Chapter 7 當銅板遊戲遇上高中數學談產生數據的離散型機制
7.4 第一節:一枚銅板的實驗
教書多年下來,我養成了一個習慣,「在課堂上」,或是「喝咖啡聊是非」,我常用「問問題」起頭,刺激「學生」、「與談者」的腦細胞,熱熱機。通常我會從比較簡單的問題(雖然有可能是無聊的問題)開始:這一節的
第一道問題:「銅板」是什麼?
我小時候(西元1966年~西元1984年)遇上這樣的問題:遇上「不知道」或是「不懂」的字,一定是「翻找字典」;二十一世紀的現代(西元2022年),我會「翻找網路」,所以我開啟「某一家網路搜尋引擎」,在「搜尋對話框」輸入「銅板」,之後「按下鍵盤上的『enter』」。
失敗!
「映入眼簾」的是兩則網路購物廣告加上一則某公司的產品頁面;
怎麼辦呢?
面對「2022年(歲末出現了一款叫做『ChatGPT』的人工智慧對話機器人)的搜尋引擎」只有一條路,
修正「搜尋對話框」的「輸入(input)」。
接著,我輸入「銅板 是什麼」,也就是上述問題說明的口語版,「『銅板』 停頓 『是什麼』 不加問號」:
成功了!
看到,「國語辭典」、「漢典」、「維基百科,自由的百科全書」。為什麼,我敢說「成功了」,因為
「國語辭典」、「漢典」是上一個世紀人們普遍使用的字典(上網找得到,表示紙本字典已經「電子化」了),
而
「維基百科,自由的百科全書」則是近代搜尋引擎面對此類問題經常建議的選項。
那「第一個問題:銅板是什麼?」的答案到底是什麼呢?如下圖所示:
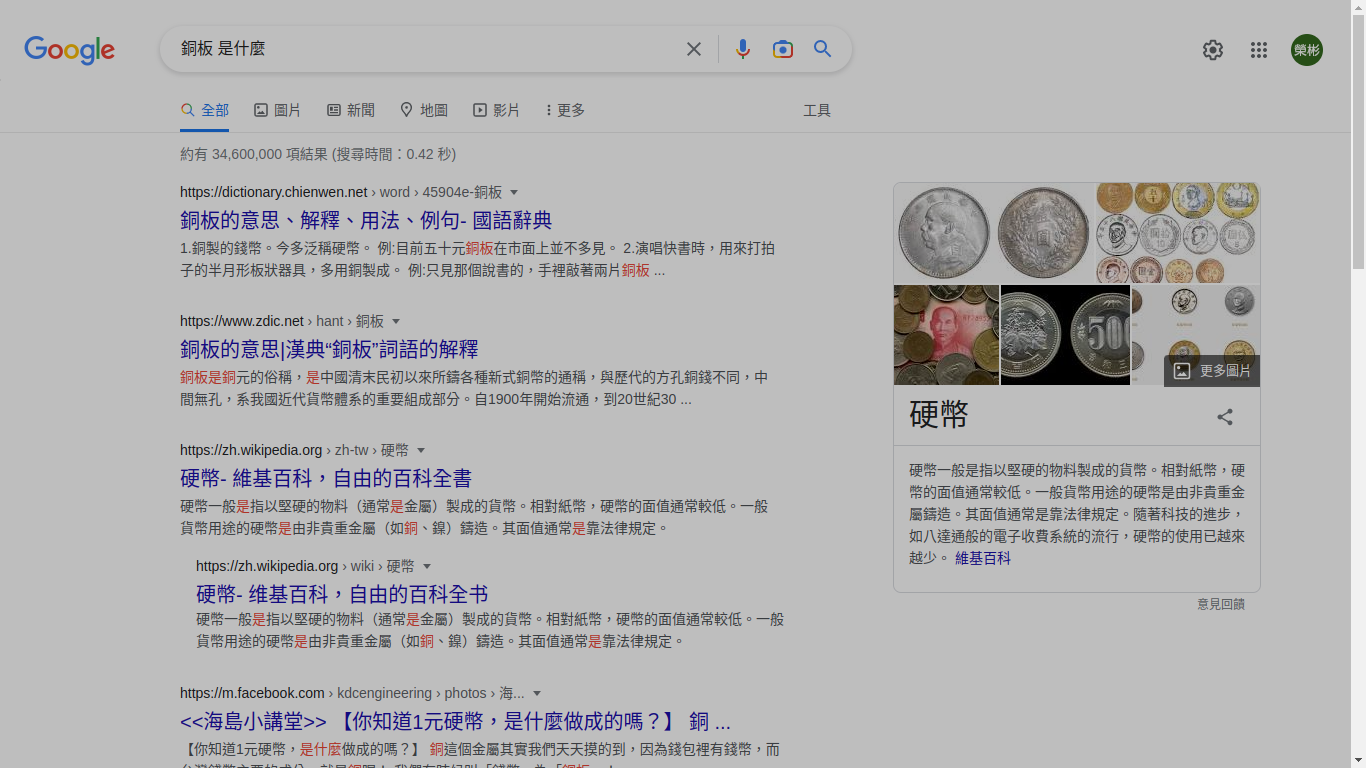
銅板就是硬幣。
這是第一道問題的答案。接下來,
第二道問題:什麼是「銅板實驗」?
有了上述跟搜尋引擎的交手經驗,為了回答第二道問題,我在「搜尋對話框」輸入「實驗 是什麼」,之後「按下鍵盤上的『enter』」。這時候,映入眼簾的是
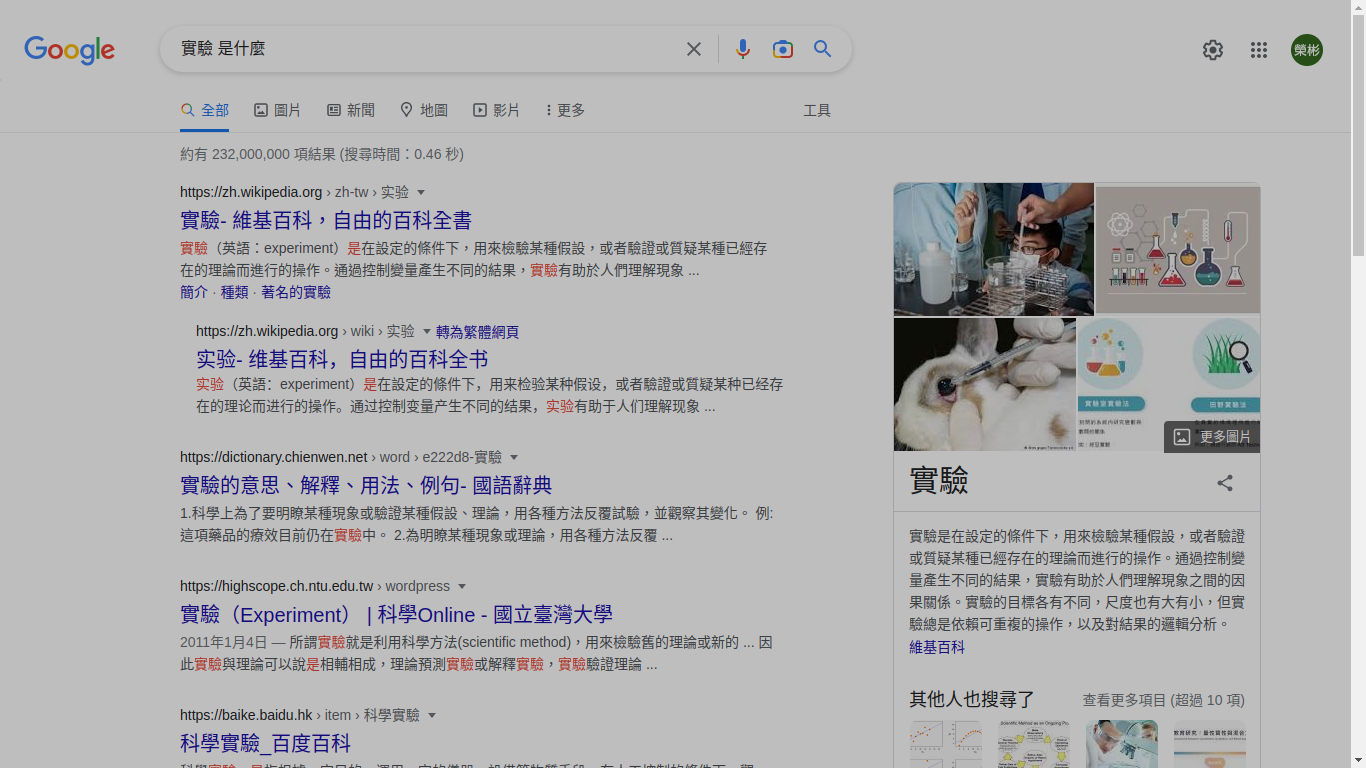
兩次的搜尋經驗之後,我學到幾件事:
- 如果想知道某一個「字串(一串字)」的意思,最佳策略是「在搜尋引擎的『搜尋對話框』輸入『XX 是什麼』」,其中「XX」代表想知道意思的字串,比如說,剛剛出現的「銅板」、「實驗」。
- 「Google」這一家搜尋引擎「似乎」與維基百科合作了,因為我不用碰觸電腦鍵盤上任何鍵或是動到滑鼠、觸控板,電腦畫面的右邊就有維基百科上一開頭的內容,讓我輕鬆知道「XX」的某些意思。
看著畫面,我發現維基百科的第一句話(注意:如果直接引用參考文獻、參考網頁的原文,相關內容會採用「斜體字(italic)」,比如說以下這一段):
「實驗是在設定的條件下,用來檢驗某種假設,或者驗證或質疑某種已經存在的理論而進行的操作。」
我把這一句話當作是「樣板」,因為它是「實驗」的一般性意義、定義。然後,我「套用樣板」自己試著、嘗試回答「什麼是銅板實驗?」。
銅板實驗是在設定的條件下,用來檢驗銅板是公平的假設,或者驗證或質疑銅板是公平的理論而進行的銅板操作。
各位讀者諸君,唸起來還不錯!雖然讀者諸君可能會懷疑、不解「銅板的理論」在哪裡啊?
