Chapter 8 Data Cleaning

Hello! In this tutorial, we’ll learn more about dplyr a tidyverse package that helps you manipulate data when doing data science. To work through this material, we’ll use the crowdtangle_barbenheimer_2023.csv dataset, which includes Facebook posts about the Barbenheimer meme.
#install.packages("janitor")
library(tidyverse) #loading tidyverse will load dplyr
library(janitor) #this is a new package that we will use to clean up the name of our variables
sm_data <- read_csv("data/crowdtangle_barbenheimer_2023.csv") |> clean_names() # make sure this file is in your working directory!## Warning: One or more parsing issues, call `problems()` on your data frame for details, e.g.:
## dat <- vroom(...)
## problems(dat)## Rows: 16794 Columns: 41
## -- Column specification -------------------------------------------------------------------------------------------------------------------------------------------
## Delimiter: ","
## chr (18): Page Name, User Name, Page Category, Page Admin Top Country, Page Description, Likes at Posting, Post Created, Type, Video Share Status, Is Video Ow...
## dbl (15): Facebook Id, Followers at Posting, Likes, Comments, Shares, Love, Wow, Haha, Sad, Angry, Care, Post Views, Total Views, Total Views For All Crosspos...
## num (2): Total Interactions, Total Interactions (weighted — Likes 1x Shares 1x Comments 1x Love 1x Wow 1x Haha 1x Sad 1x Angry 1x Care 1x )
## lgl (3): Sponsor Id, Sponsor Name, Sponsor Category
## dttm (1): Page Created
## date (1): Post Created Date
## time (1): Post Created Time
##
## i Use `spec()` to retrieve the full column specification for this data.
## i Specify the column types or set `show_col_types = FALSE` to quiet this message.## spc_tbl_ [16,794 x 41] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
## $ page_name : chr [1:16794] "Ghost Killer Entertainment" "Jetpack Cave" "Babe" "Jetpack Cave" ...
## $ user_name : chr [1:16794] "GhostKillerEntertainment" "JetpackCave" "babedotnet" "JetpackCave" ...
## $ facebook_id : num [1:16794] 100044381711160 100063550571635 100064803423556 100063550571635 100044341363521 ...
## $ page_category : chr [1:16794] "RECORD_LABEL" "ENTERTAINMENT_SITE" "MEDIA_NEWS_COMPANY" "ENTERTAINMENT_SITE" ...
## $ page_admin_top_country : chr [1:16794] "US" "MX" "GB" "MX" ...
## $ page_description : chr [1:16794] "Ghost Killer Entertainment:\nRecord Label / Music Promotion Company\nEst. 2014\n" "<U+00A1>Hola! Bienvenidos a Jetpack Cave <U+0001F31F> <U+00A1>un espacio donde encontraras las novedades del mu"| __truncated__ "For girls who don't give a fuck\n\n" "<U+00A1>Hola! Bienvenidos a Jetpack Cave <U+0001F31F> <U+00A1>un espacio donde encontraras las novedades del mu"| __truncated__ ...
## $ page_created : POSIXct[1:16794], format: "2017-05-09 05:02:02" "2019-06-07 02:31:45" "2016-05-03 21:51:20" "2019-06-07 02:31:45" ...
## $ likes_at_posting : chr [1:16794] "686064" "402302" "1323914" "409135" ...
## $ followers_at_posting : num [1:16794] 882069 413868 1389225 420993 292210 ...
## $ post_created : chr [1:16794] "2023-07-22 10:37:12 CDT" "2023-07-18 11:10:12 CDT" "2023-07-26 06:50:02 CDT" "2023-07-25 12:00:07 CDT" ...
