Chapter 18 簡介財務管理課堂數據集
18.1 旭一
「財務管理」是一門逢甲大學大商學院的必修課,而且是一門統籌課程,意思是說,雖然許多師長教授不同系、不同班級,但是預定進度是一致的,並且統一命題大考的「期中考」跟「期末考」。
話雖如此,每一位師長還是擁有一項彈性空間,那就是「平時成績」,這樣的設計,讓師長們可以擁有「依循憲法賦予講學自由」的「個人教學作為」。於是乎,作者小編的好朋友紀錄了2014年日間部一班、夜間部一班,每一位修課學生的
- 每堂課出缺席紀錄、
- 九次作業繳交紀錄、
- 四次小考每題得分細節、
- 期中考每題得分細節、
- 期末考每題得分細節、
- 原始學期總成績、
- 學期總成績、
- 三份問卷調查(期初調查、期中調查、期末調查)。
為了與讀者諸君、研究團隊深入探索這「財務管理課堂紀錄」的各種可能性,作者小編先一一介紹上述每一種紀錄。
18.3 旭二
一學期一組、一班一組、一次性的課堂學習數據集,到底可以玩出什麼「玩意」呢?
這是一個好問題,也是一個難題!基本上這一組數據集有:
- 三份問卷調查、
- 每堂課的出缺席、
- 九次作業繳交紀錄、
- 四次小考得分細節與總分、
- 期中考得分細節與總分、
- 期末考得分細節與總分、
- 補考得分細節與總分、
- 原始學期總成績、
- 學期總成績。
當作者小編多年前接到這一組數據集,只有一個印象,
辛苦!
這是一份「天上掉下來」的大禮物!裡面滿滿的紀錄(log),是「最原始」、「最底層」的數據。既然是最底層的一手數據,意味著,「只要我可以」,就可以變出許許多多種、各式各樣尺度的二手、三手數據來!比如說,「出缺席紀錄」登載「每一次上課每節課是否到課」,如果是「1」表示「出席」,如果是「0」表示「缺席」;然後再加上「正課後的實習課是否到課」,一樣如果是「1」表示「出席」,如果是「0」表示「缺席」。根據這樣的定義,
如果有一位同學某個禮拜的紀錄是「1110」,就表示「她/他出席了正課但是缺席了實習課」,因為實習課是第四節,11:10到12:00。
如果紀錄是「0110」,就表示「某一位同學遲到一堂正課而且缺席了實習課」。
諸如此類的「出缺席樣式(pattern)」,讓我們可以研究「出缺席樣式與小考成績的關係」,「出缺席樣式與期中考成績的關係」,「出缺席樣式與期末考成績的關係」,當然也可以研究「出缺席樣式與期末總成績的關係」。「出缺席樣式」除了可以發展出「出席正課實習課缺席」、「遲到一節正課實習課缺席」這一類的標籤:
也可以算出「當週正課出席堂數」與「當週正課出席堂數比例」:
如果連實習課的出缺席紀錄一起算,也可以算出「當週出席堂數」與「當週出席堂數比例」:
以上這一類「新創數字」的可能性,作者小編特別為這一類的「創作活動」取名為「特徵值工程」,並適時加入「標籤工程(類似第一張表的創作活動)」協助發展更多可能的新創數字。在這一套探討「建模技術」的微微書,作者小編將不斷示範「各種校園紀錄的新創數字」,並且融入建模過程,磨練「如何研究新創個人觀點的模型」的學習活動。除了上述令人期待的活動,還有一個更好的消息是:
這一整組「課堂活動紀錄的數據集」,可以讓作者小編近距離研究「短期追蹤研究」。
因為,「每一週都可以持續追蹤出缺席紀錄」、也可以「持續追蹤四次小考紀錄」、如果加上「期中考紀錄」與「期末考紀錄」,也可以「持續追蹤六次考試紀錄」;還有「八次課外作業的紀錄」。比如說,出缺席紀錄衍生的「追蹤紀錄表」可能長成這樣子:
請讀者諸君再一次「回到從前歲月」、「回到學生時代」,細細玩味「當年學生勇」。心裡想著「當年為了分數曾經努力過什麼?」,同時想像「真的有辦法預測學期總成績嗎?」。基於這樣的「大哉問」,
假如作者小編可以玩出這一組數據集的「意義」來,不只可以把這意義回饋給努力收集這一組數據集的師長,還可以嵌入作者小編的線上教室,讓它幫我、幫學生,提升課堂學習的「意義」。
這一組數據集發生在2014年,接近七年前,當時作者小編就跟一位研究生曾經努力過一次,時過境遷,作者小編這一回再一次近身接觸,希望
- 「再現」當年的研究方法
- 「加入」建議解釋變數群的新套件
- 「新增」機器學習的預測研究方法論
並且把這一整套研究方法論溶入「多變量分析」,一門逢甲大學統計學系大三必修課,以及「機器學習」,一門逢甲大學統計學系大四選修課。期待在這一套微微書為讀者諸君呈現「前所未有」的新樣貌與新方向。
祝成功!
18.4 建模思維之搜尋解釋(預測)變數
遊戲開始了!作者小編開始幻想了!
假如抓「學期總成績」當作是「迴歸建模的反應變數,y」,但是「『完全不知道』的解釋變數,x」在哪裏?