7.5 第二節:銅板是公平的
我們在第一節「一枚銅板的實驗」,萬事問Google,學到如何透過「搜尋引擎」得知
- 銅板是硬幣。
- 實驗是在設定的條件下,用來檢驗某種假設,或者驗證或質疑某種已經存在的理論而進行的操作。
也套用第二項知識,嘗試寫下「什麼是銅板實驗?」的答案:
- 銅板實驗是在設定的條件下,用來檢驗銅板是公平的假設,或者驗證或質疑銅板是公平的理論而進行的銅板操作。
檢視上述嘗試,我們暫時擺脫「搜尋引擎」,改採「機率論」的數學術語闡述「銅板是公平的」這一項理論。
7.5.1 建構一枚銅板實驗的母體
從第一節我們已經知道所謂的「銅板」就是「硬幣」,也就是說,銅板是一種有厚度的圓形物體(thing),也就是說,銅板有「兩面」:
一般情形下,我們用「正面」與「反面」指名這一件事,
而且為了區分彼此,銅板「設計者」與「製造者」會為銅板的正反面印上不一樣的「花紋」。比如說,台灣還在流通的「五元硬幣」一面刻著孫中山先生的人頭,另一面是伍圓的字樣。在此,本書定義
- 人頭那一面是正面;
- 伍圓字樣那一面是反面。
假如「我們同意」用「可能性」這三個字「代表」收錄了「一枚銅板丟一次實驗全部可能性」的「集合」,那我們就可以「如下所示,這樣『請R』幫忙把『可能性』放入R裡」:
可能性 <- c("正面", "反面")
可能性## [1] "正面" "反面"以上是R形成「向量」這種「資料結構」的基本說法、基本語法,其中
- 「
c」是「combine」的「去尾縮寫」,它是一種「函式(function)」,它的功能是形成「向量」; - 「
"正面"」跟「"反面"」是R表達「文字」的方式,也可以這樣寫「'正面'」跟「'反面'」。 - 我們把它們依序用逗號「
,」分開放入「()」裡,「c」就會為我們形成「R裡的向量」。 - 有了「
c("正面", "反面")」這一個向量之後,用「<-」指定給(assign)「左邊」的「可能性」。 - 我用「R字」稱呼「
可能性」。
取「R字」的靈感來自「英文字」、「中文字」、…
雖然,我們定義了「一枚銅板丟一次實驗」的全部「可能性」,但是,
「可能性」三個字「寫意『力道不足』」,也就是說「『方向感』不足」、「『專業度』不足」,「太一般了」!
於是乎,「統計學家」引用「population」這一個英文字,代表「某些字串(詞)」背後全部的「可能性」。比如說,
- 銅板
- 骰子
- 撲克牌
- 台中市民
- 台中市公車
- …
我們用「母體」翻譯「population」。也就是說,
「母體」代表「全部可能性」。
所以,我們也可以這麼說
母體 <- c("可能性一", "可能性二", "可能性三", "...")
母體## [1] "可能性一" "可能性二" "可能性三" "..."至於「可能性一」等等「可能性」的「專業術語」叫做「outcome」,也叫做「element」。我把「outcome」翻譯為「出象」,意味著「出現的現象」;「element」則翻譯為「個體」。所以不論是「哪一種研究?」,
- 實驗型
- 觀察型
母體 <- c("出象一", "出象二", "出象三", "...")
母體## [1] "出象一" "出象二" "出象三" "..."母體 <- c("個體一", "個體二", "個體三", "...")
母體## [1] "個體一" "個體二" "個體三" "..."接著,我們試著用「集合的數學符號({})」定義「一枚銅板(可能是5元硬幣,也可能是10元硬幣)丟一次實驗」的「母體」,可以是
{正面,反面}
也可以變身為
{人頭,字樣}
或者是(這是台灣在地的習慣說法!)
{人頭,梅花}
英文可以這麼寫,
{Head,Tail}
為了節省力氣,我們這麼縮寫
{H,T}
更為了方便計算某一次銅板實驗總共出現幾次「人頭」,就這麼寫
{1,0}
所以,「1」代表出現「一次人頭」;而「0」則代表出現「一次梅花」。當然,如果興趣是某一次銅板實驗總共出現幾次「梅花」,那就這麼寫
{0,1}
請各位讀者諸君特別注意,上述一枚銅板實驗的母體「不斷地變身、變變變」,但是
先「正面」後「反面」這一個順序永遠不變!
另外,「我」想強調一件事:
「不斷地變身、變變變」代表「統計學家」的「設計觀」!統計學家也是設計師!
把上述全部「到目前為止」的「集合的可能性」收錄起來,我們可以用一種叫做「資料框(data.frame,俗稱表格)」的資料結構(到目前為止我們遇到的第二種)把「集合的可能性」放入R裡:
母體的表示法 <- data.frame(row.names = c("1", "2"), stringsAsFactors = FALSE)
母體的表示法## 資料框沒有行但有 2 列母體的表示法$第一種 <- c("正面", "反面")
母體的表示法$第二種 <- c("人頭", "字樣")
母體的表示法$第三種 <- c("人頭", "梅花")
母體的表示法$第四種 <- c("Head", "Tail")
母體的表示法$第五種 <- c("H", "T")
母體的表示法$第六種 <- c(1, 0)
母體的表示法$第七種 <- c(0, 1)
knitr::kable(母體的表示法, row.names = TRUE)| 第一種 | 第二種 | 第三種 | 第四種 | 第五種 | 第六種 | 第七種 | |
|---|---|---|---|---|---|---|---|
| 1 | 正面 | 人頭 | 人頭 | Head | H | 1 | 0 |
| 2 | 反面 | 字樣 | 梅花 | Tail | T | 0 | 1 |
7.5.1.2 個人觀察上述大表之後的感想:
幾句「R話」,「R字、中文字、英文字組合的字串」,竟然可以讓「我」輕鬆地「觀察」統計世界的「裝置藝術」!
上述「發展『資料框』」的其他細節,說明如下:
- 「資料框」就是俗稱的「表格」,「橫向往右」叫做「列(row)」;「縱向向下」叫做「行(column)」。「列」有「列名稱(
rownames)」;「行」有「行名稱(colnames)」。 - 「
data.frame(row.names = c("1", "2"), stringsAsFactors = FALSE)」,讓我們「初始化(initialize)」一張「高度等於2、寬度等於0」的空白資料框(比『MS EXCEL』的空白速算表還要空白)。「資料框」是「data.frame」的R官方翻譯。「資料」等於「data」,而「框」等於「frame」,兩個字中間的「美式句點、英式句點,.」把「兩個字」串成「一個R字」。 - 「
data.frame」,就像之前的「c」一樣,只是一個形成「向量(一維的R物件)」,一個形成「資料框(二維的R物件)」。 - 「
row.names = c("1", "2")」定義「空白資料框」的「高度」跟「列(row)名稱(names)」。兩個字中間的「美式句點、英式句點,.」把「兩個字」串成「一個R字」。 - 「
stringsAsFactors = FALSE」是一個比較專業的「R話」,主要用途是「阻止R恣意改變文字的屬性」,而是「維持原來放在""內的樣子」。這裡的「stringsAsFactors」展示另一種「R字」的設計模式「strings」是「字串們」;「As」是「強迫」;「Factors」是「尺度文字」,小寫的「strings」加上第一個字母大寫的「As」,再加上第一個字母大寫的「Factors」,形成「stringsAsFactors」這一種「R字」的設計。 - 有了「空白資料框」之後,用「
$」讓我們用「向量」定義新的「行」,也就是俗稱的「欄位」。新的欄位會「依序」出現在資料框的右邊,「我」會這麼說:「往右邊長大的資料框」。 - 「
knitr::kable(母體的表示法, row.names = TRUE」這是可以讓我們展示「漂亮、寫意」表格的幫手,其中「knitr」是一個「套件」,也可以說是一本「書」,「請書」幫忙要用「::」,而「借書」要用「library」(我會到圖書館借書)。「kable」取自「table」,是「knitr」這一本書的其中一章,其中一個函式(function)。至於「row.names = TRUE」就是要求R在螢幕上顯示「列名稱」。
7.5.2 建構一枚銅板實驗的機率分配表
有了母體之後,闡述「銅板是公平的」這一項理論的第二步是「建構母體背後的『機率分配表』」。由於個人倡議
表格輔助計算,
再加上本教科書全部內容都是R統計語言的輸出結果,所以經常出現在其他統計學教科書的
「手繪表格」就不一定為我所用,請讀者諸君見諒!