## $ post_created_date : Date[1:16794], format: "2023-07-22" "2023-07-18" "2023-07-26" "2023-07-25" ...
## $ post_created_time : 'hms' num [1:16794] 10:37:12 11:10:12 06:50:02 12:00:07 ...
## ..- attr(*, "units")= chr "secs"
## $ type : chr [1:16794] "Photo" "Photo" "Photo" "Photo" ...
## $ total_interactions : num [1:16794] 195095 145913 112162 103261 89916 ...
## $ likes : num [1:16794] 54601 24812 44516 11170 62449 ...
## $ comments : num [1:16794] 3308 3743 852 1381 301 ...
## $ shares : num [1:16794] 41801 12416 9333 16146 5536 ...
## $ love : num [1:16794] 17270 36791 3121 8382 1236 ...
## $ wow : num [1:16794] 320 461 272 315 146 97 456 56 196 14 ...
## $ haha : num [1:16794] 77094 66519 53840 65550 20115 ...
## $ sad : num [1:16794] 20 49 10 7 13 10 5 21 8 2 ...
## $ angry : num [1:16794] 5 16 4 6 0 8 1 5 3 1 ...
## $ care : num [1:16794] 676 1106 214 304 120 ...
## $ video_share_status : chr [1:16794] NA NA NA NA ...
## $ is_video_owner : chr [1:16794] "-" "-" "-" "-" ...
## $ post_views : num [1:16794] 0 0 0 0 0 0 0 0 0 0 ...
## $ total_views : num [1:16794] 0 0 0 0 0 0 0 0 0 0 ...
## $ total_views_for_all_crossposts : num [1:16794] 0 0 0 0 0 0 0 0 0 0 ...
## $ video_length : chr [1:16794] "N/A" "N/A" "N/A" "N/A" ...
## $ url : chr [1:16794] "https://www.facebook.com/100044381711160/posts/829033098586073" "https://www.facebook.com/100063550571635/posts/806119938183018" "https://www.facebook.com/100064803423556/posts/665983275571781" "https://www.facebook.com/100063550571635/posts/810761124385566" ...
## $ message : chr [1:16794] "Check out our Emo spotify playlist! http://bit.ly/EmoNeverDies:=:https://open.spotify.com/playlist/3czha2tGePoOcVI4xwa3j3" "<U+00A1>QUIERE SER KEN! <U+0001FA77> Cillian Murphy (Oppenheimer) coment<U+00F3> que esta abierto a interpretar"| __truncated__ "The true Barbenheimer experience" "<U+00A1>BARBENHEIMER ES REAL! En un cine de Estados Unidos durante una funci<U+00F3>n de 'Oppenheimer' hubo un "| __truncated__ ...
## $ link : chr [1:16794] "https://www.facebook.com/photo.php?fbid=829033051919411&set=a.723874642435253&type=3" "https://www.facebook.com/photo.php?fbid=806119904849688&set=a.448295013965514&type=3" "https://www.facebook.com/photo.php?fbid=665983258905116&set=a.598827208954055&type=3" "https://www.facebook.com/photo.php?fbid=810761107718901&set=a.448295013965514&type=3" ...
## $ final_link : chr [1:16794] NA NA NA NA ...
## $ image_text : chr [1:16794] "sunny jay real estate @cleaming_ this was the original barbenheimer The Black Parade Hannah Montana ROMANEE LAN"| __truncated__ "<U+00BF>Qu<U+00E9> si interpretar<U+00ED>a a Claro,por Claro, por Ken en 'Barbie 2'? ACK JEAVE CAVE ETPACK supu"| __truncated__ "Britt BrittRivera Rivera @kindamoviesnob My sister just saw Oppenheimer and something went wrong and half the s"| __truncated__ "= <U+65E5> JETPACK ETPACK CAVE EVANS BLACKETT MS Eso ya compens<U+00F3> el precio del boleto." ...
## $ link_text : chr [1:16794] NA NA NA NA ...
## $ description : chr [1:16794] NA NA NA NA ...
## $ sponsor_id : logi [1:16794] NA NA NA NA NA NA ...
## $ sponsor_name : logi [1:16794] NA NA NA NA NA NA ...
## $ sponsor_category : logi [1:16794] NA NA NA NA NA NA ...
## $ total_interactions_weighted_likes_1x_shares_1x_comments_1x_love_1x_wow_1x_haha_1x_sad_1x_angry_1x_care_1x: num [1:16794] 195095 145913 112162 103261 89916 ...
