Chapter 14 APIs: YouTube
This chapter is still under construction.
In this chapter, we’ll learn about one way to access the YouTube API. We’ll do this using the package tuber, which is an R wrapper for the YouTube Data API v3 (the third iteration of the YouTube data wrapper). The YouTube Data API v3 (henceforth, YouTube API) has a standard rate limit of 10,000 units. Each “call” that you make to the API will cost a certain amount of units. Some types of actions are more costly than others, and larger queries will cost a greater number of units. You can make requests or pay for a larger rate limit (depending on the website’s policies).
To use any API, you will often need to get permission from a website to use their API. This is often half the work: figuring out how to get access and get R to recognize your API key.
14.1 Setting Up
14.1.1 Set Up Access
For the YouTube API, we’re going to take the following steps:
First, go to https://console.cloud.google.com/
Create a project. Projects are given permission to access one (or several) APIs.
Add the YouTube Data API v3 to your project. By default, this is not included. You can enable this by clicking the “Enable APIs and Services” button and enabling the YouTube Data API v3.
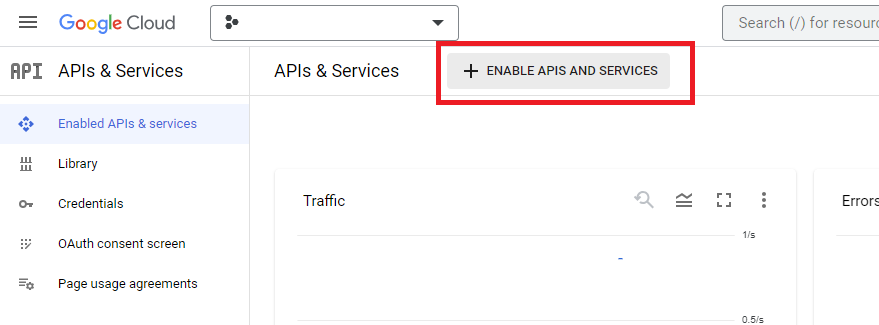
Once you enable this, you will then need to set up your authorization protocol to access the API. You will need to do three things: set up an OAuth consent screen, set up the API key credentials, and set up the OAuth 2.0 Client ID. The last one provides the credentials to use Tuber. My recommendation would be to:
1. Set up the OAuth consent screen for your “app”. For this, you will give the app a name, and provide your information as contact. Then, indicate no scope changes and no additional information. When you create this app, it will start in “testing.” But, you must change the app to “external” and “published.”
2. Once this is set up, go to the “Credentials” tab on the left hand side. A dropdown will appear.
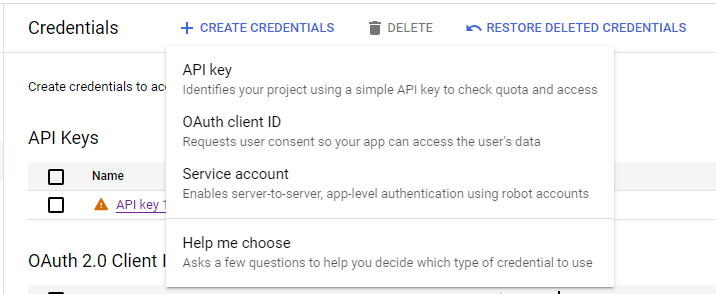
3. Set up the API key. Do not set any restrictions.
4. Set up a OAuth client ID. Use an application type of “Desktop app.”
Once you do this, the YouTube API will create a Client ID and Client Secret. You will use this information to set up tuber so that R is “communicating” with the YouTube API.
14.1.2 Set Up in R
For more on tuber, see the https://github.com/gojiplus/tuber and the https://cran.r-project.org/web/packages/tuber/tuber.pdf.
To set up tuber for use, you will need to install tuber (it is available in CRAN, but I recommend using the github version as it appears to have fewer errors and is the most up to date relative to the API). Let’s also load in tidyverse and remove scientific notations.
To authorize R for using the YouuTube API, we will use the function yt_oauth(). This function requires two (string) arguments: the Client ID will come first, and the Client Secret will come second.
#devtools::install_github("soodoku/tuber", build_vignettes = TRUE)
options(scipen = 999)
library(tidyverse)
library(tuber)
yt_oauth("", "") ### your client ID and client secrets should go hereOnce you do this, two things will happen. First, R will create a .httr-oauth file to store this authorization information (it may ask your permission before adding this file). Second, it will direct you to a page to give permission to R for accessing the API/app. Once you click confirm/accept, it should confirm the connection and direct you to a message like the one below.

