Chapter 3 Measurements, Mistakes and Misunderstandings
3.1 Types of Data
When we collect data, we will often organize the data into a table where the rows represent cases or units, and the columns represent variables that were measured on each case. An example is given below:
## Exercise SAT GPA Pulse Piercings GenderCode Sex
## 1 10 1210 3.13 54 0 1 Male
## 2 4 1150 2.50 66 3 0 Female
## 3 14 1110 2.55 130 0 1 Male
## 4 3 1120 3.10 78 0 1 Male
## 5 3 1170 2.70 40 6 0 Female
## 6 5 1150 3.20 80 4 0 Female
## 7 10 1320 2.77 94 8 0 Female
## 8 13 1370 3.30 77 0 1 Male
## 9 3 1100 2.80 60 7 0 Female
## 10 12 1370 3.70 94 2 0 Female
## 11 12 1170 2.09 63 2 0 Female
## 12 12 1150 2.90 54 0 1 Male
## 13 6 1300 3.08 66 4 0 Female
## 14 10 1200 3.86 59 4 0 Female
## 15 3 1200 3.00 88 4 0 FemaleThis example has both categorical variables (sometimes called qualitative) and quantitative variables. The variable Sex is categorical and has 2 possible values, Female and Male. Notice that the variable GenderCode, although it uses numbers, is also categorical, as the use of the number 0 for males and 1 for females is arbitrary.
The other variables are all quantitative, with the students’ GPA, SAT score, Pulse rate, number of hours per week of Exercise, and number of body Piercings.
3.2 Levels of Measurement
Beyond just qualitative vs quantitative variables, we sometimes talk about four Levels of Measurement, where types of data are arranged from weakest to strongest, in the sense of what sort of statistics can be computed.
3.3 Is Thirty-Nine Degrees Hot?
I took this photo. How do you think I might have been dressed that day?

Nominal level: this is the weakest type of data, where the variable is categorical or qualitative in nature. Examples include your religious preference and your favorite color.
Ordinal level: this is the next strongest form of data, and is the first one involving a quantitative variable. Ordinal data involves ``ranking’’. Examples include when you ranked your love of chocolate on a 1-to-10 scale, when you evaluate your instructors on a 1-to-5 scale (often called a Likert scale), and when a football coach ranks his three quarterbacks from 1 to 3, with 1 being the best player, 2 the second best, and 3 the worst.
Interval level: this is numerical data that goes beyond just ranking, but where there is no fixed zero point and the ratio between two numbers does not make sense. The standard example is temperature. For instance, suppose it is 30 degrees C in one city and 10 degrees in another. \[\frac{30}{10}=3\] But it does not make sense to say the first city is three times hotter, because if we use Fahrenheit instead, then the two cities are 86 degrees and 50 degrees, respectively, and the ratio is now \[\frac{86}{50}=1.72 \neq 3\]
Convert, Celsius to Fahrenheit: \[F=\frac{9}{5}C+32\]
Convert, Fahrenheit to Celsius: \[C=\frac{5}{9}(F-32)\]
- Ratio level: similar to ordinal level and usually treated the same in compuations. Here, there is a fixed zero point and the ratio between two numbers does make sense. For example, suppose the height of two indivuals are 6 feet tall and 5 feet tall. We can convert to inches, getting 72 and 60 inches, respectively. Multiply inches by 2.54 to get centimeters, getting 182.88 cm and 152.4 cm. The ratio is the same no matter which units you use.
\[\frac{6}{5}=\frac{72}{60}=\frac{182.88}{152.4}=1.2\]
When we use a variable to help understand or predict values of the another variable, we call the former the explanatory variable (sometimes called the independent variable, often denoted as \(X\)) and the latter the response variable (sometimes called the dependent variable, \(Y\)).
In the GPAGender data set, a college admissions officer might wish to predict the college GPA of new students, using the SAT score that they got when they took this test in high school. The explanatory variable is SAT and the response variable is GPA.
We can also use a categorical variable as the explanatory variable. If the response variable I want to understand is number of Piercings, I might notice that the female students tend to have a higher number (probably because most women have pierced ears, where most men do not) and I could use Sex as the explanatory variable.
3.4 Levels of Measurement at a restaurant
Suppose you go to Subway for lunch. Where might we run into the four levels of measurment when ordering lunch?