## $ overperforming_score : num [1:16794] 63.99 7.49 455.94 6.03 48.73 ...
## - attr(*, "spec")=
## .. cols(
## .. `Page Name` = col_character(),
## .. `User Name` = col_character(),
## .. `Facebook Id` = col_double(),
## .. `Page Category` = col_character(),
## .. `Page Admin Top Country` = col_character(),
## .. `Page Description` = col_character(),
## .. `Page Created` = col_datetime(format = ""),
## .. `Likes at Posting` = col_character(),
## .. `Followers at Posting` = col_double(),
## .. `Post Created` = col_character(),
## .. `Post Created Date` = col_date(format = ""),
## .. `Post Created Time` = col_time(format = ""),
## .. Type = col_character(),
## .. `Total Interactions` = col_number(),
## .. Likes = col_double(),
## .. Comments = col_double(),
## .. Shares = col_double(),
## .. Love = col_double(),
## .. Wow = col_double(),
## .. Haha = col_double(),
## .. Sad = col_double(),
## .. Angry = col_double(),
## .. Care = col_double(),
## .. `Video Share Status` = col_character(),
## .. `Is Video Owner?` = col_character(),
## .. `Post Views` = col_double(),
## .. `Total Views` = col_double(),
## .. `Total Views For All Crossposts` = col_double(),
## .. `Video Length` = col_character(),
## .. URL = col_character(),
## .. Message = col_character(),
## .. Link = col_character(),
## .. `Final Link` = col_character(),
## .. `Image Text` = col_character(),
## .. `Link Text` = col_character(),
## .. Description = col_character(),
## .. `Sponsor Id` = col_logical(),
## .. `Sponsor Name` = col_logical(),
## .. `Sponsor Category` = col_logical(),
## .. `Total Interactions (weighted <U+2014> Likes 1x Shares 1x Comments 1x Love 1x Wow 1x Haha 1x Sad 1x Angry 1x Care 1x )` = col_number(),
## .. `Overperforming Score` = col_double()
## .. )
## - attr(*, "problems")=<externalptr>8.1 filter()
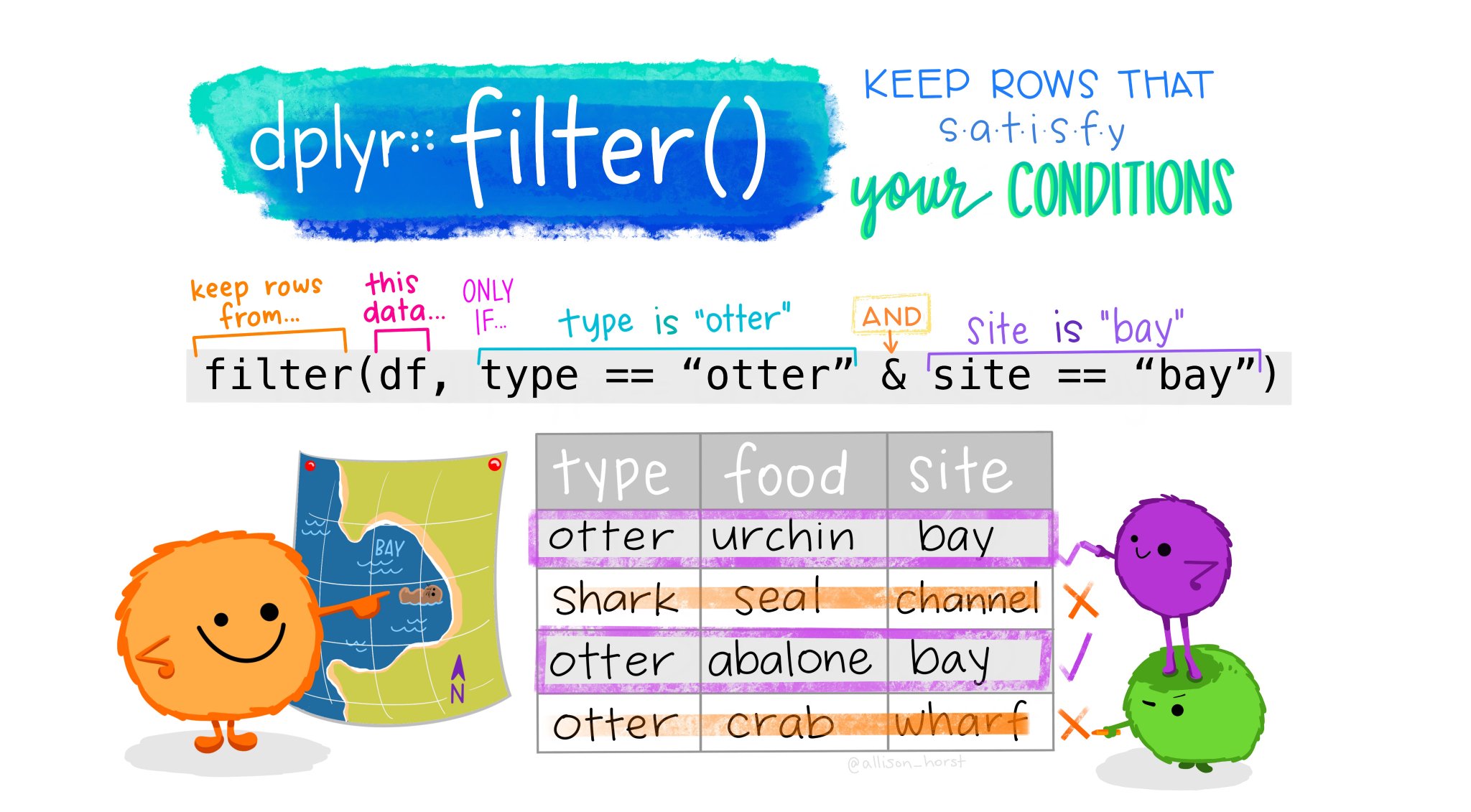
We use filter() to subset the dataset based on information in a column. For example, if we wanted to only see the responses from Texas, we could filter by the column name (i.e., the variable) stcode. To use filter() this way, we will need two arguments: the dataset you are using (in our case, covid_po) and the logical condition for the filter (in this case, when page_admin_top_country is "US").
