15 Day 15 (June 24)
15.3 Bootstrap confidence intervals
Google scholar demonstration
Motivation (see section 3.6 in Faraway (2014))
- Functions of parameters (i.e., “derived” quantities)
- Difficult to obtain the sampling distribution for non-linear functions of estimated parameters
- Further reading (Hesterberg 2015)
- Example: When do we expect the population to go extinct?
y <- c(63, 68, 61, 44, 103, 90, 107, 105, 76, 46, 60, 66, 58, 39, 64, 29, 37, 27, 38, 14, 38, 52, 84, 112, 112, 97, 131, 168, 70, 91, 52, 33, 33, 27, 18, 14, 5, 22, 31, 23, 14, 18, 23, 27, 44, 18, 19) year <- 1965:2011 df <- data.frame(y = y, year = year) plot(x = df$year, y = df$y, xlab = "Year", ylab = "Annual count", main = "", col = "brown", pch = 20, xlim = c(1965, 2040)) m1 <- lm(y~year) abline(m1)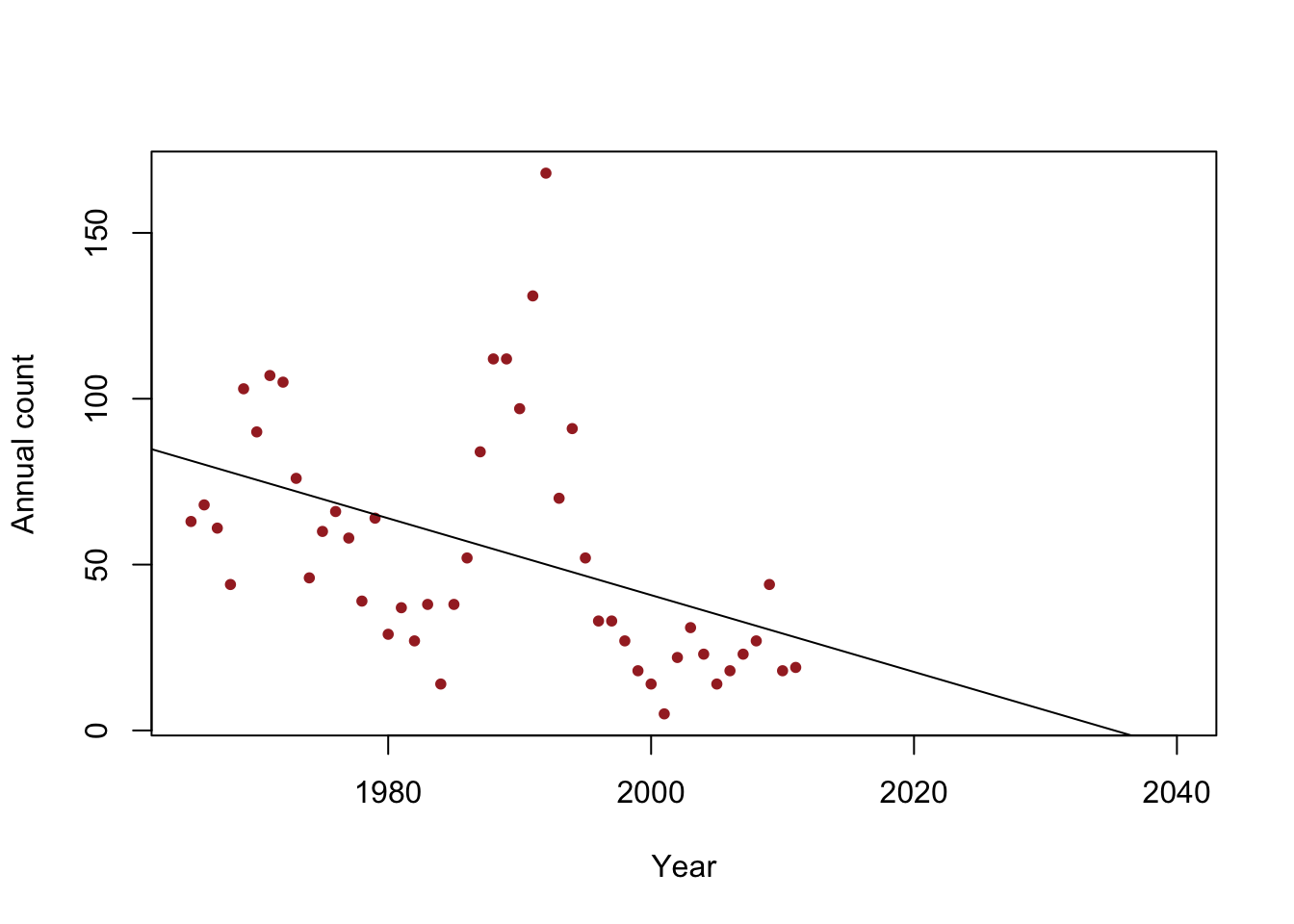
Non-parametric bootstrap (see Efron and Tibshirani (1994)).
