Bias and fairness in machine learning
Learning outcomes/objective: Learn…
- …about the discussion surrounding bias/fairness in machine learning and the underlying concepts.
- …how to assess whether an algorithm is biased.
Sources: Mehrabi et al. (2021), Dressel and Farid (2018), Osoba and Welser (2017)
1 Fundstücke/Finding(s)
2 Overview
- ‘like people, algorithms are vulnerable to biases that render their decisions “unfair”’ (Mehrabi et al. 2021, 115:2)
- Decision-making context: “fairness is the absence of any prejudice or favoritism toward an individual or group based on their inherent or acquired characteristics” (Mehrabi et al. 2021, 115:2)
- Example: Correctional Offender Management Profiling for Alternative Sanctions (COMPAS)
- Measures the risk of a person to recommit another crime
- Judges use COMPAS to decide whether to release an offender or to keep him or her in prison
- “COMPAS is more likely to have higher false positive rates for African-American offenders than Caucasian offenders in falsely predicting them to be at a higher risk of recommitting a crime or recidivism” (Mehrabi et al. 2021, 115:2)
- Generally sources of bias can be…
- …biases in the data
- …biases in the algorithms
- Assessment tools: Aequitas; Bias and Fairness Audit Toolkit (Microsoft Fair Learn); The What-if Tool (Google) IBM 360 degree toolkit
- Research: e.g., projects such as Trustworthiness Auditing for AI
3 Biases in a feed-back loop
- Figure 1 visualizes the loop capturing the feedback between biases in data, algorithms, and user interaction.
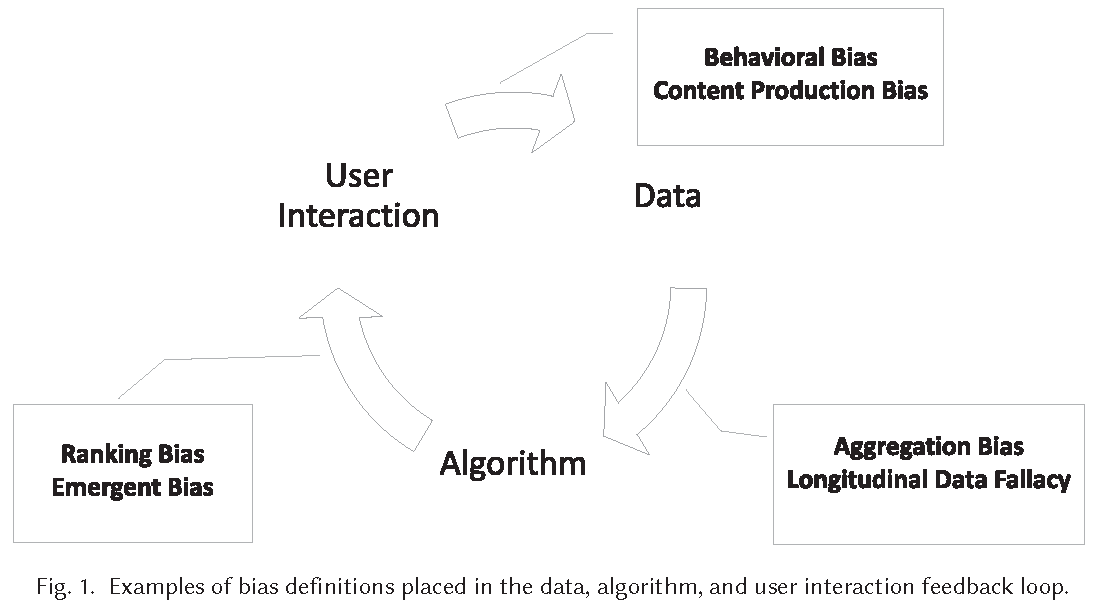
- Example of web search engine (Mehrabi et al. 2021, 115:4)
- Puts specific results at the top of its list and users tend to interact most with the top results
- Interactions of users with items will then be collected by web search engine, and data will be used to make future decisions on how information should be presented based on popularity and user interest
- Results at the top will become more and more popular, not because of the nature of the result but due to the biased interaction and placement of results by these algorithms
- Q: Can you think of other examples?
4 Exercise: Biases in a feed-back loop
- Discuss with your neighbor on how/wether this feedback loop in Figure 2 exists in the case of the recidivism example.