- 如果這個解釋變數「完全沒變化」,那「散佈圖」一定是
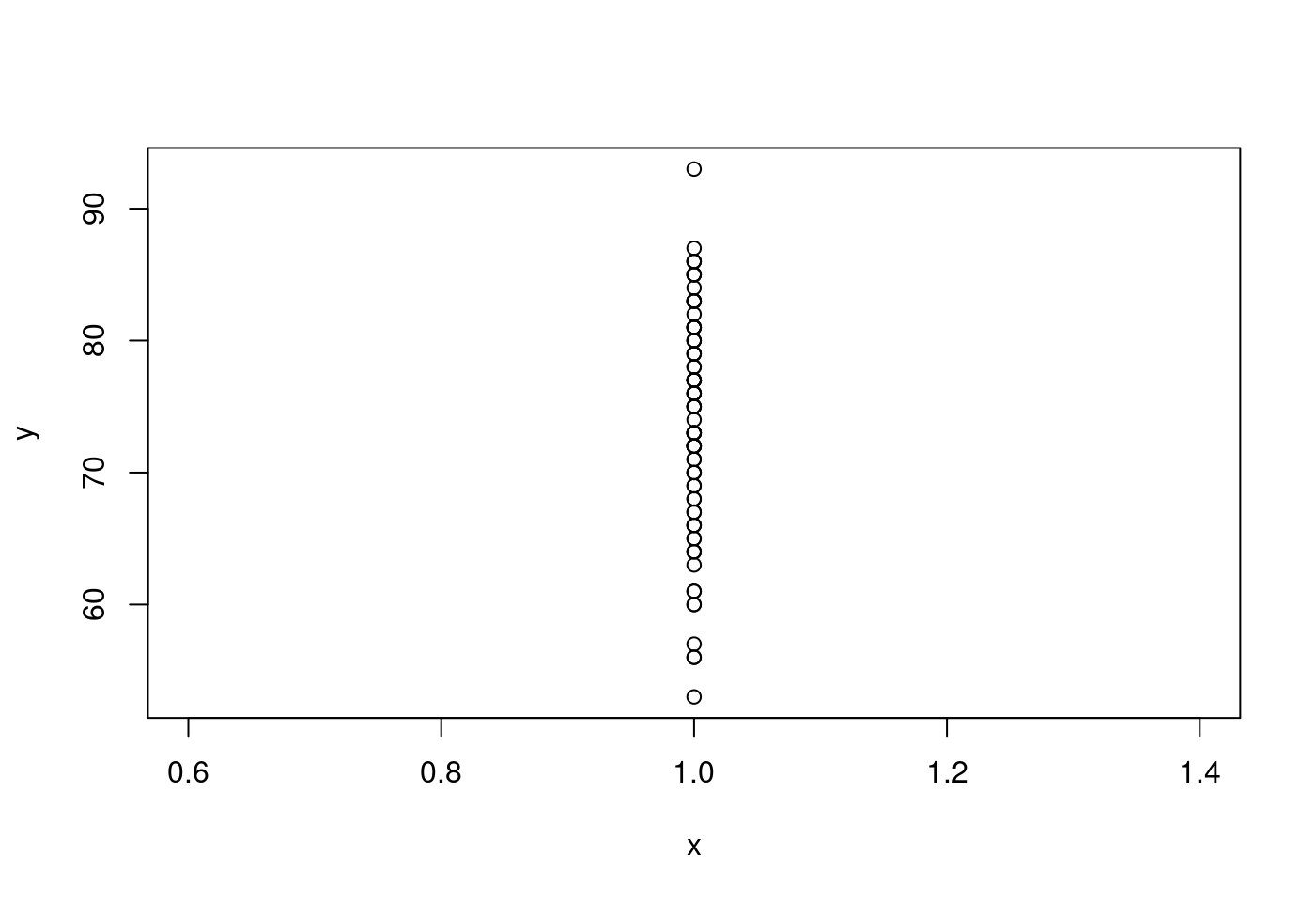
- 如果這個解釋變數「只有兩個值」,那「散佈圖」可能是