為了建構母體背後的機率分配表,我們借用一種研究工具:
樹形圖,
協助我們把母體的內容物一五一十地寫出來,協助我們「數數兒(這三個字有沒有喚起讀者諸君兒時的記憶呢!)」母體的內容物。為了慎重起見,我們再一次「萬事問Google」,在「搜尋對話框」輸入「樹形圖 是什麼」,之後「按下鍵盤上的『enter』」。這一次搜尋之後,映入眼簾的是
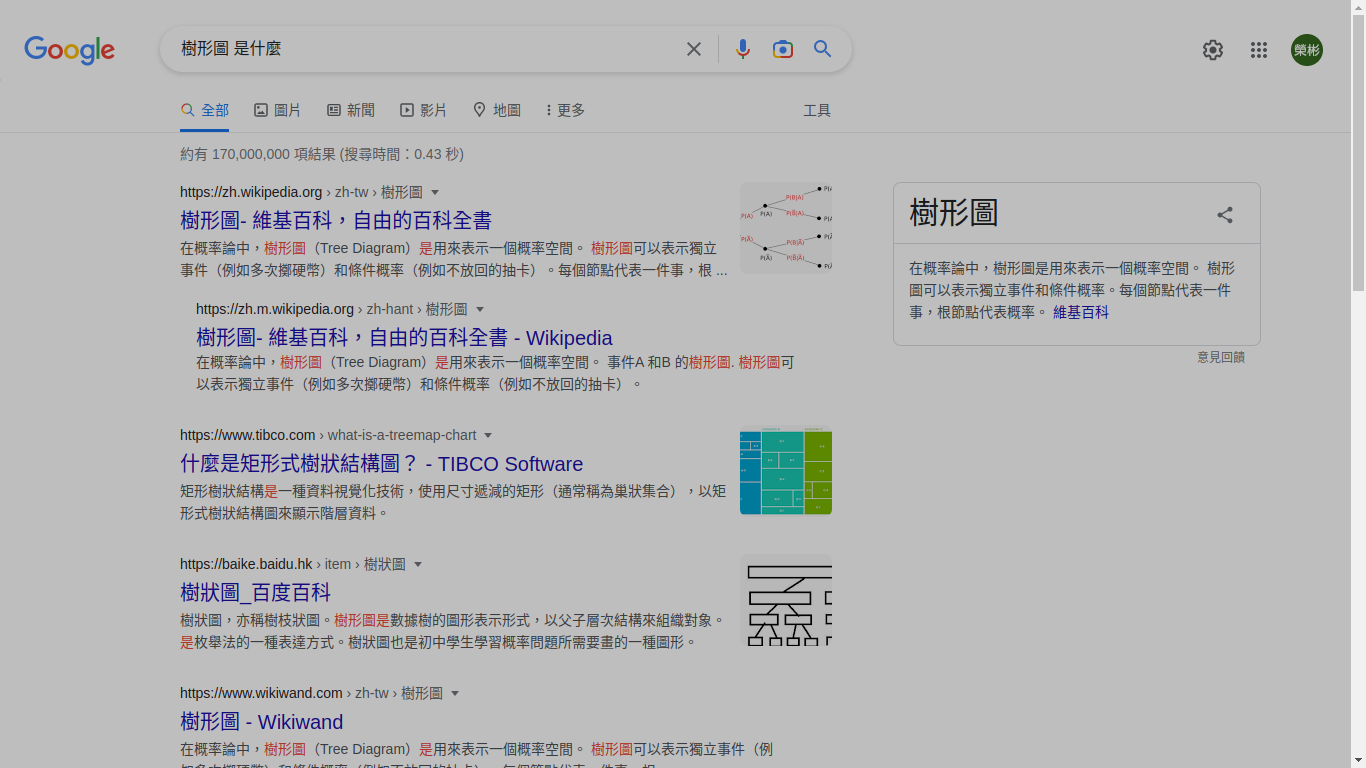
這一回,我的胃口變大了,我除了想知道「樹形圖 是什麼」,還想知道「世人、網民」怎麼看、怎麼用「樹形圖」?於是乎,我必須「往下滑動搜尋結果」,同時「點開」某個我覺得「可能有東西」的網頁。首先是這一個標題吸引我的目光,因為這一個英文字,MindOnMap,一個畢業之後持續與我合作、聊天說地的系友的維生工具:
什麼是樹形圖:定義、優缺點、何時使用等 - MindOnMap
點開之後,看到

第二個吸引我的標題是
樹狀結構圖 - IBM
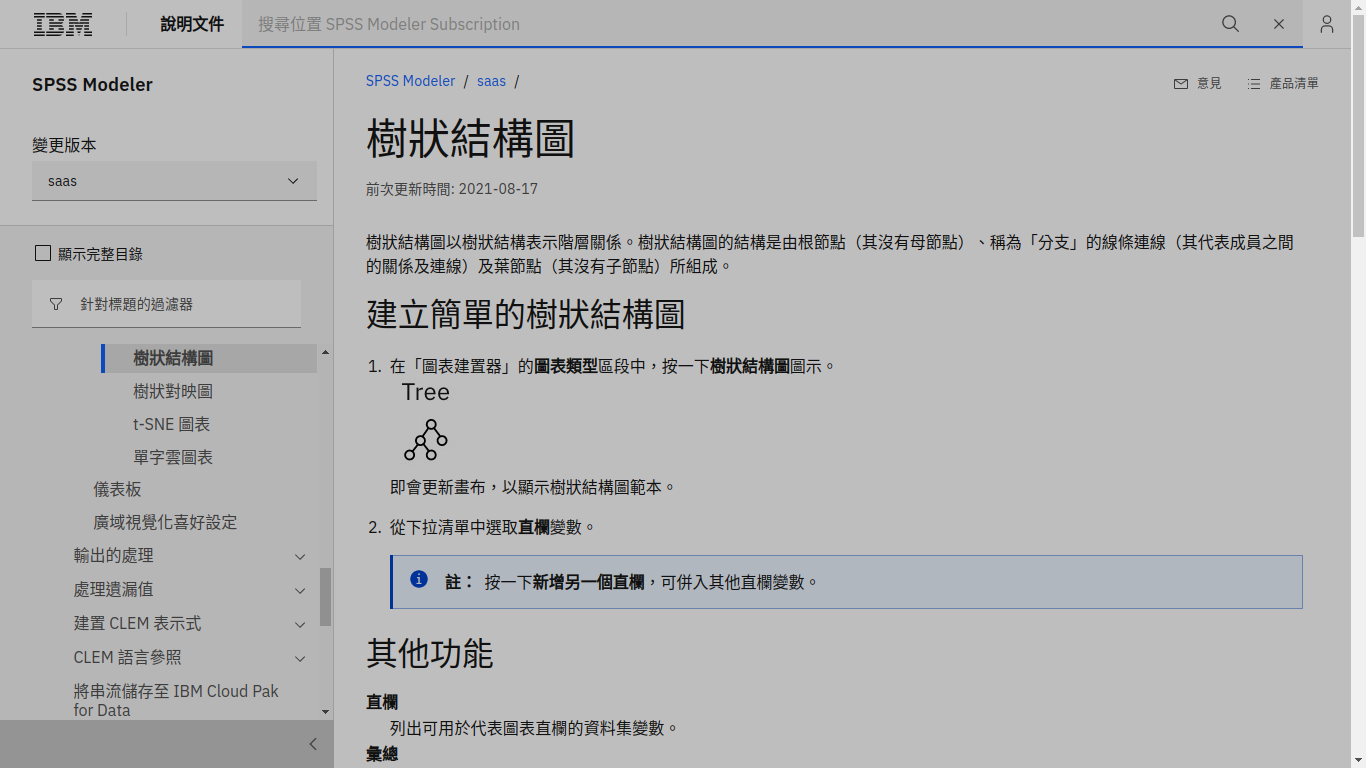
原因是「IBM」是一家歷史悠久的電腦軟硬體大廠。我相信他們提供的內容絕對值得參考,於是乎,我取上述頁面第一段文字加以改寫,讓「我」定義「什麼是樹形圖」:
樹形圖的定義:樹形圖以樹狀結構(<)向右或是向下展開全部可能的路徑。樹狀結構可能是「一生二」、「一生三」、「…」,視情況而定。左邊或是上方的節點叫做「根節點」,往右或往下長出「葉節點」,「根節點」與「葉節點」之間的「線段」叫做「分支」。如果圖形繼續長大,「葉節點」會變身為「根節點」。記住,邊長邊註記,把「可能性的標籤(比如說,銅板實驗的「正面」或是「反面」)」寫在「分支」上,為「分支」命名。等到「樹」停止生長,把每一條路徑(從「根節點」到最右邊或是最下方的「葉節點」)上的標籤(名字)收集起來,就會得到全部可能路徑的「標籤串」。
如果只是「一枚銅板丟一次的實驗」,也就是說,只有「正面、反面」兩種出象。接下來,
「我」要開始示範「表格輔助計算」,簡稱「表算」!