5 Types of bias
- Source: Mehrabi et al. (2021, sec. 3.1)
5.1 Biases: Data to Algoritm
- Biases in data, which, when used by ML training algorithms, might result in biased algorithmic outcomes
- Measurement Bias: arises from how we choose, utilize, and measure particular features
- e.g., COMPAS, where prior arrests and friend/family arrests were used as proxy variables to measure level of “riskiness” or “crime”
- Omitted Variable Bias: occurs when one or more important variables [predictors] are left out of the model
- e.g., forgetting the predictor of ‘prior offenses’
- Representation Bias: arises from how we sample from a population during data collection process
- e.g. ImageNet: bias towards Western cultures (see Figure 3 and 4 in Mehrabi et al. 2021)
- Aggregation Bias (or ecological fallacy): arises when false conclusions are drawn about individuals from observing the entire population
- i.e., any general assumptions about subgroups within the population can result in aggregation bias
- see also Simpson’s Paradox and the Modifiable Areal Unit Problem
- Sampling Bias: is similar to representation bias, and arises due to non-random sampling of subgroups
- Longitudinal Data Fallacy: Researchers analyzing temporal data must use longitudinal analysis to track cohorts over time to learn their behavior. Instead, temporal data is often modeled using cross-sectional analysis, which combines diverse cohorts at a single time point
- e.g., comment length on reddit decreased over time, however, did increase when aggregated according to cohorts
- Linking Bias: arises when network attributes obtained from user connections, activities, or interactions differ and misrepresent the true behavior of the users
- e.g. only considering links (not content/behavior) in the network could favor low-degree nodes
5.2 Exercise: Data to Algoritm
- With your neighbor please try to find an example for each of the Data to Algoritm biases mentioned above.
5.3 Biases: Algorithm to User
Biases that are a result of algorithmic outcomes and affect user behavior as a consequence
Algorithmic Bias: bias is not present in the input data but purely produced by the algorithm
- Originates from design/modelling choices: optimization functions, regularizations, choices in applying regression models on the data as a whole or considering subgroups, and the general use of statistically biased estimators in algorithms
User Interaction Bias: type of bias that can not only be observant on the Web but also get triggered from two sources—the user interface and through the user itself by imposing his/her self-selected biased behavior and interaction
- Presentation Bias: is a result of how information is presented
- Ranking Bias: idea that top-ranked results are the most relevant and important will result in attraction of more clicks than others. This bias affects search engines/crowdsourcing applications
Popularity Bias: Items that are more popular tend to be exposed more. However, popularity metrics are subject to manipulation—for example, by fake reviews or social bots
Emergent Bias: occurs as a result of use and interaction with real users. This bias arises as a result of change in population, cultural values, or societal knowledge (e.g., different people use same interface differently; Q: Example?)
Evaluation Bias: Evaluation bias happens during model evaluation
- e.g., use of inappropriate and disproportionate benchmarks for evaluation of applications such as Adience and IJB-A benchmarks that were used in the evaluation of facial recognition systems that were biased toward skin color and gender
5.4 Exercise: Algorithm to User
- With your neighbor please try to find an example for each of the Algorithm to User biases discussed above.
5.5 Biases: User to Data
Biases through user-induced biases in user-generated data (e.g., humans flagging facebook content)
Historical Bias: Already existing bias and socio-technical issues in the world and can seep into ML model from the data generation process even given a perfect sampling and feature selection
- e.g., 2018 image search result where searching for women CEOs ultimately resulted in fewer female CEO images due to the fact that only 5% of Fortune 500 CEOs were women—which would cause the search results to be biased towards male CEOs (reflects reality but do we want that)
Population Bias: arises when statistics, demographics, representatives, and user characteristics are different in the user population of the platform from the original target population (e.g., populations across platforms vary)
Self-selection Bias: is a subtype of the selection or sampling bias in which subjects of the research select themselves
- e.g., enthusiastic supporters of candidate are more likely to complete the poll that should measure popularity of their candidate.
Social Bias: happens when others’ actions affect our judgment
- e.g., we want to rate or review an item with a low score, but are influenced by other high ratings (Q: Can you think of an example?)
Behavioral Bias: arises from different user behavior across platforms, contexts, or different datasets
- e.g., differences in emoji representations among platforms can result in different reactions and behavior from people and sometimes even leading to communication errors
Temporal Bias: arises from differences in populations and behaviors over time
- e.g., Twitter where people talking about a particular topic start using a hashtag at some point to capture attention, then continue the discussion about the event without using the hashtag
Content Production Bias: Content Production bias arises from structural, lexical, semantic, and syntactic differences in the contents generated by users
- e.g., differences in use of language across different gender and age groups
5.6 Discrimination (1)
- Discrimination: “a source for unfairness that is due to human prejudice and stereotyping based on the sensitive attributes, which may happen intentionally or unintentionally” (Mehrabi et al. 2021, 115:10)
- “while bias can be considered as a source for unfairness that is due to the data collection, sampling, and measurement” (Mehrabi et al. 2021, 115:10)
- Explainable Discrimination: Differences in treatment and outcomes among different groups can be justified and explained via some attributes and are not considered illegal as a consequence
- UCI Adult dataset (Kamiran and Žliobaitė 2013): Dataset used in fairness domain where males on average have a higher annual income than females
- Reason: On average females work fewer hours than males per week
- UCI Adult dataset (Kamiran and Žliobaitė 2013): Dataset used in fairness domain where males on average have a higher annual income than females
- Q: What do you think is reverse discrimination?
- Q: Can you give other examples of explainable discrimination?
5.7 Discrimination (2)
- Unexplainable Discrimination: Unexplainable discrimination in which the discrimination toward a group is unjustified and therefore considered illegal
- Direct discrimination: happens when protected attributes of individuals explicitly result in non-favorable outcomes toward them (e.g., race, sex, etc.)
