Producing and Using Data in Cognitive Science
2025-01-02
1 Producing and using data in service of knowledge
1.1 Introduction
Welcome to the course ‘Producing and using data in Cognitive Science’. This course covers what would traditionally be included in a statistics course, plus some of a research methods course, plus some of a data science course.
The basic idea is the following: to answer scientific questions in cognitive science, we have to:
produce the right data, the data that have the best chance of answering our question;
handle those data right, organizing them, manipulating them in ways that are transparent, storing them permanently and making them accessible for the record;
use the data to make inferences that answer the question we set out to answer, and document transparently how we have done so;
communicate what we have done with the data, in the form of a clear and transparent paper or report.
A central principle that distinguishes science from other forms of activity is that all of the stages listed above should be completely transparent and reproducible by someone other than the original researcher. This is because science is a collective endeavour, not an individual one. Knowledge can only be produced and checked by a community of researchers scrutinizing, questioning, checking and improving what they each contribute.
Reproducibility means, for example, that researchers must describe the way they produced the data with sufficient detail and precision that someone else could repeat the experiment with a new sample of participants. This means that any necessary materials (or exact descriptions of them) must be available. Any operations the researchers have done to the data (calculating the values of some variables, excluding some cases, reorganising the dataset, and so on) should be completely documented so that someone else can perform them, either on the original dataset or on a new one. Then, the computations that have been made in order to make inferences from our data should be repeatable by an independent researcher, again, either reproducing those computations on the original dataset, or on a new one that they have gathered using the same methods. The way scientists do this in practice is to publish the raw data from each study, plus all the computer code used to analyze them, on a free website known as a repository, to go alongside their article or dissertation. Finally, it should be completely clear how the things that are written in a scientific article or dissertation relate to the data and code in the repository: how you get from the evidence to the verbal claims. Only if you complete all of these steps reproducibly have you executed a scientifically sound project. Working reproducibly is the central obligation of the scientist; it is a discipline to which they must always submit themselves. Whatever your supervisor might say, it is not necessary to work in a way that is novel or interesting to do good science. But it is necessary to work in a way that is reproducible.
The course will cover all the stages of producing and using data. As we go through, it will become clear that you can’t start to think about the analysis and use of your data, or the reporting, only after data collection. You have to start thinking about the data analysis way earlier, at the point where you design and plan your study. What is my research question? What is my hypothesis, or what are the alternative hypotheses I might entertain? What measurements and which comparisons do I need to make that will allow me to know whether a hypothesis is supported or not? What data do I need to rule out alternative explanations? What patterns in the data would I see if a hypothesis is supported, or if it is not? How will I look for these patterns?
You soon realise that you have to address these questions before the first data point is collected. You then set up a pipeline, or series of procedures, that defines the journey of your data, and the things that are done with them, from the beginning (when the study is just an idea) to the end (when the study is written up and the data and analysis code permanently archived). All the stages of the pipeline need to be transparent and reproducible.
1.2 Using the course
The course works in the following way. There are around 24 sessions of material. Each week in the class we will aim to cover 2 sessions, though we may spend more than one hour on some sessions. Some of the sessions are theoretical (presentation and discussion of concepts), but most are practical, in that they require you to do some R analysis and write some code.
In class, we will go through each session’s material as a group. The best thing to do is bring a laptop to class (and sort out a wifi connection). You will need to install R and RStudio. For the practical parts, you can work along at the same time as me, and I will work with my display shown on the big screen, and we will make sure we are all getting the same thing. For the theoretical parts, the important thing is to listen, think, and ask questions. If you are working through the course on your own, I hope you will find everything you need in these notes.
I can’t stress enough that you need to work through the material yourself again, after class, to consolidate it and experiment.
This year (September 2024) is the first year of the course, so I am writing the materials as we go along. The book will grow as we go, and I will try to keep it a couple of weeks ahead of where we are in the semester.
Data analysis using R is progressive; you can only manage to do the later things if you have understood and are comfortable with the earlier ones. So, if at any point you are struggling with R, go back to the opening weeks and work through them again. There are also many good R resources (websites and videos) on the web.