## Rows: 6,725
## Columns: 41
## $ page_name <chr> "Ghost Killer Entertainment", "amBi - Your Bi S~
## $ user_name <chr> "GhostKillerEntertainment", "amBiSocial", "cree~
## $ facebook_id <dbl> 100044381711160, 100064591063472, 1000644379799~
## $ page_category <chr> "RECORD_LABEL", "ACTIVITY_GENERAL", "MEDIA_NEWS~
## $ page_admin_top_country <chr> "US", "US", "US", "US", "US", "US", "US", "US",~
## $ page_description <chr> "Ghost Killer Entertainment:\nRecord Label / Mu~
## $ page_created <dttm> 2017-05-09 05:02:02, 2010-11-01 23:56:13, 2013~
## $ likes_at_posting <chr> "686064", "250511", "13544", "76098", "44239", ~
## $ followers_at_posting <dbl> 882069, 256861, 15442, 118457, 49495, 1020431, ~
## $ post_created <chr> "2023-07-22 10:37:12 CDT", "2023-07-27 16:51:44~
## $ post_created_date <date> 2023-07-22, 2023-07-27, 2023-07-23, 2023-07-31~
## $ post_created_time <time> 10:37:12, 16:51:44, 00:50:38, 00:16:46, 17:40:~
## $ type <chr> "Photo", "Photo", "Photo", "Photo", "Photo", "L~
## $ total_interactions <dbl> 195095, 79246, 42137, 41865, 35560, 33502, 3116~
## $ likes <dbl> 54601, 35480, 14153, 6159, 12973, 15907, 20125,~
## $ comments <dbl> 3308, 290, 550, 1456, 260, 582, 2586, 1953, 117~
## $ shares <dbl> 41801, 8709, 11893, 7898, 4466, 4079, 1710, 236~
## $ love <dbl> 17270, 7335, 11174, 565, 3136, 8122, 3632, 4434~
## $ wow <dbl> 320, 456, 13, 71, 18, 30, 90, 233, 24, 161, 20,~
## $ haha <dbl> 77094, 26719, 4085, 25614, 14454, 4397, 2887, 2~
## $ sad <dbl> 20, 5, 0, 8, 11, 2, 6, 5, 2, 36, 1, 4, 40, 2, 6~
## $ angry <dbl> 5, 1, 1, 2, 2, 2, 6, 7, 7, 45, 0, 3, 78, 8, 155~
## $ care <dbl> 676, 251, 268, 92, 240, 381, 122, 195, 110, 100~
## $ video_share_status <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,~
## $ is_video_owner <chr> "-", "-", "-", "-", "-", "-", "-", "-", "-", "-~
## $ post_views <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,~
## $ total_views <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,~
## $ total_views_for_all_crossposts <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,~
## $ video_length <chr> "N/A", "N/A", "N/A", "N/A", "N/A", "N/A", "N/A"~
## $ url <chr> "https://www.facebook.com/100044381711160/posts~
## $ message <chr> "Check out our Emo spotify playlist! http://bit~
## $ link <chr> "https://www.facebook.com/photo.php?fbid=829033~
## $ final_link <chr> NA, NA, NA, NA, NA, "https://kotaku.com/barbie-~
