Chapter 11 探索式數據分析二部曲
11.1 續
先回顧我們的進度:
11.1.2 第二章
探索式數據分析首部曲。再一次確認當年(1970, 1978)學者的研究目標後,首先對「房價中位數」進行「探索式分析」。這是「單變量變數的探索式分析」。既然是「探索式分析」,意味著要先取得「房價中位數(medv)」的
分配。
在第二章我們先繪製「莖葉圖」再取得「次數分配表」。「莖葉圖」已經存活了超過120年,它是1900年代Arthur Bowley的創意。不僅可以保留原始數據,還可以分成「單莖、雙莖、伍莖、拾莖」分群原始數據,在「每莖」還按「阿拉伯數字」順序依序「排列」原始數據的最後一個位數,於是「數(樹)狀」於焉成形,也就看出了分配的形狀。「房價中位數(medv)」的形狀是
- 「單峰」、
- 「非對稱」、
- 「長尾型」、
- 「長尾在右」、
- 「疑似(出現)離群值」、
- 「存在設限數據」。
房價中位數的「高峰」發生在「[19.0,23.9](以千美元計)」這個區間內。除了以上對「房價中位數分配」的觀察,作者小編也提醒了幾點「統計學的專業注意事項」:
- 「房價中位數」是一群房價的中位數,所以一定有50%的房價高過這一個數字,而且無法得知高多少?
- 「房價中位數」只要超過五萬美元通通被紀錄為五萬美元,這是統計學的「設限資料」,也表示五萬美元這些數字的紀錄誤差可能更高。
除了用「莖葉圖」呈現原始數據的分配,作者小編也製作了「各種範圍區間」的「次數分配表」跟「相對次數分配表」,雖然「次數分配表」無法呈現「分配的形狀」,也「掩蓋、濃縮原始數據」,無論如何,「次數分配表」提供快速檢視分配的介面,使用者可以藉此(次數分配表)了解「分配」的梗概。比如說,
- 最小值在哪一個區間?
- 最大值在哪一個區間?
- 最多數字落入哪一個區間?
- 是不是單峰?
- 是不是多峰?尤其是不是「M型」?
- 是不是長尾?
- 長尾在右?還是長尾在左?
諸如此類,一樣可以「(比起莖葉圖)慢慢找到答案」,雖然沒有辦法得知原始數據的相關細節。除了上述兩種呈現分配的技術,作者小編還請來了
協助計算各種「敘述統計量」。「敘述統計量」是「摘要分配的數字」,也叫做「摘要統計量」。基本上,「摘要統計量」就是「濃縮分配的數字」,除了源自數學理論的數字、統計理論的數字,還有源自其他專業領域的數字,諸如
- 最小值
- 最大值
- 中位數
- 四分位數
- 十分位數
- 百分位數
- 間距
- 四分位數間距
- 十分位數間距
- 百分位數間距
- 平均絕對誤差
- 平均數
- 去頭去尾平均數
- 加權平均數
- 變異數
- 標準差
- 偏度
- 扁度
- 變異係數
- 誤差係數
- …
不勝枚舉!
在第二章,我們只研究「medv」,房價中位數的分配、的敘述統計量,也請專家幫我們製作「摘要統計量報表」,也學到如何「DIY報表」。接下來,我們要
重複在第二章的動作。
為波士頓數據集的14個變數製作「摘要統計量報表」,甚至是「分群、分段的摘要統計量報表」。
11.1.3 準備工作
先載入波士頓數據集的背景說明,方便作者小編後續的解說、解釋與教學:
colsBostonFull<-readRDS("/home/fcu/ShinyApps/Textbooks/BOSTON/chapter02/output/data/colsBostonFull.rds")## Warning in gzfile(file, "rb"): 無法開啟壓縮過的檔案
## '/home/fcu/ShinyApps/Textbooks/BOSTON/chapter02/output/data/colsBostonFull.rds',可能的原因是
## '沒有此一檔案或目錄'## Error in gzfile(file, "rb"): 無法開啟連接colsBostonFull## 說明
## CRIM per capita crime rate by town
## ZN proportion of residential land zoned for lots over 25,000 sq.ft.
## INDUS proportion of non-retail business acres per town
## CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)
## NOX nitric oxides concentration (parts per 10 million)
## RM average number of rooms per dwelling
## AGE proportion of owner-occupied units built prior to 1940
## DIS weighted distances to five Boston employment centres
## RAD index of accessibility to radial highways
## TAX full-value property-tax rate per $10,000
## PTRATIO pupil-teacher ratio by town
## BLACK 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town
## LSTAT % lower status of the population
## MEDV Median value of owner-occupied homes in $1000's
## 中文翻譯 中文變數名稱
## CRIM 每個城鎮人均犯罪率。 犯罪率
## ZN 超過25,000平方呎的住宅用地比例。 住宅用地比例
## INDUS 每個城鎮非零售業務英畝的比例。 非商業區比例
## CHAS 是否鄰近Charles River。 河邊宅
## NOX 氮氧化合物濃度。 空汙指標
## RM 每個住宅的平均房間數。 平均房間數
## AGE 1940年之前建造的自用住宅比例。 老房子比例
## DIS 距波士頓五大商圈的加權平均距離。 加權平均距離
## RAD 環狀高速公路的可觸指標。 交通便利性
## TAX 財產稅占比(每一萬美元)。 財產稅率
## PTRATIO 生師比。 生師比
## BLACK 黑人的比例。 黑人指數
## LSTAT (比較)低社經地位人口的比例。 低社經人口比例
## MEDV 以千美元計的房價中位數。 房價中位數11.3 連戲
進入第三章,我們即將進入新的里程碑,原因是
我們將離開第二章的單變量、單變數,進入第三章的多變量、多變數!
作者小編將在這裡、這一章示範幾種可能性,不論是「分析案例」還是「撰寫程式」,
- 重複單變量學過的「動作集」許許多多次,可能至少14次、
- 發現、發想、實驗可以一次處理「多」的程式、
無論如何,作者小編用
連戲
二字形容、比喻「我如何學」、「我如何教」。所謂「連戲」,就是「用剛剛學到『舊問題』的『舊程式碼』發展『新問題』的『新程式碼』」。所以
Q1:認識變數medv的分配。
延伸出
Q2:認識變數crim, zn, indus, chas, nox, rm, age, dis, rad, tax, ptratio, black, lstat, medv的分配。
注意事項:作者小編並沒有一個變數一個變數「打」,連「逗號」都是R幫小編的,而是一段小小程式幫我顯示全部變數名稱。請讀者諸君自行挑戰解這一道題目。
…
11.3.1 發現全部波士頓數據集的次數分配表而不是莖葉圖
我們先
- 準備波士頓數據集
require(MASS) # 用「require」不用「library」,是因為如果R已經將套件MASS載入環境,就不需要再載一次。
data(Boston)
boston <- Boston
# 「不動」原始數據集,不論它有「多原始」,是R程式設計的一項絕佳習慣。
# 即便一般使用者是無法任意改變套件MASS的內容物!- 繪製「房價中位數」的莖葉圖
require(aplpack)
stem.leaf(boston[, "medv"], unit = 0.1) # 因為每一筆medv數據都帶著一位小數,所以設定「unit = 0.1」。## 1 | 2: represents 1.2
## leaf unit: 0.1
## n: 506
## 3 5 | 006
## 4 6 | 3
## 11 7 | 0022245
## 21 8 | 1334455788
## 24 9 | 567
## 34 10 | 2224455899
## 43 11 | 035778899
## 52 12 | 013567778
## 76 13 | 011112333444455668888899
## 94 14 | 011123344555668999
## 110 15 | 0001222344666667
## 126 16 | 0111223455667788
## 148 17 | 0111222344455567888889
## 173 18 | 0122233444555566777889999
## 210 19 | 0011112233333444444555566666778889999
## 246 20 | 000001111122333344445556666667788899
## (31) 21 | 0001122222444445566777777788999
## 229 22 | 00000001222223344555666667788889999
## 194 23 | 0000111111122223333445667777888899999
## 157 24 | 0011123334444555667778888
## 132 25 | 00000000123
## 121 26 | 24456667
## 113 27 | 011555599
## 104 28 | 0124456777
## 94 29 | 0011466889
## 84 30 | 1113578
## 77 31 | 01255667
## 69 32 | 0024579
## 62 33 | 011223448
## 53 34 | 67999
## 48 35 | 1244
## 44 36 | 012245
## 38 37 | 02369
## HI: 38.7 39.8 41.3 41.7 42.3 42.8 43.1 43.5 43.8 44 44.8 45.4 46 46.7 48.3 48.5 48.8 50 50 50 50 50 50 50 50 50 50 50 50 50 50 50 50這是一棵「大樹」,即便「我們要求stem.leaf把『疑似離群值』藏起來(落地不上樹)」。「莖葉圖」會是一棵「大樹」,可能有幾個原因
- 數字很多、
- 太多數字擁有兩個以上的小數、
- 數字過度集中在某一莖上、
加上「莖葉圖」是「低解析度的圖」,無法「儲存、呈現」太多資訊。上述諸多理由讓「莖葉圖」雖然是「學」統計學的利器,卻不是「用」統計學的利器。但在第二章,除了「莖葉圖」,我們還學了「次數分配表」,而且是「任意切割、任意範圍的次數分配表」。請回憶當時我們如何取得「房價中位數」的次數分配表?
table(cut(boston[, "medv"], breaks = seq(4.9, 50.9, 1.0)))##
## (4.9,5.9] (5.9,6.9] (6.9,7.9] (7.9,8.9] (8.9,9.9] (9.9,10.9]
## 3 1 7 10 3 10
## (10.9,11.9] (11.9,12.9] (12.9,13.9] (13.9,14.9] (14.9,15.9] (15.9,16.9]
## 9 9 24 18 16 16
## (16.9,17.9] (17.9,18.9] (18.9,19.9] (19.9,20.9] (20.9,21.9] (21.9,22.9]
## 22 25 37 36 31 35
## (22.9,23.9] (23.9,24.9] (24.9,25.9] (25.9,26.9] (26.9,27.9] (27.9,28.9]
## 37 25 11 8 9 10
## (28.9,29.9] (29.9,30.9] (30.9,31.9] (31.9,32.9] (32.9,33.9] (33.9,34.9]
## 10 7 8 7 9 5
## (34.9,35.9] (35.9,36.9] (36.9,37.9] (37.9,38.9] (38.9,39.9] (39.9,40.9]
## 4 6 5 1 1 0
## (40.9,41.9] (41.9,42.9] (42.9,43.9] (43.9,44.9] (44.9,45.9] (45.9,46.9]
## 2 2 3 2 1 2
## (46.9,47.9] (47.9,48.9] (48.9,49.9] (49.9,50.9]
## 0 3 0 16這張表其實是一開始那一張「莖葉圖」的縮影,成功的關鍵是「breaks = seq(4.9, 50.9, 1.0)」這一句話裡頭的「4.9」、「50.9」跟「1.0」,其中「4.9」是最接近且小於「5」的「.9」;而「50.9」是最接近且大於「50」的「.9」;至於「1.0」則是為了「模仿」莖葉圖的「單莖」。我們可以簡單一句話「喚出」房價中位數的最小值跟最大值,然後根據上述原則加上「十進位實數制」找到「.9」。
range(boston[, "medv"])## [1] 5 50記住,R是互動式語言,所以以下三句不是一次「打完」,而是根據這一句R的回應「寫」下一句,「一句喚出一句」持續跟R溝通「一步一步」找到「心中問題的答案」。
作者小編接下來的問題是
發現波士頓數據集第一個欄位的最大值跟最小值,
而且希望「仿」、「連戲」這句話「range(boston[, "medv"])」,所以「仿著寫」之前要先知道
第一個欄位的名字。
因為我們知道「medv」是「房價中位數」那個欄位的「英文名字」。於是乎,作者小編的下一句話是
colnames(boston)## [1] "crim" "zn" "indus" "chas" "nox" "rm" "age"
## [8] "dis" "rad" "tax" "ptratio" "black" "lstat" "medv"看到R的回應後,把畫面第一個出現在「兔子內」的「crim」換掉「medv」再寫出下一句話:
range(boston[, "crim"])## [1] 0.00632 88.97620看到答案後,作者小編呆住了許久
…
…
閃過幾個念頭:
- 最小值真小!
- 這麼多位小數!
- 不知如何繪製它的莖葉圖,諸如,怎麼定義葉子?最後一位小數?最後兩位小數?
- 接連帶出,下界要用哪一個「
.9」? - 上界要用哪一個「
.9」? - 維持「單莖」,還是像之前在第二章取「
1.0」的幾倍?
…
無言!
