Chapter 6 數據的家談一張資料框在R的零零總總
6.1 什麼是資料框?
這是一張最典型的資料框:
library(datasets)
data("iris")
head(iris)## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3.0 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5.0 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa6.1.1 這張資料框的某幾個數字
iris[[1]][1]## [1] 5.1iris[[2]][1]## [1] 3.5iris[[3]][1]## [1] 1.4iris[[4]][1]## [1] 0.26.1.2 這張資料框的某幾個文字
iris[[5]][1]## [1] setosa
## Levels: setosa versicolor virginicairis[[5]][51]## [1] versicolor
## Levels: setosa versicolor virginicairis[[5]][101]## [1] virginica
## Levels: setosa versicolor virginica6.1.3 這張資料框的變數
colnames(iris)## [1] "Sepal.Length" "Sepal.Width" "Petal.Length" "Petal.Width" "Species"6.1.4 這張資料框的某幾個個體、編號
rownames(iris)[1:3]## [1] "1" "2" "3"上述畫面出現了各種「單量」,數字的、文字的、名目文字的。一張資料框(data.frame)總承了
- 個別數據(單數)的單量。可能是「數字的」、「文字的」、「名目文字的(
factor)」、「順序文字的(ordered factor)」、「邏輯的」。
iris["1","Sepal.Length"] # 第一朵花「Sepal」的「長度」(變數)## [1] 5.1iris["1","Species"] # 第一朵花的「花種」(變數)## [1] setosa
## Levels: setosa versicolor virginica- 向量。來自同一個「變數」的全部「單量」。
iris[,"Sepal.Length"] # 變數「Sepal.Length」的全部單量(測量值)## [1] 5.1 4.9 4.7 4.6 5.0 5.4 4.6 5.0 4.4 4.9 5.4 4.8 4.8 4.3 5.8 5.7 5.4 5.1
## [19] 5.7 5.1 5.4 5.1 4.6 5.1 4.8 5.0 5.0 5.2 5.2 4.7 4.8 5.4 5.2 5.5 4.9 5.0
## [37] 5.5 4.9 4.4 5.1 5.0 4.5 4.4 5.0 5.1 4.8 5.1 4.6 5.3 5.0 7.0 6.4 6.9 5.5
## [55] 6.5 5.7 6.3 4.9 6.6 5.2 5.0 5.9 6.0 6.1 5.6 6.7 5.6 5.8 6.2 5.6 5.9 6.1
## [73] 6.3 6.1 6.4 6.6 6.8 6.7 6.0 5.7 5.5 5.5 5.8 6.0 5.4 6.0 6.7 6.3 5.6 5.5
## [91] 5.5 6.1 5.8 5.0 5.6 5.7 5.7 6.2 5.1 5.7 6.3 5.8 7.1 6.3 6.5 7.6 4.9 7.3
## [109] 6.7 7.2 6.5 6.4 6.8 5.7 5.8 6.4 6.5 7.7 7.7 6.0 6.9 5.6 7.7 6.3 6.7 7.2
## [127] 6.2 6.1 6.4 7.2 7.4 7.9 6.4 6.3 6.1 7.7 6.3 6.4 6.0 6.9 6.7 6.9 5.8 6.8
## [145] 6.7 6.7 6.3 6.5 6.2 5.9- 資料框。來自同一個「個體」的觀察值。
iris["1",] # 第一朵花(編號"1")的觀察值## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 1 5.1 3.5 1.4 0.2 setosa6.2 單量
作者小編已經談過「數字」、「文字」、「邏輯」。那時候,我們並不強調到底「字裡行間」是
- 一個數字,還是,多個數字?
- 一個文字,還是,多個文字?
- 一個邏輯,還是,多個邏輯?
- 數字跟文字可以在一起嗎?
- 數字跟邏輯可以在一起嗎?
- 文字跟邏輯可以在一起嗎?
這一小本,微微書,「單量」,作者小編希望再一次介紹怎麼寫:
- 一個整數、
- 一個實數、
- 一個實數的正方根、
- 一個複數、
- 一個英文字、
- 一個中文字、
- 一個英文字串、
- 一個中文字串、
- 一個特殊符號、
- 一個邏輯、
有了「零維的單量」,就可以邁向「一維的向量」跟「二維的資料框」了。
6.2.1 數字類的單量
0L # 整數0## [1] 01L # 正整數## [1] 1-1L # 負整數## [1] -10 # 實數0## [1] 01 # 實數1## [1] 1-1 # 實數-1## [1] -10.123 # 有限位數小數的正實數## [1] 0.123-0.123 # 有限位數小數的負實數## [1] -0.123sqrt(2) # 無理數的實數## [1] 1.414214pi # 知名無理數的實數## [1] 3.1415931+1i # 複數## [1] 1+1i6.3 向量
6.3.1 什麼是向量?
基本上,向量是一串同樣都是數字或都是文字在一起的物件。向量是一種資料結構。
為了示範各種向量相關的動作,作者決定「超前部署」,把準備好的示範案例放在「譜(list)」裡面,因為各個示範向量的長度都不一樣。「譜」是R裡唯一一個可以存放各式各樣長度、形狀的資料結構。把它們放在某一個「譜」裡面,事實上就像程式設計師在整個軟體工程專案裡,設計某個讓設計師更有效撰寫程式的資料結構一模一樣。
6.3.3 檢查到底是哪一種向量?
6.3.3.1 檢查是不是整數向量?
class(integer(2))## [1] "integer"typeof(integer(2))## [1] "integer"is.integer(integer(2))## [1] TRUEis.vector(integer(2))## [1] TRUE6.3.3.2 檢查是不是實數向量?
class(numeric(2))## [1] "numeric"typeof(numeric(2))## [1] "double"is.numeric(numeric(2))## [1] TRUEis.vector(numeric(2))## [1] TRUE6.3.3.3 檢查是不是複數向量?