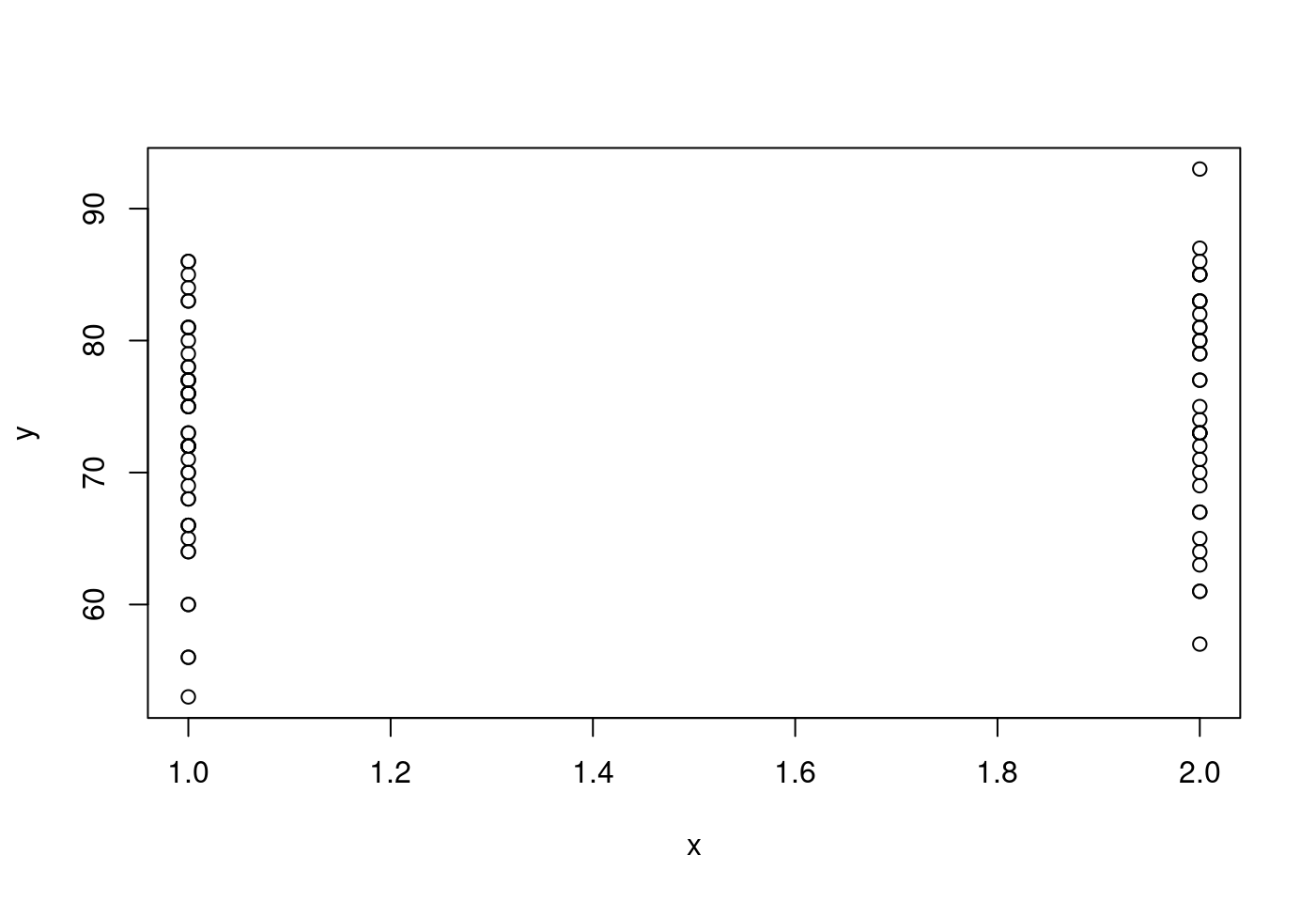
- 如果…
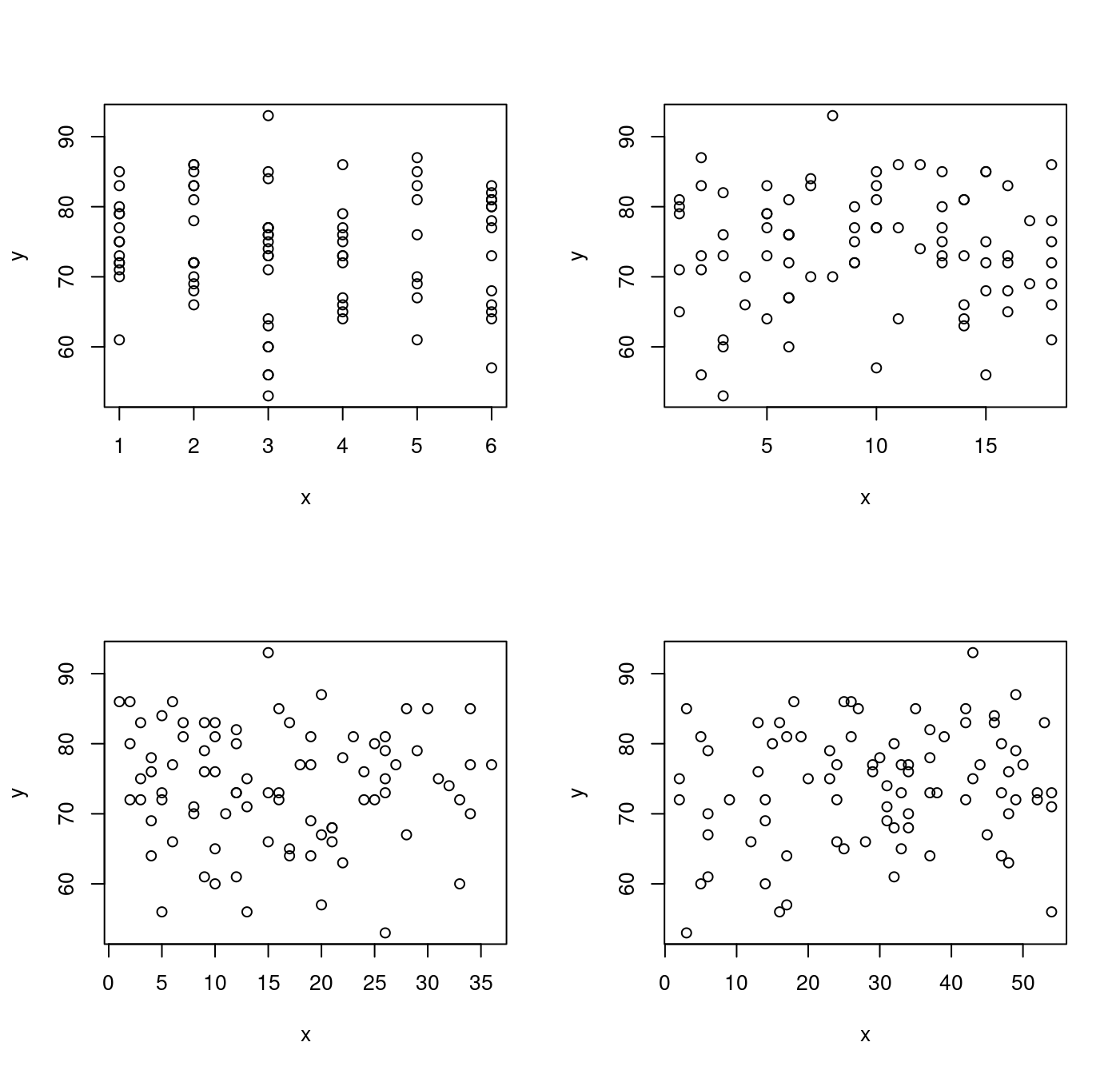
形狀就逐漸成形!