…
所以決定(繼續)先「用」下面這一句話,把全部欄位的最小值跟最大值「喚出來」:
sapply(boston, range)## crim zn indus chas nox rm age dis rad tax ptratio black
## [1,] 0.00632 0 0.46 0 0.385 3.561 2.9 1.1296 1 187 12.6 0.32
## [2,] 88.97620 100 27.74 1 0.871 8.780 100.0 12.1265 24 711 22.0 396.90
## lstat medv
## [1,] 1.73 5
## [2,] 37.97 50注意:這一回沒有請Google Search幫忙,而直接「蹦」、「用」這樣的動詞給建議程式碼,是因為在探索式數據分析首部曲跟寫一段下載數據集的耙蟲,我們已經學過「
sapply」,知道它可以一次處理、重複某一個動作「14」次,比如說,檢查內容物屬性的「class」跟拆字的「strsplit」。
看過上述答案一輪之後,
…
11.3.2 整數與實數 vs 離散與連續
我們在第二章已經確認過一次波士頓數據集每一個欄位、變數內容物的屬性,是哪一種數字
sapply(boston, class)## crim zn indus chas nox rm age dis
## "numeric" "numeric" "numeric" "integer" "numeric" "numeric" "numeric" "numeric"
## rad tax ptratio black lstat medv
## "integer" "numeric" "numeric" "numeric" "numeric" "numeric"其中
colnames(boston)[which(sapply(boston, class) == "integer")]## [1] "chas" "rad"是「整數」,剩下的
colnames(boston)[which(sapply(boston, class) == "numeric")]## [1] "crim" "zn" "indus" "nox" "rm" "age" "dis"
## [8] "tax" "ptratio" "black" "lstat" "medv"都是「實數」。接下來,作者小編先進一步檢查這兩個「整數型變數」的其他性質
sapply(boston[, c("chas", "rad")], range) # 最小值跟最大值## chas rad
## [1,] 0 1
## [2,] 1 24unique(boston[, "chas"]) # 有哪些不一樣數據?## [1] 0 1unique(boston[, "rad"])## [1] 1 2 3 5 4 8 6 7 24NROW(unique(boston[, "chas"]))/NROW(boston)*100.0 # 不一樣數據的佔比?## [1] 0.3952569NROW(unique(boston[, "rad"]))/NROW(boston)*100.0## [1] 1.778656再則,取得它們的次數分配表就這麼簡單
table(boston[, "chas"])##
## 0 1
## 471 35table(boston[, "rad"])##
## 1 2 3 4 5 6 7 8 24
## 20 24 38 110 115 26 17 24 132我們稱呼這一類的變數是「離散型變數」。至於不是這一類的變數,被我們稱呼為「連續型變數」。我們再看一次波士頓數據集每一個欄位、變數的最小值跟最大值,也就是每一個變數的數字範圍(range)。但是這一回,我們把「離散型變數」放在前頭,「連續型變數」放在後頭:
DISvars <- colnames(boston)[which(sapply(boston, class) == "integer")]
CONvars <- colnames(boston)[which(sapply(boston, class) == "numeric")]
sapply(boston[, c(DISvars, CONvars)], range)## chas rad crim zn indus nox rm age dis tax ptratio black
## [1,] 0 1 0.00632 0 0.46 0.385 3.561 2.9 1.1296 187 12.6 0.32
## [2,] 1 24 88.97620 100 27.74 0.871 8.780 100.0 12.1265 711 22.0 396.90
## lstat medv
## [1,] 1.73 5
## [2,] 37.97 50接下來,我們要研究「連續型變數」的
- 有哪些不一樣數據?
- 不一樣數據的佔比?
像原表(波士頓數據集)內的第一個欄位,,它的意義是「per capita crime rate by town」,是一種「比率」或是「比例」,再根據上述R提供的數字範圍,我們認定的內容物是一串「『有好幾位小數』的實數(有小數點的數字,雖然我們已經知道在R的環境裡是實數了)」。再則「最大值」是「最小值」的
range(boston[, "crim"])[2]/range(boston[, "crim"])[1]## [1] 14078.51倍,而且彼此的差距是「88.96988」。再則「不一樣的數字個數」
NROW(unique(boston[, "crim"])) ## [1] 504NROW(boston) # 這麼接近樣本數,「`r NROW(boston)`」。## [1] 506NROW(unique(boston[, "crim"]))/NROW(boston)*100.0 # 佔比是## [1] 99.60474再再都在說明變數是一種「連續型變數」。它的次數分配表,如果簡單地這麼跟R說,會看到
table(boston[, "crim"])##
## 0.00632 0.00906 0.01096 0.01301 0.01311 0.0136 0.01381 0.01432 0.01439 0.01501
## 1 1 1 1 1 1 1 1 1 2
## 0.01538 0.01709 0.01778 0.0187 0.01951 0.01965 0.02009 0.02055 0.02177 0.02187
## 1 1 1 1 1 1 1 1 1 1
## 0.02498 0.02543 0.02729 0.02731 0.02763 0.02875 0.02899 0.02985 0.03041 0.03049
## 1 1 1 1 1 1 1 1 1 1
## 0.03113 0.0315 0.03237 0.03306 0.03359 0.03427 0.03445 0.03466 0.03502 0.0351
## 1 1 1 1 1 1 1 1 1 1
## 0.03537 0.03548 0.03551 0.03578 0.03584 0.03615 0.03659 0.03705 0.03738 0.03768
## 1 1 1 1 1 1 1 1 1 1
## 0.03871 0.03932 0.03961 0.04011 0.04113 0.04203 0.04294 0.04297 0.04301 0.04337
## 1 1 1 1 1 1 1 1 1 1
## 0.04379 0.04417 0.04462 0.04527 0.04544 0.0456 0.0459 0.04666 0.04684 0.04741
## 1 1 1 1 1 1 1 1 1 1
## 0.04819 0.04932 0.04981 0.05023 0.05059 0.05083 0.05188 0.05302 0.0536 0.05372
## 1 1 1 1 1 1 1 1 1 1
## 0.05425 0.05479 0.05497 0.05515 0.05561 0.05602 0.05644 0.05646 0.0566 0.05735
## 1 1 1 1 1 1 1 1 1 1
## 0.0578 0.05789 0.06047 0.06076 0.06127 0.06129 0.06151 0.06162 0.06211 0.06263
## 1 1 1 1 1 1 1 1 1 1
## 0.06417 0.06466 0.06588 0.06617 0.06642 0.06664 0.06724 0.0686 0.06888 0.06899
## 1 1 1 1 1 1 1 1 1 1
## 0.06905 0.06911 0.07013 0.07022 0.07151 0.07165 0.07244 0.07503 0.07875 0.07886
## 1 1 1 1 1 1 1 1 1 1
## 0.07896 0.0795 0.07978 0.08014 0.08187 0.08199 0.08221 0.08244 0.08265 0.08308
## 1 1 1 1 1 1 1 1 1 1
## 0.0837 0.08387 0.08447 0.08664 0.08707 0.08826 0.08829 0.08873 0.09065 0.09068
## 1 1 1 1 1 1 1 1 1 1
## 0.09103 0.09164 0.09178 0.09252 0.09266 0.09299 0.09378 0.09512 0.09604 0.09744
## 1 1 1 1 1 1 1 1 1 1
## 0.09849 0.1 0.10008 0.10084 0.10153 0.1029 0.10328 0.10469 0.10574 0.10612
## 1 1 1 1 1 1 1 1 1 1
## 0.10659 0.10793 0.10959 0.11027 0.11069 0.11132 0.11329 0.11425 0.11432 0.1146
## 1 1 1 1 1 1 1 1 1 1
## 0.11504 0.11747 0.12083 0.12204 0.12269 0.12329 0.12579 0.1265 0.12744 0.12757
## 1 1 1 1 1 1 1 1 1 1
## 0.12802 0.12816 0.12932 0.13058 0.13117 0.13158 0.13262 0.13554 0.13587 0.13642
## 1 1 1 1 1 1 1 1 1 1
## 0.13914 0.1396 0.1403 0.14052 0.14103 0.1415 0.14231 0.14455 0.14476 0.14866
## 1 1 1 1 1 1 1 1 1 1
## 0.14932 0.15038 0.15086 0.15098 0.15445 0.15876 0.15936 0.16211 0.16439 0.1676
## 1 1 1 1 1 1 1 1 1 1
## 0.16902 0.17004 0.1712 0.17134 0.17142 0.17171 0.17331 0.17446 0.17505 0.17783
## 1 1 1 1 1 1 1 1 1 1
## 0.17899 0.18159 0.18337 0.18836 0.19073 0.19133 0.19186 0.19539 0.19657 0.19802
## 1 1 1 1 1 1 1 1 1 1
## 0.20608 0.20746 0.21038 0.21124 0.21161 0.21409 0.21719 0.21977 0.22188 0.22212
## 1 1 1 1 1 1 1 1 1 1
## 0.22438 0.22489 0.22876 0.22927 0.22969 0.23912 0.24103 0.24522 0.2498 0.25199
## 1 1 1 1 1 1 1 1 1 1
## 0.25356 0.25387 0.25915 0.26169 0.26363 0.26838 0.26938 0.27957 0.28392 0.28955
## 1 1 1 1 1 1 1 1 1 1
## 0.2896 0.2909 0.29819 0.29916 0.30347 0.31533 0.31827 0.32264 0.32543 0.32982
## 1 1 1 1 1 1 1 1 1 1
## 0.33045 0.33147 0.33983 0.34006 0.34109 0.3494 0.35114 0.35233 0.35809 0.36894
## 1 1 1 1 1 1 1 1 1 1
## 0.3692 0.37578 0.38214 0.38735 0.40202 0.40771 0.41238 0.43571 0.44178 0.44791
## 1 1 1 1 1 1 1 1 1 1
## 0.46296 0.47547 0.49298 0.51183 0.52014 0.52058 0.52693 0.53412 0.537 0.54011
## 1 1 1 1 1 1 1 1 1 1
## 0.5405 0.54452 0.55007 0.55778 0.57529 0.57834 0.59005 0.61154 0.6147 0.62356
## 1 1 1 1 1 1 1 1 1 1
## 0.62739 0.62976 0.63796 0.65665 0.66351 0.67191 0.7258 0.75026 0.76162 0.77299
## 1 1 1 1 1 1 1 1 1 1
## 0.7842 0.7857 0.79041 0.80271 0.82526 0.84054 0.85204 0.88125 0.95577 0.97617
## 1 1 1 1 1 1 1 1 1 1
## 0.98843 1.00245 1.05393 1.12658 1.13081 1.15172 1.19294 1.20742 1.22358 1.23247
## 1 1 1 1 1 1 1 1 1 1
## 1.25179 1.27346 1.34284 1.35472 1.38799 1.41385 1.42502 1.46336 1.49632 1.51902
## 1 1 1 1 1 1 1 1 1 1
## 1.61282 1.62864 1.6566 1.80028 1.83377 2.01019 2.14918 2.15505 2.24236 2.3004
## 1 1 1 1 1 1 1 1 1 1
## 2.3139 2.33099 2.36862 2.37857 2.37934 2.44668 2.44953 2.63548 2.73397 2.77974
## 1 1 1 1 1 1 1 1 1 1
## 2.81838 2.924 3.1636 3.32105 3.47428 3.53501 3.56868 3.67367 3.67822 3.69311
## 1 1 1 1 1 1 1 1 1 1
## 3.69695 3.77498 3.83684 3.8497 4.03841 4.0974 4.22239 4.26131 4.34879 4.42228
## 1 1 1 1 1 1 1 1 1 1
## 4.54192 4.55587 4.64689 4.66883 4.75237 4.81213 4.83567 4.87141 4.89822 5.09017
## 1 1 1 1 1 1 1 1 1 1
## 5.20177 5.29305 5.44114 5.58107 5.66637 5.66998 5.69175 5.70818 5.73116 5.82115
## 1 1 1 1 1 1 1 1 1 1
## 5.82401 5.87205 6.28807 6.39312 6.44405 6.53876 6.65492 6.71772 6.80117 6.96215
## 1 1 1 1 1 1 1 1 1 1
## 7.02259 7.05042 7.36711 7.40389 7.52601 7.67202 7.75223 7.83932 7.99248 8.05579
## 1 1 1 1 1 1 1 1 1 1
## 8.15174 8.20058 8.24809 8.26725 8.49213 8.64476 8.71675 8.79212 8.98296 9.18702
## 1 1 1 1 1 1 1 1 1 1
## 9.2323 9.32909 9.33889 9.39063 9.51363 9.59571 9.72418 9.82349 9.91655 9.92485
## 1 1 1 1 1 1 1 1 1 1
## 9.96654 10.0623 10.233 10.6718 10.8342 11.0874 11.1081 11.1604 11.5779 11.8123
## 1 1 1 1 1 1 1 1 1 1
## 11.9511 12.0482 12.2472 12.8023 13.0751 13.3598 13.5222 13.6781 13.9134 14.0507
## 1 1 1 1 1 1 1 1 1 1
## 14.2362 14.3337 14.4208 14.4383 15.0234 15.1772 15.288 15.5757 15.8603 15.8744
## 1 2 1 1 1 1 1 1 1 1
## 16.8118 17.8667 18.0846 18.4982 18.811 19.6091 20.0849 20.7162 22.0511 22.5971
## 1 1 1 1 1 1 1 1 1 1
## 23.6482 24.3938 24.8017 25.0461 25.9406 28.6558 37.6619 38.3518 41.5292 45.7461
## 1 1 1 1 1 1 1 1 1 1
## 51.1358 67.9208 73.5341 88.9762
## 1 1 1 1往下滑一次,作者小編相信讀者諸君一定想問說
這是什麼啊?跟一個一個看,有什麼不一樣!
