放當時的分享照片。
作者小編寫到這裡,一開始想要把學生的「建議」,但又不想「打字」,所以先用上面這一句話「輕輕帶過」。作者小編從分享建議的板書照片中,找到一個「不算是太好算的建議特徵值」示範可能的過程:
- 直接抓走期初調查的結果。
myDF01 <- df[, c(1,2,3,4)]
dim(myDF01)## [1] 79 4- 變出是否三堂課缺席一堂。
myDF01$three2one01 <- apply(df[, c(5,6,7)], 1, sum) == 2
myDF01$three2one02 <- apply(df[, c(9,10,11)], 1, sum) == 2
dim(myDF01)## [1] 79 6- 觀察總成果。
DT::datatable(myDF01,
options = list(scrollX = TRUE,
fixedColumns = TRUE))- 檢查成果。
class(myDF01)## [1] "data.frame"sapply(myDF01, class)## ID calculus economics accounting three2one01 three2one02
## "character" "numeric" "numeric" "numeric" "logical" "logical"dim(myDF01)## [1] 79 6colnames(myDF01)## [1] "ID" "calculus" "economics" "accounting" "three2one01"
## [6] "three2one02"20.6.3.2 乙班建議新創數字設計的總表
這裡可以放當時的分享照片。
作者小編寫到這裡,一開始想要把學生的「建議」,但又不想「打字」,所以先用上面這一句話「輕輕帶過」。作者小編從分享建議的板書照片中,找到一個「不算是太好算的建議特徵值」示範可能的過程:
- 直接抓走期初調查的結果。
myDF02 <- df[, c(1,2,3,4)]
dim(myDF02)## [1] 79 4- 變出平均到課數。
myDF02$meanPresence <- apply(df[, c(5,6,7,8,9,10,11,12)], 1, mean)
dim(myDF02)## [1] 79 5- 觀察總成果。
DT::datatable(myDF02,
options = list(scrollX = TRUE,
fixedColumns = TRUE))- 檢查成果。
class(myDF02)## [1] "data.frame"sapply(myDF02, class)## ID calculus economics accounting meanPresence
## "character" "numeric" "numeric" "numeric" "numeric"dim(myDF02)## [1] 79 5colnames(myDF02)## [1] "ID" "calculus" "economics" "accounting" "meanPresence"20.6.4 如果想預測第一次小考的總得分
library(readxl) # 有請套件「readxl」幫忙!
Q1 <- read_excel("data/Q1_insurance_2014-09-24.xlsx")
week1 <- read_excel("data/insurance_2014-10-01.xlsx")
week2 <- read_excel("data/insurance_2014-10-08.xlsx")
HW1 <- read_excel("data/hw01_insurance_2014-10-01.xlsx")
HW2 <- read_excel("data/hw02_insurance_2014-10-08.xlsx")
quiz1 <- read_excel("data/quiz01_insurance_2014-10-15.xlsx")
quiz1 <- quiz1[, colnames(quiz1)[c(1,2,4,11,5,9,6,8,3,10,7)]]
### 抓數據
df <- data.frame(ID = Q1$ID,
calculus = Q1$Q1V13,
economics = Q1$Q1V14,
accounting = Q1$Q1V15,
week101 = week1$v100101,
week102 = week1$v100102,
week103 = week1$v100103,
week1TA = week1$v1001,
week201 = week2$v100801,
week202 = week2$v100802,
week203 = week2$v100803,
week2TA = week2$v1008,
HW1 = HW1$hw_ch1,
HW2 = HW2$hw_ch5,
stringsAsFactors = FALSE)
df <- cbind(df, quiz1[,-1])
df$grade <- grade$semester_grade
df[which(df == "NA", arr.ind = TRUE)] <- NA