這似乎告訴作者小編某個「搜尋解釋變數的方向」!除了
- 變化夠大(full of randomness),也要
- 與「反應變數」有著「夠高的」相關係數。
以上這兩項條件,將指導作者小編「製造」、「搜尋」關於每一位修課學生的特徵值!
祝成功!
18.5 每堂課出缺席紀錄
先看看某一週的出缺席原始紀錄:
這是「出缺席紀錄表」的欄位名稱:
colnames(week1)## [1] "ID" "v100101" "v100102" "v100103" "v1001"這張「表」,叫做「week1」,其中的「1」代表「第一週」。
- 第一個欄位名稱「
ID」紀錄著學生的學號。讀者諸君一定看不出來「a3fbba76252a7822a6f79a8e6b5ddcfd」是學號,作者小編也看不出來,因為學號被作者小編加密了。如果不加密,作者小編一定不敢在這裡跟讀者諸君大談特談! - 第二個欄位名稱「
v100101」是「2014-10-01第一週上課第一堂課的出缺席紀錄」,其中「1」表示「出席」,「0」表示「缺席」; - 接下來,第三個欄位名稱是「
v100102」,該欄位紀錄著「2014-10-01第一週上課第二堂課的出缺席紀錄」; - 第四個欄位名稱是「
v100103」,該欄位就紀錄著「2014-10-01第一週上課第三堂課的出缺席紀錄」; - 最後一個欄位名稱,「
v1001」,則代表「2014-10-01第一週實習課的出缺席紀錄」。
作者小編的好朋友一開始把「各個紀錄表」用知名商用軟體SPSS的格式「.sav」一一存放在硬碟裡,為了可以讓更多人引用、研究這一些寶貴的紀錄,作者小編寫了一支程式,把全部「.sav」檔案轉成「.xlsx」檔案。請讀者諸君參考以下的做法
library(misty)
library(writexl)
SPSSfiles2csv <- list.files("data/第四版_SPSS版本")
for (i in 1:length(SPSSfiles2csv)) {
SPSSfile <- paste0("data/第四版_SPSS版本/", SPSSfiles2csv[i])
x <- read.sav(SPSSfile)
SPSSfile <- sub("sav", "xlsx", SPSSfiles2csv[i])
if(grepl("business", SPSSfile)){
SPSSfile <- paste0("data/business/", SPSSfile)
write_xlsx(x, SPSSfile)
} else {
SPSSfile <- paste0("data/insurance/", SPSSfile)
write_xlsx(x, SPSSfile)
}
}另外,為了把「.xlsx」檔案讀入R的環境裡,請參考以下的程式碼,比如說,讀取「2014-10-01第一週上課的出缺席紀錄檔」的寫法如下:
### 出缺席紀錄
library(readxl) # 有請套件「readxl」幫忙!
week1 <- read_excel("data/insurance_2014-10-01.xlsx")18.6 九次作業繳交紀錄
「課外作業」是非常基礎,也是非常傳統,卻是非常有效的學習活動。
基本上,在傳統教室跟著師長學習,大半時候(應該經常會超過95%),都是師長的聲音,除非是口頭報告時間,要不然學生是不被允許在課堂上高談闊論的!基於此,作者小編認為「課外作業」是「學生社交活動的一種媒介」,大家一起寫作業,「可以開書」、「可以開口」、「可以分享」、「可以辯論」、「可以練字」、「可以立論」,絕對是「非常重要的學術活動」。接下來,讓我們看看作者小編的好朋友當時留下了什麼紀錄?
每一次課外作業之後,會留下兩個欄位,
- 第一個是「
ID」,它是學號,雖然讀者諸君現在看到的是「加密過後的學號」,只要上下觀察一輪,就會發現作者小編引用的加密技術並沒有打亂「ID(學號)的一致性」,也就是說,同樣的「一長串符號」代表著「同一位修課學生」。 - 第二個欄位,現在的名稱叫做「
hw_ch1」,其中「hw」代表「homework」這一個英文字的縮寫,而「ch1」則代表「chapter 1」第一章的縮寫。這一個欄位紀錄著「是否繳交作業」,如果是「1」表示「已即時(含補交期限)繳交作業給師長或是助教」,「0」則表示「未即時(含補交期限)繳交作業給師長或是助教」。
作者小編利用以下的程式碼取得上述這一張表:
### 作業繳交紀錄
library(readxl) # 有請套件「readxl」幫忙!