確實,作者小編給你拍拍手。既然「table」無法幫我們,我們也「無力定義好的切點(帶出數字區間)」,那就只好找Google Search幫忙了。作者小編在搜尋框輸入
how to have frequency table of a continuous variable in r
因為我們在「連續型變數」遇上困境!
…
11.3.3 全掌握連續型變數的次數分配表
拜Google Search之賜,我們找到以下這一頁
knitr::include_url("https://cran.r-project.org/web/packages/descriptr/vignettes/continuous-data.html")標題就寫著「Continuous Data (連續型數據),就是「連續型變數的數據」。雖然一下子無法細看,但是作者小編相信我們要的答案就在這裡的哪裏?作者小編「control + F」叫出「搜尋框」,打入
frequency
找到有一段的標題是「Frequency Distribution」,往下看到一段參考碼
ds_freq_table(mtcarz, mpg, 4)那這一支程式是誰的?哪一個套件的?就是下一個問題。觀察剛剛抓到的「URL」
https://cran.r-project.org/web/packages/descriptr/vignettes/continuous-data.html
「packages」這個字後面的字「descriptr」就是答案,所以作者小編試著這麼寫
library(descriptr)
ds_freq_table(boston, crim, 4) # 嘗試用了作者小編的汽車知識!## Variable: crim
## |-------------------------------------------------------------------------------|
## | Bins | Frequency | Cum Frequency | Percent | Cum Percent |
## |-------------------------------------------------------------------------------|
## | 0 - 22.2 | 491 | 491 | 97.04 | 97.04 |
## |-------------------------------------------------------------------------------|
## | 22.2 - 44.5 | 10 | 501 | 1.98 | 99.01 |
## |-------------------------------------------------------------------------------|
## | 44.5 - 66.7 | 2 | 503 | 0.4 | 99.41 |
## |-------------------------------------------------------------------------------|
## | 66.7 - 89 | 3 | 506 | 0.59 | 100 |
## |-------------------------------------------------------------------------------|
## | Total | 506 | - | 100.00 | - |
## |-------------------------------------------------------------------------------|把「4」改成「8」如何?
ds_freq_table(boston, crim, 8) # 嘗試用了作者小編的汽車知識!## Variable: crim
## |---------------------------------------------------------------------------------|
## | Bins | Frequency | Cum Frequency | Percent | Cum Percent |
## |---------------------------------------------------------------------------------|
## | 0 - 11.1 | 458 | 458 | 90.51 | 90.51 |
## |---------------------------------------------------------------------------------|
## | 11.1 - 22.2 | 33 | 491 | 6.52 | 97.04 |
## |---------------------------------------------------------------------------------|
## | 22.2 - 33.4 | 7 | 498 | 1.38 | 98.42 |
## |---------------------------------------------------------------------------------|
## | 33.4 - 44.5 | 3 | 501 | 0.59 | 99.01 |
## |---------------------------------------------------------------------------------|
## | 44.5 - 55.6 | 2 | 503 | 0.4 | 99.41 |
## |---------------------------------------------------------------------------------|
## | 55.6 - 66.7 | 0 | 503 | 0 | 99.41 |
## |---------------------------------------------------------------------------------|
## | 66.7 - 77.9 | 2 | 505 | 0.4 | 99.8 |
## |---------------------------------------------------------------------------------|
## | 77.9 - 89 | 1 | 506 | 0.2 | 100 |
## |---------------------------------------------------------------------------------|
## | Total | 506 | - | 100.00 | - |
## |---------------------------------------------------------------------------------|這麼輕鬆,要「4」個區間,就寫「4」;要「8」區間就寫「8」。仔細、認真看報表才是挑戰。
- 「Bins」紀錄著「區間」、
- 「Frequency」紀錄著落入區間的個數、
- 「Cum Frequency」紀錄著到本區間為止的累計個數、
- 「Percent」紀錄著落入區間的相對次數百分比、
- 「Cum Percent」紀錄著到本區間為止的累計相對次數百分比、
作者小編看過一輪後,得到
小結論:「
crim」(per capita crime rate by town)的數據嚴重擠在第一個區間裡。這是一種嚴重集中在「左尾」的分配。
接下來,作者小編「一句一句寫」、「明著寫(這是明碼的意思)」,寫了「11」句,因為連續型變數有「12」個,雖然我們在前一章已經看過了「房價中位數」的次數分配表了。請讀者諸君先一個一個慢慢往下看,
裡面有很多故事喔!
ds_freq_table(boston, zn, 8)## Variable: zn
## |-----------------------------------------------------------------------|
## | Bins | Frequency | Cum Frequency | Percent | Cum Percent |
## |-----------------------------------------------------------------------|
## | 0 - 12.5 | 382 | 382 | 75.49 | 75.49 |
## |-----------------------------------------------------------------------|
## | 12.5 - 25 | 57 | 439 | 11.26 | 86.76 |
## |-----------------------------------------------------------------------|
## | 25 - 37.5 | 29 | 468 | 5.73 | 92.49 |
## |-----------------------------------------------------------------------|
## | 37.5 - 50 | 13 | 481 | 2.57 | 95.06 |
## |-----------------------------------------------------------------------|
## | 50 - 62.5 | 10 | 491 | 1.98 | 97.04 |
## |-----------------------------------------------------------------------|
## | 62.5 - 75 | 6 | 497 | 1.19 | 98.22 |
## |-----------------------------------------------------------------------|
## | 75 - 87.5 | 22 | 519 | 4.35 | 102.57 |
## |-----------------------------------------------------------------------|
## | 87.5 - 100 | 10 | 529 | 1.98 | 104.55 |
## |-----------------------------------------------------------------------|
## | Total | 506 | - | 100.00 | - |
## |-----------------------------------------------------------------------|ds_freq_table(boston, indus, 8)## Variable: indus
## |-------------------------------------------------------------------------|
## | Bins | Frequency | Cum Frequency | Percent | Cum Percent |
## |-------------------------------------------------------------------------|
## | 0.5 - 3.9 | 80 | 80 | 15.81 | 15.81 |
## |-------------------------------------------------------------------------|
## | 3.9 - 7.3 | 122 | 202 | 24.11 | 39.92 |
## |-------------------------------------------------------------------------|
## | 7.3 - 10.7 | 88 | 290 | 17.39 | 57.31 |
## |-------------------------------------------------------------------------|
## | 10.7 - 14.1 | 24 | 314 | 4.74 | 62.06 |
## |-------------------------------------------------------------------------|
## | 14.1 - 17.5 | 3 | 317 | 0.59 | 62.65 |
## |-------------------------------------------------------------------------|
## | 17.5 - 20.9 | 162 | 479 | 32.02 | 94.66 |
## |-------------------------------------------------------------------------|
## | 20.9 - 24.3 | 15 | 494 | 2.96 | 97.63 |
## |-------------------------------------------------------------------------|
## | 24.3 - 27.7 | 12 | 506 | 2.37 | 100 |
## |-------------------------------------------------------------------------|
## | Total | 506 | - | 100.00 | - |
## |-------------------------------------------------------------------------|ds_freq_table(boston, nox, 8)## Variable: nox
## |-----------------------------------------------------------------------------|
## | Bins | Frequency | Cum Frequency | Percent | Cum Percent |
## |-----------------------------------------------------------------------------|
## | 0.4 - 0.4 | 111 | 111 | 21.94 | 21.94 |
## |-----------------------------------------------------------------------------|
## | 0.4 - 0.5 | 89 | 200 | 17.59 | 39.53 |
## |-----------------------------------------------------------------------------|
## | 0.5 - 0.6 | 97 | 297 | 19.17 | 58.7 |
## |-----------------------------------------------------------------------------|
## | 0.6 - 0.6 | 85 | 382 | 16.8 | 75.49 |
## |-----------------------------------------------------------------------------|
## | 0.6 - 0.7 | 38 | 420 | 7.51 | 83 |
## |-----------------------------------------------------------------------------|
## | 0.7 - 0.7 | 62 | 482 | 12.25 | 95.26 |
## |-----------------------------------------------------------------------------|
## | 0.7 - 0.8 | 8 | 490 | 1.58 | 96.84 |
## |-----------------------------------------------------------------------------|
## | 0.8 - 0.9 | 16 | 506 | 3.16 | 100 |
## |-----------------------------------------------------------------------------|
## | Total | 506 | - | 100.00 | - |
## |-----------------------------------------------------------------------------|ds_freq_table(boston, rm, 8)## Variable: rm
## |-------------------------------------------------------------------------------|
## | Bins | Frequency | Cum Frequency | Percent | Cum Percent |
## |-------------------------------------------------------------------------------|
## | 3.6 - 4.2 | 4 | 4 | 0.79 | 0.79 |
## |-------------------------------------------------------------------------------|
## | 4.2 - 4.9 | 4 | 8 | 0.79 | 1.58 |
## |-------------------------------------------------------------------------------|
## | 4.9 - 5.5 | 34 | 42 | 6.72 | 8.3 |
## |-------------------------------------------------------------------------------|
## | 5.5 - 6.2 | 200 | 242 | 39.53 | 47.83 |
## |-------------------------------------------------------------------------------|
## | 6.2 - 6.8 | 174 | 416 | 34.39 | 82.21 |
## |-------------------------------------------------------------------------------|
## | 6.8 - 7.5 | 62 | 478 | 12.25 | 94.47 |
## |-------------------------------------------------------------------------------|
## | 7.5 - 8.1 | 18 | 496 | 3.56 | 98.02 |
## |-------------------------------------------------------------------------------|
## | 8.1 - 8.8 | 10 | 506 | 1.98 | 100 |
## |-------------------------------------------------------------------------------|
## | Total | 506 | - | 100.00 | - |
## |-------------------------------------------------------------------------------|ds_freq_table(boston, age, 8)## Variable: age
## |-----------------------------------------------------------------------------|
## | Bins | Frequency | Cum Frequency | Percent | Cum Percent |
## |-----------------------------------------------------------------------------|
## | 2.9 - 15 | 17 | 17 | 3.36 | 3.36 |
## |-----------------------------------------------------------------------------|
## | 15 - 27.2 | 34 | 51 | 6.72 | 10.08 |
## |-----------------------------------------------------------------------------|
## | 27.2 - 39.3 | 57 | 108 | 11.26 | 21.34 |
## |-----------------------------------------------------------------------------|
## | 39.3 - 51.5 | 40 | 148 | 7.91 | 29.25 |
## |-----------------------------------------------------------------------------|
## | 51.5 - 63.6 | 48 | 196 | 9.49 | 38.74 |
## |-----------------------------------------------------------------------------|
## | 63.6 - 75.7 | 48 | 244 | 9.49 | 48.22 |
## |-----------------------------------------------------------------------------|
## | 75.7 - 87.9 | 69 | 313 | 13.64 | 61.86 |
## |-----------------------------------------------------------------------------|
## | 87.9 - 100 | 193 | 506 | 38.14 | 100 |
## |-----------------------------------------------------------------------------|
## | Total | 506 | - | 100.00 | - |
## |-----------------------------------------------------------------------------|ds_freq_table(boston, dis, 8)## Variable: dis
## |-----------------------------------------------------------------------------------|
## | Bins | Frequency | Cum Frequency | Percent | Cum Percent |
## |-----------------------------------------------------------------------------------|
## | 1.1 - 2.5 | 188 | 188 | 37.15 | 37.15 |
## |-----------------------------------------------------------------------------------|
