Chapter 19 財務管理課堂數據集之探索式分析
19.1 旭
經過前面兩章的「洗禮」,作者小編
越來越佩服那位好朋友了!太強了!
為了更進一步理解「原始紀錄」跟「新創數字」,作者小編在這一章啟動「探索式分析」。什麼是「探索式分析」呢?「探索式分析」最想要回答這一個問題
到底「收」到什麼「數據」?
本質上,就是想回答
到底「收」到什麼「符號」?
作者小編已經在第二章示範過一些可能性了。在這一章,我們要繼續
問問題。
讓我們「更(more)」了解好朋友「收到」什麼?而修課的我們「收到」什麼?一般而言,「探索式分析」基本上會經過「三階段」(摘錄自「https://r4ds.had.co.nz/exploratory-data-analysis.html」):
- Generate questions about your data.
- Search for answers by visualising, transforming, and modelling your data.
- Use what you learn to refine your questions and/or generate new questions.
接下來,我們就一個一個「探索」,確知修課的我們「收到」什麼?必要時,啟動「清理工程」。
只要原始數據「乾淨」,後續的「新創數字」就會「乾淨」!
最好的消息是,當年協助作者小編一起研究這一整組「課堂學習數據集」的學長姐,留下一本「編碼簿」。「編碼簿」紀錄了
每一個欄位收到符號的意義。
請看,雖然作者小編無法保證「正確性」,所以請讀者諸君一起來「除錯」。
接下來,就讓我們「一步一腳印」,一個接著一個「探索」原始紀錄!
…
19.3 每堂課出缺席紀錄
請讀者諸君記住「作者小編為了探索原始紀錄走過的路」!
先看「每堂課出缺席紀錄」的「編碼簿」:
…
19.3.1 第一堂課出缺席紀錄編碼簿
codeBookInsurance <- readRDS("data/codeBookInsurance.rds")
week1codes <- codeBookInsurance[which(codeBookInsurance$source == "insurance_2014-10-01"),]
ForNow <- c("source", "question", "meaning", "備註", "choices", "codes")
DT::datatable(week1codes[,ForNow],
options = list(scrollX = TRUE,
fixedColumns = TRUE))讓我們試著解讀「這一小本編碼簿」:
- 欄位「source」,紀錄「2014-10-01」出缺席紀錄的檔案名稱。
- 欄位「question」,紀錄「2014-10-01」出缺席紀錄的欄位名稱。
- 欄位「meaning」,紀錄「2014-10-01」出缺席紀錄的欄位意義。
- 欄位「備註」,紀錄「2014-10-01」出缺席紀錄的遺漏值備註。
- 欄位「choices」,紀錄「2014-10-01」出缺席紀錄的可能選項。
- 欄位「codes」,紀錄「2014-10-01」出缺席紀錄可能選項的代號,也就是我們「收到」的符號。
19.3.2 準備數據:第一堂課出缺席紀錄
有了上述這一張表之後,讓我們啟動R的基本檢查
class(week1)## [1] "tbl_df" "tbl" "data.frame"sapply(week1, class)## ID v100101 v100102 v100103 v1001
## "character" "numeric" "numeric" "numeric" "numeric"dim(week1)## [1] 85 5colnames(week1)## [1] "ID" "v100101" "v100102" "v100103" "v1001"sapply(week1[,-1], unique)## $v100101
## [1] 1 0 999
##
## $v100102
## [1] 1 0 999
##
## $v100103
## [1] 1 0 999
##
## $v1001
## [1] 1 0看過R給的檢查報表,並核對編碼簿的記載,一切正常,至少「2014-10-01」這一週的出缺席紀錄,還沒看到「錯誤碼」或說是「意外碼」。
19.3.3 清理遺漏值
week1 <- as.data.frame(week1, stringsAsFactors = FALSE)
week1[which(week1 == 999, arr.ind = TRUE)] <- NA
DT::datatable(week1[,-1],
options = list(scrollX = TRUE,
fixedColumns = TRUE))作者小編把「好朋友遺漏值編碼『999』」換成R看得懂的「NA」,所以上述表格原本「999」的格子變成「空白」。
19.3.4 次數分配表
par(mfrow = c(2,2))
p1 <- barplot(table(week1$v100101), axes = FALSE, ylim = c(0,85), main = "第一堂課出缺席分配")
text(p1, table(week1$v100101)+5, labels = table(week1$v100101))
p2 <- barplot(table(week1$v100102), axes = FALSE, ylim = c(0,85), main = "第二堂課出缺席分配")
text(p2, table(week1$v100102)+5, labels = table(week1$v100102))
p3 <- barplot(table(week1$v100103), axes = FALSE, ylim = c(0,85), main = "第三堂課出缺席分配")
text(p3, table(week1$v100103)+5, labels = table(week1$v100103))
pTA <- barplot(table(week1$v1001), axes = FALSE, ylim = c(0,85), main = "實習課出缺席分配")
