2.2 Essay 1
Die Aufgabe des ersten Essays für den BN betrifft die Variable Wissen über die EU aus dem Arbeitsdatensatz aus diesem Seminar. Informationen zur Operationalisierung finden Sie im nachfolgenden Block.
Diskutieren Sie, um was für eine Konstrukt es sich beim Wissen über die die EU handelt. Wie wurde das Konstrukt im vorliegenden Fall operationalisiert: reflektiv oder formativ? Kritisieren Sie die Messung.
Die Variable “Wissen über die EU”
Im Rahmen einer Befragung, die am Arbeitsbereich KMW I vor einiger Zeit durchgeführt wurde, sollte das Wissen über die EU der Befragten festgestellt werden. Dafür wurde ein Wissenstest erstellt, der die folgenden 9 Fragen beinhielt:
- “Die nächste Europawahl findet im Mai 2019 statt.”
- “Die Schweiz ist Mitglied der EU.”
- “Deutschland stellt ein Mitglied der Europäischen Kommission.”
- “Der Euro-Raum besteht zurzeit aus 15 Mitgliedsstaaten.”
- “Die Europäische Union wurde kurz nach dem Ersten Weltkrieg gegründet.”
- “Der Europäische Gerichtshof befindet sich in Den Haag.”
- “Auf der Europäischen Flagge gibt es einen Stern für jedes Mitgliedsland.”
- “Der Präsident der Europäischen Kommission wird direkt von den Bürgern der Europäischen Union gewählt.”
- “Das Europäische Parlament wird direkt von den Bürgern der EU gewählt.”
Die Befragten konnten antworten, dass die jeweilige Aussage wahr oder falsch war. Die Antworten wurden entsprechend als richtig = 1 oder falsch = 0 codiert.4
Sie finden die Variablen im Datensatz mit den Namen wissen1, wissen2, .... Für die Auswertung wurde ein Summenindex über alle 9 Frageitems gebildet (M=6.73, SD=1.38).
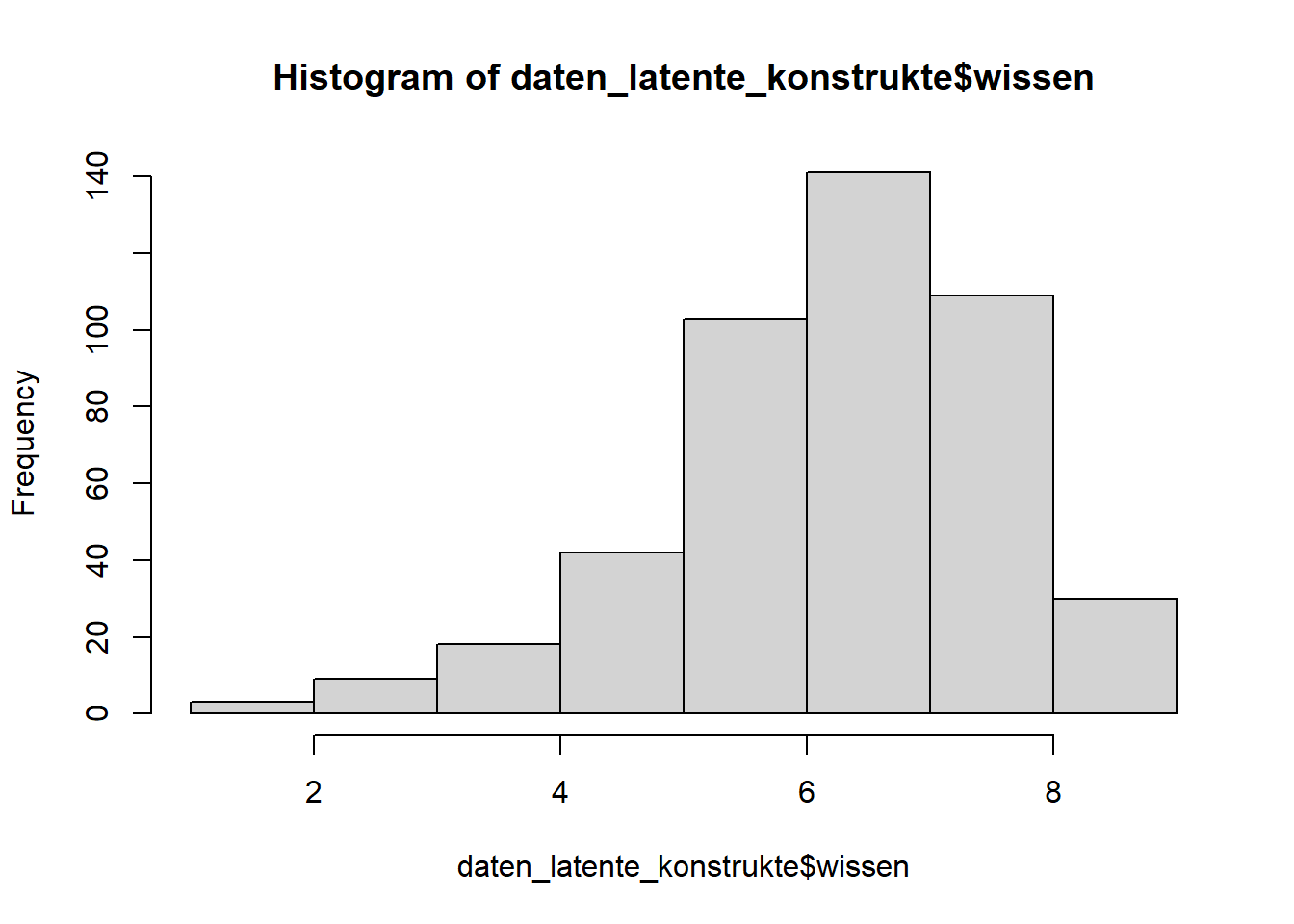
Übungsfrage
- Warum ist die visuelle Inspektion der Verteilung sinnvoll?