class(complex(2))## [1] "complex"typeof(complex(2))## [1] "complex"is.complex(complex(2))## [1] TRUEis.vector(complex(2))## [1] TRUE6.3.5 向量的四則運算
6.3.5.1 整數向量的四則運算
- 確認
0:9確實是整數
is.integer(0:9)## [1] TRUE- 整數的加法
0:9 + 9:0## [1] 9 9 9 9 9 9 9 9 9 9- 整數的減法
0:9 - 9:0## [1] -9 -7 -5 -3 -1 1 3 5 7 9- 整數的乘法
0:9 * 9:0## [1] 0 8 14 18 20 20 18 14 8 0- 整數的除法
0:9 / 9:0## [1] 0.0000000 0.1250000 0.2857143 0.5000000 0.8000000 1.2500000 2.0000000
## [8] 3.5000000 8.0000000 Inf6.3.5.2 實數向量的四則運算
- 確認
seq(0,1,0.1)確實是實數
is.numeric(seq(0,1,0.1))## [1] TRUE- 實數的加法
seq(0,1,0.1) + seq(1,0,-0.1)## [1] 1 1 1 1 1 1 1 1 1 1 1- 實數的減法
seq(0,1,0.1) - seq(1,0,-0.1)## [1] -1.0 -0.8 -0.6 -0.4 -0.2 0.0 0.2 0.4 0.6 0.8 1.0- 實數的乘法
seq(0,1,0.1) * seq(1,0,-0.1)## [1] 0.00 0.09 0.16 0.21 0.24 0.25 0.24 0.21 0.16 0.09 0.00- 實數的除法
seq(0,1,0.1) / seq(1,0,-0.1)## [1] 0.0000000 0.1111111 0.2500000 0.4285714 0.6666667 1.0000000 1.5000000
## [8] 2.3333333 4.0000000 9.0000000 Inf6.4 factor
6.4.2 準備factor
6.4.2.1 變身為標籤的文字 = 名目文字 = 名目尺度數據
x <- factor(letters, levels = letters)
x## [1] a b c d e f g h i j k l m n o p q r s t u v w x y z
## Levels: a b c d e f g h i j k l m n o p q r s t u v w x y z6.4.2.2 變身為順序有別的文字 = 順序文字 = 順序尺度數據
x <- factor(letters, levels = letters, ordered = TRUE)
x## [1] a b c d e f g h i j k l m n o p q r s t u v w x y z
## 26 Levels: a < b < c < d < e < f < g < h < i < j < k < l < m < n < o < ... < z6.4.2.3 再一次變身為順序有別的文字 = 順序文字 = 順序尺度數據
x <- factor(letters, levels = rev(letters), ordered = TRUE)
x## [1] a b c d e f g h i j k l m n o p q r s t u v w x y z
## 26 Levels: z < y < x < w < v < u < t < s < r < q < p < o < n < m < l < ... < a6.4.3 levels
factor(letters, levels = letters[1:3])## [1] a b c <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
## [16] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
## Levels: a b clevels(factor(letters, levels = letters[1:3]))## [1] "a" "b" "c"nlevels(factor(letters, levels = letters[1:3]))## [1] 3length(factor(letters, levels = letters[1:3]))## [1] 26is.na(factor(letters, levels = letters[1:3]))## [1] FALSE FALSE FALSE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
## [13] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
## [25] TRUE TRUEsum(is.na(factor(letters, levels = letters[1:3])))## [1] 23sum(!is.na(factor(letters, levels = letters[1:3])))## [1] 3x <- factor(letters, levels = letters[1:3])
x## [1] a b c <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
## [16] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
## Levels: a b clevels(x)## [1] "a" "b" "c"levels(x) <- c(levels(x), "d")
x## [1] a b c <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
## [16] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
## Levels: a b c dx[4] <- "d"
x## [1] a b c d <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
## [16] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
## Levels: a b c d6.4.3.1 順序真的存在於R嗎?
food <- factor(c("low", "high", "medium", "high", "low", "medium", "high"))
levels(food)## [1] "high" "low" "medium"food <- factor(food, levels = c("low", "medium", "high"))
levels(food)## [1] "low" "medium" "high"min(food)## Error in Summary.factor(structure(c(1L, 3L, 2L, 3L, 1L, 2L, 3L), levels = c("low", : 'min' 對因子沒有意義food <- factor(food, levels = c("low", "medium", "high"), ordered = TRUE)
levels(food)## [1] "low" "medium" "high"min(food)## [1] low
## Levels: low < medium < highmax(food)## [1] high
## Levels: low < medium < high6.4.4 強迫變成factor
6.4.4.1 強迫factor回復到一般文字
letters## [1] "a" "b" "c" "d" "e" "f" "g" "h" "i" "j" "k" "l" "m" "n" "o" "p" "q" "r" "s"
## [20] "t" "u" "v" "w" "x" "y" "z"factor(letters, levels = letters[1:3])## [1] a b c <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
## [16] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
## Levels: a b cas.character(factor(letters, levels = letters[1:3]))## [1] "a" "b" "c" NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA
## [20] NA NA NA NA NA NA NAletters <- as.character(factor(letters, levels = letters[1:3]))
letters## [1] "a" "b" "c" NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA
## [20] NA NA NA NA NA NA NAletters <- tolower(LETTERS)
letters## [1] "a" "b" "c" "d" "e" "f" "g" "h" "i" "j" "k" "l" "m" "n" "o" "p" "q" "r" "s"
## [20] "t" "u" "v" "w" "x" "y" "z"6.4.4.2 把文字變成factor
letters## [1] "a" "b" "c" "d" "e" "f" "g" "h" "i" "j" "k" "l" "m" "n" "o" "p" "q" "r" "s"
## [20] "t" "u" "v" "w" "x" "y" "z"factor(letters)## [1] a b c d e f g h i j k l m n o p q r s t u v w x y z
## Levels: a b c d e f g h i j k l m n o p q r s t u v w x y zas.factor(letters)## [1] a b c d e f g h i j k l m n o p q r s t u v w x y z
## Levels: a b c d e f g h i j k l m n o p q r s t u v w x y z6.4.4.3 把整數變成factor
0:9## [1] 0 1 2 3 4 5 6 7 8 9factor(0:9)## [1] 0 1 2 3 4 5 6 7 8 9
## Levels: 0 1 2 3 4 5 6 7 8 9factor(0:9, levels = 0:9, ordered = TRUE)## [1] 0 1 2 3 4 5 6 7 8 9
## Levels: 0 < 1 < 2 < 3 < 4 < 5 < 6 < 7 < 8 < 96.4.4.4 把實數變成factor
seq(0,1,0.1)## [1] 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0factor(seq(0,1,0.1))## [1] 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
## Levels: 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1factor(seq(0,1,0.1), levels = seq(0,1,0.1), ordered = TRUE)## [1] 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
## Levels: 0 < 0.1 < 0.2 < 0.3 < 0.4 < 0.5 < 0.6 < 0.7 < 0.8 < 0.9 < 16.5 資料框
「表格(中文翻譯不夠好!)」兩字在這一本書被稱為「資料框」。
如果看倌還沒看過「向量」,請前進向量,因為各式各樣的「向量」可以組裝出任何「資料框」。傳統統計學的術語,稱呼每一個向量是「變數(variable)」,因為每一個向量都有特殊意義。如果統計學只分析一個「向量(vector)」組成寬度為「1」的「資料框(data.frame)」的各種問題叫做「單變量分析」;如果「變數」增加了,從一個變成兩個、變成三個、甚至更多個,「單變量分析」變成「多變量分析」。現實世界都是多變量的世界,因此掌握「資料框」的零零總總R技術是非常關鍵的活動與練習。請讀者諸君一定要「刻意練習」。
…
6.5.1 準備一張資料框
6.5.2 檢查一張資料框
6.5.2.1 檢查整張資料框
class(DF)## [1] "data.frame"typeof(DF)## [1] "list"is.data.frame(DF)## [1] TRUE6.5.2.3 回復欄位屬性到製資料框之向量的屬性
n## [1] 2 3 5class(n)## [1] "numeric"s## [1] "aa" "bb" "cc"class(s)## [1] "character"b## [1] TRUE FALSE TRUEclass(b)## [1] "logical"DF <- data.frame(訪員編號 = n,
訪員姓名 = s,
逢甲學生 = b,
stringsAsFactors = FALSE)
DF## 訪員編號 訪員姓名 逢甲學生
## 1 2 aa TRUE
## 2 3 bb FALSE
## 3 5 cc TRUEsapply(DF, class)## 訪員編號 訪員姓名 逢甲學生
## "numeric" "character" "logical"6.5.3 長大一張資料框
6.5.3.1 新增一名訪員:rbind
df <- data.frame(訪員編號 = 7, 訪員姓名 = "dd", 逢甲學生 = FALSE)
DF <- rbind(DF, df)
DF## 訪員編號 訪員姓名 逢甲學生
## 1 2 aa TRUE
## 2 3 bb FALSE
## 3 5 cc TRUE
## 4 7 dd FALSE6.5.3.3 新增一個欄位:cbind
`科系` <- c("電子系", "統計系", "中文系", "企管系")
DF <- cbind(DF, `科系`)