## $ image_text <chr> "sunny jay real estate @cleaming_ this was the ~
## $ link_text <chr> NA, NA, NA, NA, NA, "Before Barbenheimer, There~
## $ description <chr> NA, NA, NA, NA, NA, "Doom Eternal and Animal Cr~
## $ sponsor_id <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,~
## $ sponsor_name <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,~
## $ sponsor_category <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,~
## $ total_interactions_weighted_likes_1x_shares_1x_comments_1x_love_1x_wow_1x_haha_1x_sad_1x_angry_1x_care_1x <dbl> 195095, 79246, 42137, 41865, 35560, 33502, 3116~
## $ overperforming_score <dbl> 63.99, 172.27, NA, 170.88, 143.97, 25.21, 34.51~We could also do this with numerical information. For example, maybe we only want to look at posts from U.S. Facebook pages with at least 15 like reactions. We can do this by filtering from the likes.
## [1] 20058.2 select()
In some instances, you not only want to filter by variable information, but you also may want to focus on a specific number of variables. This is especially common when you are ingesting/bringing in external data (e.g., secondary data or data from quadratics). For our dataset, let’s select the following variables: the user name, the page category, the date it was posted, the message type, the message, the possible Facebook reactions (likes, love, wow, haha, sad, angry, care), and the post type
sm_data_select <- sm_data %>%
select(user_name, page_category, post_created, type, message, likes, love, wow, haha, sad, angry, care)
glimpse(sm_data_select)## Rows: 16,794
## Columns: 12
## $ user_name <chr> "GhostKillerEntertainment", "JetpackCave", "babedotnet", "JetpackCave", "ReviewMovieMaiPhen", "thegoodfilms", "amBiSocial", "JustAshotttt",~
## $ page_category <chr> "RECORD_LABEL", "ENTERTAINMENT_SITE", "MEDIA_NEWS_COMPANY", "ENTERTAINMENT_SITE", "MOVIE_WRITER", "EDU_SITE", "ACTIVITY_GENERAL", "MOVIE", ~
## $ post_created <chr> "2023-07-22 10:37:12 CDT", "2023-07-18 11:10:12 CDT", "2023-07-26 06:50:02 CDT", "2023-07-25 12:00:07 CDT", "2023-07-25 06:00:36 CDT", "202~
## $ type <chr> "Photo", "Photo", "Photo", "Photo", "Photo", "Photo", "Photo", "Photo", "Photo", "Photo", "Photo", "Photo", "Photo", "Photo", "Photo", "Pho~
## $ message <chr> "Check out our Emo spotify