HW1 <- read_excel("data/hw01_insurance_2014-10-01.xlsx")18.7 四次小考每題得分細節
台灣的高等教育是「學期制」,每學期安排「十八週」。為了定期追蹤學生的學習進度與發展,作者小編的這一位好朋友「
1/4學期」安排一次小考。小考採課堂筆試方式進行,滿分100分。
先給讀者諸君看一下「欄位名稱」:
## [1] "ID" "Q1_1" "Q1_8" "Q1_2" "Q1_4" "Q1_6" "Q1_10" "Q1_7" "Q1_5"
## [10] "Q1_9" "Q1_3"各位可以發現,除了固定的「ID」,像第二個欄位名稱叫做「Q1_1」,其中「Q1」代表「第一次小考」,「1」則代表第一題,「1」是題號,這個欄位紀錄著每一位應考學生在第一題的「得分」。讀者諸君可能也已經發現,代表題號的數字並沒有「依序出現(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)」。為此,作者小編特別寫了一段「修正程式碼」:
quiz1 <- quiz1[, colnames(quiz1)[c(1,2,4,11,5,9,6,8,3,10,7)]]
colnames(quiz1)## [1] "ID" "Q1_1" "Q1_2" "Q1_3" "Q1_4" "Q1_5" "Q1_6" "Q1_7" "Q1_8"
## [10] "Q1_9" "Q1_10"至於「第一次小考」的得分細節,需要時我們再來好好觀察!
18.8 期中考每題得分細節
根據「財務管理」2014年的預定進度,在「
2014-11-12」舉辦「期中考」。
跟前一節一樣,作者小編引用同樣的思緒觀察「期中考每題得分細節」這一張表的欄位名稱:
## [1] "ID" "M_Q1" "M_Q2" "M_Q8" "M_Q6" "M_Q3" "M_Q9" "M_Q10" "M_Q4"
## [10] "M_Q7" "M_Q5" "M_Q11" "M_Q14" "M_Q15" "M_Q12" "M_Q19" "M_Q20" "M_Q13"
## [19] "M_Q16" "M_Q21" "M_Q22" "M_Q17" "M_Q18" "M_Q23" "M_Q24" "M_Q25"依舊是「沒有依序出現(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25)」,為此作者小編再一次「出動」,用以下的程式碼修正這一項「小瑕疵」:
- 先檢查名字的長度。
nchar(colnames(mid))## [1] 2 4 4 4 4 4 4 5 4 4 4 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5- 抓長度等於「
4」的名字。
colnames(mid)[which(nchar(colnames(mid)) == 4)]## [1] "M_Q1" "M_Q2" "M_Q8" "M_Q6" "M_Q3" "M_Q9" "M_Q4" "M_Q7" "M_Q5"- 排序這一些名字。
sort(colnames(mid)[which(nchar(colnames(mid)) == 4)])## [1] "M_Q1" "M_Q2" "M_Q3" "M_Q4" "M_Q5" "M_Q6" "M_Q7" "M_Q8" "M_Q9"- 抓長度等於「
5」的名字。
colnames(mid)[which(nchar(colnames(mid)) == 5)]## [1] "M_Q10" "M_Q11" "M_Q14" "M_Q15" "M_Q12" "M_Q19" "M_Q20" "M_Q13" "M_Q16"
## [10] "M_Q21" "M_Q22" "M_Q17" "M_Q18" "M_Q23" "M_Q24" "M_Q25"- 排序這一些名字。
sort(colnames(mid)[which(nchar(colnames(mid)) == 5)])## [1] "M_Q10" "M_Q11" "M_Q12" "M_Q13" "M_Q14" "M_Q15" "M_Q16" "M_Q17" "M_Q18"
## [10] "M_Q19" "M_Q20" "M_Q21" "M_Q22" "M_Q23" "M_Q24" "M_Q25"- 開始換欄位順序。
`短名字` <- sort(colnames(mid)[which(nchar(colnames(mid)) == 4)])
`短名字`## [1] "M_Q1" "M_Q2" "M_Q3" "M_Q4" "M_Q5" "M_Q6" "M_Q7" "M_Q8" "M_Q9"`長名字` <- sort(colnames(mid)[which(nchar(colnames(mid)) == 5)])
`長名字`## [1] "M_Q10" "M_Q11" "M_Q12" "M_Q13" "M_Q14" "M_Q15" "M_Q16" "M_Q17" "M_Q18"
## [10] "M_Q19" "M_Q20" "M_Q21" "M_Q22" "M_Q23" "M_Q24" "M_Q25"mid <- mid[, c("ID", `短名字`, `長名字`)]
colnames(mid)## [1] "ID" "M_Q1" "M_Q2" "M_Q3" "M_Q4" "M_Q5" "M_Q6" "M_Q7" "M_Q8"
## [10] "M_Q9" "M_Q10" "M_Q11" "M_Q12" "M_Q13" "M_Q14" "M_Q15" "M_Q16" "M_Q17"
## [19] "M_Q18" "M_Q19" "M_Q20" "M_Q21" "M_Q22" "M_Q23" "M_Q24" "M_Q25"至於「期中考」的得分細節,需要時我們再來好好觀察!
18.9 期末考每題得分細節
根據「財務管理」2014年的預定進度,在「
2015-01-07」舉辦「期末考」。
一樣,我們再一次檢視「期末考每題得分細節」這一張表的欄位名稱:
## [1] "ID" "F_C4" "F_M5" "F_M6" "F_C1" "F_M3" "F_M8" "F_C3_a"
## [9] "F_C5" "F_M7" "F_C3_b" "F_C3_c" "F_C2" "F_M10" "F_M1" "F_M9"
## [17] "F_M2" "F_M4"哇!更複雜了!
nchar(colnames(final))## [1] 2 4 4 4 4 4 4 6 4 4 6 6 4 5 4 4 4 4看起來,上一節的辦法似乎使不上力!