## | 2.5 - 3.9 | 117 | 305 | 23.12 | 60.28 |
## |-----------------------------------------------------------------------------------|
## | 3.9 - 5.3 | 79 | 384 | 15.61 | 75.89 |
## |-----------------------------------------------------------------------------------|
## | 5.3 - 6.6 | 65 | 449 | 12.85 | 88.74 |
## |-----------------------------------------------------------------------------------|
## | 6.6 - 8 | 35 | 484 | 6.92 | 95.65 |
## |-----------------------------------------------------------------------------------|
## | 8 - 9.4 | 17 | 501 | 3.36 | 99.01 |
## |-----------------------------------------------------------------------------------|
## | 9.4 - 10.8 | 4 | 505 | 0.79 | 99.8 |
## |-----------------------------------------------------------------------------------|
## | 10.8 - 12.1 | 1 | 506 | 0.2 | 100 |
## |-----------------------------------------------------------------------------------|
## | Total | 506 | - | 100.00 | - |
## |-----------------------------------------------------------------------------------|ds_freq_table(boston, tax, 8)## Variable: tax
## |-------------------------------------------------------------------------|
## | Bins | Frequency | Cum Frequency | Percent | Cum Percent |
## |-------------------------------------------------------------------------|
## | 187 - 252.5 | 71 | 71 | 14.03 | 14.03 |
## |-------------------------------------------------------------------------|
## | 252.5 - 318 | 169 | 240 | 33.4 | 47.43 |
## |-------------------------------------------------------------------------|
## | 318 - 383.5 | 35 | 275 | 6.92 | 54.35 |
## |-------------------------------------------------------------------------|
## | 383.5 - 449 | 93 | 368 | 18.38 | 72.73 |
## |-------------------------------------------------------------------------|
## | 449 - 514.5 | 1 | 369 | 0.2 | 72.92 |
## |-------------------------------------------------------------------------|
## | 514.5 - 580 | 0 | 369 | 0 | 72.92 |
## |-------------------------------------------------------------------------|
## | 580 - 645.5 | 0 | 369 | 0 | 72.92 |
## |-------------------------------------------------------------------------|
## | 645.5 - 711 | 137 | 506 | 27.08 | 100 |
## |-------------------------------------------------------------------------|
## | Total | 506 | - | 100.00 | - |
## |-------------------------------------------------------------------------|ds_freq_table(boston, ptratio, 8)## Variable: ptratio
## |---------------------------------------------------------------------------|
## | Bins | Frequency | Cum Frequency | Percent | Cum Percent |
## |---------------------------------------------------------------------------|
## | 12.6 - 13.8 | 16 | 16 | 3.16 | 3.16 |
## |---------------------------------------------------------------------------|
## | 13.8 - 15 | 42 | 58 | 8.3 | 11.46 |
## |---------------------------------------------------------------------------|
## | 15 - 16.1 | 32 | 90 | 6.32 | 17.79 |
## |---------------------------------------------------------------------------|
## | 16.1 - 17.3 | 36 | 126 | 7.11 | 24.9 |
## |---------------------------------------------------------------------------|
## | 17.3 - 18.5 | 89 | 215 | 17.59 | 42.49 |
## |---------------------------------------------------------------------------|
## | 18.5 - 19.7 | 83 | 298 | 16.4 | 58.89 |
## |---------------------------------------------------------------------------|
## | 19.7 - 20.8 | 153 | 451 | 30.24 | 89.13 |
## |---------------------------------------------------------------------------|
## | 20.8 - 22 | 56 | 507 | 11.07 | 100.2 |
## |---------------------------------------------------------------------------|
## | Total | 506 | - | 100.00 | - |
## |---------------------------------------------------------------------------|ds_freq_table(boston, black, 8)## Variable: black
## |-------------------------------------------------------------------------------|
## | Bins | Frequency | Cum Frequency | Percent | Cum Percent |
## |-------------------------------------------------------------------------------|
## | 0.3 - 49.9 | 20 | 20 | 3.95 | 3.95 |
## |-------------------------------------------------------------------------------|
## | 49.9 - 99.5 | 11 | 31 | 2.17 | 6.13 |
## |-------------------------------------------------------------------------------|
## | 99.5 - 149 | 5 | 36 | 0.99 | 7.11 |
## |-------------------------------------------------------------------------------|
## | 149 - 198.6 | 3 | 39 | 0.59 | 7.71 |
## |-------------------------------------------------------------------------------|
## | 198.6 - 248.2 | 5 | 44 | 0.99 | 8.7 |
## |-------------------------------------------------------------------------------|
## | 248.2 - 297.8 | 10 | 54 | 1.98 | 10.67 |
## |-------------------------------------------------------------------------------|
## | 297.8 - 347.3 | 24 | 78 | 4.74 | 15.42 |
## |-------------------------------------------------------------------------------|
## | 347.3 - 396.9 | 428 | 506 | 84.58 | 100 |
## |-------------------------------------------------------------------------------|
## | Total | 506 | - | 100.00 | - |
## |-------------------------------------------------------------------------------|ds_freq_table(boston, lstat, 8)## Variable: lstat
## |-------------------------------------------------------------------------|
## | Bins | Frequency | Cum Frequency | Percent | Cum Percent |
## |-------------------------------------------------------------------------|
## | 1.7 - 6.3 | 100 | 100 | 19.76 | 19.76 |
## |-------------------------------------------------------------------------|
## | 6.3 - 10.8 | 143 | 243 | 28.26 | 48.02 |
## |-------------------------------------------------------------------------|
## | 10.8 - 15.3 | 108 | 351 | 21.34 | 69.37 |
## |-------------------------------------------------------------------------|
## | 15.3 - 19.9 | 79 | 430 | 15.61 | 84.98 |
## |-------------------------------------------------------------------------|
## | 19.9 - 24.4 | 39 | 469 | 7.71 | 92.69 |
## |-------------------------------------------------------------------------|
## | 24.4 - 28.9 | 18 | 487 | 3.56 | 96.25 |
## |-------------------------------------------------------------------------|
## | 28.9 - 33.4 | 13 | 500 | 2.57 | 98.81 |
## |-------------------------------------------------------------------------|
## | 33.4 - 38 | 6 | 506 | 1.19 | 100 |
## |-------------------------------------------------------------------------|
## | Total | 506 | - | 100.00 | - |
## |-------------------------------------------------------------------------|ds_freq_table(boston, medv, 8)## Variable: medv
## |---------------------------------------------------------------------------|
## | Bins | Frequency | Cum Frequency | Percent | Cum Percent |
## |---------------------------------------------------------------------------|
## | 5 - 10.6 | 31 | 31 | 6.13 | 6.13 |
## |---------------------------------------------------------------------------|
## | 10.6 - 16.2 | 85 | 116 | 16.8 | 22.92 |
## |---------------------------------------------------------------------------|
## | 16.2 - 21.9 | 158 | 274 | 31.23 | 54.15 |
## |---------------------------------------------------------------------------|
## | 21.9 - 27.5 | 126 | 400 | 24.9 | 79.05 |
## |---------------------------------------------------------------------------|
## | 27.5 - 33.1 | 51 | 451 | 10.08 | 89.13 |
## |---------------------------------------------------------------------------|
## | 33.1 - 38.8 | 27 | 478 | 5.34 | 94.47 |
## |---------------------------------------------------------------------------|
## | 38.8 - 44.4 | 9 | 487 | 1.78 | 96.25 |
## |---------------------------------------------------------------------------|
## | 44.4 - 50 | 23 | 510 | 4.55 | 100.79 |
## |---------------------------------------------------------------------------|
## | Total | 506 | - | 100.00 | - |
## |---------------------------------------------------------------------------|接下來,作者小編「想要」試著用「cut」變出「ds_freq_table」的「bins」:
medvFT <- ds_freq_table(boston, medv, 8)
names(medvFT)## [1] "freq_data" "breaks" "frequency" "cumulative" "percent"
## [6] "cum_percent" "bins" "data" "na_count" "n"
## [11] "varname"medvFT$breaks## [1] 5.000 10.625 16.250 21.875 27.500 33.125 38.750 44.375 50.000table(cut(boston[, "medv"], breaks = medvFT$breaks)) # 比比看!##
## (5,10.6] (10.6,16.2] (16.2,21.9] (21.9,27.5] (27.5,33.1] (33.1,38.8]
## 29 85 158 126 47 27
## (38.8,44.4] (44.4,50]
## 9 23sum(table(cut(boston[, "medv"], breaks = medvFT$breaks)))## [1] 504作者小編寫到這裡,發現了幾個問題:
- 「
ds_freq_table」會出現重複計算。這現象可以從最後一列的「Total」跟「Cum Frequency」最後一個數字是否相同得到驗證。 - 「
ds_freq_table」的區間「breaks」跟「cut」的區間「breaks」切法不同。
所以,作者小編這樣改:
table(cut(boston[, "medv"], breaks = c(4.9, medvFT$breaks[-1]))) # 比比看!##
## (4.9,10.6] (10.6,16.2] (16.2,21.9] (21.9,27.5] (27.5,33.1] (33.1,38.8]
## 31 85 158 126 47 27
## (38.8,44.4] (44.4,50]
## 9 23sum(table(cut(boston[, "medv"], breaks = c(4.9, medvFT$breaks[-1]))))## [1] 506就會得到正確的「table + cut」。
…
11.4 探索式分析MASS::Boston
因為
- 波士頓數據集有「超過500筆觀察值」,
- 「莖葉圖的解析度」不好「呈現」波士頓數據集每一個變數的分配,
- 雖然可以輕鬆引用「
ds_freq_table」取得「次數分配表」,但是卻有「不易觀察」的缺點。
綜合上述諸多理由,作者小編決定請「skimr::skim」來幫忙!
11.4.1 請skimr出原版波士頓數據集的摘要統計量報表
require(skimr)
skim(boston)| Name | boston |
| Number of rows | 506 |
| Number of columns | 14 |
| _______________________ | |
| Column type frequency: | |
| numeric | 14 |
| ________________________ | |
| Group variables | None |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| crim | 0 | 1 | 3.61 | 8.60 | 0.01 | 0.08 | 0.26 | 3.68 | 88.98 | ▇▁▁▁▁ |
| zn | 0 | 1 | 11.36 | 23.32 | 0.00 | 0.00 | 0.00 | 12.50 | 100.00 | ▇▁▁▁▁ |
| indus | 0 | 1 | 11.14 | 6.86 | 0.46 | 5.19 | 9.69 | 18.10 | 27.74 | ▇▆▁▇▁ |
| chas | 0 | 1 | 0.07 | 0.25 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | ▇▁▁▁▁ |
| nox | 0 | 1 | 0.55 | 0.12 | 0.38 | 0.45 | 0.54 | 0.62 | 0.87 | ▇▇▆▅▁ |
| rm | 0 | 1 | 6.28 | 0.70 | 3.56 | 5.89 | 6.21 | 6.62 | 8.78 | ▁▂▇▂▁ |
| age | 0 | 1 | 68.57 | 28.15 | 2.90 | 45.02 | 77.50 | 94.07 | 100.00 | ▂▂▂▃▇ |
| dis | 0 | 1 | 3.80 | 2.11 | 1.13 | 2.10 | 3.21 | 5.19 | 12.13 | ▇▅▂▁▁ |
| rad | 0 | 1 | 9.55 | 8.71 | 1.00 | 4.00 | 5.00 | 24.00 | 24.00 | ▇▂▁▁▃ |
| tax | 0 | 1 | 408.24 | 168.54 | 187.00 | 279.00 | 330.00 | 666.00 | 711.00 | ▇▇▃▁▇ |
| ptratio | 0 | 1 | 18.46 | 2.16 | 12.60 | 17.40 | 19.05 | 20.20 | 22.00 | ▁▃▅▅▇ |
| black | 0 | 1 | 356.67 | 91.29 | 0.32 | 375.38 | 391.44 | 396.22 | 396.90 | ▁▁▁▁▇ |
| lstat | 0 | 1 | 12.65 | 7.14 | 1.73 | 6.95 | 11.36 | 16.96 | 37.97 | ▇▇▅▂▁ |
| medv | 0 | 1 | 22.53 | 9.20 | 5.00 | 17.02 | 21.20 | 25.00 | 50.00 | ▂▇▅▁▁ |
請注意,上述報表的最右方的「hist」紀錄著每一個變數的「直方圖」。「直方圖」源自「莖葉圖」,成功消弭了「莖葉圖的區間限制」,試圖把
- 「莖葉圖的形狀」跟
- 「『
breaks』的彈性」(請讀者諸君注意,任意「breaks」並不適合整數型、離散型變數!)