1.3 Questions, evidence, claims and knowledge
The point of science is to move along the chain from questions to knowledge. The questions we ask are called research questions. They can vary from the very general (how do humans decide what acts are morally permissible in a situation?) to the very specific (does the medication ibuprofen reduce the symptoms of depression?). Generally speaking, to address a question, we gather some relevant evidence, and use this to make a claim (yes, in my study, the depressive symptoms of people receiving ibuprofen did improve, so I claim that ibuprofen might reduce depression).
The claims made on the basis of an individual study are not yet knowledge. They are candidates for knowledge, but they should be considered candidates for further investigation, rather facts we can take for granted. Indeed, we know that most published findings are false, not in the sense that the researchers’ description of what happened in that one dataset is dishonest, but in the sense that the claims the researchers made turn out to be supported only in their dataset, and not in other datasets that are subsequently collected (Ioannidis 2005). In fact, we have some ability to estimate what proportion of published claims are generalisably true in cognitive science. This is due to the work of the Open Science Collaboration(Open Science Collaboration 2015). This group of researchers exactly repeated 100 recently published cognitive science studies. All of these studies had gone through the supposedly rigorous peer review process that leads to publication in the top journals. The claim that the original researchers had made in their studies was supported in the new data in 39% of the cases. In other words, over 60% of the patterns observed even in the studies published in the best journals turn out to be flukes of that one particular study or dataset. The researchers in those studies made claims that some more general regularity was operating, but more often than not, those claims failed to make the leap to the next stage, knowledge. The discovery that this was true is known as the replication crisis, and it has had a big impact in cognitive science.
The replication crisis means, in effect, that many claims in made in the cognitive science literature are not good candidates for knowledge. They are dead ends. The reasons for the replication crisis are multiple and complex. However, it is clear that a big part of the reason is that the ways we have produced and used data, historically, have been inadequate, in the sense of insufficiently rigorous. This course will aim to teach you best practices so that claims you make are more reliable, or, at least, you have appropriate uncertainty regarding their generalisability.
1.4 The hierarchy of evidence
Imagine there is a study that produces evidence that appears to support a claim. We agree that this is not yet knowledge. However, it makes a difference how much evidence the study contains. For example, did it produce the effect in one small sample, or was the sample very large? Was there a single sample from one population, or were there multiple samples from multiple populations all showing more or less the same result? The study should be given more weight the larger it is, and the more replication and generalisation it contains internally. Moreover, imagine now that there are two studies, independently finding the same thing. Now, we start to take the claim more seriously. And then three studies, and so on. At some point there are some claims that are so widely supported that we treat them as knowledge.
A useful way to think about this is what is called the hierarchy of evidence. The hierarchy of evidence exists in many forms reflecting different areas of research. A version suitable for cognitive science looks like this:
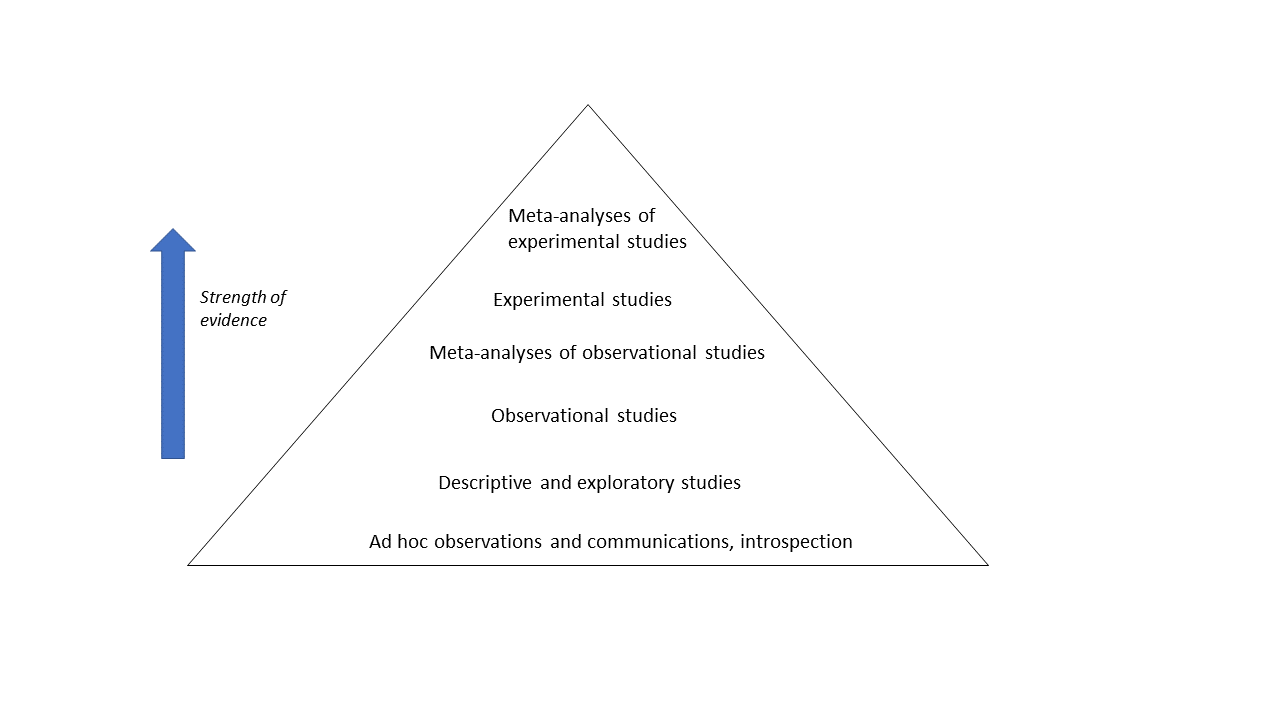
What the diagram shows is that there are weaker and stronger forms of evidence for claims in cognitive science. Ad hoc assertions, speculations based on introspection or personal experience, compelling novels, journalism, and so on belong on the bottom tier. That is, they are certainly not meaningless, but they are not very strong forms of evidence either. Above these are more systematic studies which are exploratory (meaning they do not specify a hypothesis ahead of time), or descriptive (meaning they do not develop a hypothesis at all). These forms of evidence are important; they are often the crucial step in developing ideas that subsequently get moved up the hierarchy. But, they do not yet offer explanations, still less explanations that we accept as established knowledge.
Above descriptive and exploratory studies are studies that test a hypothesis, but are observational rather than experimental. We will discuss these terms in week 2, but an observational one is one that observes what is already happening in the world, rather than intervening to establish cause and effect. Observational studies are the main form of evidence in many research areas where experimental intervention is not practically possible (this includes some very hard science areas, like in geology and astrophysics, as well as many areas of social and health sciences). Cognitive science, however, is an experimental discipline where experimental intervention, which allows stronger conclusions about cause and effect, is valued highly. Experimental evidence is the highest form of evidence in cognitive science.
At all levels of the pyramid, bigger studies (more participants, and ideally sampled from more diverse populations) provide stronger evidence for a general claim than smaller studies. More studies of the same phenomenon provides stronger evidence than fewer studies. When multiple studies exist that are studying more or less the same thing, their results can be integrated into meta-analyses. Meta-analyses pool all the information from the separate studies. They average across the quirks and good and bad luck of individual studies, to give a more precise answer to the research question. They can often also determine what methodological or contextual factors make the phenomenon of interest weaker or stronger. In the health sciences and increasingly in cognitive science, there would have to exist many many studies and a meta-analysis before we would start to count something as established.
Once there is a meta-analysis of experimental studies, are we happy to describe the claim as knowledge? That’s a tricky question. At this point, we would probably say that the claim is supported by robust or reliable evidence. This does not of course mean that people’s interpretation of why it happens, or what it means, is necessarily the right one. At this point, we can say with confidence that something happens, and does so reliably, but our understanding of why, and what is says about the mind, is always in a sense provisional.
1.5 Summary
Science is about moving along the chain from questions, to evidence, to claims, and eventually to knowledge. To make knowledge, we have to gradually accumulate evidence for our claims. As a community, we try to do this in stronger and stronger forms, to move up the hierarchy of evidence.
This session has introduced the idea that to create evidence on a research question of interest, we must produce data, handle them correctly, use them to make inferences, and communicate what we have done. We must do all of this reproducibly, which means that an outside observer can see what we have done and would be able to reproduce it themselves using resources that are freely available.