- 先抓名字有「
C」的試試之前的作法。
sort(colnames(final)[grep("C", colnames(final))])## [1] "F_C1" "F_C2" "F_C3_a" "F_C3_b" "F_C3_c" "F_C4" "F_C5"- 再抓名字有「
M」的來看名字的長度。
sort(colnames(final)[grep("M", colnames(final))])## [1] "F_M1" "F_M10" "F_M2" "F_M3" "F_M4" "F_M5" "F_M6" "F_M7" "F_M8"
## [10] "F_M9"nchar(colnames(final)[grep("M", colnames(final))])## [1] 4 4 4 4 4 5 4 4 4 4- 觀察過後,作者小編決定這麼排序這些欄位。
FC <- sort(colnames(final)[grep("C", colnames(final))])
FC## [1] "F_C1" "F_C2" "F_C3_a" "F_C3_b" "F_C3_c" "F_C4" "F_C5"sFM <- colnames(final)[grep("M", colnames(final))]
sFM <- sort(sFM[which(nchar(sFM) == 4)])
sFM## [1] "F_M1" "F_M2" "F_M3" "F_M4" "F_M5" "F_M6" "F_M7" "F_M8" "F_M9"lFM <- colnames(final)[grep("M", colnames(final))]
lFM <- sort(lFM[which(nchar(lFM) == 5)])
lFM## [1] "F_M10"final <- final[, c("ID", FC, sFM, lFM)]
colnames(final)## [1] "ID" "F_C1" "F_C2" "F_C3_a" "F_C3_b" "F_C3_c" "F_C4" "F_C5"
## [9] "F_M1" "F_M2" "F_M3" "F_M4" "F_M5" "F_M6" "F_M7" "F_M8"
## [17] "F_M9" "F_M10"成功!
至於「期末考」的得分細節,需要時我們再來好好觀察!
18.10 原始學期總成績
根據「財務管理」2014年的預定進度,在「
2015-01-07」之後開始結算「學期總成績」。
一樣,我們再一次檢視「學期總成績」這一張表的欄位名稱:
## [1] "ID" "mid_exem" "final_exem"
## [4] "final_report" "quiz1" "quiz2"
## [7] "quiz3" "quiz4" "hw_completion_record"看似正常。至於每一個欄位到底紀錄了什麼?請讀者諸君仔細往下看:
- mid_exem,這個欄位紀錄期中考原始分數。
class(unique(grade[,6]))## [1] "tbl_df" "tbl" "data.frame"dim(unique(grade[,6]))## [1] 17 1apply(unique(grade[,6])[,1,drop = FALSE], 2, sort)## mid_exem