playlist! http://bit.ly/EmoNeverDies:=:https://open.spotify.com/playlist/3czha2tGePoOcVI4xwa3j3", "<U+00A1>QUIERE SER K~
## $ likes <dbl> 54601, 24812, 44516, 11170, 62449, 33888, 35480, 25347, 25259, 16781, 25098, 14153, 6159, 16500, 34470, 23074, 24522, 29325, 15097, 12973, ~
## $ love <dbl> 17270, 36791, 3121, 8382, 1236, 20070, 7335, 12286, 34825, 19046, 15071, 11174, 565, 969, 1171, 12374, 3909, 3590, 7683, 3136, 14713, 8122,~
## $ wow <dbl> 320, 461, 272, 315, 146, 97, 456, 56, 196, 14, 229, 13, 71, 20, 39, 16, 111, 1959, 31, 18, 168, 30, 90, 39, 233, 28, 24, 161, 124, 20, 18, ~
## $ haha <dbl> 77094, 66519, 53840, 65550, 20115, 8758, 26719, 18575, 139, 13988, 612, 4085, 25614, 21060, 3675, 81, 9319, 886, 4773, 14454, 120, 4397, 28~
## $ sad <dbl> 20, 49, 10, 7, 13, 10, 5, 21, 8, 2, 19, 0, 8, 3, 13, 2, 7, 102, 8, 11, 14, 2, 6, 115, 5, 2, 2, 36, 76, 1, 2, 4, 10, 3, 19, 3, 4, 4, 3, 40, ~
## $ angry <dbl> 5, 16, 4, 6, 0, 8, 1, 5, 3, 1, 6, 1, 2, 0, 9, 0, 11, 254, 5, 2, 5, 2, 6, 0, 7, 36, 7, 45, 23, 0, 0, 3, 4, 2, 15, 0, 1, 12, 5, 78, 2, 5, 0, ~
## $ care <dbl> 676, 1106, 214, 304, 120, 543, 251, 408, 464, 512, 240, 268, 92, 100, 162, 215, 155, 187, 234, 240, 203, 381, 122, 220, 195, 193, 110, 100,~8.3 rename()
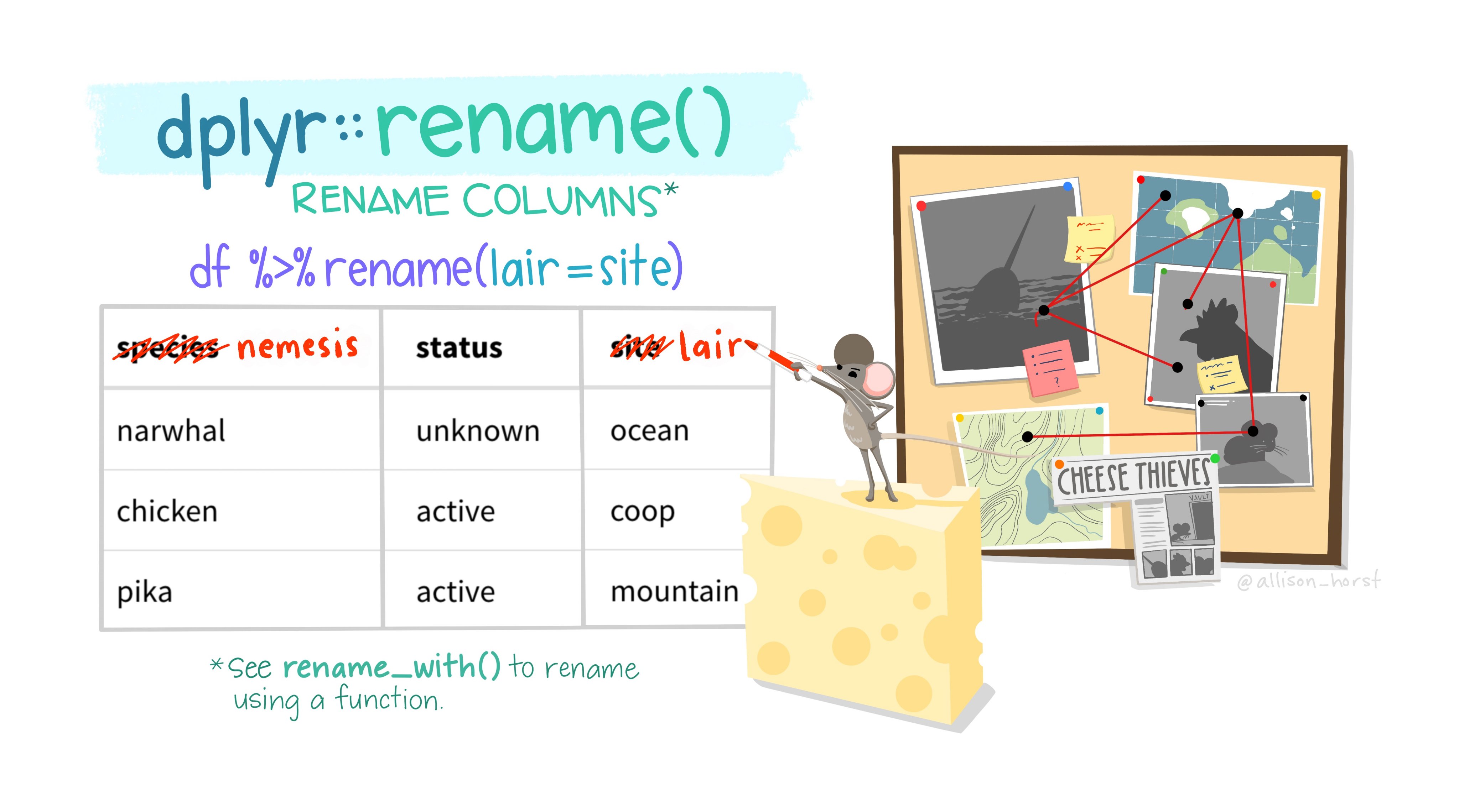
Want to rename a variable? You can use the function rename() to change a column. The way rename() work is by taking two arguments, the dataset you hope to use and the name change with the following format, new_name = old_name. You can even include more than one variable! Let’s see that in action below:
## [1] "user_name" "page_category" "post_created" "type" "message" "likes" "love" "wow" "haha"
## [10] "sad" "angry" "care"sm_data_rename <- sm_data_select %>%
dplyr::rename(datetime = post_created, like = likes)
colnames(sm_data_rename)## [1] "user_name" "page_category" "datetime" "type" "message" "like" "love" "wow" "haha"
## [10] "sad" "angry" "care"Notice how post_created and likes has now been changed to post_created and like.
8.4 arrange()
The function arrange() allows you to reorganize the rows based on the information in one variable. (in this case, we will use the like variable, which we just renamed above,)
