Learning outcomes/objective - Learn how to extract model predictions in R
1 Packages
broom package (see ?function for arguments)
tidy(): Returns statistical findings of models (e.g., coefficients + stats)
glance(): Returns one-row summary of model (e.g., R-squared as measure of fit of model)
augment(): Add prediction columns to the modeled data (including original data)
1.1 Extract coefficients, stats and predictions
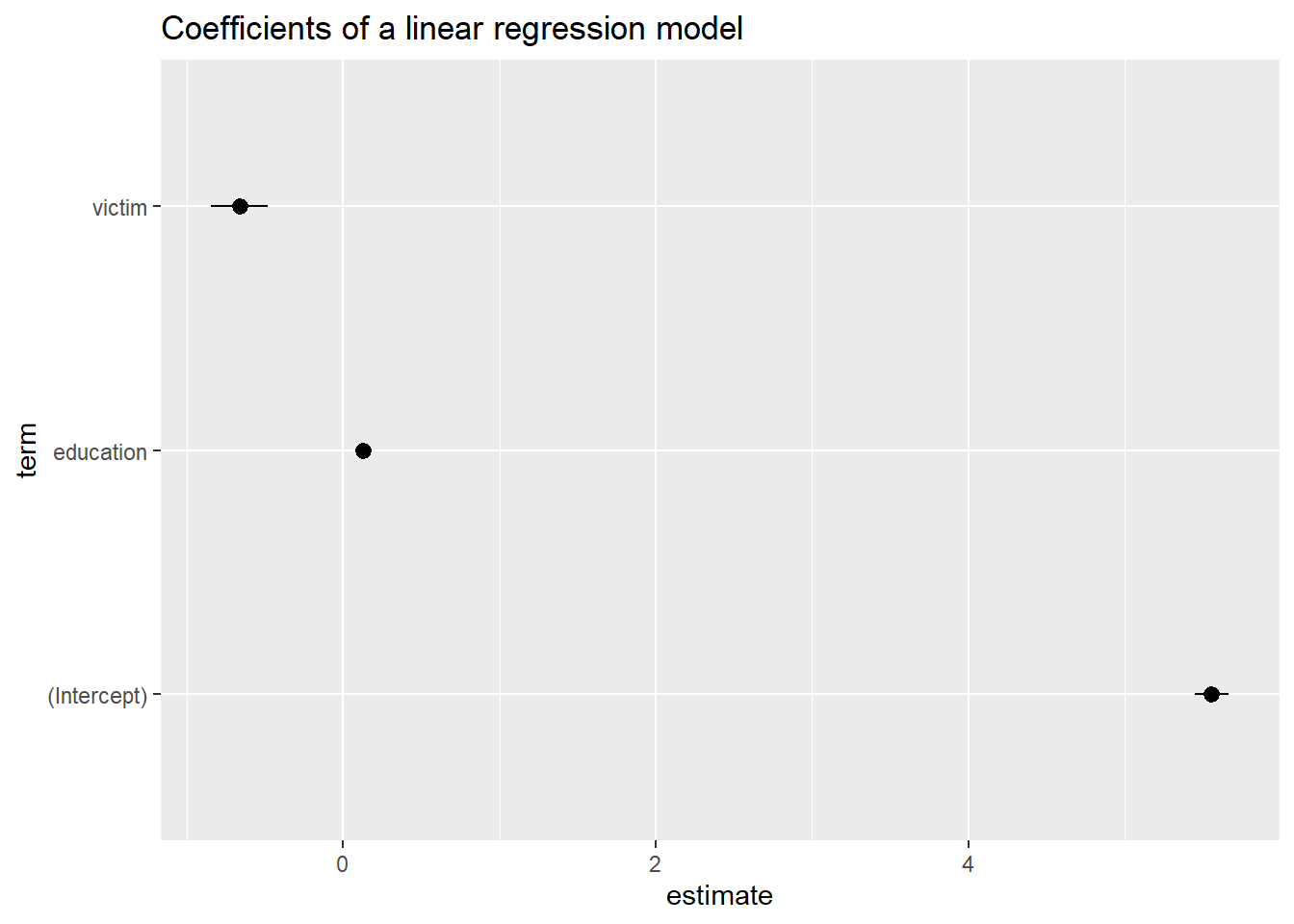
# install.packages("broom")# install.packages("ggplot2")library(broom)library(ggplot2)# Load data data <-read_csv(sprintf("https://docs.google.com/uc?id=%s&export=download","1I0eVUFyw0yn9T5roxzr67hPEl_5ZClrL"))# Inspect the data data
idpers trust victim education
Min. : 1 Min. : 0.000 Min. :0.0000 Min. : 0.000
1st Qu.: 5641 1st Qu.: 5.000 1st Qu.:0.0000 1st Qu.: 4.000
Median :11147 Median : 7.000 Median :0.0000 Median : 4.000
Mean :11103 Mean : 6.131 Mean :0.1006 Mean : 5.036
3rd Qu.:16862 3rd Qu.: 8.000 3rd Qu.:0.0000 3rd Qu.: 7.000
Max. :21419 Max. :10.000 Max. :1.0000 Max. :10.000
Name
Length:6633
Class :character
Mode :character
# View(data)# Estimate a linear model M1 <-lm(trust ~ victim + education,data = data)# Check the outputsummary(M1)
Call:
lm(formula = trust ~ victim + education, data = data)
Residuals:
Min 1Q Median 3Q Max
-6.8282 -1.0662 0.1878 1.5528 5.1046
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 5.558250 0.055462 100.217 < 2e-16 ***
victim -0.662806 0.092424 -7.171 8.23e-13 ***
education 0.126997 0.009262 13.711 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.261 on 6630 degrees of freedom
Multiple R-squared: 0.03631, Adjusted R-squared: 0.03602
F-statistic: 124.9 on 2 and 6630 DF, p-value: < 2.2e-16
# + errors + other things in the columns# What are the single columns? see ?augment -> value
1.2 Homework
Pick a dataset of your choice, estimate a linear model with an outcome of your choice. Extract the model coefficients using the tidy() function from the broom package, extract model statistics using the glance() function and add predicted values to the dataset using the augment() function.
1.3 All the code
library(tidyverse)library(lemon)library(knitr)# install.packages("broom")# install.packages("ggplot2")library(broom)library(ggplot2)# Load data data <-read_csv(sprintf("https://docs.google.com/uc?id=%s&export=download","1I0eVUFyw0yn9T5roxzr67hPEl_5ZClrL"))# Inspect the data datastr(data)summary(data)# View(data)# Estimate a linear model M1 <-lm(trust ~ victim + education,data = data)# Check the outputsummary(M1)# Extract estimatestidy(M1, conf.int =TRUE) # conf.int ? coefficients <-tidy(M1, conf.int =TRUE)# Visualize estimatesggplot(coefficients, aes(term, estimate))+geom_point()+geom_pointrange(aes(ymin = conf.low, ymax = conf.high))+labs(title ="Coefficients of a linear regression model") +coord_flip()# How can we exclude the intercept?# coefficients %>% ...# Extract model statisticsglance(M1)glance(M1)$r.squaredglance(M1)$adj.r.squared# Add predictions to dataaugment(M1) # Takes original data and appends predictions # + errors + other things in the columns# What are the single columns? see ?augment -> value