## [1,] 12
## [2,] 16
## [3,] 20
## [4,] 24
## [5,] 28
## [6,] 32
## [7,] 36
## [8,] 40
## [9,] 44
## [10,] 48
## [11,] 52
## [12,] 56
## [13,] 60
## [14,] 64
## [15,] 68
## [16,] 72
## [17,] 76- final_exem,這個欄位紀錄期末考原始分數。
apply(unique(grade[,7])[,1,drop = FALSE], 2, sort)## final_exem
## [1,] 34
## [2,] 40
## [3,] 46
## [4,] 54
## [5,] 57
## [6,] 60
## [7,] 62
## [8,] 63
## [9,] 68
## [10,] 70
## [11,] 72
## [12,] 73
## [13,] 74
## [14,] 75
## [15,] 76
## [16,] 78
## [17,] 79
## [18,] 80
## [19,] 82
## [20,] 83
## [21,] 84
## [22,] 86
## [23,] 87
## [24,] 88
## [25,] 90
## [26,] 92
## [27,] 94
## [28,] 95
## [29,] 96
## [30,] 100- final_report,這個欄位紀錄期末報告原始分數。
apply(unique(grade[,8])[,1,drop = FALSE], 2, sort)## final_report
## [1,] 3
## [2,] 4
## [3,] 5- quiz1,這個欄位紀錄第一次小考的原始分數。
apply(unique(grade[,9])[,1,drop = FALSE], 2, sort)## quiz1
## [1,] 2
## [2,] 4
## [3,] 10
## [4,] 16
## [5,] 20
## [6,] 24
## [7,] 26
## [8,] 28
## [9,] 30
## [10,] 32
## [11,] 34
## [12,] 36
## [13,] 40
## [14,] 42
## [15,] 44
## [16,] 46
## [17,] 48
## [18,] 50
## [19,] 52
## [20,] 54
## [21,] 56
## [22,] 58
## [23,] 60
## [24,] 64
## [25,] 66
## [26,] 68
## [27,] 70
## [28,] 72
## [29,] 74
## [30,] 76
## [31,] 80
## [32,] 82
## [33,] 84
## [34,] 86
## [35,] 88
## [36,] 92
## [37,] 94
## [38,] 994- quiz2,這個欄位紀錄第二次小考的原始分數。
apply(unique(grade[,10])[,1,drop = FALSE], 2, sort)## quiz2
## [1,] "0"
## [2,] "100"
## [3,] "21"
## [4,] "26"
## [5,] "29"
## [6,] "33"
## [7,] "39"
## [8,] "4"
## [9,] "43"
## [10,] "44"
## [11,] "47"
## [12,] "5"
## [13,] "52"
## [14,] "53"
## [15,] "54"
## [16,] "55"
## [17,] "58"
## [18,] "59"
## [19,] "6"
## [20,] "60"
## [21,] "61"
## [22,] "63"
## [23,] "64"
## [24,] "65"
## [25,] "66"
## [26,] "67"
## [27,] "68"
## [28,] "69"
## [29,] "70"
## [30,] "72"
## [31,] "73"
## [32,] "75"
## [33,] "76"
## [34,] "78"
## [35,] "80"
## [36,] "81"
## [37,] "82"
## [38,] "84"
## [39,] "85"
## [40,] "86"
## [41,] "87"
## [42,] "88"
## [43,] "89"
## [44,] "92"
## [45,] "93"
## [46,] "94"
## [47,] "96"
## [48,] "98"
## [49,] "NA"- quiz3,這個欄位紀錄第三次小考的原始分數。
apply(unique(grade[,11])[,1,drop = FALSE], 2, sort)## quiz3
## [1,] 10
## [2,] 20
## [3,] 26
## [4,] 30
## [5,] 34
## [6,] 36
## [7,] 42
## [8,] 44
## [9,] 46
## [10,] 48
## [11,] 50
## [12,] 52
## [13,] 54
## [14,] 62
## [15,] 64
## [16,] 66
## [17,] 68
## [18,] 72
## [19,] 74
## [20,] 76
## [21,] 78
## [22,] 80
## [23,] 82
## [24,] 84
## [25,] 86
## [26,] 87
## [27,] 88
## [28,] 90
## [29,] 92
## [30,] 94
## [31,] 96
## [32,] 98
## [33,] 100
## [34,] 994
## [35,] 99380
## [36,] 99382
## [37,] 99384
## [38,] 99390
## [39,] 99392
## [40,] 99394
## [41,] 99398
## [42,] 993100- quiz4,這個欄位紀錄第四次小考的原始分數。
apply(unique(grade[,12])[,1,drop = FALSE], 2, sort)## quiz4
## [1,] 53
## [2,] 56
## [3,] 58
## [4,] 65
## [5,] 67
## [6,] 68
## [7,] 69
## [8,] 72
## [9,] 74
## [10,] 75
## [11,] 76
## [12,] 78
## [13,] 80
## [14,] 82
## [15,] 84
## [16,] 86
## [17,] 88
## [18,] 90
## [19,] 91
## [20,] 92
## [21,] 94
## [22,] 96
## [23,] 98
## [24,] 100
## [25,] 994
## [26,] 99392
## [27,] 993100- hw_completion_record,這個欄位紀錄出缺席與作業繳交完成度。請注意以下當年修課學生可能的完成度:
apply(unique(grade[,13])[,1,drop = FALSE], 2, sort)## hw_completion_record
## [1,] 36
## [2,] 37
## [3,] 42
## [4,] 43
## [5,] 44
## [6,] 45
## [7,] 47
## [8,] 48
## [9,] 49
## [10,] 50
## [11,] 52
## [12,] 53
## [13,] 54
## [14,] 55
## [15,] 56
## [16,] 57
## [17,] 58
## [18,] 59
## [19,] 60可以看出裡面有「雜質」,需要啟動相關的「清理機制」!
18.11 學期總成績