DF## 訪員編號 訪員姓名 逢甲學生 科系
## 1 2 aa TRUE 電子系
## 2 3 bb FALSE 統計系
## 3 5 cc TRUE 中文系
## 4 7 dd FALSE 企管系6.5.3.4 屬性走掉了嗎?
class(`科系`)## [1] "character"sapply(DF, class)## 訪員編號 訪員姓名 逢甲學生 科系
## "numeric" "character" "logical" "character"6.5.4 抓取一張資料框
6.5.4.1 前頭部分
head(DF)## 訪員編號 訪員姓名 逢甲學生 科系
## 1 2 aa TRUE 電子系
## 2 3 bb FALSE 統計系
## 3 5 cc TRUE 中文系
## 4 7 dd FALSE 企管系head(DF, 1)## 訪員編號 訪員姓名 逢甲學生 科系
## 1 2 aa TRUE 電子系head(DF, 2)## 訪員編號 訪員姓名 逢甲學生 科系
## 1 2 aa TRUE 電子系
## 2 3 bb FALSE 統計系head(DF, 3)## 訪員編號 訪員姓名 逢甲學生 科系
## 1 2 aa TRUE 電子系
## 2 3 bb FALSE 統計系
## 3 5 cc TRUE 中文系6.5.4.2 尾巴部分
tail(DF)## 訪員編號 訪員姓名 逢甲學生 科系
## 1 2 aa TRUE 電子系
## 2 3 bb FALSE 統計系
## 3 5 cc TRUE 中文系
## 4 7 dd FALSE 企管系tail(DF, 1)## 訪員編號 訪員姓名 逢甲學生 科系
## 4 7 dd FALSE 企管系tail(DF, 2)## 訪員編號 訪員姓名 逢甲學生 科系
## 3 5 cc TRUE 中文系
## 4 7 dd FALSE 企管系tail(DF, 3)## 訪員編號 訪員姓名 逢甲學生 科系
## 2 3 bb FALSE 統計系
## 3 5 cc TRUE 中文系
## 4 7 dd FALSE 企管系6.5.4.4 取出數個欄位
DF[1:2]## 訪員編號 訪員姓名
## 1 2 aa
## 2 3 bb
## 3 5 cc
## 4 7 ddDF[c("訪員編號", "訪員姓名")]## 訪員編號 訪員姓名
## 1 2 aa
## 2 3 bb
## 3 5 cc
## 4 7 dd6.5.4.5 取出觀察值
6.5.4.5.1 用整數抓
DF[1,]## 訪員編號 訪員姓名 逢甲學生 科系
## 1 2 aa TRUE 電子系DF[1:2,]## 訪員編號 訪員姓名 逢甲學生 科系
## 1 2 aa TRUE 電子系
## 2 3 bb FALSE 統計系DF[c(1,2),]## 訪員編號 訪員姓名 逢甲學生 科系
## 1 2 aa TRUE 電子系
## 2 3 bb FALSE 統計系DF[c(1,3),]## 訪員編號 訪員姓名 逢甲學生 科系
## 1 2 aa TRUE 電子系
## 3 5 cc TRUE 中文系6.5.4.5.2 用名字抓
DF["1",]## 訪員編號 訪員姓名 逢甲學生 科系
## 1 2 aa TRUE 電子系DF[c("1","2"),]## 訪員編號 訪員姓名 逢甲學生 科系
## 1 2 aa TRUE 電子系
## 2 3 bb FALSE 統計系DF[c("1","3"),]## 訪員編號 訪員姓名 逢甲學生 科系
## 1 2 aa TRUE 電子系
## 3 5 cc TRUE 中文系6.5.4.5.3 用條件式抓
DF[DF$`逢甲學生`,]## 訪員編號 訪員姓名 逢甲學生 科系
## 1 2 aa TRUE 電子系
## 3 5 cc TRUE 中文系DF[!DF$`逢甲學生`,]## 訪員編號 訪員姓名 逢甲學生 科系
## 2 3 bb FALSE 統計系
## 4 7 dd FALSE 企管系DF[DF$`科系` == "中文系",]## 訪員編號 訪員姓名 逢甲學生 科系
## 3 5 cc TRUE 中文系DF[!DF$`逢甲學生` & DF$`科系` == "企管系",]## 訪員編號 訪員姓名 逢甲學生 科系
## 4 7 dd FALSE 企管系6.5.5 重排一張資料框
6.5.5.1 重排觀察值
DF[order(DF$`逢甲學生`),]## 訪員編號 訪員姓名 逢甲學生 科系
## 2 3 bb FALSE 統計系
## 4 7 dd FALSE 企管系
## 1 2 aa TRUE 電子系
## 3 5 cc TRUE 中文系DF[order(DF$`逢甲學生`, decreasing = TRUE),]## 訪員編號 訪員姓名 逢甲學生 科系
## 1 2 aa TRUE 電子系
## 3 5 cc TRUE 中文系
## 2 3 bb FALSE 統計系
## 4 7 dd FALSE 企管系6.5.5.2 重排欄位
DF <- DF[,c("訪員編號","訪員姓名","科系","逢甲學生")]
DF## 訪員編號 訪員姓名 科系 逢甲學生
## 1 2 aa 電子系 TRUE
## 2 3 bb 統計系 FALSE
## 3 5 cc 中文系 TRUE
## 4 7 dd 企管系 FALSEDF[order(DF$`逢甲學生`),]## 訪員編號 訪員姓名 科系 逢甲學生
## 2 3 bb 統計系 FALSE
## 4 7 dd 企管系 FALSE
## 1 2 aa 電子系 TRUE
## 3 5 cc 中文系 TRUEDF[order(DF$`逢甲學生`, decreasing = TRUE),]## 訪員編號 訪員姓名 科系 逢甲學生
## 1 2 aa 電子系 TRUE
## 3 5 cc 中文系 TRUE
## 2 3 bb 統計系 FALSE
## 4 7 dd 企管系 FALSE6.5.6 回顧
6.5.6.1 再看一次設定空白資料框
DF <- data.frame(C1 = numeric(0),
C2 = character(0),
C3 = logical(0))
sapply(DF, class)## C1 C2 C3
## "numeric" "character" "logical"DF <- data.frame(C1 = numeric(0),
C2 = character(0),
C3 = logical(0),
stringsAsFactors = FALSE)
sapply(DF, class)## C1 C2 C3