Alright! Now we’re ready to use tuber.
A Note: This code takes about 650-1000 units to run
14.2 Searching for videos
Tuber has a variety of functions for searching for videos. The most common one used is yt_search(). By default, yt_search searches for videos, but you can also search for playlists and channels.
This is one of the functions that can easily wipe out your rate quota. The more videos you ask for, the faster you’ll reach your rate limit. In fact, you might hit the rate limit even before finishing the query. For this reason, I recommend querying for no more than 50 or 100 videos at a time. Querying by channel or user will also make a YouTube project more feasible. Another way to limit the query is by indicating a timeframe.
# DON'T DO THIS. IT WILL HIT YOUR RATE LIMIT QUICKLY.
# But if you wanted the "simplest" query possible, this is what it would look like.
#election <- yt_search("election")For our example, let’s focus on the kurzgesagt account. Kurzgesagt is a science education channel with videos about big things like stars and galaxies and small things like ants and bacteria.
In this query below, we will search for videos with the word “science” in their title or description from the Channel Kurzgesagt (ID: “UCsXVk37bltHxD1rDPwtNM8Q”) that were published from March 15 to December 31, 2020.
kurzgesagt <- yt_search("science",
channel_id = "UCsXVk37bltHxD1rDPwtNM8Q",
published_after = "2020-03-15T00:00:00Z",
published_before = "2020-12-31T00:00:00Z",
max_results = 10) #I like to indicate a max result, but this only seems to work half the time## Auto-refreshing stale OAuth token.## Rows: 17
## Columns: 17
## $ video_id <chr> "QImCld9YubE", "dSu5sXmsur4", "ck4RGeoHFko", "E1KkQrFEl2I", "y8XvQNt26KI", "B3QTAgHlwEg", "ipVxxxqwBQw", "3mnSDifDSxQ", "gLZJlf~
## $ publishedAt <chr> "2020-05-10T12:30:08Z", "2020-10-27T15:00:02Z", "2020-07-12T12:30:23Z", "2020-11-10T15:00:26Z", "2020-08-16T12:29:23Z", "2020-0~
## $ channelId <chr> "UCsXVk37bltHxD1rDPwtNM8Q", "UCsXVk37bltHxD1rDPwtNM8Q", "UCsXVk37bltHxD1rDPwtNM8Q", "UCsXVk37bltHxD1rDPwtNM8Q", "UCsXVk37bltHxD~
## $ title <chr> "Why Are You Alive <U+2013> Life, Energy & ATP", "Geoengineering: A Horrible Idea We Might Have to Do", "What Is Intelligence? Whe~
## $ description <chr> "Get Merch designed with <U+2764> from https://kgs.link/shop-121 Join the Patreon Bird Army https://kgs.link/patreon <U+25BD><U+25BD> More infos ...~
## $ thumbnails.default.url <chr> "https://i.ytimg.com/vi/QImCld9YubE/default.jpg", "https://i.ytimg.com/vi/dSu5sXmsur4/default.jpg", "https://i.ytimg.com/vi/ck4~
## $ thumbnails.default.width <chr> "120", "120", "120", "120", "120", "120", "120", "120", "120", "120", "120", "120", "120", "120", "120", "120", "120"
## $ thumbnails.default.height <chr> "90", "90", "90", "90", "90", "90", "90", "90", "90", "90", "90", "90", "90", "90", "90", "90", "90"
## $ thumbnails.medium.url <chr> "https://i.ytimg.com/vi/QImCld9YubE/mqdefault.jpg", "https://i.ytimg.com/vi/dSu5sXmsur4/mqdefault.jpg", "https://i.ytimg.com/vi~
## $ thumbnails.medium.width <chr> "320", "320", "320", "320", "320", "320", "320", "320", "320", "320", "320", "320", "320", "320", "320", "320", "320"
## $ thumbnails.medium.height <chr> "180", "180", "180", "180", "180", "180", "180", "180", "180", "180", "180", "180", "180", "180", "180", "180", "180"
## $ thumbnails.high.url <chr> "https://i.ytimg.com/vi/QImCld9YubE/hqdefault.jpg", "https://i.ytimg.com/vi/dSu5sXmsur4/hqdefault.jpg", "https://i.ytimg.com/vi~
## $ thumbnails.high.width <chr> "480", "480", "480", "480", "480", "480", "480", "480", "480", "480", "480", "480", "480", "480", "480", "480", "480"
## $ thumbnails.high.height <chr> "360", "360", "360", "360", "360", "360", "360", "360", "360", "360", "360", "360", "360", "360", "360", "360", "360"
## $ channelTitle <chr> "Kurzgesagt <U+2013> In a Nutshell", "Kurzgesagt <U+2013> In a Nutshell", "Kurzgesagt <U+2013> In a Nutshell", "Kurzgesagt <U+2013> In a Nutshell", "Kurzge~
## $ liveBroadcastContent <chr> "none", "none", "none", "none", "none", "none", "none", "none", "none", "none", "none", "none", "none", "none", "none", "none",~
## $ publishTime <chr> "2020-05-10T12:30:08Z", "2020-10-27T15:00:02Z", "2020-07-12T12:30:23Z", "2020-11-10T15:00:26Z", "2020-08-16T12:29:23Z", "2020-0~Note that the search can take boolean functions (- for NOT and | for OR). Use ?yt_search to learn more.