df[which(df == 999, arr.ind = TRUE)] <- NA
dfNA <- df[!complete.cases(df),]
df <- df[complete.cases(df),]
df$calculus <- as.numeric(df$calculus)
df$economics <- as.numeric(df$economics)
df$accounting <- as.numeric(df$accounting)
df$Q1_1 <- as.numeric(df$Q1_1)
df$Q1_2 <- as.numeric(df$Q1_2)
df$Q1_3 <- as.numeric(df$Q1_3)
df$Q1_4 <- as.numeric(df$Q1_4)
df$Q1_5 <- as.numeric(df$Q1_5)
df$Q1_6 <- as.numeric(df$Q1_6)
df$Q1_7 <- as.numeric(df$Q1_7)
df$Q1_8 <- as.numeric(df$Q1_8)
df$Q1_9 <- as.numeric(df$Q1_9)
df$Q1_10 <- as.numeric(df$Q1_10)
DT::datatable(df[,-1],
options = list(scrollX = TRUE,
fixedColumns = TRUE))class(df)## [1] "data.frame"sapply(df, class)## ID calculus economics accounting week101 week102
## "character" "numeric" "numeric" "numeric" "numeric" "numeric"
## week103 week1TA week201 week202 week203 week2TA
## "numeric" "numeric" "numeric" "numeric" "numeric" "numeric"
## HW1 HW2 Q1_1 Q1_2 Q1_3 Q1_4
## "numeric" "numeric" "numeric" "numeric" "numeric" "numeric"
## Q1_5 Q1_6 Q1_7 Q1_8 Q1_9 Q1_10
## "numeric" "numeric" "numeric" "numeric" "numeric" "numeric"
## grade
## "numeric"dim(df)## [1] 77 25colnames(df)## [1] "ID" "calculus" "economics" "accounting" "week101"
## [6] "week102" "week103" "week1TA" "week201" "week202"
## [11] "week203" "week2TA" "HW1" "HW2" "Q1_1"
## [16] "Q1_2" "Q1_3" "Q1_4" "Q1_5" "Q1_6"
## [21] "Q1_7" "Q1_8" "Q1_9" "Q1_10" "grade"sapply(df[,-1], unique)## $calculus
## [1] 75 85 65 45 90 55 19 35
##
## $economics
## [1] 85 75 65 45 0 55 90
##
## $accounting
## [1] 75 65 85 55 90 0 45
##
## $week101
## [1] 1 0
##
## $week102
## [1] 1 0
##
## $week103
## [1] 1 0
##
## $week1TA
## [1] 1 0
##
## $week201
## [1] 1 0
##
## $week202
## [1] 1 0
##
## $week203
## [1] 1 0
##
## $week2TA
## [1] 1 0
##
## $HW1
## [1] 1 0
##
## $HW2
## [1] 1 0
##
## $Q1_1
## [1] 10 8 4 2 6 0
##
## $Q1_2
## [1] 4 10 8 6 2 0
##
## $Q1_3
## [1] 10 2 6 4 0 8
##
## $Q1_4
## [1] 10 8 6 4 2 0
##
## $Q1_5
## [1] 10 6 4 8 0 2
##
## $Q1_6
## [1] 10 0 4 8 6 2
##
## $Q1_7
## [1] 10 8 4 6 0 2
##
## $Q1_8
## [1] 4 8 10 0 2 6
##
## $Q1_9
## [1] 0 2 10 4 8 6
##
## $Q1_10
## [1] 8 10 6 0 4 2
##
## $grade
## [1] 86 78 77 85 83 81 76 79 73 87 56 80 82 71 75 72 70 65 68 64 63 61 84 67 57
## [26] 93 66 60 74 6920.7 期中考每題得分細節
### 期中考每題得分細節
library(readxl) # 有請套件「readxl」幫忙!