- From a data set with n observations, take a sample of size n with replacement. For a linear model, the sample should include both the observed response (\(y_{i}\)) and covariates (\(x_{1}\),\(x_{2}\),…,\(x_{p}\)).
- Estimate the parameters for a statistical model using the sampled data from step 1.
- Save the estimates of interest. This could be parameters of interest (e.g., \(\boldsymbol{\beta}\)) or a a derived quantity (e.g., \(R^{2}\), \(\frac{1}{\boldsymbol{\beta}}\)).
- Repeats steps (1)-(3) \(m\) times.
Inference
- The \(m\) samples of the quantities of interest are samples from the empirical distribution.
- The empirical distribution can summarized using sample statistics (e.g., quantiles, mean, variance, etc). Conceptually, this is similar to Monte Carlo integration.
Example in R
library(latex2exp) # Number of bootstrap samples (m) m.boot <- 1000 # Create matrix to save empirical distribution of -beta2.hat/beta1.hat (expected time of extinction) ed.extinct.hat <- matrix(,m.boot,1) # Set random seed so results are the same if we run it again # Results would be different due to random resampling of data set.seed(1940) # Start for loop for non-parametric boostrap for(m in 1:m.boot){ # Sample data with replacement # boot.sample gives the rows of df that we use for estimation boot.sample <- sample(1:nrow(df),replace=TRUE) # Make temporary data frame that contains the resamples df.temp <- df[boot.sample,] # Estimate parameters for df.temp m1 <- lm(y~year,data=df.temp) # Save estimate of -beta0.hat/beta1.hat (expected time of extinction) ed.extinct.hat[m,] <- -coef(m1)[1]/coef(m1)[2] } par(mar=c(5,4,7,2)) hist(ed.extinct.hat,col="grey",xlab="Year",main=TeX('Empirical distribuiton of $$-$$\\hat{\\frac{$\\beta_0}{$\\beta_1}}'),freq=FALSE,breaks=20)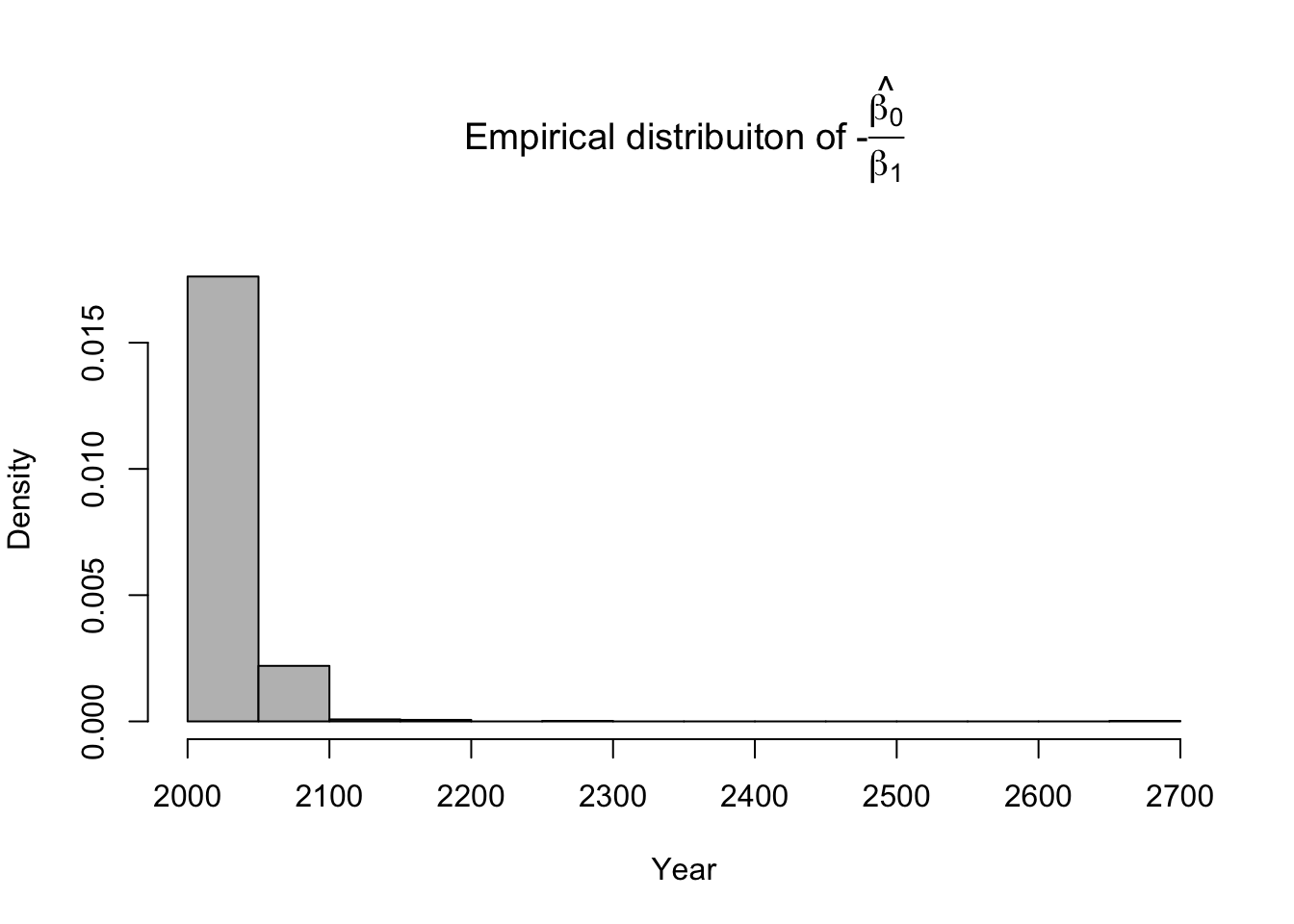
# 95% equal-tailed CI based on percentiles of the empirical distribution quantile(ed.extinct.hat,prob=c(0.025,0.975))## 2.5% 97.5% ## 2021.203 2077.168Example in R using the mosaic package
library(mosaic) set.seed(1940) bootstrap <- do(1000)*coef(lm(y~year,data=resample(df))) head(bootstrap)## Intercept year ## 1 1703.401 -0.8291862 ## 2 3017.102 -1.4887107 ## 3 2683.814 -1.3195092 ## 4 2595.994 -1.2778627 ## 5 2334.905 -1.1463994 ## 6 2011.819 -0.9811046# 95% equal-tailed CI based on percentiles of the empirical