If you wanted to get all the videos from a channel, you could also use get_all_channel_video_stats(). While this is less flexible (e.g., more difficult to indicate a timeframe), it can also be useful if you want all the videos from one account, and may take up less quota.
14.3 Channel Information
Sometimes, you may want to look for more information about the channel. You can find some of this information using get_channel_stats(). In addition to getting information about views and subscribers, you can also see the description and country-location of the channel.
## Channel Title: Kurzgesagt <U+2013> In a Nutshell
## No. of Views: 2442047343
## No. of Subscribers: 21100000
## No. of Videos: 19114.4 Playlist Information
Sometimes, rather than looking at a whole channel, you may be interested in specific playlists. This is especially common among vloggers and YouTube influences. Kurzgesagt, for example, have different playlists from different types of topics. To get information about a playlist, you will need to find the playlist ID (most easily found on YouTube).
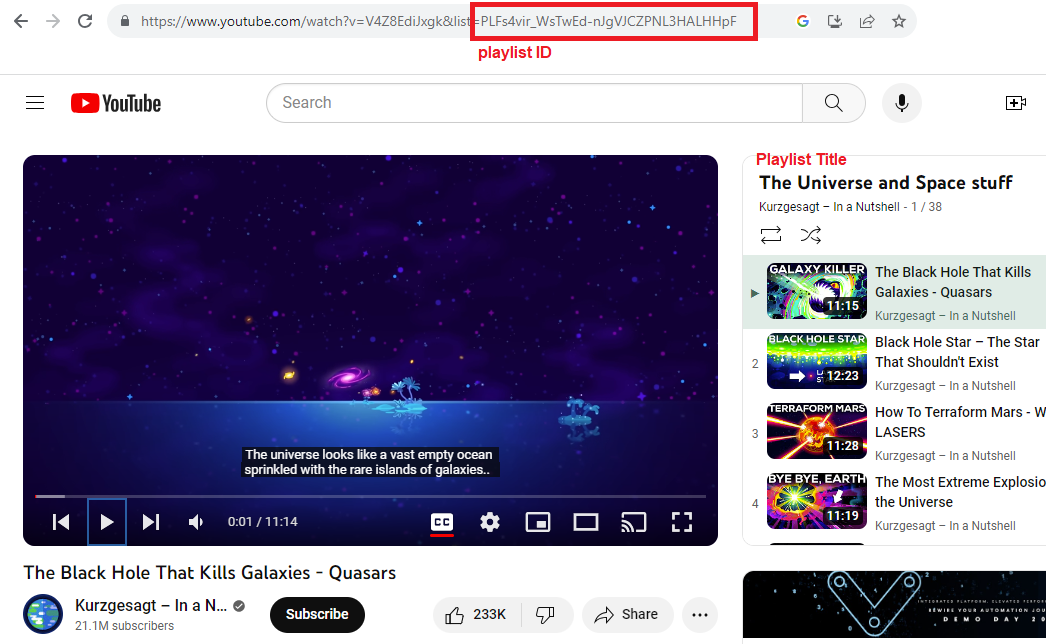
14.5 Video Information
In most cases, however, we’re interested in getting information about individual videos (or a set of videos). Two functions may be useful to you. First, is get_video_details(). This provides information about the video, including the title, description and the time it was posted. The information gathered this way tends to be static (e.g., the language of a video).
If you want to get the stats of a video (like the amount of times it is viewed or commented on), which may be constantly changing, use get_stats().