text(pTA, table(week1$v1001)+5, labels = table(week1$v1001))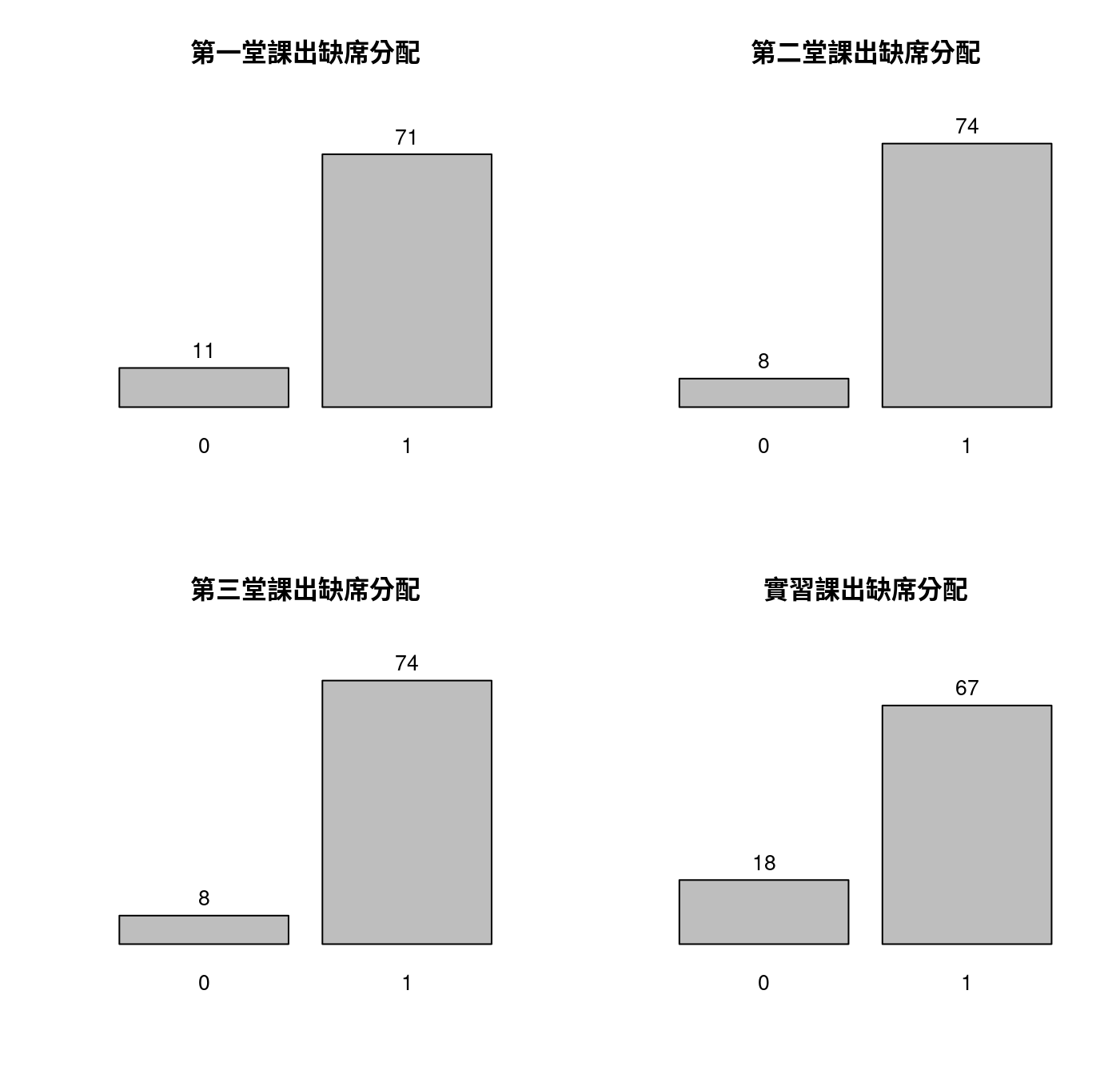
19.4 作業繳交紀錄
19.4.1 第一次作業繳交紀錄編碼簿
codeBookInsurance <- readRDS("data/codeBookInsurance.rds")
HW1codes <- codeBookInsurance[which(codeBookInsurance$source == "hw01_insurance_2014-10-01"),]
ForNow <- c("source", "question", "meaning", "備註", "choices", "codes")
DT::datatable(HW1codes[,ForNow],
options = list(scrollX = TRUE,
fixedColumns = TRUE))讓我們試著解讀「這一小本編碼簿」:
- 欄位「source」,紀錄「2014-10-01」作業繳交紀錄的檔案名稱。
- 欄位「question」,紀錄「2014-10-01」作業繳交紀錄的欄位名稱。
- 欄位「meaning」,紀錄「2014-10-01」作業繳交紀錄的欄位意義。
- 欄位「備註」,紀錄「2014-10-01」作業繳交紀錄的遺漏值備註。
- 欄位「choices」,紀錄「2014-10-01」作業繳交紀錄的可能選項。
- 欄位「codes」,紀錄「2014-10-01」作業繳交紀錄可能選項的代號,也就是我們「收到」的符號。
19.4.2 準備數據:第一次作業繳交紀錄
有了上述這一張表之後,讓我們啟動R的基本檢查
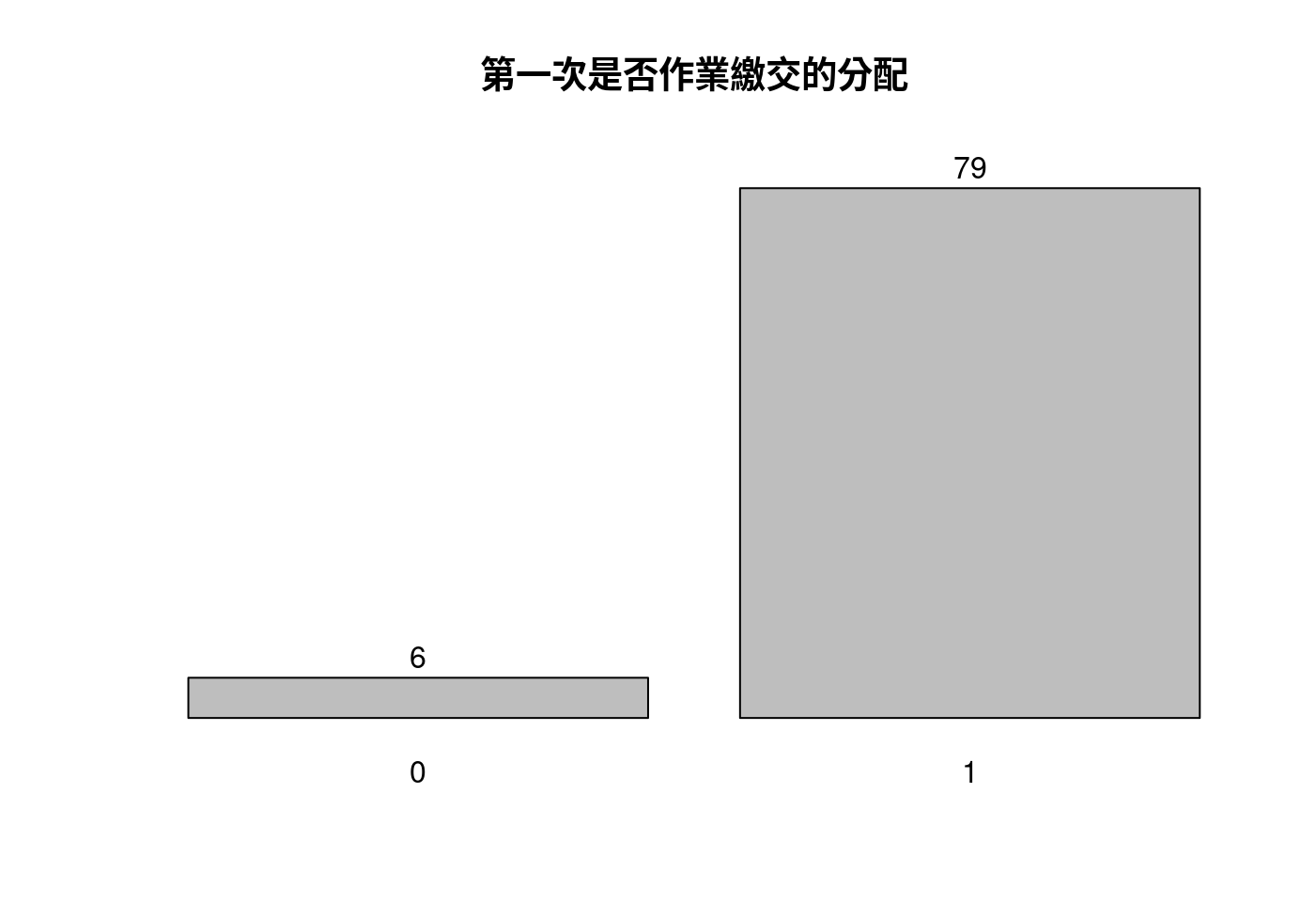
class(HW1)## [1] "tbl_df" "tbl" "data.frame"sapply(HW1, class)## ID hw_ch1
## "character" "numeric"dim(HW1)## [1] 85 2colnames(HW1)## [1] "ID" "hw_ch1"sapply(HW1[,-1], unique)## hw_ch1
## [1,] 1
## [2,] 0看過R給的檢查報表,並核對編碼簿的記載,一切正常,至少「2014-10-01」這一週的作業繳交紀錄,還沒看到「錯誤碼」或說是「意外碼」,而且
無需啟動清理遺漏值的程式碼。
19.5 第一次小考每題得分細節
19.5.1 第一次小考每題得分細節編碼簿
codeBookInsurance <- readRDS("data/codeBookInsurance.rds")
quiz01codes <- codeBookInsurance[grep("quiz01",codeBookInsurance$source),]
ForNow <- c("source", "question", "meaning", "備註", "choices", "codes")
DT::datatable(quiz01codes[,ForNow],
options = list(scrollX = TRUE,
fixedColumns = TRUE))讓我們試著解讀「這一小本編碼簿」:
- 欄位「source」,紀錄「2014-10-15」第一次小考每題得分細節的檔案名稱。
- 欄位「question」,紀錄「2014-10-15」第一次小考每題得分細節的欄位名稱。
- 欄位「meaning」,紀錄「2014-10-15」第一次小考每題得分細節的欄位意義。
- 欄位「備註」,紀錄「2014-10-15」第一次小考每題得分細節的遺漏值備註。
- 欄位「choices」,紀錄「2014-10-15」第一次小考每題最高得分。
- 欄位「codes」,紀錄「2014-10-15」第一次小考每題的配分,也就是指出我們可能「收到」的符號。
19.5.2 準備數據:第一次小考每題得分細節
有了上述這一張表之後,讓我們啟動R的基本檢查
class(quiz1)## [1] "tbl_df" "tbl" "data.frame"sapply(quiz1, class)## ID Q1_1 Q1_2 Q1_3 Q1_4 Q1_5
## "character" "character" "character" "character" "character" "character"
## Q1_6 Q1_7 Q1_8 Q1_9 Q1_10
## "character" "character" "character" "character" "character"dim(quiz1)## [1] 85 11colnames(quiz1)## [1] "ID" "Q1_1" "Q1_2" "Q1_3" "Q1_4" "Q1_5" "Q1_6" "Q1_7" "Q1_8"
## [10] "Q1_9" "Q1_10"sapply(quiz1[,-1], unique)## Q1_1 Q1_2 Q1_3 Q1_4 Q1_5 Q1_6 Q1_7 Q1_8 Q1_9 Q1_10
## [1,] "10" "4" "10" "10" "10" "10" "10" "4" "0" "8"
## [2,] "8" "10" "2" "8" "6" "0" "8" "8" "2" "10"
## [3,] "4" "8" "6" "6" "4" "4" "4" "10" "10" "6"
## [4,] "2" "6" "4" "4" "8" "8" "6" "0" "4" "4"
## [5,] "6" "2" "0" "2" "0" "6" "0" "2" "8" "0"
## [6,] "0" "0" "8" "0" "2" "2" "2" "6" "6" "2"
## [7,] "NA" "NA" "NA" "NA" "NA" "NA" "NA" "NA" "NA" "NA"看過R給的檢查報表,發現
- 照說「考試得分」是「數字」,不會是「文字」。
- 有些同學,至少有一位的分數被記錄為「
"NA"」。很明顯,這是「遺漏值」或是「缺失值」,雖然跟「編碼簿」的紀錄不合!