## "numeric" "character" "logical"6.5.6.2 再看一次製作一張資料框
n <- c(2, 3, 5)
s <- c("aa", "bb", "cc")
b <- c(TRUE, FALSE, TRUE)
DF <- data.frame(訪員編號 = n, stringsAsFactors = FALSE)
DF$`訪員姓名` <- s
DF$`逢甲學生` <- b
DF## 訪員編號 訪員姓名 逢甲學生
## 1 2 aa TRUE
## 2 3 bb FALSE
## 3 5 cc TRUEdf <- data.frame(訪員編號 = 7, 訪員姓名 = "dd", 逢甲學生 = FALSE)
DF <- rbind(DF, df)
DF## 訪員編號 訪員姓名 逢甲學生
## 1 2 aa TRUE
## 2 3 bb FALSE
## 3 5 cc TRUE
## 4 7 dd FALSE`科系` <- c("電子系", "統計系", "中文系", "企管系")
DF$`科系` <- `科系`
DF$`戶籍地` <- c("台北市", "台中市", "嘉義縣", "高雄市")
DF## 訪員編號 訪員姓名 逢甲學生 科系 戶籍地
## 1 2 aa TRUE 電子系 台北市
## 2 3 bb FALSE 統計系 台中市
## 3 5 cc TRUE 中文系 嘉義縣
## 4 7 dd FALSE 企管系 高雄市DF <- DF[order(DF$`逢甲學生`, decreasing = TRUE),c("訪員編號","訪員姓名","科系","逢甲學生")]
rownames(DF) <- 1:dim(DF)[1]
DF## 訪員編號 訪員姓名 科系 逢甲學生
## 1 2 aa 電子系 TRUE
## 2 5 cc 中文系 TRUE
## 3 3 bb 統計系 FALSE
## 4 7 dd 企管系 FALSEsapply(DF, class)## 訪員編號 訪員姓名 科系 逢甲學生
## "numeric" "character" "character" "logical"6.6 如果不想要一次一個範例,…
6.6.1 準備示範例子與範例程式碼需要的資料結構
6.6.1.1 第一個:放置示範例子的譜
- 先準備一個空的「譜(
list)」
EXs <- list()- 把各個向量放入「譜(
list)」裡
EXs[[1]] <- 0
EXs[[2]] <- 0:9
EXs[[3]] <- seq(0L,9L,1L)
EXs[[4]] <- seq(0,9,1)
EXs[[5]] <- seq(0,1,0.1)
EXs[[6]] <- "a"
EXs[[7]] <- c("a", "b")
EXs[[8]] <- c("a", "b", "c")
EXs[[9]] <- c(TRUE, FALSE, TRUE)
EXs[[10]] <- factor(c("贊成", "沒意見", "不贊成"))- 呼叫「
EXs」並且檢查是否正確
EXs## [[1]]
## [1] 0
##
## [[2]]
## [1] 0 1 2 3 4 5 6 7 8 9
##
## [[3]]
## [1] 0 1 2 3 4 5 6 7 8 9
##
## [[4]]
## [1] 0 1 2 3 4 5 6 7 8 9
##
## [[5]]
## [1] 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0
##
## [[6]]
## [1] "a"
##
## [[7]]
## [1] "a" "b"
##
## [[8]]
## [1] "a" "b" "c"
##
## [[9]]
## [1] TRUE FALSE TRUE
##
## [[10]]
## [1] 贊成 沒意見 不贊成
## Levels: 不贊成 沒意見 贊成接下來
6.6.2 這是向量嗎(is.vector)?
- 執行
is.vector
for (i in 1:10) {
Results[[i]] <- is.vector(EXs[[i]])
}- 顯示執行結果
Results## [[1]]
## [1] TRUE
##
## [[2]]
## [1] TRUE
##
## [[3]]
## [1] TRUE
##
## [[4]]
## [1] TRUE
##
## [[5]]
## [1] TRUE
##
## [[6]]
## [1] TRUE
##
## [[7]]
## [1] TRUE
##
## [[8]]
## [1] TRUE
##
## [[9]]
## [1] TRUE
##
## [[10]]
## [1] FALSE雖然同樣用「譜(
list)」,看起來「直接又了當」,但是顯示結果之後,我們會發現不必要這麼做,原因是答案、輸出檢查的結果不是「TRUE」就是「FALSE」,只有一個字,沒有長度各個不同的誘因,所以我們想重新設計「置放輸出結果的資料結構」。
6.6.3 再一次設計放置示範例子各種輸出結果的資料結構
這一次,我們也想「超前部署」,把結果放在某一張「表(data.frame)」裏。請先看以下動作的變化:
- 強迫「譜」變成「表」
as.data.frame(Results)## TRUE. TRUE..1 TRUE..2 TRUE..3 TRUE..4 TRUE..5 TRUE..6 TRUE..7 TRUE..8 FALSE.
## 1 TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE FALSE- 給這一張「表」一個名字
Report <- as.data.frame(Results, stringsAsFactors = FALSE)
colnames(Report) <- paste0("EX", 1:10) # 加欄位名稱(colnames)。
# 加列名稱(rownames),實際上作者加的是「動作名稱」,用以清楚表達「誰」擁有從左而右一整列的那些答案。
rownames(Report) <- "is.vector" - 呼叫「
Report」並且檢查是否正確
Report## EX1 EX2 EX3 EX4 EX5 EX6 EX7 EX8 EX9 EX10
## is.vector TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE FALSE作者認為這是一張可以被接受的報表。
6.6.4 繼續檢查是否為各種屬性的向量?
6.6.4.1 這是整數向量嗎?