3.5 Reliability and Validity
A test (broadly defined) is a formal and systematic procedure for gathering information about a subject’s characteristics.
The obvious example of “tests” are what you think when you hear the word test; namely, in-class exams that are desired to assess how much you have learned about a particular topic(s). But the word “test”” can also refer to such things as a survey about your attitudes towards mathematics or a psychological assessment desired to determine if a person is mentally ill.
A low stakes test is a test in which no major, life-altering decisions will be made about a person. If you fill out a survey about your attitudes towards mathematics as part of a researcher’s study, that is low-stakes (nothing good or bad will happen to you based on the results).
A high stakes test is a test used for making a major decision about an individual person. The ACT or SAT test is an example (it to some extent determines what colleges you can or cannot be accpeted into). A test designed to see whether a young child should be placed into special education is also high-stakes.
Measurement is the process of quantifying or scoring performances on tests.
Physical measurements, such as your height or the circumference of your skull, are relatively easy to measure accurately. Non-physical measurements, such as your intelligence, your personality, or your attitudes towards mathematics, are more difficult to measure. For example, we can easily and accurately measure a person’s blood pressure, but it is more difficult to measure a person’s depression. There is a physical device that measures blood pressure, but there is no physical device that directly measures your depression. A psychologist might resort to a questionnaire to indirectly measure the concept of depression.
Reliability is the extent to which a test yield consistent results; the extent to which test scores are free of random error.
Test scores are never perfect; there are a multitude of reasons for measurement error. It is relatively easy to calculate the reliability of a test (using a statisic called Cronbach’s alpha that is related to the correlation coefficient that we will cover later).
Validity is the extent to which a test actually measures the concept that it is supposedly measuring (i.e. are we mearuing the right thing?)
Validity is harder to assess numerically than reliability.
We need to have reliability to have validity (if a test is not reliable, it cannot be valid), but reliability does not guarantee validity.
Here’s a silly example that explains the difference between reliability and validity: Suppose Dr. Mecklin becomes the head of the Honors program and has a theory that intelligence can be assessed by measuring the circumference of a person’s head. The idea behind this theory is that people with big heads have big brains and thus are more intelligent than other people. So during Freshman Orientation we use a tape measure to measure the size of everyone’s heads, and the 10% of students with the largest head circumference are admitted into the Honors program.
This test (i.e. measuring the size of the head) does have reliability. We can accurately measure the size of a person’s head with a tape measure. However, this test obviously does not have validity. We aren’t really measuring intelligence; we are merely measuring the size of a person’s head and maybe what size hat they would need to wear.
A more serious example is the issue of standardized tests. For example, almost all college students in the U.S. took either the ACT and/or the SAT. Are these tests reliable? The answer is YES (the testing companies hire statisticians and specialists in test-writing and measurement to make sure that the tests are reliable). Are these tests valid? The answer is MAYBE (experts in the field have different opinions; some believe the tests are valid and other strongly believe that these tests are invalid).
A test needs to be both reliable and valid to be worthwhile.
3.6 Seven Pitfalls
1. Deliberate Bias
The question “Because it is cruel and unusual punishment, do you believe that the death penalty should be banned?” is a leading question that is deliberately trying to steer the respondents to a particular answer that is viewed as desirable.
Asking a question on a website that only attracts a specific audience will be equally biased. In 2016, after a debate between Hillary Clinton and Donald Trump, very different results were found from various sources in the media.
The following is a poll taken from http://drudgereport.com shortly after the first 2016 Presidential debate. This is a website is a politically conservative American news aggregation website.
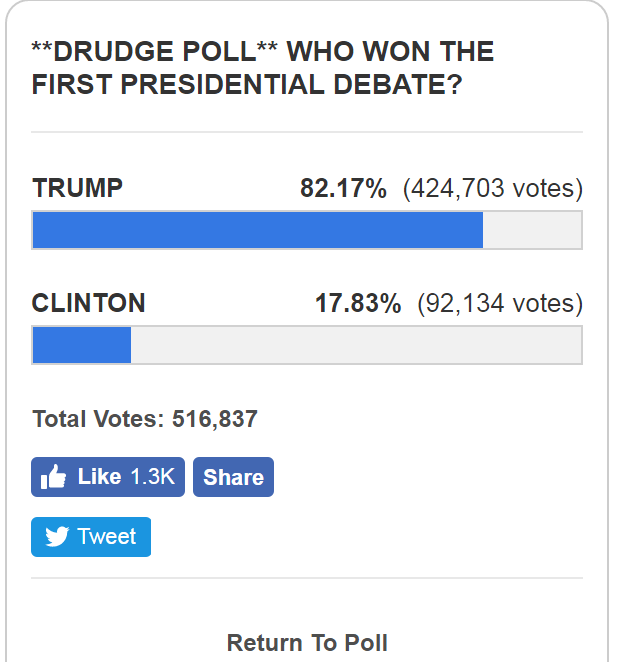
This is a convenience sample, not a scientific sample, and does not have a margin of error.