distribution quantile(-bootstrap[,1]/bootstrap[,2],prob=c(0.025,0.975))## 2.5% 97.5% ## 2021.203 2077.168## name lower upper level method estimate ## 1 year -1.623489 -0.6753815 0.95 percentile -1.15784## 2.5 % 97.5 % ## -1.9107236 -0.5405716Live example
15.4 Prediction
- My definition of inference and prediction
- Inference = Learning about what you can’t observe given what you did observe (and some assumptions)
- Prediction = Learning about what you didn’t observe given what you did observe (and some assumptions)
- Prediction (Ch. 4 in Faraway (2014))
- Derived quantity
- \(\mathbf{x}^{\prime}_0\) is a \(1\times p\) matrix of covariates (could be a row \(\mathbf{X}\) or completely new values of the predictors)
- Use \(\widehat{\text{E}(y_0)}=\mathbf{x}^{\prime}_0\hat{\boldsymbol{\beta}}\)
- Example
- Predicting the number of whooping cranes
url <- "https://www.dropbox.com/s/8grip274233dr9a/Butler%20et%20al.%20Table%201.csv?dl=1" df1 <- read.csv(url) plot(df1$Winter, df1$N, xlab = "Year", ylab = "Population size", xlim=c(1940,2021),ylim = c(0, 300), typ = "b", lwd = 1.5, pch = "*")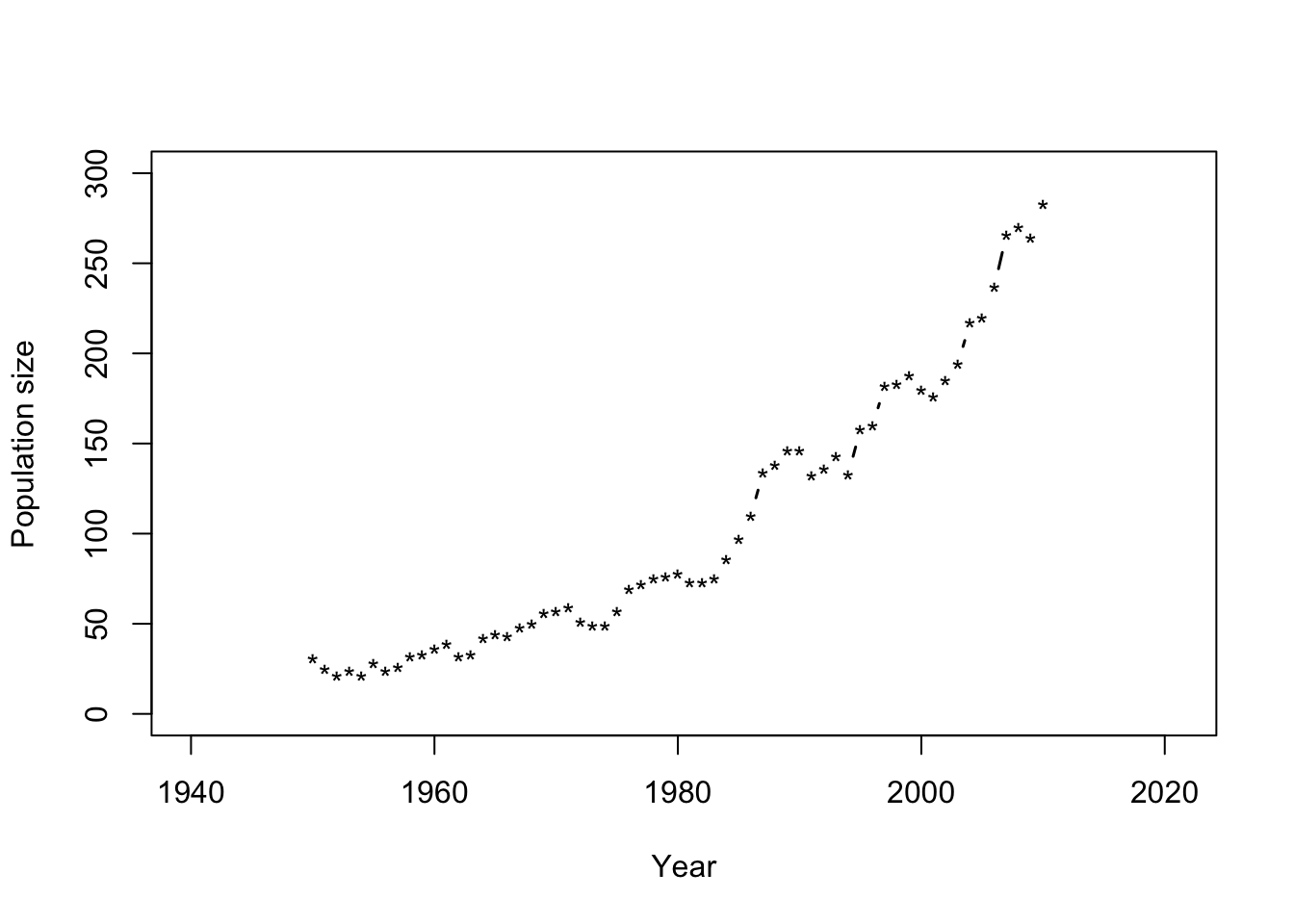
- What model should we use?