- 執行
is.integer
for (i in 1:10) {
Results[[i]] <- is.integer(EXs[[i]])
}- 給一張中間過程的「表」置放執行結果
Report0 <- as.data.frame(Results, stringsAsFactors = FALSE)
colnames(Report0) <- paste0("EX", 1:10)
rownames(Report0) <- "is.integer"- 往下併表並且呼叫「
Report」檢查是否正確
Report <- rbind(Report, Report0)
Report## EX1 EX2 EX3 EX4 EX5 EX6 EX7 EX8 EX9 EX10
## is.vector TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE FALSE
## is.integer FALSE TRUE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE6.6.4.2 這是實數向量嗎?
同樣的動作、同樣的過程,我們把上述各個步驟的程式碼收集在一起,請讀者諸君不厭其煩繼續看下去,邊看邊回想每一句話的用意跟企圖。以下是加上執行is.numeric的新報表:
for (i in 1:10) {
Results[[i]] <- is.numeric(EXs[[i]])
}
Report0 <- as.data.frame(Results, stringsAsFactors = FALSE)
colnames(Report0) <- paste0("EX", 1:10)
rownames(Report0) <- "is.numeric"
Report <- rbind(Report, Report0)
Report## EX1 EX2 EX3 EX4 EX5 EX6 EX7 EX8 EX9 EX10
## is.vector TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE FALSE
## is.integer FALSE TRUE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## is.numeric TRUE TRUE TRUE TRUE TRUE FALSE FALSE FALSE FALSE FALSE6.6.4.3 這是文字向量嗎?
for (i in 1:10) {
Results[[i]] <- is.character(EXs[[i]])
}
Report0 <- as.data.frame(Results, stringsAsFactors = FALSE)
colnames(Report0) <- paste0("EX", 1:10)
rownames(Report0) <- "is.character"
Report <- rbind(Report, Report0)
Report## EX1 EX2 EX3 EX4 EX5 EX6 EX7 EX8 EX9 EX10
## is.vector TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE FALSE
## is.integer FALSE TRUE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## is.numeric TRUE TRUE TRUE TRUE TRUE FALSE FALSE FALSE FALSE FALSE
## is.character FALSE FALSE FALSE FALSE FALSE TRUE TRUE TRUE FALSE FALSE6.6.4.4 這是factor向量嗎?
for (i in 1:10) {
Results[[i]] <- is.factor(EXs[[i]])
}
Report0 <- as.data.frame(Results, stringsAsFactors = FALSE)
colnames(Report0) <- paste0("EX", 1:10)
rownames(Report0) <- "is.factor"
Report <- rbind(Report, Report0)
Report## EX1 EX2 EX3 EX4 EX5 EX6 EX7 EX8 EX9 EX10
## is.vector TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE FALSE
## is.integer FALSE TRUE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## is.numeric TRUE TRUE TRUE TRUE TRUE FALSE FALSE FALSE FALSE FALSE
## is.character FALSE FALSE FALSE FALSE FALSE TRUE TRUE TRUE FALSE FALSE
## is.factor FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE6.6.4.5 這是邏輯向量嗎?
for (i in 1:10) {
Results[[i]] <- is.logical(EXs[[i]])
}
Report0 <- as.data.frame(Results, stringsAsFactors = FALSE)
colnames(Report0) <- paste0("EX", 1:10)
rownames(Report0) <- "is.logical"
Report <- rbind(Report, Report0)
Report## EX1 EX2 EX3 EX4 EX5 EX6 EX7 EX8 EX9 EX10
## is.vector TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE FALSE
## is.integer FALSE TRUE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## is.numeric TRUE TRUE TRUE TRUE TRUE FALSE FALSE FALSE FALSE FALSE
## is.character FALSE FALSE FALSE FALSE FALSE TRUE TRUE TRUE FALSE FALSE
## is.factor FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE
## is.logical FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE6.6.4.6 再一次修飾報表的可讀性
一開始,我們只是把示範例子放在「譜(list)」裡面,並沒有為每一道例子取一個名字。我們先彌補這一項缺失:
EXs## [[1]]