19.5.3 清理遺漏值
quiz1 <- as.data.frame(quiz1, stringsAsFactors = FALSE)
quiz1[which(quiz1 == "NA", arr.ind = TRUE)] <- NA
quiz1[,-1] <- sapply(quiz1[,-1], as.numeric)
DT::datatable(quiz1[,-1],
options = list(scrollX = TRUE,
fixedColumns = TRUE))作者小編把「好朋友遺漏值編碼『"NA"』」換成R看得懂的「NA」,所以上述表格原本「"NA"」的格子變成「空白」,並且把原本「文字紀錄」轉成「數字紀錄」。
19.5.4 次數分配表
sapply(quiz1[,-1], table)## Q1_1 Q1_2 Q1_3 Q1_4 Q1_5 Q1_6 Q1_7 Q1_8 Q1_9 Q1_10
## 0 2 6 22 4 15 20 12 10 40 16
## 2 6 5 8 3 3 1 8 7 7 6
## 4 14 49 20 6 25 6 37 20 12 11
## 6 1 4 12 1 10 2 5 8 2 3
## 8 8 6 9 4 9 2 18 12 7 16
## 10 52 13 12 65 21 52 3 26 15 3119.5.5 檔案管理
如果讀者諸君
不想「每一次」需要「
2014-10-15這一天第一次小考的紀錄」,就要執行「上述諸多程式碼一次」!
那就要「啟動『檔案管理』機制」。
saveRDS(quiz1, "output/data/quiz1.rds")往後,只要「需要」就「讀回來」:
quiz1 <- readRDS("output/data/quiz1.rds")
DT::datatable(quiz1[,-1],
options = list(scrollX = TRUE,
fixedColumns = TRUE))一模一樣!
…
19.5.6 第一次小考每題得分細節相關性分析
假如認定「每題得分」是一種「連續變數」,我們就可以用「相關係數」檢視「第一次小考每題得分細節相關性分析」:
請注意如何面對「
NA」?
cor(quiz1[,-1])## Q1_1 Q1_2 Q1_3 Q1_4 Q1_5 Q1_6 Q1_7 Q1_8 Q1_9 Q1_10
## Q1_1 1 NA NA NA NA NA NA NA NA NA
## Q1_2 NA 1 NA NA NA NA NA NA NA NA
## Q1_3 NA NA 1 NA NA NA NA NA NA NA
## Q1_4 NA NA NA 1 NA NA NA NA NA NA
## Q1_5 NA NA NA NA 1 NA NA NA NA NA
## Q1_6 NA NA NA NA NA 1 NA NA NA NA
## Q1_7 NA NA NA NA NA NA 1 NA NA NA
## Q1_8 NA NA NA NA NA NA NA 1 NA NA
## Q1_9 NA NA NA NA NA NA NA NA 1 NA
## Q1_10 NA NA NA NA NA NA NA NA NA 1Vquiz1 <- var(quiz1[,-1], na.rm = TRUE)
cov2cor(Vquiz1)## Q1_1 Q1_2 Q1_3 Q1_4 Q1_5 Q1_6 Q1_7
## Q1_1 1.0000000 0.2597206 0.2607120 0.4310823 0.1700686 0.3236321 0.3477300
## Q1_2 0.2597206 1.0000000 0.4075943 0.3753318 0.3259262 0.3619699 0.3630274
## Q1_3 0.2607120 0.4075943 1.0000000 0.2722312 0.4781278 0.4128461 0.4911992
## Q1_4 0.4310823 0.3753318 0.2722312 1.0000000 0.3947935 0.3258328 0.3790260
## Q1_5 0.1700686 0.3259262 0.4781278 0.3947935 1.0000000 0.4665947 0.3562628
## Q1_6 0.3236321 0.3619699 0.4128461 0.3258328 0.4665947 1.0000000 0.4327601
## Q1_7 0.3477300 0.3630274 0.4911992 0.3790260 0.3562628 0.4327601 1.0000000
## Q1_8 0.3370916 0.4161616 0.4566938 0.4111911 0.4848882 0.3945612 0.3214154
## Q1_9 0.2669273 0.4480556 0.3706377 0.1797812 0.3642064 0.3008578 0.2741451
## Q1_10 0.2900456 0.3170380 0.4817397 0.3916939 0.3112164 0.3747355 0.5807907
## Q1_8 Q1_9 Q1_10
## Q1_1 0.3370916 0.2669273 0.2900456
## Q1_2 0.4161616 0.4480556 0.3170380
## Q1_3 0.4566938 0.3706377 0.4817397
## Q1_4 0.4111911 0.1797812 0.3916939
## Q1_5 0.4848882 0.3642064 0.3112164
## Q1_6 0.3945612 0.3008578 0.3747355
## Q1_7 0.3214154 0.2741451 0.5807907
## Q1_8 1.0000000 0.4288572 0.3762477
## Q1_9 0.4288572 1.0000000 0.3306940
## Q1_10 0.3762477 0.3306940 1.0000000round(cov2cor(Vquiz1), 3)## Q1_1 Q1_2 Q1_3 Q1_4 Q1_5 Q1_6 Q1_7 Q1_8 Q1_9 Q1_10
## Q1_1 1.000 0.260 0.261 0.431 0.170 0.324 0.348 0.337 0.267 0.290
## Q1_2 0.260 1.000 0.408 0.375 0.326 0.362 0.363 0.416 0.448 0.317
## Q1_3 0.261 0.408 1.000 0.272 0.478 0.413 0.491 0.457 0.371 0.482
## Q1_4 0.431 0.375 0.272 1.000 0.395 0.326 0.379 0.411 0.180 0.392
## Q1_5 0.170 0.326 0.478 0.395 1.000 0.467 0.356 0.485 0.364 0.311
## Q1_6 0.324 0.362 0.413 0.326 0.467 1.000 0.433 0.395 0.301 0.375
## Q1_7 0.348 0.363 0.491 0.379 0.356 0.433 1.000 0.321 0.274 0.581
## Q1_8 0.337 0.416 0.457 0.411 0.485 0.395 0.321 1.000 0.429 0.376
## Q1_9 0.267 0.448 0.371 0.180 0.364 0.301 0.274 0.429 1.000 0.331
## Q1_10 0.290 0.317 0.482 0.392 0.311 0.375 0.581 0.376 0.331 1.000或是繪製「相關係數圖」,
library(corrplot)