m1 <- lm(N ~ Winter + I(Winter^2),data=df1) Ey.hat <- predict(m1) plot(df1$Winter, df1$N, xlab = "Year", ylab = "Population size", xlim=c(1940,2021),ylim = c(0, 300), typ = "b", lwd = 1.5, pch = "*") points(df1$Winter,Ey.hat,typ="l",col="red")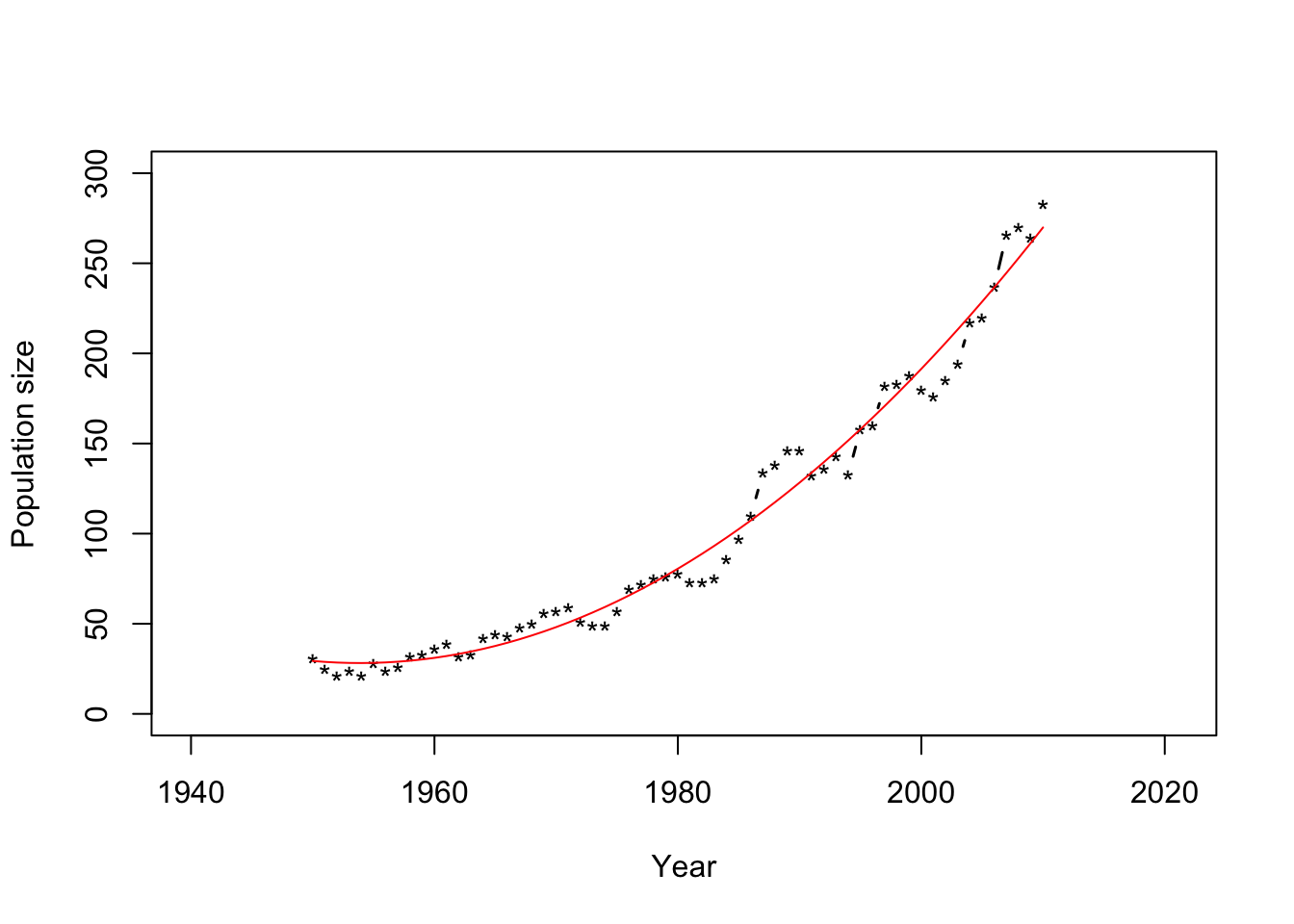
- Derived quantity
15.5 Intervals for predictions
Expected value and variance of \(\mathbf{x}^{\prime}_0\hat{\boldsymbol{\beta}}\)
Confidence interval \(\text{P}\left(\mathbf{x}^{\prime}_0\hat{\boldsymbol{\beta}}-t_{\alpha/2,n-p}\sqrt{\hat{\sigma^{2}}\mathbf{x}_{0}^{'}(\mathbf{X}^{'}\mathbf{X})^{-1}\mathbf{x}_{0}}<\mathbf{x}^{\prime}_0\boldsymbol{\beta}<\mathbf{x}^{\prime}_0\hat{\boldsymbol{\beta}}+t_{\alpha/2,n-p}\sqrt{\hat{\sigma^{2}}\mathbf{x}_{0}^{'}(\mathbf{X}^{'}\mathbf{X})^{-1}\mathbf{x}_{0}}\right)\\=1-\alpha\)