## [1] 0
##
## [[2]]
## [1] 0 1 2 3 4 5 6 7 8 9
##
## [[3]]
## [1] 0 1 2 3 4 5 6 7 8 9
##
## [[4]]
## [1] 0 1 2 3 4 5 6 7 8 9
##
## [[5]]
## [1] 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0
##
## [[6]]
## [1] "a"
##
## [[7]]
## [1] "a" "b"
##
## [[8]]
## [1] "a" "b" "c"
##
## [[9]]
## [1] TRUE FALSE TRUE
##
## [[10]]
## [1] 贊成 沒意見 不贊成
## Levels: 不贊成 沒意見 贊成names(EXs)[1] <- paste0("EX1 = c(", '0', ")")
names(EXs)[2] <- paste0("EX2 = c(", '0:9', ")")
names(EXs)[3] <- paste0("EX3 = c(", 'seq(0L,9L,1L)', ")")
names(EXs)[4] <- paste0("EX4 = c(", 'seq(0,9,1)', ")")
names(EXs)[5] <- paste0("EX5 = c(", 'seq(0,1,0.1)', ")")
names(EXs)[6] <- paste0("EX6 = c(", '"a"', ")")
names(EXs)[7] <- paste0("EX7 = c(", '"a", "b"', ")")
names(EXs)[8] <- paste0("EX8 = c(", '"a", "b", "c"', ")")
names(EXs)[9] <- paste0("EX9 = c(", 'TRUE, FALSE, TRUE', ")")
names(EXs)[10] <- paste0("EX10 = ", 'factor(c("贊成", "沒意見", "不贊成"))')
EXs## $`EX1 = c(0)`
## [1] 0
##
## $`EX2 = c(0:9)`
## [1] 0 1 2 3 4 5 6 7 8 9
##
## $`EX3 = c(seq(0L,9L,1L))`
## [1] 0 1 2 3 4 5 6 7 8 9
##
## $`EX4 = c(seq(0,9,1))`
## [1] 0 1 2 3 4 5 6 7 8 9
##
## $`EX5 = c(seq(0,1,0.1))`
## [1] 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0
##
## $`EX6 = c("a")`
## [1] "a"
##
## $`EX7 = c("a", "b")`
## [1] "a" "b"
##
## $`EX8 = c("a", "b", "c")`
## [1] "a" "b" "c"
##
## $`EX9 = c(TRUE, FALSE, TRUE)`
## [1] TRUE FALSE TRUE
##
## $`EX10 = factor(c("贊成", "沒意見", "不贊成"))`
## [1] 贊成 沒意見 不贊成
## Levels: 不贊成 沒意見 贊成成功之後,呼叫我們設計的這兩個資料結構交互閱讀、比對,讓我們瞭解每一道例子的屬性:
Report## EX1 EX2 EX3 EX4 EX5 EX6 EX7 EX8 EX9 EX10
## is.vector TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE FALSE
## is.integer FALSE TRUE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## is.numeric TRUE TRUE TRUE TRUE TRUE FALSE FALSE FALSE FALSE FALSE
## is.character FALSE FALSE FALSE FALSE FALSE TRUE TRUE TRUE FALSE FALSE
## is.factor FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE
## is.logical FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSEEXs## $`EX1 = c(0)`
## [1] 0
##
## $`EX2 = c(0:9)`
## [1] 0 1 2 3 4 5 6 7 8 9
##
## $`EX3 = c(seq(0L,9L,1L))`
## [1] 0 1 2 3 4 5 6 7 8 9
##
## $`EX4 = c(seq(0,9,1))`
## [1] 0 1 2 3 4 5 6 7 8 9
##
## $`EX5 = c(seq(0,1,0.1))`
## [1] 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0
##
## $`EX6 = c("a")`
## [1] "a"
##
## $`EX7 = c("a", "b")`
## [1] "a" "b"
##
## $`EX8 = c("a", "b", "c")`
## [1] "a" "b" "c"
##
## $`EX9 = c(TRUE, FALSE, TRUE)`
## [1] TRUE FALSE TRUE
##
## $`EX10 = factor(c("贊成", "沒意見", "不贊成"))`
## [1] 贊成 沒意見 不贊成
## Levels: 不贊成 沒意見 贊成為了提高結果報表「Report」的可讀性,作者餵了以下這一句話給「Google搜尋引擎」:
how to use color to display a logical matrix in r
發現R有這麼一個套件,plot.matrix出現在第一項搜尋結果。點進去,往下閱讀幾行之後就發現,它可以幫忙。請看原始網頁:
knitr::include_url("https://cran.r-project.org/web/packages/plot.matrix/vignettes/plot.matrix.html")根據上述網頁的建議,作者寫了以下這一段:
請記得事前要先安裝
plot.matrix。
library(plot.matrix)
plot(Report)
這是一張美圖,雖然一下子無法理解。當然,跟上述網站示意的範例,很明顯,作者哪裏錯了!對照一下,作者的程式碼跟網站的示範碼之後,作者再試一次:
- 又再一次「超前部署」,把「表」變成「矩陣(
matrix)」,as.matrix,因為套件的名字是plot.matrix,翻譯成中文就是「畫矩陣」。只接受「矩陣(matrix)」。 - 改了顏色的預設值,從「
heat」變成「topo.colors」。 - 把放在圖右邊的「
key」拿掉。「key」主要是告訴我們哪個顏色代表「FALSE」,哪個顏色代表「TRUE」。
library(plot.matrix)
Report <- as.matrix(Report)
plot(Report, col = topo.colors, key = NULL)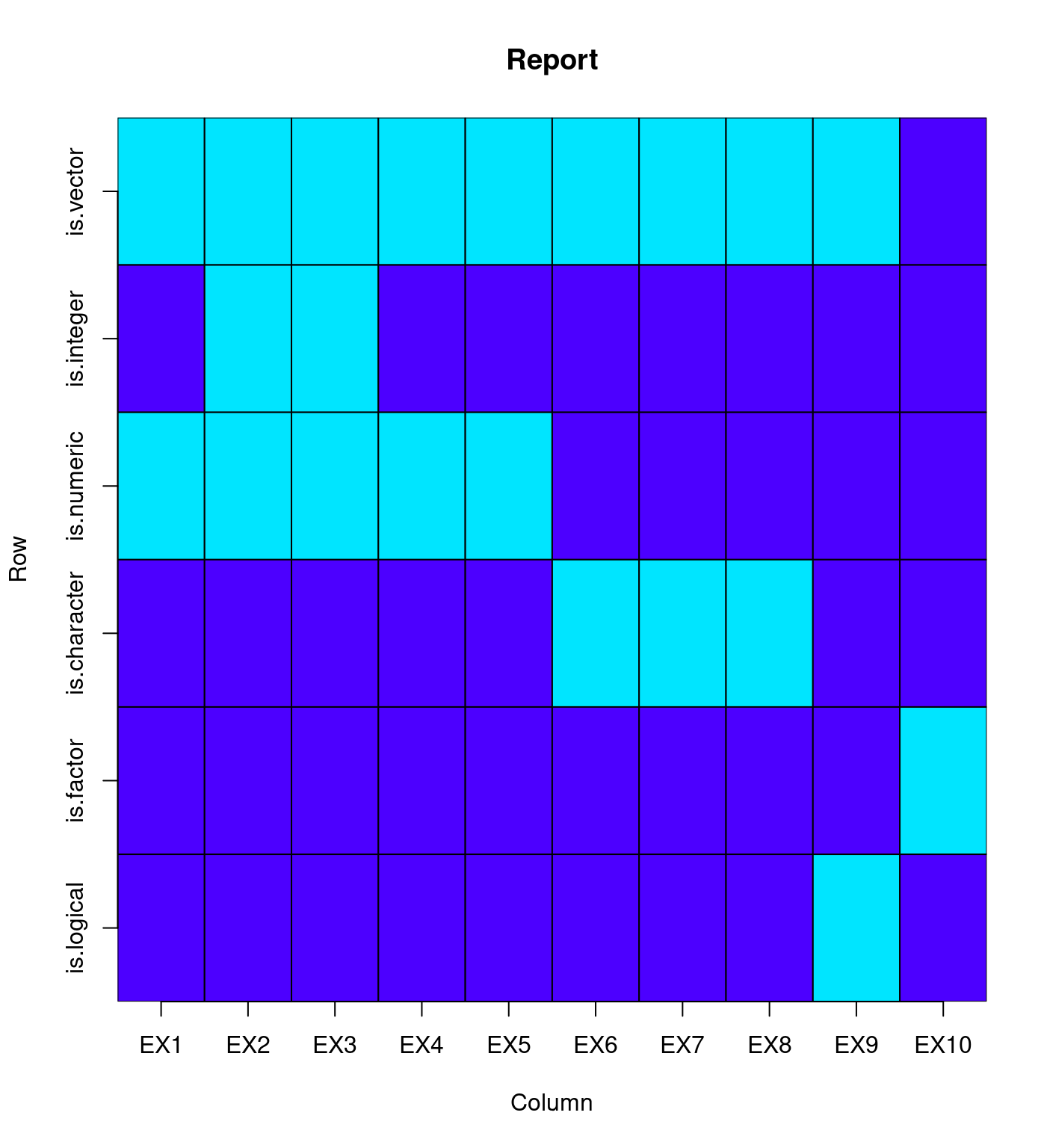
如果讀者諸君還不滿意,請持續關注上述網站,持續修改作者提供的參考碼。
值得關注的一項結果:
factor(c("贊成", "沒意見", "不贊成"))並不是「向量」。「它」到底是什麼呢?