找回來。
…
11.4.2 連續型變數的直方圖大放送
「skimr::skim」提供的「直方圖」,因為場地限制,解析度有限,作者小編認為純粹是「輔助」功能。我們需要專門畫「直方圖」的程式碼。
- 讓「
hist」自己決定怎麼「breaks」:
hist(boston[, "medv"])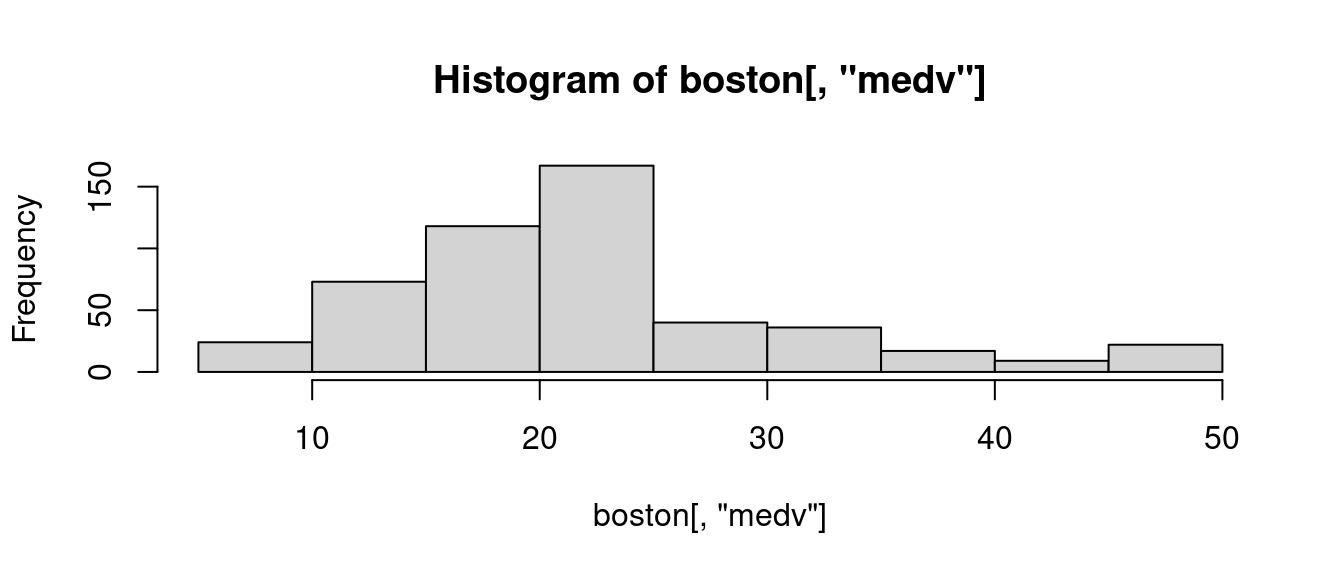
也可以模仿「莖葉圖」這樣畫:
- 引用「單莖莖葉圖」的「
breaks」:
hist(boston[, "medv"], breaks = seq(4.9, 50.9, 1.0))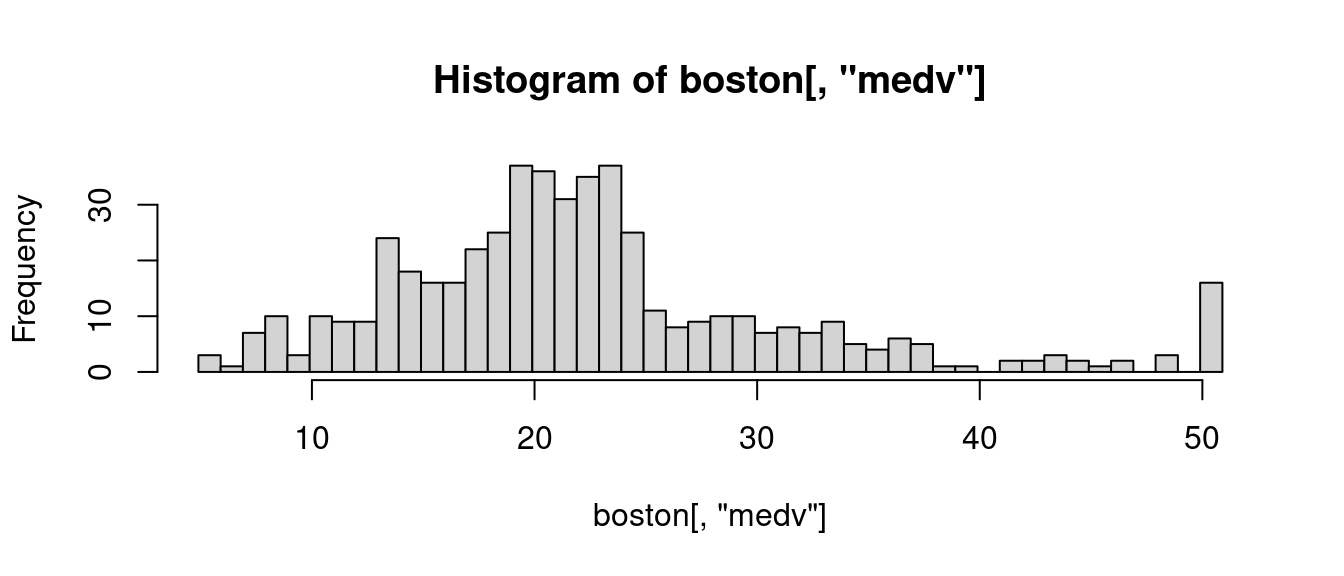
- 引用「單莖莖葉圖」的「
breaks」,而且畫的是「相對次數分配表(density)」:
hist(boston[, "medv"], breaks = seq(4.9, 50.9, 1.0), freq = FALSE)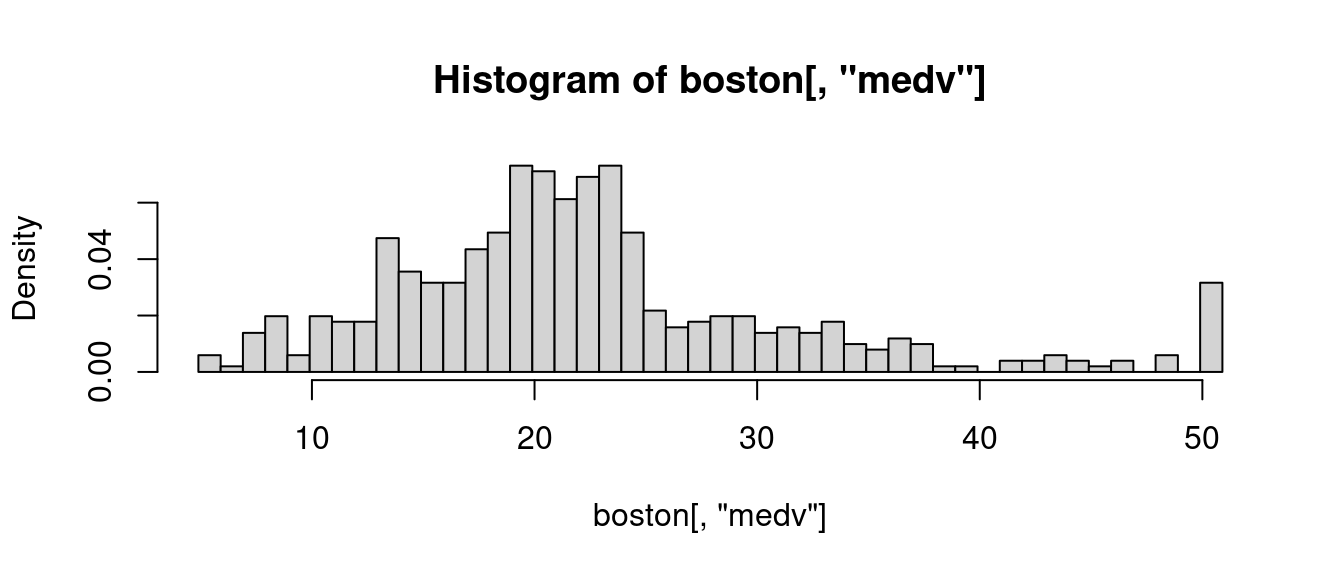
寫到這裡,作者小編「不禁」想要問
怎麼一次畫滿12張直方圖?
par(mfrow = c(6,2)) # 把畫布切成「6 x 2」。
for (variable in CONvars) {
hist(boston[, variable], main=paste0("「",variable,"」","的直方圖"))
} 
經過幾番測試,作者小編發現自己無法請「sapply」畫出一樣的效果,所以就請出作者小編大學時代學過的
for loop
來幫忙。關於「for loop」其他細節,請讀者諸君再多多參考以下官方使用手冊,至於其他細節與應用,我們「隨用(傳)隨到」。
knitr::include_url("https://www.rdocumentation.org/packages/base/versions/3.6.2/topics/Control")…
11.4.3 請skimr出波士頓數據集修正版的摘要統計量報表
我們第一次請「skimr::skim」幫忙時,並沒有區分「離散型變數」跟「連續型變數」,尤其是再一次理解兩個「整數變數」的意義。
- 先看「
chas」。它的意義是「是否鄰近Charles River。」,所以「整數『0』等同於『不是河岸宅』,整數『1』等同於『河岸宅』」,也就是說,這些看似整數的「數字」、的「符號」,其實「不是整數」、「不是數字」。所以,畫它們的直方圖,算它們的平均數是「絕對的錯誤」。它們實際上是「文字」,作者小編用「名目文字」稱呼這一類的變數。「名目文字」是一種「factor」。
### chas (= 1 if tract bounds river; 0 otherwise)
boston[,"chas"] <- factor(boston[,"chas"])
head(boston[, "chas"])## [1] 0 0 0 0 0 0
## Levels: 0 1- 再看「
rad」。先看「rad」的意義
colsBostonFull[9,2]## [1] "環狀高速公路的可觸指標。"「rad」是一種「accessibility」,想要表達「『遙不可及』還是「垂手可得」」的程度。再看
sort(unique(boston[, "rad"]))## [1] 1 2 3 4 5 6 7 8 24讀者諸君會發現,「8」之後,直接跳「24」。所以,跟「chas」一樣,外表看似「整數」,但已經不是「整數」了,「只是借用」。所以,因為「強度是一種強弱順序概念」,為了保留這一項順序,作者小編用「順序文字」稱呼這一類的變數。「順序文字」是一種「ordered factor」。
### rad (index of accessibility to radial highways)
boston[,"rad"] <- factor(boston[,"rad"], ordered = TRUE)
head(boston[, "rad"])## [1] 1 2 2 3 3 3
## Levels: 1 < 2 < 3 < 4 < 5 < 6 < 7 < 8 < 24改完之後,我們再一次請「skimr::skim」幫忙,就會看到正確的報表了。
skim(boston)| Name | boston |
| Number of rows | 506 |
| Number of columns | 14 |
| _______________________ | |
| Column type frequency: | |
| factor | 2 |
| numeric | 12 |
| ________________________ | |
| Group variables | None |
Variable type: factor
| skim_variable | n_missing | complete_rate | ordered | n_unique | top_counts |
|---|---|---|---|---|---|
| chas | 0 | 1 | FALSE | 2 | 0: 471, 1: 35 |
| rad | 0 | 1 | TRUE | 9 | 24: 132, 5: 115, 4: 110, 3: 38 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| crim | 0 | 1 | 3.61 | 8.60 | 0.01 | 0.08 | 0.26 | 3.68 | 88.98 | ▇▁▁▁▁ |
| zn | 0 | 1 | 11.36 | 23.32 | 0.00 | 0.00 | 0.00 | 12.50 | 100.00 | ▇▁▁▁▁ |
| indus | 0 | 1 | 11.14 | 6.86 | 0.46 | 5.19 | 9.69 | 18.10 | 27.74 | ▇▆▁▇▁ |
| nox | 0 | 1 | 0.55 | 0.12 | 0.38 | 0.45 | 0.54 | 0.62 | 0.87 | ▇▇▆▅▁ |
| rm | 0 | 1 | 6.28 | 0.70 | 3.56 | 5.89 | 6.21 | 6.62 | 8.78 | ▁▂▇▂▁ |
| age | 0 | 1 | 68.57 | 28.15 | 2.90 | 45.02 | 77.50 | 94.07 | 100.00 | ▂▂▂▃▇ |
| dis | 0 | 1 | 3.80 | 2.11 | 1.13 | 2.10 | 3.21 | 5.19 | 12.13 | ▇▅▂▁▁ |
| tax | 0 | 1 | 408.24 | 168.54 | 187.00 | 279.00 | 330.00 | 666.00 | 711.00 | ▇▇▃▁▇ |
| ptratio | 0 | 1 | 18.46 | 2.16 | 12.60 | 17.40 | 19.05 | 20.20 | 22.00 | ▁▃▅▅▇ |
| black | 0 | 1 | 356.67 | 91.29 | 0.32 | 375.38 | 391.44 | 396.22 | 396.90 | ▁▁▁▁▇ |
| lstat | 0 | 1 | 12.65 | 7.14 | 1.73 | 6.95 | 11.36 | 16.96 | 37.97 | ▇▇▅▂▁ |
| medv | 0 | 1 | 22.53 | 9.20 | 5.00 | 17.02 | 21.20 | 25.00 | 50.00 | ▂▇▅▁▁ |
請讀者諸君慢慢欣賞!
…
11.4.4 製作分群、分段的摘要統計量報表
我們已經知道「chas」的意義是
colsBostonFull[4,2]## [1] "是否鄰近Charles River。"也就是說,「chas」意指「是不是河岸宅」,所以「整數『0』等同於『不是河岸宅』,整數『1』等同於『河岸宅』」。那
「『河岸宅』的房價中位數」跟「『非河岸宅』的房價中位數」有差嗎?差在哪呢?