首先,把「分支」上的「母體標籤,『1』跟『0』」收錄到「一個2x1的資料框(data.frame),其中『2』代表『正面加反面總共兩種可能的出象』,是資料框的『高度』;『1』代表『一枚銅板』,是資料框的『寬度』」(資料框就是俗稱的表格)裡,如下所示:
X <- expand.grid(1:0)
X## Var1
## 1 1
## 2 0仔細端詳上述透明框框裡的「R輸出(output)」,可以觀察得知「『兩個井字號後有阿拉伯數字1跟2』說明『高度是2』;『Var1』的『1』說明『寬度是1』」。現在因為只有一枚銅板,所以如果引用這一個母體「{1,0}」,
「是否出現正面」的答案就等於「正面出現幾次」的答案。
所以,沿著資料框「X」的「橫向(1)」全部加起來,就是「正面出現幾次」,然後「回存給X」:
X <- apply(X, 1, sum)
X## [1] 1 0R把「『apply(X, 1, sum)』的輸出」依序擺放在一個向量裡。再來,把「正面出現幾次」的「絕對頻率」,也就是「次數分配表」算出來,然後一樣「回存給X」:
X <- table(X)
X## X
## 0 1
## 1 1有了「絕對頻率」,那「相對頻率」就簡單了,也就得到「母體」的「機率分配表」,一樣「再回存給X」:
X <- X/sum(X)
X## X
## 0 1
## 0.5 0.5為了「更寫實」,R可以幫我們這麼「輸出」:
library(MASS)
fractions(X)## X
## 0 1
## 1/2 1/2其中,「X = 是否出現正面(朝上)」,可能的答案有「X = 0」表示「否」、表示「銅板反面朝上」跟「X = 1」表示「是」、表示「銅板正面朝上」,再加上「X = 0的機率是1/2」,而「X = 1的機率是1/2」以及「1/2 + 1/2 = 1」。
有了「一枚銅板丟一次實驗」的「機率分配表」,再加上「1/2 = 1/2」,所以「銅板是公平的」。
最後,為了繼續實踐「『借用』表格輔助計算,不論是『手算』還是『電算』」,我們試著把上述「機率分配表」放在「資料框」裡,並且加上「行名稱」,「為其正名」:
X <- as.data.frame(X, stringsAsFactors = FALSE)
X## X Freq
## 1 0 0.5
## 2 1 0.5colnames(X) <- c("是否出現正面", "機率值")
knitr::kable(X, row.names = TRUE)| 是否出現正面 | 機率值 | |
|---|---|---|
| 1 | 0 | 0.5 |
| 2 | 1 | 0.5 |
有了這一張資料框,我們可以輕鬆地驗證上述「機率分配表」到底
是不是機率分配表?
X$介於零壹之間 <- X$機率值 >= 0 & X$機率值 <= 1
X$累加機率值 <- cumsum(X$機率值)
knitr::kable(X, row.names = TRUE)| 是否出現正面 | 機率值 | 介於零壹之間 | 累加機率值 | |
|---|---|---|---|---|
| 1 | 0 | 0.5 | TRUE | 0.5 |
| 2 | 1 | 0.5 | TRUE | 1.0 |
審慎觀察上述「大」資料框,我們可以發現
- 這一張機率分配表滿足條件:每一個機率值都介於零壹之間,因為「介於零壹之間」這一行全部都是「TRUE」、
- 這一張機率分配表滿足條件:全部機率值加起來等於壹,因為「累加機率值」最後、最下方的數字是「1.0」。
所以,它是合法的機率分配表。
有了上述「大」資料框的經驗,
「表格『不止能』輔助計算」、「表格『還可以』輔助證明」。
7.5.3 建構複雜銅板實驗的樣本空間
在前一節(2.2),出現了一段接著一段的R程式碼。當時,我並沒有多做介紹!為什麼呢?
因為我,身為一位高等教育的師長、一位教科書的作者,希望為您保留一點「想像空間」,讓您有機會「抱怨一下」或是「懷疑一下」!
7.5.3.1 觀察練習:
查一查在(2.2)節那一段「R話」出現的「R字」的意思,如何呢?然後再繼續往下「樂讀」!
以下是「一枚銅板丟一次實驗」,「我」自己發展的參考碼:
X <- expand.grid(1:0)
X
X <- apply(X, 1, sum)
X
X <- table(X)
X
X <- X/sum(X)
X其中的
- 「
expand.grid(1:0)」把「樹形圖」的「全部路徑」收錄到「資料框」裡。你也可以說這一句話可以得到「一棵樹形圖」。 - 「
X」檢查前一句話的「輸出」。 - 「
apply(X, 1, sum)」,因為「一般銅板實驗的問題是『總共出現幾次人頭』」,所以我建議這一句話,可以一句話搞定「一次加總一路徑」的全部(重複)計算。 - 「
table(X)」,X的內容物不斷更新,這一句話讓我們得知「總共出現幾次人頭」全部可能性的「絕對頻率」。 - 「
X/sum(X)」,有了「絕對頻率」,這一句話讓我們得知「相對頻率」。
如果,「一枚丟一次」變成
一枚丟兩次。
程式碼這樣改,讓我們把得到「一枚公平銅板母體背後機率分配」的「expand.grid(1:0)」改成「expand.grid(1:0, 1:0)」,就一樣可以輕鬆取得「一枚銅板丟兩次實驗出現幾次人頭結果的機率分配表」:
X <- expand.grid(1:0, 1:0)
X## Var1 Var2
## 1 1 1
## 2 0 1
## 3 1 0
## 4 0 0X <- apply(X, 1, sum)
X## [1] 2 1 1 0X <- table(X)
X## X
## 0 1 2
## 1 2 1X <- X/sum(X)
X## X
## 0 1 2
## 0.25 0.50 0.25當然,這時候是練習「舉一反三」的絕佳時機,因為
7.5.3.2 課堂練習:
「一次」變「二次」、「二次」變「三次」、…
再來,我想介紹「樣本空間」了。實際上,我們已經認識「它」,只是沒有問「它」的名字。讓我們回顧一下:以下是
- 一枚銅板丟一次實驗的樣本空間
expand.grid(1:0)## Var1
## 1 1
## 2 0- 一枚銅板丟兩次實驗的樣本空間
expand.grid(1:0, 1:0)## Var1 Var2
## 1 1 1
## 2 0 1
## 3 1 0
## 4 0 0讓我們「看看(豬走路)」更多樣本空間:
- 一枚銅板丟三次實驗的樣本空間
expand.grid(1:0, 1:0, 1:0)## Var1 Var2 Var3
## 1 1 1 1
## 2 0 1 1
## 3 1 0 1
## 4 0 0 1
## 5 1 1 0
## 6 0 1 0
## 7 1 0 0
## 8 0 0 0看過上述「三」個範例,讀者諸君或許會問:
為什麼是「一枚銅板丟三次」,而不是「一次丟三枚銅板」?
如果您有注意到這件事,恭喜您;如果沒有,這會是一件事,假如您想用銅板決定某件事的下一步?
無論如何,不管是「在課學習」或是「茶餘飯後」,這一題絕對是「大哉問」,值得好好跟好朋友一起、慢慢討論「到底為什麼?」。接下來的例子,是一種「闖關遊戲(數種遊戲、實驗接連上台)」的樣本空間:
- 一枚銅板丟完一次再來一顆骰子擲一次實驗的樣本空間
expand.grid(1:0, 1:6)## Var1 Var2
## 1 1 1
## 2 0 1
## 3 1 2
## 4 0 2
## 5 1 3
## 6 0 3
## 7 1 4
## 8 0 4
## 9 1 5
## 10 0 5
## 11 1 6
## 12 0 6看過「四個案例」之後,我們「是不是」已經有能力「定義」樣本空間了呢?讓「我」試試:
「樣本空間」的定義:某些接續實驗「『全部可能出象組合』== 『定義樹形圖路徑的標籤串』」的「集合」。
為了持續練習「表算(表格輔助計算)」,我們決定用「資料框」表達「集合」,不再引用傳統數學教科書用「大括號({})」表達「集合」。這樣的進化,讓我們更有彈性、更有機會,也更有意義,至於「是不是進化了」,請讀者諸君繼續體會!比如說,我這樣寫:
X <- expand.grid(1:0, 1:0)
colnames(X) <- c("第一次銅板的出象", "第二次銅板的出象")
knitr::kable(X, row.names = TRUE)| 第一次銅板的出象 | 第二次銅板的出象 | |
|---|---|---|
| 1 | 1 | 1 |
| 2 | 0 | 1 |
| 3 | 1 | 0 |
| 4 | 0 | 0 |
更複雜的實驗可以這麼寫:
X <- expand.grid(1:0, 1:6)
colnames(X) <- c("銅板的出象", "骰子的出象")
knitr::kable(X, row.names = TRUE)| 銅板的出象 | 骰子的出象 | |
|---|---|---|
| 1 | 1 | 1 |
| 2 | 0 | 1 |
| 3 | 1 | 2 |
| 4 | 0 | 2 |
| 5 | 1 | 3 |
| 6 | 0 | 3 |
| 7 | 1 | 4 |
| 8 | 0 | 4 |
| 9 | 1 | 5 |
| 10 | 0 | 5 |
| 11 | 1 | 6 |
| 12 | 0 | 6 |
7.5.4 定義銅板實驗的隨機變數
什麼是「隨機變數」?