corrplot(cov2cor(Vquiz1), type = "lower")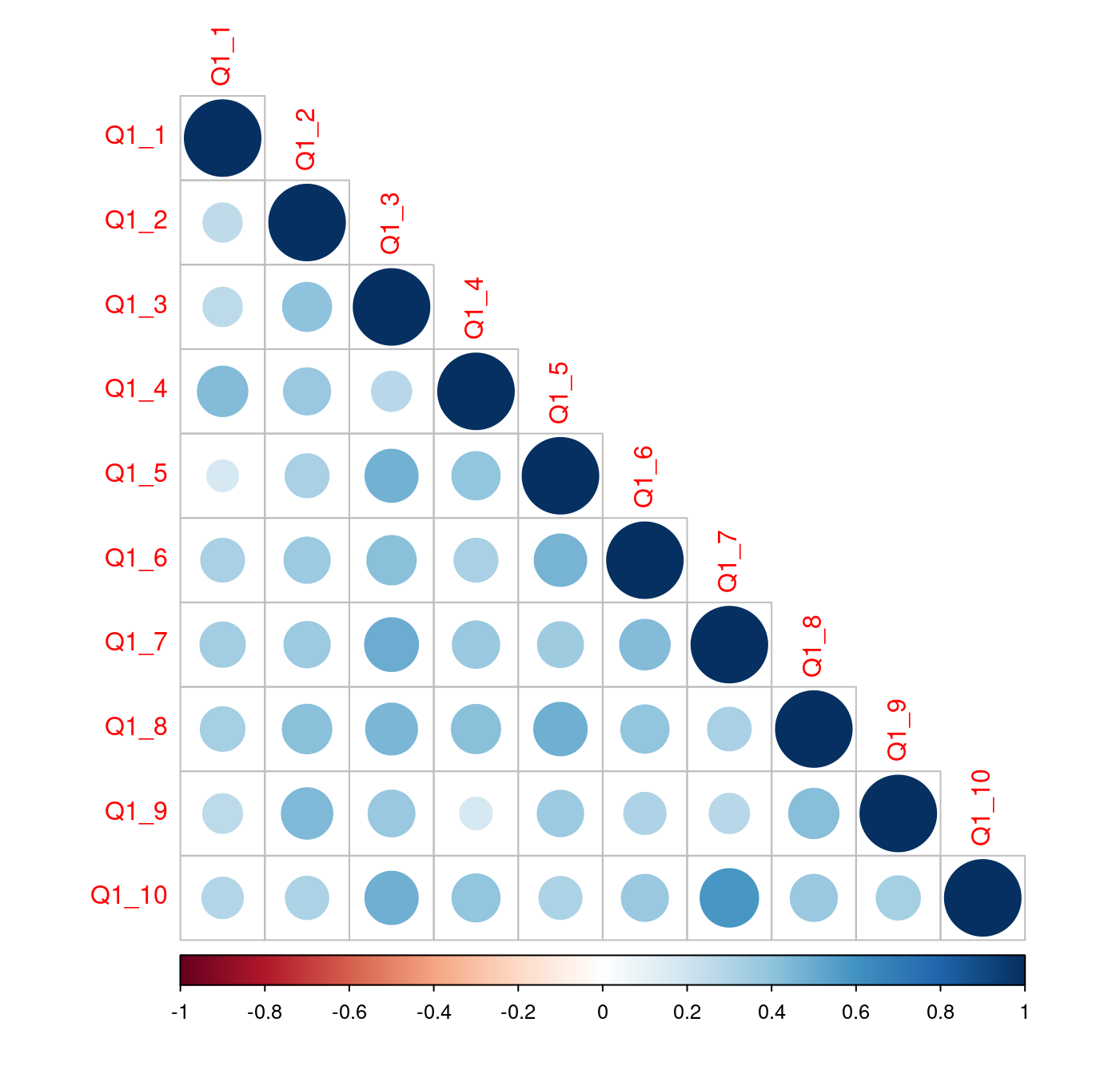
19.6 期中考每題得分細節
19.6.1 期中考每題得分細節編碼簿
codeBookInsurance <- readRDS("data/codeBookInsurance.rds")
midcodes <- codeBookInsurance[grep("mid",codeBookInsurance$source),]
ForNow <- c("source", "question", "meaning", "備註", "choices", "codes")
DT::datatable(midcodes[,ForNow],
options = list(scrollX = TRUE,
fixedColumns = TRUE))讓我們試著解讀「這一小本編碼簿」:
- 欄位「source」,紀錄「2014-11-12」期中考每題得分細節的檔案名稱。
- 欄位「question」,紀錄「2014-11-12」期中考每題得分細節的欄位名稱。
- 欄位「meaning」,紀錄「2014-11-12」期中考每題得分細節的欄位意義。
- 欄位「備註」,紀錄「2014-11-12」期中考每題得分細節的遺漏值備註。
- 欄位「choices」,紀錄「2014-11-12」期中考每題最高得分。
- 欄位「codes」,紀錄「2014-11-12」期中考每題的配分,也就是指出我們可能「收到」的符號。
19.6.2 準備數據:期中考每題得分細節
有了上述這一張表之後,讓我們啟動R的基本檢查
class(mid)## [1] "tbl_df" "tbl" "data.frame"sapply(mid, class)## ID M_Q1 M_Q2 M_Q3 M_Q4 M_Q5
## "character" "numeric" "numeric" "numeric" "numeric" "numeric"
## M_Q6 M_Q7 M_Q8 M_Q9 M_Q10 M_Q11
## "numeric" "numeric" "numeric" "numeric" "numeric" "numeric"
## M_Q12 M_Q13 M_Q14 M_Q15 M_Q16 M_Q17
## "numeric" "numeric" "numeric" "numeric" "numeric" "numeric"
## M_Q18 M_Q19 M_Q20 M_Q21 M_Q22 M_Q23
## "numeric" "numeric" "numeric" "numeric" "numeric" "numeric"
## M_Q24 M_Q25
## "numeric" "numeric"dim(mid)## [1] 85 26colnames(mid)## [1] "ID" "M_Q1" "M_Q2" "M_Q3" "M_Q4" "M_Q5" "M_Q6" "M_Q7" "M_Q8"
## [10] "M_Q9" "M_Q10" "M_Q11" "M_Q12" "M_Q13" "M_Q14" "M_Q15" "M_Q16" "M_Q17"
## [19] "M_Q18" "M_Q19" "M_Q20" "M_Q21" "M_Q22" "M_Q23" "M_Q24" "M_Q25"sapply(mid[,-1], unique)## M_Q1 M_Q2 M_Q3 M_Q4 M_Q5 M_Q6 M_Q7 M_Q8 M_Q9 M_Q10 M_Q11 M_Q12 M_Q13 M_Q14
## [1,] 1 0 1 1 0 1 1 0 1 0 0 1 1 1
## [2,] 0 1 0 0 1 0 0 1 0 1 1 0 0 0
## M_Q15 M_Q16 M_Q17 M_Q18 M_Q19 M_Q20 M_Q21 M_Q22 M_Q23 M_Q24 M_Q25
## [1,] 1 0 1 1 0 0 0 0 1 1 1
## [2,] 0 1 0 0 1 1 1 1 0 0 0看過R給的檢查報表,發現一切正常。
無需啟動清理遺漏值的程式碼。
19.6.3 次數分配表
sapply(mid[,-1], table)## M_Q1 M_Q2 M_Q3 M_Q4 M_Q5 M_Q6 M_Q7 M_Q8 M_Q9 M_Q10 M_Q11 M_Q12 M_Q13 M_Q14
## 0 38 14 46 12 60 42 18 67 27 49 50 52 54 77
## 1 47 71 39 73 25 43 67 18 58 36 35 33 31 8
## M_Q15 M_Q16 M_Q17 M_Q18 M_Q19 M_Q20 M_Q21 M_Q22 M_Q23 M_Q24 M_Q25
## 0 59 50 48 68 56 63 74 57 53 10 39
## 1 26 35 37 17 29 22 11 28 32 75 4619.7 期末考每題得分細節
19.7.1 期末考每題得分細節編碼簿
codeBookInsurance <- readRDS("data/codeBookInsurance.rds")
finalcodes <- codeBookInsurance[grep("final",codeBookInsurance$source),]
ForNow <- c("source", "question", "meaning", "備註", "choices", "codes")
DT::datatable(finalcodes[,ForNow],
options = list(scrollX = TRUE,
fixedColumns = TRUE))讓我們試著解讀「這一小本編碼簿」:
- 欄位「source」,紀錄「2015-01-07」期末考每題得分細節的檔案名稱。
- 欄位「question」,紀錄「2015-01-07」期末考每題得分細節的欄位名稱。
- 欄位「meaning」,紀錄「2015-01-07」期末考每題得分細節的欄位意義。
- 欄位「備註」,紀錄「2015-01-07」期末考每題得分細節的遺漏值備註。
- 欄位「choices」,紀錄「2015-01-07」期末考每題最高得分。
- 欄位「codes」,紀錄「2015-01-07」期末考每題的配分,也就是指出我們可能「收到」的符號。
19.7.2 準備數據:期末考每題得分細節
有了上述這一張表之後,讓我們啟動R的基本檢查
class(final)## [1] "tbl_df" "tbl" "data.frame"sapply(final, class)## ID F_C1 F_C2 F_C3_a F_C3_b F_C3_c