- 為了「分群、分段」檢視波士頓數據集的「摘要統計量」,作者小編請來套件「
dplyr」,然後這麼寫:
require(dplyr)
boston %>%
dplyr::group_by(chas) %>%
skim()| Name | Piped data |
| Number of rows | 506 |
| Number of columns | 14 |
| _______________________ | |
| Column type frequency: | |
| factor | 1 |
| numeric | 12 |
| ________________________ | |
| Group variables | chas |
Variable type: factor
| skim_variable | chas | n_missing | complete_rate | ordered | n_unique | top_counts |
|---|---|---|---|---|---|---|
| rad | 0 | 0 | 1 | TRUE | 9 | 24: 124, 5: 104, 4: 102, 3: 36 |
| rad | 1 | 0 | 1 | TRUE | 6 | 5: 11, 4: 8, 24: 8, 8: 5 |
Variable type: numeric
| skim_variable | chas | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|---|
| crim | 0 | 0 | 1 | 3.74 | 8.88 | 0.01 | 0.08 | 0.25 | 3.70 | 88.98 | ▇▁▁▁▁ |
| crim | 1 | 0 | 1 | 1.85 | 2.49 | 0.02 | 0.13 | 0.45 | 3.40 | 8.98 | ▇▁▁▁▁ |
| zn | 0 | 0 | 1 | 11.63 | 23.62 | 0.00 | 0.00 | 0.00 | 12.50 | 100.00 | ▇▁▁▁▁ |
| zn | 1 | 0 | 1 | 7.71 | 18.80 | 0.00 | 0.00 | 0.00 | 0.00 | 90.00 | ▇▁▁▁▁ |
| indus | 0 | 0 | 1 | 11.02 | 6.91 | 0.46 | 5.04 | 8.56 | 18.10 | 27.74 | ▇▆▁▇▁ |
| indus | 1 | 0 | 1 | 12.72 | 5.96 | 1.21 | 6.41 | 13.89 | 18.10 | 19.58 | ▁▅▂▂▇ |
| nox | 0 | 0 | 1 | 0.55 | 0.11 | 0.38 | 0.45 | 0.54 | 0.62 | 0.87 | ▇▇▆▃▁ |
| nox | 1 | 0 | 1 | 0.59 | 0.14 | 0.40 | 0.49 | 0.55 | 0.69 | 0.87 | ▇▅▃▃▂ |
| rm | 0 | 0 | 1 | 6.27 | 0.69 | 3.56 | 5.88 | 6.20 | 6.59 | 8.72 | ▁▁▇▂▁ |
| rm | 1 | 0 | 1 | 6.52 | 0.88 | 5.01 | 5.94 | 6.25 | 6.91 | 8.78 | ▂▇▅▂▁ |
| age | 0 | 0 | 1 | 67.91 | 28.46 | 2.90 | 42.50 | 76.50 | 94.10 | 100.00 | ▂▂▂▃▇ |
| age | 1 | 0 | 1 | 77.50 | 22.02 | 24.80 | 60.30 | 88.50 | 93.20 | 100.00 | ▁▂▂▂▇ |
| dis | 0 | 0 | 1 | 3.85 | 2.15 | 1.14 | 2.11 | 3.22 | 5.29 | 12.13 | ▇▅▂▁▁ |
| dis | 1 | 0 | 1 | 3.03 | 1.25 | 1.13 | 1.90 | 3.05 | 3.90 | 5.88 | ▇▅▇▅▂ |
| tax | 0 | 0 | 1 | 409.87 | 168.85 | 187.00 | 282.50 | 330.00 | 666.00 | 711.00 | ▇▇▃▁▇ |
| tax | 1 | 0 | 1 | 386.26 | 165.01 | 198.00 | 276.00 | 307.00 | 403.00 | 666.00 | ▇▂▃▁▅ |
| ptratio | 0 | 0 | 1 | 18.53 | 2.16 | 12.60 | 17.40 | 19.10 | 20.20 | 22.00 | ▁▃▃▅▇ |
| ptratio | 1 | 0 | 1 | 17.49 | 2.08 | 13.60 | 15.65 | 17.60 | 18.60 | 20.20 | ▇▁▆▇▆ |
| black | 0 | 0 | 1 | 355.46 | 93.42 | 0.32 | 375.36 | 391.83 | 396.38 | 396.90 | ▁▁▁▁▇ |
| black | 1 | 0 | 1 | 373.00 | 53.38 | 88.01 | 376.20 | 390.77 | 393.60 | 396.90 | ▁▁▁▁▇ |
| lstat | 0 | 0 | 1 | 12.76 | 7.17 | 1.73 | 7.16 | 11.38 | 17.09 | 37.97 | ▇▇▅▂▁ |
| lstat | 1 | 0 | 1 | 11.24 | 6.69 | 1.92 | 5.39 | 10.50 | 15.07 | 26.82 | ▇▅▆▂▂ |
| medv | 0 | 0 | 1 | 22.09 | 8.83 | 5.00 | 16.60 | 20.90 | 24.80 | 50.00 | ▃▇▅▁▁ |
| medv | 1 | 0 | 1 | 28.44 | 11.82 | 13.40 | 21.10 | 23.30 | 33.15 | 50.00 | ▅▇▃▁▃ |
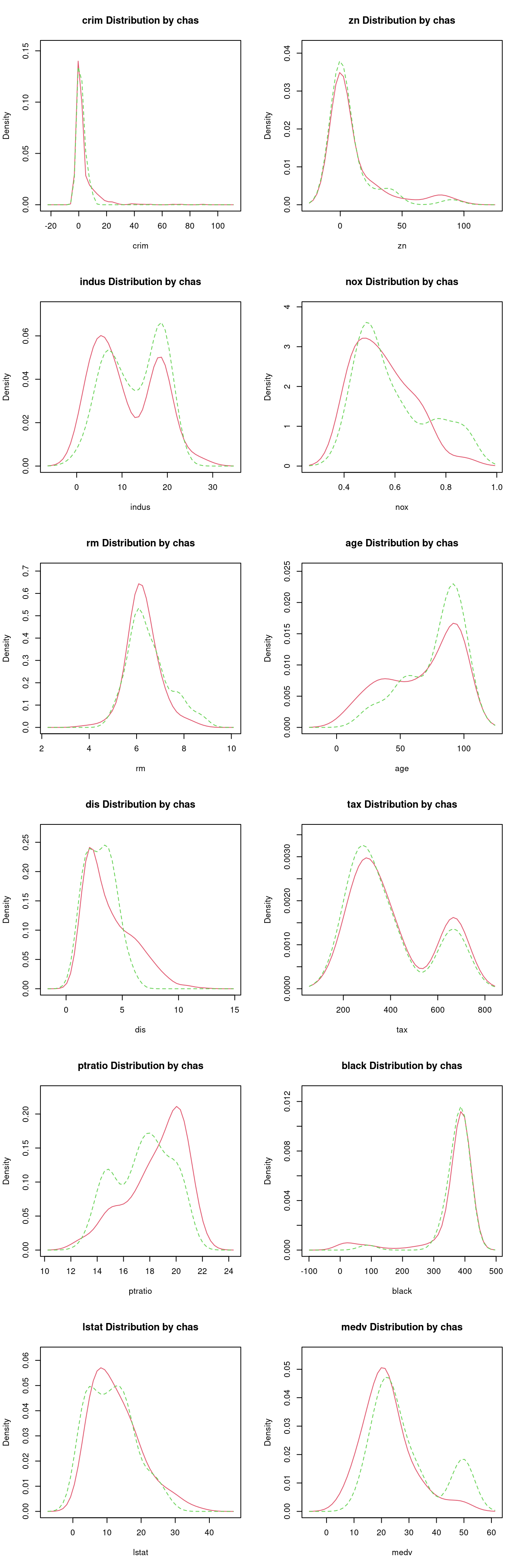
- 為了透過「圖」檢視「分配」之間的差異,作者小編找來套件「
sm」,加上「for迴圈」建議這麼做:
require(sm)
par(mfrow = c(6,2)) # 把畫布切成「6 x 2」。
for (variable in CONvars) {
sm.density.compare(boston[, variable],
boston[, "chas"],
xlab = variable)
title(main = paste0(variable, " Distribution by chas"))
} 
11.5 再一次深入解析波士頓數據集的基本資料
為了研究波士頓數據集的機器學習建模,作者小編寫了以下這一大段。如果讀者諸君對「機器學習」沒興趣,請直接跳過。繼續前進下一章。
11.5.1 準備波士頓數據集跟背景說明
require(MASS)
data(Boston)
boston <- Boston請讀者諸君「看看、觀察」前三筆、後三筆的原始數據長相:
head(boston, 3)## crim zn indus chas nox rm age dis rad tax ptratio black lstat
## 1 0.00632 18 2.31 0 0.538 6.575 65.2 4.0900 1 296 15.3 396.90 4.98
## 2 0.02731 0 7.07 0 0.469 6.421 78.9 4.9671 2 242 17.8 396.90 9.14
## 3 0.02729 0 7.07 0 0.469 7.185 61.1 4.9671 2 242 17.8 392.83 4.03
## medv
## 1 24.0
## 2 21.6
## 3 34.7tail(boston, 3)## crim zn indus chas nox rm age dis rad tax ptratio black lstat
## 504 0.06076 0 11.93 0 0.573 6.976 91.0 2.1675 1 273 21 396.90 5.64
## 505 0.10959 0 11.93 0 0.573 6.794 89.3 2.3889 1 273 21 393.45 6.48
## 506 0.04741 0 11.93 0 0.573 6.030 80.8 2.5050 1 273 21 396.90 7.88
## medv
## 504 23.9
## 505 22.0
## 506 11.9再來,作者小編複製第二章最後一節「自己下載的背景說明」的示範程式碼,然後打開新的「R Script」,貼給它,程式碼最後再加了一句話
saveRDS(colsBostonFull,"/home/fcu/ShinyApps/Textbooks/BOSTON/chapter02/output/data/colsBostonFull.rds")
- 檔案夾「output」
- 的子檔案夾「data」
- 的RDS檔案「colsBostonFull.rds」
讓往後每一章都可以直接抓來用:
colsBostonFull<-readRDS("/home/fcu/ShinyApps/Textbooks/BOSTON/chapter02/output/data/colsBostonFull.rds")## Warning in gzfile(file, "rb"): 無法開啟壓縮過的檔案
## '/home/fcu/ShinyApps/Textbooks/BOSTON/chapter02/output/data/colsBostonFull.rds',可能的原因是
## '沒有此一檔案或目錄'## Error in gzfile(file, "rb"): 無法開啟連接請看波士頓數據集的背景說明:
colsBostonFull## 說明
## CRIM per capita crime rate by town
## ZN proportion of residential land zoned for lots over 25,000 sq.ft.
## INDUS proportion of non-retail business acres per town
## CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)
## NOX nitric oxides concentration (parts per 10 million)
## RM average number of rooms per dwelling
## AGE proportion of owner-occupied units built prior to 1940
## DIS weighted distances to five Boston employment centres
## RAD index of accessibility to radial highways
## TAX full-value property-tax rate per $10,000
## PTRATIO pupil-teacher ratio by town
## BLACK 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town
## LSTAT % lower status of the population
## MEDV Median value of owner-occupied homes in $1000's
## 中文翻譯 中文變數名稱
## CRIM 每個城鎮人均犯罪率。 犯罪率
## ZN 超過25,000平方呎的住宅用地比例。 住宅用地比例
## INDUS 每個城鎮非零售業務英畝的比例。 非商業區比例
## CHAS 是否鄰近Charles River。 河邊宅
## NOX 氮氧化合物濃度。 空汙指標
## RM 每個住宅的平均房間數。 平均房間數
## AGE 1940年之前建造的自用住宅比例。 老房子比例
## DIS 距波士頓五大商圈的加權平均距離。 加權平均距離
## RAD 環狀高速公路的可觸指標。 交通便利性
## TAX 財產稅占比(每一萬美元)。 財產稅率
## PTRATIO 生師比。 生師比
## BLACK 黑人的比例。 黑人指數
## LSTAT (比較)低社經地位人口的比例。 低社經人口比例
## MEDV 以千美元計的房價中位數。 房價中位數再加上每個變數的內容物:
colsBostonFull$內容物 <- sapply(boston, class)
colsBostonFull## 說明
## CRIM per capita crime rate by town
## ZN proportion of residential land zoned for lots over 25,000 sq.ft.
## INDUS proportion of non-retail business acres per town
## CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)
## NOX nitric oxides concentration (parts per 10 million)
## RM average number of rooms per dwelling
## AGE proportion of owner-occupied units built prior to 1940
## DIS weighted distances to five Boston employment centres
## RAD index of accessibility to radial highways
## TAX full-value property-tax rate per $10,000
## PTRATIO pupil-teacher ratio by town
## BLACK 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town
## LSTAT % lower status of the population
## MEDV Median value of owner-occupied homes in $1000's
## 中文翻譯 中文變數名稱 內容物
## CRIM 每個城鎮人均犯罪率。 犯罪率 numeric
## ZN 超過25,000平方呎的住宅用地比例。 住宅用地比例 numeric
## INDUS 每個城鎮非零售業務英畝的比例。 非商業區比例 numeric
## CHAS 是否鄰近Charles River。 河邊宅 integer
## NOX 氮氧化合物濃度。 空汙指標 numeric
## RM 每個住宅的平均房間數。 平均房間數 numeric
## AGE 1940年之前建造的自用住宅比例。 老房子比例 numeric
## DIS 距波士頓五大商圈的加權平均距離。 加權平均距離 numeric
## RAD 環狀高速公路的可觸指標。 交通便利性 integer
## TAX 財產稅占比(每一萬美元)。 財產稅率 numeric
## PTRATIO 生師比。 生師比 numeric
## BLACK 黑人的比例。 黑人指數 numeric
## LSTAT (比較)低社經地位人口的比例。 低社經人口比例 numeric
## MEDV 以千美元計的房價中位數。 房價中位數 numeric11.5.2 一次看夠波士頓數據集的資料結構
我們已經初步知道每一個欄位不是「整數(integer)」就是「實數(numeric)」,也用了「head」跟「tail」看到部分數據集。R也提供一支程式「str」,讓我們一次知道每一個欄位是哪一種「內容物」跟「部分數據」。還可以知道「樣本數」,也就是「波士頓數據集這一張表的高度」跟「變數個數」,也就是「波士頓數據集這一張表的寬度」:
str(boston)## 'data.frame': 506 obs. of 14 variables:
## $ crim : num 0.00632 0.02731 0.02729 0.03237 0.06905 ...
## $ zn : num 18 0 0 0 0 0 12.5 12.5 12.5 12.5 ...
## $ indus : num 2.31 7.07 7.07 2.18 2.18 2.18 7.87 7.87 7.87 7.87 ...
## $ chas : int 0 0 0 0 0 0 0 0 0 0 ...
## $ nox : num 0.538 0.469 0.469 0.458 0.458 0.458 0.524 0.524 0.524 0.524 ...
## $ rm : num 6.58 6.42 7.18 7 7.15 ...
## $ age : num 65.2 78.9 61.1 45.8 54.2 58.7 66.6 96.1 100 85.9 ...
## $ dis : num 4.09 4.97 4.97 6.06 6.06 ...
## $ rad : int 1 2 2 3 3 3 5 5 5 5 ...
## $ tax : num 296 242 242 222 222 222 311 311 311 311 ...
## $ ptratio: num 15.3 17.8 17.8 18.7 18.7 18.7 15.2 15.2 15.2 15.2 ...
## $ black : num 397 397 393 395 397 ...
## $ lstat : num 4.98 9.14 4.03 2.94 5.33 ...
## $ medv : num 24 21.6 34.7 33.4 36.2 28.7 22.9 27.1 16.5 18.9 ...11.5.3 手動一次一個認識波士頓數據集的變數
雖然「str」可以給我們一些關於波士頓數據集的印象,但是
絕對不夠!