## # A tibble: 6 x 12
## user_name page_category datetime type message like love wow haha sad angry care
## <chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 GhostKillerEntertainment RECORD_LABEL 2023-07-22 10:37:12 CDT Photo "Check out our Emo spotify playlist! http://~ 54601 17270 320 77094 20 5 676
## 2 JetpackCave ENTERTAINMENT_SITE 2023-07-18 11:10:12 CDT Photo "\u00a1QUIERE SER KEN! \U0001fa77 Cillian Mu~ 24812 36791 461 66519 49 16 1106
## 3 babedotnet MEDIA_NEWS_COMPANY 2023-07-26 06:50:02 CDT Photo "The true Barbenheimer experience" 44516 3121 272 53840 10 4 214
## 4 JetpackCave ENTERTAINMENT_SITE 2023-07-25 12:00:07 CDT Photo "\u00a1BARBENHEIMER ES REAL! En un cine de E~ 11170 8382 315 65550 7 6 304
## 5 ReviewMovieMaiPhen MOVIE_WRITER 2023-07-25 06:00:36 CDT Photo "Barbenheimer \u0e2a\u0e21\u0e31\u0e22\u0e15~ 62449 1236 146 20115 13 0 120
## 6 thegoodfilms EDU_SITE 2023-07-05 07:26:00 CDT Photo "Barbenheimer 2023. \U0001f91d\U0001f3fc \U0~ 33888 20070 97 8758 10 8 543## # A tibble: 16,794 x 12
## user_name page_category datetime type message like love wow haha sad angry care
## <chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 ReviewMovieMaiPhen MOVIE_WRITER 2023-07-25 06:00:36 CDT Photo "Barbenheimer \u0e2a\u0e21\u0e31\u0e22\u0e1~ 62449 1236 146 20115 13 0 120
## 2 GhostKillerEntertainment RECORD_LABEL 2023-07-22 10:37:12 CDT Photo "Check out our Emo spotify playlist! http:/~ 54601 17270 320 77094 20 5 676
## 3 babedotnet MEDIA_NEWS_COMPANY 2023-07-26 06:50:02 CDT Photo "The true Barbenheimer experience" 44516 3121 272 53840 10 4 214
## 4 amBiSocial ACTIVITY_GENERAL 2023-07-27 16:51:44 CDT Photo "#barbenheimer | Join amBi - Your Bi Social~ 35480 7335 456 26719 5 1 251
## 5 skittodigital TELECOM 2023-07-25 05:09:40 CDT Photo "barbie's palace \u09a8\u09be\u0995\u09bf O~ 34470 1171 39 3675 13 9 162
## 6 thegoodfilms EDU_SITE 2023-07-05 07:26:00 CDT Photo "Barbenheimer 2023. \U0001f91d\U0001f3fc \U~ 33888 20070 97 8758 10 8 543
## 7 CiberCubaNoticias NEWS_SITE 2023-07-24 09:00:11 CDT Link "La pel\u00edcula de Barbie rompe taquillas~ 29325 3590 1959 886 102 254 187
## 8 JustAshotttt MOVIE 2023-07-15 16:09:14 CDT Photo "5 days!" 25347 12286 56 18575 21 5 408
## 9 SomosComicsLat MEDIA_NEWS_COMPANY 2023-07-19 12:27:01 CDT Photo "Las puntuaciones en Rotten Tomatoes de 'Ba~ 25259 34825 196 139 8 3 464
## 10 PhillipChuJoy BLOGGER 2023-07-19 23:23:05 CDT Photo "Sobreviv\u00ed al \"Barbenheimer\". Ambas ~ 25098 15071 229 612 19 