## id viewCount likeCount favoriteCount commentCount
## 1 YI3tsmFsrOg 32098505 782077 0 5292414.5.1 Looping This
If you want to get the stats for multiple videos, you can loop this using lapply(). Below, we’ll do this for the first 10 videos in our dataset. You’ll notice that get_stats() returns a data frame (which we will often convert into a list). In the case of the code below,
kurzgesagt_sample <- kurzgesagt[1:10,] #Take top 10 rows of this dataset
kurzgesagt_sample <- kurzgesagt_sample |> #let's pipe this data in
mutate(stats = lapply(kurzgesagt_sample$video_id, get_stats)) |> #use lapply() to loop the get_stats() function with each video ID
unnest_wider(stats) #unnest this information14.5.2 Video Comments
Another thing you may want to retrieve are the video comments of a particuar video. Importantly, this is another one of the functions that can easily wipe out your rate quota (though the cost of retrieving individual video comments is smaller than the cost of the video searches). For this reason, comments have a default quota of 100. If you indicate a larger number than 100, it will default to all the comments.
Let’s get 25 comment theads from YI3tsmFsrOg, which is the video we used to earlier. The details, gathered through get_video_details(), indicates that the name of this video is “The Deadliest Being on Planet Earth – The Bacteriophage”
video_comments <- get_comment_threads(filter = c(video_id="YI3tsmFsrOg"), max_results = 25)
#head(video_comments, 5)
kable(head(video_comments, 5), format = "markdown") #looks at the first 5 comments| channelId | videoId | textDisplay | textOriginal | authorDisplayName | authorProfileImageUrl | authorChannelUrl | authorChannelId.value | canRate | viewerRating | likeCount | publishedAt | updatedAt |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| UCsXVk37bltHxD1rDPwtNM8Q | YI3tsmFsrOg | You want to learn more about science? Check out our sciency products on the kurzgesagt shop <U+2013> all designed with love and produced with care. Getting something from the kurzgesagt shop is the best way to support us and to keep our videos free for everyone. <U+25BA><U+25BA> http://kgs.link/science (Worldwide Shipping Available) |
You want to learn more about science? Check out our sciency products on the kurzgesagt shop <U+2013> all designed with love and produced with care. |
Getting something from the kurzgesagt shop is the best way to support us and to keep our videos free for everyone.
<U+25BA><U+25BA> http://kgs.link/science
(Worldwide Shipping Available) |Kurzgesagt <U+2013> In a Nutshell |https://yt3.ggpht.com/ytc/AOPolaRZ9DHwcU8O9Z7p5yH6KvKHKwpU7ZHlWCXLkKN62A=s48-c-k-c0x00ffffff-no-rj |http://www.youtube.com/channel/UCsXVk37bltHxD1rDPwtNM8Q |UCsXVk37bltHxD1rDPwtNM8Q |TRUE |none |9235 |2019-02-08T13:53:38Z |2021-03-18T15:33:01Z |
|UCsXVk37bltHxD1rDPwtNM8Q |YI3tsmFsrOg |Not all bacteriophages reproduce rapidly?
Because Some phages that live in extreme environments(such as the polar regions and certain deserts) can take a long time assembling its offspring, otherwise the phages can wipe an entire colony of cryophiles (microbes that live in extremely cold environments).
The assembly rate of cryo phages can take up to over 10 years to make enough copies to burst out of the extremophile microbe,to repeat the sluggish infection process again.
This allows the bacteria around the infected cryophile microbe enough time to reproduce and replenish their population.
And the process can repeat itself over and over again. |Not all bacteriophages reproduce rapidly?
Because Some phages that live in extreme environments(such as the polar regions and certain deserts) can take a long time assembling its offspring, otherwise the phages can wipe an entire colony of cryophiles (microbes that live in extremely cold environments).
The assembly rate of cryo phages can take up to over 10 years to make enough copies to burst out of the extremophile microbe,to repeat the sluggish infection process again.
This allows the bacteria around the infected cryophile microbe enough time to reproduce and replenish their population.