mid <- read_excel("data/mid_insurance_2014-11-12.xlsx")
mid$ID <- sapply(mid$ID, digest::digest, serialize = FALSE)
DT::datatable(mid[,-1],
options = list(scrollX = TRUE,
fixedColumns = TRUE))上述是原始紀錄,讓作者小編檢查一些原始紀錄的屬性
class(mid)## [1] "tbl_df" "tbl" "data.frame"sapply(mid, class)## ID M_Q1 M_Q2 M_Q8 M_Q6 M_Q3
## "character" "numeric" "numeric" "numeric" "numeric" "numeric"
## M_Q9 M_Q10 M_Q4 M_Q7 M_Q5 M_Q11
## "numeric" "numeric" "numeric" "numeric" "numeric" "numeric"
## M_Q14 M_Q15 M_Q12 M_Q19 M_Q20 M_Q13
## "numeric" "numeric" "numeric" "numeric" "numeric" "numeric"
## M_Q16 M_Q21 M_Q22 M_Q17 M_Q18 M_Q23
## "numeric" "numeric" "numeric" "numeric" "numeric" "numeric"
## M_Q24 M_Q25
## "numeric" "numeric"dim(mid)## [1] 85 26colnames(mid)## [1] "ID" "M_Q1" "M_Q2" "M_Q8" "M_Q6" "M_Q3" "M_Q9" "M_Q10" "M_Q4"
## [10] "M_Q7" "M_Q5" "M_Q11" "M_Q14" "M_Q15" "M_Q12" "M_Q19" "M_Q20" "M_Q13"
## [19] "M_Q16" "M_Q21" "M_Q22" "M_Q17" "M_Q18" "M_Q23" "M_Q24" "M_Q25"sapply(mid[,-1], unique)## M_Q1 M_Q2 M_Q8 M_Q6 M_Q3 M_Q9 M_Q10 M_Q4 M_Q7 M_Q5 M_Q11 M_Q14 M_Q15 M_Q12
## [1,] 1 0 0 1 1 1 0 1 1 0 0 1 1 1
## [2,] 0 1 1 0 0 0 1 0 0 1 1 0 0 0
## M_Q19 M_Q20 M_Q13 M_Q16 M_Q21 M_Q22 M_Q17 M_Q18 M_Q23 M_Q24 M_Q25
## [1,] 0 0 1 0 0 0 1 1 1 1 1
## [2,] 1 1 0 1 1 1 0 0 0 0 0再看全班在各題的表現:
summaryMid <- data.frame(得分 = apply(mid[,-1], 2, sum)*4,
平均得分 = apply(mid[,-1], 2, mean)*4)
summaryMid[order(summaryMid$平均得分),]## 得分 平均得分
## M_Q14 32 0.3764706
## M_Q21 44 0.5176471
## M_Q18 68 0.8000000
## M_Q8 72 0.8470588
## M_Q20 88 1.0352941
## M_Q5 100 1.1764706
## M_Q15 104 1.2235294
## M_Q22 112 1.3176471
## M_Q19 116 1.3647059
## M_Q13 124 1.4588235
## M_Q23 128 1.5058824
## M_Q12 132 1.5529412
## M_Q11 140 1.6470588
## M_Q16 140 1.6470588
## M_Q10 144 1.6941176
## M_Q17 148 1.7411765
## M_Q3 156 1.8352941
## M_Q6 172 2.0235294
## M_Q25 184 2.1647059
## M_Q1 188 2.2117647
## M_Q9 232 2.7294118
## M_Q7 268 3.1529412
## M_Q2 284 3.3411765
## M_Q4 292 3.4352941
## M_Q24 300 3.5294118有了上述這些基本的理解之後,可能可以變出什麼「新數字」呢?
midNew <- mid[, 1, drop = FALSE]
midNew$score <- apply(mid[,-1], 1, sum) * 4
High <- rownames(summaryMid)[which(summaryMid$平均得分 < 1)]
Mid <- rownames(summaryMid)[which(summaryMid$平均得分 >= 1 & summaryMid$平均得分 < 3)]
Low <- rownames(summaryMid)[which(summaryMid$平均得分 >= 3)]
midNew$High <- apply(mid[, High], 1, sum)*4
midNew$Mid <- apply(mid[, Mid], 1, sum)*4
midNew$Low <- apply(mid[, Low], 1, sum)*4
DT::datatable(midNew[,-1],
options = list(scrollX = TRUE,
fixedColumns = TRUE))20.8 期末考每題得分細節
上述是原始紀錄,讓作者小編檢查一些原始紀錄的屬性
class(final)## [1] "tbl_df" "tbl" "data.frame"sapply(final, class)## ID F_C1 F_C2 F_C3_a F_C3_b F_C3_c