- The 95% CI is \(\mathbf{x}^{\prime}_0\hat{\boldsymbol{\beta}}\pm t_{\alpha/2,n-p}\sqrt{\hat{\sigma^{2}}\mathbf{x}_{0}^{'}(\mathbf{X}^{'}\mathbf{X})^{-1}\mathbf{x}_{0}}\)
- In R
## fit lwr upr ## 1 29.35980 21.43774 37.28186 ## 2 28.84122 21.42928 36.25315 ## 3 28.47610 21.54645 35.40575 ## 4 28.26444 21.78812 34.74075 ## 5 28.20624 22.15308 34.25940 ## 6 28.30150 22.64000 33.96300plot(df1$Winter, df1$N, xlab = "Year", ylab = "Population size", xlim=c(1940,2021),ylim = c(0, 300), typ = "b", lwd = 1.5, pch = "*") points(df1$Winter,Ey.hat[,1],typ="l",col="red") points(df1$Winter,Ey.hat[,2],typ="l",col="red",lty=2) points(df1$Winter,Ey.hat[,3],typ="l",col="red",lty=2)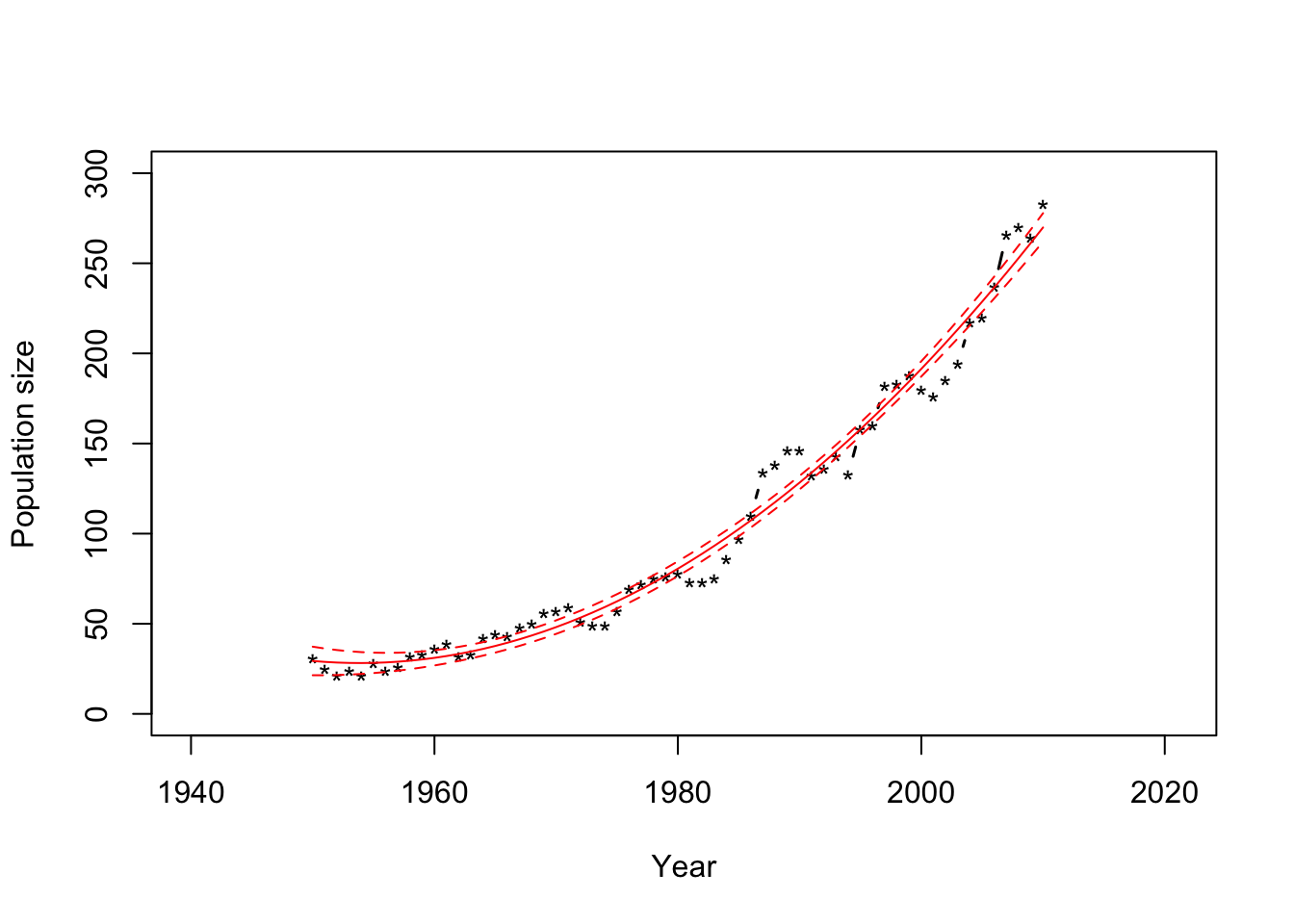
- Why are there so many data points that fall outside of the 95% CIs?