The tweet below reports the results of a poll taken by CNN/ORC.
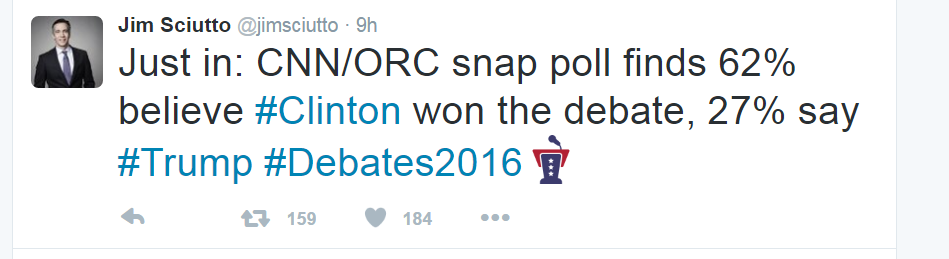
More complete results of that poll are here: http://i2.cdn.turner.com/cnn/2016/images/09/27/poll.pdf
It was a scientific sample, and does have a margin of error reported with it.
Many other polls by various newspapers, news channels, and other sites had widely varying estimates of who won the debate.
2. Unintentional Bias
A question’s wording may inadvertently be confusing. For example, I might ask a question “Have you used drugs in the past week?”, where some might interpret the question to be asking about the use of recreational substances that might be illegal, where others would be thinking about prescriptions drugs.
Also, we may have unconscious biases about different genders, races, socioeconomic classes, etc. that could affect the way we answer questions or approach situations that we don’t even realize.
3. Desire To Please
Suppose I am a nutrition researcher and I administer a survey to people about their eating habits. It is likely that what they self-report as their eating habits will not totally line up with what they actually eat.
It is likely people for a variety of reasons might choose to fib about their true eating habits–maybe exaggerating how often they eat vegetables and not mentioning all the cheeseburgers or ice cream.
4. Asking The Uninformed
You might get “I don’t know” or “no response”, and if too many people answer this way, you don’t gain much. For example, if I ask potential voters if they have a positive or negative opinion of Joe Sestak, a former Congressman from Pennsylvania that is running for the Senate, would you be surprised if a majority of the sample said “who’s that”?
Also, some people are more than happy to share opinions on topics that they know little to nothing about. Examples include people giving opinions on brands of shoes that were made up and didn’t actually exist.
5. Unnecessary Complexity
A question can be asked in a format or with vocabularly that is too complicated for the subjects. For example, asking college students to rate if they like their professor on a 1-to-5 or 1-to-10 Likert scale is appropriate, but with pre-school aged children, a simpler scale with a smily face or frowny face would be more appropriate.
What about this question?
“In the view of escalating environmental degradation and incipient resource depletion, would you favor economic incentives for recycling of resource-intensive consumer goods?”
6. Ordering of Questions
If questions are potentially related to eaqch other, then the first question asked can impact the answers on subsequent questions.
Example: Suppose I ask a random sample the following two questions, in this order.
Q1: What do you believe is the most important problem facing the nation? [open question]
Q2: Do you approve or disapprove of the way President Trump is handling his job?
What if I switch the order? What if I change Q1 to be a closed question, giving the following options:
immigration
the economy
climate change
crime.
7. Confidentiality vs. Anonymity
Confidentiality is when the researcher knows the identity of the subjects, but promises not to reveal that identity when reporting the results.
Anonymity, on the other hand, is when the subject’s identity is unknown to the researcher.
I think you can see that for sensitive topics, such as sexual behavior, illegal activity such as drug use, etc. that this distinction is important and can impact if the subjects will honestly answer questions or not.