6.6.5 檢查向量的其他屬性
6.6.5.1 向量的長度
「長度」會清楚說明向量內有幾個元素?
for (i in 1:10) {
Results[[i]] <- length(EXs[[i]])
}
Report0 <- as.data.frame(Results, stringsAsFactors = FALSE)
colnames(Report0) <- paste0("EX", 1:10)
rownames(Report0) <- "length"
Report <- rbind(Report, Report0)
Report## EX1 EX2 EX3 EX4 EX5 EX6 EX7 EX8 EX9 EX10
## is.vector 1 1 1 1 1 1 1 1 1 0
## is.integer 0 1 1 0 0 0 0 0 0 0
## is.numeric 1 1 1 1 1 0 0 0 0 0
## is.character 0 0 0 0 0 1 1 1 0 0
## is.factor 0 0 0 0 0 0 0 0 0 1
## is.logical 0 0 0 0 0 0 0 0 1 0
## length 1 10 10 10 11 1 2 3 3 36.6.5.2 class
for (i in 1:10) {
Results[[i]] <- class(EXs[[i]])
}
Report0 <- as.data.frame(Results, stringsAsFactors = FALSE)
colnames(Report0) <- paste0("EX", 1:10)
rownames(Report0) <- "class"
Report <- rbind(Report, Report0)
Report## EX1 EX2 EX3 EX4 EX5 EX6 EX7
## is.vector 1 1 1 1 1 1 1
## is.integer 0 1 1 0 0 0 0
## is.numeric 1 1 1 1 1 0 0
## is.character 0 0 0 0 0 1 1
## is.factor 0 0 0 0 0 0 0
## is.logical 0 0 0 0 0 0 0
## length 1 10 10 10 11 1 2
## class numeric integer integer numeric numeric character character
## EX8 EX9 EX10
## is.vector 1 1 0
## is.integer 0 0 0
## is.numeric 0 0 0
## is.character 1 0 0
## is.factor 0 0 1
## is.logical 0 1 0
## length 3 3 3
## class character logical factor6.6.5.3 typeof
for (i in 1:10) {
Results[[i]] <- typeof(EXs[[i]])
}
Report0 <- as.data.frame(Results, stringsAsFactors = FALSE)
colnames(Report0) <- paste0("EX", 1:10)
rownames(Report0) <- "typeof"
Report <- rbind(Report, Report0)
Report## EX1 EX2 EX3 EX4 EX5 EX6 EX7
## is.vector 1 1 1 1 1 1 1
## is.integer 0 1 1 0 0 0 0
## is.numeric 1 1 1 1 1 0 0
## is.character 0 0 0 0 0 1 1
## is.factor 0 0 0 0 0 0 0
## is.logical 0 0 0 0 0 0 0
## length 1 10 10 10 11 1 2
## class numeric integer integer numeric numeric character character
## typeof double integer integer double double character character
## EX8 EX9 EX10
## is.vector 1 1 0
## is.integer 0 0 0
## is.numeric 0 0 0
## is.character 1 0 0
## is.factor 0 0 1
## is.logical 0 1 0
## length 3 3 3
## class character logical factor
## typeof character logical integer6.6.5.4 mode
for (i in 1:10) {
Results[[i]] <- mode(EXs[[i]])
}
Report0 <- as.data.frame(Results, stringsAsFactors = FALSE)
colnames(Report0) <- paste0("EX", 1:10)
rownames(Report0) <- "mode"
Report <- rbind(Report, Report0)
Report## EX1 EX2 EX3 EX4 EX5 EX6 EX7
## is.vector 1 1 1 1 1 1 1
## is.integer 0 1 1 0 0 0 0
## is.numeric 1 1 1 1 1 0 0
## is.character 0 0 0 0 0 1 1
## is.factor 0 0 0 0 0 0 0
## is.logical 0 0 0 0 0 0 0
## length 1 10 10 10 11 1 2
## class numeric integer integer numeric numeric character character
## typeof double integer integer double double character character
## mode numeric numeric numeric numeric numeric character character
## EX8 EX9 EX10
## is.vector 1 1 0
## is.integer 0 0 0
## is.numeric 0 0 0
## is.character 1 0 0
## is.factor 0 0 1
## is.logical 0 1 0
## length 3 3 3
## class character logical factor
## typeof character logical integer
## mode character logical numeric6.6.6 互換屬性
向量的內容物是可以變來變去的,或許變過一輪之後,不一定回到原來的樣子,但是請大家記得「萬事萬物都是文字」!為了示範互換的機制與結果,我們再一次設計需要的資料結構:
- 把示範例子放在「譜(
list)」裡。
EXs <- list()
EXs[[1]] <- c(0L, 2L, 3L)
EXs[[2]] <- c(0, 2, 3)
EXs[[3]] <- c("aa", "bb", "cc")
EXs[[4]] <- factor(c("贊成", "沒意見", "不贊成"))
EXs[[5]] <- c(TRUE, FALSE, TRUE)
EXs## [[1]]
## [1] 0 2 3
##
## [[2]]
## [1] 0 2 3
##
## [[3]]
## [1] "aa" "bb" "cc"
##
## [[4]]
## [1] 贊成 沒意見 不贊成
## Levels: 不贊成 沒意見 贊成
##
## [[5]]
## [1] TRUE FALSE TRUE- 設計存放結果的「譜(
list)」。
Results <- list()
Results## list()- 先設計輸出畫面的長相,然後開始進行各種「強迫(
as.)」
for (i in 1:5) {
print(paste0("第", i, "次互換,從c(", paste0(EXs[[i]],collapse = ","), ")變成..."))
Results[[1]] <- as.integer(EXs[[i]])
Results[[2]] <- as.numeric(EXs[[i]])
Results[[3]] <- as.character(EXs[[i]])
Results[[4]] <- as.factor(EXs[[i]])
Results[[5]] <- as.logical(EXs[[i]])
names(Results) <- c("整數向量","實數向量","文字向量","factor向量","邏輯向量")
print(Results)
print(paste0(rep("*", 38), collapse = ""))
}## [1] "第1次互換,從c(0,2,3)變成..."
## $整數向量
## [1] 0 2 3
##
## $實數向量
## [1] 0 2 3
##
## $文字向量
## [1] "0" "2" "3"
##
## $factor向量
## [1] 0 2 3
## Levels: 0 2 3
##
## $邏輯向量
## [1] FALSE TRUE TRUE
##
## [1] "**************************************"
## [1] "第2次互換,從c(0,2,3)變成..."
## $整數向量
## [1] 0 2 3
##
## $實數向量
## [1] 0 2 3
##
## $文字向量
## [1] "0" "2" "3"
##
## $factor向量
## [1] 0 2 3
## Levels: 0 2 3
##
## $邏輯向量
## [1] FALSE TRUE TRUE
##
## [1] "**************************************"
## [1] "第3次互換,從c(aa,bb,cc)變成..."
## $整數向量
## [1] NA NA NA
##
## $實數向量
## [1] NA NA NA
##
## $文字向量
## [1] "aa" "bb" "cc"
##
## $factor向量
## [1] aa bb cc
## Levels: aa bb cc
##
## $邏輯向量
## [1] NA NA NA
##
## [1] "**************************************"
## [1] "第4次互換,從c(贊成,沒意見,不贊成)變成..."
## $整數向量
## [1] 3 2 1
##
## $實數向量
## [1] 3 2 1
##
## $文字向量
## [1] "贊成" "沒意見" "不贊成"
##
## $factor向量
## [1] 贊成 沒意見 不贊成
## Levels: 不贊成 沒意見 贊成
##
## $邏輯向量
## [1] NA NA NA
##
## [1] "**************************************"
## [1] "第5次互換,從c(TRUE,FALSE,TRUE)變成..."
## $整數向量
## [1] 1 0 1
##
## $實數向量
## [1] 1 0 1
##
## $文字向量
## [1] "TRUE" "FALSE" "TRUE"
##
## $factor向量
## [1] TRUE FALSE TRUE
## Levels: FALSE TRUE
##
## $邏輯向量
## [1] TRUE FALSE TRUE
##
## [1] "**************************************"成功!雖然輸出畫面還有待改善!
6.6.7 屬性強度:整數?實數?文字?factor?還是邏輯?