為了回答這一個問題,我們「應該」先回答
什麼是「變數」?
接著,回答
什麼是「隨機」?
最後,再回答
什麼是「隨機變數」?
請注意上述
解題順序。
我會在這裡特別跟讀者諸君提到「解題順序」這一件事的主要原因:個人認為不管「什麼樣的問題」,一定都有「解題步驟」。「好的解題步驟」帶您上天堂;「壞的解題步驟」帶您下地獄。我將持續努力提供「好的解題步驟」給您參考,請您試用並且上網給予回饋。萬分感激。
這一回,我們也想跳過「萬事問Google」,讓我們請「R」幫忙解題。假設我們「丟一枚公正銅板三次」:
- (第一步)先準備「樣本空間」:
X <- expand.grid(1:0, 1:0, 1:0)
colnames(X) <- c("第一次銅板的出象", "第二次銅板的出象", "第三次銅板的出象")
knitr::kable(X, row.names = TRUE)| 第一次銅板的出象 | 第二次銅板的出象 | 第三次銅板的出象 | |
|---|---|---|---|
| 1 | 1 | 1 | 1 |
| 2 | 0 | 1 | 1 |
| 3 | 1 | 0 | 1 |
| 4 | 0 | 0 | 1 |
| 5 | 1 | 1 | 0 |
| 6 | 0 | 1 | 0 |
| 7 | 1 | 0 | 0 |
| 8 | 0 | 0 | 0 |
每一次我們「丟一枚公正銅板三次」,不論過程如何「有聊」、「無聊」,
- 「每一次」看到什麼、看到哪一個出象組合「完全看機會」、
- 「每一次」都只會看到上述「八種出象組合其中的一種」、
- 不論一輩子玩多少次「每一次」,也不見得「八種出象組合全看過」、
我們用「隨機」簡稱上述的現象。
然後,「我」這一位「統計學家」為了輕鬆點,省點力氣,往後「出象組合」簡稱「出象」。所以,本書的「出象」不是單一實驗的出象,就是眾多接續實驗的出象組合。
「每一次出象」就是「一筆樣本」。我們定義了「樣本」。
- (第二步)「設計」,然後「計算」「第一個數字
X」:這一類實驗,在教科書裡常見的「X」是「總共出現幾次人頭?」
X$總共出現幾次人頭 <- apply(X, 1, sum)
knitr::kable(X, row.names = TRUE)| 第一次銅板的出象 | 第二次銅板的出象 | 第三次銅板的出象 | 總共出現幾次人頭 | |
|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 3 |
| 2 | 0 | 1 | 1 | 2 |
| 3 | 1 | 0 | 1 | 2 |
| 4 | 0 | 0 | 1 | 1 |
| 5 | 1 | 1 | 0 | 2 |
| 6 | 0 | 1 | 0 | 1 |
| 7 | 1 | 0 | 0 | 1 |
| 8 | 0 | 0 | 0 | 0 |
- 「
X」是某種數字,比如說,現在的「X = 總共出現幾次人頭」是某一個正整數、 - 既然「每一次的出象」不見得剛好就是「前一次的出象」,所以,「每一次出象帶出來的數字」就會「變來變去」、
- 我們用「變數」簡稱「變來變去的數字」。
重要觀察:「每一筆樣本」都會「生」出「某個隨機變數的數字」來。
- (下一步)我們不再說「第三步」,說不定「永遠走不到」,也有可能是「第二步」,就看「統計學家、研究者、設計師」的意圖了!現在,就讓「我」胡思亂想。
「我」想計算「是否連續出現人頭?」
X$是否連續出現人頭 <- NA
knitr::kable(X, row.names = TRUE)| 第一次銅板的出象 | 第二次銅板的出象 | 第三次銅板的出象 | 總共出現幾次人頭 | 是否連續出現人頭 | |
|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 3 | NA |
| 2 | 0 | 1 | 1 | 2 | NA |
| 3 | 1 | 0 | 1 | 2 | NA |
| 4 | 0 | 0 | 1 | 1 | NA |
| 5 | 1 | 1 | 0 | 2 | NA |
| 6 | 0 | 1 | 0 | 1 | NA |
| 7 | 1 | 0 | 0 | 1 | NA |
| 8 | 0 | 0 | 0 | 0 | NA |
「我」身為本書作者的「我」,暫時沒有答案,所以「我」指定「
NA(Not Available)」給「是否連續出現人頭」這一行,這一個欄位。
………
7.5.4.1 示範CDIO解題方法論:
「市面上」有一種解題邏輯,解題(大)步驟,叫做「CDIO」。在本書預設的範圍裡,我為這四個英文字母做了以下的定義:
- C:解析問題。這是最重要的一步。「解析問題」把「大問題」分出許許多多「小問題」,然後「再一一分析小問題」。「解析問題」,是一項非常值得擁有的能力。請讀者諸君三不五時抓到機會就練習!
- D:設計步驟。諸多「小問題」被確認之後,再來就是「排序,安排解題順序」。有時候,我們會遇到「條條大路通羅馬」的「大問題」,這時候「到底走哪一條路」就是「大問題」之後的「大問題」,建議讀者諸君「嘗試『多種』排序小問題被解決的順序」,藉此練習「降低成本」的經驗與素養。
- I:設計程式。根據上述確認後的步驟,逐一開發、搜尋每一道步驟的參考程式碼。這一段「找到」的程式碼,非常有可能是中間過程的程式碼,而不是最後「上線測試」的程式碼。現在是「網路時代」,也是「開放原始碼時代」,請讀者諸君在這一段練習「搜尋參考碼」的能力。
7.5.4.1.1 (開竅了)個人長期搜尋參考碼的體驗與觀察:
搜尋參考碼,是一種「從『search』出發,最後停在『research』的探索活動」。話說單純,「起心動念」才是「關鍵」。有人重視「成果」、有人重視「歷程」,無論如何,找到「喜樂」絕對是「幸福」。
- O:測試程式。有了「每一個小問題、每一道步驟」的「合用程式碼」。「合用程式碼」是「改寫參考程式碼後的程式碼」,是「回答每一道小問題的程式碼」。把「全部合用程式碼組裝起來」並且「進行測試與除錯」是這一段的主要工作。當然,這一段之後,我們會有「一開始那個大問題的答案」。
現在,讓「我」示範「如何照著CDIO的指引回答『是否連續出現人頭?』這一道問題」?