- Was ist problematisch bei der visuellen Verteilung mittels Histogram?
An dieser Stelle wollen wir das Sample mit einem Mediansplit in zwei ungefähr gleich große Gruppen teilen, da wir an anderer Stelle noch einmal Gruppen gegenüberstellen wollen.
#Neue dichotome Wissensvariable bilden
median(daten_latente_konstrukte$wissen)## [1] 7daten_latente_konstrukte$wissen_dichotom <- ifelse(daten_latente_konstrukte$wissen<7, 0, ifelse(daten_latente_konstrukte$wissen>=7, 1, NA))
counts2 <- table(daten_latente_konstrukte$wissen_dichotom)
barplot(counts2, main="Verteilung Wissen EU",
xlab="Richtige Antworten")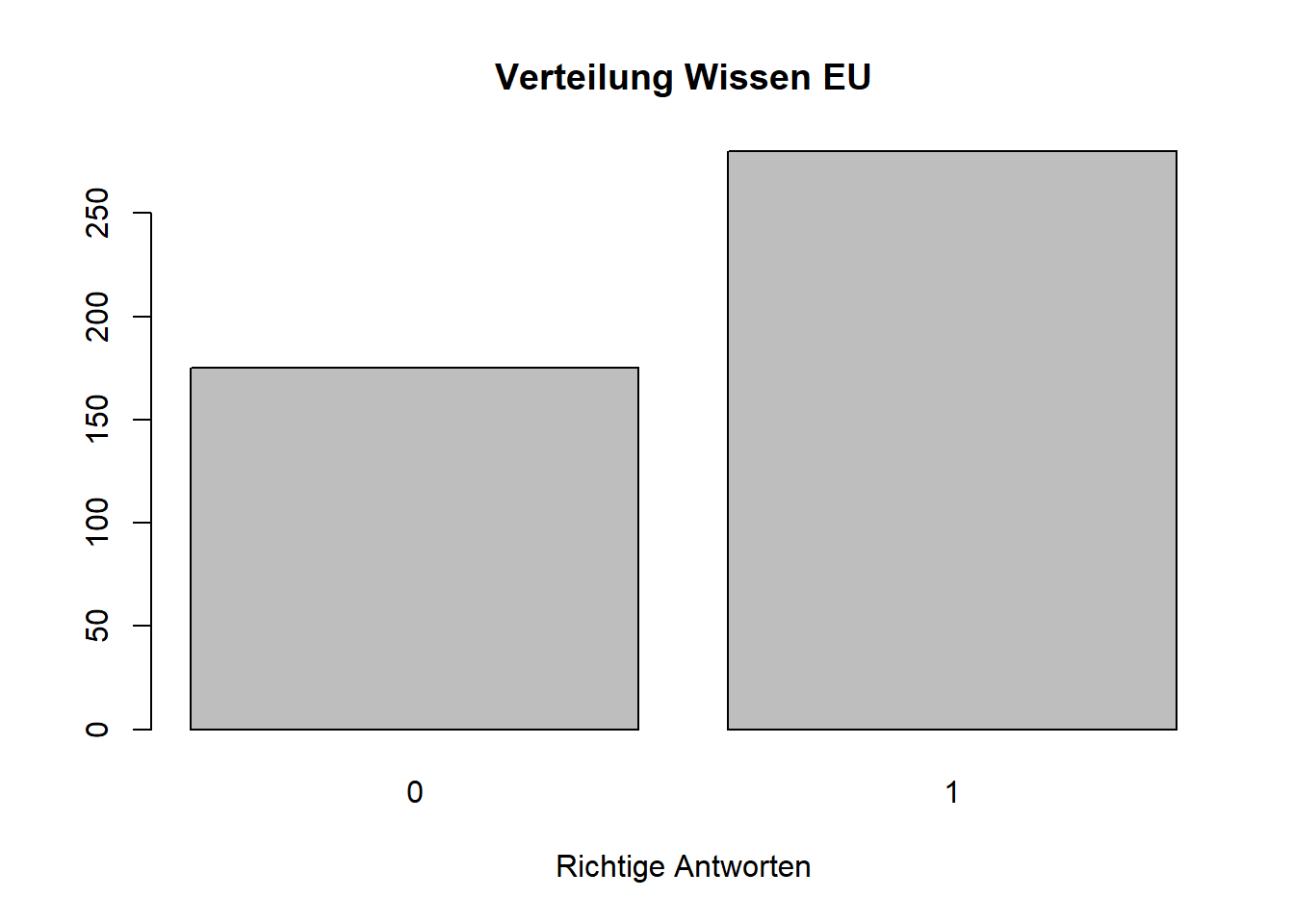
Naja, das hat ja halbwegs gut geklappt. Immerhin haben wir jetzt zwei Gruppen, die wir dann demnächst mal gegenüberstellen, also miteinander vergleichen können.