Prediction intervals vs. Confidence intervals
CIs for \(\widehat{\text{E}(y_0)}=\mathbf{x}^{\prime}_0\hat{\boldsymbol{\beta}}\)
How to interpret \(\widehat{\text{E}(y_0)}\)
What if I wanted to predict \(y_0\)?
- \(y_0\sim\text{N}(\mathbf{x}^{\prime}_0\hat{\boldsymbol{\beta}},\hat{\sigma}^2)\)
Expected value and variance of \(y_0\)
Prediction interval \(\text{P}\left(\mathbf{x}^{\prime}_0\hat{\boldsymbol{\beta}}-t_{\alpha/2,n-p}\sqrt{\hat{\sigma^{2}}(1+\mathbf{x}_{0}^{'}(\mathbf{X}^{'}\mathbf{X})^{-1}\mathbf{x}_{0})}<y_0<\mathbf{x}^{\prime}_0\hat{\boldsymbol{\beta}}+t_{\alpha/2,n-p}\sqrt{\hat{\sigma^{2}}(\mathbf{x}_{0}^{'}(\mathbf{X}^{'}\mathbf{X})^{-1}\mathbf{x}_{0})}\right)=\\1-\alpha\)
The 95% PI is \(\mathbf{x}^{\prime}_0\hat{\boldsymbol{\beta}}\pm t_{\alpha/2,n-p}\sqrt{\hat{\sigma^{2}}(1+\mathbf{x}_{0}^{'}(\mathbf{X}^{'}\mathbf{X})^{-1}\mathbf{x}_{0})}\)
Example in R
## fit lwr upr ## 1 29.35980 6.630220 52.08938 ## 2 28.84122 6.284368 51.39807 ## 3 28.47610 6.073089 50.87910 ## 4 28.26444 5.997480 50.53139 ## 5 28.20624 6.058655 50.35382 ## 6 28.30150 6.257741 50.34526plot(df1$Winter, df1$N, xlab = "Year", ylab = "Population size", xlim=c(1940,2021),ylim = c(0, 300), typ = "b", lwd = 1.5, pch = "*") points(df1$Winter,y.hat[,1],typ="l",col="red") points(df1$Winter,y.hat[,2],typ="l",col="red",lty=2) points(df1$Winter,y.hat[,3],typ="l",col="red",lty=2)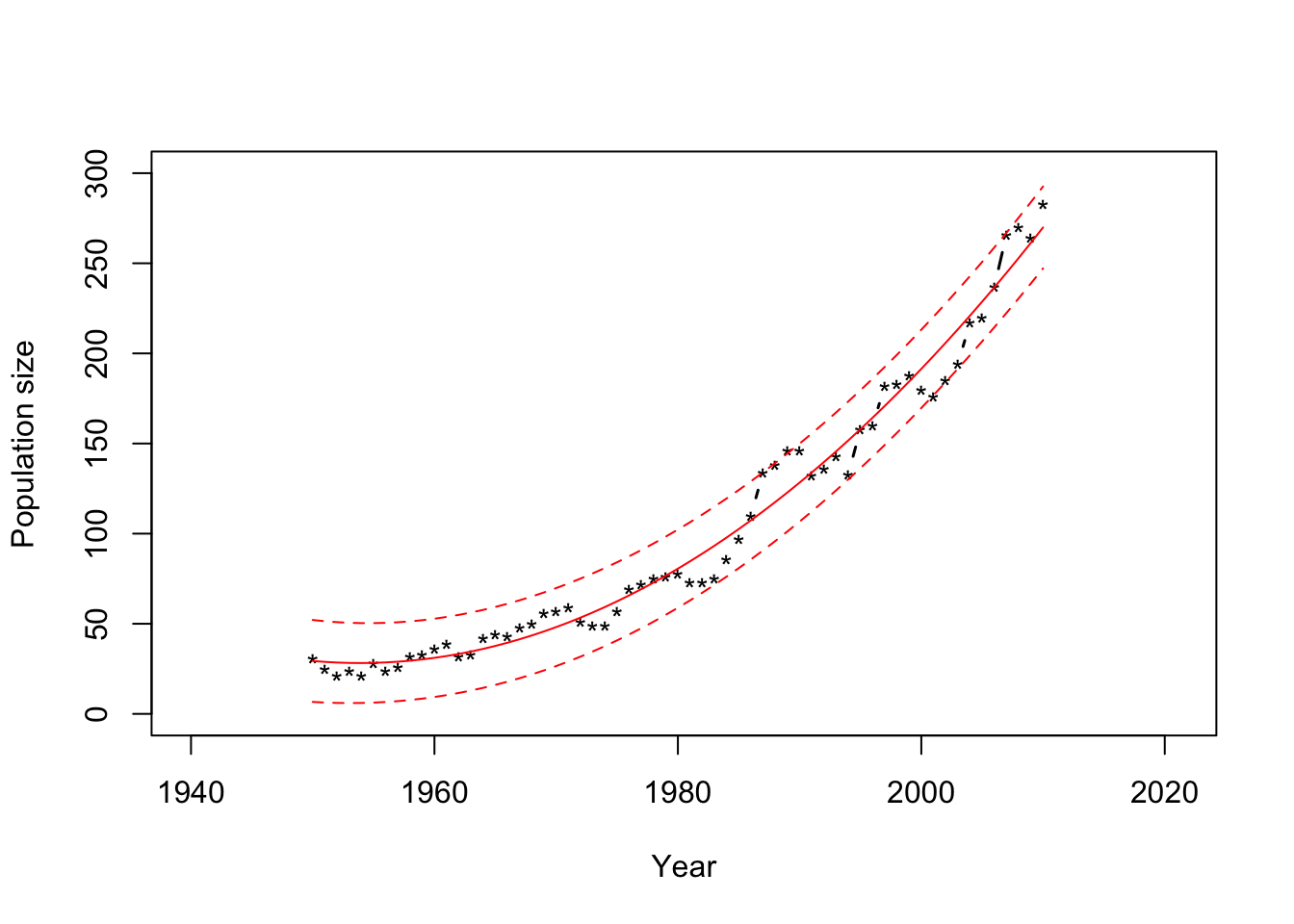
Live example