- see Table 3 (Mehrabi et al. 2021, 115:15)
- Indirect discrimination: individuals appear to be treated based on seemingly neutral and non-protected attributes; however, protected groups, or individuals, still get to be treated unjustly as a result of implicit effects from their protected attributes (e.g., residential zip code: Q:why?)
- Q: Can you think of other examples of indirect discrimination?
- Direct discrimination: happens when protected attributes of individuals explicitly result in non-favorable outcomes toward them (e.g., race, sex, etc.)
- Sources of discrimination
- Systemic discrimination: refers to policies, customs, or behaviors that are a part of the culture or structure of an organization that may perpetuate discrimination against certain subgroups of the population
- Statistical discrimination: a phenomenon where decision-makers use average group statistics to judge an individual belonging to that group
5.8 Algorithmic fairness (1)
- No universal definition of fairness (Saxena 2019)
- Fairness: “absence of any prejudice or favoritism towards an individual or a group based on their intrinsic or acquired traits in the context of decision-making” (Saxena et al. 2019)
- Many different definitions of fairness (Mehrabi et al. 2021; Verma and Rubin 2018)
- Definition 1 (Equalized Odds) (Hardt, Price, and Srebro 2016): probability of a person in the positive class being correctly assigned a positive outcome and the probability of a person in a negative class being incorrectly assigned a positive outcome should both be the same for the protected and unprotected group members (Verma and Rubin 2018), i.e, protected and unprotected groups should have equal rates for true positives and false positives
- Definition 2 (Equal Opportunity) (Hardt, Price, and Srebro 2016): probability of a person in a positive class being assigned to a positive outcome should be equal for both protected and unprotected (female and male) group members (Verma and Rubin 2018), i.e., the equal opportunity definition states that the protected and unprotected groups should have equal true positive rates
5.9 Algorithmic fairness (2)
- Definition 3 (Demographic Parity) (Dwork et al. 2012; Kusner et al. 2017): also known as statistical parity …the likelihood of a positive outcome should be the same regardless of whether the person is in the protected (e.g., female) group (Verma and Rubin 2018)
- Definition 4 (Fairness through Awareness): “An algorithm is fair if it gives similar predictions to similar individuals” (Dwork et al. 2012; Kusner et al. 2017), i.e., two individuals who are similar with respect to a similarity (inverse distance) metric defined for a particular task should receive a similar outcome.
- Definition 5 (Fairness through Unawareness) : “An algorithm is fair as long as any protected attributes A are not explicitly used in the decision-making process” Kusner et al. (2017)
- Definition 6 (Treatment Equality): “Treatment equality is achieved when the ratio of false negatives and false positives is the same for both protected group categories” (Berk et al. 2021).
- …to be continued (cf. Mehrabi et al. 2021, sec. 4).
5.10 Algorithmic fairness (3)
- Fairness definitions fall into different types as shown in Table in Figure 3.
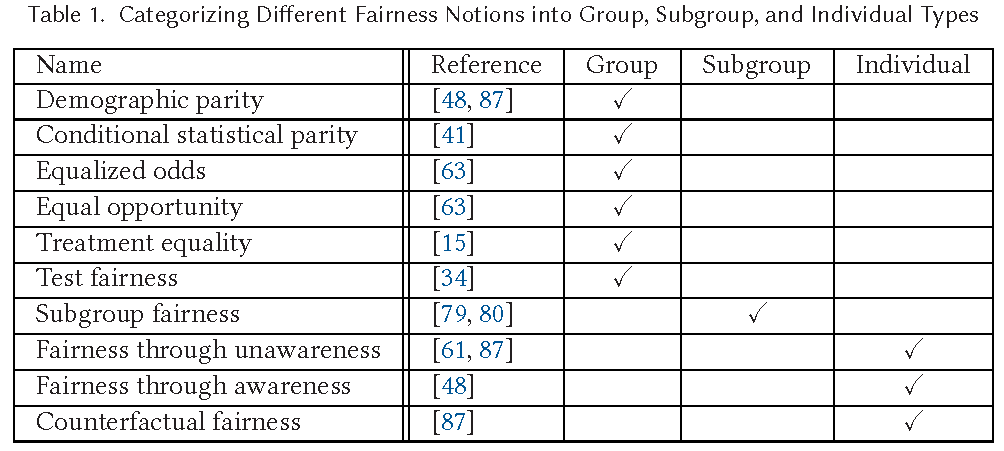
- (1) Individual Fairness: Give similar predictions to similar individuals
- (2) Group Fairness: Treat different groups equally
- (3) Subgroup Fairness:
- Subgroup fairness intends to obtain the best properties of the group and individual notions of fairness. It is different than these notions but uses them to obtain better outcomes.
- It picks a group fairness constraint like equalizing false positive and asks whether this constraint holds over a large collection of subgroups
5.11 Exercise: Topics for term paper
- Discuss with your neighbor what topics you are interested, what outcomes would be interesting to predict and what kind of data you would need.
- Investigate whether data of the kind you are interested in is accessible/downloadable.