根據「財務管理」2014年的預定進度,在「
2015-01-07」之後開始結算「學期總成績」。
一樣,我們再一次檢視「學期總成績」這一張表的欄位名稱:
## [1] "ID" "usually_grade" "mid_grade" "final_grade"
## [5] "semester_grade"至於每一個欄位到底紀錄了什麼?請讀者諸君仔細往下看:
- usually_grade,這個欄位紀錄最後學生得到的平時成績。
apply(unique(grade[,2])[,1,drop = FALSE], 2, sort)## usually_grade
## [1,] 62
## [2,] 70
## [3,] 72
## [4,] 73
## [5,] 76
## [6,] 77
## [7,] 78
## [8,] 82
## [9,] 83
## [10,] 86
## [11,] 87
## [12,] 88
## [13,] 90
## [14,] 91
## [15,] 92
## [16,] 93
## [17,] 94
## [18,] 95
## [19,] 97
## [20,] 98
## [21,] 99
## [22,] 100- mid_grade,這個欄位紀錄最後學生得到的期中考成績。
apply(unique(grade[,3])[,1,drop = FALSE], 2, sort)## mid_grade
## [1,] 12
## [2,] 22
## [3,] 25
## [4,] 29
## [5,] 30
## [6,] 32
## [7,] 33
## [8,] 34
## [9,] 35
## [10,] 36
## [11,] 37
## [12,] 38
## [13,] 39
## [14,] 40
## [15,] 41
## [16,] 42
## [17,] 43
## [18,] 44
## [19,] 45
## [20,] 46
## [21,] 47
## [22,] 48
## [23,] 49
## [24,] 50
## [25,] 51
## [26,] 52
## [27,] 53
## [28,] 54
## [29,] 55
## [30,] 56
## [31,] 57
## [32,] 58
## [33,] 59
## [34,] 60
## [35,] 61
## [36,] 62
## [37,] 64
## [38,] 65
## [39,] 66
## [40,] 67
## [41,] 68
## [42,] 72
## [43,] 76
## [44,] 79
## [45,] 80- final_grade,這個欄位紀錄最後學生得到的期末考成績。
apply(unique(grade[,4])[,1,drop = FALSE], 2, sort)## final_grade
## [1,] 37
## [2,] 39
## [3,] 46
## [4,] 47
## [5,] 55
## [6,] 56
## [7,] 59
## [8,] 60
## [9,] 61
## [10,] 63
## [11,] 66
## [12,] 67
## [13,] 70
## [14,] 71
## [15,] 72
## [16,] 73
## [17,] 74
## [18,] 75
## [19,] 76
## [20,] 77
## [21,] 78
## [22,] 79
## [23,] 80
## [24,] 81
## [25,] 82
## [26,] 83
## [27,] 84
## [28,] 85
## [29,] 86
## [30,] 87
## [31,] 88
## [32,] 89
## [33,] 90
## [34,] 91
## [35,] 92
## [36,] 93
## [37,] 95
## [38,] 100- semester_grade,這個欄位紀錄最後學生得到的學期總成績。
apply(unique(grade[,5])[,1,drop = FALSE], 2, sort)## semester_grade
## [1,] 53
## [2,] 56
## [3,] 57
## [4,] 60
## [5,] 61
## [6,] 63
## [7,] 64
## [8,] 65
## [9,] 66
## [10,] 67
## [11,] 68
## [12,] 69
## [13,] 70
## [14,] 71
## [15,] 72
## [16,] 73
## [17,] 74
## [18,] 75
## [19,] 76
## [20,] 77
## [21,] 78
## [22,] 79
## [23,] 80
## [24,] 81
## [25,] 82
## [26,] 83
## [27,] 84
## [28,] 85
## [29,] 86
## [30,] 87
## [31,] 9318.12 期初調查
「期初調查」的目的是為了「理解、掌握」學生的「部分背景資料」,方便作者小編的好朋友可以據以調整教學設計。
一樣,先看一下當年這一份「期初調查結果」的欄位名稱:
colnames(Q1)## [1] "ID" "Q1V1" "Q1V2" "Q1V3_YY"
## [5] "Q1V3_MM" "Q1V3_DD" "Q1V4_college" "Q1V4_department"
## [9] "Q1V4_grade" "Q1V6_1" "Q1V6_2" "Q1V6_3"
## [13] "Q1V7_1" "Q1V7_2" "Q1V7_3" "Q1V8_1"
## [17] "Q1V8_2" "Q1V8_3" "Q1V8_4" "Q1V9"
## [21] "Q1V10" "Q1V11" "Q1V12" "Q1V13"
## [25] "Q1V14" "Q1V15"看起來,「順序滿好的」。只是,
到底問了什麼呢?
光看「欄位名稱」,絕對無法得知,當年這一位財務管理授課師長到底問了什麼?為此,當年作者小編跟研究生第一次研究這一組數據集的時候,邊寫過一份所謂的「編碼簿」,紀錄著每一個欄位相關的資訊。作者小編抓出「期初調查」來,
考考大家,
哪幾題是「複選題」?
18.13 期中調查
「期中調查」的目的是為了「理解、掌握」學生在經過「半學期」之後,「在課的行為」、「有沒有指定的原文教科書」、「是否掌握財管的基礎觀念」以及「授課滿意度」,方便作者小編的好朋友可以據以調整教學設計。
一樣,先看一下當年這一份「期初調查結果」的欄位名稱:
colnames(Q2)## [1] "ID" "Q2V2" "Q2V3" "Q2V4" "Q2V5" "Q2V6" "Q2V7"
## [8] "Q2V8" "Q2V9" "Q2V10" "Q2V11" "Q2V12_1" "Q2V12_2" "Q2V12_3"
## [15] "Q2V12_4" "Q2V13" "Q2V14" "Q2V15" "Q2V16" "Q2V17" "Q2V18"
## [22] "Q2V19"一樣,到底問了什麼呢?
18.14 期末調查
「期末調查」的目的是為了「總結」學生在經過「一學期」之後,「在課的行為」、「是否掌握財管的基礎觀念」以及「授課滿意度」,方便作者小編的好朋友可以據以調整「來年的教學設計」。
一樣,先看一下當年這一份「期末調查結果」的欄位名稱:
colnames(Q3)## [1] "ID" "Q3V2_1" "Q3V2_2" "Q3V3" "Q3V4" "Q3V5" "Q3V6" "Q3V7"
## [9] "Q3V8" "Q3V9" "Q3V10" "Q3V11" "Q3V12" "Q3V13" "Q3V14" "Q3V15"
## [17] "Q3V16" "Q3V17" "Q3V18" "Q3V19" "Q3V20" "Q3V21" "Q3V22"一樣,到底問了什麼呢?