因為根據作者小編的「實務經驗」,真實數據集可能「暗藏錯誤的數據」,所以接下來,作者小編做了幾個假設、猜測:
- 懷疑「
MASS::Boston」可能暗藏「前後不一致的數據」? - 是不是需要修正「某些變數內容物的屬性」?
為此,接下來,是作者小編的手工藝,意味著「拿起紙筆看著螢幕做筆記再喚出程式碼」,在R與作者小編個人對「數字」的「素養」,經過一番奮鬥之後,作者小編撰寫了幾隻程式:
- 檢查阿拉伯數字的一致性?
- 檢查整數的一致性?
- 檢查小數位數的一致性?
- 檢查是不是介於
(0,1)之間?
經過一整個下午的奮鬥,作者小編決定用「function」的方式呈現成果。請看
- 檢查小數位數的一致性?
digitConsis <- function(col = 1, digits = 1){
### 先單純試寫!
N <- digits + 1
x <- sapply(boston[, col], function(w){
strsplit(format(w, nsmall = N), "[.]")[[1]][2]
})
x <- unname(sapply(x, function(w){
strsplit(w, "")[[1]][N]
}))
return(sum(x != "0"))
}- 檢查是不是介於
(0,1)之間?
zeroOne <- function(col = 1, digits = 1){
### 先單純試寫!
N <- digits + 1
x <- sapply(boston[, col], function(w){
strsplit(format(w, nsmall = N), "[.]")[[1]][1]
})
return(sum(x != "0"))
}- 檢查整數的一致性?
ALLinteger <- function(col = 9){
x <- sapply(boston[, col], is.integer)
return(sum(!x))
}- 檢查阿拉伯數字的一致性?
smallDummy <- function(col = 1, digits = 0){
### 先單純試寫!
N <- digits + 1
x <- sapply(boston[, col], function(w){
strsplit(format(w, nsmall = N), "")[[1]][2]
})
return(sum(!is.na(x)))
}11.5.3.1 確認每一個變數的數字種類
看過
boston[63:68,]## crim zn indus chas nox rm age dis rad tax ptratio black
## 63 0.11027 25.0 5.13 0 0.4530 6.456 67.8 7.2255 8 284 19.7 396.90
## 64 0.12650 25.0 5.13 0 0.4530 6.762 43.4 7.9809 8 284 19.7 395.58
## 65 0.01951 17.5 1.38 0 0.4161 7.104 59.5 9.2229 3 216 18.6 393.24
## 66 0.03584 80.0 3.37 0 0.3980 6.290 17.8 6.6115 4 337 16.1 396.90
## 67 0.04379 80.0 3.37 0 0.3980 5.787 31.1 6.6115 4 337 16.1 396.90
## 68 0.05789 12.5 6.07 0 0.4090 5.878 21.4 6.4980 4 345 18.9 396.21
## lstat medv
## 63 6.73 22.2
## 64 9.50 25.0
## 65 8.05 33.0
## 66 4.67 23.5
## 67 10.24 19.4
## 68 8.10 22.0作者小編作了以下關於各個變數內容物的假設:
- (1)「犯罪率(
crim)」是五位小數的實數、 - (2)「住宅用地比例(
zn)」是一位小數的實數、 - (3)「非商業區比例(
indus)」是兩位小數的實數、 - (4)「河岸宅(
chas)」是0或1的整數、 - (5)「空污指標(
nox)」是小於一且帶著四位小數的實數、 - (6)「平均房間數(
rm)」是三位小數的實數、 - (7)「老房子比例(
age)」是一位小數的實數、 - (8)「加權平均距離(
dis)」是四位小數的實數、 - (9)「交通便利性(
rad)」是整數、 - (10)「財產稅率(
tax)」是零位小數的實數、 - (11)「生師比(
ptratio)」是一位小數的實數、 - (12)「黑人指數(
black)」是某一個公式算出來的,是帶著兩位小數的實數、 - (13)「低社經人口比例(
lstat)」是兩位小數的實數、 - (14)「房價中位數(
medv)」是一位小數的實數、
開始檢查,要是看到「0」就過關:
- 「犯罪率(
crim)」是五位小數的實數、
digitConsis(col = 1, digits = 5)## [1] 0- 「住宅用地比例(
zn)」是一位小數的實數、
digitConsis(col = 2, digits = 1)## [1] 0- 「非商業區比例(
indus)」是兩位小數的實數、
digitConsis(col = 3, digits = 2)## [1] 0- 「河岸宅(
chas)」是0或1的整數、
smallDummy(col = 4, digits = 0)## [1] 0- 「空污指標(
nox)」是小於一且帶著四位小數的實數、
zeroOne(col = 5, digits = 4)## [1] 0digitConsis(col = 5, digits = 4)## [1] 0- 「平均房間數(
rm)」是三位小數的實數、
digitConsis(col = 6, digits = 3)## [1] 0- 「老房子比例(
age)」是一位小數的實數、
digitConsis(col = 7, digits = 1)## [1] 0- 「加權平均距離(
dis)」是四位小數的實數、
digitConsis(col = 8, digits = 4)## [1] 0- 「交通便利性(
rad)」是整數、
ALLinteger(col = 9)## [1] 0- 「財產稅率(
tax)」是零位小數的實數、
digitConsis(col = 10, digits = 0)## [1] 0- 「生師比(
ptratio)」是一位小數的實數、
digitConsis(col = 11, digits = 1)## [1] 0- 「黑人指數(
black)」是某一個公式算出來的,是帶著兩位小數的實數、
digitConsis(col = 12, digits = 2)## [1] 0- 「低社經人口比例(
lstat)」是兩位小數的實數、
digitConsis(col = 13, digits = 2)## [1] 0- 「房價中位數(
medv)」是一位小數的實數、
digitConsis(col = 14, digits = 1)## [1] 011.5.3.2 請skimr::skim幫忙報告疑似百分比變數的最大值跟最小值
檢查完「實數」跟「整數」的一致性之後,作者小編懷疑「英文版的變數說明」裡涉及「proportion」、「%」、「rate」等三個字眼的這些變數:
PROP <- c(grep("proportion", colsBostonFull$說明)[-4],
grep("%", colsBostonFull$說明),
grep("rate", colsBostonFull$說明)[-2])
colsBostonFull[PROP,]## 說明
## ZN proportion of residential land zoned for lots over 25,000 sq.ft.
## INDUS proportion of non-retail business acres per town
## AGE proportion of owner-occupied units built prior to 1940
## LSTAT % lower status of the population
## CRIM per capita crime rate by town
## 中文翻譯 中文變數名稱 內容物
## ZN 超過25,000平方呎的住宅用地比例。 住宅用地比例 numeric
## INDUS 每個城鎮非零售業務英畝的比例。 非商業區比例 numeric
## AGE 1940年之前建造的自用住宅比例。 老房子比例 numeric
## LSTAT (比較)低社經地位人口的比例。 低社經人口比例 numeric
## CRIM 每個城鎮人均犯罪率。 犯罪率 numeric可能都是「百分比」。也就是說,只要「除以100數據就會回到區間[0,1]之間」。讓我們請「skimr::skim」幫忙,而且只看最大值跟最小值。
require(skimr)
my_skim <- skim_with(
numeric = sfl(最小值 = min,
最大值 = max),
append = FALSE
)
my_skim(boston[, PROP])| Name | boston[, PROP] |
| Number of rows | 506 |
| Number of columns | 5 |
| _______________________ | |
| Column type frequency: | |
| numeric | 5 |
| ________________________ | |
| Group variables | None |
Variable type: numeric
| skim_variable | n_missing | complete_rate | 最小值 | 最大值 |
|---|---|---|---|---|
| zn | 0 | 1 | 0.00 | 100.00 |
| indus | 0 | 1 | 0.46 | 27.74 |
| age | 0 | 1 | 2.90 | 100.00 |
| lstat | 0 | 1 | 1.73 | 37.97 |
| crim | 0 | 1 | 0.01 | 88.98 |
觀察報表之後,再審視「背景說明」,作者小編更有信心這些變數
colsBostonFull[PROP,"變數名"]## NULL都是「百分比變數」。
11.5.3.3 請skimr::skim幫忙報告比值變數的最大值跟最小值
繼續看。
作者小編看到「生師比(ptratio)」,因為個人就在大學教書,這一個數字的本質並不生疏,知道它的分母並不固定,但是只要對「生師比(ptratio)」取倒數「1/ptratio」,就可以得到區間[0,1]之間的「師生比」;再看到「稅率(tax)」,加上發現英文說明裡有一個字「per」,意識到「稅率(tax)」的分母是「10000美元」,也就是說,「稅率(tax)除以10000」就會回到區間[0,1]之間。
PROP <- c(grep("rate", colsBostonFull$說明)[2],
grep("ratio", colsBostonFull$說明)[-1])
my_skim(boston[, PROP])| Name | boston[, PROP] |
| Number of rows | 506 |
| Number of columns | 2 |
| _______________________ | |
| Column type frequency: | |
| numeric | 2 |
| ________________________ | |
| Group variables | None |
Variable type: numeric
| skim_variable | n_missing | complete_rate | 最小值 | 最大值 |
|---|---|---|---|---|
| tax | 0 | 1 | 187.0 | 711 |
| ptratio | 0 | 1 | 12.6 | 22 |
一樣請「skimr::skim」幫忙看最大值跟最小值。
11.5.3.4 分類英文說明
- 根據作者小編的專業(數學、統計、資訊)抓出每一個變數英文說明的某一個關鍵字,然後重排「背景說明表」:
newOrder <- c(grep("average", colsBostonFull$說明),
grep("proportion", colsBostonFull$說明)[-4],
grep("%", colsBostonFull$說明),
grep("rate", colsBostonFull$說明),
grep("ratio", colsBostonFull$說明)[-1],
grep("dummy", colsBostonFull$說明),
grep("distances", colsBostonFull$說明),
grep("index", colsBostonFull$說明),
12, 5, 14)
colsBostonFull[newOrder,]## 說明
## RM average number of rooms per dwelling
## ZN proportion of residential land zoned for lots over 25,000 sq.ft.
## INDUS proportion of non-retail business acres per town
## AGE proportion of owner-occupied units built prior to 1940
## LSTAT % lower status of the population
## CRIM per capita crime rate by town
## TAX full-value property-tax rate per $10,000
## PTRATIO pupil-teacher ratio by town
## CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)
## DIS weighted distances to five Boston employment centres
## RAD index of accessibility to radial highways
## BLACK 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town
## NOX nitric oxides concentration (parts per 10 million)
## MEDV Median value of owner-occupied homes in $1000's
## 中文翻譯 中文變數名稱 內容物
## RM 每個住宅的平均房間數。 平均房間數 numeric
## ZN 超過25,000平方呎的住宅用地比例。 住宅用地比例 numeric
## INDUS 每個城鎮非零售業務英畝的比例。 非商業區比例 numeric
## AGE 1940年之前建造的自用住宅比例。 老房子比例 numeric
## LSTAT (比較)低社經地位人口的比例。 低社經人口比例 numeric
## CRIM 每個城鎮人均犯罪率。 犯罪率 numeric
## TAX 財產稅占比(每一萬美元)。 財產稅率 numeric
## PTRATIO 生師比。 生師比 numeric
## CHAS 是否鄰近Charles River。 河邊宅 integer
## DIS 距波士頓五大商圈的加權平均距離。 加權平均距離 numeric
## RAD 環狀高速公路的可觸指標。 交通便利性 integer
## BLACK 黑人的比例。 黑人指數 numeric
## NOX 氮氧化合物濃度。 空汙指標 numeric
## MEDV 以千美元計的房價中位數。 房價中位數 numeric- 百分比變數
percentOrder <- c(grep("proportion", colsBostonFull$說明)[-4],
grep("%", colsBostonFull$說明),
grep("rate", colsBostonFull$說明)[-2])