## "character" "numeric" "numeric" "numeric" "numeric" "numeric"
## F_C4 F_C5 F_M1 F_M2 F_M3 F_M4
## "numeric" "numeric" "numeric" "numeric" "numeric" "numeric"
## F_M5 F_M6 F_M7 F_M8 F_M9 F_M10
## "numeric" "numeric" "numeric" "numeric" "numeric" "numeric"dim(final)## [1] 85 18colnames(final)## [1] "ID" "F_C1" "F_C2" "F_C3_a" "F_C3_b" "F_C3_c" "F_C4" "F_C5"
## [9] "F_M1" "F_M2" "F_M3" "F_M4" "F_M5" "F_M6" "F_M7" "F_M8"
## [17] "F_M9" "F_M10"sapply(final[,-1], unique)## $F_C1
## [1] 8 6 0 2
##
## $F_C2
## [1] 10 2 8 9 6 0 1 5
##
## $F_C3_a
## [1] 10 6 8 0 5
##
## $F_C3_b
## [1] 10 6 0 2 4 8
##
## $F_C3_c
## [1] 0 2
##
## $F_C4
## [1] 10 0 1 4 8 6 9
##
## $F_C5
## [1] 10 2 1 8 4 5 6 9
##
## $F_M1
## [1] 1 0
##
## $F_M2
## [1] 1 0
##
## $F_M3
## [1] 1 0
##
## $F_M4
## [1] 0 1
##
## $F_M5
## [1] 1 0
##
## $F_M6
## [1] 1 0
##
## $F_M7
## [1] 1 0
##
## $F_M8
## [1] 1 0
##
## $F_M9
## [1] 0 1
##
## $F_M10
## [1] 1 0再看全班在各題的表現:
summaryFinal <- data.frame(得分 = c(apply(final[,FC], 2, sum),
apply(final[,c(sFM,lFM)], 2, sum)*3),
平均得分 = c(apply(final[,FC], 2, mean),
apply(final[,c(sFM,lFM)], 2, mean)*3))
summaryFinal[c(FC,sFM,lFM),]## 得分 平均得分
## F_C1 636 7.4823529
## F_C2 605 7.1176471
## F_C3_a 827 9.7294118
## F_C3_b 788 9.2705882
## F_C3_c 150 1.7647059
## F_C4 759 8.9294118
## F_C5 686 8.0705882
## F_M1 240 2.8235294
## F_M2 153 1.8000000
## F_M3 225 2.6470588
## F_M4 123 1.4470588
## F_M5 207 2.4352941
## F_M6 192 2.2588235
## F_M7 48 0.5647059
## F_M8 177 2.0823529
## F_M9 129 1.5176471
## F_M10 207 2.4352941有了上述這些基本的理解之後,可能可以變出什麼「新數字」呢?
finalNew <- final[, 1, drop = FALSE]
finalNew$score <- apply(final[,FC],1,sum)+apply(final[,c(sFM,lFM)],1,sum)*3
finalNew$Cscore <- apply(final[,FC],1,sum)
finalNew$Mscore <- apply(final[,c(sFM,lFM)],1,sum)*3
DT::datatable(finalNew[,-1],
options = list(scrollX = TRUE,
fixedColumns = TRUE))20.12 期初調查
到底問了什麼呢?
光看「欄位名稱」,絕對無法得知,當年這一位財務管理授課師長到底問了什麼?為此,當年作者小編跟研究生第一次研究這一組數據集的時候,邊寫過一份所謂的「編碼簿」,紀錄著每一個欄位相關的資訊。作者小編抓出「期初調查」來,
20.15 參考碼
20.15.1 取得第一次小考每一題的總得分與平均得分
### 小考每題得分細節
library(readxl) # 有請套件「readxl」幫忙!
quiz1 <- read_excel("data/quiz01_insurance_2014-10-15.xlsx")
quiz1$ID <- sapply(quiz1$ID, digest::digest, serialize = FALSE)
quiz1 <- quiz1[, colnames(quiz1)[c(1,2,4,11,5,9,6,8,3,10,7)]]
sapply(quiz1, class)
quiz1[which(quiz1 == "NA", arr.ind = TRUE)] <- NA
quiz1 <- quiz1[complete.cases(quiz1),]
quiz1[,-1] <- sapply(quiz1[,-1], as.numeric)
sapply(quiz1, class)
summaryQuiz1 <- data.frame(得分 = apply(quiz1[,-1], 2, sum),
平均得分 = apply(quiz1[,-1], 2, mean))
summaryQuiz1[order(summaryQuiz1$平均得分),]