## "character" "numeric" "numeric" "numeric" "numeric" "numeric"
## F_C4 F_C5 F_M1 F_M2 F_M3 F_M4
## "numeric" "numeric" "numeric" "numeric" "numeric" "numeric"
## F_M5 F_M6 F_M7 F_M8 F_M9 F_M10
## "numeric" "numeric" "numeric" "numeric" "numeric" "numeric"dim(final)## [1] 85 18colnames(final)## [1] "ID" "F_C1" "F_C2" "F_C3_a" "F_C3_b" "F_C3_c" "F_C4" "F_C5"
## [9] "F_M1" "F_M2" "F_M3" "F_M4" "F_M5" "F_M6" "F_M7" "F_M8"
## [17] "F_M9" "F_M10"sapply(final[,-1], unique)## $F_C1
## [1] 8 6 0 2
##
## $F_C2
## [1] 10 2 8 9 6 0 1 5
##
## $F_C3_a
## [1] 10 6 8 0 5
##
## $F_C3_b
## [1] 10 6 0 2 4 8
##
## $F_C3_c
## [1] 0 2
##
## $F_C4
## [1] 10 0 1 4 8 6 9
##
## $F_C5
## [1] 10 2 1 8 4 5 6 9
##
## $F_M1
## [1] 1 0
##
## $F_M2
## [1] 1 0
##
## $F_M3
## [1] 1 0
##
## $F_M4
## [1] 0 1
##
## $F_M5
## [1] 1 0
##
## $F_M6
## [1] 1 0
##
## $F_M7
## [1] 1 0
##
## $F_M8
## [1] 1 0
##
## $F_M9
## [1] 0 1
##
## $F_M10
## [1] 1 0看過R給的檢查報表,發現一切正常。
無需啟動清理遺漏值的程式碼。
19.7.3 次數分配表
sapply(final[, c(FC)], table)## $F_C1
##
## 0 2 6 8
## 1 3 9 72
##
## $F_C2
##
## 0 1 2 5 6 8 9 10
## 3 5 15 1 3 15 3 40
##
## $F_C3_a
##
## 0 5 6 8 10
## 1 1 1 2 80
##
## $F_C3_b
##
## 0 2 4 6 8 10
## 3 2 1 2 1 76
##
## $F_C3_c
##
## 0 2
## 10 75
##
## $F_C4
##
## 0 1 4 6 8 9 10
## 3 2 1 6 6 1 66
##
## $F_C5
##
## 1 2 4 5 6 8 9 10
## 7 2 2 1 11 11 2 49sapply(final[, c(sFM, lFM)], table)## F_M1 F_M2 F_M3 F_M4 F_M5 F_M6 F_M7 F_M8 F_M9 F_M10
## 0 5 34 10 44 16 21 69 26 42 16
## 1 80 51 75 41 69 64 16 59 43 6919.7.4 檔案管理
如果讀者諸君
不想「每一次」需要「
2015-01-07這一天的期末考得分細節」,就要執行「上述諸多程式碼一次」!
那就要「啟動『檔案管理』機制」。
saveRDS(final, "output/data/final.rds")往後,只要「需要」就「讀回來」:
final <- readRDS("output/data/final.rds")
DT::datatable(final[,-1],
options = list(scrollX = TRUE,
fixedColumns = TRUE))一模一樣!
…
19.7.5 期末考每題得分細節相關性分析
cor(final[, c(FC)])## F_C1 F_C2 F_C3_a F_C3_b F_C3_c F_C4
## F_C1 1.00000000 0.12696886 -0.07321249 0.06858582 0.06984303 0.2473922
## F_C2 0.12696886 1.00000000 0.06501778 0.29377574 0.08319029 0.3185339
## F_C3_a -0.07321249 0.06501778 1.00000000 0.52282172 0.17733129 0.2505644
## F_C3_b 0.06858582 0.29377574 0.52282172 1.00000000 0.13743351 0.4180902
## F_C3_c 0.06984303 0.08319029 0.17733129 0.13743351 1.00000000 0.3433730
## F_C4 0.24739222 0.31853389 0.25056440 0.41809018 0.34337297 1.0000000
## F_C5 0.05871641 0.14794858 0.12872219 0.16400854 0.32765397 0.2062755
## F_C5
## F_C1 0.05871641
## F_C2 0.14794858
## F_C3_a 0.12872219
## F_C3_b 0.16400854
## F_C3_c 0.32765397
## F_C4 0.20627548
## F_C5 1.00000000或是繪製「相關係數圖」
corrplot::corrplot(cor(final[, c(FC)]), type = "lower")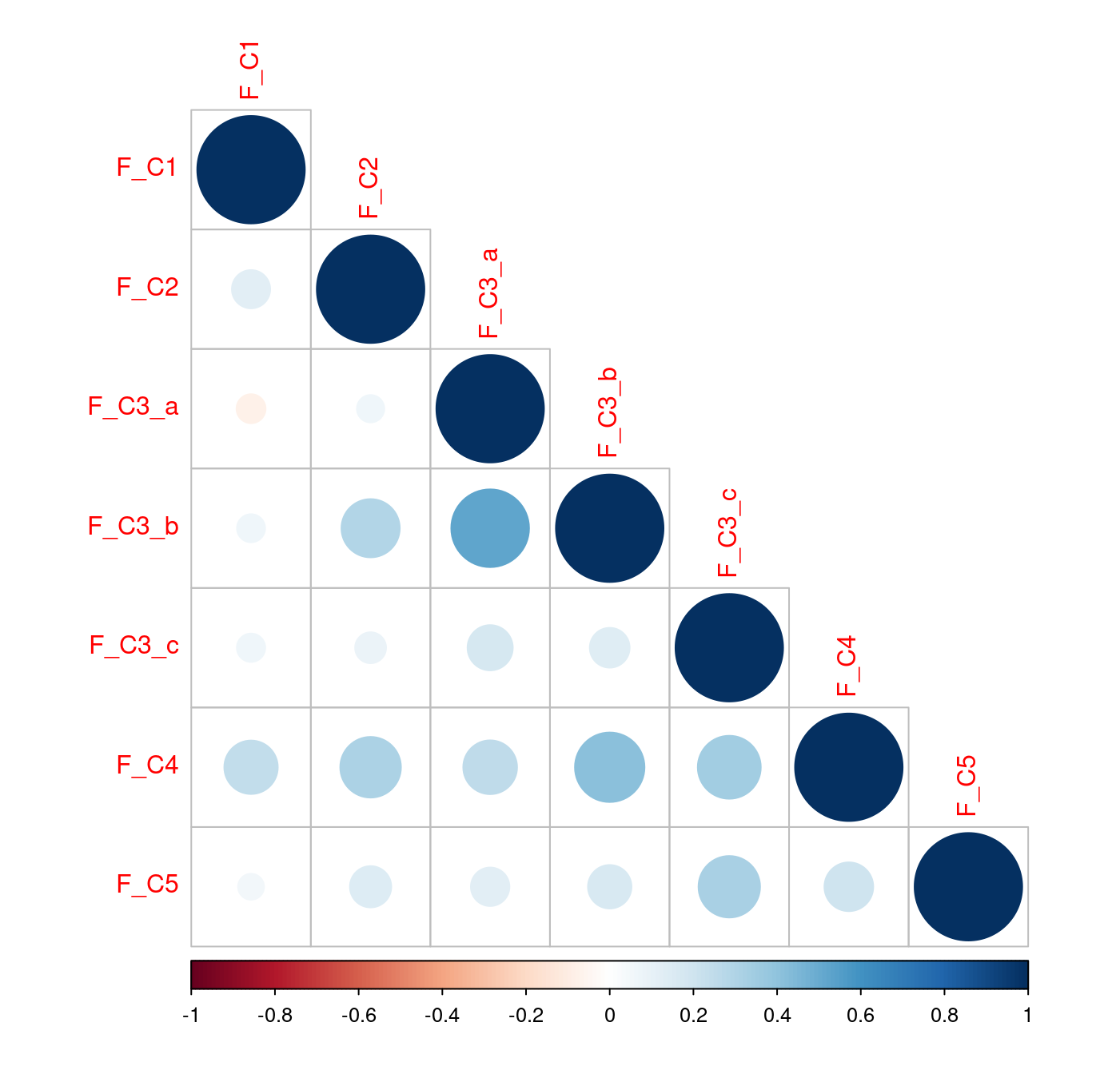
19.8 原始學期總成績
19.8.1 原始學期總成績編碼簿
codeBookInsurance <- readRDS("data/codeBookInsurance.rds")
gradecodes <- codeBookInsurance[grep("grade",codeBookInsurance$source),]
gradecodes <- gradecodes[-grep("grade", gradecodes$question),]
ForNow <- c("source", "question", "meaning", "備註", "choices", "codes")
DT::datatable(gradecodes[,ForNow],
options = list(scrollX = TRUE,
fixedColumns = TRUE))讓我們試著解讀「這一小本編碼簿」:
- 欄位「source」,紀錄各個考核項目原始得分的檔案名稱。
- 欄位「question」,紀錄各個考核項目原始得分的欄位名稱。
- 欄位「meaning」,紀錄各個考核項目原始得分的欄位意義。
- 欄位「備註」,紀錄各個考核項目原始得分的遺漏值備註。
- 欄位「choices」,紀錄各個考核項目原始得分的最高得分。
- 欄位「codes」,紀錄各個考核項目原始得分的最高得分,也就是指出我們可能「收到」的符號。
19.8.2 準備數據:原始學期總成績
有了上述這一張表之後,讓我們啟動R的基本檢查
class(originalGrade)## [1] "tbl_df" "tbl" "data.frame"sapply(originalGrade, class)## ID mid_exem final_exem