colsBostonFull[percentOrder,]## 說明
## ZN proportion of residential land zoned for lots over 25,000 sq.ft.
## INDUS proportion of non-retail business acres per town
## AGE proportion of owner-occupied units built prior to 1940
## LSTAT % lower status of the population
## CRIM per capita crime rate by town
## 中文翻譯 中文變數名稱 內容物
## ZN 超過25,000平方呎的住宅用地比例。 住宅用地比例 numeric
## INDUS 每個城鎮非零售業務英畝的比例。 非商業區比例 numeric
## AGE 1940年之前建造的自用住宅比例。 老房子比例 numeric
## LSTAT (比較)低社經地位人口的比例。 低社經人口比例 numeric
## CRIM 每個城鎮人均犯罪率。 犯罪率 numeric- 比值變數
ratioOrder <- c(grep("rate", colsBostonFull$說明)[2],
grep("ratio", colsBostonFull$說明)[-1])
colsBostonFull[ratioOrder,]## 說明 中文翻譯
## TAX full-value property-tax rate per $10,000 財產稅占比(每一萬美元)。
## PTRATIO pupil-teacher ratio by town 生師比。
## 中文變數名稱 內容物
## TAX 財產稅率 numeric
## PTRATIO 生師比 numeric- 其他實數型變數
numericOrder <- c(grep("average", colsBostonFull$說明),
grep("distances", colsBostonFull$說明),
12, 5, 14)
colsBostonFull[numericOrder,]## 說明
## RM average number of rooms per dwelling
## DIS weighted distances to five Boston employment centres
## BLACK 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town
## NOX nitric oxides concentration (parts per 10 million)
## MEDV Median value of owner-occupied homes in $1000's
## 中文翻譯 中文變數名稱 內容物
## RM 每個住宅的平均房間數。 平均房間數 numeric
## DIS 距波士頓五大商圈的加權平均距離。 加權平均距離 numeric
## BLACK 黑人的比例。 黑人指數 numeric
## NOX 氮氧化合物濃度。 空汙指標 numeric
## MEDV 以千美元計的房價中位數。 房價中位數 numeric- 整數型變數
intOrder <- c(grep("index", colsBostonFull$說明),
grep("dummy", colsBostonFull$說明))
colsBostonFull[intOrder,]## 說明
## RAD index of accessibility to radial highways
## CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)
## 中文翻譯 中文變數名稱 內容物
## RAD 環狀高速公路的可觸指標。 交通便利性 integer
## CHAS 是否鄰近Charles River。 河邊宅 integer11.6 修正版波士頓數據集
require(MASS)
data(Boston)
boston <- Boston
### percentOrder
percentVar <- colsBostonFull$變數名[percentOrder]
percentVar## NULLboston[,percentVar] <- boston[,percentVar]/100.0
head(boston)## crim zn indus chas nox rm age dis rad tax ptratio black lstat
## 1 0.00632 18 2.31 0 0.538 6.575 65.2 4.0900 1 296 15.3 396.90 4.98
## 2 0.02731 0 7.07 0 0.469 6.421 78.9 4.9671 2 242 17.8 396.90 9.14
## 3 0.02729 0 7.07 0 0.469 7.185 61.1 4.9671 2 242 17.8 392.83 4.03
## 4 0.03237 0 2.18 0 0.458 6.998 45.8 6.0622 3 222 18.7 394.63 2.94
## 5 0.06905 0 2.18 0 0.458 7.147 54.2 6.0622 3 222 18.7 396.90 5.33
## 6 0.02985 0 2.18 0 0.458 6.430 58.7 6.0622 3 222 18.7 394.12 5.21
## medv
## 1 24.0
## 2 21.6
## 3 34.7
## 4 33.4
## 5 36.2
## 6 28.7### ratioOrder
ratioVar <- colsBostonFull$變數名[ratioOrder]
ratioVar## NULLboston[,ratioVar[1]] <- boston[,ratioVar[1]]/10000.0
boston[,ratioVar[2]] <- 1.0/boston[,ratioVar[2]]
head(boston)## crim zn indus chas nox rm age dis rad tax ptratio black lstat
## 1 0.00632 18 2.31 0 0.538 6.575 65.2 4.0900 1 296 15.3 396.90 4.98
## 2 0.02731 0 7.07 0 0.469 6.421 78.9 4.9671 2 242 17.8 396.90 9.14
## 3 0.02729 0 7.07 0 0.469 7.185 61.1 4.9671 2 242 17.8 392.83 4.03
## 4 0.03237 0 2.18 0 0.458 6.998 45.8 6.0622 3 222 18.7 394.63 2.94
## 5 0.06905 0 2.18 0 0.458 7.147 54.2 6.0622 3 222 18.7 396.90 5.33
## 6 0.02985 0 2.18 0 0.458 6.430 58.7 6.0622 3 222 18.7 394.12 5.21
## medv
## 1 24.0
## 2 21.6
## 3 34.7
## 4 33.4
## 5 36.2
## 6 28.7### rad (index of accessibility to radial highways)
boston[,"rad"] <- factor(boston[,"rad"], ordered = TRUE)
### chas (= 1 if tract bounds river; 0 otherwise)
boston[,"chas"] <- factor(boston[,"chas"])
head(boston)## crim zn indus chas nox rm age dis rad tax ptratio black lstat
## 1 0.00632 18 2.31 0 0.538 6.575 65.2 4.0900 1 296 15.3 396.90 4.98
## 2 0.02731 0 7.07 0 0.469 6.421 78.9 4.9671 2 242 17.8 396.90 9.14
## 3 0.02729 0 7.07 0 0.469 7.185 61.1 4.9671 2 242 17.8 392.83 4.03
## 4 0.03237 0 2.18 0 0.458 6.998 45.8 6.0622 3 222 18.7 394.63 2.94
## 5 0.06905 0 2.18 0 0.458 7.147 54.2 6.0622 3 222 18.7 396.90 5.33
## 6 0.02985 0 2.18 0 0.458 6.430 58.7 6.0622 3 222 18.7 394.12 5.21
## medv
## 1 24.0
## 2 21.6
## 3 34.7
## 4 33.4
## 5 36.2
## 6 28.7改完之後,作者小編把「新版的波士頓數據集」存起來,讓後續章節可以繼續使用
saveRDS(boston, "/home/fcu/ShinyApps/Textbooks/BOSTON/chapter03/output/data/boston2.rds")11.6.1 DIY修正版波士頓數據集的摘要統計量報表
以下是針對「房價中位數」,作者小編自創的報表。
medv <- boston[, "medv"]
mySummary <- data.frame(最小值 = min(medv),
Q1 = quantile(medv, probs = 0.25),
平均數 = mean(medv),
中位數 = quantile(medv, probs = 0.50),
Q3 = quantile(medv, probs = 0.75),
最大值 = max(medv),
標準差 = sd(medv),
間距 = diff(range(medv)),
偏度 = moments::skewness(medv),
扁度 = moments::kurtosis(medv))
rownames(mySummary) <- "medv"
mySummary## 最小值 Q1 平均數 中位數 Q3 最大值 標準差 間距 偏度 扁度
## medv 5 17.025 22.53281 21.2 25 50 9.197104 45 1.104811 4.468629如何複製給波士頓數據集的其他變數呢?
讓我們「連戲」吧!
for (variable in CONvars[-12]) {
VAR <- boston[, variable]
mySummary1 <- data.frame(最小值 = min(VAR),
Q1 = quantile(VAR, probs = 0.25),
平均數 = mean(VAR),
中位數 = quantile(VAR, probs = 0.50),
Q3 = quantile(VAR, probs = 0.75),
最大值 = max(VAR),
標準差 = sd(VAR),
間距 = diff(range(VAR)),
偏度 = moments::skewness(VAR),
扁度 = moments::kurtosis(VAR))
rownames(mySummary1) <- variable
mySummary <- rbind(mySummary, mySummary1)
}
mySummary## 最小值 Q1 平均數 中位數 Q3 最大值
## medv 5.00000 17.025000 22.5328063 21.20000 25.000000 50.0000
## crim 0.00632 0.082045 3.6135236 0.25651 3.677083 88.9762
## zn 0.00000 0.000000 11.3636364 0.00000 12.500000 100.0000
## indus 0.46000 5.190000 11.1367787 9.69000 18.100000 27.7400
## nox 0.38500 0.449000 0.5546951 0.53800 0.624000 0.8710
## rm 3.56100 5.885500 6.2846344 6.20850 6.623500 8.7800
## age 2.90000 45.025000 68.5749012 77.50000 94.075000 100.0000
## dis 1.12960 2.100175 3.7950427 3.20745 5.188425 12.1265
## tax 187.00000 279.000000 408.2371542 330.00000 666.000000 711.0000
## ptratio 12.60000 17.400000 18.4555336 19.05000 20.200000 22.0000
## black 0.32000 375.377500 356.6740316 391.44000 396.225000 396.9000
## lstat 1.73000 6.950000 12.6530632 11.36000 16.955000 37.9700
## 標準差 間距 偏度 扁度
## medv 9.1971041 45.00000 1.1048108 4.468629
## crim 8.6015451 88.96988 5.2076524 39.752786
## zn 23.3224530 100.00000 2.2190631 6.979949
## indus 6.8603529 27.28000 0.2941463 1.766782
## nox 0.1158777 0.48600 0.7271442 2.924136
## rm 0.7026171 5.21900 0.4024147 4.861027
## age 28.1488614 97.10000 -0.5971856 2.029986
## dis 2.1057101 10.99690 1.0087788 3.471299
## tax 168.5371161 524.00000 0.6679683 1.857015
## ptratio 2.1649455 9.40000 -0.7999445 2.705884
## black 91.2948644 396.58000 -2.8817983 10.143769
## lstat 7.1410615 36.24000 0.9037707 3.476545round(mySummary, 2)## 最小值 Q1 平均數 中位數 Q3 最大值 標準差 間距 偏度 扁度
## medv 5.00 17.02 22.53 21.20 25.00 50.00 9.20 45.00 1.10 4.47
## crim 0.01 0.08 3.61 0.26 3.68 88.98 8.60 88.97 5.21 39.75
## zn 0.00 0.00 11.36 0.00 12.50 100.00 23.32 100.00 2.22 6.98
## indus 0.46 5.19 11.14 9.69 18.10 27.74 6.86 27.28 0.29 1.77
## nox 0.38 0.45 0.55 0.54 0.62 0.87 0.12 0.49 0.73 2.92
## rm 3.56 5.89 6.28 6.21 6.62 8.78 0.70 5.22 0.40 4.86
## age 2.90 45.02 68.57 77.50 94.07 100.00 28.15 97.10 -0.60 2.03
## dis 1.13 2.10 3.80 3.21 5.19 12.13 2.11 11.00 1.01 3.47
## tax 187.00 279.00 408.24 330.00 666.00 711.00 168.54 524.00 0.67 1.86
## ptratio 12.60 17.40 18.46 19.05 20.20 22.00 2.16 9.40 -0.80 2.71
## black 0.32 375.38 356.67 391.44 396.22 396.90 91.29 396.58 -2.88 10.14
## lstat 1.73 6.95 12.65 11.36 16.96 37.97 7.14 36.24 0.90 3.48作者小編只能說:水啦!
11.6.2 請skimr出修正版波士頓數據集的摘要統計量報表
require(skimr)
skim(boston)| Name | boston |
| Number of rows | 506 |
| Number of columns | 14 |
| _______________________ | |
| Column type frequency: | |
| factor | 2 |
| numeric | 12 |
| ________________________ | |
| Group variables | None |
Variable type: factor
| skim_variable | n_missing | complete_rate | ordered | n_unique | top_counts |
|---|---|---|---|---|---|
| chas | 0 | 1 | FALSE | 2 | 0: 471, 1: 35 |
| rad | 0 | 1 | TRUE | 9 | 24: 132, 5: 115, 4: 110, 3: 38 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| crim | 0 | 1 | 3.61 | 8.60 | 0.01 | 0.08 | 0.26 | 3.68 | 88.98 | ▇▁▁▁▁ |
| zn | 0 | 1 | 11.36 | 23.32 | 0.00 | 0.00 | 0.00 | 12.50 | 100.00 | ▇▁▁▁▁ |
| indus | 0 | 1 | 11.14 | 6.86 | 0.46 | 5.19 | 9.69 | 18.10 | 27.74 | ▇▆▁▇▁ |
| nox | 0 | 1 | 0.55 | 0.12 | 0.38 | 0.45 | 0.54 | 0.62 | 0.87 | ▇▇▆▅▁ |
| rm | 0 | 1 | 6.28 | 0.70 | 3.56 | 5.89 | 6.21 | 6.62 | 8.78 | ▁▂▇▂▁ |
| age | 0 | 1 | 68.57 | 28.15 | 2.90 | 45.02 | 77.50 | 94.07 | 100.00 | ▂▂▂▃▇ |
| dis | 0 | 1 | 3.80 | 2.11 | 1.13 | 2.10 | 3.21 | 5.19 | 12.13 | ▇▅▂▁▁ |
| tax | 0 | 1 | 408.24 | 168.54 | 187.00 | 279.00 | 330.00 | 666.00 | 711.00 | ▇▇▃▁▇ |
| ptratio | 0 | 1 | 18.46 | 2.16 | 12.60 | 17.40 | 19.05 | 20.20 | 22.00 | ▁▃▅▅▇ |
| black | 0 | 1 | 356.67 | 91.29 | 0.32 | 375.38 | 391.44 | 396.22 | 396.90 | ▁▁▁▁▇ |
| lstat | 0 | 1 | 12.65 | 7.14 | 1.73 | 6.95 | 11.36 | 16.96 | 37.97 | ▇▇▅▂▁ |
| medv | 0 | 1 | 22.53 | 9.20 | 5.00 | 17.02 | 21.20 | 25.00 | 50.00 | ▂▇▅▁▁ |