6 240
## # i 16,784 more rows# using arrange(variable) will order the numbers from smallest to largest
# adding a "-" in front of the variable reverses the order, so this will cause the rows to go from the largest to the smallestNotice here that the results of arrange are not saved. In order to do that, you need to assign it to a variable (either itself, or a new variable)
8.5 mutate()

You can use mutate() to create new variables. Below, we add to our data frame sm_data_rename by creating a variable to add all the reactions (this is different from “engagement” as comments do not count in this reaction metric.) To do this, we use numbers.
sm_data_rename <- sm_data_rename %>%
mutate(all_reactions = like + love + wow + haha + sad + angry + care) #modify sep = " " to change the separator!
#sm_data_rename$all_reactions #to see the variableTo use mutate(), we use an “equation” using the = sign. On the left side, we will write the name of the new variable (in this case, all_reactions). On the right side, we add all the variables we want to add by (variable1 + variable2 + … + variableN).
Another thing that might be worth learning is how to use the paste() function, which is how you combine strings. For example, maybe you want to combine the page category information with the post type. You can use paste() within mutate() to create this variable.
8.6 group_by() and summarize()
Finally, let’s learn about group_by() and summarize(), which is used to summarize numeric variables by categorial ones. For example, say we wanted to see whether videos get more likes than regular text posts. To check this, we can group by the type of the post, and then summarize the average of likes. Let’s try this now.
sm_data_rename %>%
group_by(type) %>% #group by the type of content
summarize(avg_likes = mean(like)) %>% #create a new variable, avg_likes, by getting the mean for each type
arrange(-avg_likes) #arrange the data so the avg_likes is high-to-low## # A tibble: 8 x 2
## type avg_likes
## <chr> <dbl>
## 1 Photo 205.
## 2 Native Video 92.7
## 3 Status 84.1
## 4 Link 67.5
## 5 Video 34.3
## 6 Live Video Complete 18.0
## 7 YouTube 11.3
## 8 Live Video Scheduled 3.13In this dataset, photos get the most likes (by far), followed by Native Videos, and Text posts (“Status”)
Learn more about group_by and summarize here.