## "character" "numeric" "numeric"
## final_report quiz1 quiz2
## "numeric" "numeric" "character"
## quiz3 quiz4 hw_completion_record
## "numeric" "numeric" "numeric"dim(originalGrade)## [1] 85 9colnames(originalGrade)## [1] "ID" "mid_exem" "final_exem"
## [4] "final_report" "quiz1" "quiz2"
## [7] "quiz3" "quiz4" "hw_completion_record"sapply(originalGrade[,-1], unique)## $mid_exem
## [1] 60 28 40 56 48 68 32 16 76 52 64 44 20 36 72 24 12
##
## $final_exem
## [1] 90 92 76 88 84 80 82 78 68 72 40 83 96 63 70 94 86 95 60
## [20] 54 46 79 73 87 62 100 34 75 57 74
##
## $final_report
## [1] 4 5 3
##
## $quiz1
## [1] 76 66 68 70 74 60 56 88 92 80 58 82 84 86 46 64 94 54 42
## [20] 32 28 16 4 2 50 40 30 48 26 36 24 44 994 10 34 52 20 72
##
## $quiz2
## [1] "98" "69" "81" "84" "58" "85" "75" "76" "89" "96" "94" "78"
## [13] "68" "64" "87" "67" "73" "65" "70" "88" "53" "66" "5" "59"
## [25] "60" "72" "61" "80" "26" "100" "55" "6" "63" "82" "44" "92"
## [37] "0" "NA" "21" "43" "47" "39" "29" "4" "54" "93" "86" "52"
## [49] "33"
##
## $quiz3
## [1] 98 94 90 100 68 74 50 84 44 82
## [11] 72 96 26 36 20 42 78 86 76 54
## [21] 66 99382 52 87 99380 64 99390 80 99384 993100
## [31] 34 62 99394 48 99392 99398 46 10 88 30
## [41] 92 994
##
## $quiz4
## [1] 88 98 100 90 91 96 94 994 993100 86
## [11] 78 76 69 92 53 84 99392 65 74 72
## [21] 67 75 58 82 56 68 80
##
## $hw_completion_record
## [1] 60 59 58 55 56 53 57 49 44 48 45 54 50 52 37 36 47 43 42看過R給的檢查報表,發現有兩種「遺漏值」或是「缺失值」的代號:
- 「
"NA"」、 - 分數超過「100」的都代表「遺漏值」。
19.8.3 清理遺漏值
originalGrade <- as.data.frame(originalGrade, stringsAsFactors = FALSE)
originalGrade[which(originalGrade == "NA", arr.ind = TRUE)] <- NA
originalGrade$quiz2 <- as.numeric(originalGrade$quiz2)
originalGrade[which(originalGrade > 100, arr.ind = TRUE)] <- NA
DT::datatable(originalGrade[,-1],
options = list(scrollX = TRUE,
fixedColumns = TRUE))19.8.4 次數分配表
sapply(originalGrade[,-1], table)## $mid_exem
##
## 12 16 20 24 28 32 36 40 44 48 52 56 60 64 68 72 76
## 1 1 2 3 6 8 5 10 8 13 5 8 6 3 2 2 2
##
## $final_exem
##
## 34 40 46 54 57 60 62 63 68 70 72 73 74 75 76 78 79 80 82 83
## 1 1 2 1 1 4 1 1 3 2 5 1 1 2 3 3 2 6 5 2
## 84 86 87 88 90 92 94 95 96 100
## 8 3 3 7 2 8 3 1 2 1
##
## $final_report
##
## 3 4 5
## 38 23 24
##
## $quiz1
##
## 2 4 10 16 20 24 26 28 30 32 34 36 40 42 44 46 48 50 52 54 56 58 60 64 66 68
## 2 1 1 1 1 1 1 1 1 1 1 2 3 3 3 2 1 1 2 4 4 3 2 7 3 2
## 70 72 74 76 80 82 84 86 88 92 94
## 2 1 6 4 2 1 4 3 1 2 3
##
## $quiz2
##
## 0 4 5 6 21 26 29 33 39 43 44 47 52 53 54 55 58 59 60 61
## 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 1 1 1 1
## 63 64 65 66 67 68 69 70 72 73 75 76 78 80 81 82 84 85 86 87
## 1 2 2 1 2 2 3 1 3 1 5 2 1 2 3 2 3 3 1 2
## 88 89 92 93 94 96 98 100
## 3 1 1 1 6 5 3 1
##
## $quiz3
##
## 10 20 26 30 34 36 42 44 46 48 50 52 54 62 64 66 68 72 74 76
## 2 1 1 1 1 3 1 2 1 1 2 2 1 3 4 2 4 3 4 2
## 78 80 82 84 86 87 88 90 92 94 96 98 100
## 1 1 3 4 2 1 2 4 1 2 1 4 2
##
## $quiz4
##
## 53 56 58 65 67 68 69 72 74 75 76 78 80 82 84 86 88 90 91 92
## 1 1 1 1 1 1 1 3 1 1 2 4 1 1 2 3 3 4 1 3
## 94 96 98 100
## 9 9 10 11
##
## $hw_completion_record
##
## 36 37 42 43 44 45 47 48 49 50 52 53 54 55 56 57 58 59 60
## 1 1 1 1 3 2 1 3 5 1 3 4 2 5 7 3 3 11 2819.8.5 檔案管理
如果讀者諸君
不想「每一次」需要「原始學期總成績」,就要執行「上述諸多程式碼一次」!
那就要「啟動『檔案管理』機制」。
saveRDS(originalGrade, "output/data/originalGrade.rds")往後,只要「需要」就「讀回來」:
originalGrade <- readRDS("output/data/originalGrade.rds")
DT::datatable(originalGrade[,-1],
options = list(scrollX = TRUE,
fixedColumns = TRUE))一模一樣!