And the process can repeat itself over and over again. |kvd1 |https://yt3.ggpht.com/ytc/AOPolaSkgmjkIDrjcP3rg-xyEuADvJiNTPp7ZAYIl4dUcA=s48-c-k-c0x00ffffff-no-rj |http://www.youtube.com/channel/UCIgfoou4DXpF6avFLT0_xJA |UCIgfoou4DXpF6avFLT0_xJA |TRUE |none |0 |2023-09-18T13:57:45Z |2023-09-18T13:57:45Z |
|UCsXVk37bltHxD1rDPwtNM8Q |YI3tsmFsrOg |The thingy from Steven Universe movie!!! |The thingy from Steven Universe movie!!! |Glorgy. |https://yt3.ggpht.com/HF0Wpgd0DNlIuj1_CUCtoIzqiBWB7Ro4b-dEWbJmFee8XIPkgZmnW53ok0hnWbRT-EUOu9UGEg=s48-c-k-c0x00ffffff-no-rj |http://www.youtube.com/channel/UCTW_u20_FAC5RdDU_De_rew |UCTW_u20_FAC5RdDU_De_rew |TRUE |none |0 |2023-09-18T12:02:00Z |2023-09-18T12:02:00Z |
|UCsXVk37bltHxD1rDPwtNM8Q |YI3tsmFsrOg |Bacteriophages equal W |Bacteriophages equal W |Chicken nugget Dont eat me |https://yt3.ggpht.com/UyGSsz1VqkupHR9aacUWoByZKhVunKb-cYazU8G32saYxwiQBRsXBo7B5wnhnQBfDEyZ45uXWg=s48-c-k-c0x00ffffff-no-rj |http://www.youtube.com/channel/UC6Y8m8zlTnEvWlD9T3WuZNg |UC6Y8m8zlTnEvWlD9T3WuZNg |TRUE |none |0 |2023-09-18T11:32:28Z |2023-09-18T11:32:28Z |
|UCsXVk37bltHxD1rDPwtNM8Q |YI3tsmFsrOg |can you do one on tardegrades? |can you do one on tardegrades? |LiamMC <U+0001F5F8> |https://yt3.ggpht.com/m9J3lDUB34AmReG4kLCAObXcK3REOT28wvTe3jwPVynzN_ASizICryf6ekF2rdVEGdphGp2muk0=s48-c-k-c0x00ffffff-no-rj |http://www.youtube.com/channel/UCATW6zBCXFCtVwZ_9yoY5DQ |UCATW6zBCXFCtVwZ_9yoY5DQ |TRUE |none |0 |2023-09-17T22:17:01Z |2023-09-17T22:17:01Z |
14.6 Bonus: Getting Captions
In addition to getting this information, you may also be interested in getting the closed captions of a video. Many YouTube videos will have closed captions by default (or transcriptions that are included). This allows researchers to circumvent the problem of speech-to-texting or transcribing the YouTube videos.
tuber has a function for getting captions (get_captions()). Unfortunately, this function can be tricky to use as it requires information about the caption track ID. An alternative approach is to use the package youtubecaption. This package is available on github.
Unlike the earlier functions in tuber, the function in youtubecaption requires a full url to use We can construct this url using paste0() a function that concatenates (or “pastes”) two substrings. As with the comments, let’s use the same video about “The Bacteriophage.”
#remotes::install_github("jooyoungseo/youtubecaption")
library(youtubecaption)
url_start <- "https://www.youtube.com/watch?v=" #this is the start of the URL
stats$id #displays the video id ## [1] "YI3tsmFsrOg"## [1] "YI3tsmFsrOg"url_all <- paste0(url_start, stats$id) #this concatenates/pastes the start of the URL with the video ID
captions_youtubecaption <- get_caption(url_all) #this will yield the same result
head(captions_youtubecaption)## # A tibble: 6 x 5
## segment_id text start duration vid
## <int> <chr> <dbl> <dbl> <chr>
## 1 1 [Music] 0 1.42 YI3tsmFsrOg
## 2 2 A war has been raging for billions of years, 1.42 2.92 YI3tsmFsrOg
## 3 3 killing trillions every single day, while we don't even notice. 4.34 5.12 YI3tsmFsrOg
## 4 4 The war is fought by the single deadliest entity on our planet: 9.7 4.08 YI3tsmFsrOg
## 5 5 the bacteriophage 13.8 1.76 YI3tsmFsrOg
## 6 6 or 'phage' for short. 15.5 1.65 YI3tsmFsrOg14.7 Other APIs
Want to learn more about the youtube API? Check out these guides:
* Scraping Youtube comments with Youtube API and R, Youtube tutorial (2020)
* Using tuber and purrr together
* A very short tutorial on tuber
While this tutorial focuses on the YouTube API, there are many other APIs that may be of interest.
* APIs for social scientists
+ This is a great resources for learning about different APIs and what is necessary to get keys for them
And, moving beyond just social media APIs, you may be interested in retrieving APIs from a variety of other data sources. To do this, you’ll want to learn more about the httr2 package (formerly httr, learn more about the difference here). I’ve provided some tutorials below:
* Accessing Web APIs, INFO201 Textbook
* Using httr::GET to get data from an API, Youtube tutorial (2022)
* Getting starting with APIs in R using httr and jsonlite
* R and Rest APIs, Youtube tutorial (2023)