記住這句話,「萬事萬物都是文字」。讓我們測試一下,表面上各種屬性混雜的向量,打進去R之後,會以什麼樣的屬性被R存下來?
- 先設計例子,以及存放例子的「譜(
list)」。
EXs <- list()
EXs[[1]] <- c(11L, 22)
EXs[[2]] <- c(11L, 22, "33")
EXs[[3]] <- c(11L, 22, "33", TRUE, FALSE)
EXs## [[1]]
## [1] 11 22
##
## [[2]]
## [1] "11" "22" "33"
##
## [[3]]
## [1] "11" "22" "33" "TRUE" "FALSE"- 設計存放測試結果的「表」。
Results <- data.frame()
Results## 資料框沒有行但有 0 列- 執行屬性測試並且紀錄在表裡。加了「欄位名(
colnames)」跟「列名稱(rownames)」。
for (i in 1:3) {
x <- list()
x[[1]] <- is.vector(EXs[[i]])
x[[2]] <- is.integer(EXs[[i]])
x[[3]] <- is.numeric(EXs[[i]])
x[[4]] <- is.character(EXs[[i]])
x[[5]] <- is.factor(EXs[[i]])
x[[6]] <- is.logical(EXs[[i]])
x <- as.data.frame(x)
colnames(x)<-c("is.vector",
"is.integer",
"is.numeric",
"is.character",
"is.factor",
"is.logical")
Results <- rbind(Results, x)
}
rownames(Results)[1] <- 'c(11L, 22)'
rownames(Results)[2] <- 'c(11L, 22, "33")'
rownames(Results)[3] <- 'c(11L, 22, "33", TRUE, FALSE)'
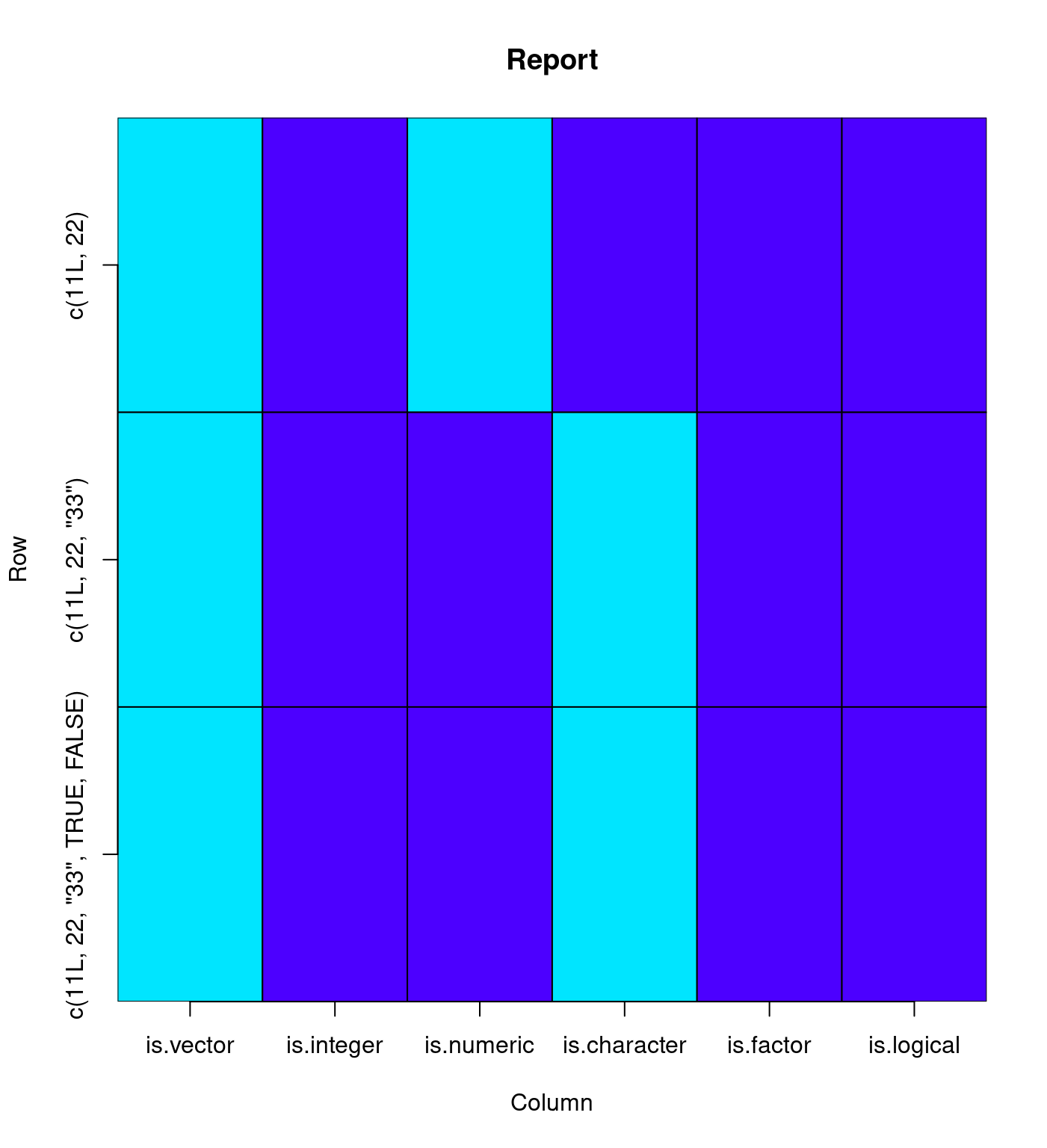
Results## is.vector is.integer is.numeric is.character
## c(11L, 22) TRUE FALSE TRUE FALSE
## c(11L, 22, "33") TRUE FALSE FALSE TRUE
## c(11L, 22, "33", TRUE, FALSE) TRUE FALSE FALSE TRUE
## is.factor is.logical
## c(11L, 22) FALSE FALSE
## c(11L, 22, "33") FALSE FALSE
## c(11L, 22, "33", TRUE, FALSE) FALSE FALSE接著, 繪製示意圖:
library(plot.matrix)
Report <- as.matrix(Results)
plot(Report, col = topo.colors, key = NULL)