- (C:解析問題)「是否連續出現人頭?」是「我」想要的「隨機變數」。什麼是「連續出現人頭」呢?比如說:第一種出象的前兩次出象,
knitr::kable(X[1,1:2], row.names = TRUE)| 第一次銅板的出象 | 第二次銅板的出象 | |
|---|---|---|
| 1 | 1 | 1 |
就是其中一個例子,而且「前後相乘」的結果是「1」;
prod(X[1,1:2]) # 乘起來等於1。## [1] 1但是,第三種出象的後兩次出象
knitr::kable(X[3,2:3], row.names = TRUE)| 第二次銅板的出象 | 第三次銅板的出象 | |
|---|---|---|
| 3 | 0 | 1 |
就不是,而且「前後相乘」的結果是「0」。
prod(X[3,2:3]) # 乘起來等於0。## [1] 0- (D:設計步驟)根據上述的觀察,我只要做完下述八次計算就會有「隨機變數:
是否連續出現人頭」的答案。
- 「第一列的第一個出象」乘以「第一列的第二個出象」是否等於
1;「第一列的第二個出象」乘以「第一列的第三個出象」是否等於1,只要出現一個1,「第一列的連續出現人頭」就等於1。 - 「第二列的第一個出象」乘以「第二列的第二個出象」是否等於
1;「第二列的第二個出象」乘以「第二列的第三個出象」是否等於1,只要出現一個1,「第二列的連續出現人頭」就等於1。 - 「第三列的第一個出象」乘以「第三列的第二個出象」是否等於
1;「第三列的第二個出象」乘以「第三列的第三個出象」是否等於1,只要出現一個1,「第三列的連續出現人頭」就等於1。 - 「第四列的第一個出象」乘以「第四列的第二個出象」是否等於
1;「第四列的第二個出象」乘以「第四列的第三個出象」是否等於1,只要出現一個1,「第四列的連續出現人頭」就等於1。 - 「第五列的第一個出象」乘以「第五列的第二個出象」是否等於
1;「第五列的第二個出象」乘以「第五列的第三個出象」是否等於1,只要出現一個1,「第五列的連續出現人頭」就等於1。 - 「第六列的第一個出象」乘以「第六列的第二個出象」是否等於
1;「第六列的第二個出象」乘以「第六列的第三個出象」是否等於1,只要出現一個1,「第六列的連續出現人頭」就等於1。 - 「第七列的第一個出象」乘以「第七列的第二個出象」是否等於
1;「第七列的第二個出象」乘以「第七列的第三個出象」是否等於1,只要出現一個1,「第七列的連續出現人頭」就等於1。 - 「第八列的第一個出象」乘以「第八列的第二個出象」是否等於
1;「第八列的第二個出象」乘以「第八列的第三個出象」是否等於1,只要出現一個1,「第八列的連續出現人頭」就等於1。
- (I:設計程式)把上述「手算」抓出來。
- 「前兩次出象前後相乘」
- 「是否等於
1」 - 「後兩次出象前後相乘」
- 「是否等於
1」 - 「
是 + 是 = 2」 - 「
是 + 否 = 1」 - 「
否 + 是 = 1」 - 「
否 + 否 = 0」 - 「上述加法結果大於等於
1就表示至少有一次前後相乘等於1」 - 「上述結果如果大於等於
1就給『是否連續出現人頭』1;如果小於1就給『是否連續出現人頭』0」
prod(X[1,1:2])## [1] 1prod(X[1,1:2]) == 1## [1] TRUEprod(X[1,2:3])## [1] 1prod(X[1,2:3]) == 1## [1] TRUE(prod(X[1,1:2]) == 1) + (prod(X[1,2:3]) == 1)## [1] 2(prod(X[1,1:2]) == 1) + (prod(X[1,2:3]) == 1) >= 1## [1] TRUEifelse((prod(X[1,1:2]) == 1) + (prod(X[1,2:3]) == 1) >= 1, 1, 0)## [1] 1prod(X[3,1:2])## [1] 0prod(X[3,1:2]) == 1## [1] FALSEprod(X[3,2:3])## [1] 0prod(X[3,2:3]) == 1## [1] FALSE(prod(X[3,1:2]) == 1) + (prod(X[3,2:3]) == 1)## [1] 0(prod(X[3,1:2]) == 1) + (prod(X[3,2:3]) == 1) >= 1## [1] FALSEifelse((prod(X[3,1:2]) == 1) + (prod(X[3,2:3]) == 1) >= 1, 1, 0)## [1] 0- (O:測試程式)以下是「我」的參考碼:
X <- expand.grid(1:0, 1:0, 1:0)
colnames(X) <- c("第一次銅板的出象", "第二次銅板的出象", "第三次銅板的出象")
X$總共出現幾次人頭 <- apply(X, 1, sum)
knitr::kable(X, row.names = TRUE)我想直接套用,就像「代公式」一般!所以,我要「找到」一個「函式(
function)」可以取代「sum」,或是「寫出」一個「函式(function)」可以取代「sum」。
- 「
連續出現人頭」這是「我」設計的「R字」。 - 引用「I:設計程式」最後一句話「
ifelse((prod(X[3,1:2]) == 1) + (prod(X[3,2:3]) == 1) >= 1, 1, 0)」,或許需要改寫(測試與除錯),並且把計算結果放在「y」裡。 - 然後「輸出(
return)」給「我」。
連續出現人頭 <- function(x){
y <- ifelse((prod(x[1:2]) == 1) + (prod(x[2:3]) == 1) >= 1, 1, 0)
return(y)
}所以,答案是
X <- expand.grid(1:0, 1:0, 1:0)
colnames(X) <- c("第一次銅板的出象", "第二次銅板的出象", "第三次銅板的出象")
X$是否連續出現人頭 <- apply(X, 1, 連續出現人頭)
knitr::kable(X, row.names = TRUE)| 第一次銅板的出象 | 第二次銅板的出象 | 第三次銅板的出象 | 是否連續出現人頭 | |
|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 |
| 2 | 0 | 1 | 1 | 1 |
| 3 | 1 | 0 | 1 | 0 |
| 4 | 0 | 0 | 1 | 0 |
| 5 | 1 | 1 | 0 | 1 |
| 6 | 0 | 1 | 0 | 0 |
| 7 | 1 | 0 | 0 | 0 |
| 8 | 0 | 0 | 0 | 0 |
經過「目視檢查」,「我」發現「答案沒有錯」!
7.5.5 「我」想定義「不公平銅板」!
經過前面四節的洗禮,我們有了「公平銅板」相關的知識與經驗!那接下來,讓我們挑戰
「活用知識」、「推廣知識」、「新創知識」!
「舉一反三」,我們已經練習過了!接下來,讓我們試試
把「公平」變成「不公平」!
也就是說,我們想知道以下這一張「機率分配表」的「從無到有」。
## X
## 0 1
## 1/3 2/37.5.5.1 題外話:
「統計學」引用「科學邏輯」、「工程邏輯」、「電腦邏輯」、「數學邏輯」與「數字邏輯」,透過「新創數字」、「設計數字」或「新創邏輯」、「設計邏輯」持續構築「觀察世界各個角落」的工具組。
先「觀察」上述「R輸出」,「我」發現「1, 2, 3」這三個數字,其中「1, 2」在「分子」;「3」在分母。然後,「1/3」上面有個「0」、「2/3」上面有個「1」。我們請R幫忙顯示「非顯而易見」的隱藏資訊:
class(X)## [1] "table"attributes(X)## $class
## [1] "table"
##
## $dim
## [1] 2
##
## $dimnames
## $dimnames$X
## [1] "0" "1"根據上述「R輸出」,發現「1/3」上面有個「0」、「2/3」上面有個「1」,這兩個「數字符號」是「文字」,不是「整數」。再加上,我們針對上述「機率分配表」,得知
0 < 1/3 < 10 < 2/3 < 11/3 + 2/3 = 1
所以,我「假設」
- 出現「
0」的機率是「1/3」,也就是「0.3333333」; - 出現「
1」的機率是「2/3」,也就是「0.6666667」;
所以,「我」這樣解題
- 定義母體
X <- c(1, 1, 0)
X## [1] 1 1 0- 定義樹形圖取得樣本空間
X <- expand.grid(X)
X## Var1
## 1 1
## 2 1
## 3 0- 定義某一個有興趣的隨機變數
X <- apply(X, 1, sum)
X## [1] 1 1 0- 計算絕對頻率表,也就是未來一定會遇到的「次數分配表」
X <- table(X)
X## X
## 0 1
## 1 2- 定義機率分配表
X <- X/sum(X)
X## X
## 0 1
## 0.3333333 0.6666667也就是用
「
{1, 1, 0}」表示這一枚「不公平銅板」的「母體」。然後引用之前學過的參考碼取得「機率分配表」。
這樣,「我」就可以定義「不公平銅板」了!
7.6 第三節:談離散型機率分配首部曲
什麼是「離散型機率分配」呢?
根據本章前述的內容,我們知道「機率分配表」定義「機率分配」。至於,「離散」兩字在「統計學」的範圍裡,是什麼意思呢?我們先看「非數字的文字」,比如說,我們在「一枚銅板丟一次實驗」裡學到的
正面、反面
我們也知道,除了「正面、反面」,「一枚銅板丟一次實驗」不會出現「其他出象」了。關於這個現象,「我」的說詞是
「正面」跟「反面」的中間沒有「可能性」了,不存在「?面」。
這時,閃過「側面」的請舉手!