…
19.8.6 原始學期總成績相關性分析
cor(originalGrade[,-1])## mid_exem final_exem final_report quiz1 quiz2 quiz3
## mid_exem 1.00000000 0.33465773 -0.04454324 NA NA NA
## final_exem 0.33465773 1.00000000 0.08651101 NA NA NA
## final_report -0.04454324 0.08651101 1.00000000 NA NA NA
## quiz1 NA NA NA 1 NA NA
## quiz2 NA NA NA NA 1 NA
## quiz3 NA NA NA NA NA 1
## quiz4 NA NA NA NA NA NA
## hw_completion_record -0.06248221 0.07351269 0.15583012 NA NA NA
## quiz4 hw_completion_record
## mid_exem NA -0.06248221
## final_exem NA 0.07351269
## final_report NA 0.15583012
## quiz1 NA NA
## quiz2 NA NA
## quiz3 NA NA
## quiz4 1 NA
## hw_completion_record NA 1.00000000VoriginalGrade <- var(originalGrade[,-1], na.rm = TRUE)
cov2cor(VoriginalGrade)## mid_exem final_exem final_report quiz1 quiz2
## mid_exem 1.00000000 0.36307971 -0.12138705 0.36166880 0.46726890
## final_exem 0.36307971 1.00000000 0.05530651 0.37537002 0.45848262
## final_report -0.12138705 0.05530651 1.00000000 0.05854508 -0.04119399
## quiz1 0.36166880 0.37537002 0.05854508 1.00000000 0.48824369
## quiz2 0.46726890 0.45848262 -0.04119399 0.48824369 1.00000000
## quiz3 0.43008503 0.50210330 0.27594769 0.39908699 0.46353334
## quiz4 0.33598611 0.45465424 0.06330442 0.52857250 0.51873918
## hw_completion_record -0.09718835 0.07934673 0.09093482 0.24668700 0.13670552
## quiz3 quiz4 hw_completion_record
## mid_exem 0.4300850 0.33598611 -0.09718835
## final_exem 0.5021033 0.45465424 0.07934673
## final_report 0.2759477 0.06330442 0.09093482
## quiz1 0.3990870 0.52857250 0.24668700
## quiz2 0.4635333 0.51873918 0.13670552
## quiz3 1.0000000 0.53629155 0.13786028
## quiz4 0.5362916 1.00000000 0.22349876
## hw_completion_record 0.1378603 0.22349876 1.00000000round(cov2cor(VoriginalGrade), 2)## mid_exem final_exem final_report quiz1 quiz2 quiz3 quiz4
## mid_exem 1.00 0.36 -0.12 0.36 0.47 0.43 0.34
## final_exem 0.36 1.00 0.06 0.38 0.46 0.50 0.45
## final_report -0.12 0.06 1.00 0.06 -0.04 0.28 0.06
## quiz1 0.36 0.38 0.06 1.00 0.49 0.40 0.53
## quiz2 0.47 0.46 -0.04 0.49 1.00 0.46 0.52
## quiz3 0.43 0.50 0.28 0.40 0.46 1.00 0.54
## quiz4 0.34 0.45 0.06 0.53 0.52 0.54 1.00
## hw_completion_record -0.10 0.08 0.09 0.25 0.14 0.14 0.22
## hw_completion_record
## mid_exem -0.10
## final_exem 0.08
## final_report 0.09
## quiz1 0.25
## quiz2 0.14
## quiz3 0.14
## quiz4 0.22
## hw_completion_record 1.00或是繪製「相關係數圖」,
library(corrplot)
corrplot(cov2cor(VoriginalGrade), type = "lower")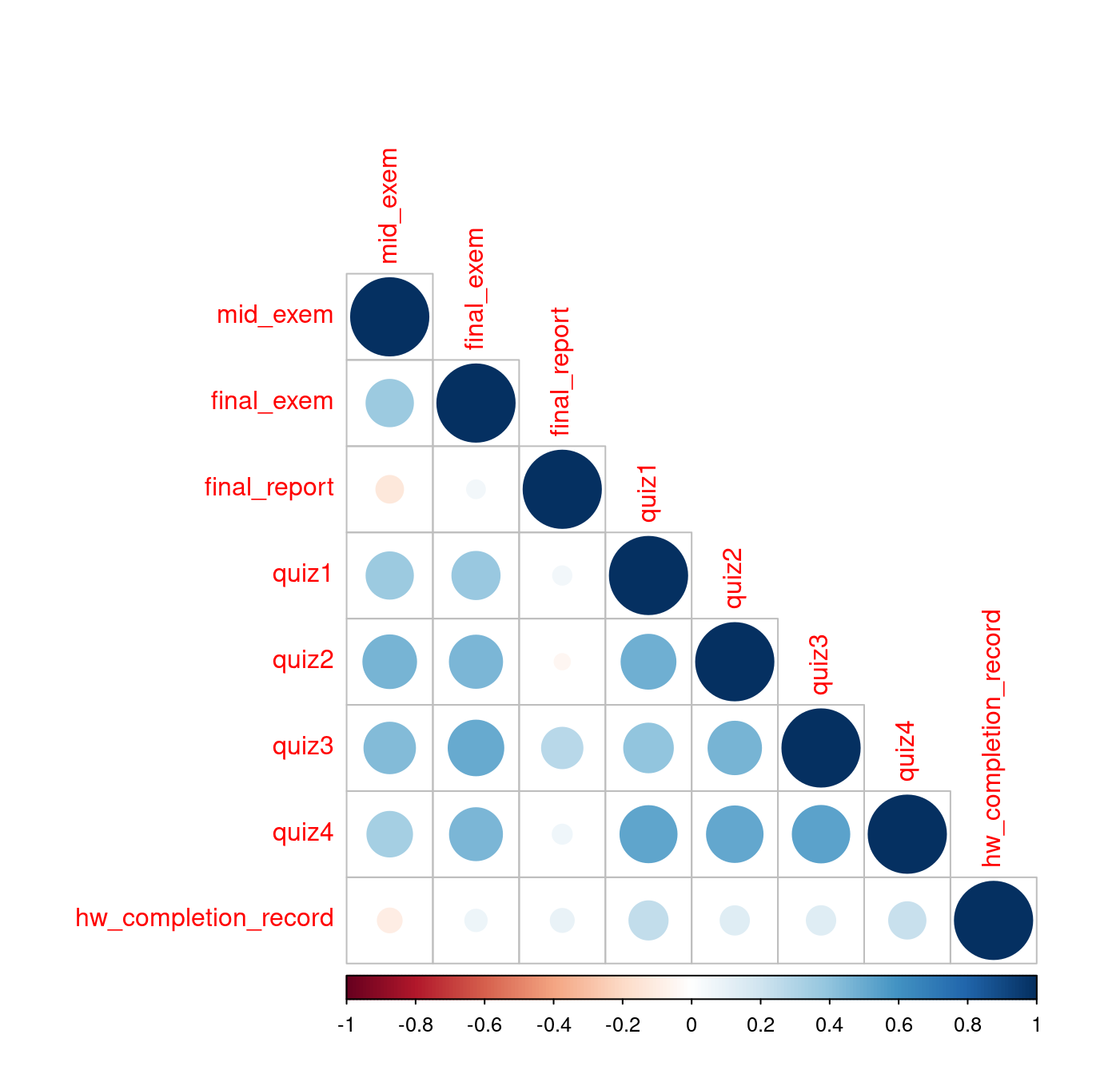
19.9 學期總成績
19.9.1 學期總成績編碼簿
codeBookInsurance <- readRDS("data/codeBookInsurance.rds")
SemGradecodes <- codeBookInsurance[grep("grade",codeBookInsurance$source),]
SemGradecodes <- SemGradecodes[grep("grade", SemGradecodes$question),]
ForNow <- c("source", "question", "meaning", "備註", "choices", "codes")
DT::datatable(SemGradecodes[,ForNow],