第二個例子,
整數「
0」跟整數「1」之間不存在任何整數。
我們用「離散」形容這一類的現象。假如實驗的「母體」存在這一類的現象,我們會這麼說
離散型母體
然後,它會帶出「離散型機率分配表」,也就會定義「離散型機率分配」。
7.6.0.1 課堂練習:
請再舉三個「離散型母體」的例子。
再看過「三個」,如果「你」與「朋友」分享上述課堂練習的成果,說不定不只「三個」例子,把「它們」擺在一起,多看幾眼,肯定會「發現」
「有限多個出象」的「母體」會是一種「離散型母體」。我們稱呼這種母體是「有限母體」。
7.6.1 離散型均勻分配
「均勻」的意思是
「大家『機會均等』」,意思是,「全部出象『機會均等』」。「機會均等」就是「每一個出象的機率都等於『出象個數分之一』」。
- 比如說,如果母體只有「兩種出象」。為了逐步提升讀者諸君的「計算素養」,「我」會適時「請R幫忙」,可能是「某個物件」、「某個函示」、「某個套件」等等。在這裡引用放著「小寫英文字母」的向量,
letters來幫忙,如果這麼寫「letters[1:2]」就是「抓」字母「a」跟「b」。
X <- expand.grid(letters[1:2])
X## Var1
## 1 a
## 2 bX <- table(X)
X## Var1
## a b
## 1 1X <- X/sum(X)
X## Var1
## a b
## 0.5 0.5MASS::fractions(X)## Var1
## a b
## 1/2 1/2- 如果母體只有「三種出象」,
X <- expand.grid(letters[1:3])
X <- table(X)
X <- X/sum(X)
MASS::fractions(X)## Var1
## a b c
## 1/3 1/3 1/3- 如果母體只有「四種出象」,
X <- expand.grid(letters[1:4])
X <- table(X)
X <- X/sum(X)
MASS::fractions(X)## Var1
## a b c d
## 1/4 1/4 1/4 1/4- 假如你有一筆「滿意度調查」的數據,不論問卷題目怎麼寫,如果題目的選項分別是「非常滿意」、「滿意」、「沒意見」、「不滿意」、「非常不滿意」。為了後續「推論『個個選項被選到的機會均等』這一道虛無假設」,我們準備了「虛無假設成立時的機率分配」:
X <- expand.grid(c("非常滿意", "滿意", "沒意見", "不滿意", "非常不滿意"))
X <- table(X)
X <- X/sum(X)
X## Var1
## 非常滿意 滿意 沒意見 不滿意 非常不滿意
## 0.2 0.2 0.2 0.2 0.2X <- data.frame(讀者滿意度 = as.character(MASS::fractions(X)), stringsAsFactors = FALSE)
knitr::kable(X, row.names = TRUE)| 讀者滿意度 | |
|---|---|
| 非常滿意 | 1/5 |
| 滿意 | 1/5 |
| 沒意見 | 1/5 |
| 不滿意 | 1/5 |
| 非常不滿意 | 1/5 |
7.6.1.1 註記:
很可惜,也很開心,為了「視覺效果」,「我」把
- 「
X」從前三個例子的「table」變成「data.frame」,並且 - 把「分數表示式(
MASS::fractions(X))」變成「文字(as.character(MASS::fractions(X)))」。 - 請看後來的「資料框(
data.frame)」的長相。這時候,建議讀者諸君直接唸出「英文字」,並且嘗試用「英文字」思考,其中「()」唸作「of」:
class(X)## [1] "data.frame"dim(X)## [1] 5 1rownames(X)## [1] "非常滿意" "滿意" "沒意見" "不滿意" "非常不滿意"colnames(X)## [1] "讀者滿意度"class(X$讀者滿意度)## [1] "character"7.6.2 伯努利分配
「均勻」之後,當然就是「不均勻」。也就是說,接下來,「我」想
「一般化」均勻分配。
但是,這一段的
「一般化」只作到「一般化兩種出象」的「機會」,把「均勻」變成「不均勻」。
這個「只有兩個出象的不均勻分配」叫做「伯努利分配」。接下來,先不「請R」內建函式(function)幫忙,「我」要示範「如何用CDIO進行『一般化工程』」。先請
學霸參考碼。
X <- expand.grid(letters[1:2])
X <- table(X)
X <- X/sum(X)
X上述參考碼「已經」可以貼上「學霸」的標籤了,因為「它」幫我們學到諸多「Things」!雖然
此「學霸」非彼「學霸」!!!
但是,可惜的是,現在的「我」
無法「一般化」學霸參考碼!
X <- expand.grid(letters[1:2])
X <- table(X)
X <- X/sum(X)
X怎麼辦?
7.6.2.1 啟動「CDIO」解題:
- C:解析問題。這句「R話」:「
expand.grid(letters[1:2])」幫我們取得「母體」的樹形圖(現在只有「一根節點」、「兩葉節點」與「兩分支」,<),而且把這一棵樹形圖放入「資料框」。這句話的「母體」就是「letters[1:2]」,也就是「c("a", "b")」。所以,
假如我可以「一般化」定義母體的程式碼,說不定我可以「一般化」學霸參考碼!
- D:設計步驟。「我」知道「
letters」是一個「向量」,「c」是一個「函式」:
is.vector(letters)## [1] TRUEis.function(c)## [1] TRUE「向量」是「明碼」;「函式」是「暗碼」。寫「明碼」必須知道「背景」;寫「暗碼」必須認清「假設」。所以,「我」先試試「暗碼」的「函式」。
- I:設計程式。現在,「出象,只有兩種」,所以,還是可以「暫時」請「
letters[1:2]」幫忙。那,「如何『不均勻』呢?」。
遇上思緒「塞車不前」時,「我」至少會做一件事:閱讀。翻書找答案、翻書找刺激、翻書找靈感!
經過「某本商用統計學」的「二項分配」時,看到「成功的機率,p」。考量「與其它作者的聯繫度」,所以「我」決定
「函式」只要「輸入(input)」「
a」的「機率」。
當然,這一個數字必須滿足機率的數學要求,而且這一個數字可以是「分數」也可以是「小數」。
伯努利分配 <- function(p){
require(MASS)
p <- as.character(fractions(p))
p <- strsplit(p, "/")[[1]]
p <- as.integer(p)
if(length(p) == 2 & p[1] < p[2]){
X <- c(rep("a", p[1]), rep("b", (p[2] - p[1])))
X <- expand.grid(X)
colnames(X) <- "X"
X <- table(X)
X <- X/sum(X)
return(fractions(X))
} else {
return("輸入的機率值不是「太小」就是「不滿足數學要求」!")
}
}- O:測試程式。
伯努利分配(1/2)## X
## a b
## 1/2 1/2伯努利分配(1/3)## X
## a b
## 1/3 2/3伯努利分配(1/4)## X
## a b
## 1/4 3/4伯努利分配(0.1)## X
## a b
## 1/10 9/10伯努利分配(0.3)## X
## a b
## 3/10 7/10伯努利分配(0.5)## X
## a b
## 1/2 1/2伯努利分配(0.7)## X
## a b
## 7/10 3/10伯努利分配(0.9)## X
## a b
## 9/10 1/10伯努利分配(0.01)## X
## a b
## 1/100 99/100伯努利分配(0.001)## X
## a b
## 1/1000 999/1000伯努利分配(0.0001)## [1] "輸入的機率值不是「太小」就是「不滿足數學要求」!"伯努利分配(1.0)## [1] "輸入的機率值不是「太小」就是「不滿足數學要求」!"伯努利分配(2.0)## [1] "輸入的機率值不是「太小」就是「不滿足數學要求」!"7.6.2.2 再一次「一般化」伯努利分配
示範「CDIO」解題的過程中,「我」有這麼一句話:
現在,「出象只有兩種」,所以,還是可以「暫時」請「
letters[1:2]」幫忙。
現在,讓「我們」回到現實來。什麼意思呢?這世界可以「二分」為
- 「正」、「反」
- 「內」、「外」
- 「天」、「地」
- 「上」、「下」
- 「日」、「夜」
- 「黑」、「白」
- 「陰」、「陽」
- 「成功」、「失敗」
最後的「成功」與「失敗」,是其他上述「二擇一世界」的「抽象版」。因為「成功」可以被定義為
- 「正」出現了,「反」沒出現。
- 「內」出現了,「外」沒出現。
- 「天」出現了,「地」沒出現。
- 「上」出現了,「下」沒出現。
- 「日」出現了,「夜」沒出現。
- 「黑」出現了,「白」沒出現。
- 「陰」出現了,「陽」沒出現。
也就是說,「失敗」被定義為
- 「正」沒出現,「反」出現了。
- 「內」沒出現,「外」出現了。
- 「天」沒出現,「地」出現了。
- 「上」沒出現,「下」出現了。
- 「日」沒出現,「夜」出現了。
- 「黑」沒出現,「白」出現了。
- 「陰」沒出現,「陽」出現了。
讓「我們」重新定義「伯努利分配」這一支函式,
伯努利分配 <- function(p){
require(MASS)
p <- as.character(fractions(p))
p <- strsplit(p, "/")[[1]]
p <- as.integer(p)
if(length(p) == 2 & p[1] < p[2]){
X <- c(rep("成功", p[1]), rep("失敗", (p[2] - p[1])))
X <- expand.grid(X)
colnames(X) <- "X"
X <- table(X)
X <- X/sum(X)
return(fractions(X))
} else {
return("輸入的機率值不是「太小」就是「不滿足數學要求」!")
}
}然後,再一次「測試」,
伯努利分配(1/2)## X
## 成功 失敗
## 1/2 1/2伯努利分配(1/3)## X
## 成功 失敗
## 1/3 2/3伯努利分配(1/4)## X
## 成功 失敗
## 1/4 3/4伯努利分配(0.1)## X
## 成功 失敗
## 1/10 9/10伯努利分配(0.3)## X
## 成功 失敗
## 3/10 7/10伯努利分配(0.5)## X
## 成功 失敗
## 1/2 1/2伯努利分配(0.7)## X
## 成功 失敗
## 7/10 3/10伯努利分配(0.9)## X
## 成功 失敗
## 9/10 1/10伯努利分配(0.01)## X
## 成功 失敗
## 1/100 99/100伯努利分配(0.001)## X
## 成功 失敗
## 1/1000 999/1000伯努利分配(0.0001)## [1] "輸入的機率值不是「太小」就是「不滿足數學要求」!"伯努利分配(1.0)## [1] "輸入的機率值不是「太小」就是「不滿足數學要求」!"伯努利分配(2.0)## [1] "輸入的機率值不是「太小」就是「不滿足數學要求」!"7.6.2.3 有請「R官方的好朋友distributions3」出場!
「我」發現「R社群」出現「distributions3」這一個套件(package),當「我」在準備2022年(新冠肺炎全球大流行的第三年)「暑修數理統計(II)」的時候,「distributions3」這一本巨著,竟然可以快速、有效地把
「數理統計」數字化。
請讓「我」透過「伯努利分配(Bernoulli distribution)」為您介紹「distributions3」。首先,「我」到「library」借出「distributions3」:
library(distributions3)接著定義「成功機率」,p,
p <- 0.9再請巨著「distributions3」幫我「定義『成功機率等於0.9的伯努利分配』」。
X <- Bernoulli(p)
X## [1] "Bernoulli distribution (p = 0.9)"為了「確認幫手的可信度」,「我」要求「distributions3」透過「機率密度函數(pdf, probability density function)」,也就是本章已經介紹過的「機率分配表」,計算「出現、觀察到『成功』跟『失敗』」的機率。
pdf(X, 1)## [1] 0.9pdf(X, 0)## [1] 0.1再來,「我」想知道「我的函示伯努利分配」做不到的部分,「distributions3」給(輸出)「我」什麼?
p <- 0.0001
X <- Bernoulli(p)
X## [1] "Bernoulli distribution (p = 0.0001)"pdf(X, 0)## [1] 0.9999pdf(X, 1)## [1] 0.0001真開心!為什麼?因為,「自我發展」是每一個人的「天賦人權」,「發展停滯」乃「稀鬆平常」,趁勢、順勢練習「解決問題」的能力才是「自我發展」的本質!
事實證明「distributions3」這一本巨著、這一個套件確實可以讓「我」繼續前行!最後,檢查「X」是什麼物件?
class(X)## [1] "Bernoulli" "distribution"7.6.3 二項分配
本節(第三節)一開始談「均勻分配」,討論過一輪之後,為了繼續「自我發展」,「我」建議啟動「一般化工程」,
把「兩種出象的機會,從『均勻』變成『不均勻』,實際上變成『不一定均勻』」,
經過一番「努力」與「來往」,尤其是「與R社群的來往」,變出了「伯努利分配」。
希望現在的您,「鼓足勇氣」並且決定「繼續往前」!
在「我們 = 『我』加『R社群』」繼續進一步「一般化」之前,先讓「我們」看看「伯努利分配」的樹形圖:
p = 1/2
p <- 1/2
p <- as.character(fractions(p))
p <- strsplit(p, "/")[[1]]
p <- as.integer(p)
X <- c(rep("成功", p[1]), rep("失敗", (p[2] - p[1])))
X <- expand.grid(X)
colnames(X) <- "X"
X## X
## 1 成功
## 2 失敗p = 1/3
p <- 1/3
p <- as.character(fractions(p))
p <- strsplit(p, "/")[[1]]
p <- as.integer(p)
X <- c(rep("成功", p[1]), rep("失敗", (p[2] - p[1])))
X <- expand.grid(X)
colnames(X) <- "X"
X## X
## 1 成功
## 2 失敗
## 3 失敗p = 2/3
p <- 2/3
p <- as.character(fractions(p))
p <- strsplit(p, "/")[[1]]
p <- as.integer(p)
X <- c(rep("成功", p[1]), rep("失敗", (p[2] - p[1])))
X <- expand.grid(X)
colnames(X) <- "X"
X## X
## 1 成功
## 2 成功
## 3 失敗讓我們順勢而為,
7.6.3.3 第一次定義「二項分配」
這一節,我們接續前一節的「一般化」企圖,繼續「一般化」,並且將苗頭指向
「重複」、「重複實驗」或是「重複觀察」。
為什麼往這樣的方向「一般化」呢?讓我們回顧一下,前兩個機率分配可能是為了「什麼?」
- 關於「銅板實驗」:
- 「一枚公平銅板丟一次實驗」背後的「機率分配」就是「均勻分配」。
- 「一枚公平銅板丟一次實驗」背後的「機率分配」也是「伯努利分配」。
- 「一枚公平銅板丟一次實驗」跟「均勻分配」之間的橋樑是「出現哪一面?」。
- 「一枚公平銅板丟一次實驗」跟「伯努利分配」之間的橋樑是「出現正面的次數?」。
- 關於「骰子實驗」:
- 「一枚公平骰子丟一次實驗」背後的「機率分配」也是「均勻分配」。
- 「一枚公平骰子丟一次實驗」背後的「機率分配」也可以是「伯努利分配」。
- 「一枚公平骰子丟一次實驗」跟「均勻分配」之間的橋樑是「出現哪一個點數?」。
- 「一枚公平骰子丟一次實驗」跟「伯努利分配」之間的橋樑是「出現三點的次數?」。
- 關於「重複實驗」:
- 「一枚銅板丟兩次實驗」背後的「機率分配」是哪一個呢?也就是,
- 「一枚銅板丟一次實驗」被「重複兩次」背後的「機率分配」是哪一個呢?
- 「一枚銅板丟一次實驗」被「重複多次」背後的「機率分配」是哪一個呢?
- 「一枚骰子丟兩次實驗」背後的「機率分配」是哪一個呢?也就是,
- 「一枚骰子丟一次實驗」被「重複兩次」背後的「機率分配」是哪一個呢?
- 「一枚骰子丟一次實驗」被「重複多次」背後的「機率分配」是哪一個呢?
我們可以這麼回答嗎?
重複多少次的伯努利分配。
先不管這一個答案「對」還是「錯」?我們想知道一個「橋樑 = 隨機變數」「服從」哪一種「機率分配」?這一個「隨機變數」是
成功次數。
「我」之所以這樣問、這樣設計、這樣算!乃因為
「伯努利分配」背後的「母體」等於「某些『成功』加某些『失敗』的集合」。
這是「『一般化』之路」的一處「休息站」。「『一般化』之路」走到這裡,「一般人」肯定已經「受不了」了,因為「看不到路的盡頭」,如果再加上「孤獨地走著」,那肯定是「雪上加霜」!通常這時候,「我」會「請R」幫忙,因為「我」相信
「找人幫忙手算」跟「找人幫忙電算」比起來,難度一定「高上許多」!話雖如此,有了R,「我」可以變成「我們」;下一次,希望「您」「我」成為朋友,「我」再一次變成「我們」。
所以,「我們」把「伯努利分配的樹形圖」的測試碼,變出產生「伯努利分配背後母體」的函式來,取名為「伯努利母體」。
伯努利母體 <- function(p){
p <- as.character(fractions(p))
p <- strsplit(p, "/")[[1]]
p <- as.integer(p)
X <- c(rep("成功", p[1]), rep("失敗", (p[2] - p[1])))
return(X)
}然後,嘗試看看「電算」加「表算」,把「一枚公平銅板丟兩次實驗的出象」會得到「幾次正面」,也就是「某一種出象的成功次數」背後的「機率分配」算出來:
- (第一步)準備實驗的樹形圖:
X1 <- 伯努利母體(p = 1/2)
X2 <- X1
X <- expand.grid(X1, X2)
colnames(X) <- c("X1", "X2")
knitr::kable(X, row.names = TRUE)| X1 | X2 | |
|---|---|---|
| 1 | 成功 | 成功 |
| 2 | 失敗 | 成功 |
| 3 | 成功 | 失敗 |
| 4 | 失敗 | 失敗 |
- (第二步)計算每一種出象(樹形圖上的某一條路徑)的成功次數:
X$成功次數 <- apply(X == "成功", 1, sum)
knitr::kable(X, row.names = TRUE)| X1 | X2 | 成功次數 | |
|---|---|---|---|
| 1 | 成功 | 成功 | 2 |
| 2 | 失敗 | 成功 | 1 |
| 3 | 成功 | 失敗 | 1 |
| 4 | 失敗 | 失敗 | 0 |
- (第三步)計算成功次數的機率分配表:
X <- X$成功次數
X <- table(X)
X <- X/sum(X)
MASS::fractions(X)## X
## 0 1 2
## 1/4 1/2 1/4- (製作報表)把上述機率分配表放在資料框裡:
X <- data.frame(二項機率 = as.character(MASS::fractions(X)), stringsAsFactors = FALSE)
knitr::kable(X, row.names = TRUE)| 二項機率 | |
|---|---|
| 0 | 1/4 |
| 1 | 1/2 |
| 2 | 1/4 |
再「玩」一次,這一回是「重複三次」:
X1 <- 伯努利母體(p = 1/2)
X2 <- X1
X3 <- X1
X <- expand.grid(X1, X2, X3)
colnames(X) <- c("X1", "X2", "X3")
X$成功次數 <- apply(X == "成功", 1, sum)
X <- X$成功次數
X <- table(X)
X <- X/sum(X)
X <- data.frame(二項機率 = as.character(MASS::fractions(X)), stringsAsFactors = FALSE)
knitr::kable(X, row.names = TRUE)| 二項機率 | |
|---|---|
| 0 | 1/8 |
| 1 | 3/8 |
| 2 | 3/8 |
| 3 | 1/8 |
再「玩」一次,但是這一回除了「重複三次」,「成功機率」由「1/2」變成「1/3」:
X1 <- 伯努利母體(p = 1/3)
X2 <- X1
X3 <- X1
X <- expand.grid(X1, X2, X3)
colnames(X) <- c("X1", "X2", "X3")
X$成功次數 <- apply(X == "成功", 1, sum)
X <- X$成功次數
X <- table(X)
X <- X/sum(X)
X <- data.frame(二項機率 = as.character(MASS::fractions(X)), stringsAsFactors = FALSE)
knitr::kable(X, row.names = TRUE)| 二項機率 | |
|---|---|
| 0 | 8/27 |
| 1 | 4/9 |
| 2 | 2/9 |
| 3 | 1/27 |
「我們」一路發展下來,從最簡單的「一枚銅板丟一次實驗」、「」
有失有得?