options = list(scrollX = TRUE,
fixedColumns = TRUE))讓我們試著解讀「這一小本編碼簿」:
- 欄位「source」,紀錄各個考核項目得分的檔案名稱。
- 欄位「question」,紀錄各個考核項目得分的欄位名稱。
- 欄位「meaning」,紀錄各個考核項目得分的欄位意義。
- 欄位「備註」,紀錄各個考核項目得分的遺漏值備註。
- 欄位「choices」,紀錄各個考核項目得分的最高得分。
- 欄位「codes」,紀錄各個考核項目得分的最高得分,也就是指出我們可能「收到」的符號。
19.9.2 準備數據:學期總成績
有了上述這一張表之後,讓我們啟動R的基本檢查
class(semesterGrade)## [1] "tbl_df" "tbl" "data.frame"sapply(semesterGrade, class)## ID usually_grade mid_grade final_grade semester_grade
## "character" "numeric" "numeric" "numeric" "numeric"dim(semesterGrade)## [1] 85 5colnames(semesterGrade)## [1] "ID" "usually_grade" "mid_grade" "final_grade"
## [5] "semester_grade"sapply(semesterGrade[,-1], unique)## $usually_grade
## [1] 100 98 99 92 94 88 93 97 95 86 82 76 83 90 62 87 77 78 73
## [20] 72 70 91
##
## $mid_grade
## [1] 65 36 47 62 54 66 64 41 68 55 29 80 59 50 56 46 53 58 67 37 25 22 51 33 45
## [26] 39 40 38 44 52 76 72 43 60 30 57 48 35 42 12 34 32 49 79 61
##
## $final_grade
## [1] 90 93 81 92 83 88 85 76 72 82 80 61 39 84 86 63 91 75 77
## [20] 95 71 87 60 89 66 47 79 73 55 56 78 100 59 37 67 46 74 70
##
## $semester_grade
## [1] 86 78 77 85 83 81 76 69 79 73 87 56 80 82 71 75 72 70 65 68 64 63 61 84 67
## [26] 57 66 93 60 74 53看過R給的檢查報表,發現一切正常。
無需啟動清理遺漏值的程式碼。
19.9.3 次數分配表
sapply(semesterGrade[,-1], table)## $usually_grade
##
## 62 70 72 73 76 77 78 82 83 86 87 88 90 91 92 93 94 95 97 98
## 2 1 1 1 2 1 1 5 4 1 2 3 2 1 5 5 2 3 2 11
## 99 100
## 1 29
##
## $mid_grade
##
## 12 22 25 29 30 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52
## 1 2 1 5 1 1 1 1 1 1 3 1 3 2 3 1 2 1 3 4 3 2 1 2 4 2
## 53 54 55 56 57 58 59 60 61 62 64 65 66 67 68 72 76 79 80
## 1 2 5 1 1 2 1 1 1 3 5 2 2 1 1 1 1 1 1
##
## $final_grade
##
## 37 39 46 47 55 56 59 60 61 63 66 67 70 71 72 73 74 75 76 77
## 1 1 1 1 1 1 1 3 2 2 2 1 1 1 3 3 1 4 1 3
## 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 95 100
## 2 2 5 5 2 9 1 4 3 3 3 1 3 3 1 2 1 1
##
## $semester_grade
##
## 53 56 57 60 61 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83
## 1 2 1 2 2 1 3 2 3 2 2 2 3 2 7 6 1 4 4 6 2 3 3 5 1 5
## 84 85 86 87 93
## 1 4 3 1 119.9.4 檔案管理
如果讀者諸君
不想「每一次」需要「學期總成績」,就要執行「上述諸多程式碼一次」!
那就要「啟動『檔案管理』機制」。
saveRDS(semesterGrade, "output/data/semesterGrade.rds")往後,只要「需要」就「讀回來」:
semesterGrade <- readRDS("output/data/semesterGrade.rds")
DT::datatable(semesterGrade[,-1],
options = list(scrollX = TRUE,
fixedColumns = TRUE))一模一樣!
…
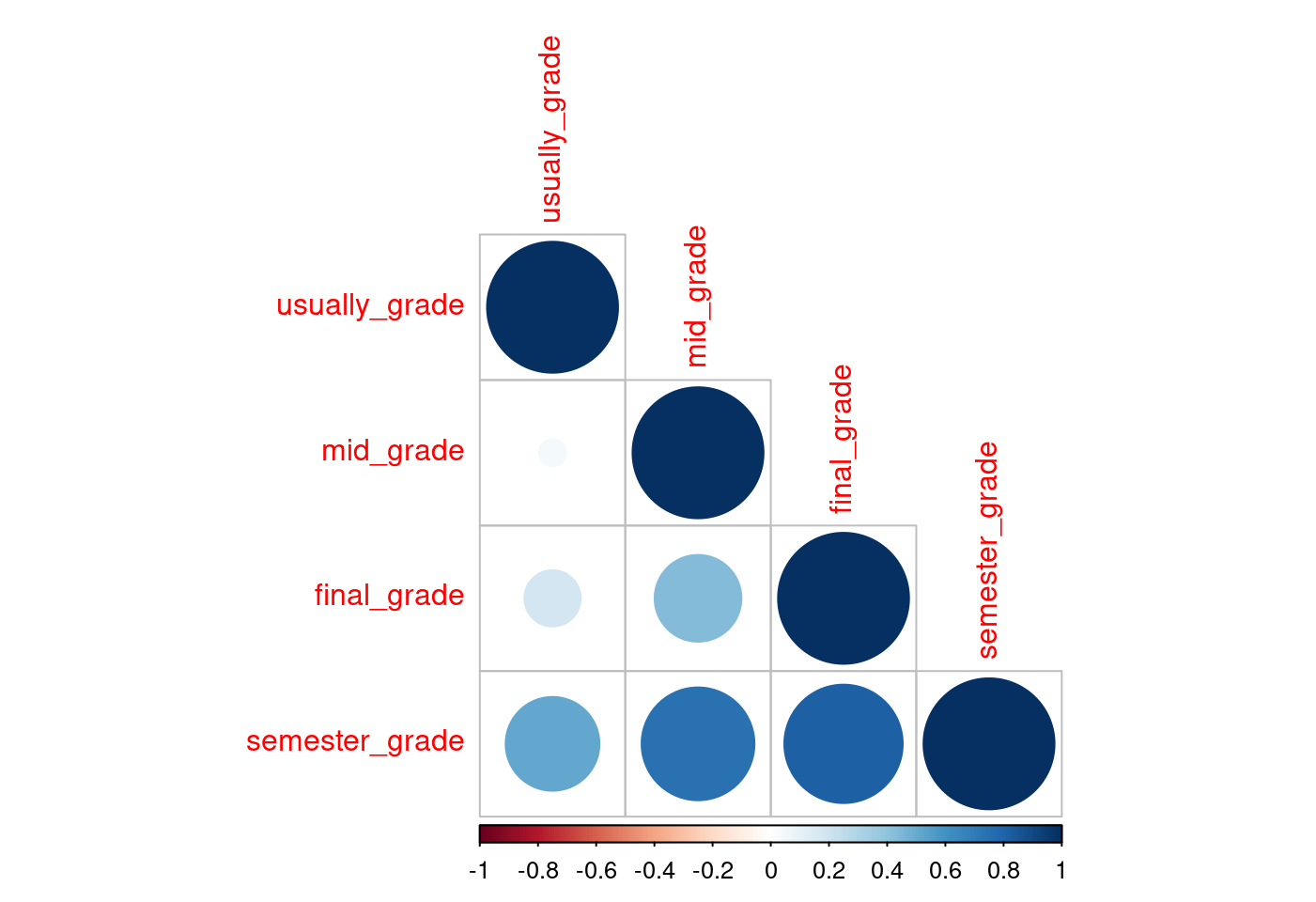
19.9.5 學期總成績相關性分析
cor(semesterGrade[,-1])## usually_grade mid_grade final_grade semester_grade
## usually_grade 1.00000000 0.04410822 0.1850170 0.5131391
## mid_grade 0.04410822 1.00000000 0.4393461 0.7418845
## final_grade 0.18501704 0.43934606 1.0000000 0.8168738
## semester_grade 0.51313909 0.74188454 0.8168738 1.0000000或是繪製「相關係數圖」,
library(corrplot)
corrplot(cor(semesterGrade[,-1]), type = "lower")